基于组合深度学习模型的突发事件新闻识别与分类研究
2021-03-15宋英华
宋英华,吕 龙,刘 丹
(1. 武汉理工大学中国应急管理研究中心,武汉 430070;2. 武汉理工大学安全科学与应急管理学院,武汉 430070)
1 引 言
据中国互联网络信息中心(China Internet Net‐work Information Center,CNNIC)统计,截至2019年6 月,中国网民人数突破8.5 亿人,其中超过6.8亿人是网络新闻用户,占网民总数的80.3%[1]。由于网络新闻用户的数量庞大,一旦发生突发事件并在网络中传播,舆情扩散速度极快。如果传播中的突发事件属于负面新闻,就会造成巨大的网络舆论,甚至会导致大规模群体性事件的发生,这既不利于社会秩序的稳定,又挑战政府执政能力,破坏政府和国家在社会治理中的公信力。关于热点新闻事件的网络舆情管控,十九大报告中多次强调互联网的监督管理工作,要求有关单位加强网络内容治理,建立完善的网络治理体系[2]。同时,2018 年中央网信办联合公安部发布《具有舆论属性或社会动员能力的互联网信息服务安全评估规定》,要求“及时处理热点问题,防止网络舆情失控”[3]。网络舆情治理需要提前识别突发事件,而突发事件主要是以新闻文本为载体在互联网中传播,因此,新闻文本分类在网络舆情前期的监督管理工作中的尤为重要。高效精确的突发事件新闻识别与自动分类可使有关部门及时搜集信息并跟踪突发事件发展趋势,当某类突发事件新闻报道的频率剧增,应当引起重视,尽早提醒政府和相关部门及时关注并处理热点事件,这不仅为政府采取措施争取宝贵时间,有效地避免事件进一步恶化、导致群体性事件发生,而且能够维护党和政府治理社会的公信力。
高效精确的突发事件新闻识别与文本自动分类的核心在于文本信息表示和算法模型。国内外研究学者对此开展了大量的研究,总体分为两个阶段:传统机器学习阶段和深度学习阶段。在传统机器学习中,学者主要研究文本特征提取技术,例如,李文斌等[4]在统计计算各词语的信息增益(informa‐tion gain,IG)时,考虑文本各文档对于词语熵值的贡献度不同,在计算公式中引入文档贡献系数;刘海峰等[5]在计算互信息(mutual information,MI)时发现模型对低频词过度敏感,于是提出互信息与TF-IDF (term frequency-inverse document frequency)结合选取文本特征;Piskorski 等[6]用NEWUS 系统抽取网络新闻中暴力和灾难事件的信息特征,首先提取网络新闻主题特征,然后按照新闻主题聚类,最后利用浅层语义分析和抽取语法对聚类中的每篇文档进行事件匹配,以此挖掘新闻文本之间的差异;张永奎等[7]基于关键词库采用ID3 算法实现突发事件文本分类应用;毛文娟[8]采用TF-IDF值表示文本特征信息,基于K-means 聚类算法进行训练样本分类,以相似度和阈值监测新话题文本;王强[9]采用TDIDF 作为特征向量值,基于KNN(K-nearest neigh‐bor)算法对新样本进行文本分类。传统机器学习方法提取文本特征的能力有限,难以表达词与词之间的相互关系和词序信息,导致准确率存在瓶颈。
近年来,深度学习方法逐渐成为研究趋势和热点,有学者提出使用深度学习技术提取文本特征信息,例如,Collobert 等[10]基于传统机器学习技术在提取文本特征时容易出现数据维度爆炸和高稀疏性的问题,首次提出词向量概念;Mikolv 等[11]首次提出词嵌入方法word2vec 模型,该模型为词向量转换提供了技术支撑。同时,有学者提出使用神经网络作为分类模型,例如,Kim[12]利用word2vec 模型生成词向量,采用卷积神经网络(convolutional neural networks,CNN)进行特征信息学习;金占勇[13]在词向量基础上,使用长短时记忆网络(long shortterm memory,LSTM)实现突发灾害事件网络舆情情感分析;王东波等[14]在研究先秦典籍过程中,首先构建分类体系,然后使用TF-IDF 表达文本特征,并输入至Bi-LSTM (bi-directional LSTM) 模型中,实验结果表明,深度学习方法效果明显优于机器学习方法。