基于多粒子群协同的城轨列车速度曲线多目标优化
2021-03-13杨飞凤涂永超吴仕勋
徐 凯,杨飞凤,涂永超,吴仕勋
(1. 重庆交通大学 信息科学与工程学院,重庆 400074;2. 重庆市公共交通运营大数据工程技术研究中心,重庆 400074)
列车自动驾驶ATO是城市轨道列车控制系统的重要组成。在列车运行过程中,ATO由已知信息进行优化调整,得到最优控制策略,给出控制力让列车按照最优驾驶曲线运行[1]。目前对于ATO控制策略的优化,国内外主要采用的方法有粒子群算法PSO,遗传算法GA和差分进化DE等智能算法[2-4]。
文献[5]在求解列车自动驾驶速度曲线时, 采用改进后的粒子群算法,将多目标优化向单目标转化,用加权求和的形式得到目标函数。上述传统的加权方法忽略了各目标间的相互影响,没有考虑他们之间的复杂关系,无法体现多目标优化的本质。为充分体现多目标研究的实质,通常采用Pareto原理来求解此类问题。而目前文献基于Pareto原理优化时,往往只考虑两目标问题,例如文献[6]将时间和能耗作为两个优化目标,混合了差分和模拟退火两种进化算法进行求解;文献[7]对比了两种多目标优化算法MOPSO和NSGA_II,并验证了在计算时间、可行解的多样性以及Pareto前沿解的逼近程度等性能指标,MOPSO表现更佳,但却未提及对MOPSO算法的深入改进。此外,为了保证行车安全和效率,城轨列车运行控制还有精准停车这一重要目标,即停车误差不能超过30 cm。文献[8]基于Pareto原理,采用MOPSO算法优化了能耗、时间以及停车误差这三个目标,却没有评价算法的性能指标,特别是对算法收敛性能的改进。
此外,不同运行模式对列车能耗影响的研究相对较少[9]。文献[10]在列车两种不同的运行模式下,应用非现代智能算法,即时间逼近搜索这一传统数学方法来求解问题。现有参考文献在研究中,未同时结合列车多种运行工况序列和多目标优化,也未考虑各类工况序列对解集的影响以及各种模态下的性能指标评价等问题,这让研究的复杂度及难度大大降低。
综上,本文首先基于Pareto原理,以时间、能耗和停车精度为目标,再加以对列车运行中不同典型工况序列的分析,并结合列车运行多模态和多目标优化问题,提出一种协同进化的多目标混沌粒子群算法(Co-evolution Based Multi-objective Chaotic Particle Swarm Optimization,CMOCPSO)。经仿真试验验证,相较于MOPSO,本文算法在多样性、收敛性指标方面得到了进一步改善。最后,为了获取各类典型工况序列下最优的列车自动驾驶速度曲线,用模糊隶属度法进行了筛选。
