Time optimization for workflow scheduling based on the combination of task attributes
2021-01-12LuRuiqiZhuChenyanCaiHailinZhouJiaweiJiangJunqiang
Lu Ruiqi Zhu Chenyan Cai Hailin Zhou Jiawei Jiang Junqiang
(1School of Information Science and Engineering, Hunan Institute of Science and Technology, Yueyang 414006, China) (2College of Computer Science and Electronic Engineering, Hunan University, Changsha 410082, China)
Abstract:In order to reduce the scheduling makespan of a workflow, three list scheduling algorithms, namely, level and out-degree earliest-finish-time (LOEFT), level heterogeneous selection value (LHSV), and heterogeneous priority earliest-finish-time (HPEFT) are proposed. The main idea hidden behind these algorithms is to adopt task depth, combined with task out-degree for the accurate analysis of task prioritization and precise processor allocation to achieve time optimization. Each algorithm is divided into three stages: task levelization, task prioritization, and processor allocation. In task levelization, the workflow is divided into several independent task sets on the basis of task depth. In task prioritization, the heterogeneous priority ranking value (HPRV) of the task is calculated using task out-degree, and a non-increasing ranking queue is generated on the basis of HPRV. In processor allocation, the sorted tasks are assigned one by one to the processor to minimize makespan and complete the task-processor mapping. Simulation experiments through practical applications and stochastic workflows confirm that the three algorithms can effectively shorten the workflow makespan, and the LOEFT algorithm performs the best, and it can be concluded that task depth combined with out-degree is an effective means of reducing completion time.
Key words:directed acyclic graph; workflow scheduling; task depth; task out-degree; list heuristic
The explosive growth of data poses a huge challenge in terms of the efficiency and difficulty of data processing[1]. As the increasing data volumes are being accumulated, a powerful computation capability is required to extract information. Previously, homogeneous computing that improved the performance of computational components was no longer sufficient to meet the performance requirements of large-scale scientific and engineering computing[2]. The heterogeneous distributed computing system, as a new carrier of computing mode, is a computing platform that interconnects a series of computing resources with different performances through networks[3], which can provide significant computing power. Grid computing[4], cloud computing[5], edge computing[6]and mobile cloud computing[7]have been developed as typical heterogeneous distributed computing systems in recent years.
Workflow is an application process that can be fully automated. It is commonly used to describe scientific computational problems with large structures and complex logical processes, and has important practical implications[8]. It is widely used in geophysics, astronomy, bioinformatics and other fields[9]. At the same time, it has a natural close coupling with heterogeneous distributed systems due to the characteristics of workflow. In addition, research on the combination of them is ongoing. Task scheduling is the main object of the workflow research, and its essence is to solve the mapping between precedence constrained tasks and computing resources to achieve optimization goals, such as shortening workflow execution time, reducing execution costs, lowering energy consumption, or improving system reliability[10-16]. As a common quality of service (QoS) element, time has always been an important goal of research due to its significance[17-20].
The problem of minimizing the execution time of workflows in low complexity situations has been studied extensively, but many algorithms only focus on different performance and communication overheads of the processor to formulate scheduling strategies. However, few have incorporated the structure of the workflow, such as the depth and out-degree of task, into the strategy. The out-degree, as an important factor controlling workflow formation, should be taken into account in this problem. Many researchers have also experimentally adjusted the magnitude of the out-degree to control the number of parallel tasks at the same level. Moreover, since the quality of the solution is very sensitive to the priority assignment of tasks, the out-degree facilitates the obtaining of more accurate task priorities. Moreover, the levelization strategy can place tasks with identical depth at the same level and select the task with the highest out-degree among them for priority scheduling, which can effectively reduce the workflow scheduling completion time by eliminating scheduling blocking while maximizing the parallelism of currently ready tasks.
On the basis of the preceding thoughts, this paper presents the following algorithms: level and out-degree earliest-finish-time (LOEFT), level heterogeneous selection value (LHSV), and heterogeneous priority earliest-finish-time (HPEFT). These algorithms are divided into three stages, namely, task levelization, task prioritization, and processor allocation. In the task levelization and task prioritization stages, a more precise task queue, which largely determines the completion time of the workflow, is obtained. In the processor allocation phase, the task queue is acquired to achieve the precise positioning of the processor to minimize the completion time of the workflow. Heterogeneous selection value (HSV) and earliest-finish-time (EFT) are two indicators used as the bases for different algorithms to allocate processors. Simulation experiments demonstrate that the LOEFT, LHSV, and HPEFT algorithms can simply and efficiently achieve the workflow of the makepan minimization, and the LOEFT algorithm has the most optimal scheduling results.
1 Related Works
Among the workflow scheduling time optimization algorithms, list heuristics has attracted widespread attention due to its efficiency and practicality[21]. The classical heterogeneous earliest-finish-time (HEFT), which was proposed by Topcuoglu et al.[17], achieved high performance in terms of robustness and schedule length. However, in more complex cases, the HEFT algorithm often fails to achieve desired scheduling results. On the basis of the HEFT algorithm, Bittencourt et al.[18]proposed the Lookahead algorithm, which sets up a prediction mechanism to schedule the current task to the processor that minimizes the EFT of all subsequent tasks; unfortunately, its complexity is high. The improved heterogeneous earliest time (IHEFT) algorithm proposed by Wang et al.[19]considers the minimum value of the upward weight on different resources as the ranking criterion. However, this approach cannot achieve good scheduling results in large-scale workflows. The HSV algorithm proposed by Xie et al.[20]can effectively reduce scheduling imprecision caused by differences in computing resources. Nevertheless, in some types of applications, the HSV algorithm will break the precedence constraint between tasks, posing a serious threat to system security while prolonging the makespan. Sih et al.[22]proposed a non-preemptive DAG workflow dynamic-level-scheduling (DLS) algorithm for DAG workflows, which not only takes into account the communication overhead between processing units, but also integrates the processing unit interconnection topology information and supplements it with time (communication overhead) and space (processing unit load) scheduling to eliminate resource competition. It also constantly adjusts the task priority to fit the compute nodes. The authors start from the homogeneous computing system and gradually extend to the heterogeneous computing system. Daoud et al.[23]invented the longest-dynamic-critical-path (LDCP) algorithm for task scheduling in processor-limited heterogeneous computing environments. The LDCP algorithm is a static list heuristic scheduling algorithm, and as such, it can be divided into three phases. The first stage is the task sorting stage, where at each step of the algorithm, the maximum value of the sum of task execution time and communication time on the path from the entry task to the exit task is the author’s LDCP, and the tasks are sorted according to it. The second stage is the processor selection stage. Based on the insertion scheduling strategy[24], the task is assigned to the processor that will allow it to obtain the minimum completion time. The third stage is the state update stage. Once the running processor of the task has been assigned, the system must update the state information in time to reflect this scheduling. The experimental results show that LDCP is superior to the HEFT and DLS algorithms in reducing the workflow completion time, but it has a higher time complexity than the HEFT algorithm.
