基于三维引文关联网络的潜在知识流动探测
——以基因编辑领域为例
2021-03-15王菲菲王筱涵芦婉昭宋艳辉
王菲菲,王筱涵,徐 硕,芦婉昭,宋艳辉
(1. 北京工业大学经济与管理学院,北京 100124;2. 杭州电子科技大学管理学院,杭州 310018)
1 引 言
随着知识经济时代的到来,知识的价值被逐渐挖掘出来。同时,知识流动的活力凸显,在知识创新和科学发展方面发挥着不可替代的作用[1]。作为技术创新的基础,知识创新是经济增长与科技进步的动力源泉。知识流动是知识创新的必要条件,当创新主体中的知识转移(流动)到其他创新主体时,通过融合、内化、创新等形式又转化为新的知识,从而激发知识创新的产生[2]。
潜在知识流动,又称未来知识流动,是指目前尚未产生,但在未来很有可能发生的知识流动,可用于揭示学术领域内未来的知识创新。通过对已有的知识流动进行分析,推测出可能发生的创新方向,即探测潜在知识流动。潜在知识流动探测有助于科研工作人员追踪研究前沿与新兴研究趋势,为研究人员选择研究方向提供参考。
科学文献作为学术界最为普遍的知识载体,在学术生态圈中充当着学术媒介的角色。文献间的引证关系,本质上揭示的是知识流动与知识转移的过程[3]。被引方通过科技文献,将自身的知识进行传播,同时所传播的知识被引用方接受与吸收。施引方和被引方构成知识流动的线段,此线段的载体为科技文献。这种领域内知识的交叉融合有利于激发和启迪开拓思维,促使重大科学创新的产生[4]。目前,关于知识流动的研究大多数是以引文网络为基础展开的,且多集中于直引网络,在此基础上抽取到知识(主题)层面,构建知识流动网络。实际上,除了直引这种最为基本的引文关联外,共被引和耦合也是非常具有分析价值的两种典型引证关系。两者均是通过第三方文献的直引关系所建立的间接关联,而这种间接关联的存在会进一步强化原有的直引关联强度,这也成为三种引文关联融合的一项充分条件。此外,Morris 等[5]曾用一张盲人摸象图比喻从单一特征或关系来揭示领域内科学知识结构的片面性与局限性,形象地反映出单一分析维度对科学知识领域体系解释不够全面的问题,这也成为多重引文关联融合应用的一项必要条件。在这种背景下,本文的研究议题应运而生,旨在对直引-共被引-耦合三维引文关联网络进行融合的基础上,映射到主题层面构建知识流动网络,进行预测分析,挖掘领域内潜在知识流动,进而探测领域内的研究前沿或新兴趋势。
2 相关研究概述
2.1 三维引文关联融合
在文献中,主题是知识的直接表征。文献之间的引证关系本质上揭示的是知识之间的流动与转移,因而在刻画知识流动网络方面具有较为广泛的应用。文献间传统的引证关系主要包括:直引关系、共被引关系以及耦合关系。其中,直引关系作为最直接的一种引文关联方式,最能刻画领域内的知识流动现状。Shibata 等[6]研究表明,相比共被引与文献耦合网络而言,对直引网络分析作为引文分析中最为直接的关联挖掘方式,其在探测领域内的研究现状、挖掘知识交流情况等诸多方面的应用中具有最佳的表现。目前,已有的关于知识流动的研究多是以引文网络为基础,且多集中于直引网络[7-8]。直引分析固然重要,但是另两种引文关联方式同样也不可忽视,它们亦可作为直引网络在领域内实现更全面的关联发现中的有益补充[9]。三种引文关联在刻画领域研究现状各有侧重,单一引文关联不足以涵盖科学研究领域的全貌,不能反映真实的知识交流情况。相关研究表明[10],不同学术网络所揭示的学科知识结构及未来演化情况侧重于不同的方面,多重引文关联的融合将更全面地揭示领域内科学知识结构与研究现状。
