基于比特负载的非线性虚拟光网络映射机制的研究
2021-01-29任雪琦沈天雨史成林晏春平周怡君顾萍萍
任雪琦,沈天雨,史成林,朱 敏,晏春平,周怡君,顾萍萍
(1.东南大学 电子科学与工程学院,江苏 南京 210096;2.东南大学 微电子学院,江苏 南京 210096;3.东南大学 移动通信国家重点实验室,江苏 南京 210096;4.太仓市同维电子有限公司,江苏 太仓 215400;5.东南大学 机械工程学院,江苏 南京 210096)
0 引言
近年来,新兴互联网应用不断涌现,这些应用通常需要特定的网络服务以提供特定的比特率和服务质量(QoS),光网络虚拟化概念的提出很好地解决了这个问题[1-3]。具体来说,它可以将底层物理网络虚拟化后的资源分配给不同的虚拟光网络(VON)请求,提供专用的VON服务,以满足不同应用的特定服务质量的要求,这个过程称为虚拟光网络映射(VONE)[4]。在公共物理基础设施上,为了使多个VON服务高效共存,需要灵活、协调地利用所有虚拟化的底层资源,包括每条底层光纤链路(SFL)中的频谱槽资源、每个底层交换节点(SN)中收发器的子载波资源和调制器资源。作为一种新型的底层物理网络,弹性光网络(EON)是近几年很有前景的一项技术,与传统的波分复用(WDM)光网络相比,EON通过采用灵活的频谱和调制方案,提供了更好的灵活性和服务粒度。它允许光纤链路的光谱资源以较小的频谱粒度进行灵活的分段和聚合,在某种意义上实现了物理链路层的光谱虚拟化。
在现有的VONE方案中,中国科学技术大学的朱祖勍等人设计了两种不同弹性光网络上的VONE嵌入算法,两种算法基于传输距离进行调制器的分配,并提出了一种分层辅助图(LAG)的方法[5]。东南大学的朱敏等人提出了一种基于资源虚拟化的集成虚拟光网络嵌入方案,并设计了一种新的路由、频谱、子载波和调制器分配算法来建立虚拟链路映射的光路[6]。巴西利亚大学的Lucas R.Costa等人提出一个新颖的方法来解决路由、调制器、频谱分配(RMSA)问题,采用距离自适应调制方案,消除频谱连续性和传输距离限制问题[7]。在上述的工作中,进行虚拟链路(VOL)映射过程中,RMSA通常采用相对简单的调制格式配置方法,如按传输距离配置调制格式或限制调制器数量降序分配[5-9]。