1 列车运行多目标优化模型
考虑到列车运行的复杂性,对其运动建模简化为单质点,根据牛顿第二定律得到
ma=f(v,u)-g(v)-w(v,s)
(1)
式中:m为列车的质量;a为列车运行加速度;f(v,u)为列车运行时所受牵引力或制动力;g(v)、w(v,s)分别为列车运行时所受的基本阻力和附加阻力;v、u、s分别为列车运行速度、操控工况和线路位置。对于本文所提的牵引、制动、惰行及巡航4种列车运行工况,当f(v,u)大于0时,列车为牵引或巡航状态;当f(v,u)等于0时,列车为惰行状态,当f(v,u)小于0时,列车为制动状态。
本文用时间作为迭代步长,列车运行位置及速度表达如下
(2)
si+1=si+Δs
(3)
式(2)、式(3)是计算列车行驶位置的迭代公式,si表示第i次迭代后的位置,ai由式(1)中a离散处理得到,s0=0,Δt=0.1 s。
Δv=vi+aiΔt
(4)
vi+1=vi+Δv
(5)
式(4)和式(5)表示在第i次迭代时列车速度vi的计算公式,v0=0,Δt=0.1 s。
在满足安全等各种约束条件下,求解列车能耗、运行时间以及停车精度三个目标的计算模型如下。
站间运行时间为
T′=∑Δt
(6)
站间能耗指标[4]为
(7)
式中:E为能耗适应度;F为牵引力;v为列车运行速度;ξM为在牵引力作用下由电能转为机械能的变换因子;A为辅助功率;T0为列车在站点间的实际运行时间;ξB为在制动力作用下,由机械能转为电能的变换因子;B为制动力。
停车精度计算公式为
S′=∑Δs
(8)
D=|S′-S|
(9)
式中:D为停车精度;S′为列车在站间的实际运行距离;S为站间实际长度。
基于上述式(1)~式(5)建立的模型,列车运行多目标优化问题旨在求解得到一系列的工况转换点{xi},i=1, 2,…,m(xi∈ [ 0,S]),使得在式(11)的限制条件下,列车减少运行时间、降低能耗和提高停车精度。综上,列车运行多目标优化问题表述为
min{T0,E,D}
(10)
约束条件为
(11)
式中:v0、ve分别为列车行驶初速度与末速度;vi为第i次迭代时列车实际的运行速度;vlim为对应的列车限速值;T′为列车实际运行时间;T0为计划运行时间,s;S′为列车实际运行距离;S为站点间距,cm。
