基于社会化问答社区涌现模式分析的领域热点识别研究
2021-03-15于晶
于 晶
(华东师范大学政治学系,上海 200241)
1 引 言
学科的前沿热点代表着科技领域的关键核心问题和发展趋势。科技发达国家对前沿热点的研究都非常重视,我国政府也制定了鼓励能够引领未来发展的高技术领域的政策,并提出了建设世界一流大学和一流学科的教育发展战略。因此,领域热点的识别对于大到国家的科技发展战略、突破技术封锁、提升综合竞争力,小到科研工作者研究方向和研究问题的选择,均具有重要的研究意义和应用价值。
领域热点识别和趋势分析是科技情报和文献计量学领域的重要问题之一,得到了学者广泛的关注。现有研究主要基于正式发表的学术文献数据,利用文献计量的方法进行研究。黄晓斌等[1]将这类方法划分为三种:基于引用关系的方法、基于文本内容的方法和基于复合关系的方法。其中,基于引用关系的方法利用了文献引用频次或引文网络展开研究[2-3];基于文本内容的方法则使用了关键词、摘要文本或者文献全文,主要方法包括词频分析和文本主题分析等方法[4-6];更多领域热点识别研究采用了将上述两种方法相结合的复合关系方法[7-10]。除此之外,还有一些研究关注领域热点分析相关的其他问题:文献[3,10]侧重于利用可视化的方法分析领域的趋势;文献[11-12]则更关注领域发展趋势的预测,分别利用决策树和回归分析的方法来预测领域热点的发展趋势。
基于文献计量的方法能够有效识别研究领域的前沿研究和热点,但是大多数研究仅引用了正式发表的文献数据。在科学研究过程之中,研究人员之间会通过多种途径进行交流。当前,各种基于社交媒介的应用层出不穷,这也成为研究人员进行交流的重要方式。在所有的交流方式中,社会化问答社区由于其特殊的机制成为学术与技术人员集中交流的平台。与基于文献计量的方法相比,利用交流方式中产生的大规模交互与交流数据来识别领域研究的热点和发展趋势,更容易检测到研究人员的动向和趋势,因而具有潜在的优势互补作用。现有研究中,尽管已经有一些相关的探索,如文献[13],但就整体而言还处于尝试阶段,缺乏更加深入的识别方法和有效性验证方法的研究。
为了利用社会化问答社区中丰富的用户交流数据,本文提出一种基于涌现模式挖掘(emerging pattern mining)的研究领域热点识别框架。该框架利用领域关键词的组合(称为模式)来表示研究的子域或子问题,利用涌现模式挖掘方法来分析热点模式,从而识别出领域热点并分析其发展趋势。本文的主要贡献包括三个方面。第一,提出利用在线问答社区中的用户交互数据来识别领域中研究热点,并整合现有的Web 文本分析、涌现模式挖掘等方法给出一种具有较高可行性的解决方案;第二,针对领域热点识别问题的独特之处,提出利用模式聚类的方法将大量无意义低频模式排除,较好地解决涌现模式挖掘中计算量大且结果中可能包含大量无意义模式的问题;第三,基于知乎社区(zhihu.com)的真实数据集进行实验,将实验结果与前沿研究相对比,从而验证了所提出的领域热点识别框架的有效性。
2 相关研究
2.1 领域热点识别
传统上,研究领域的热点识别方法主要基于文献计量学方法。结合文献[1]的研究,本文将基于文献计量的方法分为三种类型:基于引文分析的方法、基于文本的分析方法和基于语义的方法。
基于引文分析的方法可分为:基于同被引分析的方法和基于引文网络分析的方法。基于同被引分析的方法主要利用文献之间的同被引关系及被引频次构建评价指标,并结合聚类的方法来识别领域热点或前沿研究问题。例如,Schiebel[3]利用来自地理学的二维或三维可视化方法来处理共被引网络数据,通过可视化的方法来识别领域热点。基于引文网络分析的方法根据文献之间的引用关系构建网络结构,并进一步结合网络科学的分析方法来识别领域研究热点。例如,Shibata 等[2]利用复杂网络方法的多种网络衡量指标,结合网络节点聚类方法,对两个领域的热点识别进行比较研究,认为基于网络拓扑的分析方法能够得到更好的效果。
