基于细粒度评论挖掘的书评自动摘要研究
2021-03-15章成志童甜甜周清清
章成志,童甜甜,周清清
(1. 南京理工大学信息管理系,南京 210094;2. 南京师范大学网络与新媒体系,南京 210023)
1 引 言
科学地评价图书质量和使用规律对揭示图书整体或部分的内在客观规律,更好地实现图书价值和社会功用具有重要作用[1]。图书评论作为当前图书评价的一种重要形式,反映了读者对图书质量的价值判断,对读者感知和购买抉择具有重要影响。挖掘图书评论,不仅有助于用户全面了解图书,还可作为反馈机制,为出版社提供优化营销策略的建议。一般认为,图书评论主要涉及图书内容和图书形式两个方面[1],其中,图书内容方面的评论,是对作品的思想意义、社会价值进行分析评价;图书形式方面的评论,是评析图书在装帧艺术版本和体例结构上的优劣。随着互联网的发展,图书评论规模逐步扩大,且载体形式越来越多样化,图书评论研究工作逐渐受到重视。国内外的在线平台(如亚马逊①电子商务平台,网址为https://www.amazon.com、豆瓣网②社区阅读平台,网址为https://www.douban.com等)为读者提供大量且多样化的在线图书评论。与传统的专家评论相比,在线图书评论更贴近普通读者,具有更强的互动性。传统专家评论虽更具权威性,但评论的图书覆盖率相对较低。将海量的在线评论挖掘结果以摘要的形式展现给用户,能够大幅度提升用户获取或理解信息的效率[2]。因此,为用户提供简洁的在线图书评论摘要,具有重要的研究意义和应用价值。
目前,关于评论摘要的研究主要采用基于多文档句子抽取的方法。例如,祝振媛[3]基于亚马逊的图书在线评论数据,对评论句子进行分类、摘要句子抽取,从而构建一个针对英文的多文档自动摘要框架。Sharifi 等[4]针对Twitter 文本,提出一种总结微博文档的算法,该方法首先产生单文档的摘要,再挖掘多个单文档摘要,从而生成多文档摘要,但是评论数据涉及主题广泛且包含细粒度的情感信息。现有的评论摘要研究忽视了评价实体以及针对实体的情感信息。此外,由于平台类型(电子商务型或者社区阅读型)的不同,不同的图书评论平台在评论偏向性上存在较大的差异[5]。例如,亚马逊等电商平台的图书评论包含如图书纸张、价格等方面的丰富信息,而豆瓣网则包含图书内容质量相关的信息。因此,仅依据单一平台的评论数据无法构建全面的图书评论自动摘要。本文提出基于细粒度评论挖掘的图书评论自动摘要方法,充分考虑不同平台数据的差异,兼顾各类型图书的属性特征、内在质量以及使用规律等属性,最终生成多元互补的评论摘要。
本文首先定义图书评论摘要基本要素,并对基于细粒度评论挖掘的图书评论自动摘要方法深入探讨;提出基于属性级情感分析方法来构建图书属性摘要,利用文档摘要的方法构建图书内容摘要,并通过实验以验证本文提出的图书自动摘要方法的有效性。本文的研究意义在于:一方面,定义基于细粒度评论挖掘评论摘要的基本要素,丰富评论摘要的研究方法;另一方面,将评分、评论数量等频次特征及评论文本信息结合起来,从图书属性层面分析用户对图书的情感,从而全面地评价图书,为图书评价理论提供研究思路。
2 相关研究概述
