基于表示学习的双层知识网络链路预测
2021-03-15曹志鹏潘启亮
曹志鹏,潘 定,潘启亮
(暨南大学,广州 510632)
知识网络是由创造、转移、吸收和应用知识的行为主体构成,在知识传播与交流过程中,彼此联结而形成的复杂网络。许多学者借助合著网络、引证网络和共词网络等对知识网络的形成和演化进行了深入的研究。从研究对象和立足点上看,这些研究体现出了两种不同的研究思路:一种是基于物理统计的方法,侧重于对实际知识网络的拓扑结构和演化特征进行客观的描述及分析,其研究对象往往是文献、书刊等;另一种是基于认知的角度,与思维、语言等要素相结合,侧重语义地图、知识图谱等,其研究对象往往是关键词等情报单元[1]。不同的研究思路促进了知识网络研究的发展,但也在一定程度上造成了割裂。实际上,知识网络的完整研究应该兼具物理统计和认知两种角度,但是这方面的进展却相对缓慢,目前仅有的研究主要集中于二部图网络和异质网络。近年来,人工智能领域,尤其是网络表示学习和人工神经网络的技术突破,为知识网络的研究带来了新的方法,为融合知识网络客观主体和认知文本提供了新的途径。
本文将借助知识表示学习和神经网络等人工智能技术,对合著主体及知识文本分别建立复杂网络,形成双层知识网络结构。利用网络表示学习,分别将两层网络中的节点映射到低维的向量空间,然后输入到专门设计的卷积神经网络中进行链路预测。该模型在进行链路预测时,综合利用合著网络的拓扑结构特征以及作者研究领域等文本内容中的潜在信息,使预测准确率得到大幅提升。
1 相关研究工作
1.1 情报学基本原理
随着科学的发展,学科领域日益复杂,知识与信息呈几何级增长,知识体系逐步演化为一个复杂的知识网络。知识网络属于宏观情报学的研究范畴,知识网络中节点的链路产生机制受到情报学基础理论的指导和约束。靖继鹏教授在著作《情报学理论基础》[2]中给出四个基本原理,即情报产生原理、情报序化原理、情报传递原理和情报吸收原理。
靖继鹏教授认为,“情报产生原理”的理论基础是相似性原理,包括几何相似、运动相似和动力相似。只有相似单元、相似层次的构造,才能产生相似;具备相似过程、相似环境,相似才能产生。如果客观事物中相似属性、相似特征越多、越强烈,那么这种相似的功能就越多、越大。“情报序化原理”指出,序化就是将杂乱无章、随机的知识,加以整序、分析综合成人们解决问题的形态。情报序化原理依据耗散结构理论来阐述,因为耗散结构理论同样是人类情报现象和行为的基本原理。“情报传递原理”研究情报传递交流的行为和过程,情报传递必须处于激发状态,即I≥I0,传递情报所需的时间(T)与其自身的价值(I)和情报用户对情报的需求强度(F)成正比,与传递环境阻力(f)成反比。“情报吸收原理”指出,“情报接受”是用户与情报之间保持的一种关系,是接受主体能动的行为,是情报主体为了追求和实现情报价值的一种合目的性和合规律性的行为,其实质是情报价值的选择性实现[2-3]。
情报学的基本原理为知识网络的链路预测提供了理论支撑,指明了链路预测的努力方向。网络结构相似性是链路预测的重要切入点,寻找知识网络中与某节点结构和功能类似的节点,有助于分析该节点可能产生的链路。情报序化的基础耗散结构理论指出,系统由无序走向有序的一个重要条件是系统内部要素之间存在非线性的相互作用,那么作为复杂系统的知识网络,其链路预测应基于非线性的作用,即预测函数要具有非线性的特征。情报传递和吸收原理则动态解释了信息在高维知识网络向量场中的流动方向和大小。这些都表明,用同样符合这些特征的人工神经网络来拟合知识网络,借鉴网络表示学习技术能够提升链路预测的效果。
1.2 知识网络链路预测
链路预测是知识网络的重要研究领域,处理的是信息科学中最基本的问题——缺失信息的还原与预测。链路预测通过网络中已知的网络节点、网络结构等信息,预测网络中尚未产生的两个结点之间产生链接的可能性[4]。链路预测可以分为两类:未知链路预测和未来链路预测。未知链路(missing links)是指网络中实际存在,但尚未被探测到的链路;未来链路(future links)是指网络中目前不存在,但应该存在或将来很可能存在的链路。两者对应的数据集划分方法也有所不同,前者多采用随机抽样,后者需要考虑时序状态[5]。