由于领域热点识别不可避免地需要提取出表示领域的关键词或主题词,因此纯粹使用基于引文分析方法的研究较少,更多的研究采用了词频分析或关键词共现分析等基于文本分析的方法或者两种方法的结合。Liao 等[4]利用2008—2017 年运筹学和管理科学领域发表的ESI(Essential Science Indicators)高被引论文数据集,通过分析被引量最大的论文的关键词来识别领域热点。Xie[9]分别从国家、机构、作者、期刊、文献的角度,利用引文和共词分析方法来识别重要的机构、作者和文献,进一步分析抗癌药物领域的研究热点。杨颖等[8]首先构造关键词共现网络并进行聚类,然后通过对高频主题词汇以及各类别中具有代表性文献的解读来识别领域研究热点。
基于文本的分析方法仅考虑关键词的词频,而基于语义的方法则使用了基于机器学习的方法来挖掘文本内容中的语义信息。例如,高盈盈等[12]使用了LDA(latent Dirichlet allocation)主题模型来识别领域关键词。近年来,深度学习在自然语言处理领域迅速发展,其研究结果也被用于领域识别的研究之中。例如,阮光册等[14]利用doc2vec[15]方法生成文档向量进行相似度计算,再通过聚类算法和主题词提取算法识别领域热点;Asatani 等[16]利用网络表示学习方法学习节点的表征信息,以及其随着网络变化的趋势,提出一个称为IPY(intrinsic publica‐tion year)的指标,该指标与文献被引频次之间存在着相关性,因此基于该指标来检测研究热点及发展趋势[17]。
上述现有研究都仅利用了正式发表的学术文献数据。本文与其最大的区别在于使用了社会化问答社区中科技工作者的交互数据来识别领域热点,并对其发展趋势进行量化分析。
2.2 社会化问答社区
根据关注的研究对象,可将社会化问答社区的相关研究分为平台、用户和信息三种类型。关于平台方面的研究,主要关注社会化问答社区的管理与发展策略。例如,Srba 等[18]以Stack Overflow 为例,探究了社区的问题失败率(被删除或未回答的问题在所有新问题中所占的比例)上升的原因,并证实这一现象与越来越多的低质量内容和社区中不受欢迎的用户群体密切相关。关于用户的研究则主要关注用户的行为。例如,张宝生等[19]从知识共享的角度出发,运用经典扎根理论研究用户知识贡献行为意向的影响因素;张颖等[20]探索了付费问答社区中影响提问者问题选择行为的因素,发现回答者的专业性、知名度以及信息服务质量对提问者选择行为有正向影响。关于信息方面的研究主要包括问答质量评价[21]和用户个性化信息推荐[22],或者对社区中的新问题进行专家推荐[23]等方面的研究。
现有在线社区的研究中也有一些关于热点话题检测的工作。利用已有信息预测社区的热点话题、热门趋势,这不仅利于平台自身的管理决策,而且能够为企业带来巨大的经济价值。Zhang 等[24]提出了一种热点话题检测方法,用于分析雅虎问答平台的数据。该方法首先提取关键词,然后对问答内容进行聚类,通过分析问题类型的频次来对热点趋势进行描述。Lu 等[25]也利用了聚类的方法来检测在线社区中与健康相关的热点话题。这些研究与本文研究有相似之处,均依赖于文本信息的提取;区别在于本文引入了涌现模式挖掘的方法,能够从领域模式的角度识别领域热点并对热点趋势进行量化的分析。
2.3 涌现模式挖掘