然而,此类方法无法准确地判断非线性损耗(NLI)带来的影响,采用更保守的调制格式,从而导致光谱利用效率的降低。因此,在VONE中,考虑到实际传输路径NLI干扰情况的RMSA方案,可以有效提高底层物理网络链路的光谱利用效率。因此,本文在EON中对考虑到NLI的集成式虚拟网络映射机制进行研究,引入了基于OFDM的比特负载技术,即每个子载波基于信道状态独立配置调制格式,承载不同比特率的负载。仿真结果证明,该方案可以显著提高光谱利用率和数据传输效率。
1 问题描述和理论分析
1.1 集成式虚拟网络映射机制
光网络虚拟化技术可以为不同应用提供特定QoS要求的专属VON服务,多个VON服务之间可以共享物理网络资源,包括整个网络中的链路和节点资源。一个VON请求通常由几个虚拟节点(VN)组成,而这些VN通过虚拟光链路(VOL)相互连接,将底层物理网络资源分配给每个VON请求的过程称为VONE。在VONE中,每个VN映射到一个SN,每条VOL映射到一条光路,而一条光路一般由一条或多条SFL组成[9]。在我们前面的工作中,我们提出了集成式的VONE,节点映射与链路映射以集成的方式实现,即当一个新的VN节点被映射后,继而映射新VN节点与所有已映射节点之间的一条或多条VOL。图1为集成式VONE的示例。在图1中,一个三节点的VON请求,试图映射到一个五节点的简单网络拓扑中。首先,将该请求的VN-a映射到SN-E,接着把VN-b映射到SN-B,在映射完VN-b之后,将VOL(a,b)映射到光路(B-E)。接着,将VN-c映射到SN-C,由于新映射的VN节点c与VN-a和VN-b间均存在VOL,因此分别执行(b,c)→(B-C)和(a,c)→(E-D-C)的虚拟链路映射。

图1 集成式VONE中的节点映射和链接映射示例
1.2 基于OFDM的比特负载技术
1.2.1 非线性损耗模型。GN模型是计算无色散补偿NLI的解析模型。在GN模型中,由克尔效应引起的在同一光纤链路上传输的多个请求间的NLI被建模为加性高斯噪声,它与光纤放大器引入的加性自发辐射(ASE)噪声非相干地结合在一起[11-13]。本文采用文献[14]中的损耗模型,考虑了ASE和NLI的干扰,若将请求i分配给光路ri,则它的信噪比(SNR)可由(1)式计算
