基于LightGBM算法的中小上市公司财务困境预测研究
2021-03-29洪欣琪
洪欣琪
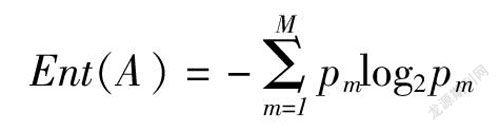
摘要:基于集成思想选择L1、随机森林、极限树、f_classif、XGBoost五种方法构建特征选择集成评分模型并筛选出关键特征,利用SMOTE算法处理非平衡数据,在此数据预处理基础上基于LightGBM算法建立财务困境预测模型并将实验结果与以逻辑回归、支持向量机、决策树、XGBoost等算法为基础建立的预测模型对比。结果显示,在测试集上LightGBM集成学习模型对中小企业财务困境预测准确率高达0.950 877、AUC值为0.975 8远远高于基于其他算法的预测模型。这对金融企业精准评价中小企业的财务风险以及政府实施中小企业政策扶持提供决策参考。
关键词:财务困境预测;集成学习;LightGBM;特征选择
中图分类号:F275;TP311.1 文献标志码:A 文章编号:1008-4657(2021)03-0057-17
引言
我国中小企业是在经济运行中发挥关键作用的社会主义经济发展主体,在稳定就业、平稳经济增长、促进技术创新和推动结构转型中作用显著。2018年末我国中小企业达到1 807万家[ 1 ],在全部规模的企业单位中占比99.8%。截至2019年,我国中小企业营业收入已达到约78.1万亿元,2019~2023预计年均复合增长率约为3.75%,2023年将达到90.5万亿元。2018年中小企业吸纳就业人口23 300.4万人,在全部企业就业人口中占比79.4%[ 2 ]。中小企业虽然地位关键,但绝大多数中小企业将会面临“第三门槛”的现象[ 3 ],即中小企业到达第三个经营年份将会面临破产的风险,这主要是由于企业出现财务困境而导致,所以利用技术手段辨别可能会陷入财务困境的中小企业对银行、政府以及中小企业自身发展非常必要。
建立财务困境预警体系以及预警模型从而精准识别可能会出现财务困境中小企业的过程尤为重要。传统的财务困境预警模型以利用计量方法为主导,但随着科技的发展和学术研究发现利用机器学习方法建立的财务困境预警模型比计量模型更准确且高效。本文在传统的机器学习算法的基础上,以集成思想为主导,创新性的采用2017年由微软亚洲研究院提出的轻量化梯度促进机(Light Gradient Boosting Machine, LightGBM)算法建立中小企业财务困境预测模型,为了提高模型预测精度和准确性在数据预处理阶段通过过采样处理非平衡财务数据,并建立特征选择集成评分模型来进一步筛选影响判断财务状况的关键特征。在与逻辑回归、支持向量机、决策树、XGBoost等算法做对比实验时,LightGBM财务困境预测模型的预测准确性高达0.950 877,远高于其他预测模型。实验结果表明本文对LightGBM算法的创新应用不仅具有理论研究意义,对银行、政府和中小企业自身具有现实的实践意义。
1 文献综述
在中小企业财务困境的界定上,不同的学者持有不同的看法。在国外,以Beaver W H等[ 4 ]的研究观点作为最经典的财务困境的定义,即出现债务拖欠、无法支付股息红利出现违约行为,最终企业实行破产清算。Carmichael D R[ 5 ]在前者的研究基础上扩大了对财务困境定义的范围,认为当企业出现流动资金短缺、股本不足时也视作出现财务困境的信号。在国内,吴世农等[ 6 ]提出公司陷入财务困境的过程就是从正常到逐步恶化的过程。张金昌等[ 7 ]对财务困境的界定更加全面,不仅将财务困境界定义为从资金紧张、债务违约到企业失败破产的动态过程还将企业财务困境问题归结为资金供求失衡。