牵引(T)、制动(B)、惰行(C)和巡航(H)为列车运行中的四种工况,ATO将上述工况合理组合成多种工况序列。城轨交通不同于干线铁路之处在于,站间距离相对较短,由于受限于线路长度,列车在站间行驶时工况转换点不宜过多。原则上要求两个工况转换点距离不能过近,因为频繁切换工况易造成不必要的损耗。此外,还应删去列车在运行中有“制动”的操纵,例如“T-C-B-T-C-B”这种明显费时又耗能的工况序列。
据此,去除那些违背工况转换原则、既费时又耗能以及让乘客不舒适的一系列操控序列,最终选出下述6种典型且可行的工况序列进行研究:①T-H-C-B;②T-C-H-C-B;③T-C-T-C-B;④T-H-T-C-B;⑤T-C-H-T-C-B;⑥T-C-T-C-T-C-B。
图1是上述①~⑥6种工况序列下,采用本文所提出的算法求解得到的边沿解和最优解空间的分布效果图,图1中的一个解即为一种列车自动驾驶方案。
由图1可看出,6种工况序列对应的解的分布大不相同,此外不同工况序列的最优解也有所差异。这说明研究多种工况序列能够改善算法解的质量,优化解的分布性和多样性。
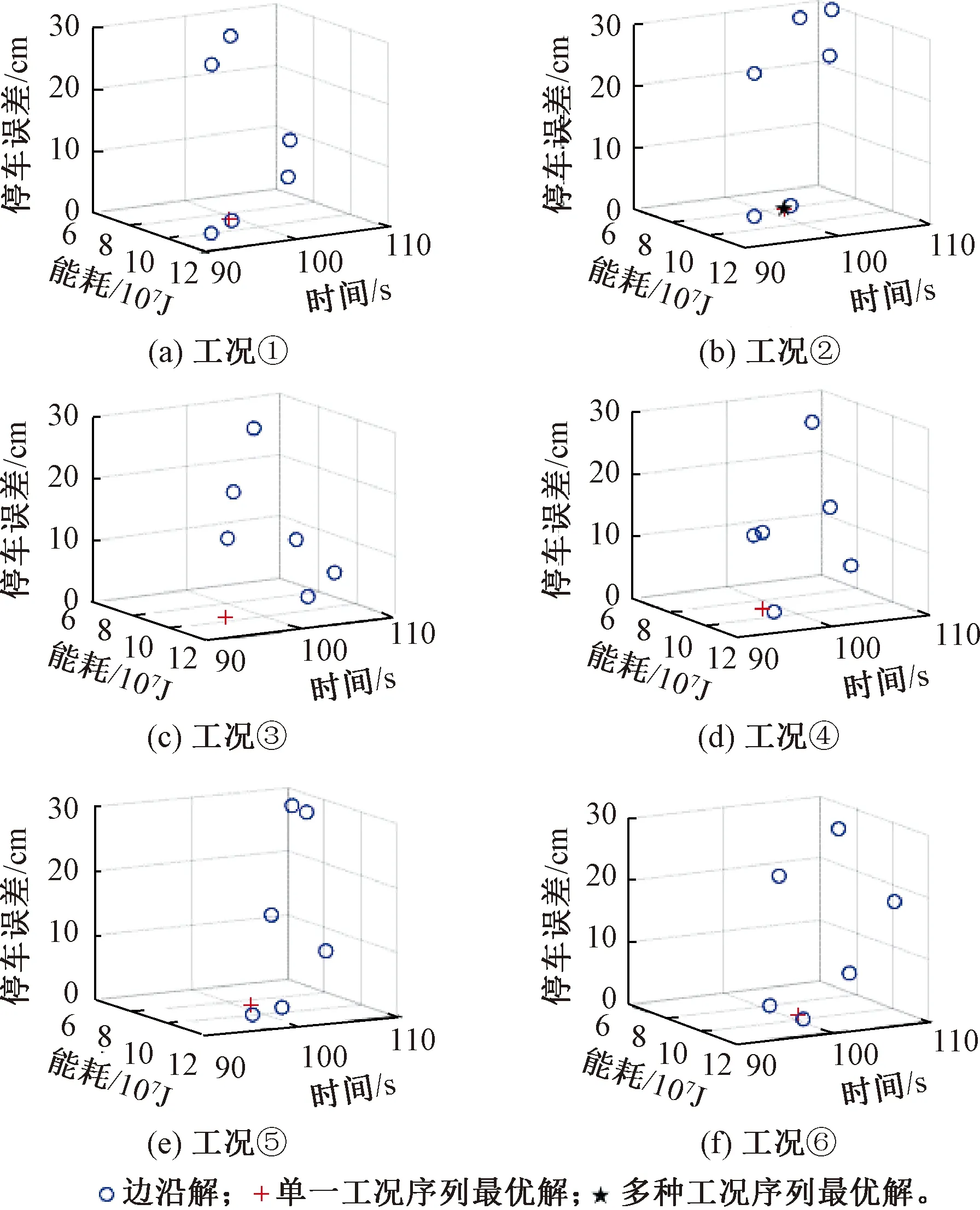
图1 6种典型工况序列下边沿解及最优解空间分布
2 基于协同进化的多目标混沌粒子群算法
2.1 CMOCPSO算法框架和思想
图2是本文所提出的CMOCPSO算法框架,图2中清晰地展示了所提算法的特点,采用全局和局部两层结构实现并行搜索,各层内协同演化,引入双外部档案进行层间的信息交流,具体为:
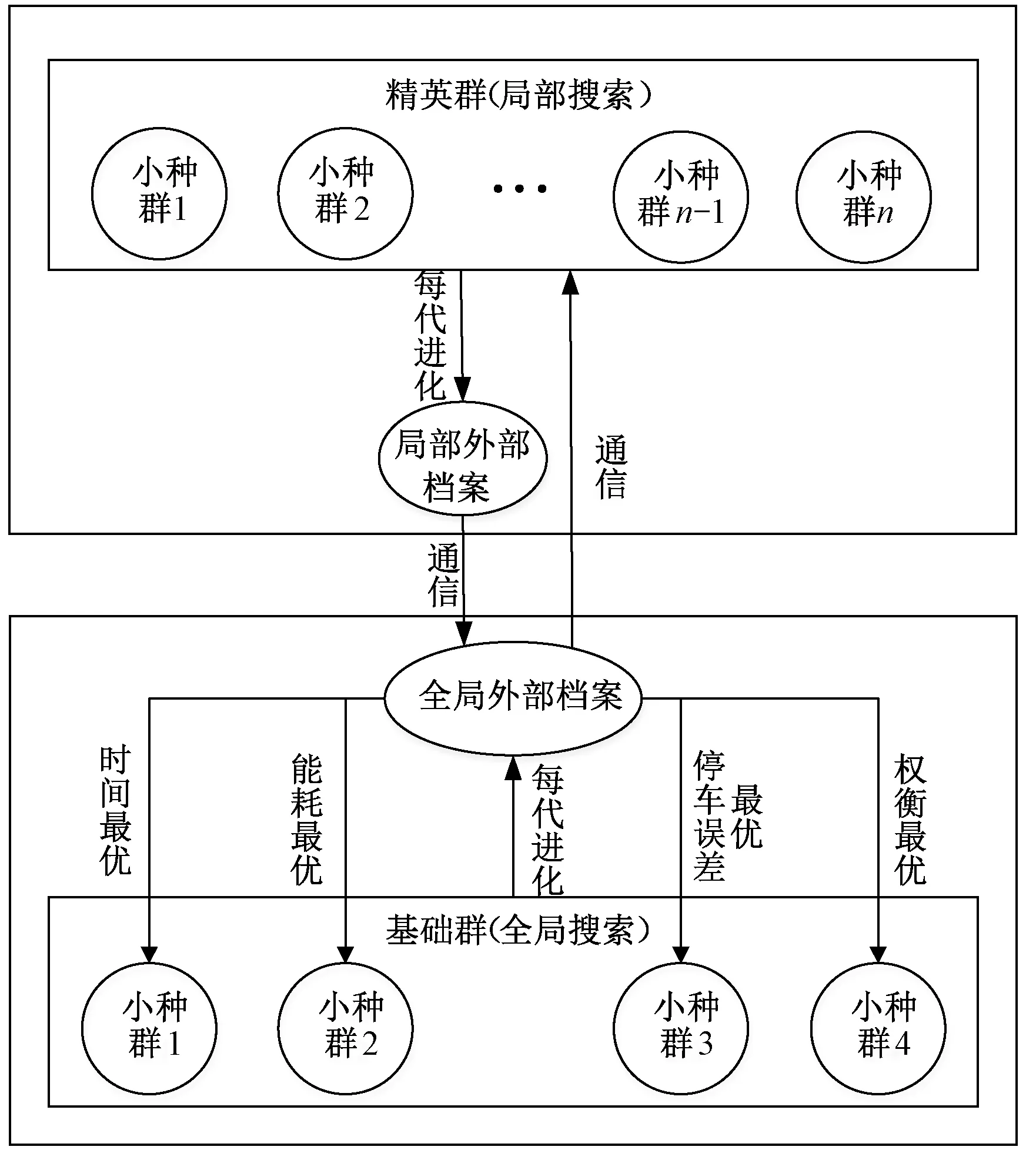
图2 算法的总体框架
Step1分层设计。在图2中分层结构用上下两个虚线框标出。全局外部档案与基础群共同构成下层,其中基础群的小种群有4个,协同演化,完成全局寻优;而局部外部档案与精英群共同构成上层结构,其中精英群用于局部精细搜索,由n个小种群组成,协同演化深入挖掘出更多优质解。
Step2引入双外部档案,完善各层结构。在下层中,全局外部档案接收基础群中4个小种群每次迭代后的可行解,并通过Pareto支配获取前沿解。再从前沿解的解集里选取时间、能耗、停车误差及权衡最优的4个粒子,并分别返送回与之对应的基础群小种群中;与下层有所不同,上层精英群中n个小种群每进化一次,局部外部档案就接收其产生的可行解,由支配关系判断后得到Pareto前沿解即可。
Step3上下层之间以T为周期实现信息交互,加速搜索过程。每间隔T次迭代,在下层的全局外部档案解集中选出n个精英解,经过扰动处理产生与之对应的n个新精英小种群,共同实现局部搜索,使得精英解周围潜在的优质解得以充分挖掘;并且,在本次交互周期里,下层全局外部档案将接收上层局部外部档案获得的Pareto前沿解。
