Centre symmetric quadruple pattern-based illumination invariant measure
2021-01-12HuChanghuiZhangYangLuXiaoboLiuPan
Hu Changhui Zhang Yang Lu Xiaobo Liu Pan
(1School of Automation, Southeast University, Nanjing 210096, China)(2Key Laboratory of Measurement and Control of Complex Systems of Engineering of Ministry of Education, Southeast University, Nanjing 210096, China)(3School of Transportation, Southeast University, Nanjing 211189, China)
Abstract:A centre symmetric quadruple pattern-based illumination invariant measure (CSQPIM) is proposed to tackle severe illumination variation face recognition. First, the subtraction of the pixel pairs of the centre symmetric quadruple pattern (CSQP) is defined as the CSQPIM unit in the logarithm face local region, which may be positive or negative. The CSQPIM model is obtained by combining the positive and negative CSQPIM units. Then, the CSQPIM model can be used to generate several CSQPIM images by controlling the proportions of positive and negative CSQPIM units. The single CSQPIM image with the saturation function can be used to develop the CSQPIM-face. Multi CSQPIM images employ the extended sparse representation classification (ESRC) as the classifier, which can create the CSQPIM image-based classification (CSQPIMC). Furthermore, the CSQPIM model is integrated with the pre-trained deep learning (PDL) model to construct the CSQPIM-PDL model. Finally, the experimental results on the Extended Yale B, CMU PIE and Driver face databases indicate that the proposed methods are efficient for tackling severe illumination variations.
Key words:centre symmetric quadruple pattern; illumination invariant measure; severe illumination variations; single sample face recognition
Severe illumination variation is considered to be one of the serious issues for the face image in the outdoor environment, such as the driver face image in the intelligent transportation systems[1]. Hence, it is important to address illumination variations in face recognition, especially for severe illumination variation. The face illumination invariant measures[2-4]were developed based on the lambertian reflectance model[5].
Due to the commonly-used assumption that illumination intensities of neighborhood pixels are approximately equal in the face local region, the illumination invariant measure constructed the reflectance-based pattern by eliminating illumination of the pixel face. The Weber-face[2]proposed a simple reflectance-based pattern that the difference between the center pixel and its neighbor pixel was divided by the center pixel in the 3×3 block region. The multiscale logarithm difference edgemaps (MSLDE)[3]was obtained from the multi local edge regions of the logarithm face. The local near neighbor face (LNN-face)[4]was attained from the multi local block regions of the logarithm face. In MSLDE and LNN-face, different weights were assigned to different local edge or block regions, whereas the edge-region-based generalized illumination robust face (EGIR-face) and the block-region-based generalized illumination robust face (EGIR-face) removed the weights associated with multi edge and block regions, respectively[1]. The EGIR-face and BGIR-face were obtained by combining the positive and negative illumination invariant units in the logarithm face local region.
The local binary pattern (LBP)-based approach was an efficient hand-crafted facial descriptor, and was robust to various facial variations. The centre symmetric local binary pattern (CSLBP)[6]employed the symmetric pixel pairs around the centre pixel in the 3×3 block region to code the facial feature. Recently, the centre symmetric quadruple pattern (CSQP)[7]extended the centre symmetric pattern to quadruple space, which can effectively recognize the face image with variations of illumination, pose and expression.
Nowadays, the deep learning feature is the best for face recognition, which requires massive available face images to train. VGG[8]was trained by 2.6 M internet face images (2 622 persons and 1 000 images per person). ArcFace[9]was trained by 85 742 persons and 5.8 M internet face images. As large-scale face images for training the deep learning model are collected via internet, the deep learning feature performed very well on internet face images. However, the internet face images are without severe illumination variations, and thus the deep learning feature performed unsatisfactorily under severe illumination variations[10].
In this paper,the centre symmetric quadruple pattern based illumination invariant measure (CSQPIM) is proposed to tackle severe illumination variations. The CSQPIM model is obtained by combining the positive and negative CSQPIM units, and then the CSQPIM model is used to generate several CSQPIM images of the single image. The single CSQPIM image with the arctangent function develops the CSQPIM-face. Multi CSQPIM images employ the extended sparse representation classification (ESRC) to form the CSQPIM image-based classification (CSQPIMC). Furthermore, the CSQPIM model is integrated with the pre-trained deep learning model (PDL), which is termed as CSQPIM-PDL for brevity.
1 Centre Symmetric Quadruple Pattern
The centre symmetric pattern was widely used in the LBP-based approach, and the most recent one is CSQP[7]which extended the centre symmetric pattern to quadruple space. The quadruple space is based on a 4×4 block region, which means that the CSQP codes the LBP-based facial feature in a face local region with the size of 4×4 pixels. The CSQP divided the local kernel of the size 4×4 into 4 sub-blocks of the size 2×2. Fig.1 shows the centre symmetric quadruple pattern. Suppose thatm≥n, the pixel imageIhasmrows andncolumns. In Fig.1,I(i,j) denotes the pixel intensity at location (i,j), where location (i,j) denotes the image point of thei-th row and thej-th column.

