学术文本词汇功能识别
——在关键词自动抽取中的应用
2021-03-15夏义堃李鹏程
姜 艺,黄 永,夏义堃,李鹏程,陆 伟
(1. 武汉大学信息管理学院,武汉 430072;2. 武汉大学信息检索与知识挖掘研究所,武汉 430072;3. 武汉大学信息资源研究中心,武汉 430072)
1 引 言
随着文本数据的日益增长,关键词自动抽取——从文本中挖掘能够高度概括其研究内容和主题的关键词[1]——一直以来都是一个备受关注的研究问题。由于对关键词抽取任务理解的不同,关键词抽取研究主要分为基于排序[2-3]、基于分类[4-5]、基于序列标注[6-7]和基于序列生成[8-9]四大类研究模式[1,10]。在上述研究模式的框架下,现有研究所使用的特征主要包括:①候选词基准特征,如词频、长度、位置、外部知识库等;②图结构特征,如词间关系和中心度量等;③主题特征;④词嵌入向量特征[11]。
上述几类特征更多地考虑词汇本身的分布特点,而忽略了词汇与文献之间的语义关系。词汇功能定义了词汇在学术文献中所承担的语义角色,如“问题”“方法”“技术”“数据”[12],这些具有不同语义功能的词汇从不同的角度反映文献的研究内容。科学研究被普遍认为是提出问题并解决问题的过程[13-14],在一定程度上,学术文献可视为科学研究过程的固化,而文献的核心问题与核心方法则是从文档层面对研究工作内容的总结[12]。同时,关键词也是对文献主题和内容的凝练与反应,作者在选择关键词时有其目的性,其选择的关键词通常是一些注明研究领域、表征研究主题、描述研究所使用的方法和知识等具有一定语义功能的词[15]。因此,关键词往往会涵盖能够充分表征文献研究问题和研究方法等内容的词汇。刘智锋等[16]通过对信息计量学领域的期刊(Journal of Informetrics)论文统计指出,具有研究主题或研究方法语义功能的关键词数量比例高达74.99%。同样地,本文对所使用的计算机领域数据集中,作者标注关键词的词汇功能进行了统计,发现问题和方法词共占67.99%。因此,从科学研究过程的共性出发,考虑领域数据集的统计特点,本文将词汇的功能分为“研究问题”“研究方法”和“其他”。从上文可知,作者在标注关键词时对研究问题和研究方法词具有很强的倾向性,这说明词汇功能特征可以为关键词抽取提供强有力的线索。
因此,为验证词汇功能对于关键词自动抽取的有效性,本文需解决以下三个问题:①如何利用词汇功能特征进行关键词自动抽取?②词汇功能特征对于关键词自动抽取是否有效?③在多种关键词自动抽取模式中词汇功能特征是否有效?
针对上述三个问题,本文使用了两种关键词抽取模式——基于分类和基于排序的模式,在对现有文献关键词词汇功能统计分析的基础上,抽取候选关键词构建特征数据集,然后,融合词汇功能特征训练关键词分类器和排序器,对词汇功能的效果进行了验证与分析。
2 相关研究
对于关键词自动抽取,目前已有许多研究对该任务进行了探讨,提出了不同的算法和模型,并取得了较好的效果。本节将对学术文本词汇功能的相关研究进行阐述,并进一步介绍基于不同模式的关键词自动抽取研究。
2.1 学术文本词汇功能
学术文献的词汇功能是指词汇在“学术文本”这一特定背景下所承担的功能和意义,也是词汇作为一个符号在该环境下对应的内容或用途[12]。对于学术文本词汇功能相关的研究,国内外相关学者已取得了一定的进展。Kondo 等[17]对文献的标题结构进行分析,将标题中的语义信息划分为研究主题(head)、研究方法(method)、研究目的(goal)和其他(other)四类,并基于此构建了技术趋势图生成系统。Nanba 等[18]对标题和摘要中的技术(tech‐nology)和效果(effect)两类词进行了自动识别,其中技术包括算法、工具、材料和数据,效果是属性和属性值的组合。