(1)
其中
(2)
(3)
(4)
(5)
式中各参数具体细节见表1。式(5)第一项为自通道干扰(SCI),因单信道系统中的自相位调制(SPM)引起频谱展宽而导致的,第二项交叉通道干扰(XCI)则是由多信道系统中交叉相位调制(XPM)而引起的[14]。考虑到接收均衡器补偿,诸如偏振模色散引起的信号衰退被忽略,故本文非线性效应仅考虑SPM和XPM[14]。

表1 GN模型相关参数
1.2.2 基于OFDM的比特负载技术。针对基于OFDM调制的光路请求,传统的RMSA算法通常给所有子载波分配统一的调制格式,而不独立考虑影响每个子载波通道的NLI等带来的影响。本文引入了基于OFDM的比特负载技术,该技术提供了很好的灵活性,每个子载波可以根据信道优劣状态独立调制,使每个子载波负载不同的比特速率。这种使每个子载波负载不同比特速率的技术,在OFDM中通常被称为比特负载[15]。注意,本文中OFDM系统采用单偏振模式。
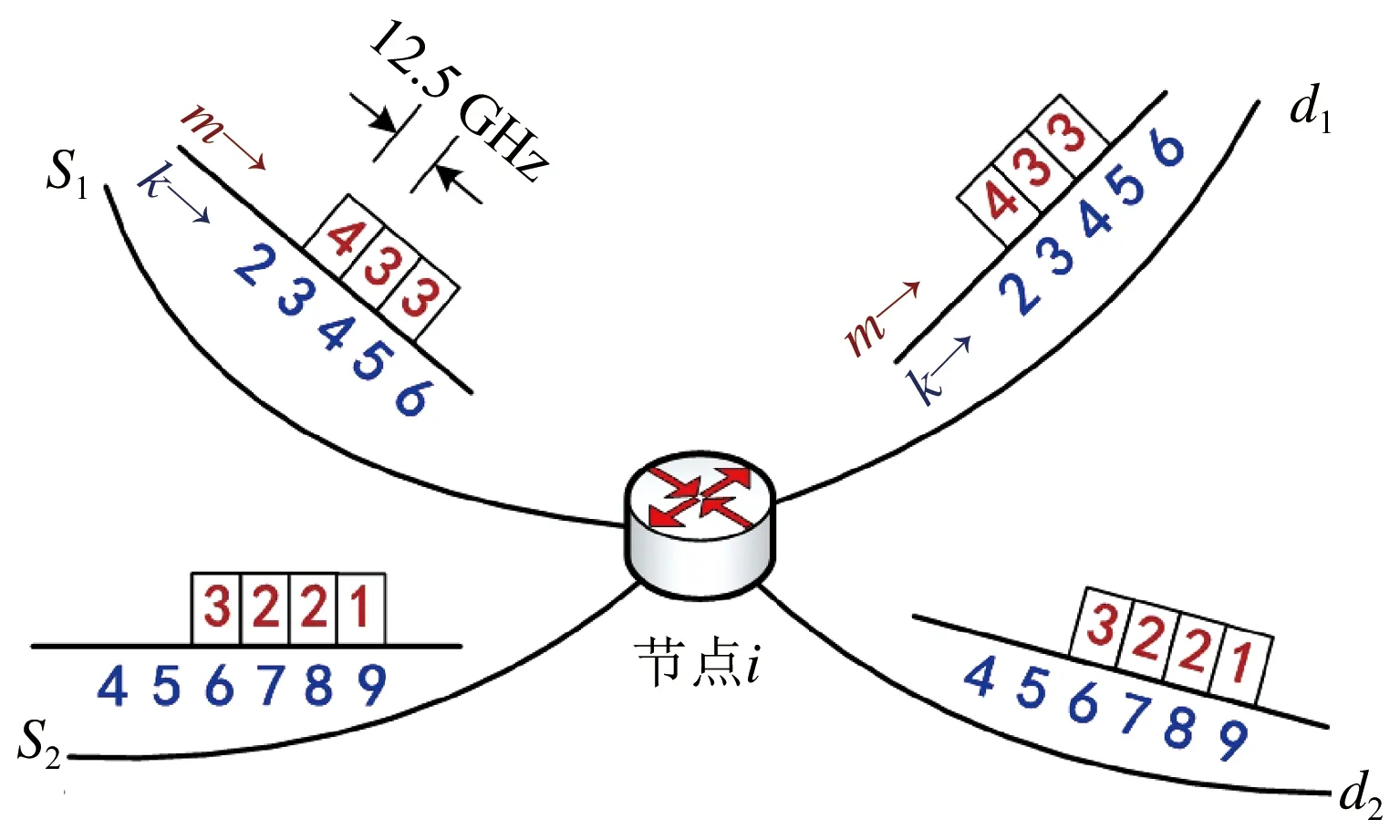
图2 节点i处请求比特负载的示例
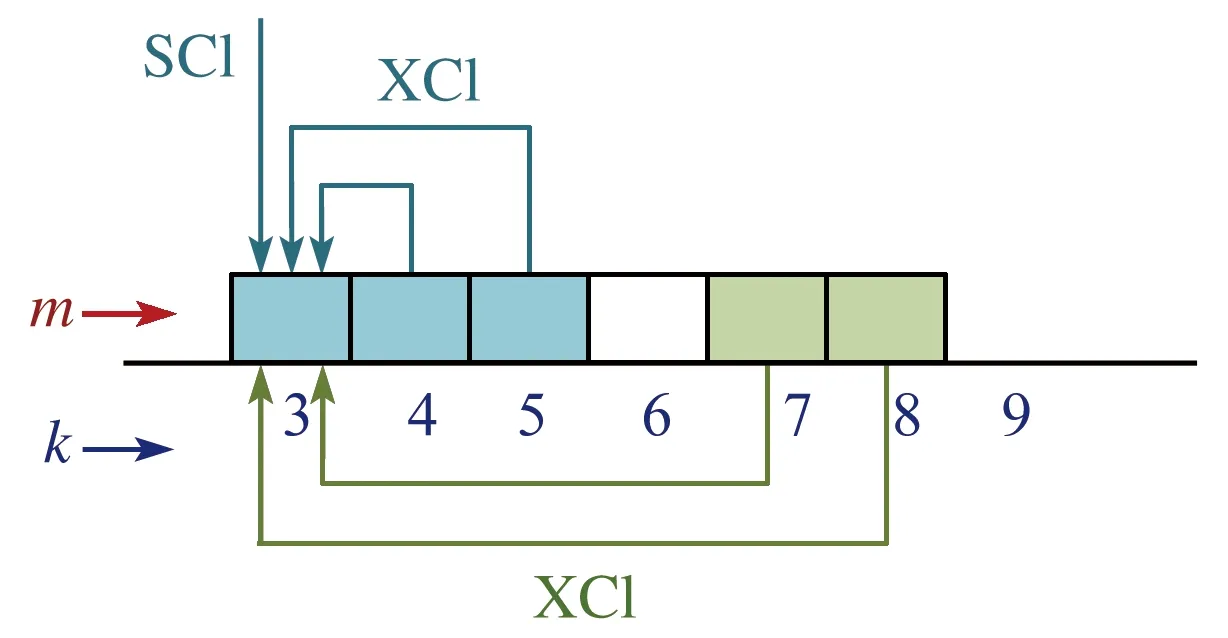
图3 单条链路上的非线性干扰NLI
图2为某一个节点i处的比特负载的示例。光纤链路上的频谱资源以12.5 GHz的粒度,被灵活地配置给各个请求。其中m(框内数字表示)为第k个频谱资源块(框下数字表示)使用的调制格式,m=1,2,3,4分别表示BPSK、QPSK、8-QAM和16-QAM。当采用基于OFDM的比特负载技术时,分配给同一个请求的各个频谱块,可以分配不同的调制格式,进行独立调制。在BER为10-9的前提下,我们设置不同调制格式的SNR阈值分别为12.6、15.6、19.2和22.4 dB[15]。以请求(s1,d1)为例,该请求将占用3个子载波资源(即该条链路上的第3、4、5的频谱资源块)。如图3所示,利用式(1)至(5),计算各频谱块的SNR值,若分别为22.6、22.3和22.2 dB,通过SNR阈值对比,最终给这3个子载波分别分配调制格式16-QAM、8-QAM、8-QAM。