上世纪80年代以来,机器学习算法在各个领域广泛应用逐渐取代了数理统计建模方法并走向成熟,逻辑回归、神经网络、决策树、随机森林、支持向量机等方法在中小企业财务困境预测上均有着广泛的应用。其中在逻辑回归算法研究中Dreiseitl S等[ 8 ]提出逻辑回归能够实现向前、向后和逐步变量选择,令模型更易理解实现更小的泛化错误。众多文献中对于支持向量机的研究较为丰富,更多的是与其他算法的对比分析,Huh J等[ 9 ]利用小样本实验对比支持向量机与BP神经网络的分类效果并发现支持向量机的效果更好。方匡南等[ 10 ]建立的SGL-SVM方法以及Mehdipour V等[ 11 ]在支持向量機与GEP的对比实验中也得出了相同结论。神经网络在企业财务困境预测的应用中,Odom M D等[ 12 ]率先引入ANN模型来预测公司破产,Sung T K等[ 13 ]等学者使用辨别算法、遗传算法、神经网络来编辑决策树,其结果可解释并改善机器学习的“黑箱”特性。当对机器学习算法深入研究之后,学者们逐渐意识到单一学习器存在许多弊端,为了优化研究结果,集成学习成为研究热点[ 14 ]。集成学习将单一学习器作为基学习器以投票算法集成最终实验结果[ 15 ]。Dietterich T G[ 16 ]在文章中总结道最原始的集成算法是采用多数投票制的贝叶斯平均。Jiang M R等[ 17 ]集成模式分解、极限学习、改进的和谐搜索算法等预测股票价格。Zhao Y等[ 18 ]将深层自然网络模型和Bagging集成模型相结合建立SDAE-B模型,以上学者均得出结论:基于集成算法的模型在回归和预测方面的表现优于单一算法模型。2017年在集成学习领域再次实现了创新,提出了LightGBM算法,该算法在集成学习的基础上从数据和特征两方面进行改进,实现对大型数据集的学习并降低了内存的消耗[ 18 ]。作为集成学习领域的研究热点,Minastireanu E A[ 19 ]利用LightGBM算法建立个人网络贷款违约预测模型,我国学者Sun P C [ 20 ]和马晓君等[ 21 ]对以LightGBM算法为基础的个人网络贷款违约预测模型进行了深入研究。在许多复杂问题的预测上,包括GPU恶意软件预测[ 22 ]、房价预测[ 23 ]、谷歌商店顾客购买力预测[24]等,LightG BM算法均提供了良好的解决路径和精确的实验结果,并且众多研究根据LightG BM模型的预测结果能够获取研究问题的主要影响因素[ 25 ]。通过对国内外文献的梳理我们发现LightG BM算法在许多学科的应用上表现极佳,主要包括提升了训练速度、训练精度,降低了训练内存、支持并行学习、更快的处理海量数据等。本文认为将性能优良的LightGBM算法应用于中小企业财务困境预测上将会促进该领域的发展。
对财务困境预测的研究一直是金融领域或者会计领域研究的热点问题,如果企业走向破产不仅会对自身和与之合作的金融机构带来致命打击还会引起整个金融市场的波动,因此对企业财务困境进行科学而准确的预测至关重要。随着机器学习领域的研究成果逐渐丰富,在财务困境预测问题上应用集成学习深入研究更具有理论意义和实践意义。通过对以往学者针对集成学习以及LightGBM算法应用的总结发现,LightG BM算法发展时间较短,众多针对LightG BM算法的研究并不丰富且很少涉及中小企业财务困境预测问题。本文创新性的将LightG BM算法应用于中小企业财务困境预测方面并建立财务困境预测模型,而且在数据预处理时利用过采样处理非平衡财务数据集并建立特征选择集成评分模型筛选重要实验特征并在此基础上进一步提高财务困境预测的准确性。
2 理论基础
通过建立财务预警模型能够对可能出现的财务危机进行及时反映,对企业和相关金融机构来说根据财务困境预测模型结果能够基本掌握企业自身或是目标客户财务状况,及时采取应对措施降低财务风险;对于政府来说,及时了解众多公司的财务状况有助于其科学而全面的管控维持市场秩序。但是建立精准的财务困境预警模型对技术要求非常高,若不能保证模型预测精度和准确性将会给市场上的多方主体带来巨大损失。2017年由亚洲微软研究院研发并开源的LightGBM算法是一个基于梯度决策树的框架。作为集成学习技术框架下的新的分支LightGBM算法的提出主要为了解决XGBoost算法在运算时间和运算内存损耗上的弊端,两种算法的核心思想以及理论支撑基本一致。LightGBM算法以决策树为基础、将GBDT作为核心并通过二阶泰勒展开,利用直方图算法、优化叶子生长策略、直方图差加速等方法改进GBDT,在数据和特征两方面分别利用GOSS方法和EFB方法做了加速处理。LightGBM提出后在诸多应用中实现了高速、高准确率以及大规模数据处理的作用现已成为机器学习算法领域的应用热点。下文将以LightGBM算法理论实现的逻辑顺序梳理相关算法的理论支撑。