Gupta 等[19]将学术文献的词汇功能分为话题(focus)、技术(technique)和领域(domain)三类,并进行自动识别,其中,话题是指文献的主要贡献,技术包括所使用的方法或工具,领域则为文献的应用领域。Tsai 等[20]重点关注技术(technique)和应用(application)两类语义概念,提出了一种无监督的启发式算法,对文献中的词汇进行识别与分类。Heffernan 等[14]认为,科学研究是问题提出和解决的过程,将科学文献中的词汇功能分为研究问题和解决方法,并训练分类模型对短语是否为问题或方法进行二值判断。
此外,国际语义测评任务SemEval 2017 Task 10[21]基于计算机科学、材料科学和物理学领域的文献数据,提出了关键词抽取、关键词分类和同种类型关键词的语义关系抽取三个子任务。其中,关键词类型包括过程(process)、任务(task) 和材料(material),过程包括研究方法和研究设备,材料包含实验语料和物理材料等。程齐凯[12]对学术文本词汇功能的显现机理进行阐释后,对学术文本的词汇功能进行明确定义,构建了领域相关词汇功能和领域无关词汇功能结合而成的学术文本词汇功能框架,并基于条件随机场和机器学习排序实现了词汇功能的自动标注,其中,领域相关词汇功能依赖于特定的研究领域,并以计算机科学、数学科学和社会科学三个领域为例进行了阐释;领域无关词汇功能,则是从科学研究的普遍过程和共同特点考虑,分为研究问题和研究方法两大类,其中研究问题是科研工作中的问题、主题等对象,研究方法是用于解决问题的技术、手段和途径。程齐凯等[22]将学术文献视为研究人员应用研究方法解决研究问题过程的固化,对文献标题中的研究问题词(topic)和研究方法词(method)进行自动标引,在此基础上构建了领域无关学术文献词汇功能的标准化数据集。另外,刘智锋等[16]结合信息计量学领域的研究特性,将信息计量学领域学术文本关键词的词汇功能分为领域范围、研究对象、研究主题、研究方法、数据以及其他六类,并基于此构建了相应的数据集。
2.2 关键词自动抽取方法
2.2.1 基于排序的方法
考虑到关键词和非关键词对于文档重要程度的差异,基于排序的方法往往按候选词的重要性大小选择文档的关键词,通常利用词的统计特征或词图结构特征通过一定的模式对候选词进行排序。Salton等[2]提出的TFIDF 算法是典型的基于统计特征的抽取方法,该算法综合词汇的词频和文档频率构造了特征TFIDF,并以该特征对候选词的重要性进行评分,对得分简单排序后选择文档的关键词。李素建等[23]以候选词的长度、出现频数、首次出现位置等七个特征,提出了分类试验、正例试验和打分试验三种基于最大熵模型的关键词标引方法,其中,打分方法综合考虑在模型中影响正负概率的特征,在三种方法中显现出可观的潜力。此外,Campos等[24-25]推出的YAKE 系统也利用了多种统计特征,如词的大小写、位置、词频以及与上下文的关联等,通过综合以上信息对候选词的重要性进行评估排序,实现了关键词的自动抽取。
基于图模型的抽取方法中,Mihalcea 等[3]提出的TextRank 算法最具有代表性,该算法以词和词的共现关系构建网络图,并使用PageRank 算法为每个词打分并排序,以此获取文档的关键词。基于Tex‐tRank 算法衍生出了许多抽取效果更好的改进算法,例如,Liu 等[26]使用LDA(latent Dirichlet allocation)融合主题信息构建的Topical PageRank (TPR) 算法;Florescu 等[27]通过加入位置等信息提出的Posi‐tionRank 模型;方俊伟等[28]利用候选词的先验知识实现的PK-TextRank 算法等。