一般来说,对于传统的RMSA算法,受到非线性干扰影响严重的子载波决定了该请求所有子载波的调制格式。而当采用比特负载技术时,分别独立对待各个不同的子载波信道情况,通过选择适当的调制格式,最大化每个子载波所承载的比特速率,从而最大限度地提高总体频谱利用率,并最小化所需的子载波总数。
2 算法设计
2.1 VAG辅助图
本文首先根据VON请求带宽,建立了一个虚拟分层辅助图(VAG),将底层拓扑网络分解成若干层辅助图,以帮助链路和频谱资源的分配。当VON请求到达时,根据频谱粒度带宽f=12.5 GHz和各种调制格式谱利用率SU(m),先将VON请求比特率bw转化为采用不同的调制格式下所需的频谱资源块的数量Ns

(6)
算法1用于构建第f层虚拟辅助图,链路上频谱资源块slot的使用情况用该条链路的“位掩码”

算法1 VAG辅助拓扑
来表示,某一资源块已被占用,则为1,可用则为0。通过扫描所有SFL的频谱资源情况,查询每条SFL在第f个到第(f+Nslots-1)个频谱资源块上是否存在连续可用的资源。若存在,则将该链路插入第f层辅助图中;否则,该条SFL将被删除,从而建立第f层辅助图。

算法2 节点映射

算法3 链路映射

算法4 BL-VONE算法
2.2 节点映射和链路映射算法
在某一辅助层上映射某一个虚拟节点VN时,按照该辅助层上物理节点SN的节点度降序的次序,依次选择一个节点度满足要求的备选节点SN,即备选节点SN的节点度不小于该虚拟节点VN的节点度(节点度θ为该节点向外延伸链路数量)。然后,如果该虚拟节点VN与所有已经映射成功的虚拟节点VN之间存在虚拟光路VOL,则开始对一条或多条VOL进行链路映射。只有这样的所有VOL都映射成功了,才被认为该虚拟节点VN成功地映射在备选节点SN上。否则,就选择下一个备选节点SN。算法2给出了节点映射的详细过程。
在进行虚拟链路VOL映射时,我们为每一条物理链路SFL定义一个权重值cost,即为链路中所有频谱资源块slot上GNLI的总和。
(7)