涌现模式挖掘是一种数据挖掘任务,其目标是找到不同数据集中分布存在显著差异的模式[26]。所挖掘的模式能够通过可理解的形式来描述数据集之间关于模式相关属性的新趋势。涌现模式挖掘的方法主要有基于边界的方法和基于树的方法。如Dong 等[27]利用边界的概念以无损的方式描述大量的EP 使得边界仅由集合中的最小和最大EPS 组成,为挖掘结果提供了良好的结构,并减少挖掘结果集的大小。基于树的算法以树状结构表示训练数据,与基于边界的方法相比,基于树的算法效率较高。基于决策树的方法允许直接处理数值属性而不需要先前的离散化阶段,如García-Borroto 等[28]从一组不同的决策树中提取规律并进行归纳。该方法可以获得更少的判别规则,从而获得更高的分类精度。
涌现模式还可以进一步分为跳跃涌现模式(jumping emerging patterns,JEP)、最小涌现模式(minimal emerging patterns,MinEP)、最大涌现模式(maximal emerging patterns, MaxEP) 等 多 种 类型[29]。MinEP 是最普遍的涌现模式,每个涌现模式的子模式不再是涌现模式;MaxEP 则相反,每个涌现模式的父模式不再是涌现模式。Kane 等[30]提出了最小跳跃涌现模式挖掘方法,能够计算基本JEP 和top-kMinEP。Wang 等[31]提出了一种基于“重叠”或“交叉”的机制来利用MaxEP 特性,这种方法结合了贝叶斯方法和基于EP 的分类器的优点,具有更好的整体分类精度。
涌现模式挖掘方法能够衡量不同数据集中模式的差异,并识别出其中差异性比较显著的模式。但是,其计算量都比较大,而且结果中容易现较多无意义的模式。本文从候选模式的构建入手,首先利用关键词的共现性进行聚类,然后在聚类结果的基础之上构建候选模式集合。不但使计算量大大减小,而且能够有效减少结果中的无意义模式。
3 方 法
3.1 领域热点识别框架
本文提出利用社会化问答社区中的用户交互数据,在不依赖文献计量分析的情况下来识别领域研究热点。解决该问题的思路主要依赖涌现模式分析方法对用户的问答文本进行挖掘,整体框架主要包含四个关键步骤:首先,需要从问答内容中提取出与领域热点相关的关键词;其次,根据提取出的关键词集合构建潜在模式集合;再次,根据关键词出现频率及共现性识别涌现模式,从而识别领域的研究热点及趋势;最后,需要对识别的效果进行检验或验证。
本文提出的领域热点识别框架如图1 所示,下文中将对框架的各组成部分进行详细描述。
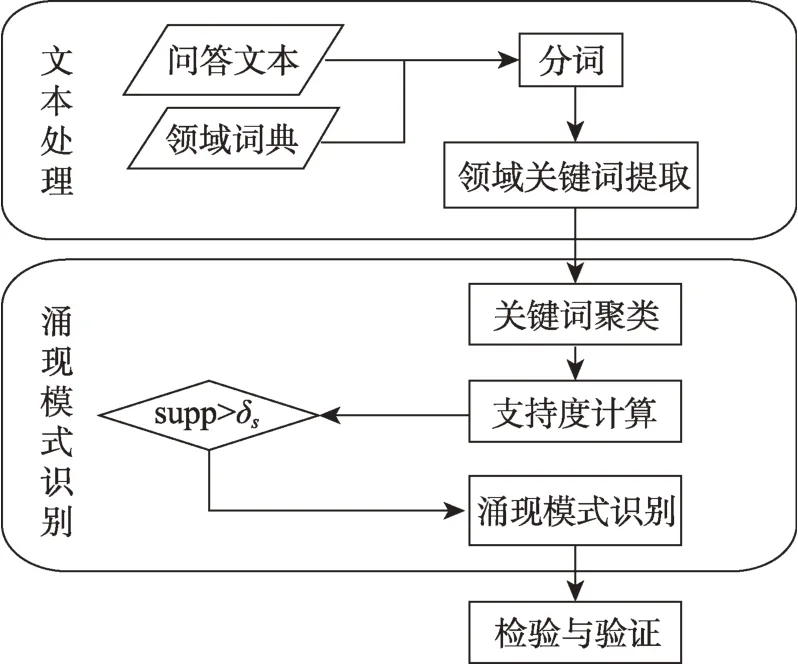
图1 领域热点识别框架
3.2 问答文本处理
问答文本处理的核问题,是将文本内容处理为结构化的形式,并提取文本内容中的领域关键词。具体来说,需要将每条问答文本表示为领域关键词的集合。其中,为第i条问答中的第j个领域关键词;K为领域关键词的集合。
3.2.1 分 词
本研究中使用的分词工具为pkuseg[32]。pkuseg是一个开源的多领域中文分词工具包,支持细分领域分词,从而有效提升了分词的准确度。此外,pkuseg 还可以很方便地使用自定义词汇表。分词工具所用的分词模型通常基于大规模文本数据集训练得到,一般情况下能够得到较好的分词效果。但是在各个科研领域中都存在大量的学术术语,这些术语可能由多个词所组成,分词工具难以对其进行准确的切分。例如,术语“机器学习”,在领域热点识别研究中需要将其识别为一个词汇,但实际上绝大多数分词工具将其切分为“机器”和“学习”两个词汇,失去了该术语所表达的含义。本研究基于领域的常用术语构造领域词典,将领域词典作为自定义词汇表,从而使得分词工具能够很好地识别这些术语。