经典的链路预测方法主要有:①基于节点结构相似性的方法,包括共同邻居(common neighbors,CN)指标、Adamic-Adar(AA)指标、网络资源分配(resource allocation,RA)指标等;②基于路径结构相似性的方法,包括局部路径(local path,LP)指标、Katz 指标和LHN-II(Leicht-Holme-Newman -II)指标等;③基于随机游走相似性的方法,包括平均通勤时间(average commute time,ACT)指标、有重启的随机游走(random walk with restart,RWR)指标、局部随机游走(locally random walk,LRW)指标等。此外,还有一些研究提出了基于似然分析和基于机器学习的链路预测方法。这些算法以及衍生出来的改进算法,都是通过对已知数据结构特征的刻画来实现预测。虽然在科学合著网络等实际网络中取得了较好的预测效果,但是也存在明显的不足,即这些指标一般只能运用到同质性的复杂网络中,不能用于包含异质节点和异质边的网络。
近年,有一些学者在经典链路预测方法之外另辟蹊径,尝试提出二分网络等异质网络的链路预测方法。张金柱等[6]在作者-关键词二分网络中,抽取多种路径表示作者间的关联,并计算多种合著连接预测指标,最终通过机器学习方法组合这些指标,构建出一个二分网络中基于路径组合的合著关系预测模型。项欣等[7]以作者-关键词网络为例,基于相似连接、优先连接等演化机制,构建了二分属性知识网络上的链路预测模型。陈文杰等[8]以CNKI 引文数据集为例,结合引文网络K阶邻近结构和关键词属性,提出了基于向量共享的交叉学习机制,并运用到链路预测中。整体上看,已有的关于异质知识网络或多层知识网络的研究还很少,且已提出的算法仅是考虑到了节点的文本词语,少有结合网络表示学习和神经网络并进行深入分析的成果。
1.3 网络表示学习
网络表示学习的目的是学习网络节点的潜在低维表示,同时保留网络拓扑结构、节点内容、节点外部信息以及其他方面的信息。常见的基于网络表示学习算法主要分成两大类。
一是基于网络结构的网络表示学习。这类算法包括:基于矩阵分解和特征向量计算的方法、基于简单神经网络的方法和基于深层神经网络的方法。具体算法包括谱聚类方法中的局部线性表示(locally linear embedding,LLE)、拉普拉斯特征映射(La‐placian eigenmap,LE)、有向图表示(directed graph embedding,DGE)、GraRep 算法[9]及各类改进算法。这类算法基于网络的邻接矩阵或者拉普拉斯矩阵,在时间复杂度和空间复杂度上都较高,难以应用到大规模数据和实时数据中[10]。神经网络相关的网络表示学习算法主要有DeepWalk 算法、word2vec 算法、LINE 算法和SDNE 算法等[11]。这类算法使用随机游走序列而不是邻接矩阵,虽然降低了计算时间和空间消耗,但是仍然专注于网络结构本身而无法处理节点结构以外的额外信息。
二是结合外部信息的网络表示学习。在真实世界的复杂网络中,节点往往具有丰富的外部信息,如标签信息、地理位置信息、研究领域信息等。传统网络表示学习主要依赖网络拓扑结构信息,而忽略了这些异质的外部信息。增加外部信息有助于提高网络表示的质量,并增强表示向量在具体的网络分析中的应用。半监督的网络表示学习方法,如MMDW 算 法[12]、node2vec 算 法、GCN 算 法[13]等;结合外部信息的网络表示学习算法主要是结合文本信息的方法,如TADW 算法[14]、CANE 算法[15]等;结合边上标签信息的网络表示学习,如TransNet 算法[16]等。