在两个SN之间,为每一条VOL找到3条最短路径,按first-fit原则依次选择。在所选路径上,基于比特负载技术由式(1)至(5),分别计算每一个资源块slot上的SNR,并根据各调制器阈值,为每一个频谱块slot分配最佳调制格式。再根据所有分配slot的总的传输带宽能力是否能满足该VON请求的比特率带宽要求,来决定链路映射是否成功,算法3解释了链路映射算法的具体细节。
2.3 非线性集成式虚拟网络映射算法
在本文提出的非线性集成式虚拟网络映射算法中,我们假设,每个具有特定比特率要求的请求是预先随机生成的。我们定义一个参数Ω来衡量各个VON请求的优先级,Ω为每一个VON请求的虚拟节点数与虚拟链路数的总和乘以该请求的比特率bw
(8)
根据参数Ω将待配置的VON请求降序排列。对于每个VON请求,首先获取其比特率带宽bw,分别根据16-QAM和BPSK这两种调制格式,通过式(6)计算该请求所需频谱资源块slot的最大数量和最小数量。这是因为在相同符号率的前提下,采用越高阶的调制格式,频谱利用率就越高,所需的频谱资源块的数量就越少。然后,利用算法1,从第一层开始,建立VAG辅助拓扑,采取first-fit策略逐层查询。在每一层VAG中,分别计算SN和VN的节点度,在满足节点度条件下,以集成式的方式进行节点映射和链路映射。若节点映射成功,进行下一个VN映射,若失败则选择下一SN节点重新映射。直到所有VN节点全部映射成功,则该VON请求映射成功;并继续下一个VON请求,直至所有请求映射完成,具体细节见算法4。
3 仿真与数据分析
如图4所示,仿真采用一个小型的6节点网络,每条链路包含双向的一对光纤,图中数字表示为跨度的个数,单个跨度长度设置为100 km。仿真设置如下:本文假设网络在193.6 THz波段上运行,每个频谱资源块的带宽f为12.5 GHz,总带宽为4.375 THz,即总资源块数F为350个[15]。信号功率谱密度G=13 mW/THz,噪声系数NF=4.5 dB,每个跨度的长度L=100 km,功率损耗α=0.22 dB/km,光载波频率v=193 THz,非线性系数γ=1.32(Wkm)-1,色散系数β2=-22.7 ps2/km。有4种调制格式可用:BPSK、QPSK、8-QAM、16-QAM,对应SNR阈值分别为12.6、15.6、19.2和22.4 dB[15]。本次仿真随机生成100至700 Gbps的请求,仿真结果来源于10次相似结果的均值。