2.2 混沌粒子群算法
粒子群优化PSO算法为一种并行随机的启发式搜索方法,其粒子的移动速度和位置的计算模型为
(12)
(13)
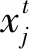
混沌具有良好的遍历性,可以帮助算法快速跳出局部最优。结合搜索速度快且能力强的PSO,便能相互取长补短,即形成全新的混沌粒子群算法CPSO。此处选用典型混沌系统Logistic方程
L_r1(j+1)=μL_r1(j)[1-L_r1(j)]
(14)
L_r2(j+1)=μL_r2(j)[1-L_r2(j)]
(15)
式中:j为粒子序数;μ为控制参数,0≤μ≤4;当μ=4且0≤L_rk(1) ≤1(k=1,2)时,系统为完全混沌状态。用L_r1(j)和L_r2(j)替换式(12)中的r1和r2,发挥混沌在算法中的遍历性,既可以避免粒子陷入局部最优,又能使算法快速搜索到全局最优解。
2.3 基础群的进化策略
在进行全局搜索时,多目标优化有别于单目标优化,它引入一个全局外部档案。所以,式(12)和式(13)不再适用于本文所提算法,需对其进行修正,从而得到新的粒子速度及位置更新公式为
(16)
(17)
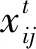
策略1(常规法):把基础群均匀分成4个小种群,从全局外部档案中随机选取4个Pareto前沿解作为4个小种群对应的gBest′。
策略2(目标引导法):基于待优化的3个目标,可以把基础群划分为4个小种群,其中前3个小种群的进化具有指向性,其各自对应的gBest′从全局外部档案中时间、能耗及停车精度极端最优粒子中选出,分别用以优化时间、能耗及停车精度这3个指标。这种方式使得各个目标的边沿最优解得到最大限度挖掘。而第4个小种群则用于3个目标的综合权衡寻优,从全局外部档案Pareto前沿解集中随机选取一个作为其对应的gBest′,称为权衡最优粒子。
策略2采用一个小种群与一个目标优化相对应的方法,使得各目标上的边缘最优信息得到更大程度地挖掘,而所有目标的综合优化由剩余的第4个小种群负责,让可行解的分布更加均匀。在此策略下,基础群形成了一个全方位、高效协同的搜索粒子群体。本文后续试验中验证了该策略的优越性。
2.4 精英群的进化策略及其实现