Apart from list scheduling algorithms, other types of algorithms can be classified into clustering and task duplication heuristic algorithms[17]. Huang et al.[25]proposed three new task clustering approaches, critical path clustering heuristic (CPCH), larger edge first heuristic (LEFH), and critical child first heuristic (CCFH), attempting to minimize the communication cost over the execution path to obtain better workflow scheduling performance. The proposed scheme is evaluated through a series of simulation experiments and compared with other cluster-based task graph scheduling methods. The experimental results show that the proposed CPCH, LEFH, and CCFH significantly outperform the typical schemes, with an average makepan performance improvement of up to 21% for workflows with a large communication computation ratio (CCR). Similar to clustering heuristics, which aim to eliminate inter-processor communication overhead, duplication-based algorithms are proposed to replicate their forerunners using idle slots in processors. In Ref. [26], a workflow scheduling algorithm for heterogeneous cloud environments based on task duplication is presented. The algorithm is divided into two stages. The first stage computes the priority of all tasks and the second stage schedules task replication by computing the data arrival time from one task to another task. The proposed algorithm aims at minimizing the workflow execution time and maximizing the resource utilization. Simulation experiments verify the advantages of the proposed algorithm in terms of makespan and average cloud utilization.
2 System Models
The scheduling system model comprises of a target computing environment and an application model. The target computing environment is assumed to be setP, which is comprised of differentpindependent types of processors that are fully connected. In addition, all inter-processor communications are assumed to perform without contention in a fully connected topology.
Workflow can usually be represented by a directed acyclic graph (DAG), whose model isG=(T,E,W,C). Among them,Trepresents the set of all nodes,T={t1,t2,t3,…,tn}. Each node represents a tasktiin the application;Erepresents a set of directed edges that are constrained between tasks, that is,ei,j∈Eindicates that tasktjcan be started after the execution ofti.tiis a predecessor task, andtjis a successor task. Nodes without predecessor tasks are entry tasks and are marked astentry. Nodes without successor tasks are exit tasks and are marked astexit. Fig.1 is a schematic of Montage workflow DAG applied to astronomical observation.
Wis expressed as a computation cost matrix of size |P|×|T|, where |P| represents the number of processors, |T| represents the number of tasks to be executed, andwi,krepresents the execution time of tasktion processorpk.Cis represented as the communication cost matrix of size |T|×|T|, andci,jrepresents the communication overhead on edgeei,j. Tab.1 shows an example of the computation cost matrix of the Montage workflow in Fig.1.
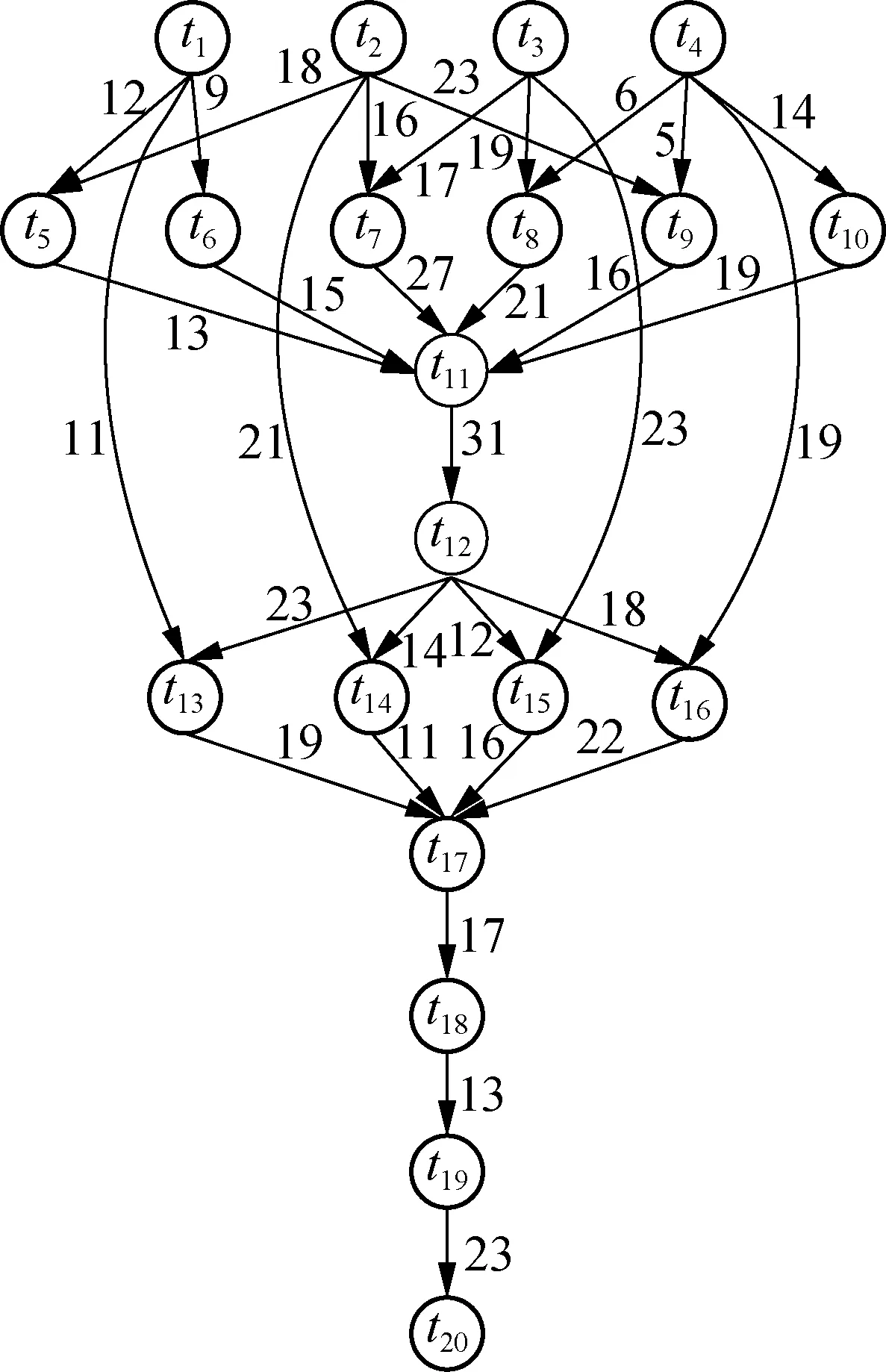
Fig.1 Montage workflow DAG graph

Tab.1 Sample computation costs
In accordance with the task depth value, the workflow is divided into several independent task sets from top to bottom to maximize the parallelism of tasks at the same level. InG=(T,E,W,C), if the level of the predecessor tasktiis expressed as level (ti), then the level of its direct successor task is expressed as level(ti)+1, and the specific definition is
(1)
where pred (ti) is the set of immediate predecessors of taskti.