鉴于上述现状,本研究尝试对三种不同的引文方式进行适度融合,进而实现更加全面的、真实的知识流动探测分析。迄今为止,有些学者提出了具体的思路来实现不同的引用关系的融合,最具代表性的是由Persson[11]提出的研究思路,其研究是基于一种被普遍认同的假设:如果两篇论文引用了相同的文献或者被相同的文献所引用,那么两者原本存在的直引关联将会被进一步增强[12]。Persson[11]的研究表明,在文献层面将共被引与耦合两种关联强度进行加权处理,进一步作为直引强度的附加,能够更好地实现领域内知识关联的探测。除此之外,在研究对象的价值计量研究中,引文网络融合的趋势较为明显,且已经在科学文献或专利技术的价值测度中均有一定的应用[13]。鉴于此,本文旨在从三维引文关联的文献层面,进一步抽取到主题层面,即构建三维引文关联下知识流动网络(主题关联网络),实现主题间更加全面的知识流动(引文关联)的识别。
2.2 潜在知识流动发现
潜在知识流动通过对现有知识流动网络进行分析推导,预测将来有可能发生的创新知识。多数研究通过对引文网络进行分析,知识流动方向与引用方向相反。潜在知识流动,即运用此种分析方式进行推测,将现有知识流动网络整合,预测出新的知识节点关联。
引文分析中的引证关系本质上揭示的是知识之间的流动与转移,当一个主题中的知识转移到其他主题,通过融合、内化、创新等形式又转化为新的知识。从知识论关于知识的发展模式来看,梁永霞等[14]认为文献引用的过程是在前人知识的基础上知识进化的过程,是知识的选择、遗传和变异的过程,也是知识的生产、传播和应用的过程,其认为引文分析的过程就是对知识流动过程和知识活动系统的分析。Yan[15]根据JCR(Journal Citation Reports)的主题分类,构建了主题间的知识交流网络,分析结果发现,相对于自然科学,社会科学与其他学科交流较少,具有独立性特征;Jo 等[16]通过期刊引文网络分析了纳米学与技术领域的学科结构及其跨学科特征,利用中介中心性确定了重要期刊,并分析了重要期刊在学科间知识流动中的作用;Ma 等[17]利用作者引证网络研究不同学科间的知识交流模式,并提出两个定量指标对知识交流进行测度。张艺蔓等[18]提出将引文内容分析与全文本引文分析相结合的方法,分析知识流动情况,从而探测出学科内部与学科间的知识流动趋势;宋凯等[19]从文献引证角度,将知识转移与知识转化结合,利用LDA(latent Dirichlet allocation,LDA) 模型进行主题提取,进而探讨一国与其他国家间的知识流动情况;李盈等[20]构建医学领域内期刊论文间的引文网络,通过可视化的引文网络表征知识的创造和传递过,利用社会网络分析方法揭示医学领域内各个学科间的知识流动特点和规律,为医学信息服务提供参考。
上述文献均以引文网络为基础,来探究知识流动的现状,或是挖掘知识流动的特点与规律,少有研究基于知识流动视角来实现未来知识流动的探究。本文在前期研究中,利用三种引文关系来预测学者间未来可能的显性交流,可视为从知识流动视角下探究未来交流情况的一种尝试[21]。但该研究仅停留在作者层面,并未延展到具体的知识细粒度层面。