上下两层之间进行通信,一旦通信周期到来,从下层全局外部档案的Pareto前沿解集中获取n个精英解,将它们送入上层的精英群,并对其进行扰动,产生n个相对应的精英小种群。其中每一个小种群有m个粒子,用来搜寻这n个精英解周围更多潜在的优势解。精英小种群生成公式为
Xi1=l_besti
(18)
Xij=l_besti+λrand()
(19)
式中:Xij为精英群的第i个小种群中的第j个粒子;l_besti为第i个小种群扰动所用粒子;λ为精英群约束步长的最大值;rand()为-1到1之间的随机数。
需要说明的是,为了实现更为精细的搜索,精英群的搜索步长一般要小于基础群,将其限制在一个较小的范围内。
2.5 算法流程图
基于策略2的CMOCPSO算法的流程见图3。
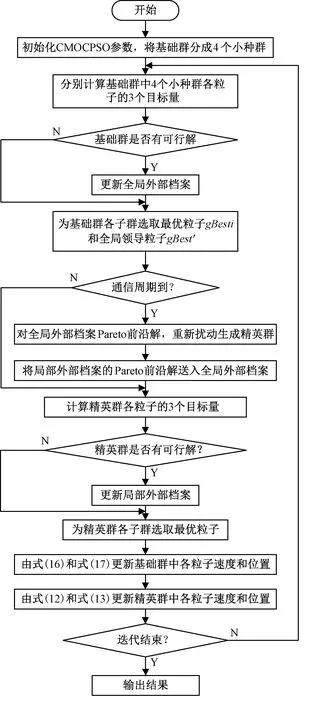
图3 基于策略2的CMOCPSO算法流程
3 仿真试验及分析
3.1 仿真参数设置
(1)线路及列车相关参数。本文仿真试验选用重庆轻轨六号线某一区间段。在该区段上,站间限制速度为80 km/h,站内限制速度为60 km/h,线路区间长1 620 m;列车在行驶中影响基本阻力的因素较多且复杂,在实际应用中用理论公式难以表述,可由大量试验综合得到的经验公式来计算[11],这里的基本阻力公式及列车参数的选用参考了文献[12]。列车全长120 m,4节动车车厢,2节拖车车厢,动车质量35 t/节,拖车质量34 t/节;列车区段的目标运行时间为90~110 s。
(2)算法参数设置:CMOCPSO算法中基础群有4个小种群,每个小种群有50个粒子。精英群中小种群个数为4,每个小种群粒子数为10,共40个粒子,学习因子c1、c2和c3取值均为2,惯性权重因子w取值为1,最大进化代数为100;MOPSO粒子总数为100,最大进化代数为200。这两种算法函数评价次数均为20 000次。
(3)通信周期T设置:在上述图2中,通信周期是指上下两层进行双向信息交互时所需经历的进化代数T。参数T的设置在很大程度上影响Pareto前沿解集的分布,若该值过大,就意味着通信次数过少,容易使精英群长期滞留于某些局部搜索区域,很难跨区域实现更精细的寻优,最终会导致整个解集的分布不均匀;若该值过小,表示两层间交互过于频繁,这将导致精英群搜索效率低,不能深入挖掘可行解。
图4采用T-H-C-B工况序列。基于本文算法,在三种交互周期T=5、10和20下可得对应解空间分布的对比图。对于不同通信周期T下的解空间,图4中以3种符号分别表示。由图4可知,相较于T=5或T=20,当T=10时,在能耗和时间指标上有明显优势,这也证明了试验结果与前述分析吻合,因此在后续试验中通信周期T取10。