Similar to Ref.[20], the heterogeneity of the computing node is considered in the model, and the execution time of each task on different processors is calculated to improve accuracy. The specific calculation process is
(2)
where succ (ti) is the set of immediate successors of taskti.
Based on the previous equation, the heterogeneous upward rank value is defined as
(3)
The out-degree of a task (outd(ti)) is also a factor that affects the priority of the task. If the task with a larger outd(ti) is not scheduled first, then all subsequent tasks will not be ready, thereby prolonging the makespan of the workflow. Similar to Ref.[20], the product of the average upward ranking value and the out-degree is used as the ranking criterion for task priority. This value is called the heterogeneous priority rank value (HPRV). The calculation formula is
HPRV(ti)=outd(ti)×hranku(ti)
(4)
EST(t,p) represents the earliest execution time available for taskton processorp. Correspondingly, the earliest execution completion time of taskton processorpis called the earliest finish time and is expressed as EFT(t,p). The specific definitions are shown as
EST(ti,pk)=
(5)
EFT(ti,pk)=EST(ti,pk)+wi,k
(6)
where avail[pk] is the EST when processorpkis ready for execution; AFT(tj) is the actual execution finish time of tasktj. The maximum value of the start time of the predecessor task oftjtriggeringtiis selected in each calculation to ensure that all data needed by tasktihas arrived at processorpk.
HSV combines the principles of “looking up” and “looking down” to consider the EFT and the longest distance exit time (LDET) to achieve processor allocation. The specific definition is
HSV(ti,pk)=EFT(ti,pk)×LDET(ti,pk)
(7)
where LDET(ti,pk) represents the longest time thattitakes from processorpkto exit tasktexit. The calculation formula is
LDET(ti,pk)=ranku(ti,pk)-wi,k
(8)
3 Algorithms
The LOEFT, LHSV, and HPEFT algorithms belong to the list scheduling algorithm. The basic idea is to construct an ordered task queue by assigning priorities to each task in the task graph. Assigning each task in the task queue, in turn, can complete the workflow. The processor minimizes time until all nodes in the task list have been scheduled. The specific process and pseudo code are as follows.
3.1 LOEFT algorithm
The LOEFT algorithm can be divided into three stages:task levelization, task prioritization, and processor allocation. In the first stage, the workflow is divided into a hierarchical set taskGroups composed of several groupkin accordance with the depth valuek. In the second stage, the HPRV corresponding to tasktin each groupkis calculated in turn, and the non-increasing order is placed in groupkon the basis of the HPRV. In the third stage, the processor with the minimum EFT is assigned to the current task. The specific steps are shown in Algorithm 1.
Algorithm1LOEFT algorithm
Input: DAG workflowG=(T,E,W,C), processors setP;
Output: task scheduling sequence SL.
taskGroups=∅;
calculate the depth valuekof each tasktaccording to Eq.(1);
calculate the HPRV of each tasktaccording to Eq.(4);
grouptwith the same depth valuekinto groupk, and all groupkform taskGroups;
sort groupkin taskGroups in ascending order according to the value ofk;
sort tasks in groupkin non-increasing order according to the HPRV;
for all groupk∈taskGroups do
for allt∈groupkdo
calculate the EFT(t,p) ofton each processorpaccording to Eq. (6);
assigntonto the processorpwith the smallest EFT(t,p);
savet-ppairs into the scheduling sequence SL;
end for
end for
return SL;
3.2 LHSV algorithm
The LHSV algorithm is also divided into three stages: task levelization, task prioritization, and processor allocation. Among them, the former two phases are the same as the LOEFT algorithm, and the processor allocation phase assigns the processor with the smallest HSV value to the current task. The specific steps are shown in Algorithm 2.
Algorithm2LHSValgorithm
Input: DAG workflowG=(T,E,W,C), processors setP;
Output: task scheduling sequence SL.
taskGroups = ∅;
calculate the depth valuek of each tasktaccording to Eq.(1);
calculate the HPRV of each tasktaccording to Eq.(4);
groupt with the same depth valuekinto groupk, and all groupkform taskGroups;
sort groupkin taskGroups in ascending order according to the value ofk;
sort tasks in groupkin non-increasing order according to the HPRV;
for all groupk∈ taskGroups do
for allt∈ groupkdo
calculate the HSV (t,p) ofton each processorpaccording to Eq.(7);
assigntonto processorpwith the smallest HSV (t,p);
savet-ppairs into the scheduling sequence SL;
end for
end for
return SL;
3.3 HPEFT algorithm
The HPEFT algorithm is divided into two stages, namely, task prioritization and processor allocation. The stages are the same as the latter two stages of the LOEFT algorithm, respectively. The specific steps are shown in Algorithm 3.
Algorithm3HPEFT Algorithm
Input: DAG WorkflowG= (T,E,W,C), processors setP;
Output: task scheduling sequence SL.
calculate the HPRV of each tasktinGaccording to Eq.(4);
sort tasks inGin non-increasing order according to the HPRV;
for allt∈Gdo
calculate the EFT(t,p) ofton each processorpaccording to Eq.(6);
assigntonto the processorpwith the smallest EFT(t,p);
savet-ppairs into the scheduling sequence SL;
end for
return SL;
In the task levelization phase, all tasks are classified into different groups according to their own depth, and thus the time complexity isO(t2); in the task prioritization and processor allocation phase, all tasks and processors need to be traversed, which can be done inO(p×t2). Therefore, the time complexity of the LOEFT, LHSV and HPEFT algorithms are allO(p×t2), which is identical to that of the algorithm HEFT.
