学者身份管理系统元数据分布规律研究
2021-03-15司莉,陈辰
司 莉,陈 辰
(武汉大学信息管理学院,武汉 430072)
1 引 言
近年来,研究人员在权威文档和标识符系统中进行注册,越来越成为一种趋势,这些系统包括规范中枢系统(如LC/NACO 和VIAF)、ID 中枢系统(如ISNI 和ORCID)、研究和协作中枢系统(如nanoHBU)、主题作者ID 系统(如AuthorClaim)、研究人员画像系统(如Google Scholar 和LinkedIn、VIVO)、研究信息管理系统(CRIS)、参考管理系统(如Mendeley)、国家研究门户(如荷兰的NAR‐CIS)、主题仓储(如arXiv)、在线百科全书(如Wikipedia)[1]。除此之外,研究网络工具(research networking software,RNS)、学者档案、学者概要系统、个人信息管理系统、个人在线资料、学者信息仓储和身份管理系统等也包括在内,本文将这些系统统称为“身份管理系统”。
同一个学者可在多个系统中进行表示和注册,这些系统的元数据元素不尽相同,出现学者信息的分散化和碎片化现象,这给共享、重用和聚合来自不同系统的数据,满足学者及机构影响力评价带来较大的困难[2]。由于当前各个系统缺乏有效的共享工作流,不同系统对同一实体进行重复信息收集和创建工作,因此促进各个系统间的元数据共享和复用,是提高身份管理数据利用效率,满足学者学术影响力评价需求的必然要求[3]。
通过对各个系统的元数据结构和元素值进行比较研究,可了解系统的功能差异及重叠部分,为实施身份管理策略及数据复用提供参考[4]。目前,有许多关于学者在身份管理系统中的分布特点的研究,从元数据层面探讨身份管理系统的研究仍然缺乏。本研究的主要目标是探讨中国学者在身份管理系统中的元数据分布规律,为实施元数据增强和复用与各系统的互操作提供有益的参考。
2 相关研究
2.1 关于学者在身份管理系统中的分布及元数据使用研究
图书馆及其他文化机构、版权管理组织和学术机构等创建了一些不同的身份管理系统,研究者对学者在这些系统中的分布进行调查与识别,结果发现学者分布呈现明显的人口统计(如职称、性别和年龄等)和学科分布特点[5-8]。
Panigabutra-Roberts[9]对LC/NAF、VIAF、ISNI、ORCID、Scopus、ResearchGate 等系统进行元数据使用分析,识别出描述研究人员和作品的顶层元数据,并据此设计了应用于美国田纳西大学教职员工和研究生的元数据概要文件。Ortega[10]通过从Re‐searchGate、Academia.edu 和Mendeley、微软学术搜索和谷歌学者中获取作者元数据,探讨了社会和使用指标(altmetrics)与文献计量指标之间的联系。Lee 等[11]根据在RIM 中的参与度,将129 名调查样本分为读者、个人记录管理人员和社区成员三类群体,通过统计不同群体在ResearchGate 中的元数据使用频率,发现不同群体的大部分概要文件至少使用了来自人员、出版物和研究主题类别的一个元素,且不同群体使用的元数据元素具有不同特点。Stvilia 等[12]基于Lee 等[11]的元数据使用分析结果,定义了面向不同群体的元数据概要文件,读者组的概要文件拥有最少的元数据元素,而社区成员组的概要文件拥有最多的元数据元素。