2.1 决策树
决策树形成的二叉树结构可以作为多层的规则集合或者类空间和特定空间的条件概率分布,既可以用于分类任务也可以用于回归任务,本文主要以决策树二分类算法为基础来讨论。各个节点的排放顺序决定决策树的构建,有3种排放节点顺序的策略包括:信息增益、增益比、基尼系数,这3种策略决定了决策树的划分标准,一般选择信息增益最大的属性作为根节点并通过递归计算最优的节点属性便组成最优决策树。
信息增益 = 样本熵 - 所有测试属性熵的合
其中,熵是指样本集纯度,理论上熵值越小样本集纯度越高,熵的计算公式如下所示
在上述公式中,pm为第m类样本的占比。
信息熵指带入测试的属性对于样本集纯度的增益效果,即对样本纯度的提升效果。与熵值相反,信息熵则是越大越好。信息熵计算公式如下所示
在上式中,AW为满足某个测试属性的样本集。
为避免过拟合并能够在未知的测试集样本中取得较好得效果,“剪枝”过程非常重要。决策树中“剪枝”包括“预剪枝”和“后剪枝”,“预剪枝”是指在划分节点之前计算,若该节点划分不能实现泛化能力的提高则停止划分;“后剪枝”是指生成决策树后自下而上对非节点进行考察,若叶节点被子树替代能够提高泛化能力则将此叶节点替换为子树。
2.2 集成学习
集成学习(Ensemble Learning)是将若干个基学习器相结合最终实现超过单一学习器学习效果的目的。集成学习根据需要预测的样本集生成若干基学习器,基学习器首先进行训练得到各自的預测结果,之后按照集成策略将基学习器得到的结果进行结合,最后获得最优结果。当下,有两种集成学习方法被广泛使用:一种是装袋算法(Bootstrap aggregating, Bagging)对训练集抽取时采取有放回的方式,产生众多子数据集,根据子数据集建立若干基学习器在互不干扰的条件下分别进行训练得到训练结果,利用简单投票法或加权求和法结合基学习器产生的结果得到更为精确的数据。Bagging方法能够将数据并行化处理,在随机森林算法中有充分体现。另一种是提升算法(Boosting),Boosting方法建立一系列机制能够将弱学习器提升为强学习器,体现一种整体思想。首先对完整数据集进行训练得到一个弱学习器并获取训练误差,更新数据权重,让误差数据在下一轮训练中加强学习,经过反复学习迭代,训练误差将会逐渐降低,最终得到最为准确的训练结果。GBDT、XGBoost算法、LightGBM算法均采用了Boosting算法。
2.3 GBDT
GBDT在提升树(BDT)算法的每棵树残差叠加过程进行改进,向损失函数负梯度方向进行优化,提升弱回归树最终形成强回归树。
设每颗决策树有N个子叶,故每棵树划分了N个不相干的区域,分别为R1m,R2m,…R3m,并将Rnm的预测值确定为bnm。回归树可以用下方公式描述
在x∈Rnm时I(*)值为1,其他情况为0。
将改进模型的梯度下降步长设置为βm,则新的回归树公式为:
其中,L(y1,fm-1(x1))为梯度提升决策回归树的损失函数,梯度下降的优化条件是使损失函数最小化,利用回归树替换,上式可以转化为:
2.4 LightGBM算法
在GBDT的基础上LightGBM算法在很多方面做出了改进,除了在数据和特征两方面提升了训练速度,还利用二阶泰勒展开式优化了算法的目标函数将决策树的复杂度作为正则项。
LightGBM算法为了使指定的损失函数L(y1,f(x))最小化,通过训练找到f(x)的近似值f(x),其中f(x)又叫做優化函数,可以表示成
在LightGBM模型中集成K颗回归树来拟合最终的模型,这一过程可以表示为
模型中回归树用Mq(x),q∈{1,2,…,J}表示,M为叶子节点样本权重向量,J为回归树中叶子个数。特别的,在生成第t颗树时之前的(t-1)颗树的信息均会被利用,因此经过t次迭代生成的目标函数将如下所示
在上式中,Ω(fm(x))为正则化项,目的式为让模型在训练数据时避免过拟合的现象。对目标函数进行二阶泰勒展开,则展开后的目标函数可以表示为
在确定树结构为q(x)后,相应的目标函数为