知识网络表示学习是面向知识网络中的实体和关系进行表示学习,该方向逐渐成为知识网络领域热门研究话题,在知识网络的节点分类、聚类分析和链路预测等领域有良好的运用前景。
2 研究思路与研究设计
本研究的双层知识网络,由作者合著关系网络和学术领域关系网络构成,是具有双层网络结构的复杂网络。首先,通过特定的网络表示学习算法,分别计算得到两层网络中节点的低维向量表示;其次,将代表同一作者的向量按照特定规则运算,得到该作者的综合向量表示;最后,在进行链路预测时,将两个作者的综合向量表示作为输入,通过深层卷积神经网络计算,输出作者间合作的概率。新的节点向量融合了作者合著关系网络的结构信息和作者学术领域信息,具有更优秀的链接预测能力。
2.1 网络结构表示学习
作者合著关系网络记作G=(V,E),其中V表示节点集合,E表示边的集合;边e=(vi,vj) ∈E表示了节点vi到vj的一条边,i,j≤|V|,|V|表示网络节点的数量。网络的邻接矩阵定义为A∈R|V|×|V|。若(vi,vj)∈E,则Aij= 1;否则,Aij= 0。采用邻接矩阵作为该网络的表达形式,邻接矩阵A的每一行,表示节点与所有其他节点的合作关系。
网络结构表示学习,主要采用node2vec 算法。该算法以word2vec 算法为基础,由Grover 等[17]在2016 年提出,其改进了经典的DeepWalk 算法的游走序列生成策略,引入将宽度优先搜索(breadth-first sampling,BFS) 和深度优先搜索(depth-first sam‐pling,DFS)策略,DFS 注重邻近的节点并刻画了相对局部的一种网络表示,BFS 则反映了更高层面上的节点间的同质性。该算法通过兼顾BFS 的宽度和DFS 的广度,让随机游走序列更完整的保存节点中所包含的网络原始信息。具体如图1 所示。
该算法将Skip-Gram 架构扩展到网络,寻求优化 目 标 函 数并 使 用 随机梯度上升来优化模型参数[17]。其中,vi∈V,定义Ns(vi)⊂V为节点vi通过策略S得到的邻居节点。在得到节点的表示学习向量后,Grover 等[17]通过bootstrapping 方法将单个节点的特征学习扩展到节点对的特征学习中,并提出edge2vec 方法,以适用(于)网络节点对的链路预测任务。具体如表1所示。

图1 BFS和DFS的节点vi搜索策略(修改自文献[17])
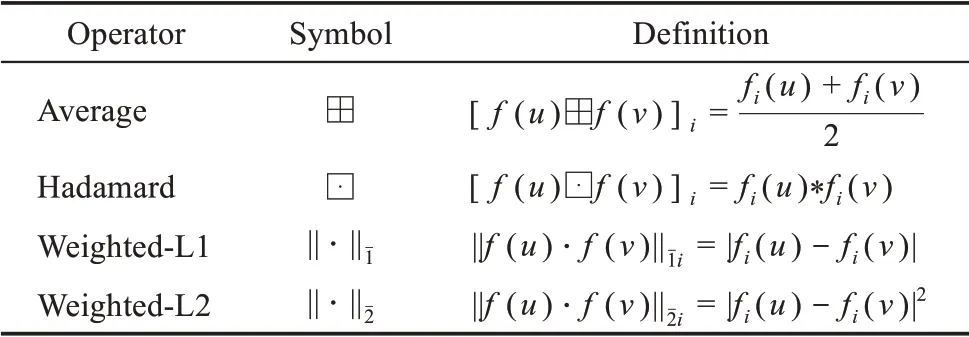
表1 生成节点对向量的二元运算方法(修改自文献[17])
2.2 研究领域表示学习
与网络结构表示学习类似,将作者研究领域网络记作D=(N,B),其中N是节点集合,B是边的集合,边b=(ni,nj) ≤B表示节点ni到nj的一条边,i,j∈|N|。网络的邻接矩阵定义为B∈R|N|×|N|,|N|表示网络中节点的数量,若(ni,nj)∈B,则Bij= 1;否则,Bij= 0。
研究领域表示学习主要采用doc2vec 算法,该算法基于word2vec 算法,由Mikolov 等[18-19]提出。实际上,word2vec 是一个浅层神经网络模型,输入是采用独热编码的单词,隐藏层不使用激活函数,用Softmax 回归。当模型训练好后,该模型通过训练数据所学得的隐藏层的权重矩阵即词的向量表示。这个模型在定义数据的输入和输出时,一般分为CBOW(continuous bag-of-words)与Skip-Gram 两种方法。CBOW 模型的训练输入是某一个特征词的上下文相关词所对应的词向量,而输出就是这个特定词的词向量。Skip-Gram 方法与CBOW 相反,即输入是一个特定词的词向量,而输出是特定词对应的上下文词向量。具体如图2 所示。
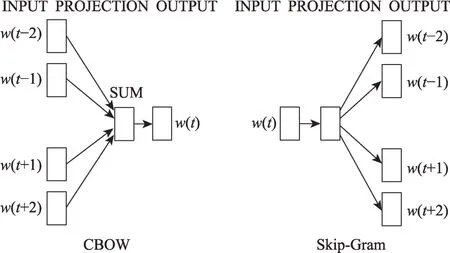
图2 CBOW和Skip-Gram模型(修改自文献[18])