此外,社会化问答社区中的问答内容中广泛存在着多语言混合使用的现象。例如,在知乎中,问答内容可能包含英文语句或段落,或者更普遍的情况是回答者直接在内容中使用了英文的术语或缩写。为了将这些术语包含在内,本文在构建领域词典的同时也给出了每个术语对应的常见英文翻译。在数据分析的过程中,将每个术语以及其对应的一个或多个常见英文翻译处理为同一个关键词。
3.2.2 领域关键词提取
经过分词的问答内容,需要进一步提取其中的领域关键词。本文使用基于TF-IDF(term frequencyinverse document frequency)与支持度相结合的方法来提取领域关键词。
TF-IDF 是一种衡量词汇在文档集合中重要程度的方法。一般情况下,一个词在一个文档中出现的次数越多,该词的重要性就越高。同时,如果文档集中出现该词的文档数量越多,就越说明该词不包含特殊的信息,即重要性越低。
对于文档集D,出现在文档中的所有词汇构成一个词汇表L。基于L可以将任意文档表示为长度为|L|的向量,该向量的第j个元素表示词汇表L中的第j个词在该文档中出现的次数。将给定词汇j在文档i中出现的次数与文档总词汇量的比值称为词频(term frequency,TF),记为
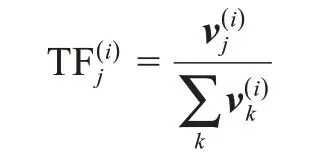
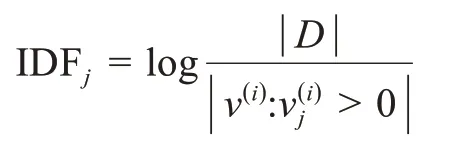
其中,IDFj表示词汇j在文档集中的逆文档频率。
于是,文档i中的词汇j的TF-IDF 值为

社会化问答社区中,领域关键词的提取可以通过设定一个阈值δtf-idf,将每个文档中的词作为该文档中的领域关键词。实验表明,得到的领域关键词集中包含了很多的相关性较低的词汇。为了剔除这些词汇,数据分析中需要进一步剔除在文档集中支持度较低的词汇(即suppj>δw-supp),词汇j的支持度定义为
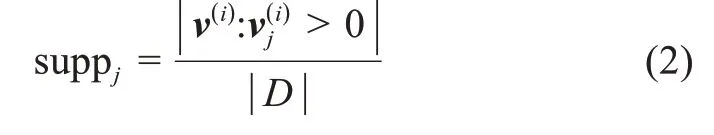
3.3 涌现模式识别
社会化问答社区的文本内容中包含了大量的领域关键词,本研究的目的是根据这些领域关键词的变化趋势来识别领域识的热点。研究中将每个领域关键词看作一个项(item),多个领域关键词构成一个项集(item set)。一个项集可以被看作相应研究领域中的一种模式,通过分析不同时间段内模式的变化情况,可以识别其中的涌现模式[26],从而识别出该领域中的研究热点。
3.3.1 涌现模式的识别
令F={f1,f2,…,fk}为领域关键词的集合(或称为项集)。其子集X⊆F称为k项集,k=|X|。给定一组按时间顺序排列的数据集D1,D2,…,一个项集X在文档集Dt上的支度为
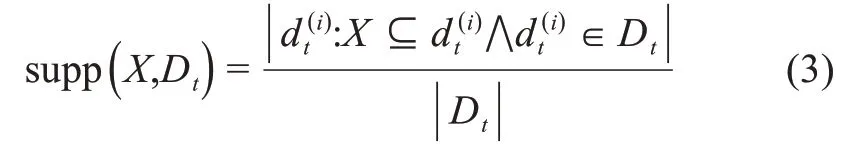
表示模式X在该数据集中出现的频率。X在Dt到Dt+1中支持度的变化情况用增长率来衡量:
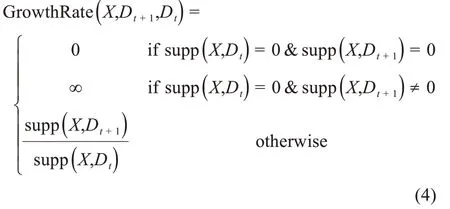
如果模式X满足则称X为一个上升涌现模式(或上升模式);如果,则称X为一个下降涌现模式(或下降模式),其中δe>1 为阈值。当GrowthRage(X,Dt+1,Dt)= ∞时,称X为一个跳跃涌现模式(jumping emerging pattern),或跳跃模式[29]。上升模式或跳跃模式表示被关注越来越多的模式;下降模式则表示被关注越来越少的模式。社会化问答社区中领域热点的识别,就是要找出问答内容中的上升模式或跳跃模式。
涌现模式挖掘算法的难点,在于要从数量巨大的候选模式中,识别出满足条件的涌现模式。假设要考虑的项(item)的数量为n,则理论上候选模式的数量为。以社会化问答社区领域热点识别为例,若领域关键词为20,则候选模式的数量高达1048555;而实际上,领域关键词的数量远不止20,因此通过直接计算的方法识别涌现模式是不可行的。