2.2 关于学者身份管理系统的元数据共享研究
学者身份管理系统的元数据共享对于减少数据重复建设工作,支持元数据的扩展、迭代增强、重用和开放交换具有重要作用[13]。数据质量是影响元数据共享和重用的主要因素。例如,VIAF 和ISNI采取大规模集中聚合模式实现规范记录及其他身份数据的共享,在进行数据来源匹配时,Angjeli 等[14]发现质量较差、稀疏或未区分的记录影响了匹配效果。此外,在对ORCID 和Scopus 等系统进行分布式链接时,Bilder[15]发现由于受到元数据不完整等质量问题影响,两个系统并没有大规模构建Same‐As 关系。
对于同一身份实体元数据的共享方式,NACO指出,可通过将一文件完全合并到另一个文件、从一个文件指向另一个文件(如MARC024 字段和ORCID 指向到ResearcherID 的链接)、通过SameAs语句进行聚合等方式实现[16]。在元数据共享的技术方面,Shi 等[17]认为,对元数据进行上下文过滤,需要能够集成来自身份源元数据的技术,而关联数据使用URI 作为实体的标识符,并指定了数据元素之间的语义关联Web,支持跨多个数据源进行互操作,是适合支持元数据共享和语义增强的技术。对元数据共享的基础设施方面,合作编目计划(Pro‐gram for Cooperative Cataloging,PCC)认为,应该利用现有的结构和协议来确保图书馆和其他网络数据提供者之间更好地集成[18]。Ilik[19]则受航空业使用的实时交换和数据验证系统启发,提出用于作者信息实时交换的系统架构,将其称为全球分布系统(Global Distribution system,GDS),该系统将由分散中心组成,所有利益相关方(如出版商、供应商、OCLC、图书馆和其他利益相关者)都能够参与交换/核实作者的信息。
目前,研究主要集中3 个方面:一是对相关身份管理系统进行元数据使用评估,但尚缺乏对不同系统的元数据进行比较研究;二是研究多集中于对身份管理系统的共享方式、技术及其基础设施等方面,但尚缺乏从学者层次上研究不同系统的元数据结构及信息分布差异问题;三是研究多针对国外学者,尚缺乏针对中国学者在身份管理系统中的分布研究。
本研究主要基于统计学分析方法,对中国学者在身份管理系统中的识别情况进行分析,在此基础上,结合词频分析、共现分析、相关分析和主成分分析方法对不同身份管理系统的元数据分布进行度量,通过挖掘元数据结构表现特点,提取不同系统的元数据信息贡献量,为制定有效的元数据复用和增强策略提供参考。
3 研究设计