究其根本,基于引文关联的知识流动发现是一种知识关联的发现,鉴于这种知识关联的有向性,可将其视为一种知识流动的发现。翟东升等[22]利用专利间的引用关系,构建IPC 引用网络表征知识间的流动,以此网络为基础进行链路预测,进而实现技术关联发现。李睿[23]从专利对论文的引用视角出发,探讨了有向知识关联下的知识流动,揭示了基础研究学科与技术发明领域之间存在的知识关联。
在上述文献中,大多数文献是以直引网络为基础,通过知识流动层面来探究知识关联,预测将来可能发生的知识流动,即潜在知识流动探测。三维引文关联融合主体间的多重引文关系,可以更全面真实地揭示领域内的知识交流与知识转移现状,有助于更真实、准确地对潜在知识流动进行识别。因此,本文尝试基于一种新的研究视角,通过三维引文关联融合下的知识流动网络链路预测,实现潜在知识流动的发现与探究。
3 研究方法与工具
3.1 三维引文关联融合
传统的引文关联有三种,包括直引关联、共被引关联和耦合关联。显而易见,直引关联是通过施引与被引关系而建立,表现为文献之间一种更为直接的引用关联;而共被引关联与耦合关联是通过第三方文献所建立的较为间接的引用关联。针对三维引文关联融合,本文参考Persson[11]提出的加权直接引用理论(weighted direct citations,WDC),将共被引与耦合两种间接关联通过加权变换附加到直引关联上,形成一种新型的融合后的引用强度;同时,进一步将共被引和耦合两种关联结果进行标准化处理再重新加权,得到标准加权直接引用结果(normalized weighted direct citation,NWDC)。加权直接引用理论具体算法原理如图1 所示。
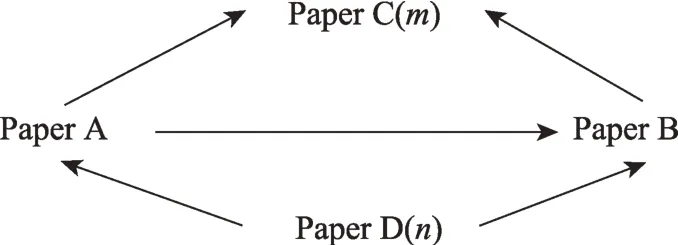
图1 加权直接引用理论算法原理图
图1 中的箭头方向代表文献施引的方向,即文献A 施引于文献B;m表示文献C 的被引频次;n表示文献D 的施引频次(即总参考文献数)。在图1所示的引用关系中,文献A 引用文献B 的WDC 值为3,文献A 引用文献B 的NWDC 值为(1+1/m+1/n)。
3.2 知识流动网络构建
鉴于主题是文献中知识的直接表征,本文用LDA 主题模型提取文献中的主题以代表知识。本文在三维引文关联融合的基础上,从文献层面进一步提取主题层面,进而构建三维引文关联视角下的知识流动网络。
首先,利用LDA 模型对文献集合进行主题提取。LDA 模型是“词-主题-文档”为层次结构的三层贝叶斯概率模型,该模型具有较好的主题识别能力,能够从文本语料库中抽取潜在的主题,因此,被广泛应用于科学文献的主题发现。为了确定所抽取的主题的数量,本文利用困惑度(perplexity)来评估主题模型对于待处理数据的预估能力,困惑度值越小,其模型预估能力越强,代表LDA 对于主题聚类能力越强[24],计算公式为

其中,Dtest是测试集;wd是文档d中单词序列;Nd是文档d中的单词数目。
其次,以三维引文关联网络为基础,根据LDA模型所提取各文献所对应的主题,将文献层面的三维引文关联网络映射到主题层面,构建领域内的知识流动网络。知识流动网络表征领域内各研究主题之间流动与转移过程,其作为多知识融合创新的表征,可从中挖掘特定领域内的研究前沿或新兴趋势。知识流动网络原理如图2 所示。