4 Experiments and Results
The HEFT algorithm was selected for comparison with LOEFT, LHSV, and HPEFT, and all algorithms were written in Java in a MacPro Workstation with Intel Xeon Quad-Core@2.80 GHz, 4 Cores, and 16 GB DDR3 RAM as the hardware configuration.Fast Fourier transform (FFT), Gaussian elimination (GE), Laplace, and random DAG instances generated by the Task Graph Generator (TGG)[27]are analyzed. TGG is a handy, easy to use tool specially designed to be used to develop task graphs that are needed for research works in the areas of task scheduling. Meanwhile, some parameters for generating task graphs, which are also consistently used in Refs. [17, 28-29], are given in Tab.2.
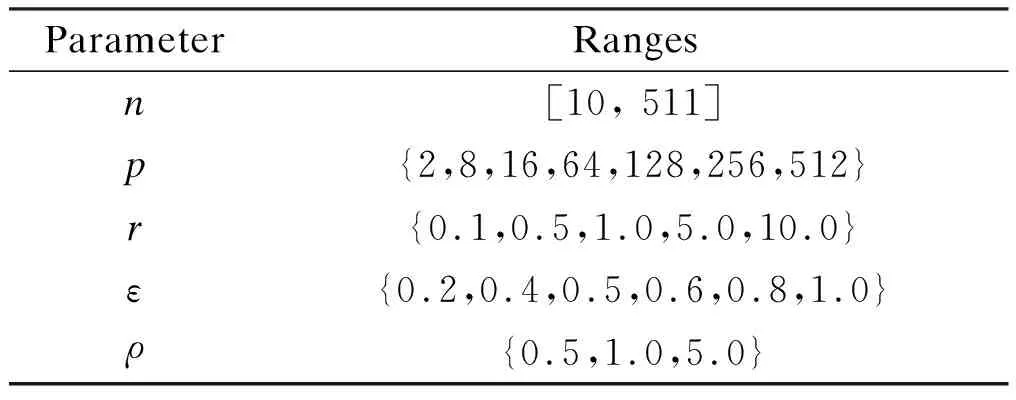
Tab.2 The important parameter settings of task graph generator
In particular,ndenotes the number of DAG nodes;pdenotes the number of processors.rmeans the communication-to-computation ratio; the smaller the ratio, the higher the communication cost, and vice versa.εis the heterogeneous factor; the smaller the factor, the higher the homogeneity.ρis the parallelism factor; the larger the factor, the higher the parallelism of application. Then, TGG takes these parameters as input and outputs some text files, which stores task-to-processor mappings, computation cost values, communication cost values, etc. Based on these output files, we further extract the values, construct the topology, and then import them into the algorithm to observe the resulting output. In each round of simulation, we try to diversify the combination of parameters as much as possible in order to simulate reality.
The two metrics,RandS, are presented to measure the performance of the algorithm.Ris the normalization of the scheduling length, that is
(9)
where the denomination is the summation of the minimum computation cost of the critical path execution time, and the moleculemis the actual execution time. The lowestRindicates the best algorithm with respect to performance.
Sdenotes the speedup, which is computed by dividing the minimum sequential execution time by the actual execution timemof the algorithm, which can be expressed as
(10)
where the sequential execution time is computed by assigning all tasks to a single processor that minimizes the cumulative computation costs. Contrary toR, the highestSindicates the best algorithm with respect to performance.
TheRandSvalues change with time. SmallerRvalue and largerSvalue indicate a greater efficiency of the algorithm.
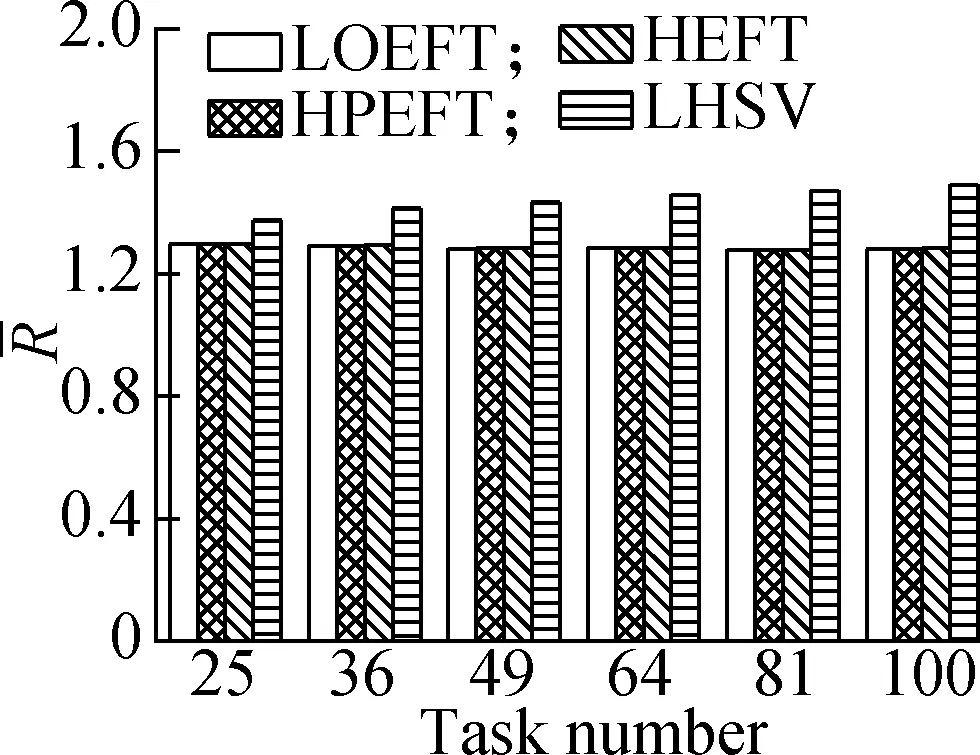
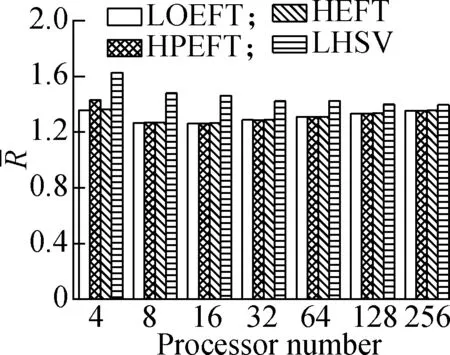
Experiment1This compares the change trend of theRvalue of each algorithm under the four different DAG workflows when the number of tasks changes. The specific steps are as follows: fixing other parameters (p,r,ε, andρ) and changing the number of tasks. The results are shown in Fig.2. The experimental analysis shows that the LOEFT algorithm performs best with the increase in the number of tasks. Its averageRvalue is 4.5% lower than that of the HEFT algorithm. In addition, theRvalue of the HPEFT algorithm is 0.3% higher than that of the HEFT algorithm. The LHSV algorithm is 8.9% higher than the HEFT algorithm. Moreover, the HPEFT algorithm is almost similar to the HEFT algorithm given that they share a similar philosophy when dealing with task scheduling. Meanwhile, the LOEFT and LHSV algorithms use task-level strategies to increase the number of concurrent tasks at the same level. However, the HSV value, which is adopted by the LHSV algorithm during the processor allocation phase, is equal to 0 when the iterating task is an exit task due to LDET(texit) = 0, that leads to a random choice of the processors totexit, thereby potentially extending the workflow completion time.