图4 不同通信周期下的解空间分布图
3.2 算法性能评价指标
为了验证本文算法的优越性,还须先明确下列几个指标,用以度量算法的收敛性和多样性。
(1)收敛性指标GD及γ
(20)
式中:n为算法所获Pareto前沿解的个数;di为第i个解与真实Pareto前端的最小距离。
(21)
式中:G={g1,g2,…,g|G|}为算法获得的Pareto前沿解集;r*={r1,r2,…,r|r*|}是真实的Pareto前沿解集。
上述指标GD及γ的值越小,则算法有更好的收敛性。
(2)多样性指标SP、Δ分别为
(22)
(23)
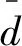
上述指标SP及Δ的值越小,表示解集分布越均匀。
3.3 试验结果及分析
本文将两种不同策略和两种不同算法分别独立运行,其次数均为20,并从以上收敛性、多样性指标和Pareto前沿解个数等多个角度出发,对试验结果进行统计分析,对比两种不同策略及算法的优劣。
3.3.1 CMOCPSO算法策略的选取
对比2.3节中提到的两种策略,即常规法和目标引导法,其相关指标统计结果如表1所示。

表1 两种不同策略下的算法性能评价指标对比
由表1可知,在算法的收敛性、多样性以及Pareto前沿解的个数等方面,目标引导法都优于常规法。因此,在后续试验中,CMOCPSO算法采用策略2,用目标引导法选取全局领导粒子,并将其与MOPSO算法从多方面比较分析。
3.3.2 两种算法下的收敛性和多样性分析对比
采用多目标粒子群MOPSO和本文所提出的CMOPSO算法进行仿真试验对比,其统计结果如表2所示。

表2 两种不同算法的性能评价指标统计
表2比较了Pareto前沿解的收敛性、多样性以及数量这三个方面的指标。从表2中可知,除了多样性SP的均方差这一项指标上CMOCPSO与MOPSO两者持平,在剩余的各个指标上,CMOCPSO算法都具有明显的优势。进一步分析各项指标平均值,可知CMOCPSO不仅能加快算法收敛速度,而且还能提高可行解的多样性,较大程度增加了解的个数。
上述两种算法在Pareto解空间与前沿解的分布情况见图5和图6。
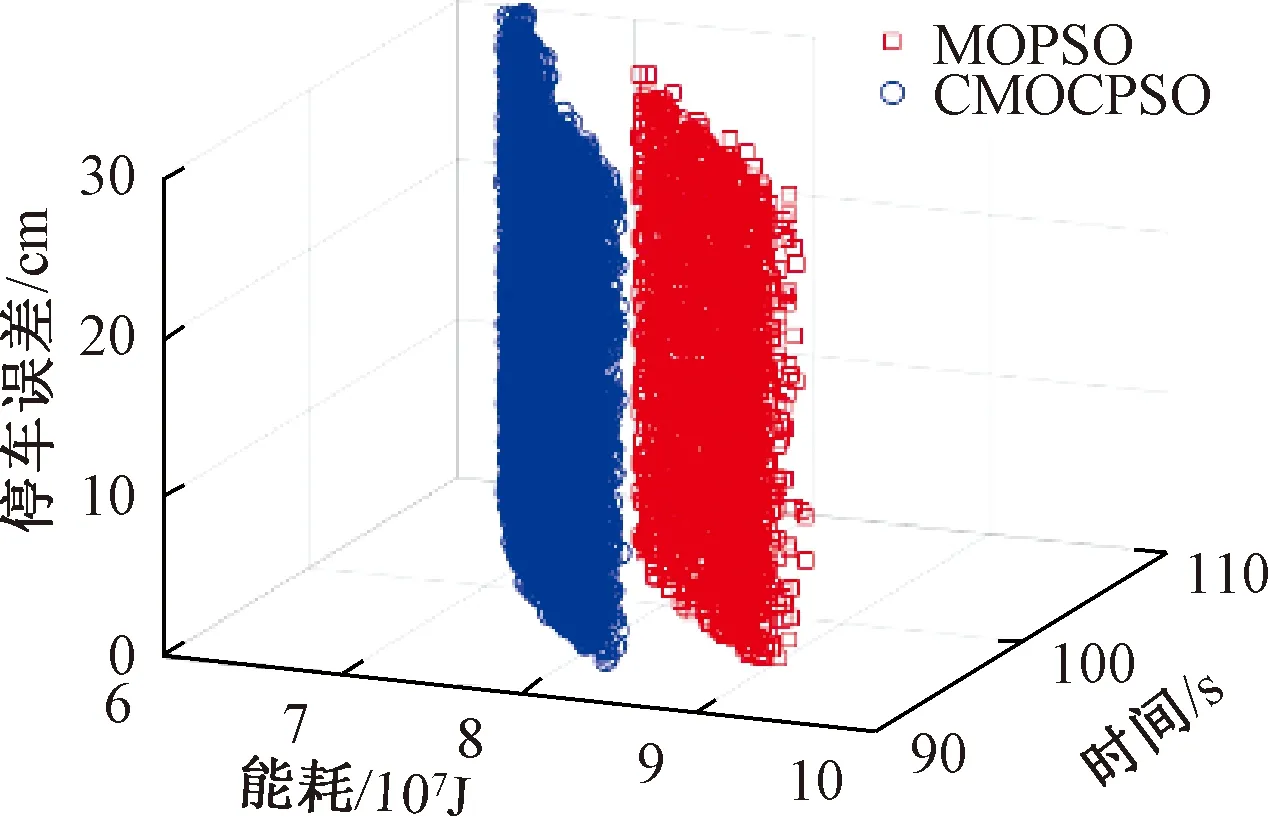
图5 不同算法下的Pareto解空间比较
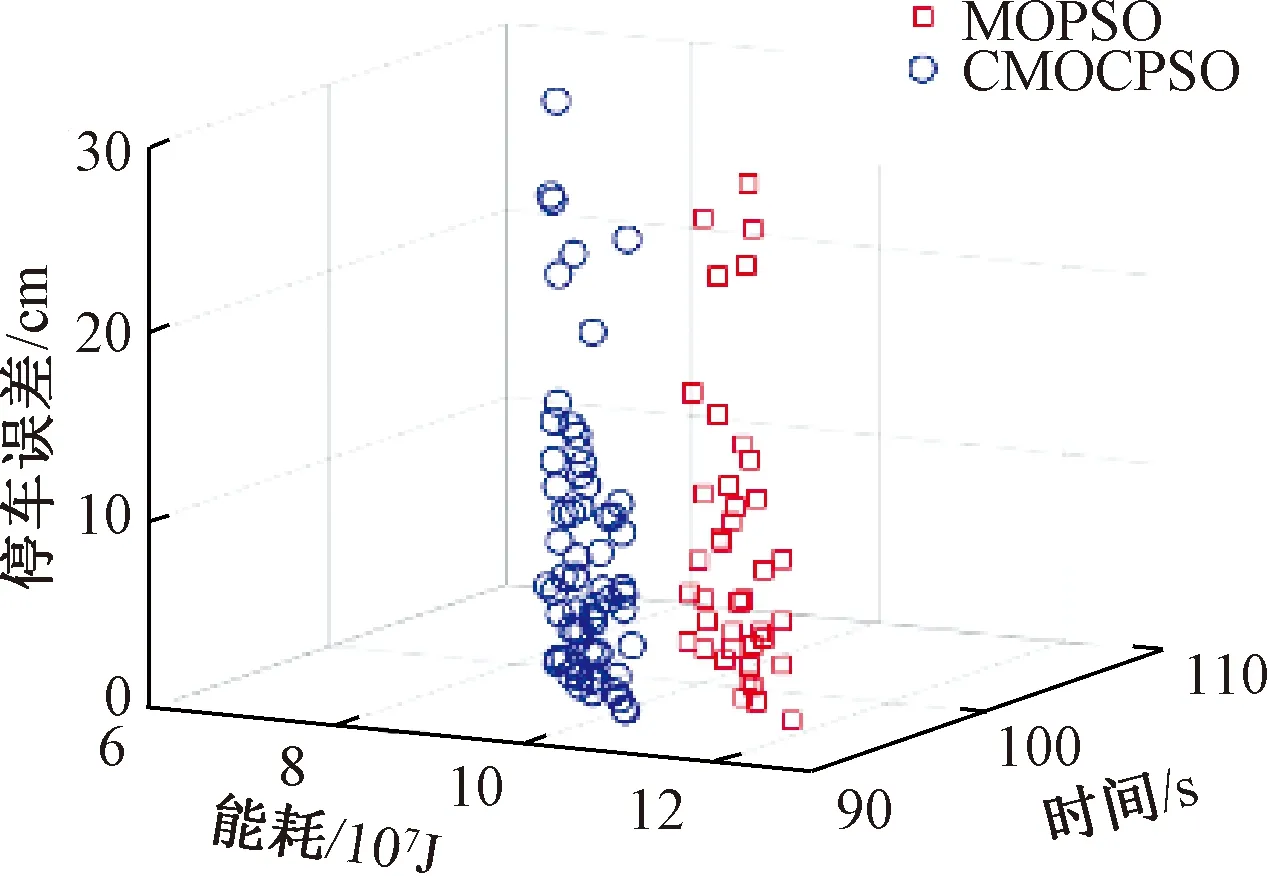