3.1 确立数据样本
首先,根据六大系部(人文科学、社会科学、理学、工学、信息科学和医学部)在武汉大学机构知识库中的2018 年的发文规模确定相应比例的人数,然后根据“机构单位”进行限定浏览,获取该系部中排列最前的文章的学者,共选择100 名武汉大学的在职教师作为分析样本。
其次,从武汉大学官网及学者个人实验室主页等获取该学者较为权威的简介信息,以核实和确认在系统中的身份。
最后,确定身份管理系统样本,其选择标准为:系统与中国学者密切相关,且保证中国学者在该系统具有较多数量的分布,同时结合不同的语言类型、注册类型、构建方式以及开放程度,选择以下5 个身份管理系统作为调查样本。
①中文名称规范联合数据库检索系统(Chinese Name Authority Joint Database Search System,CNAJDSS),是由中文名称规范联合协调委员会(Cooperative Committee for Chinese Name Authority,
CCCNA)于2009 年创建,各成员机构共享图书馆名称规范文档的一站式检索系统。②百度学者(Baidu Scholar,BS) 主页,是百度学术推出的一项服务,目前已经上线了包含400 多万个中国学者主页。③开放研究者与贡献者身份识别码(Open Researcher and Contributor Identifier,ORCID),是由国际上的学术出版商、国家图书馆、专业协会等推动的项目,其目标是建立“研究人员和贡献者”的集中注册表。④Scopus Author ID(简称ScopusID),是爱思唯尔出版集团为其摘要/索引服务中的作者生成唯一标识符,并生成作者身份概要的系统。⑤Publons Researcher Profiles 是科睿唯安(Clarivate Analytics)的个人资料管理工具,其为研究者生成唯一标识符,并创建个人公共简介,可全面跟踪学者的出版物、引文指标、同行评议和编辑历史。以上各系统的特点表现如表1 所示。
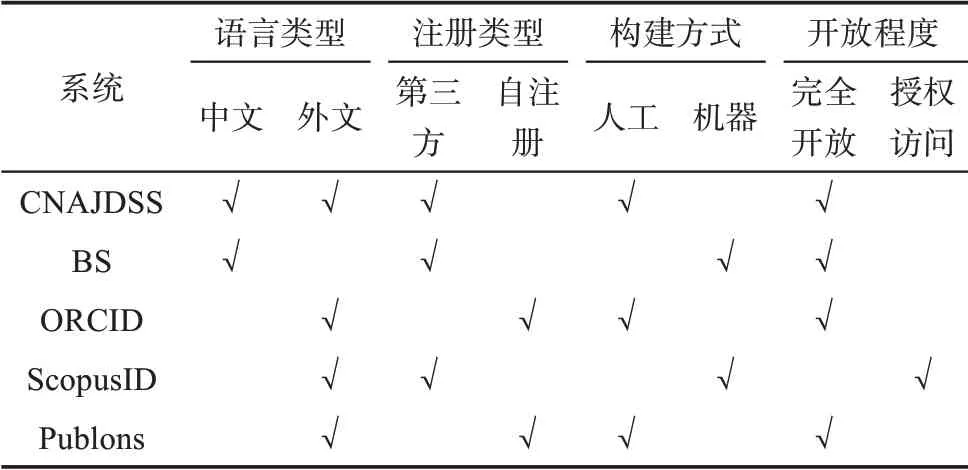
表1 身份管理系统及其特点
3.2 元数据指标采集和分类
3.2.1 元素集的识别
根据系统指定的元数据模型进行元素集采集,如果系统没有发布元数据模型,则采集单个样本在概要文件中的元数据集。在该过程中,对系统中部分非结构化信息进行了人工提取,如CNAJDSS 中的标目附注项、ORCID 和Publons 传记中的有关职称、学科领域、机构从属关系、籍贯等信息,共识别出33 个元素集。
3.2.2 元素集归类框架
本研究定义了一个框架用以对识别出的元数据进行分类,该框架涉及识别信息、学术CV、影响力评价指标、社会网络及计量分析五大类,具体内容如下。
(1)识别信息(或个人资料):是指对消除学者歧义具有重要鉴别意义的元素,如姓名、性别、职称/职位、日期(生卒)、人员或记录ID 等。