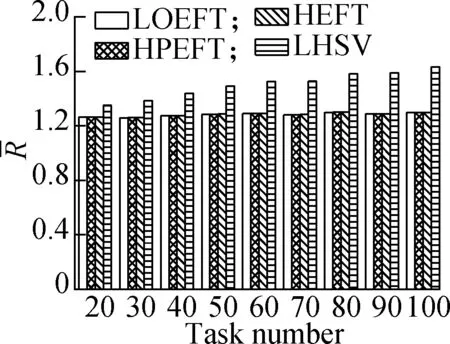
(a)
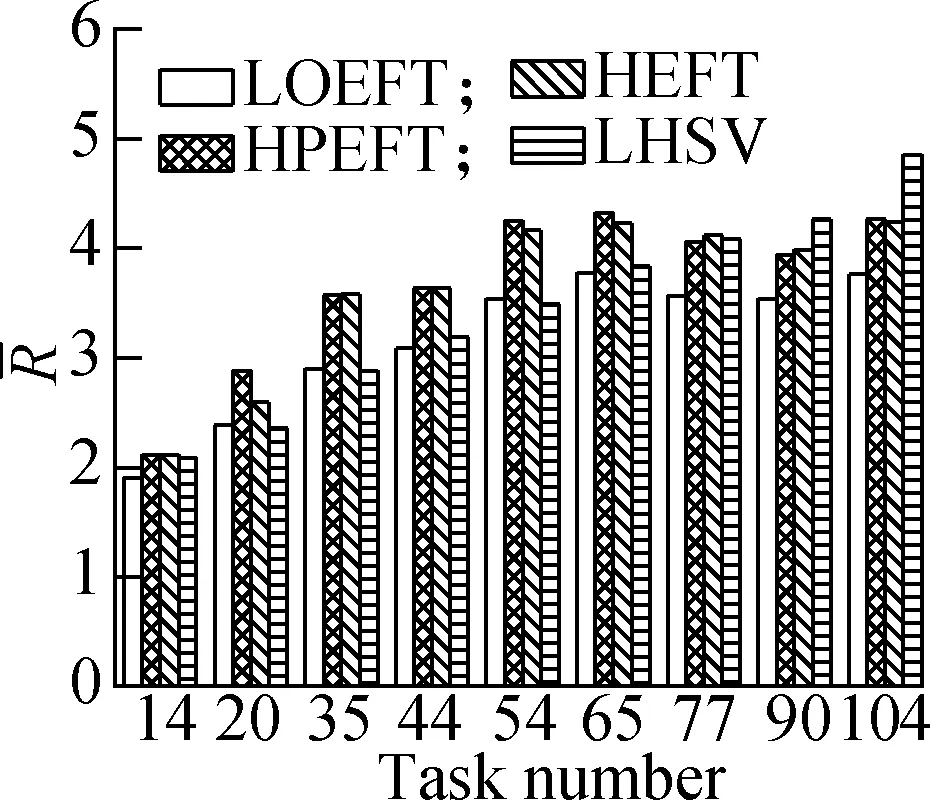
(b)

(c)
(d)
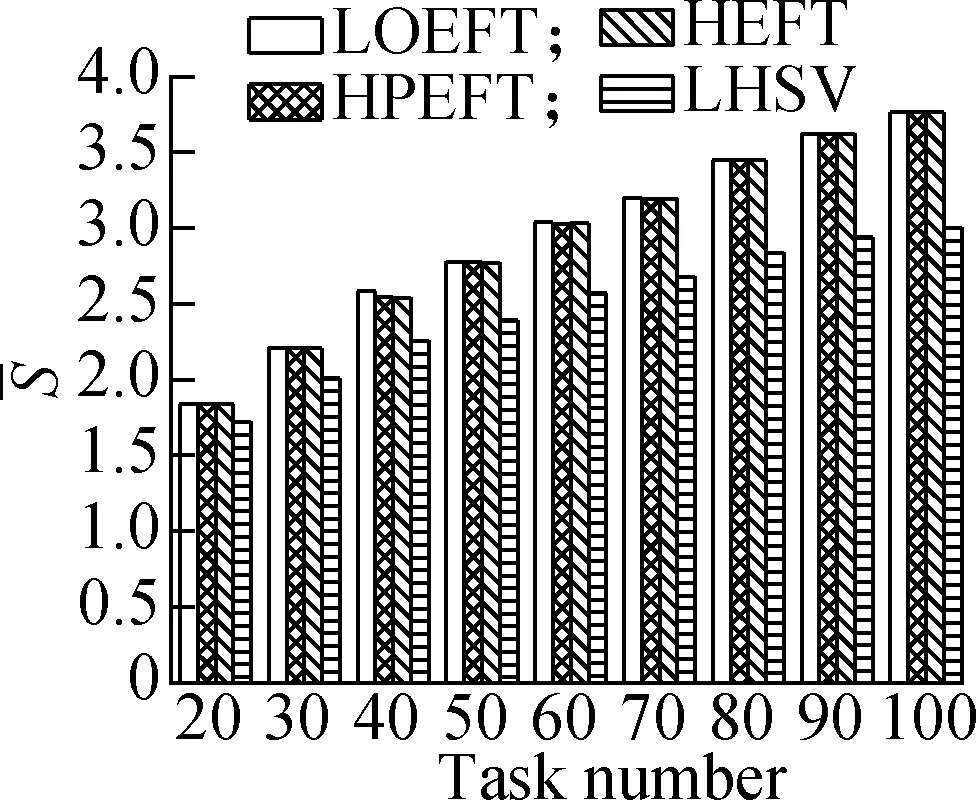
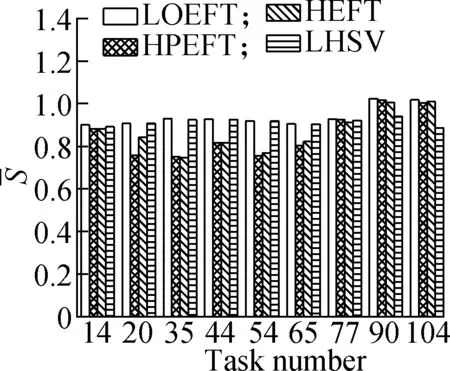
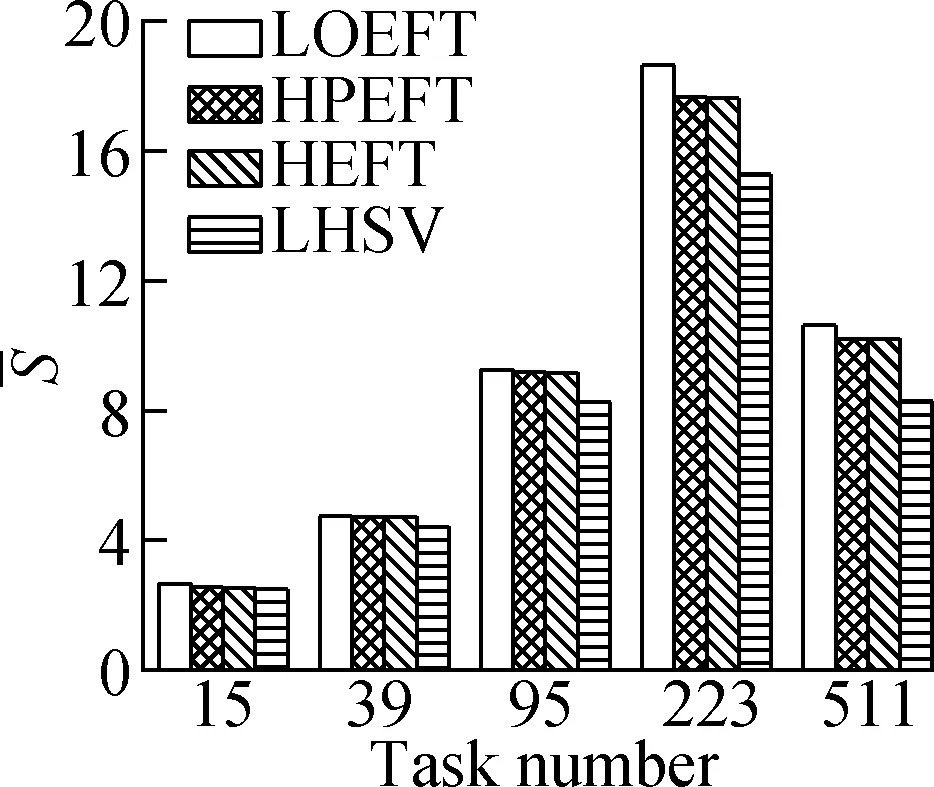
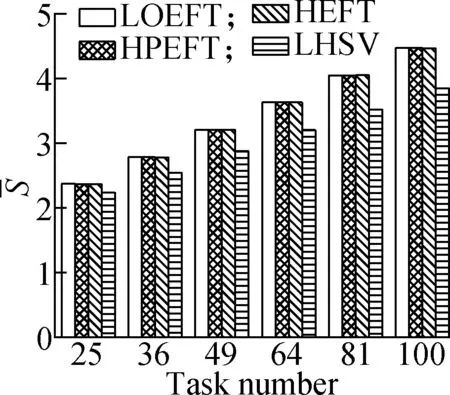
Experiment2This compares the trend of theSvalue of each algorithm under the four different DAG workflows when the number of tasks changes. The specific steps are the same as experiment 1. The results are shown in Fig.3. Through the experimental analysis, it is proved that with the increase in the number of tasks, the LOEFT algorithm shows the best performance among four approaches, with theSvalue being 3.1% higher than the HEFT algorithm. The HPEFT algorithm has the closest trend to the HEFT algorithm, and itsSvalue is reduced by 0.2%. The LHSV algorithm has the worst performance, and itsSvalue is reduced by 7.8%. The task priority phase of the LOEFT and the HPEFT algorithms is the same as their processor allocation phase. The LOEFT algorithm’s task-depth based levelization strategy increases the number of concurrent releases between tasks, and the LOEFT algorithm can obtain more accurate task prioritization, which reduces the difference caused by the processor performance difference.