上式中为每个叶子节点的最优权值得分,模型需要实现的最优化问题是指将目标函数最小化,通过计算回归树叶子节点的分裂收益使分裂收益达到最大,并选择收益最大的分裂特征,将这一过程持续迭代,直到满足条件为止。分裂收益可以由下式表示
随着机器学习所面对的问题日益复杂、数据逐渐庞大,特征维度不断提高,LightGBM算法模型能够深化训练层次,通过使用直方图算法、Leaf-wise叶子生长策略、直方图加速算法来降低计算速度、减少算法复杂度、降低计算机内存使用最关键的是很大程度上提高了模型训练的准确性。
3 研究设计
3.1 样本选取
本文实验数据均来源于国泰安数据库,共选取777家中小上市公司2015~2019年的财务数据,其中被“ST”处理的企业为77家,正常企业为707家,符合实际市场情况。由于企业连续两年出现亏损会被“ST”处理,即被认为企业出现财务困境,本文认为若企业在T年被“ST”处理一般此消息在T-1年的年报中就已经公布,所以选择T-2年的财务数据进行财务困境预测建模更合理。考虑到企业应对财务危机存在时滞且模型结果容易出现过拟合,本文选择利用T-2、T-3、T-4年的中小企业财务数据和非财务数据分别建模,其中非财务数据的选择参考了王瑞芳[ 26 ]、杨青龙等[ 27 ]学者的研究成果选择了企业管理类指标数据。为了减少实验过程中可能会出现的异常情况,在数据集构建时根据以下标准对数据进行预筛选:
剔除银行业、证券业等价格波动较大的公司;
剔除财务报表公布不完整的公司;
剔除因其他原因被ST处理的公司。
财务数据由60个反映中小企业的偿债能力、发展能力、经营能力、每股指标、现金流和盈利能力的财务指标和4个反映中小企业股权信息指标构成,如下表1所示。在样本的划分上,将被“ST”处理的中小企业设定为存在财务困境的企业,“非ST”的中小企业设定为正常公司,以数据集的70%作为训练集,训练分类模型,以30%作为测试集来检验模型的实际分类效果。
3.2 数据预处理
3.2.1 缺失值探索及插补
由于中小企业规模较小财务管理水平有限,从数据库获取的原始数据存在部分缺失现象,本文首先利用python对所获取的中小企业64个财务指标进行缺失值探索,结果如下表2所示。
由上表可知共有25个特征不存在缺失值,但某些财务特征缺失值达78.14%,简单删除缺失值将会损失大量数据造成模型训练效果不佳,故本文选择对数据集缺失值进行插补。经过数据分布的抽样检验结果如图1所示,该数据集不服从正态分布所以无法利用平均值、众数等简单方法进行填补,本文使用的K-最近邻(KNN)法通过相关性分析或欧氏距离确定与缺失值最近的K个样本,通过对K个样本值的加权平均来估计缺失值实现较好的插补效果。
3.2.2 异常值处理
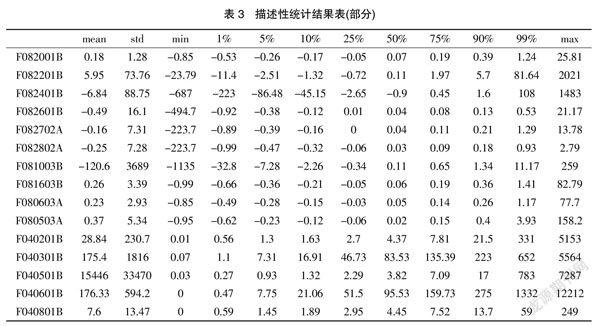
由于中小企业财务管理水平有限或者人工统计数据时出现纰漏,所获取的中小企业财务数据中存在不符合整体数据特征的情况,当数据集中包含大量异常值将会影响最终实验结果。本文利用描述性统计对数据集中的异常值进行探索,结果如表3所示。
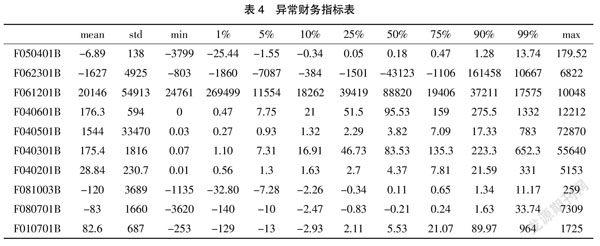
本文对财务数据的描述性统计包括平均值、最大值、最小值以及在1%、5%、10%...99%时的数据分布,根据描述性统计结果共有10个财务指标数据整体出现异常,部分数据出现严重的量纲不统一的现象例如Max最小的仅有2.79最大却达到了12 212,某些数据在99%分布时占比为81.64出现了严重右偏,本文将10个整体异常的异常值删除,并统一数据量纲。异常财务指标如表4所示。
3.2.3 非平衡数据的处理
现实中,“ST”处理的中小企业数量要远远小于正常企业,所以收集的原始数据集高度不平衡,当使用非平衡数据训练预测模型时便会出现分类器失真的现象。其中本文数据中正常样本有707个但存在财务困境样本有70个存在严重不平衡,经过综合分析选择利用抗噪性更强、更适用于本文数据的SMOTE算法来平衡数据集,SMOTE算法的核心思想是人工合成少数类实现数据样本平衡。
3.2.4 特征选择