以word2vec 为基础,Mikolov 在2013 年提出了句子和文档的向量表示模型,即doc2vec,模型在输入层引入了文档向量,并将其看作输入单词所构成的语境信息的补充[20]。与word2vec 的Skip-Gram和CBOW 方法对应,doc2vec 在处理输入向量和输出向量时,也分为PV-DM(distributed memory ver‐sion of paragraph vector) 和PV-DBOW (distributed bag of words version of paragraph vector)两种方法,具体如图3 所示。
在doc2vec 得到文档的表示学习后,可以利用文档的余弦相似性进行作者间的链路预测。
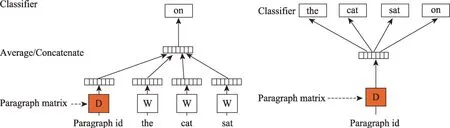
图3 PV-DM和PV-DBOW文档表示学习框架(修改自文献[19])
2.3 双层知识网络链路预测
双层知识网络链路预测主要通过专门设计的卷积神经网络完成,做到同时关注网络结构节点向量和研究领域节点向量,更好的聚合网络结构和文本信息,大幅度提高链路预测的准确性。这是由于该关注机制避免了传统单层合著网络表示学习的不足,即单层合著网络的表示学习只能依靠节点拓扑结构的特征,无法感知节点的属性信息,使得预测能力受到网络结构的限制。知识网络中作者的合作预测固然是作者根据自身合作经历所做出的理性选择,有来自以往合作的惯性动力,与此同时,作者在选择合作伙伴时也关注与自己研究领域相近的其他作者。新的链路产生是多方面共同作用的结果。以往的研究大多聚焦在一个方面,少有同时关注文本和结构信息的知识网络链路预测方法,或者尚未形成较为理想的模型。本研究提出的双层知识网络链路框架(图4)通过引入节点属性的特征向量,给单层合著网络带来额外的信息,减少知识网络的混沌程度,有效且大幅度强化了网络的预测能力。
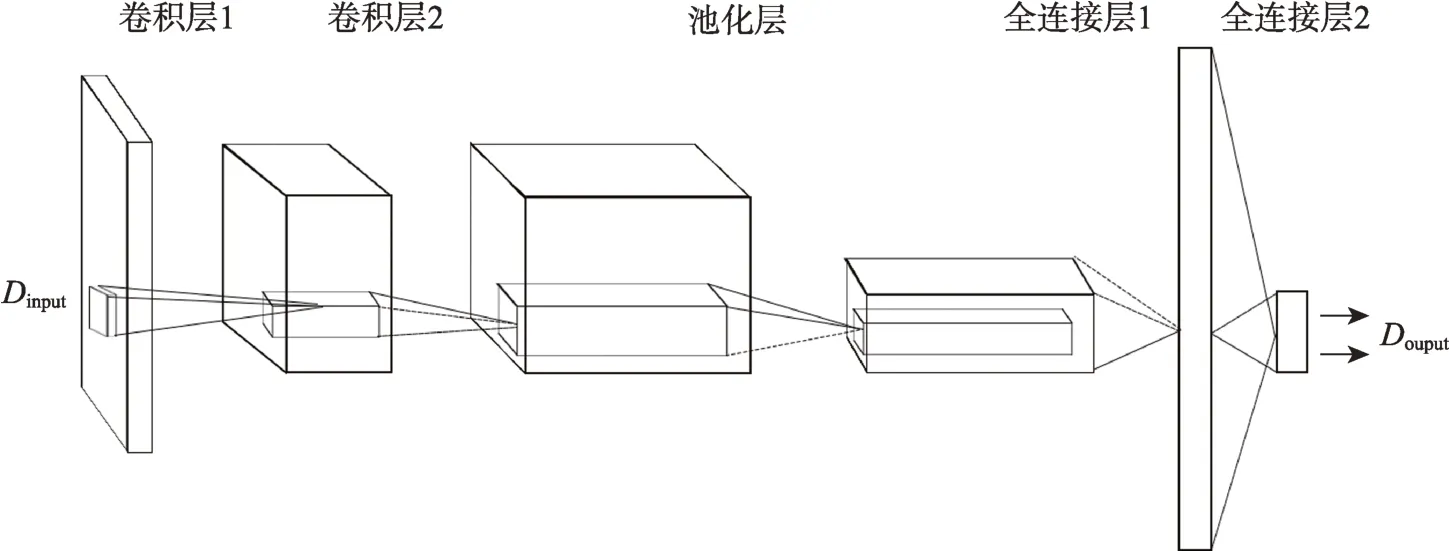
图4 卷积神经网络链路预测框架
本研究提出的框架主要借鉴了图像视觉识别领域成熟的卷积神经网络机制。卷积神经网络有两个突出的优势:一个是参数共享,降低了神经网络处理图像时内存和计算资源的开销;另外一个是具有局部感知能力,与人类处理图像的机制类似,局部感知机制使得每个神经元不需要感知图像中的全部信息,只对图像的局部像素进行感知,然后在全连接层进行合并,从而得到图像的总体表征。这种神经网络结构对平移、比例缩放、倾斜或者其他形式的变形具有高度不变性。
卷积神经网络的特点使其非常适合运用到双层知识网络的链路预测中,但需要解决一个问题,即使用什么样的输入和输出数据作为训练的样本?在图像处理中,往往使用图片的像素矩阵;在自然语言处理中,往往是上下文词语的one-hot 表示。显然,在双层知识网络中,并没有现成的数据来源,尤其是要结合两层网络的所有信息。因此,本研究提出了一种整合结合网络结构表示学习和作者研究领域表示学习的数据整合方式,
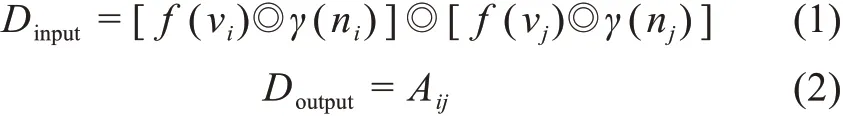
其中,Dinput和Doutput分别表示卷积神经网络的输入数据和分类标签(即是否存在链接);f(vi)表示图G中的节点vi通过node2vec 训练后得到的表示学习;γ(ni)表示图D中的节点ni通过word2vec 训练后得到的表示学习;Aij表示在作者合著关系网络中节点vi和vj的度;运算符号◎表示对向量按行进行叠加 操 作,例 如:的运算结果构成了双层知识网络中的作者vi的综合向量,该向量聚合了网络结构信息和研究领域信息,应当注意的是,研究领域图D中的节点ni须是作者节点vi对应的研究领域。
根据图4,Dinput是卷积神经网络的数据输入,即进行◎操作后的节点对向量,框架主体包括2 个卷积层、1 个池化层和2 个全连接层,输出Doutput是两个节点间的链接情况,是2 分类变量。下文将使用hypernet2vec 代表基于卷积神经网络的双层知识网络链路预测框架。
2.4 模型评价