评论摘要技术对评论文本进行压缩提炼,有效地解决信息过载问题[6]。本文从评论摘要和图书评论挖掘两个方面,对相关研究进行简要概述。
2.1 评论摘要研究概述
传统的评论摘要技术,是通过对多文档句子的多种特征进行统计分析,计算句子的重要程度,再通过适当的方法选出摘要句子,从而形成评论摘要。Beineke 等[7]识别候选摘要句的位置信息、词性等特征,依据机器学习方法判断句子是否可以组成摘要结果。Khabiri 等[8]利用聚类方法识别相似评论,采用优先级的排序框架,自动抽取前K个用户评论构建评论摘要。Nishikawa 等[9]根据句子的信息量与可读性,对评论句子进行打分,选择分数高的句子作为评论摘要。Titov 等[10]利用统计模型,挖掘评论的主题信息与相关文本的片段,对相应文本片段进行打分,将分数较好的片段作为评论摘要。不同于前人的研究,Ma 等[11]着眼于构建特定主题的评论摘要,利用主题模型将评论划分为多个主题集群,依据评论的评级和长度,从主题集群中选择最具有代表性的评论作为评论摘要,从而为读者提供评论中讨论的主题信息。
评论数据一般包含一定的社会化信息,且话题多样、带有情感信息[12]。传统的评论摘要技术基本没有考虑摘要对象的情感信息。近年,评论摘要主要以实体、属性及情感信息为中心,并给出持有不同观点人的比例,也称为观点摘要。Trappey 等[13]以电影评论为研究数据,识别电影的相关特征及情感词,构建特征/情感对,从而生成电影评论观点摘要。Lu 等[14]则以电商网站的短文本评论信息为研究对象,采用属性级情感分析方法,挖掘评论评分与文本信息,从而生成属性级别的产品观点摘要。Ganesan 等[15]基于图方法发现词组,进而生成简短的产品观点摘要。Gatesan[16]提出一种与领域无关的摘要生成方法,该方法仅使用一个N-gram 模型生成词组,在评论文本上实验,结果表明该方法能够高效抽取摘要。Nguyen 等[17]结合评论和微评论文本,提出一种新型的评论摘要方法,期望得到远超两者的总和信息。
综上可知,评论摘要是一种集成式的技术。观点摘要技术能够快速地抽取图书特征与观点词,但忽视了图书的内容信息。基于内容挖掘的文档摘要方法能够弥补观点摘要在图书内容分析方面的不足,如主题挖掘方法可以获取图书在线评论中与图书内容相关的信息。
2.2 图书评论挖掘研究概述
图书评论是对图书的内容与形式进行评论,并就图书对读者的意义进行研究的一种社会评论活动[1]。图书评论作为同行评议的结果,一般发表在学术期刊中,因其包含对学术图书学术创新、学术价值的评价,一直以来都是衡量学术专著质量的指标[18]。Gorraiz 等[19]利 用Web of Science 的 图 书 专 业书评,分析并验证了图书评论数量与被引次数间的相关关系,明确指出书评能够作为BKCI(Book Ci‐tation Index)筛选学术图书的参考。