另外,Rose 等[29]提出了RAKE(rapid automatic keyword extraction)算法,先利用网络中词的度和词频计算词的得分,再基于词的得分计算短语的得分并以此排序。随着机器学习的兴起,有监督的学习排序方法逐渐被提出,典型的代表是Jiang 等[30]提出的Ranking SVM(support vector machine)模型。在此基础上,Zhang 等[31]利用词汇的TFIDF、引文TFIDF、位置信息以及共现频次等多种特征,实现了更加先进的机器学习排序算法,取得了较好的效果。
2.2.2 基于分类的方法
以候选词在关键词抽取任务中的身份类别(是或不是关键词)为研究对象,许多研究者将关键词抽取问题转化为分类问题,利用文档中蕴含的信息构建特征来编码文档中的词条,并基于各种特征训练分类器对候选词进行判别,从而实现关键词的筛选。Witten 等[4]提出的著名算法KEA 就是典型的基于分类的抽取方法,该算法使用TFIDF 和词汇首次出现的位置等特征训练朴素贝叶斯模型,实现候选词的分类,取得了较好的抽取效果。还有些研究者通过改进或扩充原有特征对KEA 模型进行扩展并提升了模型的抽取性能,例如,Nguyen 等[32]在模型中添加了表征位置信息的向量和词汇的后缀序列等特征进行关键词抽取;Medelyan 等[5]通过加入包括节点度、语义关联性、链接概率等基于维基百科的新特征,提出了KEA 的扩展模型Maui。
此外,Caragea 等[33]不仅使用TFIDF、首次出现的位置、词性等特征,还利用引文上下文构造了新特征,提出了朴素贝叶斯二分类模型CeKE,进一步提升了抽取效果。除了朴素贝叶斯模型,Tur‐ney[34]基于C4.5 决策树提出了GenEx 模型;Hulth[35]在文档内频率、位置和词性等统计特征的基础上,加入了更多语言学的知识,训练了一个规则归纳系统实现关键词抽取;Zhang 等[36]利用全局上下文信息和局部上下文信息,实现了基于支持向量机(SVM)的抽取算法;方龙等[37]基于TFIDF 和词汇首次出现的位置,通过融合学术文本的结构功能提升了基于SVM 的关键词抽取效果。
2.2.3 基于序列标注的方法
从文本的角度出发,关键词抽取也可以视为待抽取文本的序列标注问题,基于序列标注的抽取方法也逐渐被提出。Zhang 等[38]首次将条件随机场模型(conditional random fields,CRFs)应用到关键词自动抽取任务中,利用局部上下文特征(如前一个词或后一个词、TFIDF、词性、位置等)、全局上下文特征(如是否在文章标题、摘要、段落等文章结构中出现)以及混合上下文特征(如前一个词加后一个词等),训练CRFs 模型对文本进行标注与关键词抽取。近年来,Gollapalli 等[6]以词的大小写、是否在标题中出现以及是否为无监督方法抽取结果的前十之一等为特征,以单个特征或组合特征训练CRFs 标注器抽取关键词;Patel 等[39]将词嵌入向量作为特征之一,同TFIDF、相对位置等特征一起训练CRFs 实现关键词抽取。同时,基于神经网络的序列标注方法也逐渐引起研究者的兴趣,例如,Sahrawat 等[7]利 用BERT (bidirectional encoder repre‐sentation from transformers)等预训练模型获得上下文信息更丰富的嵌入向量,提出了BiLSTM-CRF 抽取模型;Martinc 等[40]使用Transformer 模型并加入词性信息对文本进行标注,提出了TNT-KID 模型,这些模型大都取得了不错的效果。
2.2.4 基于序列生成的方法