为了验证链路预测的性能,通常将数据划分为两部分:一部分用于模型训练,一部分用于模型预测。本研究采用AUC(area under curve)作为评估模型的评价指标,通过比较双层知识网络的链路预测和其他链路预测指标的AUC 值,判断本模型与主流模型的性能优劣。AUC 是从整体上衡量算法的性能,其在几何上指的是ROC 曲线(receiver oper‐ating characteristic curve)下面积的大小,也可以理解为在测试集中随机选择一条连边的预测分数值,比随机选择一条不存在的边的预测分数值高的概率。假设独立比较n次,如果有n'次测试集中的分数大于不存在集合中的边的分数,有n"次相等,那么AUC 的定义为
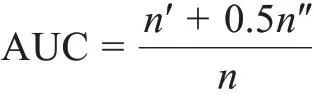
本研究将利用这个指标来衡量模型的性能,AUC值越高,表示模型更加优越。
3 数据来源与数据处理
本研究采用Python 编程语言和TensorFlow 机器学习框架作为数据爬取、数据预处理和模型实现的开发工具。
3.1 数据来源和数据抽样
3.1.1 数据来源
本研究的基础数据采集自CSSCI(Chinese Social Sciences Citation Index,中文社会科学引文索引)数据库中2010—2018 年管理学核心期刊论文的基本信息,包括《管理世界》《南开管理评论》《中国行政管理》等10 种,论文基本信息包括论文名称、论文作者、论文标题和论文关键词,共采集16523 篇论文,论文作者19650 名。
3.1.2 数据抽样
与链路预测研究常见的抽样方法不同,本研究不能直接采用随机抽样的方法生成训练集和测试集数据。这是由于一篇文章发表之后,作者、参考文献和关键词这些属性信息就确定了,因此断边重连机制无法应用其中[3]。具体来讲,本研究加入了经典链路预测指标(如CN 指标、RA 指标、LP 指标等)所不涉及的作者研究领域信息,如果在建立训练集和测试集时,不区分同一作者在两个数据集合中的研究领域信息,会导致训练集中的部分作者研究领域信息重合和其在训练集中的研究领域信息一致;如果直接使用本模型,可能导致错误的实验结果。
例如,假设作者A、作者B 和作者C 共同发表了一篇文章,即作者A、B、C 相互间建立了连接关系,那么三位作者也共享基于该论文题目和关键词的研究领域文档。如果作者A 与作者B 的连边和作者A 和作者C 的连边被选择进入训练集,作者B和作者C 的连边进入测试集,很显然,因为B 和C有几近相同的研究领域(即研究领域相似度约等于1),在预测B 和C 的连接时,不管模型本身的预测效果如何,B 和C 几乎能够被预测。显而易见,这种预测结果并不是因为模型的贡献,而仅仅是因为训练集中已经包含了测试集的信息,这不是本研究所希望看到的检验模型的效果。以往一些类似的研究中,采用了上面随机抽样的方法,可能忽视或者低估这个问题对检验结果的影响。
要得到能够适合本研究的训练集和测试集数据,必须保证训练集和测试集中同一作者的研究领域不能采集自同一篇论文。一种可行的方法是采取时间分段抽样,以某一时点为分界,将该时间点以前的所有论文用于建立训练集,该时点之后的所有论文用于建立测试集。
3.2 数据处理
本研究以2015 年为时间节点,将2010—2014 年的数据作为训练集数据源,2015—2018 年的数据作为测试集数据源,测试集和训练集的论文量如表2所示。筛选出2 个数据源中共同出现过的作者,利用训练集数据源建立作者合著关系网络,选取其中最大连通子图的节点作为最终训练和测试样本的节点。
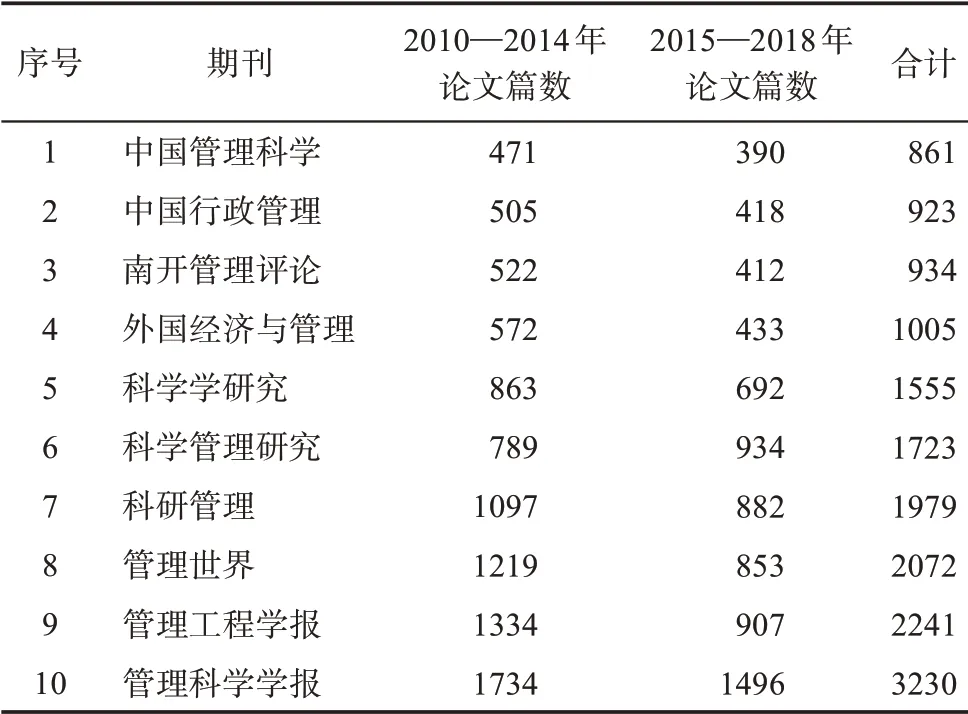
表2 2010—2018年CSSCI管理学核心期刊论文数
3.2.1 网络结构表示学习
首先,建立训练集作者合著关系网络G。采用邻接矩阵作为该网络的表达形式,邻接矩阵的每一行表示一个节点和其他节点的合作关系,关系值用0 和1 表示,0 代表没有发生过合作,1 代表有过合作,网络基本特征如表3 所示。