相对于传统机器学习方法,深度学习方法的精度有所提高,但其神经网络模型种类繁多,每种网络模型学习信息的侧重点存在差异,如CNN模型因其独特的局部连接结构更倾向于提取局部空间特征信息,而RNN(recurrent neural network)模型因其序列结构(某一时刻的输出作为下一时刻的部分输入)更倾向于提取时间序列特征信息。由于单一的深度学习模型提取信息能力存在一定缺陷,有学者开始研究组合深度学习模型提取特征信息,例如,刘月等[15]在组合深度学习模型的基础上,引入注意力机制研究新闻文本分类;Lai 等[16]将文本特征进行词向量处理,输入至RNN 和CNN 组成的RCNN(region CNN)神经网络,并运用至文本分类中,分类性能明显提高;赵容梅等[17]将卷积层与循环层重复串联两次组成混合神经注意力网络(CNN-LSTM based on attention,CLA),第一次串联实现词编码,第二次串联实现句子编码,最后基于注意力机制在Softmax 层实现中文隐式情感分析任务;梁志剑等[18]在研究文本分类中,首先使文本词向量化,然后使用BiGRU 神经网络提取文本特征信息,采用TF-IDF 算法对每种特征赋予权值,最后使用贝叶斯分类器实现分类任务;金宁等[19]首先使用词向量方法表示文本特征,然后计算每个词的TF-IDF 权值,权值矩阵与词向量矩阵相乘,得到文本加权词向量,然后输入至BiGRU 层提取特征信息,最后经过卷积层实现农业问题分类;赵洪[20]在研究自动式文摘技术时,分别讨论了CNN、RNN和组合模型方法的原理和优缺点。然而,上述组合深度学习的研究均采用单一的词向量表达文本信息,只考虑了词语间相互关系信息,而忽略了词语与类别间相互关系。
鉴于此,考虑突发事件新闻与普通事件新闻关键词特征不同,以及各类突发事件关键词区分明显的特点,为使模型能更全面学习文本特征信息、提升其性能,本文设计了两级分类模型监控网络新闻事件:第一级突发事件新闻识别模型识别网络中的突发事件;第二级分类模型在上一级模型的基础上实现突发事件新闻分类。遵循组合深度学习新闻文本分类的研究思路,特选取CNN、LSTM 和MLP(multilayer perceptron)模型,提出双输入组合深度学习的新闻文本分类的DCLSTM-MLP 模型,采用基于词向量的方式与基于词语离散度的方式并行表达,基于词向量表征词语间关系作为CNN 模块的输入,基于离散度向量表征词语与类别间关系作为MLP 模块的输入,从而实现对新闻文本的局部空间特征信息、时间序列特征信息和词语与类别间关系的综合学习。
2 基于组合深度学习的新闻文本分类流程
当互联网上出现新闻事件时,基于组合深度学习的新闻文本分类流程步骤如下:
Step1.将新闻文本输入卷积神经网络中,预测该新闻文本是否属于突发事件新闻,若不是则不需要监控,否则进入Step2。
Step2.突发事件新闻文本预处理和特征表达:分词和过滤停用词,使用word2vec 模型得到文本词向量,并计算文本离散度向量。基于离散度的向量输入反映了词语与类别之间的关联信息,值越大对分类的贡献度越大;基于词向量的输入反映了词与词之间的语义关系。使用两种特征表达方式可使模型尽可能学会文本深层次的特征。
Step3.将词向量输入至MCNN(multiple CNN)模块,经过两次卷积和池化操作得到文本空间特征信息,再将空间特征输入至LSTM 模块学习时间特征信息;将离散度向量输入至MLP 模块,隐藏层神经元则学习词语与类别之间的相互关系,MLP 模块和LSTM 模块的输出值拼接融合,输入至Softmax 层进行特征缩放,并输出突发事件新闻预测类别。
基于组合深度学习的新闻文本分类的具体流程如图1 所示。