大量的在线评论数据为图书评价研究工作提供了丰富的数据资源。Kousha 等[20]以Choice 上的451篇专业书评为研究对象,分析书评星级与图书被引次数之间的关系,提出了学术图书馆的专业书评可以作为评价图书学术影响力的替代指标。Zuccala等[21]依据社会化阅读型网站Goodreads 的图书评论,发现Goodreads 的读者评分、评论数目、读者等级等多方面因素,与图书被引次数存在相关关系。Kousha 等[22]以电商网站Amazon 上的图书评论为研究对象,对比分析2739 本学术专著和1305 本畅销图书的图书评论,发现亚马逊的在线评论能反映图书的受欢迎程度,从而验证在线图书评论对图书评价具有重要意义。Zhou 等[23]采用情感分析方法,从图书属性层面,细粒度地挖掘Amazon 的图书在线评论。章成志等[5]提出一种整合不同平台的图书综合影响力评价方法,即通过对社交平台、电子商务网站等数据源图书评论的采集与整合,进行图书综合影响力的评价,实验结果表明,整合不同平台数据的评价方法能够更加全面地评价图书影响力。
综上所述,基于图书评论的挖掘研究多采用基于频次信息的计量统计,方法单一,且仅考虑单一的图书评论平台,而忽视了评论数据间的差异。
3 图书评论摘要基本框架与关键方法
本文首先对图书评论摘要的基本要素进行定义,然后给出基于细粒度评论挖掘的图书评论自动摘要的基本框架,最后描述本文涉及的相关关键技术。
3.1 图书评论摘要基本要素
本文旨在通过细粒度评论挖掘与文档自动摘要技术,依据在线图书评论,生成具有一定可读性的图书评论摘要。本文将图书评论摘要定义成三种基本要素,即图书基本信息、图书属性摘要和图书内容摘要,如表1 所示。

表1 图书评论基本要素
本文的图书属性摘要为结构化的摘要。与以往研究中的产品评论观点挖掘不同,本文更强调与图书相关的产品特征信息。图书属性摘要信息主要有两个特征:第一,是观点的基本要素,即观点评价的对象与对应的情感信息;第二,图书属性摘要信息给出对于实体和属性持有不同观点的人的数量或比例。基于图书属性摘要,用户能够很方便地看到现有用户是如何评价这本图书的,并且能够获得关于某个特定属性的量化信息。
图书内容摘要是对一本图书质量的主观见解与价值判断,其不仅能够更深刻地揭示图书的内容,还能够评析图书内容的优劣。图书内容摘要由两部分构成:图书内容信息和核心观点句。图书内容信息强调对图书内容的解读,区别于图书属性信息的结构化摘要。核心观点句则是通过一定方法筛选出的评论句。评论越处于核心地位,越是能代表大部分人的观点,影响力越大。基于图书内容摘要,用户能够获得更多关于图书内容本身的评价。
3.2 图书评论自动摘要框架图
本文给出基于细粒度评论挖掘的图书评论自动摘要框架,具体如图1 所示。图书评论摘要框架主要包括三部分:基于属性级情感分析的图书属性摘要构建、基于评论自动摘要算法的图书内容摘要构建和图书评论摘要的生成。其中,图书属性摘要部分,本文先对图书评论语料进行预处理,接着采用属性抽取与属性情感判断方法进行情感分析,从而构建观点摘要;图书内容摘要方面,本文从预处理后的图书评论中筛选出候选内容句,再利用文档自动摘要方法构建内容摘要。
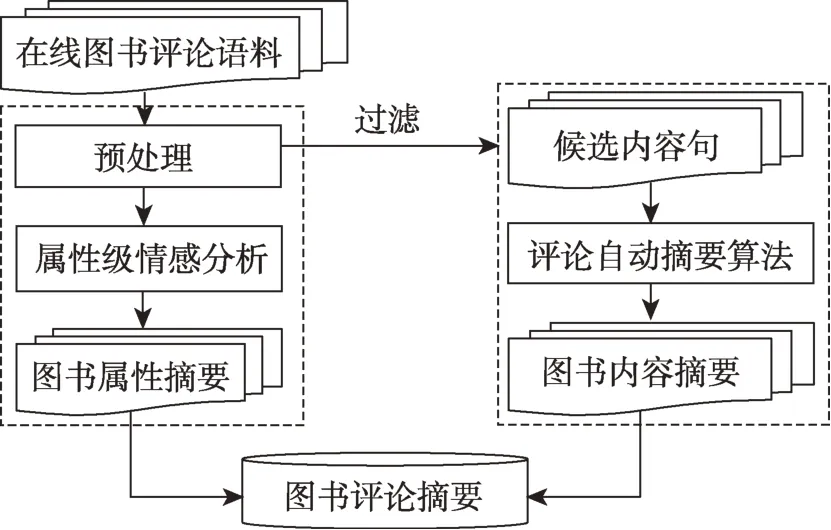
图1 基于细粒度评论挖掘的书评自动摘要框架图
3.3 关键方法
图书评论摘要的自动生成主要包括四个部分:评论数据预处理、基于属性级情感分析方法的图书属性摘要构建、基于文档摘要技术的图书内容摘要构建以及图书评论摘要生成。