表3 训练集作者合著关系网络的基本特征
在作者合著关系网络的基础上采用node2vec 计算得到网络结构表示学习,向量的维度d=128,如表4 所示。
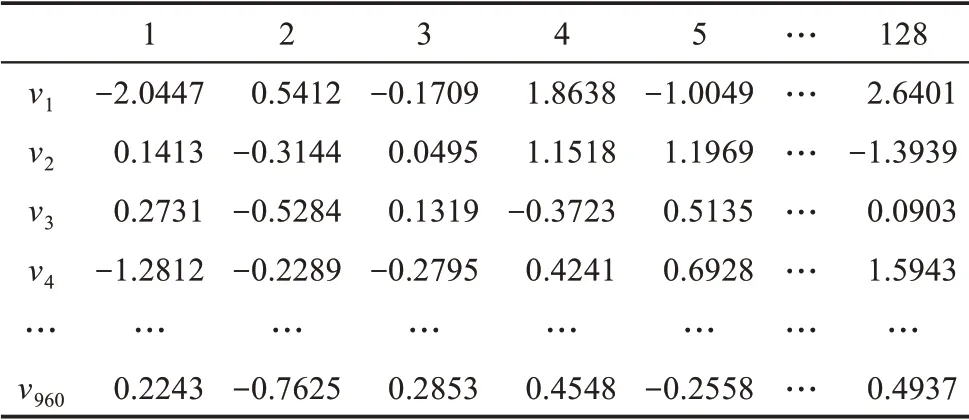
表4 训练集作者合著关系网络结构表示学习
在表4 中,节点{v1,v2,v3,…,v960}={吴晓波,杨力,高旭东,吴晓云,…,宿慧爽}∈V。表中的每一行代表从作者合著关系网络结构中捕获和学习到的信息,每一列代表该信息的一个维度。
3.2.2 研究领域表示学习
作者研究领域主要用作者发表过的论文标题和关键词来描述。从训练集提取出作者所发表的每一篇论文的关键词和论文标题,合并为一篇文档;然后,对文档进行中文分词,得到一个关键词集合,该集合代表了作者的学术研究领域。
{吴晓波:技术创新战略 制造企业 阿里巴巴集团 专利 绿色运营模式 企业绩效 政府作用 许可 二次创新 技术跨越……}
{杨力:全要素能源效率 无效 影子价格 技术缺口比率 区域差异 能源技术 技术差距 改进 决策单元 中国 共同技术率 非期望产出……}
{高旭东:商业模式 探索型创新 企业 融资社会嵌入 低收入群体 利用型创新 多案例研究BOP 人力资本}
{吴晓云:模式全球化组织结构 战略 营销 顾客 服务营销标准化 绩效 前置因素 服务性全球营销战略 市场相似性 东道国 服务性跨国公司……}
根据作者的学术研究领域,利用doc2vec 计算得到作者研究领域的向量表示,向量的维度d=128,如表5 所示。
在表5 中,节点{u1,u2,u3,…,u960}={吴晓波,杨力,高旭东,吴晓云,…,宿慧爽}∈N。表中的每一行代表从作者研究领域网络中捕获和学习到的信息,每一列代表该信息的一个维度。
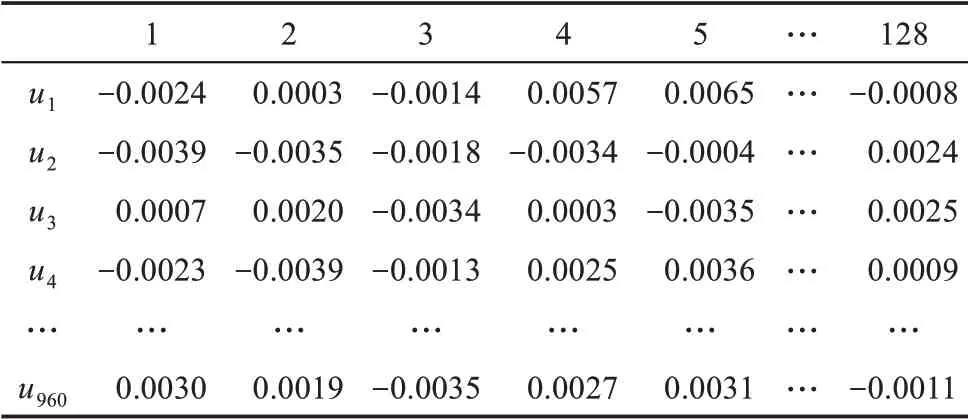
表5 训练集作者研究领域表示学习
4 实证分析
4.1 模型性能
为了验证基于表示学习的双层知识网络链路预测模型hypernet2vec 的性能,本研究选取了3 种经典的链路预测指标作为比较参考,分别是基于节点结构相似性的网络资源分配(RA)指标、基于路径结构相似性的局部路径(LP)指标和基于随机游走的局部随机游走(LRW)指标。同时,加入只使用单层网络进行链路预测的相关指标,分别是基于合著网络结构的edge2vec 指标和基于作者研究领域的doc2vec 指标。除此之外,还加入综合使用网络结构信息和研究领域信息进行链路预测的基准方法,即通过计算节点间的向量余弦相似性进行链路预测,该算法公式是,其中,vi和vj分别是节点结构向量和研究领域向量的横向拼接,该指标命名为hypernet_base。本研究使用AUC作为评估标准,值越大说明模型越好。若AUC 值为0.5,则表示预测效果与随机猜测相当。各指标的AUC 值取10 次结果的平均值,如表6 所示。

表6 hypernet2vec与经典链路预测指标的AUC值
从表6 可知,几种主要算法的AUC 值差异比较大,分布在0.66~0.78。RA 模型是基于共同邻居的指标,仅利用一阶相似性的网络拓扑结构信息,算法比较简单,但与其他指标相比,效果最差。基于路径信息的LP 指标在共同邻居指标的基础上考虑了三阶邻居的贡献,利用了比基于共同邻居指标更多的网络结构信息,预测效果得到了明显的提升,从0.6655 提升至0.7052。LRW 指标的预测效果在局部路径指标的基础上又有了一定的提升,在经典的链路预测算法中取得了最好的预测效果。值得注意的是,使用基于合著网络结构的edge2vec 指标的AUC 值是0.7039,使用基于作者研究领域的doc2vec指标的AUC 值为0.6899,综合使用合著网络结构信息和作者研究领域信息的hypernet_base 指标的AUC值为0.7038,大致与LP 指标相当,优于基于共同邻居的指标,但都比不上基于随机游走的指标。本研究所提出的hypernet2vec 框架的预测效果在所有指标中表现最为优秀,AUC 值与所有参考的指标的平均值约提升了11.17%,比其中的最好值仍然能够提高7.40%,这说明hypernet2vec 框架在链路预测方面优于以往的指标,并取得显著优势。