Fig.1 The centre symmetric quadruple pattern
The CSQP code[7]is calculated as
A(i,j)=27×C(I(i,j),I(i+2,j+2))+
26×C(I(i,j+1),I(i+2,j+3))+
25×C(I(i+1,j),I(i+3,j+2))+
24×C(I(i+1,j+1),I(i+3,j+3))+
23×C(I(i,j+2),I(i+2,j))+
22×C(I(i,j+3),I(i+2,j+1))+
21×C(I(i+1,j+2),I(i+3,j)+
20×C(I(i+1,j+3),I(i+3,j+1)))
(1)
(2)
whereI1andI2are two pixels in the CSQP. From Eqs.(1) and (2), the CSQP codeA(i,j) is a decimal number. The CSQP[7]can efficiently capture diagonal asymmetry and vertical symmetry in a facial image.
2 CSQP-Based Illumination Invariant Measure
One of the major contribution of the CSQP[7]is that the 4×4 face local region is employed. The even×even block region such as the 4×4 block has no centre pixel in the face local region, whereas the odd×odd block region such as the 3×3 block or the 5×5 block has a centre pixel. The current illumination invariant measure usually used the odd×odd block region. The even×even block region has never been used in the illumination invariant measure. In this paper, the 4×4 block region CSQP is extended to the illumination invariant measure.
From the lambertian reflectance model[5], the logarithm image can be presented asI(i,j) = lnR(i,j) + lnL(i,j), whereRandLare the reflectance and illumination, respectively. Fig.2 shows the proposed CSQPIM pattern, which is a logarithm version of the CSQP in Fig.1. According to the commonly-used assumption of the illumination invariant measure that illumination intensities are approximately equal in the face local region, the CSQPIM units are defined as
U1=ln(I(i,j))-ln(I(i+2,j+2))=
ln(R(i,j))-ln(R(i+2,j+2))
(3)
U2=ln(I(i,j+1))-ln(I(i+2,j+3))=
ln(R(i,j+1))-ln(R(i+2,j+3))
(4)
U3=ln(I(i+1,j))-ln(I(i+3,j+2))=
ln(R(i+1,j))-ln(R(i+3,j+2))
(5)
U4=ln(I(i+1,j+1))-ln(I(i+3,j+3))=
ln(R(i+1,j+1))-ln(R(i+3,j+3))
(6)
U5=ln(I(i,j+2))-ln(I(i+2,j))=
ln(R(i,j+2))-ln(R(i+2,j))
(7)
U6=ln(I(i,j+3))-ln(I(i+2,j+1))=
ln(R(i,j+3))-ln(R(i+2,j+1))
(8)
U7=ln(I(i+1,j+2))-ln(I(i+3,j))=
ln(R(i+1,j+2))-ln(R(i+3,j))
(9)
U8=ln(I(i+1,j+3))-ln(I(i+3,j+1))=
ln(R(i+1,j+3))-ln(R(i+3,j+1))
(10)
The CSQPIM unitUk(k=1,2,…,8) is the subtraction of the pixel pairs of the CSQPIM pattern. As illumination intensities are approximately equal in the CSQPIM pattern,the CSQPIM unitUkcan be represented by the logarithm reflectance subtraction of the CSQPIM pixel pairs, which is independent of the illumination. Hence,Uk(k=1,2,…,8) can be used to develop the illumination invariant measure.