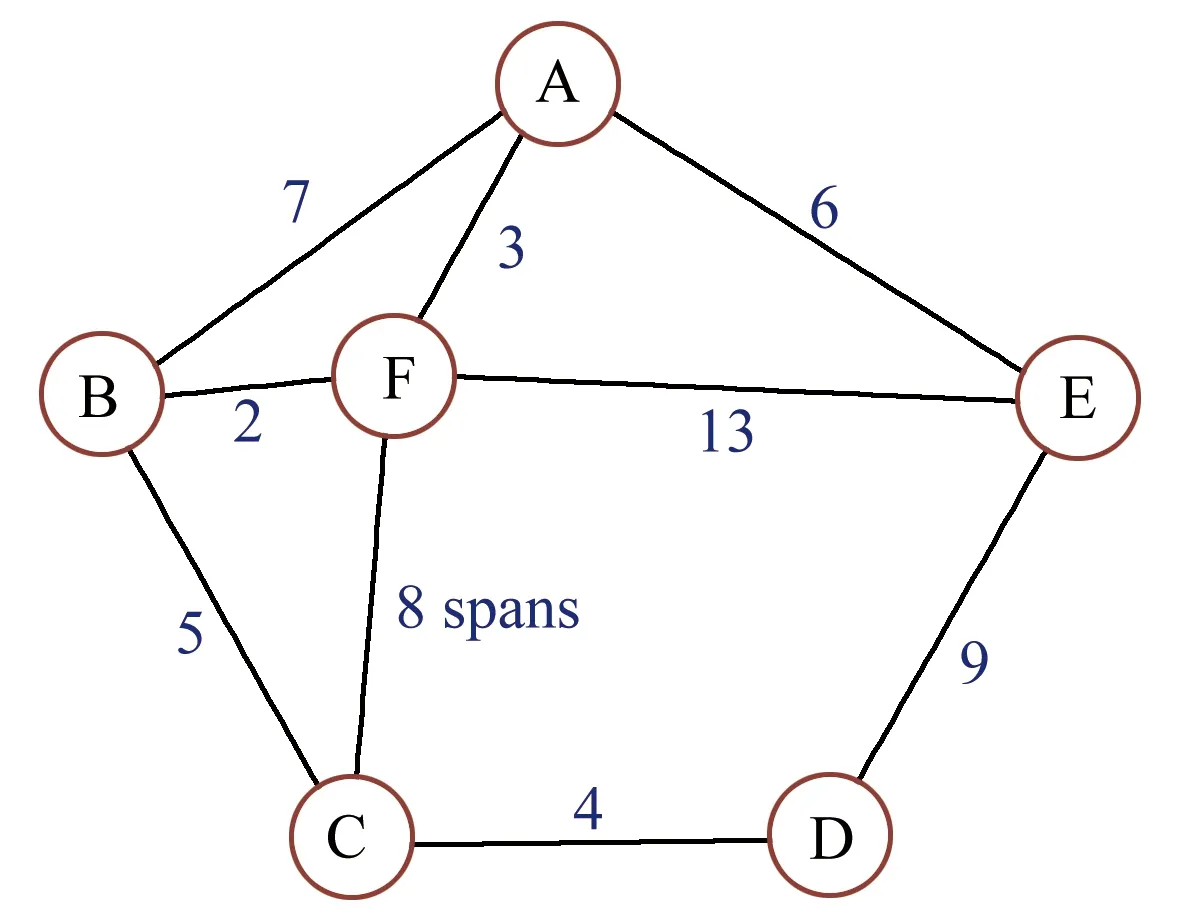
图4 简单6节点拓扑图(图中数字为跨度个数)
基准算法比较:与本文提出的BL-VONE算法做对比的是,采用单一调制格式的集成式虚拟光网络嵌入算法(UM-VONE)。为了提高频谱利用率,该算法首先从最高阶的调制格式进行分配,由此计算该请求所需的频谱资源块slot的数量,再按照first-fit策略,依据VAG辅助图确定频谱资源块slot的具体位置,计算其SNR,判断该SNR值是否满足所分配的调制格式的门限值。若满足,则成功配置该VON请求;若不满足,则选择低一阶调制格式,重复上述步骤,直至选至最低级调制格式。

表2 BL-VONE和UM-VONE在不同请求数下的子载波使用总量

表3 BL-VONE和UM-VONE不同请求数下所有链路中使用到的最大频谱资源块的序号
在表2和图5中,我们分别验证了当VON请求数为15、20、25、30、35时,BL-VONE和UM-VONE算法使用到的子载波总数的性能差异。子载波总数定义为
(9)
图5的横坐标为VON请求个数,纵坐标为使用到的子载波总个数。从图5中可以看出,相比UM-VONE算法,BL-VONE算法使用的子载波总数减少9%,BL-VONE算法有利于提高子载波资源的利用率,这是因为BL-VONE算法可以充分利用每一个子载波的SNR的情况,选择合适的调制格式,最大化子载波资源的数据承载能力。
在表3和图6中,呈现的是在不同VON请求数下,BL-VONE和UM-VONE算法在所有链路中使用到的最大频谱资源块的序号。图6中横坐标为VON请求个数,纵坐标为所有链路中使用到的最大频谱资源块的序号。值得一提的是,图表中的数据是10次仿真运行后,平均后得到的数据,因此不是整数。当请求数为35时,BL-VONE与UM-VONE算法使用到的最大频谱资源块的序号达到10.2%的差距。从图6中可以看出,本文采用的BL-VONE算法大大压缩了请求所占频谱带宽,随着请求数增多,优化率呈上升趋势。这是因为随着请求数增多,BL-VONE算法优化频谱利用率的优势变得越来越显著。