由于关键词不一定在文档中出现,但标注人员可根据对文档的整体理解,提炼出合适的词作为文档的关键词,而深度学习模型恰好能够实现对文本的理解,因此,不少研究将翻译模型的思想应用到关键词抽取任务中,提出了基于序列生成的方法。Meng 等[8]提出了生成模型copyRNN,通过深度学习捕获文本的语义信息,使用Encoder-Decoder 框架预测关键词;Chen 等[9]进一步考虑到关键词生成中的重复问题和覆盖问题,加入词汇间的相关性约束提出了CorrRNN 模型;Chen 等[41]着重考虑标题对文档主题内容的概括作用,提出了利用标题指导关键词生成的TG-Net 模型;Zhao 等[42]通过在模型中加入词性约束模块也降低了关键词的重复率,提升了效果。
可见,关键词自动抽取任务已经形成了较为成熟的研究模式,并且各种模式下的成果十分丰富。模型使用的文本特征呈现多样化趋势,主要考虑词汇在文档中出现的频次、所处的位置、与其他词的共现关系以及词汇的词向量、上下文等信息,或与源文档相关的外部知识,如引文、维基百科等,众多研究结果证明了典型特征(如TFIDF、位置信息等)对于关键词自动抽取的有效性,为本研究的开展提供了坚实的基础。但是,在语义信息的使用方面,仍然未有研究考虑与文献内容密切相关的词汇功能特征。同时,对学术文本词汇功能的探究大都聚焦于其分类与识别任务,几乎没有研究深入讨论词汇功能在关键词自动抽取中的应用。因此,本文拟利用候选词的词汇功能构造相关特征参与关键词抽取,从而探究学术文本词汇特有的语义功能——词汇功能在关键词自动抽取中的有效性,充分发挥词汇功能的作用,优化关键词抽取任务的效果。
3 研究方法
词汇功能是一些特定的词所具有的语义特征,与关键词紧密相关,而传统的两阶段抽取方法首先会构建与关键词较为相近的候选关键词集合,在此基础上直接将候选词的词汇功能应用于关键词的选择,能够更加直观地发挥学术文本中关键词的词汇功能作用。另外,有监督的方法已经较为成熟有效,如方龙等[37]对学术文本结构功能特征在关键词自动抽取中的应用研究,对于本研究也有较好的借鉴作用。因此,本文将基于相同的模式——分类和排序,探究词汇功能在关键词自动抽取中的作用。
3.1 问题定义
给定一篇学术文献ai,其摘要表示为Di(w1,w2,…,wli),关键词词表表示为Ki(k1,k2,…,km)。关键词自动抽取则是学习函数g(z)使得
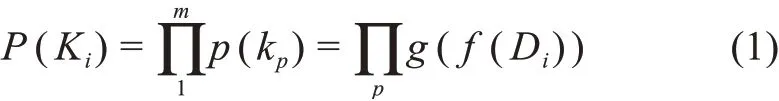
概率最大,其中f(Di)是基于摘要的特征抽取方法。那么基于分类的关键词自动抽取则可以定义为:假设V(v1,v2,…,vN)为领域关键词词表,若cj⊆di且cj∈V,则选择cj为文献ai的候选词,使得Ci=(c1,c2,…,cj,…,cn);然后,学习分类函数h(x)对cj是否为文献ai的关键词进行判定,若是,则使kp=cj,从而使得

其中,Ki⊆Ci。类似地,对文献ai的候选词集合Ci=(c1,c2,…,cj,…,cn),基于排序的关键词抽取通过学习函数̂(x)对cj打分后排序Ci中的全部候选词得到C'i,即,使得

按一定的阈值返回top_n个候选词,构成关键词集合Ki。
区别于上述一般的关键词自动抽取规则,在融合词汇功能的关键词自动抽取中,
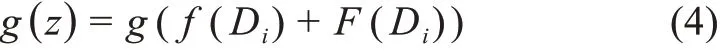
特别地,F(Di)表示融合词汇功能特征的构造函数。在本研究中,不仅要获得候选词的基础特征,还要基于候选词的词汇功能构建新特征,进而学习函数h(x)和ĥ(x),实现对候选词的分类和排序,从而得到最终的抽取结果。
3.2 关键词自动抽取流程
本文将分为候选关键词集合构建和关键词抽取两个阶段进行实验,主要包括4 个步骤:①候选关键词集合构建;②特征构建;③模型训练;④结果评估。整体流程如图1 所示。
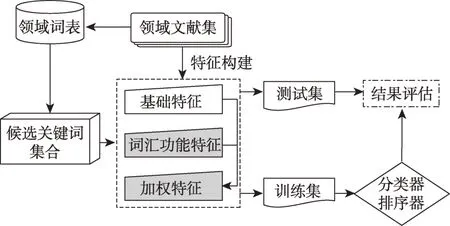