总之,现有的涌现模式挖掘算法都存在着计算复杂度高的问题。更重要的是,由于大规模问答数据集中存在的个性化表达、数据质量参差不齐等因素,使得这类算法得到的涌现模式数量较大,而且其中相当一部分是没有意义或无法解释的。因此,本文提出一种基于聚类的涌现模式识别方法:首先,利用关键词在问答文档中的共现性对关键词进行聚类;其次,在聚类结果的基础之上,构建候选模式。候选模式仅在每个类别内部构建。这样,一方面排除了大量偶然出现的、无意义的候选模式;另一方面,使得候选模式的数量大大下降,甚至使得直接计算的方式就能够有效的识别涌现模式。
3.3.2 模式聚类
领域热点识别与普通的涌现模式挖掘问题存在着显著的差异。首先,模式用于描述一个研究领域中较小的子领域或研究问题,在细粒度的层面上不需要很高的精确度。例如,模式{机器学习, 深度学习, 人工智能}与模式{深度学习, 人工智能}在细粒度层面上是不同的模式,但是两者所描述的子领域并没有太大的差异。其次,一个研究领域中的关键词数量较为庞大,但是子领域或研究问题的数量要少得多。最后,属于同一个子领域的关键词往往具有较高的语义相似度,而不同子领域中,使用的关键词往往有着较大的差异。基于领域热点识别与普通的涌现模式挖掘问题的区别,就可以得到一个合理的推测,即如果一个模式中出现了语义距离相距甚远的关键词,那么就可以认为该模式不是一个有意义的模式,因而也不会是涌现模式。本文利用模式聚类来实现这种思路,从而大大降低涌现模式识别的计算量。
模式聚类的目的是根据关键词在数集D=D1∪D2…中的共现性进行聚类,将包含了不属于同一类别的关键词的模式排除在候选模式之外,从而使候选模式的数量显著降低。
关键词集合F={f1,f2,…,fk}的共现矩阵表示为

其 中, 第i行 第j列 元 素eij= |d:fi∈d∧fj∈d∧d∈D|表示关键词fi和fk共同出现在数据集D中同一文档的次数。
直接将共现矩阵作为属性矩阵对关键词进行聚类是不恰当的,因为利用关键词与其他关键词的共现向量不能准确的计算一对关键词之间的距离[33]。由于两个关键词共现的次数越多两者之间的距离越近,故可以将共现矩阵式(5)转化为相似性矩阵:

当eij= 0 时,sij= 0;当eij≠0 时,sij= 1/eij。
相似性矩阵S是一个对称矩阵,因此可以表示以关键词为节点、以成对关键词之间的相似性为权值所形成的无向加权网络。基于该网络,容易利用最短路径算法计算两个节点之间的距离,从而得到任意两个关键词之间的距离所构成的矩阵:

其中,dij为关键词fi与fj之间的距离。
基于距离矩阵(7)可以利用层次聚类算法,以及类间距离的阈值δd将关键词集合F聚类为
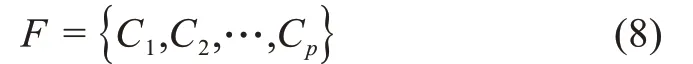
其中,Ci={fi1,fi2,…}为第i个类别;fij表示第i个类别中的第j个关键词。
3.3.3 候选模式生成
由于属于不同类别的关键词不太可能会出现在同一涌现模式之中,因此候选模式由属于同一类别的关键词组成:
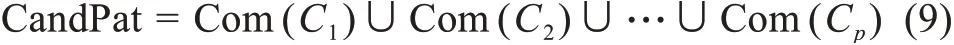
其中,Com(Ci)为第i个类别中任意一个或多个元素的组合(即候选模式)所构成的集合。
基于模式聚类所形成的候选模式数量大大下降,假设关键词的数量为20,聚类得到4 个类别,则候选模式的数量由1048555 降为最优情况下的104个。因此,可以认为模式聚类是一种高效的剪枝方法。需要注意的是,这种方法的有效性需要满足一定的条件,在其他涌现模式挖掘问题中的有效性要根据具体问题进行分析。