图1 基于组合深度学习的新闻文本分类流程图
2.1 基于离散度的词语与类别间特征表示
与普通事件新闻文本相比,突发事件新闻文本中含有相对较少、但与突发事件新闻主题关联性较强的关键词特征,如新闻文本中出现“地震”,则该文本很有可能是地震类突发事件新闻。因此,本文利用相关性较强的关键特征词表示新闻文本信息,并用来区分普通事件新闻与突发事件新闻。深度学习中,词向量法采用空间距离代表词义近似程度,以及one-hot 法采用0 和1 表示特征词是否出现,忽略了词语在文中的占比权重和词语与类别间的关联信息,因此,本文提出基于离散度的特征表示方法,具体步骤如下:
Step1.统计某个类别出现特定词语的文本数量,组成该词语的类别频数向量。设vIm表示第m个类别中出现词语I的文本数量,词语I在含有n个类别的样本集中频数向量VI为

Step2.考虑文本集中各类别文本数量不同产生类别频数向量的偏差,计算每个类别文本特定词语的出现概率。设qi表示为第i类文本总数,类别概率向量PI为
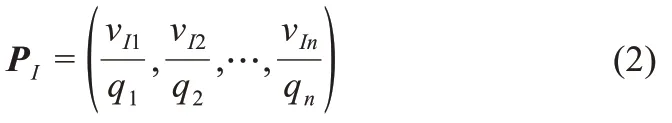
Step3.计算PI的方差作为词语I的离散度,方差越大,离散度越大,表明分类过程中包含的特征信息也越明显。设是词语I的概率均值,是词语I的概率方差,离散度计算公式为
主体要素是以国家司法机关、行政机关为主的全社会力量。要求发动组织和全社会的人关心和参与治理犯罪。[5]科技是总体国家安全观重点涉及的领域,高新技术犯罪将会给国家安全造成巨大隐患。只有动员全社会的力量才能切实有力的预防此类犯罪,使危害国家安全者无处藏身,危害国家安全的行为无法得逞。[6]践行总体国家安全观有利于凝聚预防人工智能犯罪的磅礴力量,构筑起多元主体参与的犯罪预防体系。众人拾柴火焰高,相关主体应积极行动起来,为构筑起多元主体参与的犯罪预防体系添砖加瓦。


Step4.以各词语的离散度组成文本离散度向量,长度为词语总数,词语出现,则对应的词序列处为该词的方差值,否则为0。设z为样本集中词汇总量,文本离散度向量D表示为

2.2 DCLSTM-MLP模型
DCLSTM-MLP 模型结构如图2 所示,该模型主要由三个部分组成:多层感知网络(MLP)、多层卷积神经网络(MCNN) 和单向长短时记忆网络(LSTM)。其中,MLP 是以基于离散度的词语与类别间特征向量为输入,隐藏层神经元学习词语与类别之间的相互关系,输出词语与类别间的特征信息向量;MCNN 是以含有词语间特征信息的词向量为输入,该部分有5 种型号卷积核,经过不同型号卷积核的卷积-池化-再卷积操作,反复提取词向量中的局部特征,输出多种型号卷积核的文本空间特征信息向量;一种型号的卷积核提取的特征向量为一个时间片段,多种型号的卷积核提取的特征信息组成多个时间片段,输入至LSTM 部分,使其学习多个时间片段的时间序列特征信息,最后输出综合空间特征向量。MLP 与LSTM 输出的特征向量拼接融合成新的特征信息向量,然后输入至全连接层再学习,将再学习后提取的特征信息输入至Softmax 层进行特征缩放,最终得到文本类别。
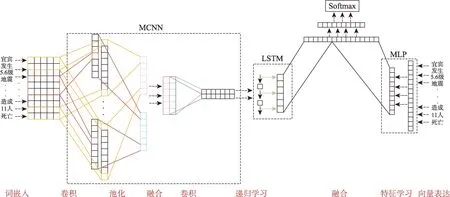
图2 DCLSTM-MLP模型结构
2.2.1 基于MCNN模型的词向量特征提取
卷积神经网络用于提取局部特征,由卷积层和池化层组成,包含若干个共享的滤波器,大小由每次过滤的词数量(m) 和词向量维度(a) 决定。设每次过滤的词数为m,Z(x,y)表示第x个词语第y个维度的值,用W(c,d)表示滤波器中第c行第d列的值。用f(i,1)表示卷积后第i行的特征值,则有
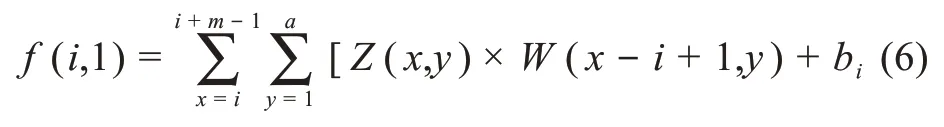
将滤波器得到的特征值经过最大池化操作,得到该滤波器的最大特征值C,