(a)
(b)
(c)
(d)
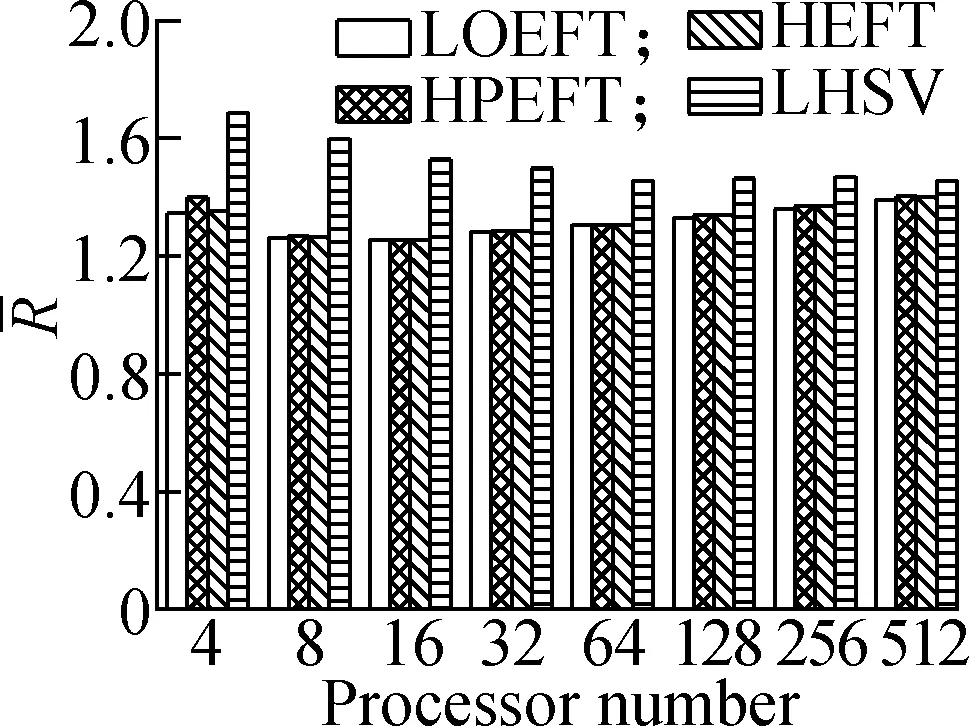
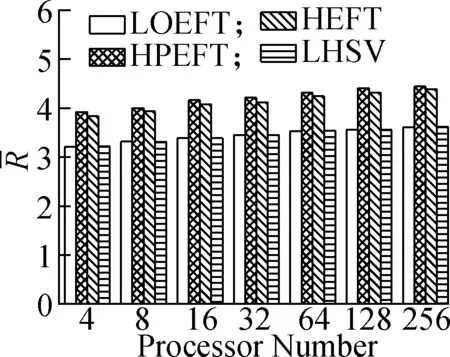
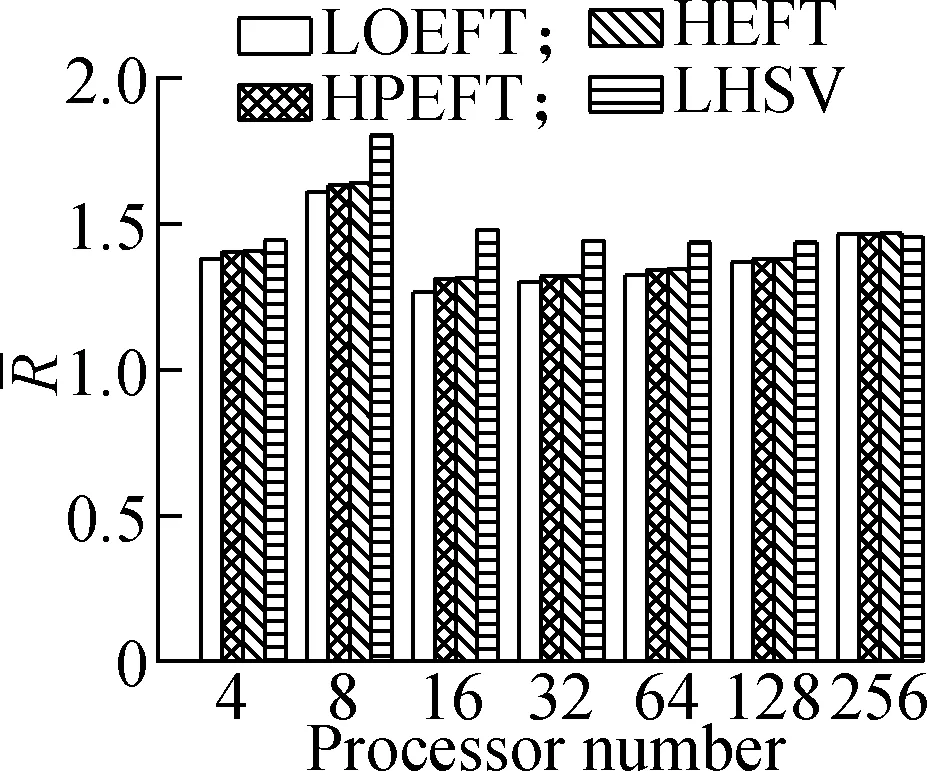
Experiment3This compares the change trend of theRvalue of each algorithm under the four different DAG workflows when the number of processors changes. The specific steps are as follows: fixing other parameters (n,r,ε, andρ) and changing the number of processors. The obtained results are shown in Fig.4. According to the experimental analysis, in the process of increasing the number of processors, the increasing order of the averageRvalue is as follows: LOEFT, HEFT, HPEFT, and LHSV. TheRvalue of the LOEFT algorithm is 4.7% lower than that of the HEFT algorithm, and theRvalues of the HPEFT and LHSV algorithms are 0.7% and 4% higher than that of the HEFT algorithm, respectively. This is caused by the task prioritization obtained by the LOEFT algorithm that achieves precise positioning of the processor on the basis of more accurate task prioritization. In addition, the HSV value, which is the selection criterion of the LHSV algorithm processor, misjudges the exit task, thereby extending the completion time of the workflow.