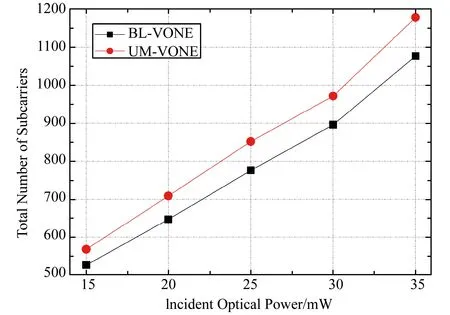
图5 BL-VONE和UM-VONE不同请求数下子载波总数

图6 不同请求数下使用到的最大频谱资源块的序号
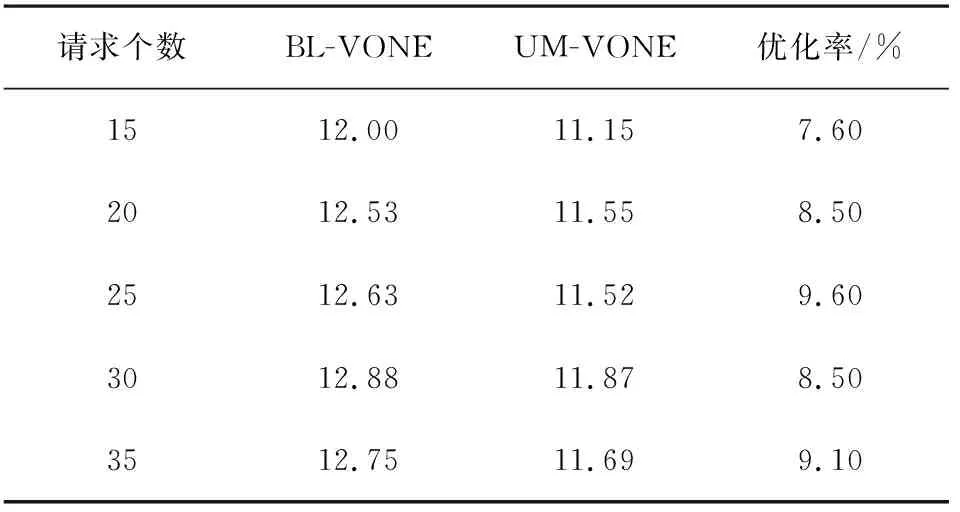
表4 不同请求数下传输效率ω (Gbps/每个子载波)

表5 BL-VONE和UM-VONE不同入纤功率下子载波使用总量
表4和图7展示了BL-VONE和UM-VONE算法在不同VON请求数下,每个子载波的平均频谱效率ω,即每个子载波平均可携带的信息量,如式(10)所示。图7中横坐标为VON请求个数,纵坐标为传输效率ω。由图7可以看出,在我们提出的BL-VONE算法中,每个子载波平均可携带的信息量明显优于UM- VONE算法,优化率提高了约9%,这再一次说明了本文中采用的比特负载技术可以自适应地利用各个子载波信道的SNR限制条件,有效地提高频谱利用率
(10)
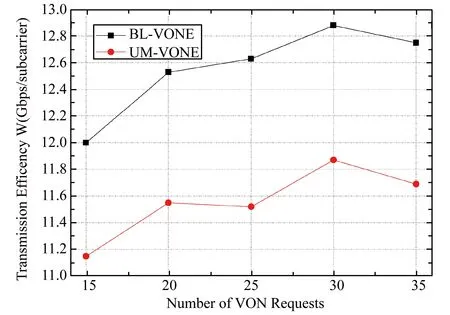
图7 BL-VONE和UM-VONE不同请求数下传输效率ω
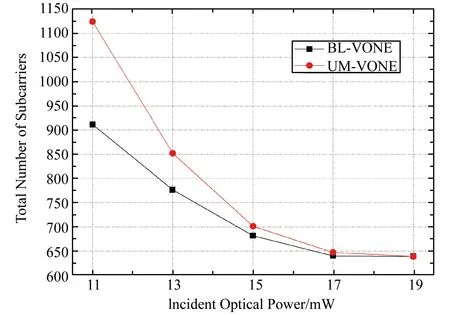
图8 BL-VONE和UM-VONE不同入纤功率下子载波总数
表5和图8展示了BL-VONE和UM-VONE算法在不同入纤功率下,使用到的子载波总个数。图8中横坐标为入纤功率,纵坐标为使用到的子载波总个数。由表5和图8可以看出随着入迁功率的增大,子载波总数减小,这是因为增大的入纤功率可以改善子载波信道的SNR,从而提升子载波的传输效率,大大减少所需的子载波数。当入纤功率大于17 mW时,两算法间所需的子载波总数差距逐渐减小直至为0。这是因为当入纤功率增大到某一值后,子载波信道的SNR环境大大改善,超过了所有调制格式的门限值,所有请求均选用最高级调制格式,故结果趋于一致。
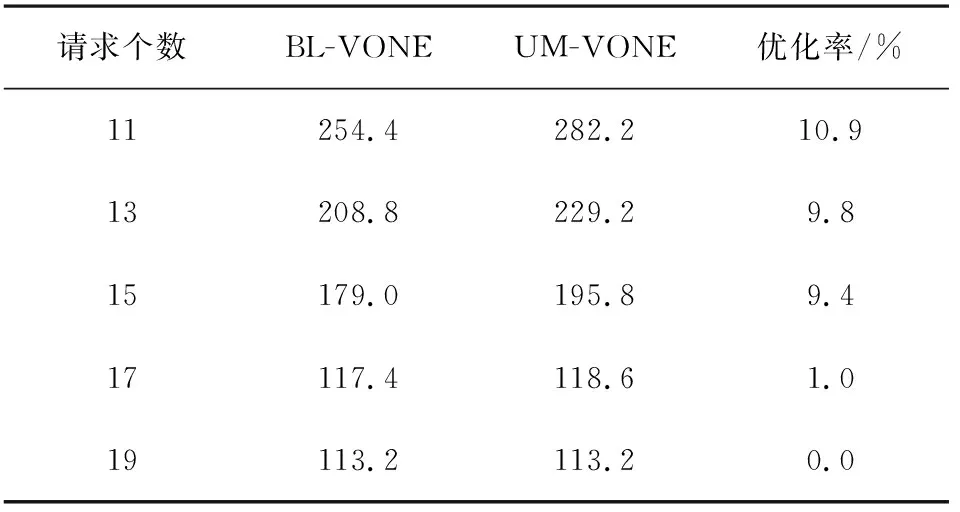
表6 BL-VONE和UM-VONE不同入纤功率下的所有链路中使用到的最大频谱资源块的序号