3.3.1 图书评论预处理
图书评论预处理主要包括降噪处理、词性标注以及依存句法分析等步骤。在线评论包含大量的噪声,如HTML 标签符号、表情符号等,一定程度上会影响后续文本挖掘的准确率,因此在预处理阶段需要对评论数据进行降噪处理。具体而言,首先,观察并统计语料中出现的特殊符号,人工构建停用符号表;其次,基于停用符号表,利用正则表达式过滤特殊符号。在词性标注以及依存句法分析阶段,利用Standford Parser①句法分析工具,网址为http://projects.csail.mit.edu/spatial/Stanford_Parser工具,提取句子中的名词、句子主干以及词性依存。Stanford Parser 以宾州树库作为分析器的训练数据,可以找出句子中词语间的依存信息,并支持以有向图、树多种形式输出。
3.3.2 图书属性摘要构建方法
本文提出利用属性级情感分析方法对图书评论进行细粒度的挖掘,识别图书的相关特征与情感关键词,从而构建图书属性摘要。属性级情感分析包括两个子任务:属性抽取和属性情感判断。其中,属性抽取是从在线评论中抽取用户评价对象,如内容、纸张、价格等;属性情感判断主要是判断用户对某一属性所持的观点倾向性。
在属性抽取部分,为全面、高效地挖掘在线图书评论中用户关注的属性,本文采取基于深度学习的属性抽取方法[24],该方法包括三个步骤:候选属性抽取、候选属性聚类和属性确定。首先,从评论数据中抽取高频名词作为候选属性词;其次,依据word2vec[25]对候选属性词进行词向量表示,利用近邻传播聚类(affinity propagation,AP)方法[26]对候选属性词进行聚类;最后,人工过滤聚类后的候选属性词集中的非属性类簇,以及每一类属性类簇中的非属性词,从而获得图书属性词集。
在属性情感判断部分[24],本文利用情感词典,结合相关语义规则,对产品评论内容进行属性层面的情感分析。本文采用SentiWordNet②英文情感字典,网址为https://sentiwordnet.isti.cnr.it/情感词典,依据距离属性词最近情感词的情感值,计算评论属性的情感值。
本文利用属性关注度与属性满意度指标构建图书的属性摘要,从而生成结构化的属性摘要。其中,属性关注度是用户对该属性的关注程度;属性满意度则是用户对图书该属性的满意程度[5],具体如表2 所示。

表2 属性关注度和属性满意度定义
3.3.3 图书内容自动摘要方法
图书内容摘要主要包含两部分:图书内容信息和核心观点句。图书内容信息的抽取可通过文档自动摘要技术实现。文档自动摘要技术需要处理的冗余信息更多,需要去除冗余信息,将其余信息进行有机的融合,最终呈现给用户简洁、全面的图书评论摘要。
本文提出利用图书属性词集,依据句子中是否出现非内容属性词为依据,将所有评论数据划分为内容句和非内容句;以非内容句为数据源,依据TextRank 抽取评论句,最终生成图书内容摘要。TextRank 算法综合考虑文本整体的信息来选择词语或者句子,以更好的表达文本,是文档摘要技术中被广泛应用的句子抽取式算法[27]。该方法首先把文本分割成若干单元并建立图模型,然后利用投票机制对文本中的重要句子进行排序,最终实现文摘自动提取。