为了选择与中小企业发生财务困境关联密切的财务特征,本文对所收集到的64个中小企业财务指标进行特征选择。许多研究在进行特征选择时方法较为单一,对预测模型效果有一定的影响,本文集成L1正则化(L1)、极限树、随机森林、特征选择过滤器(f_classif)、XGBoost五种特征选择方法构建特征选择评分模型。
本文所选择构建特征选择集成模型的5种特征选择算法涵盖了两大主流特征选择方法:单变量特征选择和Embedding特征选择法。其中f_classif代表了单变量特征选择主要解决分类任务的特征选择需要,保留评分最高的K个特征;L1特征选择与极限树特征选择属于Embedding特征选择法这一类,通过设置惩罚项得到稀疏解从而实现降维的目的并且可以根据重要性对所选特征进行打分,其中极限树又叫做极端随机数,与随机森林采用的Bagging模型不同,极限树采用的是所有样本并且完全随机地得到分叉值,因为分裂过程是随机的所以特征选择也是随机进行的。这样的特性使得极限树在某种程度上能够取得比随机森林更好更全面的结果;基于随机森林和XGBoost算法建立的特征选择模型将机器学习算法中的打分机制引入特征选择,逐渐成为主流方法。本文通过集成这5种特征选择方法最终从64个财务指标中筛选出14个实验特征,特征选择评分模型流程图如图2所示。
根据构建的特征选择评分模型,5种特征选择方法分别按照对财务困境预测的重要性進行排序,其中L1特征选择筛选出19个财务指标,随机森林特征选择筛选出15个财务指标,极限树特征选择筛选出19个财务指标,f_classif特征选择筛选出24个财务指标,XGBoost特征选择筛选出18个财务指标,在评分模型中当财务指标被1种特征选择方法选中时计1分,评分达到3分或3分以上的财务指标作为最终的训练特征。各种方法及评分模型最终筛选出的财务指标如表5、表6所示。
在5种特征选择方法中,极限树算法不仅可以挑选出关键特征还能生成所有特征对于企业财务困境预测重要性排序有助于深入分析企业财务特征与非财务特征对中小企业财务困境预测的影响程度。生成的结果如表7所示。
由上表展示的结果可知代表中小上市公司发展能力的财务指标在财务困境预测中的占据十分重要的地位。重要性排在前十位的指标分别是总资产增长率、每股留存收益、资产报酬率、流动资产净利润率、总资产净利润率、每股未分配利润、净资产收益率、营业利润率、可持续增长率、权益乘数。本文认为特征重要性排序可以作为特征选择集成模型结果的有效补充并增添机器学习算法的可解释性。无论是最终选择的实验特征还是特征重要性排序,本文发现非财务指标对财务困境预测的影响较小,建立模型时还是以财务指标数据作为最终实验数据。
3.3 评价指标
为了辨别LightGBM集成学习模型的分类效果以及与其他分类器相比是否更优,本文引入6种评价指标,分别为准确率、精准率、召回率、f1_score、AUC(Area Under the Curve)和ROC曲线(Receiver Operating characteristic Curve)。首先,我们根据样本真实的类别和模型预测类别的组合形成4类,分别为TP(真正例)、FP(假正例)、TN(真反例)、FN(假反例)。很明显将这4类所包含的样本相加就是完整的数据集,分类结果的混淆矩阵如表8所示。
3.3.1 准确率
准确率(accuarcy)正确分类的样本占总样本的比率即正确分类的概率,是判断分类模型分类效果最直观的评价指标,计算公式为
准确率的判断受数据是否平衡的影响较大,当数据非平衡时,准确率会出现虚高的情况,需要预先处理非平衡数据以及与其他评价指标相结合。
3.3.2 精准率、召回率与f1_score
精准率(precision)又称作查准率,表示在分类器判别为正例的样本中有多少是真正的正例。精准率公式如下所示
召回率(recall)又称作查全率,表示样本的所有正例中有多少被准确的分辨出来。召回率公式如下所示
精准率与召回率是一对相互矛盾的概念,当精准率高时召回率便低,所以在实际情况下在不同的领域侧重于不同的指标,例如在传染病例辨别中需要100%将病例辨别出来这就需要较高的召回率。为了调和精准率与召回率产生的结果,本文引入f_score评价指标。f_score又称作平衡F分数,是精准率与召回率的调和平均数,公式如下所示