图1 融合学术文本词汇功能的关键词抽取流程
3.2.1 候选关键词集合构建
在对特定领域的学术文献进行关键词抽取时,领域先验知识具有较好的作用[28,37]。因此,本文利用计算机领域中主要期刊文献的作者关键词构建领域关键词词表,基于词表匹配的方法,对实验文献集中的每一篇实验文献ai,从其摘要中匹配出n个词条作为其候选关键词,以此构建文献ai的候选关键词集合Ci=(c1,c2,…,cj,…,cn),并对每一个候选关键词cj是否为关键词进行标注。
3.2.2 特征构建
如图1 所示,在特征构建阶段,首先基于摘要文档为候选词构建基础特征——词频特征和位置特征,同时,对候选词的词汇功能类别进行识别,再基于词汇功能对候选词的基础特征进行加权操作,从而构建最终的加权特征。本节将对上述步骤进行详细介绍。
3.2.2.1 基础特征
1)词频特征(TFIDF)
Salton 等[2]在1988 年将TFIDF 应用于关键词自动抽取,该指标用于评估一个词对文档集中某篇文档的重要程度,是信息检索领域的重要加权指标之一。TFIDF是词频(term frequency,TF)和逆文档频率(inverse document frequency,IDF)的乘积,具体计算为

其中,nij表示词ti在文档dj中出现的次数;|A|表示文档集中的文档总数;|{j:ti∈dj}|表示包含词ti的文档数。从上述公式可以看出,词汇的TFIDF 与其在文档中出现的频次成正比,与其在文档集中出现的频次成反比。一个词的TFIDF 越大,表明该词对于当前文档的重要性越高。
2)位置特征(FI)
词汇在文档中的位置也是重要的特征信息[4],本文采用候选关键词在文档中首次出现的位置FI(first index) 作为关键词抽取模型的第二个特征,计算公式为

其中,indexij为词ti在文档dj中首次出现的位置;|dj|是文档dj的总长度,即dj包含的总字数。
3.2.2.2 词汇功能特征
1)词汇功能识别
虽然学术文本的词汇功能可以分为多种类别[12],但是通过对本文的研究数据统计发现(数据详情见第4.1 节),一篇文献的作者关键词中,作为研究问题或研究方法的关键词较多,占比达到67.99%,而用于表征文献其他内容的关键词相对较少,仅占32.01%。因此,本文将词汇功能分为“研究方法”“研究问题”和“其他”三类,其中,“研究方法”“研究问题”即程齐凯[12]定义的领域无关词汇功能。本文采用人工标注的方法对数据集中的关键词进行词汇功能标注。每篇文献的关键词统计结果如表1所示。

表1 每篇文献的关键词统计结果
2)基于词汇功能的加权特征
在刘智锋等[16]的研究中,具有研究主题和研究方法语义功能的作者关键词占比较高,分别达到40.85%和34.14%,而标记为其他语义功能的关键词仅25.01%,本文的统计结果(表1)同样表明,作者在标注关键词时更偏向于能够表征文献主题和方法的词。因此,在进行关键词抽取时,应该重点关注词汇功能为“研究问题”和“研究方法”的候选词。并且,统计结果显示,以上两类关键词在数量上存在一定差异,这说明不同词汇功能的词被作者标注为文献关键词的概率是不同的。为此,本文设置了权重wt和权重wf,根据候选关键词的词汇功能类型(term_func),对基础特征TFIDF 和FI 按不同的比例进行加权,从而构造加权词频特征TFIDF′和加权位置特征FI′,计算公式为

如公式(9)和公式(10)所示,对于具有“研究问题”和“研究方法”功能的候选词,按一定比例改变其基础特征的大小;由于仍有部分关键词不是文献的研究问题或方法,故对于“其他”的候选词,实验保持其值不变。综上所述,基于表1 的统计结果,本文将分别设置参数wt0、wt1、wf0、wf1为1.5、2.0、0.75、0.5,以此计算加权词频特征TFIDF′和加权位置特征FI′。