3.4 有效性验证
本文利用卡方检验和实际数据对比,对领域热点识别框架的有效性进行验证。卡方检验用于对识别出的涌现模式,在不同时间段数据集Dt中,差异的显著性进行检验。在实际数据对比中,将相关领域顶级国际会议上所发表的论文的主题与涌现模式识别结果进行对比,以验证其有效性。
4 实 验
4.1 数据收集与处理
本研究利用知乎社区中的问答内容来验证上述领域热点识别框架的有效性。为了便于对比分析,研究中选择了知乎社区中的“机器学习”话题(https://www.zhihu.com/topic/19559450/hot),抓取了该话题下的“讨论”和“精华”版块的全部问答内容。知乎社区是按照“话题—子话题”所构成的树状结构来组织问答内容的。这些话题并非一成不变的,会随着当前研究热点的变化而做出一定的改变,与领域内容相关的工具、软件、竞赛等话题也会不断更新。其中,部分子话题可能会在多个父话题中重复出现。尽管子话题的划分可能会变化,但隶属于该话题的问答内容有足够的稳定性,能够满足本文所提出的方法的需要。
在本研究进行期间,“机器学习”的子话题结构树中共有327 个子话题。经过抓取后,去除重复问答内容后,共得到2011 年2 月—2019 年11 月的4507 个提问及20669 个回答。由于提问内容通常都非常短(平均长度为25 个字符),下文的分析中将其排除在外,仅使用了回答的文本数据。这些数据在时间上的分布如图2a 所示。本研究所获取的数据截至2019 年11 月25 日,因此将2019 年数据用虚线表示。从图2 中可知,知乎社区发展的早期(知乎于2010 年12 月上线)问答数量较少;自2014 年起“机器学习”话题中问答的数量快速增长。因此,由于2011—2014 年数量过少,基于涌现模式的热点识别主要针对2015—2019 年数据。
在分析之前,还需要对数据加以清理,以避免冗余或无用数据对结果造成的影响。主要的清理内容包括文本中所包含的HTML 文本以及无意义的符号,如连续重复多次的“-”“_”“.”“=”“+”等符号。此外,过短的回答内容中包含的信息量不足,因而也需要将其去除,下文的分析中除去了长度小于50 的回答。清理后的数据量分布如图2b 所示。

图2 数据量分布
4.2 实验结果与分析
4.2.1 领域关键词提取结果
基于公式(1)和公式(2)所示的方法,处理知乎社区“机器学习”话题中的回答内容得到542 个领域关键词(δtf-idf=0.25,δw-supp=10),经过筛选后最终得到378 个领域关键词。知乎问答内容属于用户生成内容(user generated content,UGC)的一种,而用户生成内容的特点就是语言使用灵活、不规则用法较多。特别地,在“机器学习”话题中大量出现中英文术语混合使用的情况。为了应对这种情况,在分析中将重要的英文领域关键词考虑在内。例如,“卷积神经网络”的英文术语可以为“Convolu‐tional Neural Network”“Convolutional Networks”“CNN”等。这些不同形式的术语(包括中文术语)具有相同的含义。为了避免数据稀疏性,需要将这些术语进行分组处理。例如,将“卷积神经网络”“卷积网络”“Convolutional Neural Network”“Con‐volutional Networks”“CNN”分为一个领域关键词组。每个分组分配一个ID,同一分组中的关键词具有相同的含义。
知乎问答数据经过处理后,本研究得到了230个领域关键词组。接下来,将回答内容中的已识别领域关键词替换为其所属的关键词组的ID。基于领域关键词组及替换后的数据集容易统计得到公式(5)的共现矩阵,进一步处理得到公式(6)所示的230 ×230 的相似矩阵。