核心观点句是对图书内容信息的补充扩展,包含用户对图书内容方面的情感信息。核心观点句可通过信息计量指标筛选,如评论有用性、点赞人数等。本文以评论句中的内容句为研究数据,结合前文属性情感分析的结果,将内容句划分为正面评论和负面评论;依据评论有用性指标为句子打分,按照分值排序,分别抽取前两句,若不足两句则全部保留,从而筛选出核心观点句。
3.3.4 图书评论摘要生成
本文综合图书属性摘要与内容摘要得到最终的图书评论摘要。首先,通过属性级情感分析获取图书的属性词集。其次,通过对在线评论的多粒度情感分析,获得用户的整体的情感倾向,以及对各个属性的关注度、满意度,构建图书属性摘要。最后,通过图书属性词集将图书评论分为内容句与非内容句,以源数据中的内容句为对象,进行文档自动摘要,通过评论有用性等计量指标获取图书内容信息中的核心观点句,从而构建图书内容摘要。
4 实验与结果分析
本文以亚马逊、Goodreads 和Choice 网的评论数据为数据源。首先,通过文本预处理对评论数据进行数据清洗;其次,采用属性级情感分析方法,构建图书属性词集,并生成图书评论属性摘要;再次,根据属性词集,本文将评论数据划分为内容句和非内容句,利用TextRank 模型构建评论内容摘要;最后,本文生成图书评论摘要,并依据深度、广度指标对摘要进行评估。
4.1 实验语料
数据来源是分别从电商网站(Amazon①www.amazon.com)、社交媒体网站(Goodreads②www.goodreads.com)和专业评论网站(Choice③www.choice.com)收集的图书评论。Choice 作为学院和研究图书馆协会(Association of College and Research Libraries)的出版单位,每月出版500~600 篇专业评论,在美国已被多数学术图书馆作为购买图书的参考[28]。Ama‐zon 是目前全球领先的电子商务平台,不仅提供丰富的图书,而且设有提供图书评分、评论功能,具有较强的代表性。Goodreads 是目前全球著名图书社区网站,存在较为丰富的用户数据,且评论对象通常针对图书内容本身,故评论具有重要的决策参考价值[29]。相较于其他图书门户网站,这些平台的图书评论较易获取,且图书种类齐全。因此,本文首先通过爬虫从Choice 平台获取4 个学科69263 本图书的元数据,接着采集图书在Choice、Amazon和Goodreads 的图书在线评论。本文通过人工过滤,仅保留在各个平台均有评论信息的图书,最终得到3639 本图书在3 个平台的在线评论数据,数据样例如表3 所示。
4.2 评价方法
周清清[30]认为主题能够反映图书评论中的隐含信息,利用主题数与主题分布度量图书的深度与广度。本文参考该方法,利用LDA (latent Dirichlet allocation)模型识别图书评论摘要中的主题数,从深度和广度的角度,对本文的图书内容摘要与专业评论Choice 中的内容句进行比较分析。摘要的深度值计算方式为
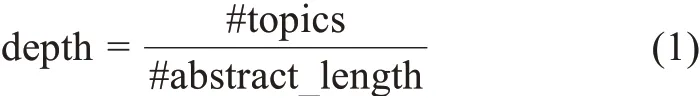