3.3.3 AUC值与ROC曲线
ROC曲线是受试者工作特征曲线的简称,以真阳率(TPR)为纵坐标,假阳率(FPR)为横坐标的感受性曲线。ROC曲线之所以被广泛应用是因为不同于传统二分类的评价方式在ROC曲线上可以反映更多模糊的中间状态,适应范围更广泛。
如果一个分类器的ROC曲线将另一个分类器的ROC曲线包裹住,则说明前者的分类效果更出色。但是,如果两个分类器的ROC曲线相交则无法通过曲线图来分辨效果,因此本文引入表示ROC曲线下方面积的AUC值,设ROC曲线是由众多点连接而成,点的坐标分别为{(x1,y1),(x2,y2),…,(xn,yn)},则
AUC值越高说明模型分类效果越好。
3.4 实验结果及分析
本文通过代码实现建立了LightGBM集成学习模型,通过对训练集的学习来训练模型,再利用测试集检验模型的分类效果,最终T年基于LightGBM算法财务困境预测模型的准确率达到95.0877%,实验结果与真实值之间的均方误差为0.233 2,并获得LightGBM最终的ROC曲线和AUC值,LightGBM模型ROC曲线和AUC值如图3所示。
为了验证基于LightGBM算法的财务困境分类模型的实际分类效果,基于T年的数据利用对逻辑回归、支持向量机、决策树等机器学习模型以及XGBoost集成学习模型进行训练和测试,在本文所选的对比算法中逻辑回归与支持向量机是典型的线性分类器,主要处理二分类问题。其中逻辑回归不仅能够处理大规模数据实现分类还能够生成具有定性作用的连续型数值,而支持向量机在运算速度和运算准确性上远高于逻辑回归。决策树算法是典型的非线性分类器能够完成多分类任务,并且能够处理相关性不高的数据,通过剪枝操作能够使决策树模型更具有灵活性在准确性的提高上和适应数据范围上有了进一步的发展。XGBoost不同于以上4种机器学习方法而是属于集成学习范畴并且在集成学习中占据重要地位,作为一种优化分布式梯度增强库在实现过程中表现出更高效、更便捷、更灵活等特点,是一种新颖的处理稀松数据的树学习算法。实验结果如表9所示。
T年财务数据建立的所有模型训练集的效果要优于测试集,集成学习模型的分类预测效果整体好于机器学习模型。在机器学习模型中,决策树模型在训练集上的效果最好,召回率达到0.999 6,AUC值达到0.999 5,接近于完全正确分类,但是在测试集上结果却不理想,AUC值仅0.754 3;支持向量机模型和逻辑回归模型在测试集上都展现出良好的分类效果,AUC值分别为0.959 4和0.941 5;在集成学习模型的对比中,无论在训练集还是在测试集上LightGBM都表现出出众的的分类效果,各种分类评价指标略高于另一个集成学习算法XGBoost,其中在测试集上AUC值达到0.975 8是所有分类预测模型中最高的,并且LightGBM集成学习模型所花费的时间更短,分类预测效率更高。
为了更直观的对比不同分类预测模型的效果,本文还在实验中实现了各种模型的ROC曲线图,如图4~8所示。
由以上每种分类模型的ROC曲线图可以看出,比起机器学习分类模型,XGBoost和LightGBM集成分类模型的ROC曲线更凸向左上方,而LightGBM模型的ROC曲线将XGBoost包裹住,说明LightGBM集成学习模型的分类效果是最好的。
为了检验不同年份的财务数据对识别中小企业财务困境的效果产生的影响,本文利用T-2、T-3、T-4年的数据对逻辑回归、支持向量机、决策树等机器学习模型以及XGBoost、LightGBM集成学习模型进行训练和测试,对比结果如下表10~12所示。
通过对表10~12所示的实验结果比较可知距离T年越近的财务数据反映中小企业财务问题就越明显划分预测中小企业是否出现财务困境的准确性就越高。无论是机器学习算法还是集成算法训练集正确率要高于测试集,这是符合理论逻辑的,经过结果对比可以发现在机器学习算法中支持向量机和决策树的分类效果要优于逻辑回归,而支持向量机与决策树在不同的评价指标下表现各异。在集成学习算法中,XGBoost与LightGBM在训练集上均表现出完美的分类效果,在测试集上基于LightGBM算法建立的中小企业财务困境预测模型要明显优于基于XGBoost算法建立的模型,在T-2年LightGBM算法实现了高达0.968 8的AUC值。