(2)学术CV:是为了突出个人学术专业背景而展示的信息,包括基金项目、获奖、出版物列表和出版物来源。
(3)影响力评价指标:分为书目计量指标和替代计量指标,前者主要包括较为传统的出版物数量、总被引频次、H 指数、G 指数和同行评审(peer review);后者主要包括页面浏览/搜索次数和关注者/跟随者。
(4)社会网络:主要包括合作者、合作机构和允许分享的功能元素。
(5)计量分析:基于系统平台数据而提供的附加功能,如出版物等的分析,以确定重要的数量趋势和主题概念的元素。
4 结果与讨论
4.1 学者在身份管理系统中的分布统计
4.1.1 学者在不同类型系统的分布特点
本研究统计结果显示:100 名学者在5 个系统中的分布频次并不一致,从多到少依次是BS(81人)、 ScopusID (79 人)、 ORCID (43 人)、CNAJDSS(41 人)、Publons(18 人)。其中有4 人没有在任何系统中进行表示。
(1)从学者在国内外系统的占有分布上看,学者在国内外相似系统的占有率上较为平衡,如关注论文作者的BS 和ScopusID 的数量差为2,注重人名消歧的CNAJDSS 与ORCID 数量差为2。但从整体上看,学者在ORCID 和Publons 等系统上的占有率不到一半,由此可见,中国学者在身份管理系统中的显示度还有待提高。包括期刊编辑在内的学术交流社区成员,呼吁中国学者通过积极注册ORCID、ResearchGate、Google Scholar 和Loop 等系统,以提高中国学者在国际科学界的显示度[20]。
(2)从学者在新兴与传统的身份管理系统上的分布看,在传统的规范文档占有率少于新兴的唯一标识符系统(Publons 除外)。CNAJDSS 主要针对专著作者进行人名规范,在本样本数据中,人名占有率不到一半,已不能满足不断扩大的规范控制对象的需要。未来应结合利用新兴标识符系统制定身份管理的策略,进一步探索规范控制向标识符管理领域转型的方式和路径[21]。
(3)从学者在自动化和手工管理维护系统的分布上看,依靠机器挖掘的自动化方式创建学者身份系统的数量多于依靠由专业人员手工管理的系统,如百度学者和ScopusID 的数量明显多于其他系统。由专业人员进行系统维护,数据质量高,但是费时费力且不可扩展的[22]。由机器自动收集、聚合、摄入、挖掘研究身份信息,可扩展性强,但仍然需要人工干预以确保其质量。人工和机器方式结合才能达到较为理想的身份管理效果。
4.1.2 学者在身份管理系统中的重叠共现特点
同一学者可同时在多个系统中进行表示和分布,呈现明显的系统重叠特点。统计结果显示,同一学者同时出现在3 个系统中的人数最多(32 人),其次是2 个系统(25 人)、4 个系统(23 人)、1 个系统(14 人)、5 个系统(2 人)。学者在系统中的数量分布情况如图1 所示。以同时占有3 个系统的学者为例进行说明,在BS/ORCID/Scopus 中同时分布 的 为10 人,CANJDSS/BS/ORCID 为1 人,CAN‐JDSS/BS/Scopus 为16 人,CANJDSS/ORCID/Scopus为1 人,ORCID/Scopus/Publons 为4 人,总共32 人。