相似矩阵表示以领域关键词组为节点,以相应节点间的相似性为边的网络。其中,180 个节点是相互连通的构成了整个网络的最大连通子图,如图3 所示。其余50 个为孤立节点,在后续分析中被作为独立的候选模式。图3 中,节点的大小与节点的度正相关,即对应的关键词组共现的关键词组数量;边的宽度与对应关键词组对的共现频次正相关。该图同时也描述了关键词组对之间的相似性,共现频次大关键词组对相似度越高,见公式(6)。基于关键词组对之间的相似性,在最大连通子图上,利用最短路径算法可得到任意两个领域关键词组之间的距离,构成了如公式(7)所示的距离矩阵。该矩阵进一步被用于对领域关键词组进行聚类。

图3 关键词组共现网络
4.2.2 候选模式识别结果
研究中使用层次聚类算法基于距离矩阵对关键词组进行聚类,实际上,相当于依据关键词对的相似性对图3 所示的关键词组共现网络的节点进行聚类。类间距的计算采用了ward 方法,即两个聚类之间的距离定义为合并两者造成的总离差平方和的减小数量[34]。影响聚类结果最关键的参数为下层聚类合并为上层聚类的类间距阈值δdist。本研究通过类间距阈值δdist与候选模式数量的关系来确定δdist的取值。如图4a 所示,当δdist>0.015 时候选模式的数量随着δdist的增加急剧上升。将类间距阈值确定为δdist= 0.015,得到的候选模式数量为8411。
候选模式集合中的绝大多数模式是无意义的模式,这些模式通常在问答内容中极少出现。为了将这些无意义的模式排除在外以降低涌现模式识别的计算量,本研究进一步将问答数据中出现频率较低的模式排除在外,仅保留频繁模式以供后续分析。模式频率就是该模式在数据集上的支持度,见公式(3)。将模式支持度的阈值表示为δp-supp,频繁模式是那些支持度高于该域值的模式。如图4b 所示,随着模式支持度域值δfreq的增加,频繁模式数量迅速减少(除了2011—2013 年由于数据量太少而变化较小)。而且,随着δfreq的增加,频繁模式数量减少的速度也快速降低。当δfreq较小时,各年度问答数据中频繁模式数量差异较大;当δfreq较大时,频繁模式数量差异较小。这说明频繁模式对阈值δfreq的大小并不敏感,而非频繁模式则对δfreq比较敏感。因此,可以合理的推测,那些有意义的模式会被包含在频繁模式之中,而无意义的模式由于出现频率较低而被剔除。为了保留较多的频繁模式用于涌现模式识别,本研究将频率阈值设定为δfreq= 0.01。
4.2.3 领域热点识别结果
基于频繁模式的分析结果,利用公式(3)和公式(4)所示的涌现模式识别方法进行领域热点识别。公式(4)中的增长率阈值定义为δe= 2,即一个频繁模式在数据Db中支持度大于在数据Da中支持度的2倍或小于1/2 时,则认为该模式为涌现模式。由于涌现模式识别结果基于频繁模式进行分析,而频繁模式数量已经大大减少,所以涌现模式分析结果对δe不敏感。
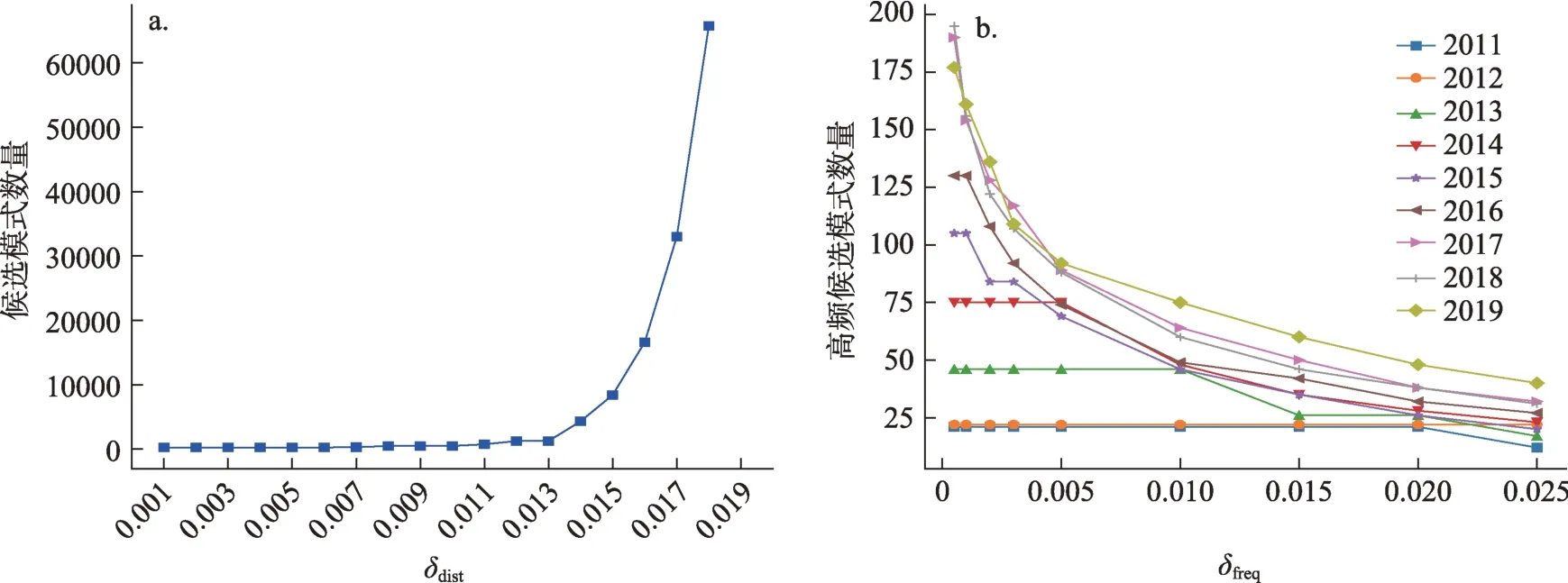
图4 类间距阈值对候选模式数量的影响
表1 所示的结果为2019 年问答数据与2015 年问答数据的分析结果,共包含表示领域热点的模式18个。其中,上升模式11 个,跳跃模式5 个,下降模式2 个。从结果中可看出,机器学习领域的热点几乎都集中在深度学习相关的问题或方法之上。而以支持向量集为代表的传统机器学习方法的关注度下降明显,是一个显著的下降模式。卡方检验的结果也验证了在两个数据集中这些领域对应的模式具有显著的差异。