4.2 模型稳定性
4.2.1 预测效果稳定性
本研究所提出的hypernet2vec 框架与其他算法分别进行10 次实验,得到的AUC 值如图5 所示,AUC 值的数据差异如表7 所示。研究结果,hyper‐net2vec 与其他算法相比,AUC 值的极差和标准差偏大,预测效果存在一定的不稳定性。就整体而言,hypernet2vec 模型就算取10 次中的最差值,仍然比其他指标的最优值大3.13%,性能提升仍然显著。从图5 中还可以看出,hypernet2vec 模型的不稳定性一定程度上与作者研究领域网络层doc2vec 的不稳定性有关,另外一个原因可能来自模型卷积神经网络本身,如本研究使用Adam 作为损失函数的优化算法,可能导致得到局部优化的参数,造成训练结果的差异。

图5 hypernet2vec与经典链路预测指标10次实验的AUC值

表7 各链路预测指标AUC值差异统计
4.2.2 正样本量对预测的影响
模型训练的正样本是指训练集数据中真实存在的作者合作关系,正样本的数量对模型的性能起到重要的作用。本节将选择5 个正样本比例进行实验,分别是20%、40%、60%、80%和100%,每种样本量计算10 次取平均AUC 值,结果如图6 所示。从图6 可知,当入选正样本量是全部正样本的20%时,所有的指标预测效果都很差,跟随机猜测类似;随着样本量的增加,各个指标的AUC 值都不断上升,但hypernet2vec 模型上升的幅度最大。这说明要提高作者合作关系的链路预测性能,在其他条件不变的情况下,必须提高正样本量的大小。实际上,本实验集中数据节点共有960 个,可能存在的连边达到920640 条,而实验集中的实际连边仅有1405 条,占全部可能连边的0.15%,这是个非常稀疏的网络,如果实际连边数能够再增加,hyper‐net2vec 框架的链路预测效果将会有比其他指标更大幅度的提升。
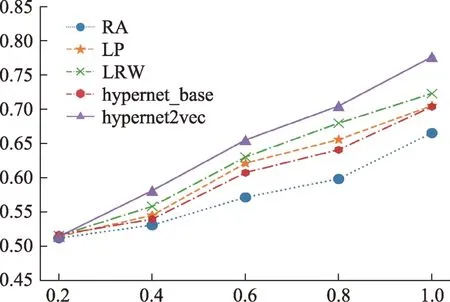
图6 不同正样本量下hypernet2vec与经典链路预测指标的AUC值
影响模型预测效果的另一个因素是正负样本的比例。由于训练集数据正负样本比例严重失衡,在这种情况下,常用的方案是过采样和欠采用。在本实验中,两种采样方式差异不大,但是正负样本比例须控制在1∶20 以内,才能保证较好的预测效果,如果负样本占比过大,模型的预测AUC 值会出现快速下降。这也提示在模型训练时必须考虑到正负样本的比例问题,否则可能存在比较严重的过拟合风险。
5 结论与展望
5.1 研究结论
当前知识网络链路预测主要是基于网络的拓扑结构相似性,很少考虑作者的研究领域等相关的文本信息,导致信息利用不充分等问题,本文提出了一种综合采用网络拓扑结构和节点文本信息的双层知识网络的链路预测框架hypernet2vec 算法。双层知识网络,即作者合著关系网络和学术领域关系网络,利用网络表示学习,分别将两层网络中的节点映射到低维的向量空间,再输入到专门设计的卷积神经网络中计算并进行链路预测。通过在我国管理学领域的实际科研合著网络中进行实验,研究结果表明,与经典的链路预测指标(如RA 指标、LP 指标、LRW 指标和余弦相似性指标等)相比,hyper‐net2vec 算法预测的AUC 值取得了显著的提升,平均提升幅度达11.17%,并且随着知识网络密度的增加,hypernet2vec 算法的预测准确性提升最为明显。综上所述,本文所提出的算法是一种新的且行之有效的链路预测算法,能够在真实的知识网络环境中表现出优异的预测性能。
5.2 研究贡献
5.2.1 进一步明晰知识网络链接的混合择优机制