设有k种型号的滤波器,每种滤波器有h个,则经过卷积、池化和融合后可得到大小为(k,h)的feature map_1,用X(xx,yy)表示该feature map_1 中的值,代表第xx种型号、第yy个滤波器的最大特征值。
再次经过z个(z为类别数)大小为(1,h)的滤波器卷积操作,用Hl(1,zz)表示第l个滤波器第zz列的值,对feature map_1 进行卷积,提取每个卷积核与文本类别之间的关系,得到大小为(k,z)的feature map_2,用U(s,n)表示feature map_2 中的值,代表第s种型号、第n个滤波器的提取的特征信息与类之间的关系。设Φ是激活函数,bn是偏置量,则有

2.2.2 基于LSTM模型的时间序列特征提取
LSTM 单元结构中输入门(input gate)、输出门(output gate) 和遗忘门(forget gate)。LSTM 模型提取MCNN 输出的feature map_2 中,各卷积核与类别间相互关系信息的序列信息。U(s:)表示feature map_2 第s行的向量,则有
遗忘门:

输入门:
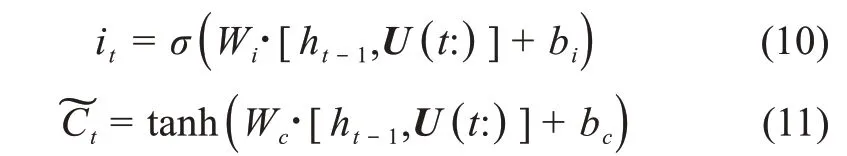
输出门:

其中,Wf、Wi和Wc、Wo分别是遗忘门、输入门和输出门的神经网络权重参数;bf、bi和bc、bo分别表示遗忘门、输入门和输出门的神经网络偏置量;C͂t和ht表示神经单元在t时刻的状态值。
3 实验及结果分析
3.1 突发事件新闻文本搜集
《国家突发公共事件总体应急预案》将突发事件分为4 类:公共卫生事件、社会安全事件、事故灾难事件和自然灾害事件。本文通过爬虫技术,在百度新闻上以关键词的形式,搜索10 类自然灾害事件:暴风灾害、暴雨灾害、暴雪灾害、地震灾害、海啸灾害、洪涝灾害、泥石流灾害、森林火灾灾害、沙尘暴灾害和山体滑坡灾害,5477 条突发事件新闻文本;以及开源的常规新闻事件文本集(如经济类、艺术类、政治类等新闻文本)有2815 条;合并后共计8292 条新闻文本。
3.2 普通事件与突发事件二分类模型分析
总样本集包含5477 条突发事件新闻文本和2815条普通新闻文本,随机选取6699 篇新闻文本作为训练集、1593 篇作为测试集,并将训练集输入至CNN 模型中。CNN 模型主要参数有文本长度、词向量维度、卷积核个数和全连接层神经元数,每次改变单一模型参数,重复模拟3 次,得到模型的准确率、召回率和综合值的平均值,去平均值最大时的参数为最佳参数,最佳参数和最优结果如表1 所示。
由表1 可知,CNN 模型准确率、召回率和综合值均达到99.55%,可有效地识别普通事件新闻和突发事件新闻,为下一步突发事件新闻文本分类打下基础。
3.3 突发事件新闻文本多分类模型分析
3.3.1 离散度向量优越性检验
为检验提出的检验离散度向量表达方法的特征信息提取能力,以突发事件新闻文本为样本集,与空间向量表达法(vector space model,VSM)、卡方检验法与TF-IDF方法对比实验,具体结果如图3所示。