图2 中,文献A 与文献B 存在三维引文关联,通过LDA 模型抽取到文献A 的主题数量为2,抽取到文献B 的主题数量为3。从文献A 到文献B 的三维引文关联,可映射为6 项知识流动事件,即文献B 所研究的主题Topic_B1、Topic_B2、Topic_B3 向文献A所研究的主题Topic_A1、Topic_A2 产生了知识流动。
各文献内主题贡献度存在差异性,根据LDA 抽取后所获得的文档-主题分布文档,获得各文档下不同主题的概率分布,进而实现文献中各主题权重的分配与赋值。值得注意的是,本文中知识流动方向与文献间的引用方向恰好相反。根据上述原理,通过文献间的引用关系、文献-主题贡献分布,将主题对之间的信息转换为知识流动矩阵,最终转化为具有加权有向特性的知识流动网络。
3.3 基于链路预测的潜在知识流动发现
链路预测方法是通过分析社会网络的拓扑特征,来评估网络中两个节点之间产生链接的可能性,是目前应用最为广泛的一种预测节点间是未来否存在链接的方法[25]。在某种程度上来说,潜在知识流动的预测就是主题之间的未来链接预测,本文利用链路预测方法分析网络中的知识流动,即未来可能发生的知识流动以及知识流动的变化,将基于三维引文关联网络所映射出的主题知识流动网络进行特征分析,预测将来节点间产生链接的可能性,挖掘未来可能发生的新的知识融合趋势与未来演化趋势,进而预测未来的研究热点或者研究前沿问题。
潜在知识流动存在于满足以下两个假设的有向主题对中[22]:①有向主题对之间目前不存在知识流动;②两个主题之间存在产生知识流动(存在链接)的可能性。本文采用链接预测指标来衡量有向主题对之间的发生链接的可能性。
鉴于知识流动网络的加权有向的特性,本文选取了适用于加权有向网络的链路预测指标特征。具体选取指标包括加权有向的共同邻居(common neighbor,CN)指标、加权有向的admic-adar(AA)指标、加权有向的资源分配(resource allocation,RA)指标以及加权有向的优先连接(preferential at‐tachment,PA)指标。
(1)加权有向网络的CN 指标。无权无向的共同邻居指标是通过两个节点的共同邻居数量来定义两个主题的相似性。针对加权有向网络,计算公式为

其中,Γ(x)表示与主题x相关联的主题集合;wx→z表示为主题x向主题z流动的知识量(链接权重值)。该指标越大,说明主题x未来向主题y产生知识转移的可能性越大。
(2)加权有向网络的AA 指标。该指标对共同邻居节点赋予权重,并且共同邻居节点的度越小其贡献越大,

其中,表示邻居主题节点z除去自身强度的度,该指标越大,说明主题x未来向主题y产生知识转移的可能性越大。
(3)加权有向网络的RA 指标。受资源分配的启发,知识流动网络中不存在知识流动的两个主题x与y,因此主题x能够利用其共同邻居主题z向主题y传递知识资源,主题z在该过程中承担传输媒介角色。假设每个媒介都有一单位的资源平均分配给其邻居,那么主题y接受的资源数就是可定义为两主题的相似度,即
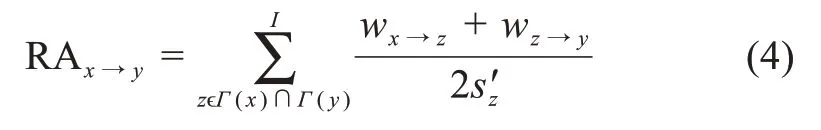
(4)加权有向网络的PA 指标。新链接连接到主题x与主题y的概率与两节点的度乘积成正比,推广到加权有向网路,定义为
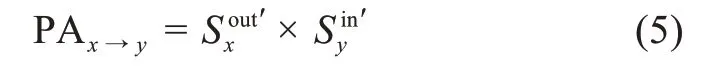
其中,表示主题x除去自身强度外的点出度;表示主题y除去自身强度外的点入度。