其中,depth 为摘要的深度值;#topics 是摘要中涉及的主题数;#abstract_length 为摘要长度。
摘要的广度值计算方式为

表3 图书的在线评论数据样例(以图书Culture为例)

其中,width 为图书的广度值;e_topics 是图书主题分布的信息熵;v_topici是图书属于第i主题的概率;N是主题数。
4.3 实验结果分析
本文依据在线图书评论中的内容句构建图书内容摘要,通过比较Choice 评论中的内容句(专家评论)与图书内容摘要的深度/广度值,评估本文方法效果。
4.3.1 图书评论属性摘要生成
为构建图书属性摘要,首先需要抽取图书评论属性词。本文参考周清清等[24]的方法,即以高频名词构建候选属性词,然后通过词向量表示方法构建候选属性词向量;在此基础上完成候选属性的聚类,得到聚类后的候选属性词集;结合人工过滤的方法从图书评论中抽取图书属性词,最终得到7 种属性词,部分属性词集结果如表4 所示,全部属性集如附表所示。

表4 图书属性词样例
为评估属性抽取效果,将本文使用的方法与现有的属性抽取方法进行对比,即基于LDA 的属性抽取方法[31]。表5 给出基于LDA 的属性抽取方法与本文使用方法的属性抽取结果。
总体而言,两种方法的抽取结果存在较大差异,基于LDA 的方法在属性数量层面远小于基于本文使用的方法。基于LDA 的方法仅能抽取出6 种属性词,而本文使用的方法能够抽取出7 种属性词。并且,对于每一个属性,本文使用的方法能够抽取出更多、更细粒度的属性。图书的内容属性和插图属性抽取结果如表6 所示。本文使用的方法能发现更多细粒度的属性词;而基于LDA 的属性抽取方法仅能挖掘少量图书属性,无法对同义属性进行聚类,进而无法保证已挖掘图书属性的全面性。例如,图书的内容属性,基于的LDA 方法仅能发现“content”“viewpoint”等少数属性,而本文使用的方法发现了48 个内容属性。通过以上分析可知,LDA 方法可以抽取属性,但是依赖人工拣选,并且最终属性抽取数量较少,无法聚集其他相关属性;本文使用的方法能发现更多细粒度的属性,并且简单、高效。

表5 两种方法属性抽取结果对比

表6 两种方法挖掘的属性集示例
通过上文的属性抽取和属性情感倾向分析工作,本文利用属性关注度指标以及属性满意度指标构建图书的观点摘要,最终形成图书属性信息。表7给出图书属性值计算结果样例,该图书共有7 个属性,用户对7 个属性的满意度均较高,其中关注度最低为0.66、最高为0.92,差别较大。具体而言,用户对该图书内容属性的关注度最高(0.92),而对图书版本属性关注度最低(0.64)。在属性满意度层面,用户对图书的适用人群属性满意度最高(0.92),而对图书外观属性的满意度最低(0.87)。这说明用户对图书不同属性的关注度、满意度存在较大差异。
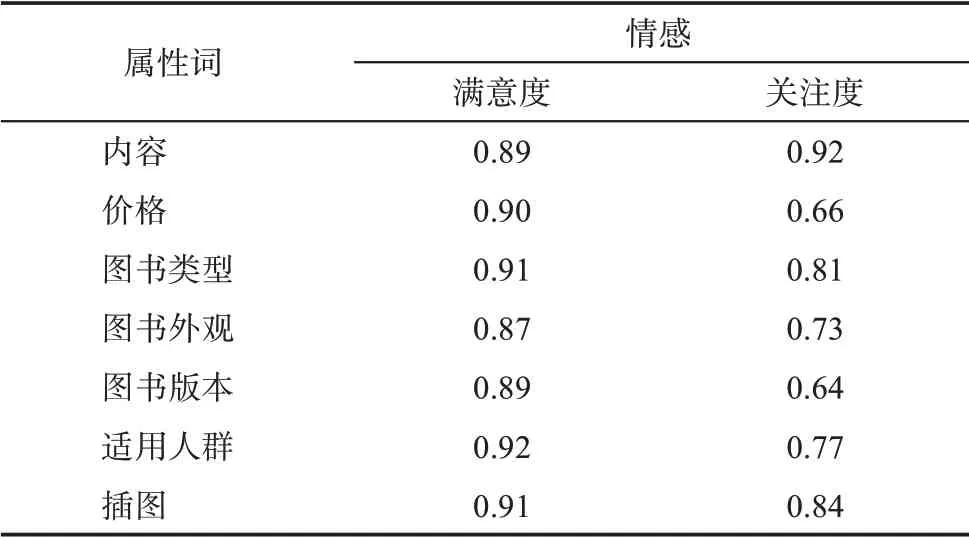
表7 图书属性值计算结果样例(以图书The Louvre:All the Paintings为例)