仅基于2015 年和2019 年数据无法判断这些领域热点发展过程中的趋势变化情况。因此,本文利用2015—2019 年的全部数据,对这些领域热点的趋势进行了分析,结果如表2 所示。其中,增长率大于1 表明上升趋势,小于1 则表明下降趋势(见第3.3 节)。大部分的领域热点的热度并非一直持续上涨,而是有所变化的。但是总体来看,所有的上升模式和跳跃模式都有着明显的上升趋势,而下降模式则有着明显的下降趋势。卡方检验结果也表明这些领域热点模式的变化是显著的。此外,领域热点的趋势也能够表明方法的有效性。以“Bert”和“Transformer”为 例,“Transformer”是2017 年 由Google 提出的一种用于机器翻译的模型;“Bert”是2018 年提出的一种基于“Transformer”的词向量学习模型。这些都是基于深度学习的自然语言处理领域近几年的突破性进展。而表2 的趋势分析中可以看出其分别在2017/2018 和2018/2019 数据中开始具有很大的增长率,这表明知乎社区的“机器学习”话题能够紧跟领域发展的趋势,而且这些趋势能够被基于涌现模式的方法所捕获。
为了进一步验证热点模式识别结果的有效性,本文还分析了相关领域重要会议上所发表的论文中这些热点领域的变化情况。鉴于所识别出的热点模式几乎都来自深度学习相关领域(与实际情况一致),因此,本研究选择该领域的顶级会议ICLR(International Conference on Learning Representations)作为分析对象。所用数据来自OpenReview(https://openreview.net/)。2017—2018 年ICLR 会议接收的论文中,频次最高的关键词如表3 所示。这些关键词与表1 和表2 所示的基于知乎社区的领域热点识别结果高度重合,进一步说明了本文提出的领域热点识别框架的有效性。

表1 2015/2019年领域热点识别结果
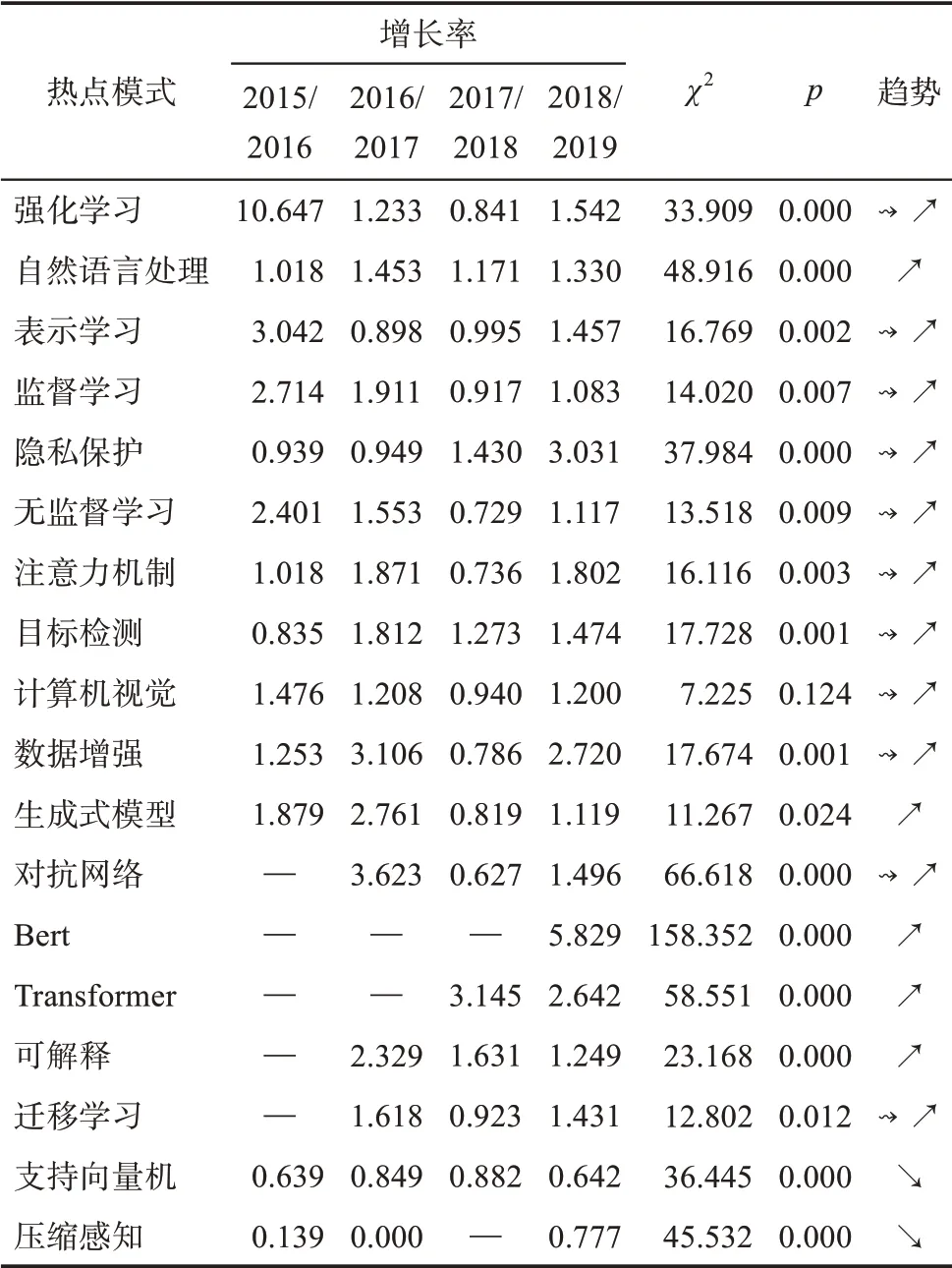
表2 2015—2019年领域热点趋势
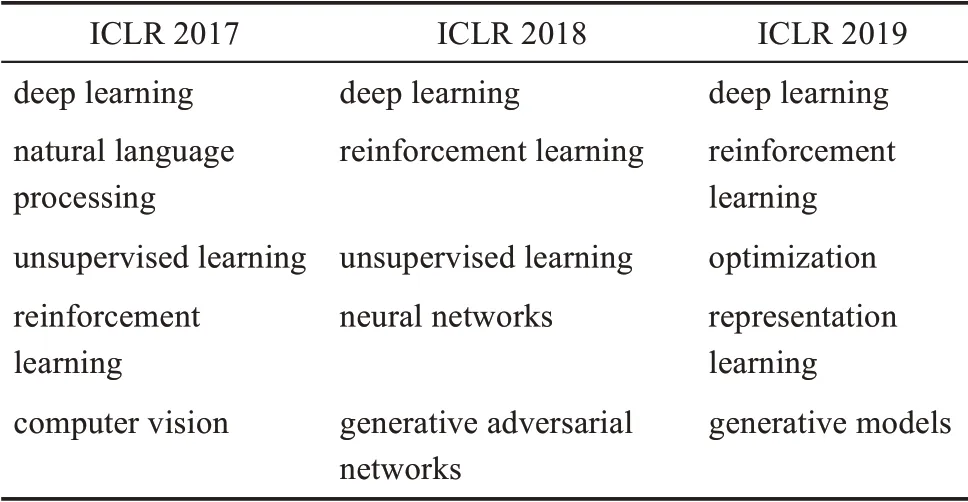
表3 ICLR高频关键词
5 结 论
本文提出了一种利用社会化问答社区中的用户交互数据进行研究领域热点识别的框架。该框架将领域热点看作由领域关键词组成的模式利用涌现模式挖掘(emerging pattern mining)方法来识别领域热点,主要包括领域关键词提取、关键词聚类、候选模式构建以及领域热点模式识别等关键步骤。为了解决涌现模式挖掘方法计算量大、结果中容易出现较多无意义模式的问题,本文提出在领域关键词聚类的基础之上构建候选模式。由于排除了大量包含了属于不同类别的关键词的低频模式,从而大大降低了计算量和无意义模式出现的可能性。该框架能够利用社会化问答社区中研究者的交互内容来识别领域研究热点,因而相对于基于文献计量的方法具有更好的时效性,对领域热点趋势的变化更加敏感。此外,该框架整合了已有的文本分析、涌现模式识别、网络节点聚类等方法,易于拓展至其他类型的社交媒体热点识别的应用中。本文基于2011—2019 年知乎社区“机器学习”话题中用户的问答内容进行实验,验证了领域热点识别框架的有效性。本文提出的分析框架不仅能用于识别领域研究热点,还能够用于社交媒体中的势点识别和趋势分析、突发事件中的舆情走势和讨论热点识别等问题,具有较广泛的应用价值。今后将继续对本文提出的方法在这些相关问题中的适应性展开研究。
该分析框架还有一些不足之处:在关键词提取阶段为了提高关键词提取质量需要人工介入,增加了分析的工作量,并且引入了一定程度的不确定性。在后续研究中,将考虑利用基于深度学习的序列标注方法来提取关键词对该研究框架进行完善。