图6 不同算法下的Pareto前沿解比较
由图5和图6可知,相较于MOPSO,CMOCPSO算法具有更好的收敛性。从总体上看,由它计算所得到的能耗明显更小,时间更短;同时,CMOCPSO在可行解上呈现出更好的分布性,各目标对应的解空间跨域范围更广,且Pareto前沿解的数量更多。
3.3.3 两种算法的时间复杂度分析
对于MOPSO算法,设I1为算法迭代最大次数,h为目标个数,m为种群粒子总数。只要算法迭代次数与粒子数足够大,可以忽略对低次幂的计算[13]。因此,MOPSO算法的时间复杂度关键取决于外部档案的更新,其计算过程为:1×h×m2+2×h×m2+…+(I1-1)×h×m2=0.5×h×(I1-1)×I1×m2≈6×108。
对于CMOCPSO算法,设I2为算法进化最大次数,h为目标个数,上下层之间的交互周期T=10;其中下层基础群有4个小种群,每个小种群有k个粒子,上层精英群有n个小种群,这里的n=4,每个精英小种群有k1个粒子;全局和局部外部档案的规模,即至多可容纳的Pareto前沿解数目分别为A1=1 000,A2=100。
在CMOCPSO算法中,全局与局部外部档案的更新,以及将局部外部档案的解向全局外部档案更新,以上三个过程占据了主要的时间计算复杂度。
其中,对全局外部档案进行更新的时间复杂度计算为:1×h×42×k2+2×h×42×k2+…+(I2-1)×h×42×k2=0.5×h×(I2-1)×I2×42×k2≈6×108。
最后,局部外部档案的解向全局外部档案更新的时间复杂度计算为A1×A2×(I2/T)=1.0×106。
综合分析可得该算法时间复杂度是6.25×108。
综上所述,以上两种算法的时间复杂度均处于一个数量级,是一种较为理想的状态。为了获取更好的算法性能指标,仅牺牲少许的时间复杂度是合适的,这符合算法改进的基本准则[14]。
3.4 各类工况序列最优方案的选定
基于Pareto原理的多目标优化结果是一个解集。在列车运行优化问题中,一种列车自动驾驶方案对应于一个Pareto解。本文采用模糊隶属度函数对解中每个目标对应的隶属度进行评价,以此筛选出不同工况序列下最优的驾驶方案。所述模糊隶属度函数的定义为[15]
(24)

利用式(25),可以求得每个解的满意度值,则最优的驾驶方案即为最大满意度值所对应的Pareto解。
(25)
式中:Ψi为第i个Pareto解对应的满意度值;A为外部档案的规模。