最终,本文将图书属性的结构化信息转化为可读性较强的属性摘要。表8 为图书属性值计算结果样例,包含四个方面:图书ISBN 标识、图书标题名、图书所属学科和图书属性摘要。图书属性摘要包含三个维度信息:首先,图书的总体评分信息,如“多数用户对此书持有好评”;其次,提供获得较高关注度的图书属性信息;最后,提供图书属性满意度较高的某些属性信息,如图书内容属性、图书价格属性。
4.3.2 图书评论内容摘要生成
以图书在线评论中的内容句为实验数据,本研究利用TextRank 算法自动抽取图书内容句,从而构建图书内容信息,通过比较Choice 评论中的内容句(专家评论)和图书内容摘要(本研究的研究成果)的深度/广度值,评估本研究方案的实验结果。在采用TextRank 自动生成一本书摘要时,本研究设置摘要长度与Choice 的内容句长度保持一致。对于核心观点句的筛选,本研究对评论内容句按照评论有用性指标进行排序,选取排名前两句。最终,结合图书评论属性摘要与内容摘要,得到图书评论摘要,图书评论摘要样例如表8 所示。
4.3.3 图书评论摘要生成
通过上述步骤,本文最终得到图书评论摘要。如表8 所示,以图书The Louvre: All the Paintings为例,该图书评论摘要包括三个部分:图书基本信息、图书属性摘要和图书内容摘要。其中,图书内容摘要的结果分成两个部分:图书内容信息和核心观点句。核心观点句从正面评论、负面评论的角度对图书内容信息进行补充,细粒度揭示图书内容。

表8 图书评论摘要样例(以图书The Louvre:All the Paintings为例)
从表8 可看出,图书The Louvre:All the Paintings属于Arts & Photography 类别。图书属性摘要包含:图书的总体评分信息,如“多数用户对此书持有好评”;较高关注度或满意度的图书属性信息,如图书价格属性。图书内容信息方面,主要描述图书是一本艺术品集,包含人类历史上许多伟大的艺术作品,该图书的3022 幅绘画均注明绘画者姓名、日期、艺术家出生和死亡日期,以及在卢浮宫的详细信息。核心观点句方面,主要描述读者对图书内容的观点信息,如读者认为这本书是一个宏伟而美丽的收藏品,汇集整个卢浮宫收藏品,这是一件了不起的成就;对于普通读者来说,附在画上的描述内容丰富,并且包含人类历史上一些最伟大的艺术作品;同时,也有读者认为,这本书中的图片都非常小,无法完美呈现卢浮宫的作品。由以上分析可知,本文的图书评论摘要能够从多维度、细粒度地反映图书信息。
4.3.4 图书评论摘要评估结果
为比较图书摘要的效果,本文以Choice 的内容句为对照组,分别从深度与广度指标来比较两种图书内容摘要方法。困惑度可用于度量概率模型预测样本的性能优劣[32]。为了得到最佳的主题建模结果,本文利用困惑度来比较主题建模的结果,计算不同主题数(N= 5,10,15,20,25,30,35,40,45,50)对应的困惑度[31]。计算方法为
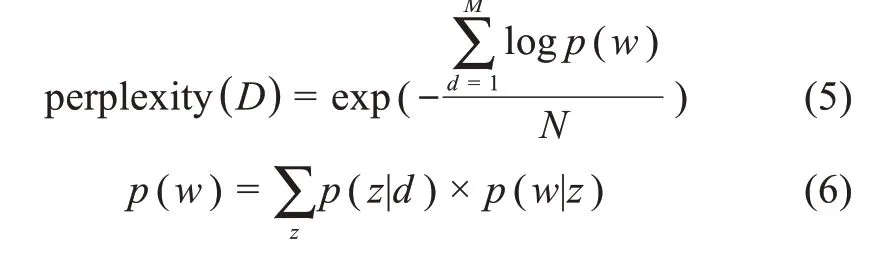
其中,M为数据集D中文本的数量;N为数据集D中的单词数;p(w)为每个单词的概率;p(z|d)为文本中每个主题的概率;p(w|z)表示主题中每个单词的概率;z为训练得到的主题;z表示数据集中的文本。越低的困惑度表示更好的建模结果。当主题数为30 时,困惑度最低,主题建模效果最优。因此,本文将主题数设定为30。