(a)
(b)
(c)
(d)
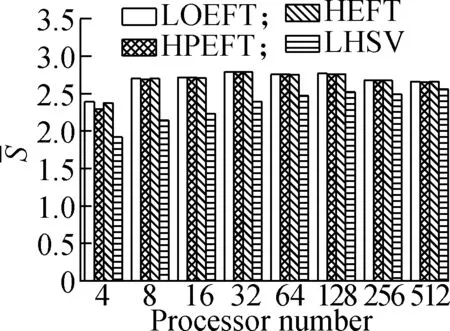
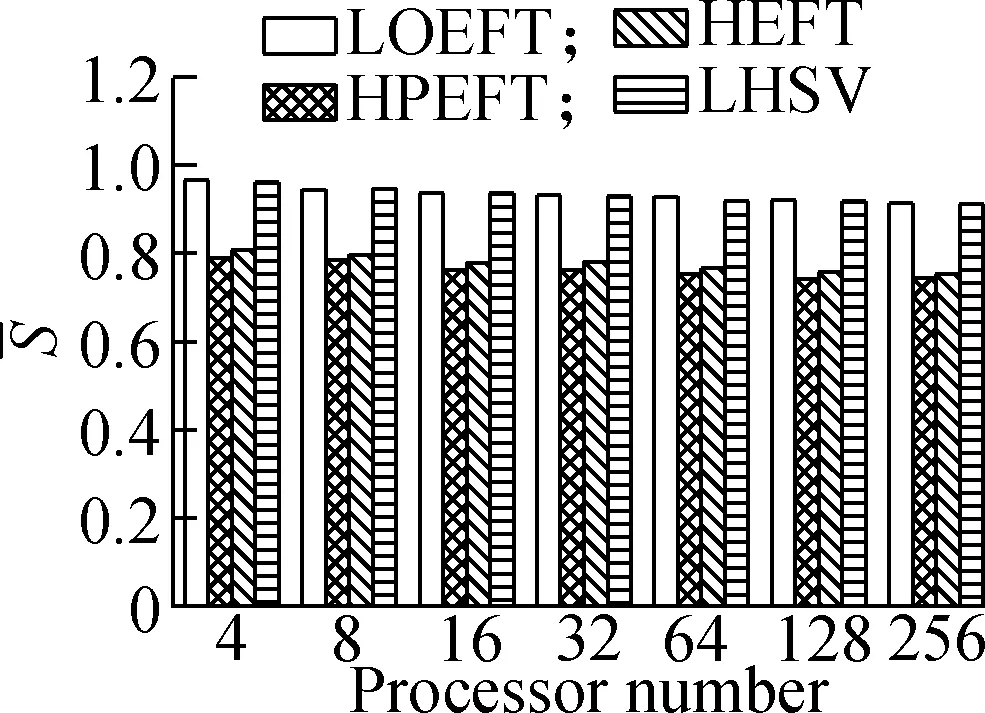
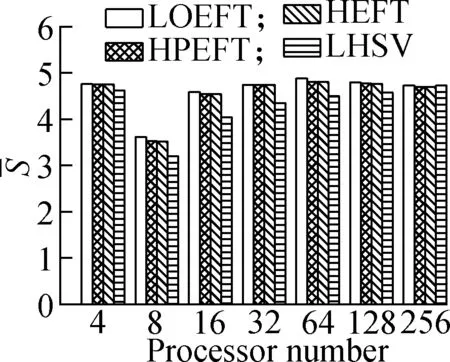
Experiment4It compares each algorithm’sSvalue under the four different DAG workflows when the number of processors changes. The specific steps are the same as experiment 3. The results are shown in Fig.5. According to the experimental analysis, with the increase in processor number, the decreasing order of the averageSvalue is as follows: LOEFT, HEFT, HPEFT, and LHSV. Compared with the HEFT algorithm, the change trend of the LOEFT algorithm positively increases, the change trend of the HPEFT algorithm is the closest, and the change trend of the LHSV algorithm negatively increases. This result also confirms the conclusion drawn from the previous experiments that the LOEFT algorithm has a clear advantage over the three algorithms in terms of time optimization.
(a)
(b)
(c)
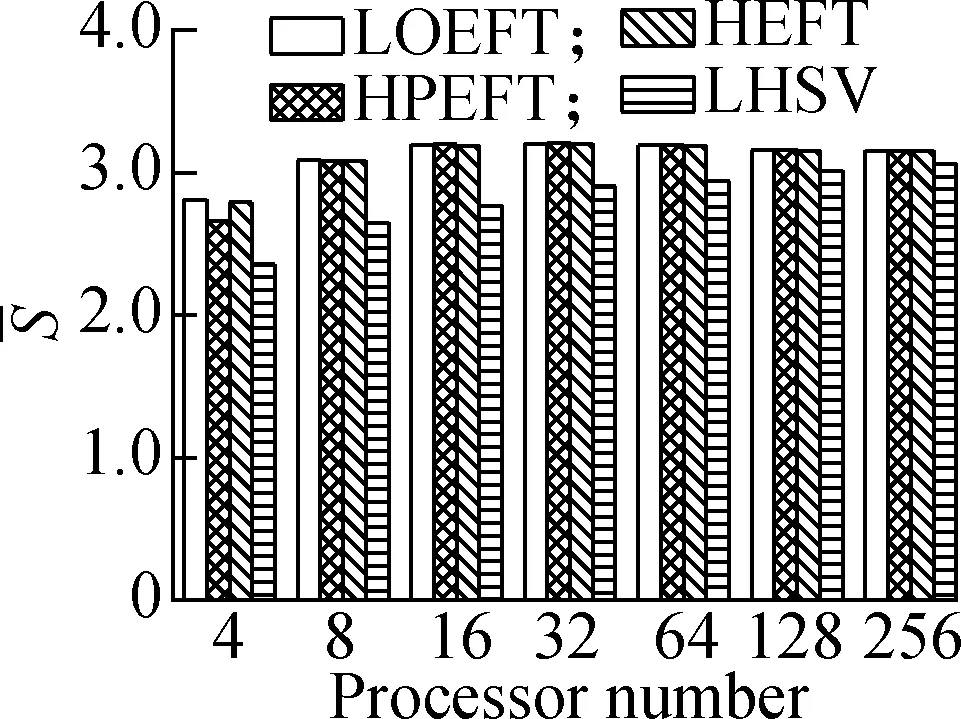
(d)
5 Conclusions
1)As application completion time has a profound impact on users, systems, and the environment, optimizing it is an ongoing research topic in computing systems.
2)As a special application, workflow is commonly used in scientific research. Aiming at the scheduling time optimization problem of the static workflow under the heterogeneous distributed computing system, three algorithms are proposed, namely, LOEFT, LHSV, and HPEFT. In particular, task depth is incorporated into task out-degree, thus enabling the proposed algorithms to minimize workflow completion time in a simple and efficient manner. Among them, the LOEFT algorithm has achieved excellent scheduling results.
3)The model studied in this paper is relatively simple, and the proposed equation is coarse in granularity. Thus, there is a possibility for further improvement. Next, we will highlight the difficulty of the problem and consider imposing a duplication strategy for tasks with a large out-degree, and simultaneously optimize the time and reliability of workflow scheduling.
杂志排行

Journal of Southeast University(English Edition)的其它文章
- Bandwidth-enhanced dual-polarized antenna with improvedbroadband integrated balun and distributed parasitic element
- UAV trajectory planning algorithmfor data collection in wireless sensor networks
- A multi-attention RNN-based relation linking approach for question answering over knowledge base
- Q-learning-based energy transmission scheduling over a fading channel
- Centre symmetric quadruple pattern-based illumination invariant measure
- Flexural behaviour of SFRRAC two-way composite slab with different shapes