根据上述链路预测指标特征进行机器学习建模,采用机器学习中的集成学习方法随机森林(random forest,RF)算法构造分类器,融合不同的特征。以某时间切片下网络中的各链路预测为特征,将其下一时间切片网络中是否存在链接(0、1表示)作为分类结果训练模型,挑选出当前尚未产生链接的有向节点对,与训练好的模型相匹配,从而探究出未来可能发生链接的有向知识节点对。
链接权重的预测在网络预测中也占据十分重要的地位,但是鲜有学者研究链接权重的预测。当一对存在链接的有向知识节点对,目前链接权重较低,尚未引起学者广泛关注,未来若链接权重增长较大,则该有向知识节点对可能在未来成为研究热点或者研究前沿,并得到广泛地学术认可。同样地,以上述4 个链接预测指标为特征值,采用随机森林构造回归器,以某时间切片下网络中的各链路预测为特征,并将其下一时间切片网络中链接的权重作为目标变量y进行回归模型的训练。将网络中所有节点对的数据与训练好的模型相匹配,研究知识节点对之间的链接权重的变化,实现链接边权的预测。
4 数据获取与预处理
基因编辑领域诞生于20 世纪80 年代初,初期研究人员多见于欧美等地,在近十年,特别是CRISPR/Cas9 技术问世以来,成为世界性热点学科领域。CRISPR/Cas9(clustered regulatory interspaced short palindromic repeats/CRISPR-associated protein 9)是最近发现的一种新型的基因组定点编辑技术[26],这项划时代的靶向基因操作技术,在生物医学、遗传学、细胞学领域都得到了广泛关注。
为了更加全面地获得整个基因编辑领域内的论文数据,本研究选定Web of Science 数据库,并将检索年限定于1980—2017 年,以“gene edit* or crispr”为主题在数据库中检索共获得18717 篇文献,截取article、proceedings paper、review、book review 四类文献共14943 篇作为本研究的基本数据源。数据检索与获取时间是2018 年1 月5 日。最终选定被引频次≥10 的7072 篇文献为本研究的论文集合。按论文的发表时间,对论文集合时间切片,分别构建发表年 限 介 于T1 时 期(1980—2013 年) 与T2 时 期(2014—2017 年) 的标准加权直接引用(NWDC)网络,形成两个时期持续变化的引文关联融合网络。
为了科学、规范地提取基因编辑领域内的主题,本研究提取上述7072 篇文献的标题、摘要以及关键词作为实验数据集,并对该数据集进行数据预处理。利用Python 中提供的分词工具,实现分词、去除停用词、词干化等自然语言处理规范化过程,获得最终的文本语料库。利用LDA 主题模型对提取的语料库进行主题提取,主题数-困惑度的曲线如图3 所示,当主题数为200 时,困惑度指标达到最低值;后续随着主题数的增加,困惑度指标逐渐升高。因此,本文选取的主题数目为200。
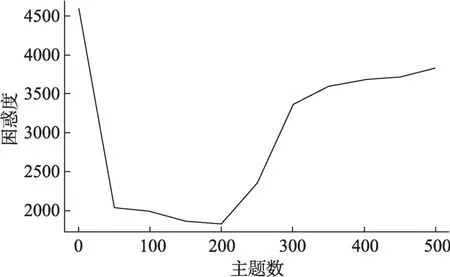
图3 主题数-困惑度折线图
5 三维引文关联视角下的潜在知识流动发现
5.1 知识流动网络构建