3.2.3 融合词汇功能的关键词抽取模型训练
在第3.2.1 节和第3.2.2 节的基础上,本文将使用 sickit-learn①https://pypi.org/project/scikit-learn/和 TensorFlow Ranking (TF-Rank‐ing)②https://github.com/tensorflow/ranking[43]实现效果稳定且常用的SVM 算法和学习排序算法,以相同的参数,利用不同特征组合的训练集数据(具体设置见第4.3 节)分别训练关键词分类器和关键词排序器,从而对比分析融合词汇功能的加权特征的作用。
3.3 结果评价
对于二分类模型,在以候选关键词为单位的二类分类层次上,采用准确率Acc 评估SVM 模型对关键词的判别能力;在以文献为单位的文献层次上,本研究选择P、R和F[10]为评价指标。假设候选词总个数为X,模型分类正确的候选词个数为x,作者关键词集合为,模型抽取的关键词集合为K,那么上述评价指标的计算公式为
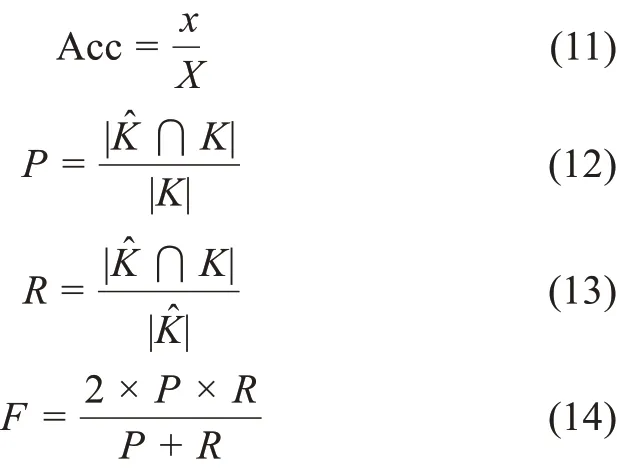
对于学习排序模型,本文采用P@n、MAP、NDCG@n[43]对实验结果进行评价。
4 实验与结果分析
4.1 数据集与预处理
本研究采用计算机领域核心期刊《计算机工程》2007—2018 年刊载的8511 篇学术文献数据,以文献摘要构建关键词抽取的文档集,并获取全部作者关键词。同时,实验收集了计算机领域1998—2018 年发表于中文核心期刊的30 万篇文献的作者关键词,经过滤处理后,构建了大小为448474 的领域关键词词表。实验使用的文献集共有作者关键词34554 个(去重后21065 个),平均每篇4.06 个,最多8 个,最少1 个,其中约95.95%的关键词(33155个)在本文使用的词表中出现,说明本文基于领域关键词词表进行关键词自动抽取具有一定的合理性。
为了更客观地评估词汇功能特征在学术文本关键词自动抽取任务中的作用,本文根据候选词匹配的结果,对实验数据集进行了过滤,删除了关键词集合中不包含作者关键词的文献数据,共获得8286篇有效文献用于后续实验。经筛选后的数据中,平均每篇文献的关键词词数为4.09 个,其中2.96 个在摘要中出现,2.85 个被成功匹配为文献的候选关键词。
对于候选词的词汇功能,本文根据人工标注的关键词词汇功能进行标注,若候选词为关键词,则其词汇功能同关键词;反之,则标注为“其他”。对于位置特征FI,本文直接按公式(8)进行计算;对于词频特征TFIDF,本文使用中文分词工具jieba①https://pypi.org/project/jieba/,在用户词典中加入领域词表V,并采用全模式对摘要文本进行分词,在此基础上按公式(5)~公式(7)进行计算。
4.2 特征分析
本研究对实验使用的8286 篇文献的候选词的词频特征和位置特征进行了统计,结果如表2 所示。其中,正例的TFIDF 均值为0.088,约为负例的2倍,正例的FI 均值为0.280,远小于负例均值0.430。可以看出,相较于非关键词,关键词在摘要中出现的位置更靠前,并且具有更大的TFIDF 值,因此,对于更有潜力成为关键词的词——具有“研究问题”和“研究方法”功能的候选词,本研究将通过一定的加权策略增大其TFIDF,并减小其FI,从而增强基础特征在关键词抽取中的作用。

表2 候选词基础特征统计结果
4.3 实验设置