目前,有关知识网络演化机制的提法较多,如富者愈富、好者变富、马太效应、累积优势等。这些演化机制都指向了BA 网络的无标度属性,即网络演化是度择优机制发生作用的结果,经典的链路预测模型与这种优先连接机制密切相关。经典模型在很大程度上解释了新连边的来源,但由于受到单层网络结构特征的限制,难以描述真实知识网络的连边产生机制。这是因为知识网络新增连边时,节点除了倾向度大的节点合作外,还受到其他内在因素的驱动,包括人际交往、知识交流等[21]。有些学者已经意识到这个问题,通过研究提出了可能影响链路预测的额外机制,如认为知识节点的外部属性对连边的形成也具有贡献。但是目前的文献大多是从理论上进行阐述,在真实知识网络中进行检验的研究很少,尤其是对加入作者兴趣和研究领域后链路预测性能提升的定量研究几乎没有。hypernet2vec模型综合利用了作者合著关系网络的结构信息和研究领域关系网络的文本信息,实际上,是引入混合网络结构和节点属性信息的择优机制,带来了链路预测性能的大幅提升。研究表明,本模型比仅利用合著网络结构信息的edge2vec 模型的AUC 值由0.7039 提升至0.7766,比仅利用研究领域的doc2vec模型的AUC 值提升幅度达到12%。
5.2.2 进一步揭示知识网络链路预测中神经网络发生作用的深层机理
网络表示学习和卷积神经网络都是人工智能领域热门研究方向,并且被不同的学科验证其有效性。本文首次在双层知识网络中引入表示学习技术和卷积神经网络,取得了良好的效果,进一步揭示了神经网络在知识网络链路预测中发生作用的深层机理。
正如文献回顾和相关研究中指出,情报产生原理的理论基础是相似性原理。双层知识网络的链路产生,即两个作者建立合作关系,根本上由网络结构本身和作者研究领域决定。前者代表作者在整个网络中的几何结构特征相似,在网络中具有相似的网络地位和功能;后者代表作者的属性相似性,作者的研究领域相似的地方越多、越强烈,其合作关系的产生可能性越大。相似性是复杂系统重要的动力学机制,知识网络节点连接的相似性原理是复杂系统自相似理论和分形理论的具体体现。从节点的角度看,具有潜在连接可能的节点之间具有相似的结构和研究领域,从连边的角度看,边的产生与边的结构、功能、含义的相似性有关。知识网络节点和连边的相似性通过节点表示学习以及节点表示学习的综合,来进行抽象和计算。在节点表示学习的计算过程中,运用了基于随机游走的各种策略,如DFS、BFS 等,这些策略使得本文得到的节点表示学习向量不仅能包括节点小局部的结构和功能,还包括更大范围的局部甚至近乎整体的特征。而这正是自相似和分形理论“通过认识部分来反映和认识整体,以及通过认识整体来把握和深化对部分的认识”思想的具体实现,其揭示了知识网络系统看似杂乱、破碎的连边现象内部所蕴含的规律,使知识网络系统从无序中发现有序。另外,情报序化原理依据耗散结构理论来阐述,即系统由无序走向有序的一个重要条件,是系统内部要素之间存在非线性的相互作用。本文提出的链路预测模型基于卷积神经网络,在激活网络结点时引入非线性函数sig‐moid,该函数数学形式是,通过该激活函数将上层节点的输入进行非线性转换,然后输出到下一层神经网络,这实际是对双层知识网络作者之间非线性相互作用机制的模拟,也是卷积神经网络能够起作用的深层依据。
5.3 研究展望
作者合作关系的链路预测是多种因素共同驱动的结果。本文提出的基于网络表示学习的双层知识网络链路预测模型综合考虑了合著网络本身的内生动力、作者合作的历史、作者的研究领域等信息,这些信息通过相互补充,降低了网络的不确定性,增加了链路预测的成功率。然而,知识网络作为科学知识积累和思想传播的载体网络,知识的传承与创新还通过学者之间的非正式网络进行联系和沟通。这个非正式网络包括学者的学术群体朋友圈、师徒关系等社会网络。如果能够将学者的社会网络层增加到双层知识网络中,扩展知识网络到三层,这对作者合作关系的预测无疑起到积极的作用,这也是将来值得研究的方向。另外,本模型没有考虑到作者合作关系的权重,对加权网络的研究也值得进一步探索。