图1 学者在系统中的分布情况
为了解哪些系统更可能拥有同一学者的身份信息,本文从学者分布层面分析不同系统中的共现关系。首先,通过统计两两系统拥有同一学者的共现频次,并制作共现矩阵;然后,通过社会网络分析工具Ucinet,绘制共现图谱,图谱如图2 所示,通过此图可直观了解学者在两两系统中的重叠和紧密程度。
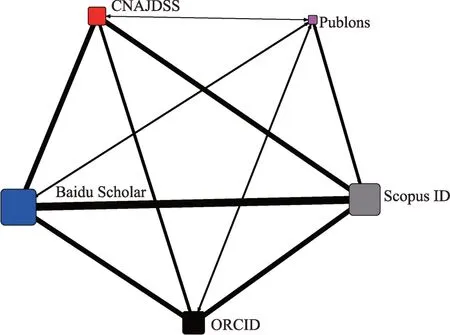
图2 学者系统分布共现图
在图2 中,节点表示学者在各个系统的占有数量,节点越大,表示占有数量越多,连线表示同一学者在各个系统的共现关系,连线越粗表示共现频次越高。从图2 可见,Scopus 和百度学术的共现频次最高,说明BS 和Scopus 主要关注期刊论文作者,因此,具有较高的重叠率。Publons 与其他系统的关联都不强,尤其是与CNAJDSS 的共现频次极低。这与Publons 拥有中国学者的数量不高有关系,而且2 个系统关注的学科领域和范围有一定差别,规范文档主要针对在人文社科领域的专著作者,Publons 中的作者多为自然科学领域发表研究成果的作者,所以重叠概率较低。
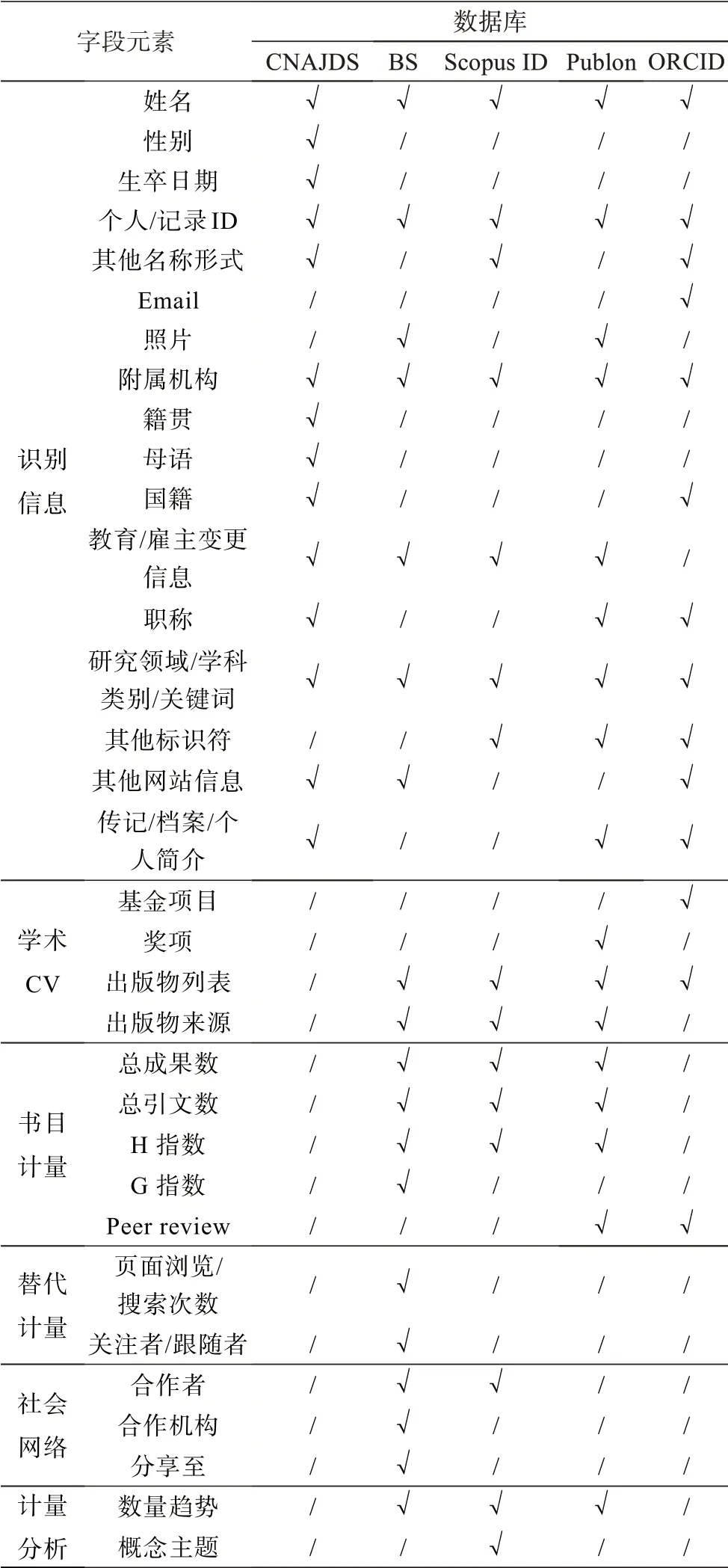
表2 系统元素分类分布情况
4.2 身份管理系统中元数据结构的比较分析
本研究通过对身份管理系统使用的元素集(元数据结构)进行对比分析,可了解各个系统元素集特点及其功能差异,为系统数据增强和重用提供参考。
4.2.1 各系统元素集的分布
本文对采集的系统元素集依照第3.2.2 节提出的分类框架进行归类,其具体分布情况如表2 所示。
4.2.2 各系统元素值出现频率
基于学者层面的元素值频率统计,可了解系统元数据的一致性和完整性程度。图3 是通过热图制作工具Heml 绘制的,数据变量值为各个元素值的出现频率,具体计算方式为

例如,学者在CNAJDSS 中的出现频次为41 人,而在这41 人的规范记录中,性别字段的出现频次为10,则性别字段值出现频率为
图3 中的颜色由黄到红依次渐变,表示频率由低到高,深红色表示频率为1 的字段值。颜色越深说明该元素值频率越高,其字段值出现越多,元素填充越完整,其信息缺失越少。
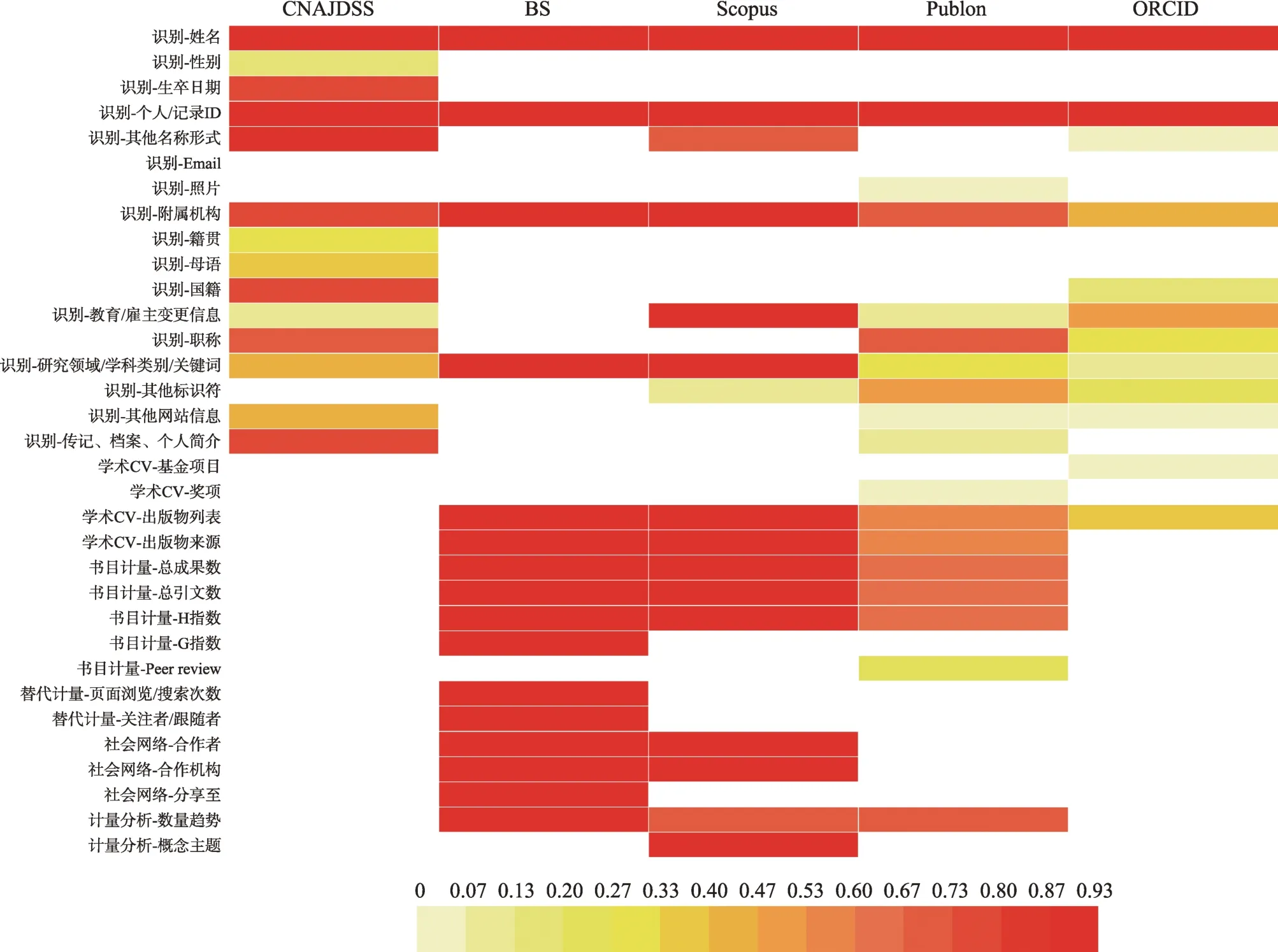
图3 元数据字段值热图(彩图请见http://qbxb.istic.ac.cn/CN/volumn/home.shtml)