针对本文所述的6种典型工况序列,采用上述模糊隶属度法对各自工况的Pareto前沿解集进行了筛选,得到对应的最优驾驶方案,见表3。
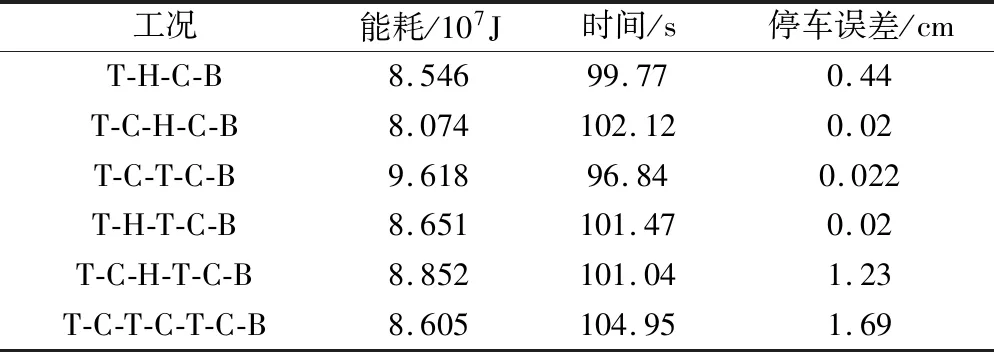
表3 各典型工况序列下的最优方案
图7是表3中各类典型工况序列下的速度-距离曲线,分别用6种不同的颜色曲线标明。
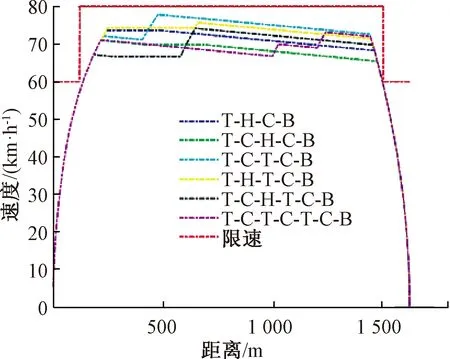
图7 各典型工况序列下的最优速度-距离曲线
在利用CMOCPSO获得Pareto前沿解集后,可以从这些解集中选出能耗最低、用时最少以及停车精度最高的各类不同工况序列与其对应的控制策略。由表4可知:工况序列为T-H-C-B时,能耗最低;工况序列为T-H-C-B时,用时最少;工况序列为T-H-T-C-B时,停车精度最高。
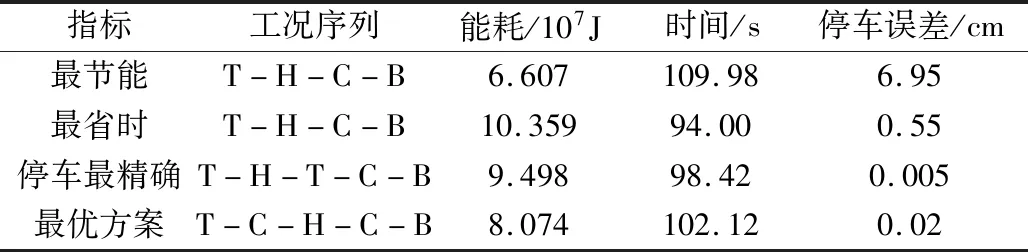
表4 多种工况序列对应的极端解和最优策略
根据式(24)和式(25),再结合表4进一步得到:工况序列T-C-H-C-B是多种工况序列下的最优策略,图8是该工况序列下的最优速度-距离曲线。此外,由表4中的统计数据可以看出,从多种工况序列解集中应用模糊隶属度方法筛选出的最优策略,在每个目标上的值都相对均衡;再由表3分析可得,相较于其余5种运行工况模式,本文确定的各类工况序列下的最优方案T-C-H-C-B最少在对应的两个目标上呈现出的效果更佳。

图8 多种工况序列对应的最优速度-距离曲线
综合表3和表4的各项数据可知,仅研究单一工况序列将存在解的多样性低、空间分布不均匀且数量少的问题。因此,对多种工况序列进行分析与挖掘,这对实际工程的应用是具有研究价值的。
4 结论
针对城轨列车运行速度曲线优化问题,本文提出了一种新颖的协同进化多目标混沌粒子群CMOCPSO算法进行求解,通过仿真试验验证及分析,得到下列结论:
(1)在多种工况模式下,对应解的分布存在较大的差异。相较于单一的工况序列,在解的数量和质量上,多种工况序列下的解都具有明显的优势,因此可获得数量多且优质的列车自动驾驶策略。
(2)与MOPSO相比较,采用目标引导策略的CMOCPSO算法,通过设置恰当的通信周期,其可行解在多样性、收敛性和数量等多个指标上性能更优,从而最终获得的列车运行速度曲线也最佳。
(3)相较于其余5种工况模式所对应的最优驾驶策略,这里采用模糊隶属度法,从不同典型工况序列的Pareto解集中选择出最优驾驶方案,使得列车运行能耗、时间和停车精度这3个目标至少有2个表现良好。