对于二分类模型,本文基于数据集大小对其进行了5 折交叉验证处理;同时,为了降低正例(23652)和负例(459111)数据不平衡对分类器的影响,实验选择训练文献中全部标记为1 的候选词及其特征数据和随机抽取的等量标记为0 的候选词及其特征数据作为训练集,抽取每篇测试文献中所有标记为1 的候选词及其特征数据和等量的标记为0 的候选词及其特征数据作为测试集,以此训练SVM 分类器。对于学习排序模型,实验按8∶1∶1 的比例划分训练集、验证集和测试集,以默认参数进行训练,训练步数设为10000。另外,实验分别对基础特征和加权特征进行归一化处理。
本文以使用词频特征TFIDF 和位置特征FI 的实验为基准实验,设置了10 组不同的特征组合进行二分类实验和学习排序实验,分别为:实验①,仅使用词频特征;实验②,仅使用加权词频特征;实验③,使用词频特征和加权词频特征;实验④,仅使用位置特征;实验⑤,仅使用加权位置特征;实验⑥,使用位置特征和加权位置特征;实验⑦,使用两个加权特征;实验⑧,使用两个基础特征和加权词频特征;实验⑨,使用两个基础特征和加权位置特征;实验⑩,使用两个基础特征和两个加权特征。
4.4 实验结果与分析
表3 是分类实验的评价结果。从表中可以看出,在二分类层次上,相较于基准实验,所有使用加权特征的实验的Acc 指标均有所提高,其中实验⑩效果最好,达到0.840,相对于基准实验(0.674)提高了约24.63%;在文献层次上,从F值来看,有多组实验的效果均优于基准实验(0.532),包括仅使用单个加权特征的实验⑤(0.596),并且最优实验(实验⑩)的F值提升至0.666,相对提升幅度达到25.19%。以上结果说明,融合词汇功能的特征能够有效地提高基于分类的关键词自动抽取效果。

表3 SVM二分类结果评价
鉴于每篇文献的作者关键词约为4.09 个,本文选择n= 5 时的P@n和NDCG@n以及MAP 对基于排序的抽取结果进行了评价,评价结果如表4 所示。从表4 可以发现,除了实验①、实验④和实验⑤外,其他实验组相较于基准实验在三个指标上都有明显的提升,其中效果最好的实验⑩在MAP、NDCG@5 和P@5 上依次达到0.813、0.828 和0.447,相对提升高达168.32%、189.50%和148.30%。提升效果最弱的实验②也达到0.490、0.500 和0.300,相对提升61.72%、74.83%和66.67%。这些结果充分说明,在基于排序的关键词自动抽取中,词汇功能特征具有积极的作用。
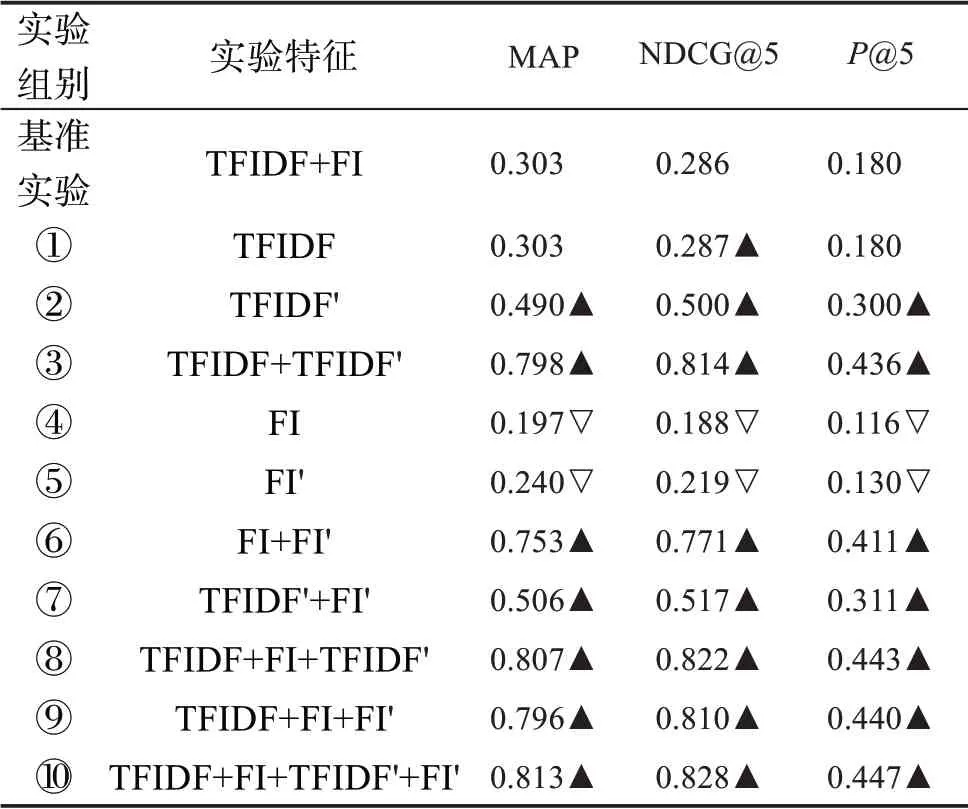
表4 TF-Ranking学习排序结果评价
4.5 讨 论
本研究对二分类实验中仅使用基础特征的基准实验和融合词汇功能特征后的最佳实验(实验⑩)的预测错误进行了统计分析。实验⑩预测错误的词共有1468 个,根据表5 可知,有1173 个词(约79.90%)是在仅使用基础特征时就出错的,且关键词比非关键词少,分别有441 个和732 个。在这些关键词中,词汇功能为“其他”的关键词有298 个,为“研究方法”和“研究问题”的分别仅有134 个和9 个,也就是说,两次实验均未被正确分类的关键词中,大部分(约67.57%)的关键词并不具有问题或方法功能,根据加权策略,这些关键词的加权特征与基础特征并无差别,并没有改变对关键词的区分能力,因此在基准实验中无法被正确分类,在实验⑩中仍无法被预测正确。而在基准实验预测错误的3060 个词中,共有1887 个词(约61.67%)在融合词汇功能特征后被预测正确,包括774 个非关键词和1113 个关键词。从表6 可以看出,重新预测正确的关键词比非关键词多,并且预测正确的关键词全部具有问题或方法功能,进一步说明通过词汇功能增强关键词的基础特征后,关键词更容易正确地被识别出来,分类效果自然得到较好的提升。

表5 基准实验和实验⑩均预测错误的结果统计

表6 基准实验预测错误但实验⑩预测正确的结果统计