从单个系统元数据的纵向比较上看,即使在同一个集合中,元素值出现频率也有所不同。系统的数据维护方式影响元数据值的完整性和一致性,依靠机器自动填充数据的系统颜色趋于一致,且颜色较深,说明各个元数据值出现频次一致,而且填充完整(如BS 和ScopusID);而依赖人工去填充和维护数据的系统,颜色深浅不一,浅色元素较多,说明元素值出现频次并不平衡,且缺失值较多(如规范文档、Publons 和ORCID)。而ORCID 中出现了较多的空白或接近空白的记录,这些记录给人员识别、系统互操作和数据关联带来很大的困难。
4.2.3 各系统元数据结构的相似度
从多个系统元数据的横向比较上看,各个系统包含的信息元素集并不一致。通过Kendall 协调系数计算相似度,可进一步描述各系统元数据变量之间的一致性程度,从而为数据复用和关联提供参考。身份管理系统的元数据结构相似度如表3 所示。
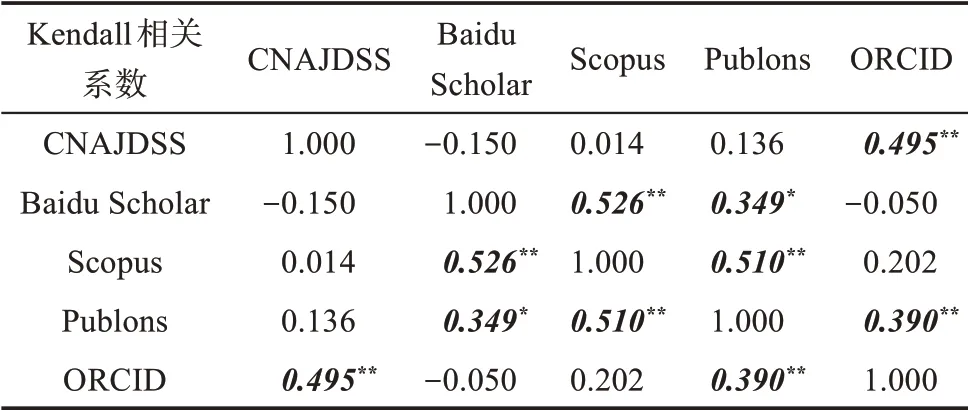
表3 身份管理系统的元数据结构相似度
在表3 中,斜体加粗的数字为显著性相关。其中,CNAJDSS 与ORCID 在元素集结构上较为相似,其信息主要集中在人名识别方面,而且信息分别由图书馆专业人员和学者本人进行维护,可信度较高。BS 与Scopus 和Publons 在元数据结构上较为相关,其中与Scopus 的相似系数最高,其信息主要集中在学术CV、影响力评价指标和计量分析功能元素等方面。Publons 和Scopus 则都侧重于书目计量指标,而BS 在书目和替代计量指标方面都有涉及。Scopus 中书目计量分析指标中包括主题趋势预测,而其他系统则没有涉及。
此外,BS 与CNAJDSS 和ORCID 呈现负相关,并且与CNAJDSS 的相关系数最低,说明元数据结构存在较大的差异,各自形成信息流孤岛,但另一方面可以说明2 个系统具有较强的元数据互补能力。
Publons 与BS、Scopus 和ORCID 都较为相关,并且与Scopus 的相关系数最高。从总体上看,虽然Publons 在学者出现频次以及与其他系统的共现频次都不突出,但是从元数据结构上看,其与多个系统都较为相关,因此,在进行系统数据关联时,可参考Publons 元素集进行模型开发和设计,以最大限度满足和容纳不同系统的元素。
4.3 身份管理系统中的元素值共现及主成分分析
学者在身份管理系统中的分布以及系统元数据的出现频率,将影响各个系统元数据的共现关系。本文基于对元素共现关系统计,进一步进行主成分分析,获得统计学意义上包含更多信息的指标,为有针对性的信息复用和取舍提供参考。
4.3.1 元素值共现分析
首先,统计每位学者在各个系统中的元素值出现频次,构建元素值-学者矩阵;其次,统计两两元素值在同一学者中的共现频次,构建元素值共现矩阵。图4 为各个系统元素值的共现图谱。
从单一系统内部的元素值共现关系看:呈现明显的共现相关规律,但各个系统的元素值共现范围并不相同。其中,BS 和Scopus 各系统内部的大部分元素共现频次较高,而其他3 个系统内部的共现频次呈现明显的差异,元素共现范围从大到小依次是CNAJDSS、Publons 和ORCID。在CNAJDSS 内部,共现频次较多的元素为姓名、个人/记录ID、其他名称形式、出版物列表、出生日期、研究领域/学科类别/关键词,其他元素则表现稀疏和不稳定;在ORCID 和Publons 内部,除了“姓名”和“个人/记录ID”共现频次较高外,其他元素都较低。