在三维引文关联融合分析中,本文采用标准加权直接引用(NWDC)网络来表示文献层面的多重引文关联;根据第3.2 节中构建知识流动网络的方法,通过文献到主题的映射,将文献层面的NWDC网络映射到主题层面,最终构建出三维引文关联融合视角下的知识流动网络(图4)。本文采用Gephi进行可视化分析,为了使得可视化效果更佳清晰,设置阈值为0.5。在图4 中,节点的大小与度中心性成正比,在T1 时期中,topic60、topic7、topic41 等主题具有较高的度中心性;T2 时期中,topic47、topic60、topic5 主题具有高的度中心性。这些主题在整个基因编辑领域内的知识流动与传播过程中占据着核心地位,是重要的研究关注点。
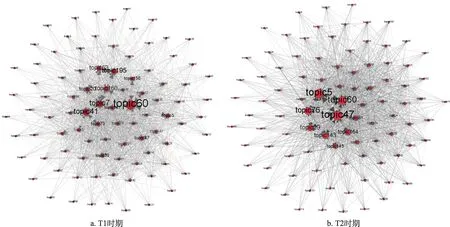
图4 三维引文关联融合视角下的知识流动网络
由于知识流动网络属于加权有向网络,因而选取了点入度与点出度作为衡量主题重要程度的两个网络指标。由表1 可知,T1 时期,topic60(原核生物基因编辑)、topic7(RNA 编辑)和topic41(人类细胞基因编辑)是较为重要的研究主题;T2 时期时,topic47(真核生物基因编辑)、topic5(基因编辑技术的开发)和topic76(人类疾病治疗技术)得到了更多学者的关注,成为该领域内关注度最高的研究主题。
T1 时期,最强的知识流动为:topic60(原核生物基因编辑)→topic7(RNA 编辑)、topic7(RNA编辑)→topic195(植物基因编辑)、topic195(植物基因编辑)→topic8(植物物种研究);T2 时期,最强的知识流动为:topic60(原核生物基因编辑)→topic5(基因编辑技术的开发)、topic5(基因编辑技术的开发) →topic47(真核生物基因编辑)、topic47(真核生物基因编辑)→topic5(基因编辑技术的开发)、topic47(真核生物基因编辑)→top‐ic76(人类疾病治疗技术)、topic60(原核生物基因编辑)→topic76(人类疾病治疗技术)。
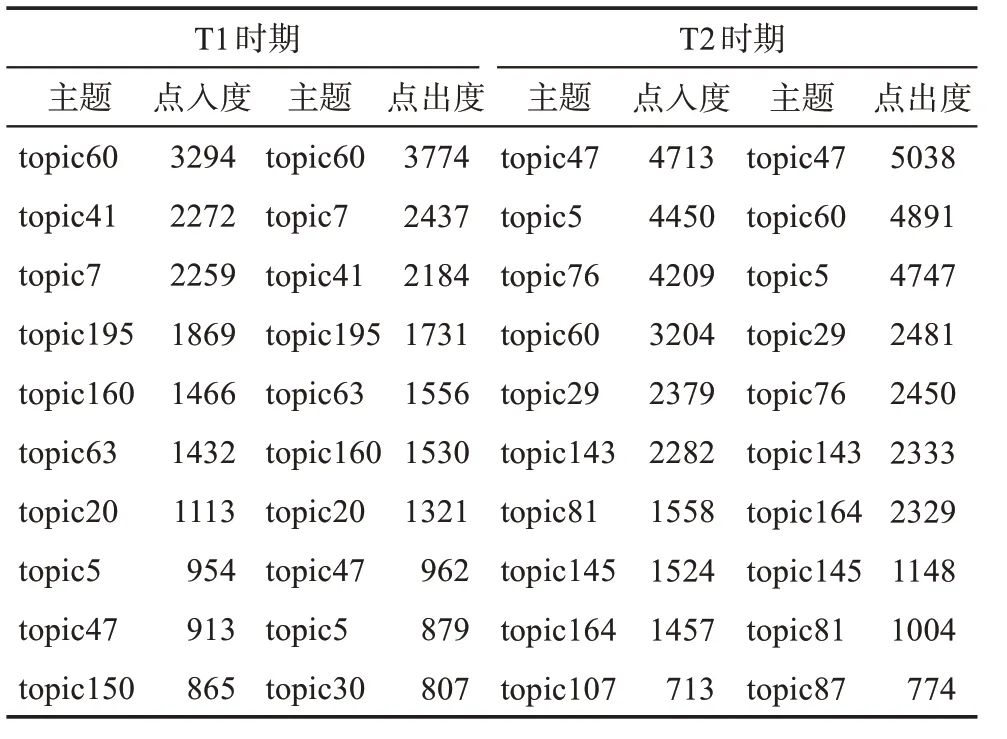
表1 知识流动网络的点入度与点出度
5.2 链路预测模型训练
5.2.1 潜在知识流动发现预测模型训练
对T1 时期的知识流动网络,针对每一组有向主题对,计算相对应的链路预测指标作为特征值x;并以T2 时期所对应的分类数据(有连接为1、无连接为0)作为目标变量y值。将上述数据输入到多个分类器中进行训练,以期找到最合适的分类器模型。
为了检验模型的准确度,本研究采用“留出法”划分数据集,随机选取80%的数据作为训练集,其余20%数据作为测试集。针对各分类器模型,本研究经过参数调整得到了该模型下的最优结果。表2 为训练好的各分类器算法基于测试数据集的评价指标:准确率(accuracy)、精确率(preci‐sion)、召回率(recall)与F1 分数(F1-score)。
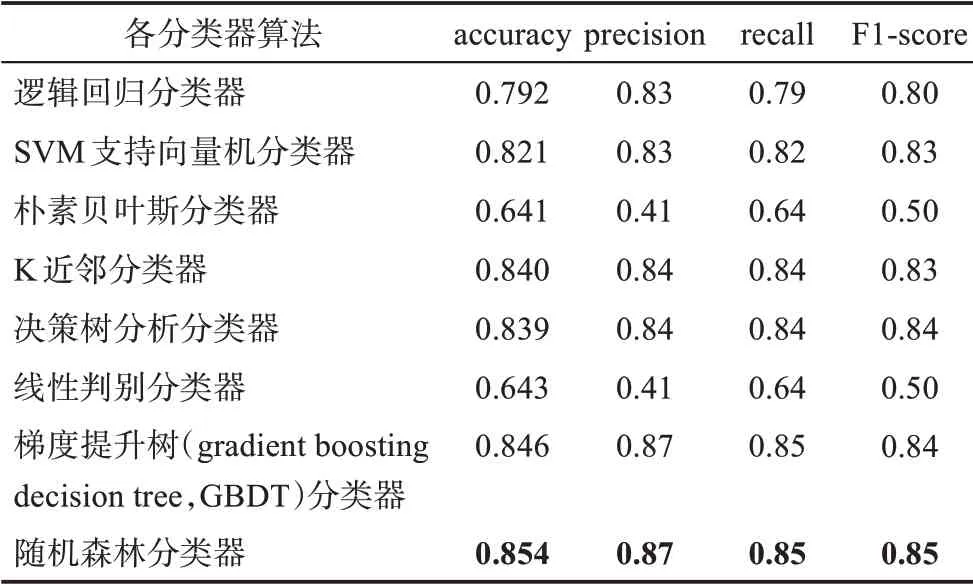
表2 各分类器评价结果
随机森林属于机器学习中的集成学习方法,通过集成学习的思想把多棵决策树集成一种算法,并且其输出的类别是由个别决策树输出的类别的众数而定。由表2 可知,随机森林算法在各分类器算法中表现最优,识别准确率高达85%,这也证明了随机森林算法的优越性。因此,本文采用随机森林算法进行基因编辑领域中的潜在知识流动发现。