另外,对于排序实验,本文对相较于基准实验(TFIDF+FI)有明显提升的实验增加P@3 和P@8 指标对实验结果进行了评估,评估结果如图2 所示。从图中可以看出,无论n取何值,融合词汇功能的实验评价结果均优于基准实验;更重要的是,虽然所有实验的P@n都随着n的增大而降低,但是明显地,相较于基准实验,融合词汇功能实验的下降幅度更大,并且n越小,与基准实验的差距越大,各实验与基准实验在P@3 上的差距显著大于P@8,说明融合词汇功能的排序模型能将更多的关键词排到更靠前的位置,从而更高效地实现关键词抽取。
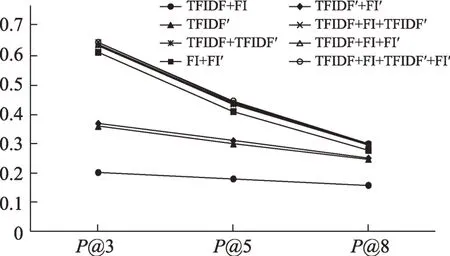
图2 P@n评价结果
表7 为基准实验和实验⑩分类结果的部分示例。从表7 可以看出,基准实验分类正确的候选词,实验⑩均分类正确,并且实验⑩能够有效地将基准实验中分类错误的候选词正确分类,在一定程度上,这说明融合词汇功能的新特征的加入并没有削弱基础特征对关键词的区分能力,反而提升了分类效果。

表7 分类抽取结果示例
由表2 可知,关键词的TFIDF 值一般更大,在文中出现的位置更靠前。在文献147 中,关键词“前景”和“背景”的TFIDF 值(0.049,0.038)都相对较小,而FI 值(0.513,0.603)相对较大,但是作为文章的“研究问题”,经过加权后,TFIDF′值(0.067,0.051)变大,FI′值(0.257,0.301)减小,使得其更容易被识别为文章的关键词;文献4942 的关键词“性能评估”也同样重新被实验⑩判断正确。从文献21 也能看出,具有“研究问题”或“研究方法”功能的词能够通过加权特征与其他相近的非关键词区别开来,如具有相似特征的关键词“误码率”(TFIDF = 0.071,FI = 0.694)和候选词“码率”(TFIDF = 0.061,FI = 0.701),其中“误码率”具有“研究方法”功能,因此其加权特征得到相应的改善,使得两者的加权特征有了明显的差异(“误码率”:TFIDF′ = 0.072,FI′ = 0.521;“码率”:TFIDF′ = 0.041,FI′ = 0.701),从 而 被 正 确分类。
从表7 数据可知,通过对“研究问题”和“研究方法”词进行加权后,其他候选词的加权特征(数据归一化后)相应地也会朝着相反方向有所改变,即词频特征变小,位置特征变大,使得上述两类关键词和其他词具有更大的距离,从而同时提高分类器对正例和负例的区分能力。但是,对于某些词频特征和位置特征较为反常的词,如文献4942 中的“新型”一词,虽然不是关键词,但FI 值很小,TFIDF 值较大,加权特征也不明显,无论是基准实验还是实验⑩都难以判断正确,这说明本文提出的融合词汇功能的关键词自动抽取方法虽然有较好的效果,但对“其他”功能的候选词的识别仍需进一步改进。
5 结 语
本文采用基于分类和基于排序的关键词抽取方法,基于领域关键词词表获取候选关键词,在基础特征中融合候选词在文献中的词汇功能,以SVM二类分类模型和学习排序模型实现学术文本的关键词自动抽取。实验结果表明,词汇功能有效地提升了关键词的抽取效果,在关键词自动抽取中具有积极的意义。
本文提出的融合词汇功能的关键词自动抽取方法具有较好的效果,但仍存在一定的缺陷:首先,词汇功能包括且不限于“研究问题”和“研究方法”,而本文仅以这两种功能增强关键词的基础特征,讨论词汇功能在关键词抽取中的作用;其次,关键词抽取具有多种模式,但本文仅验证了词汇功能对分类模型和排序模型的提升效果;最后,本文只在计算机领域的部分文献数据上进行了探究,相关结论具有一定的领域局限性。在以后的工作中,考虑将对词汇功能类别进一步细分,并基于更多的关键词抽取模式验证其效果。此外,应进一步考虑学术文献词汇功能在更多领域中的应用场景,充分利用其价值,发挥其作用。