从不同系统之间的元素值共现关系比较看:呈现不同的共现特点,其中大部分系统之间都有不同数量的共现元素,而Publons 与CNAJDSS 的共现元素则呈现大部分缺失,2 个系统无论在学者层面,还是元数据结构、元素值层面,都呈现较弱的共现关系。
4.3.2 主成分分析
本研究通过分析各个身份管理系统不同元素指标的主成分,可检测最重要和信息量最大的指标,从而为制定身份数据复用策略提供参考。具体分析过程为:①基于系统元素共现矩阵,进行相关系数的转换,得到元素相似矩阵;②将相似矩阵导入SPSS,进行主成分分析(principal component analy‐sis,PCA);③设置主成分分析相关参数,最后得到2 个成分分组,其累积方差约为98.4%,如表4 所示,基本覆盖了大部分信息。
各个元素对2 个分组的方差贡献率情况如表5所示。
1)总体贡献率
本研究通过提取对各成分的贡献率在0.9 以上的系统元素,可发现第一组成分(F1) 与由BS、Scopus 和部分CNAJDSS 组成的信息具有较高的载荷,内容涉及学术CV、影响力评价指标、社会网络关系、计量分析元素等。3 个系统总方差解释累积率为70.8%(表4),其中,BS 和Scopus 中所有元素对第一组成分都有较高且一致的贡献率,而CNAJDSS 则只有较少信息元素对该成分具有较高贡献,主要为“国籍、其他网站信息和荣誉奖项”三类。第二组成分(F2)与Publons 部分元素组成的信息具有较高的载荷,内容涉及个人识别信息和学术CV,其中贡献率较高的元素为“其他标识符、照片、历史机构、其他网站信息、奖项、总成果数、H 指数、出版物列表”。通过主成分分析得到的2 个分组可以发现,并非所有身份系统的元素指标均具有很强的相关性,而是包含不同的信息量。
从统计结果可以看出,ORCID 在2 个分组中都没有具有较高的信息贡献率,是信息量最少的系统,因此,在进行身份信息提取和复用时,要慎重将其作为替代资源。
2)通用元素的贡献率
主成分分析还可以对各个系统相同元素的信息贡献程度进行测度,以帮助相关人员进行信息复用取舍,同时避免重复数据的收集。表2 显示,5 个系统共有的元素为姓名、个人/记录唯一标识符、研究领域/学科类别/关键词以及当前附属机构,其中,前两者是各个系统必备元素,信息贡献较为稳定,而后两者在各系统中的出现频次表现不一,可利用因子分析对后两者进行信息量测度。