5.2.2 潜在知识流动权重预测模型训练
针对知识流动权重的预测,本研究利用T1 时期的知识流动网络,计算各组有向主题对的链路预测指标;并且以T2 时期所对应的链接边的权重作为目标变量y值。同样地,采取“留出法”,随机抽取80%样本数据作为训练集,其余20%为测试集数据。如表3 所示,针对各个回归模型的性能评估,分别选取了均方误差(MSE)、平均绝对误差(MAE) 以及决定系数(R2) 评价各模型的好坏。通过对各个模型评价指标对比分析,本研究发现基于随机森林算法构建的回归模型效果最佳,MSE 与MAE 指标均为最小值,且R2值最大值,为0.784。因此,本文采用基于随机森林算法的回归模型,对基因编辑领域内的知识流动权重进行预测。
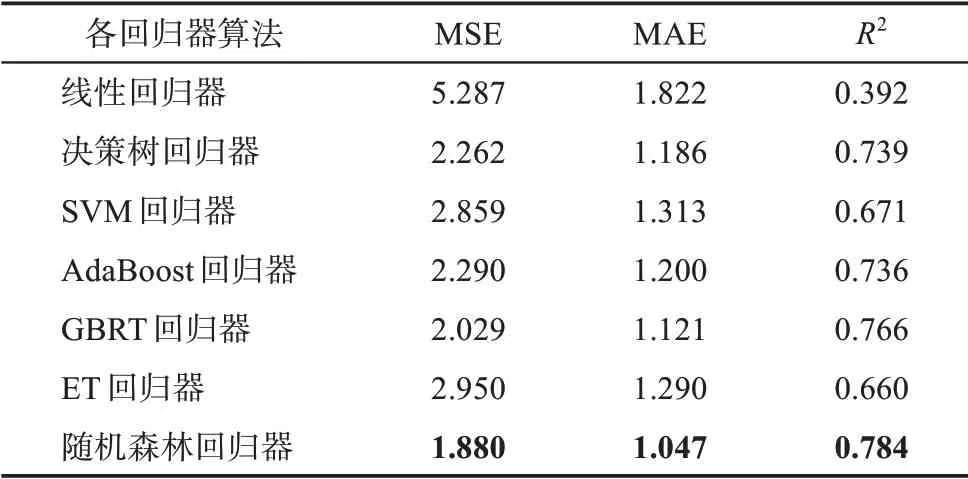
表3 各回归器评价结果
5.3 潜在知识流动发现
本研究基于上述训练好的模型,以T2 时期中未存在知识流动的主题对链路预测指标为输入特征,进行结果预测分析,采用Scikit-learn[27]进行分类器学习训练,参数feature_importances_表征了各特征值的重要程度,作为各特征值的参考权重。本研究将各特征值与对应权重加权求和得到综合指标,即表征知识流动出现可能性。按照综合指标值的大小倒序排序,最有可能在未来发生链接的Top 10 主题对,如表4 所示。

表4 潜在知识流动发现
从表4 可知,“免疫细胞治疗→原核生物基因编辑”这项主题对之间的知识流动在未来最可能发生;“原核生物基因编辑→癌细胞基因编辑”“真核生物基因编辑→癌细胞基因编辑”“基因编辑技术的开发→癌细胞基因编辑”和“原核生物基因编辑→人类蛋白质组计划”等主题对之间在未来同样存在知识流动的可能性。目前,有学者表示,CAR T 细胞免疫疗法与基因编辑技术的组合仍是个前景绝佳的研究领域[28],两者的结合可看作精准医疗和干细胞治疗行业的完美结合[29]。免疫细胞治疗向基因编辑技术的引入,推动基因编辑技术真正从研发走向临床。同时,随着基因编辑技术研究热度的迅速提升与拓展,基因编辑技术在疾病基因治疗中探索发展,为肿瘤等多种重大疾病的治疗提供了新的治疗路径。
5.4 潜在知识流动权重预测
针对潜在知识流动权重的预测,本文关注于目前网络中已存在链接权重的预测。基于上述训练好的权重预测模型,以T2 时期中存在知识流动主题对的链路预测指标为输入特征,进行结果预测分析,并计算预测权重与T2 时期实际权重的差值,即权重差值=预测权重-T2 时期权重。根据权重差值进行倒序排列,取权重差值最大的Top 10 主题对为未来具有发展潜力的主题组合(表5),取权重差值最小的Top 10 主题对作为未来知识流动将会消失的主题组合(表6)。
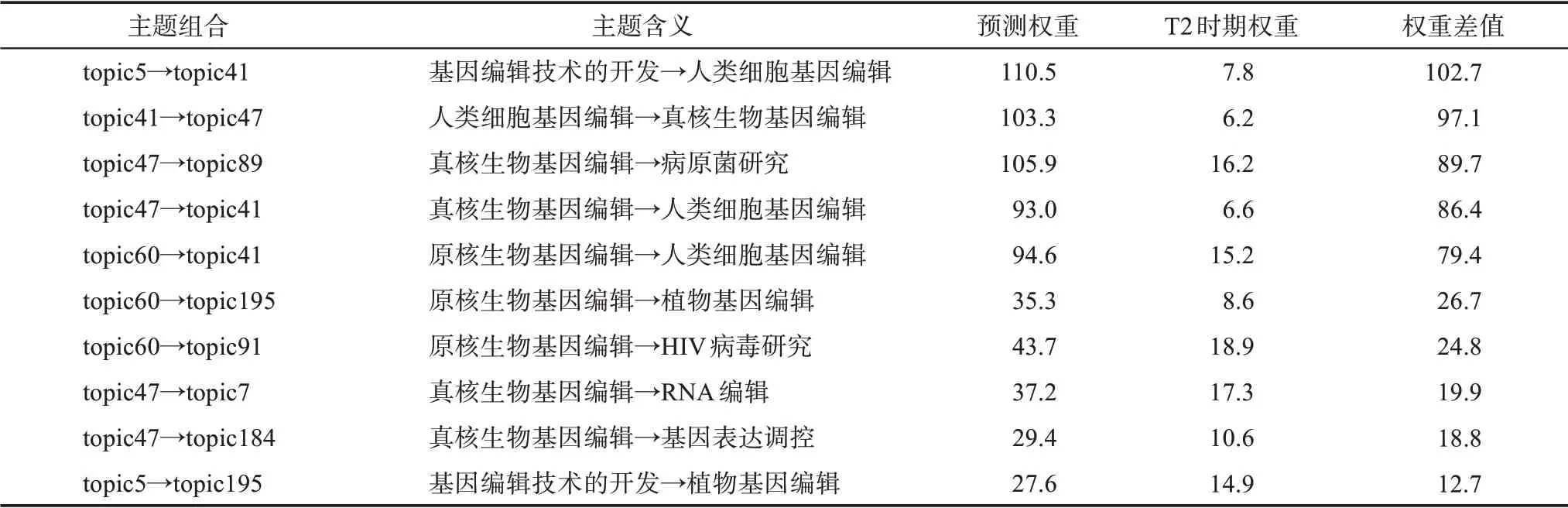
表5 未来热点研究主题(未来研究前沿)

表6 未来消失的知识流动
由表5 可知,第一,“基因编辑技术的开发→人类细胞基因编辑”“真核生物基因编辑→人类细胞基因编辑”与“原核生物基因编辑→人类细胞基因编辑”三组涉及“人类细胞基因编辑”的主题对融合事件将在未来成为领域内的研究热点,传统的基因编辑技术将有效助力人类细胞基因编辑的发展,尤其是关于基因编辑技术在人类疾病方面中的探索发展[30];第二,“真核生物基因编辑→病原菌研究”与“原核生物基因编辑→HIV 病毒研究”主要涉及基因编辑技术在病原菌、病毒等生命科学基础研究领域的拓展应用;第三,“原核生物基因编辑→植物基因编辑”“真核生物基因编辑→RNA 编辑”主要针对基因编辑技术本身的发展,持续衍生并产品化开发了更为精准、高效、低成本的基因编辑技术。总体而言,未来研究热点主要集中于基因编辑理论研究本身到其他方面的拓展。