基于Choice 内容句的图书内容摘要(简称为“基于Choice 的图书内容摘要”)与基于本文内容方法的内容摘要的评价指标,如表9 所示。
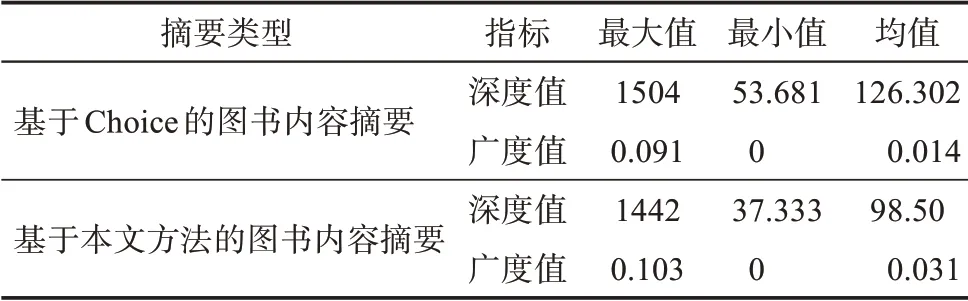
表9 图书内容摘要评价指标对比
从表9 可知,基于Choice 的图书内容摘要,其深度值与广度值的均值分别为126.302、0.014,广度值远小于深度值;基于本文方法的图书内容摘要,其深度值与广度值的均值分别为98.50、0.031,广度值也远小于深度值,最大值为0.103。对比两种方法的指标可以看出,本研究产生的内容摘要,其平均广度值高于基于Choice 的图书内容摘要的平均广度值;在深度值指标层面,本文的摘要平均深度值低于Choice 的图书内容摘要的平均深度值。研究结果表明:基于本文方法的图书评论摘要,在深度上目前还不能达到基于Choice 的内容摘要,但基于本文方法的内容摘要能够提供更多关于图书不同主题的信息。需要指出的是,本文方法仅借助多个图书评论平台,在得到更加全面的内容摘要的同时,提供关于图书的核心观点句,从而为辅助读者快速了解图书内容信息。

表10 两种图书内容摘要结果对比(以图书The Louvre:All the Paintings为例)
为了进一步分析两种摘要的差异,本研究以图书The Louvre: All the Paintings为例,从深度广度的角度评估本文实验结果,表10 为该图书两种摘要的深度值、广度值和图书内容摘要。由表10 可知,基于Choice 的图书内容摘要的深度值高于本文方法的深度值,而其广度值低于本文方法的广度值;基于Choice 的图书内容摘要从图书作者、图书成果层面进行了概括,而基于本文方法的评论摘要则提供更细粒度的信息。结合两种类型摘要的内容来看,基于本文方法的图书内容摘要包含更细粒度的内容信息,如图书主人公、故事情节等。
5 结论与展望
针对网络上存在的大量产品评论信息,本文提出一种基于细粒度评论挖掘的书评摘要模型,并探讨评论摘要的生成方法。本文利用属性级情感分析的文本挖掘方法来构建图书属性摘要;采用基于图算法的文档自动摘要技术,依据评论句的重要性排序,选择一定数量的句子作为图书内容摘要。本文利用图书评论有用性等指标,从在线评论中抽取出核心观点句,与前两部分结合,最终形成图书评论摘要。实证结果表明,本文提出的方法较优,生成的评论摘要具有较好的可读性,并且能够提供细粒度、多维度的图书评价信息。
下一步工作主要包括三个方面。首先,本研究目前只考虑了一种文档摘要方法,在下一步工作中将考虑按照评论文本的主题信息,挖掘更多潜在候选摘要句,从而丰富图书内容文摘的主题信息;其次,未来研究将以中文图书为例,进一步验证本文所提出方法的适用性,此外,后续研究中将进一步引入评论质量评估方法,对在线图书评论的质量进行度量,过滤低质量评论,从而在此基础上生成质量更高的图书评论摘要;最后,未来将进一步扩展研究对象(如电影评论),并考虑结合实际应用场景(如在图书或电影推荐中)进行自动摘要的有效性评估。

附表 图书属性词集