为便于对因子意义进行解释,对成分矩阵进行因子旋转,构造新的方差贡献率。统计结果显示,各个系统在“研究领域/学科类别/关键词”上的信息贡献量分别为:CNAJDSS,0.941;BS,0.916;Scopus, 0.785; Publons, 0.436; ORCID, 0.222。在“附属机构”信息上的贡献率为:CNAJDSS,0.936; BS, 0.916; Scopus, 0.785; ORCID,0.682;Publons,0.337。由此可见,CNAJDSS 在研究主题以及附属机构信息共有元素的贡献量最高,因此,在提取此类信息时,可将CNAJDSS 作为参考贡献源,以获得较多的信息量,避免重复数据的收集。而ORCID 和Publons 在两种信息量的提取上具有较低的贡献,为此可避免将其作为替代资源,可结合实际减少此类数据的提取工作。
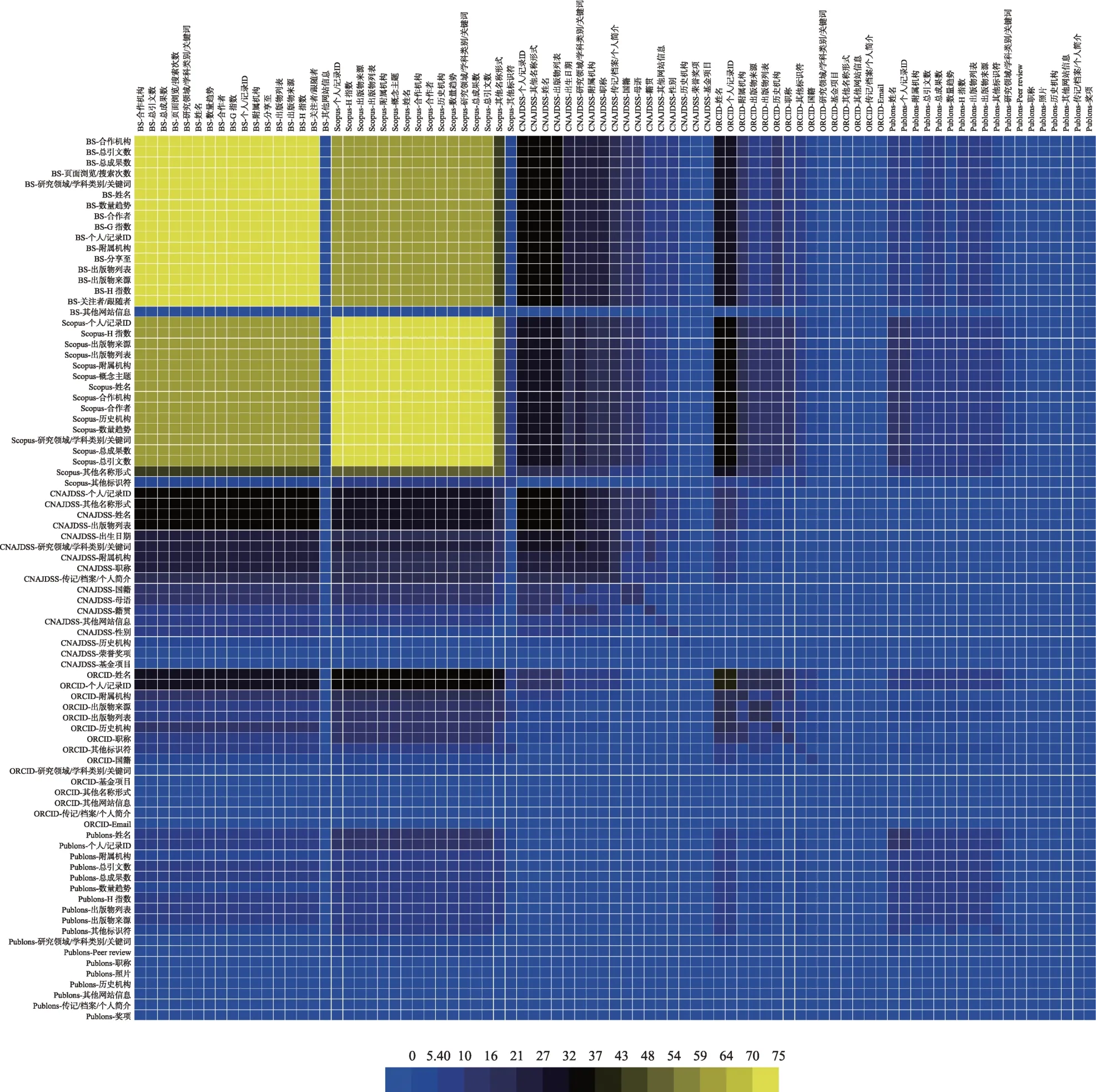
图4 系统元素共现图谱(彩图请见http://qbxb.istic.ac.cn/CN/volumn/home.shtml)
表4 累积方差贡献率
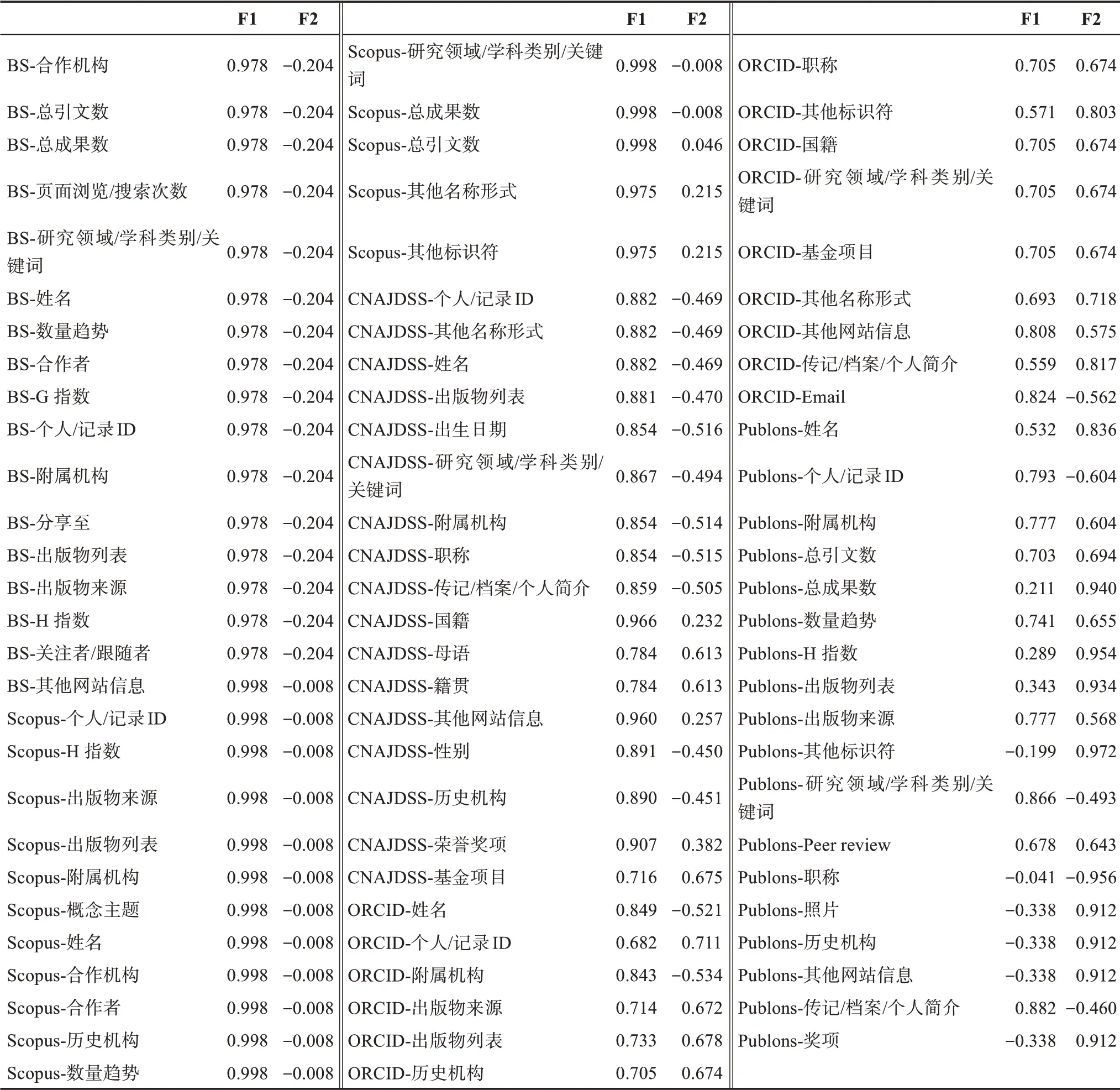
表5 身份管理系统元素的PCA成分列表
5 结论与展望
学者身份管理系统处于复杂的信息流格局中,如何依据身份管理系统的元数据分布特点进行有针对性的迭代增强,从而构建完整的“元数据生命周期”,是未来身份管理生态系统发展关键[21]。本研究通过分析中国学者在各类身份管理系统分布特点的基础上,进一步评估系统元数据结构和对身份信息的贡献率,得出如下结论:
(1)不同服务范围、功能定位、数据维护方式的身份管理系统,具有不同的学者分布特点和规律。同一学者拥有多个身份管理系统的概率高于只拥有一个系统的,且各个系统共现频次不同,Sco‐pus 和百度学术的共现频次最高,而Publons 与其他系统共现频次都极低。
(2)不同身份管理系统的元数据集结构具有差异,从单个系统元数据集合纵向比较看,依靠机器自动填充数据的系统,其元数据较为完整和一致;而依赖人工填充数据的系统,元素表现较为稀疏和不完整。从多个系统的横向比较来看,其相似程度也具有不同的表现。
(3)学者在身份管理系统中的分布,以及元数据集结构影响元素值的共现关系,通过主成分分析法提取两组公共因子,说明并非所有身份系统的元素指标均具有很强的相关性,而是呈现出2 个不同的成分分组。通过旋转因子法对各系统相同/相似元素进行贡献测度,发现CNAJDSS 在“研究主题”和“附属机构信息”上贡献水平突出。
本研究的局限与展望:首先,由于有些系统没有发布元数据服务模型,作者通过收集单个学者的概要文件来确定元数据集,可能影响元素收集的完整性。因此,本研究查看多个学者的概要文件,通过比较来不断完善和补充元素集,可一定程度改善此问题。其次,鉴于人名识别的复杂性,为保证信息识别的正确性,本研究选择武汉大学的100 名样本并采用人工方式进行身份匹配,样本数量可能限制了研究结果的普遍性,未来可在此基础上扩大数据样本规模,并结合机器匹配算法进行人名的识别分布研究,以期为身份数据的复用提供更多可操作性的建议。