在表6 中,“人类细胞基因编辑↔RNA 和小RNA”“RNA 编辑↔植物基因编辑”两组主题组合之间在T2 时期具有较强的知识流动链接,视为未来最可能消失的主题节点对。“基因编辑应用医学治疗→干细胞相关研究”“病毒相关研究→基因编辑应用医学治疗”等主题对之间的知识流动在未来同样可能会消失。
由表5 和表6 可知,未来研究者针对RNA 基因编辑与植物基因编辑的关注度将会较少,而更关注于基因编辑在人类疾病治疗与防护方面的应用。
6 结 论
直引-共被引-耦合三维引文关联网络所映射出的知识流动网络,全面揭示目前领域内的知识交流与知识转移的现状,但科研工作者与科研管理机构人员对未来可能出现的知识流动更感兴趣。当一个主题内的知识转移到其他主题时,会内化为新的知识,加以创新模式的转换,形成领域内的研究热点或研究前沿。因此,本文提出了一种三维引文关联融合视角下未来潜在知识流动预测的框架,主要包括三个步骤:第一,根据文献之间的引用关系,基于标准加权直接引用(NWDC)理论并通过LDA 主题模型提取主题,构建三维引文关联融合视角下的知识流动网络;第二,计算网络中主题对的链路预测指标作为特征值,分别使用随机森林分类器与回归器对特征值进行训练,获得未来链接预测模型与未来边权预测模型;第三,基于基因编辑领域的实证研究,预测该领域内未来可能出现的研究热点或者研究前沿问题,以及未来具有发展潜力的研究主题。
采用预测潜在知识流动的思路,本研究发现了一些未来可能出现的知识流动。通过专家评审的定性分析方法,确认预测结果中潜在知识流动的发现与实际领域情况相吻合[31],可视为基因编辑领域内的研究前沿与热点问题,主要集中在三个方面:①基因编辑技术在免疫细胞、病毒细胞等生命科学基础研究领域的拓展应用;②基因编辑技术本身的发展,为持续衍生并开发出更精准、高效的基因编辑技术;③基因编辑技术在疾病基因治疗中探索发展,为肿瘤等多种重大疾病提供新的治疗途径。因此,基因编辑领域内的研究方向展现出了“宏观基础研究→细粒度基础研究→临床治疗”的发展态势,未来一系列知识流动的产生将会真正推动CRISPR 技术从研发迈向临床。
基因编辑领域内的实证研究,进一步印证了本文中三维引文关联融合视角下探究潜在知识流动的可行性与有效性。知识流动预测中的随机森林算法,无论是分类器还是回归器,两种预测层面都表现出了最优的评价结果。分类器用于预测目前尚未存在、在未来极有可能出现的知识流动;而回归器主要用于预测目前链接权重较低的,尚未引起广泛关注、但在未来具有较高链接权重的知识流动。这两种预测层面综合互补,从不同角度探究学术领域内的潜在知识流动与未来研究的热点。同时,本研究中也存在遗憾之处,例如,在为LDA 主题模型中所提取的各主题确认主题名称时,借鉴了专家的评审意见,这种定性分析方法,无法避免主观判断所造成的可操纵性与不确定性。在未来研究中,将努力探索是否存在定量分析方法确认各主题名称,以期采用定性与定量分析相结合的方法,更精准有效地实现主题名称的定位。