4 结论与展望
本文从国泰安数据库获取777家中小上市公司的财务指标数据和非财务数据作为原始数据,并将原始非平衡数据进行平衡化处理,利用L1、随机森林、极限树、f_classif、XGBoost等5种特征选择构建特征选择评分模型,从64个财务指标中筛选出14个作为本文的实验特征组成更加紧凑、更高密度的数据集使得训练后的模型预测效果更好。本文首次将LightGBM集成学习模型在中小企业财务困境预测上应用,并将经过预处理的数据以7:3的比例划分训练集与测试集,利用训练集训练模型,测试集检验最终结果,最终结果显示LightGBM集成学习模型测试集上的准确率达到95.087 7%,AUC值达到97.58%。在与不同的分类模型分类效果的比较中,集成学习模型的分类效果要优于简单的机器学习模型,在众多的集成学习模型中,LightGBM的分类效果最好。
中小企业在我国国民经济中占据重要地位,为我国税收和就业贡献巨大力量,对中小企业财务困境预测现在和未来都将会是会计与金融领域的热点问题,中小企业的财务困境的预测对金融机构和监管机构都非常重要。本文通过特征选择集成评分模型筛选实验特征并对所选中小上市公司各类指标重要性进行排序发现代表企业发展能力的财务指标对是否出现财务困境问题的影响较大,据此实验结果为提高我国中小上市公司综合发展能力提出几点建议:
首先为提高中小上市公司的可持续发展能力在不同的生命周期应该关注的焦点各不相同[ 28 ]。在企业初始创立时期整体较为脆弱,应该关注企业所处行业环境、政府的政策支持、初创产品的优势以及企业自身的技术条件;当企业进入成长期便应该追求外部大量的资金支持其扩大再生产、内部严谨的组织结构配合企业的进一步发展;在企业步入成熟期后需要将各方面的条件协调起来共同发挥作用,包括经营规范、管理制度、组织结构和人力资源等;如果企业出现财务困境转而进入衰退期则需要在技术创新和企业转型上投入大量精力并利用企业文化激发内部二次创业的激情。
其次为提高中小上市公司的创新发展能力应该增加对以下六个方面的关注[ 29 ]:以国家政策方向作为企业发展大方向,把握国家的政策优势;依托国家新基建发展力量,实现企业转型;提高金融体系的创新力度,降低金融与实体之间资金对接壁垒;将内部管理流程责任制分配,实现企业内部组织模式优化;结合中小上市公司“小规模、轻资产”的特点形成供应链多方合作机制;营造企业创新发展的健康生态,实现发展模式创新。
本文通过对数据预处理、特征选择以及集成学习模型的探讨提出以下几点展望:
第一,由于中国的中小上市公司所有权结构和治理结构的特殊性,导致数据有一定的限制性,而且金融数据的非平衡性是普遍现象,未来可以拓宽中小上市公司的数据类型,并进一步探索非平衡数据的处理。第二,在模型训练过程中不同类型的误差将会造成不同的损失,可以给误差“不等成本”计算“成本敏感”,尝试引入假设检验、交叉验证t检验和McNemar检验来比较在泛化功能上是否将优于其他分类器。第三,本文提出的特征选择评分模型以及LightGBM集成学习模型可以尝试应用于深度学习领域,并试验性地探索和解释模型的“黑箱”特性。
参考文献:
[1] 冯海波,陆倩倩.对中小企业减税可以提高其吸纳就业能力吗——基于中小板上市公司数据的分析[J].税务研究,2020(10):21-28.
[2] 国家统计局.我国企业信息化水平持续提升——第四次全国经济普查系列报告之四[EB/OL].(2019-12-05)[2021-2-8].http://www.stats.gov.cn/tjsj/zxfb/201912/t20191205_1715468.html.
[3] 陽友明.对中小企业财务风险预警体系构建研究[J].财会学习,2017(7):61.
[4] Beaver W H, Financial ratios as predictors of failure[J]. Journal of Accounting Research, 1966(4): 71-111.