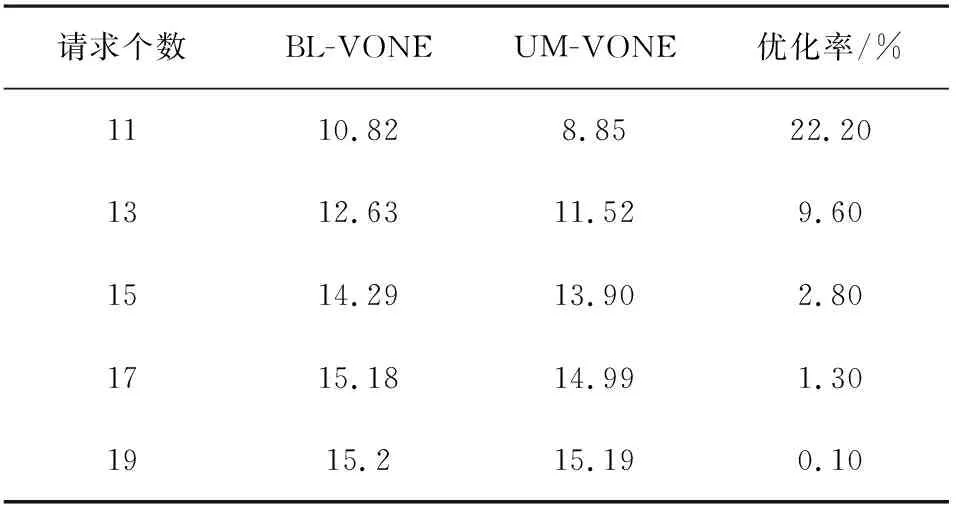
表7 不同入纤功率下传输效率ω (Gbps/每个子载波)
表6和图9为在不同入纤功率下,BL-VONE和UM-VONE这两个算法在所有链路中使用到的最大频谱资源块的序号。图9中横坐标为入纤功率,纵坐标为使用到的最大频谱资源块的序号。从表6和图9可以看到,随着入迁功率的增大,网络中使用到的最大频谱资源块的序号减小,并最终趋于一致。这也是因为随着入迁功率的增大,每个子载波信道的SNR大大改善,以至于所有VON请求均选用最高级调制格式,所两个算法可以得到相同的结果。而当入纤功率为11 mW时,BL-VONE算法相较于UM-VONE算法,最大频谱资源块序号的优化率达到10.9%。以此说明,我们提出的BL-VONE算法的优越性。
表7和图10列出了BL-VONE和UM-VONE两个算法在不同入纤功率下的传输效率ω。图10中横坐标为入纤功率,纵坐标为传输效率ω。图10中ω随着入迁功率的增大而增大,这是因为随着入纤功率的增大,VON请求分配到的调制格式级别就随之提高,从而单个子载波携带的信息量增大。同时,与图8类似,随着功率的增加,两算法间的传输效率逐渐逼近,直至趋于一致。

图9 BL-VONE和UM-VONE不同入纤功率下最大粒度系数

图10 BL-VONE和UM-VONE不同入纤功率下传输效率ω
4 结论
在弹性光网络中,考虑到光纤链路传输的非线性损伤,引入了基于OFDM的比特负载技术,提出了一种非线性集成式虚拟网络映射BL-VONE机制。该机制在进行虚拟链路配置时,根据每一个子载波信道具体的SNR情况,在保证链路端到端误码率BER为10-9的前提下,实现了为单个子载波独立分配最优的调制格式。而对于传统的UM-VONE算法,在虚拟光路配置的过程中,仅仅简单地按照光路长度配置调制格式,而且为多个连续使用的子载波统一配置调制格式,这就给网络资源带来了较大的冗余,造成资源浪费。仿真结果表明,提出的BL-VONE算法相较于基于单一调制机制的UM-VONE算法,可以提高约9%的频谱利用率和约9%的传输效率,证明了提出的BL-VONE算法的优越性。