表1 CNN模型最佳参数和最优结果
由图3 可知,本文提出的离散度向量表达方法相对于VSM、卡方检验和TF-IDF 方法具有较好的信息表达能力,并且提取的特征信息更丰富。

图3 各特征表达方式性能对比
3.3.2 模型参数调整
基于深度学习的新闻文本分类模型参数决定模型性能,为对比分析本文提出的DCLSTM-MLP 组合模型与MLP、Text-CNN、Text-LSTM、CLSTM 和CNN-MLP 模型,在获取的突发事件新闻文本的同一训练集基础上,通过重复模拟3 次,每次改变单一模型参数,得到精确度、召回率和综合值的平均值,取综合值最大时的参数为最佳参数,如表2~表7所示,并以此设定各模型的最佳状态。

表2 MLP模型参数及最佳值

表3 Text-CNN模型参数及最佳值

表4 Text-LSTM模型参数及最佳值
3.3.3 模型对比分析
在设定各模型最佳状态的基础上,以突发事件新闻文本同一测试集为对象,得到各模型的准确率、召回率和综合值,结果如图4 所示。
由图4 可得到如下结论:
(1)总体而言,文本分类模型结构越复杂,表明其神经元个数越多,网络层次越多,学习能力越强,模型的综合性能也越强。从准确率角度分析,模型优劣比较为MLP<Text-LSTM<Text-CNN<CLSTM<CNN-MLP<DCLSTM-MLP;从召回率角度分析,MLP<Text-CNN<Text-LSTM<CLSTM<CNN-MLP<DCLSTMMLP;从综合值角度分析,MLP<Text-CNN<Text-LSTM<CLSTM<CNN-MLP<DCLSTM-MLP。
(2)MLP 模型相对其他神经网络结构最简单,模型学习特征的能力有限;CLSTM 模型结构比CNN-MLP 复杂,但前者采用以词向量为输入值的单输入方式,后者采用以词向量和离散度向量为输入值的双输入方式,后者输入的信息更充足,模型学习的内容更全面,因此后者的准确率稍高;DCLSTM-MLP 模型结构最复杂,该模型不仅可以学习文本的序列信息与空间信息,也可以学习特征词语与类别间相互关系信息,该模型准确率明显高于其他模型;综合值是综合衡量准确率和召回率的参数,既能客观反映准确率的趋势,又能反映召回率的趋势,所以模型越复杂,综合值越高。

表5 CNN-MLP模型参数及最佳值

表6 CLSTM模型参数及最佳值

表7 DCLSTM-MLP模型参数及其最佳值
(3) DCLSTM-MLP 模型准确率达到94.82%,明显高于其他模型(88.76%、92.46%、92.35%、93.68%和93.0%),其召回率(94.97%) 与综合值(94.83%) 也明显优于其他模型。总体而言,DCLSTM-MLP 模型综合值(94.83%) 比其他模型分别高(6.06%、2.36%、2.47%、1.14%和1.79%),这表明该组合模型能提高分类性能。

图4 模型性能对比
4 结束语
针对突发事件新闻与普通事件新闻的关键词特征不同,以及各类突发事件关键词区分明显的特点,本文有如下三点创新。①设计了两级分类模型,第一级模型识别突发事件新闻,第二级模型实现突发事件新闻分类。②不同于现有研究采用词向量方式表达文本特征信息,本文考虑各词语对分类影响贡献度提出了离散度向量,通过计算各词语的概率方差得到各词对分类的贡献度。③模型采用词向量与离散度向量共同表达文本特征的双输入模式,以离散度向量表征词语与类别间的相互关系,以词向量表征词语间的语义信息。通过实验对比分析,本文提出的两级分类模型中,第一级模型突发事件识别率达到99.5%,第二级模型准确率达到94.82%,表明该模型具有较好的突发事件新闻识别和分类能力。
本文不足之处在于文本预处理中使用了公开停用词表,没有构建与突发事件对应的专用停用词表,导致部分特征信息被过滤掉,后期可建立突发事件新闻专用停用词表。同时,样本集数量较少,且各类新闻数量分布不均匀,导致模型效能有限,后期需采用更多的样本集进行实验。