[5] Carmichael D R. The auditors reporting obligation: The meaning and implementation of the fourth standard of reporting[J]. Audit Res Monogr, 1972(2): 94.
[6] 吴世农,卢贤义.我国上市公司财务困境的预测模型研究[J].经济研究,2001(6):46-55.
[7] 张金昌,王大伟.财务困境预警:概念界定与理论辨析[J].财经论丛,2020(12):61-69.
[8] Dreiseitl S, Ohno-Machado Lucila. Logistic regression and artificial neural network classification models: A methodology review[J]. Journal of Biomedical Informatics, 2002, 35(5)352-359.
[9] Huh J, Park Jong hun, Shin Dong min, et al. A hierarchical svm based behavior inference of human operators using a hybrid sequence kernel[J]. Sustainability, 2019, 11(18): 4 836.
[10] 方匡南,杨阳.SGL-SVM方法研究及其在财务困境预测中的应用[J].统计研究,2018,35(8):104-115.
[11] Mehdipour V,Memarianfard M. Application of support vector machine and gene expression programming on tropospheric ozone prognosticating for tehran metropolitan[J]. Civil Engineering Journal,2017,3(8): 557.
[12] Odom M D, Sharda R. A neural network model for bankruptcy prediction[J].International Joint Conference on Neural Networks, 1990(2): 163-168.
[13] Sung T K, Chang Namsik, Gunhee Lee. Dynamics of modeling in data mining: Interpretive approach to bankruptcy prediction[J/OL].Dynamics of Modeling in Data Mining: Interpretive Approach to Bankruptcy Prediction,1999,16(1): 63-85.
[14] Tsai C F,Hsu Y F,Yen David C. A comparative study of classifier ensembles for bankruptcy prediction[J]. Applied Soft Computing,2014(24): 977-984.
[15] Zhu Y, Zhou L, Xie C, et al. Forecasting SMEscredit risk in supply chain finance with an enhanced hybrid ensemble machine learning approach[J]. Prod Econ,2019(211): 22-33.
[16] Dietterich T G. Ensemble methods in machine learning[J]. International Workshop on Multiple Classifier Systems, 2000(1):1-2.
[17] Jiang M R, Jia L F, Chen Z S, et al. The two-stage machine learning ensemble models for stock price prediction by combining mode decomposition, extreme learning machine and improved harmony search algorithm[J]. Annals of Operations Research, 2020.
[18] Zhao Y, Li J P, Yu L. A deep learning ensemble approach for crude oil price forecasting[J].Energy Economics, 2017(66): 9-16.
[19] Minastireanu E A.Light GBM Machine Learning Algorithm to Online Click Fraud Detection[J]. Journal of Information Assurance & Cybersecurity. 2019:263928.
[20] Sun P C. Research on credit rating model of P2P project based on LightGBM algorithms[C].Proceedings of 2019 6th International Conference on Machinery, Mechanics, Materials, and Computer Engineering. Huhhot: Francis Academic Press, 2019: 345-348.
[21] 马晓君,沙靖岚,牛雪琪.基于LightGBM算法的P2P项目信用评级模型的设计及应用[J].数量经济技术经济研究,2018,35(5):144-160.
[22] Yadkikar P R. GPU based malware prediction using LightGBM and XGBoost[D]. California: California State University, 2020.
[23] 顾桐,许国良,李万林,等. 基于集成LightGBM和贝叶斯优化策略的房价智能评估模型[J].计算机应用,2020,40(9):2 762-2 767.
[24] 叶志宇,冯爱民,高航.基于深度LightGBM集成学习模型的谷歌商店顾客购买力预测[J]. 计算机应用,2019,39(12):3 434-3 439.
[25] Soo Y K. Predicting hospitality financial distress with ensemble models: The case of US hotels, restaurants, and amusement and recreation[J].Serv Bus,2018(12): 483-503.
[26] 王瑞芳.基于Lasso-logistic和XGBoost的上市公司財务困境预测[D].武汉:中南财经政法大学,2019.
[27] 杨青龙,田晓春,胡佩媛.基于LASSO方法的企业财务困境预测[J].统计与决策,2016(23):170-173.
[28] 张小红.生命周期视角下中小企业可持续发展能力评价研究[J].管理观察,2019,(28):15-16.
[29] 李波,林诗敏,洪露,等.提升科技型中小企业创新发展能力[N].贵州日报,2020-05-13(010).
[责任编辑:郑笔耕]