Fig.2 The CSQPIM pattern

(11)
From Eq.(3), the CSQPIM image can be written as
(12)
whereαis the weight to control the balance of positive and the negative CSQPIM units, and 0≤α≤2. From Eq.(12), the CSQPIM-face is obtained by the CSQPIM image with the arctangent function,

(13)
where parameter 4 is the same as that recommended in Ref.[3]. Some CSQPIM images and CSQPIM-faces are shown in Fig.3. In the first row, 5 original images with different illumination variations are from one single face. The second row contains the logarithm images of the 5 original images in the first row. Each of the third rows to the seventh row contains CSQPIM images of the 5 original images in the first row. Each of the eighth rows to the twelfth row contains CSQPIM-faces of the 5 original images in the first row. Compared with Refs.[1, 3-4], the CSQPIM image and CSQPIM-face are quite different from previous illumination invariant measures.

Fig.3 Some CSQPIM images and CSQPIM-faces under different parameters
3 Classification of the CSQPIM image
3.1 Single CSQPIM image classification
According to Refs.[1-4], the high-frequency interference seriously impacts the performance of the illumination invariant measure under the template matching classification method, which can be tackled by the saturation function well. Hence, the illumination invariant measure with the saturation function (i.e. CSQPIM-face) is more efficient than the illumination invariant measure without the saturation function (i.e. CSQPIM image) for the single image recognition by the template matching classification method, such as the nearest neighbor classifier. In this paper, The CSQPIM-face is employed to tackle the single CSQPIM image recognition under the nearest neighbor classifier, and parameterα=0.4 in Eq.(13) is adopted under severe illumination variations, which is the same as that recommended in Ref.[1].
3.2 Multi CSQPIM images classification
In many practical applications, such as the driver face recognition in the intelligent transportation systems[1], the severe illumination variation and single sample problem coexist. Similar to Ref.[1], Eq.(12) is used to generate multi training CSQPIM images of the single training image by different parameterα. Multi CSQPIM images employ the noise robust ESRC[11]to tackle severe illumination variation face recognition with a single sample problem. Multi training CSQPIM images contain more intra class variations of the single training image as shown in Fig.3, which can improve the representation ability of ESRC. In this paper, we select three CSQPIM images withα=0.4, 1, and 1.6 to form multi training CSQPIM images of each single training image, which is the same as that recommended in Ref.[1]. Accordingly, the CSQPIM image of the test image is also generated byα=1, and the CSQPIM image of each generic image is also generated byα=1.
In this paper, ESRC with multi CSQPIM images is termed as multi CSQPIM images-based classification (CSQPIMC). The homotopy method[12]is used to solve theL1-minimization problem in the CSQPIMC.
3.3 Multi CSQPIM images and the pre-trained deep learning model based classification
Similar to Ref.[1], the proposed CSQPIM model can be integrated with the pre-trained deep learning model. The ESRC can be used to classify the state-of-the-art deep learning feature. The representation residual of the CSQPIMC can be integrated with the representation residual of the ESRC of the deep learning feature to conduct the final classification, which is termed as multi CSQPIM images and the pre-trained deep learning model-based classification (CSQPIM-PDL).
In this paper, the pre-trained deep learning models VGG[8]and ArcFace[9]are adopted. Multi CSQPIM images and VGG (or ArcFace)-based classification is briefly termed as CSQPIM-VGG (or CSQPIM-ArcFace).
4 Experiments
The CSQPIM model is proposed to tackle severe illumination variations. The performances of the proposed methods are validated on the benchmark Extended Yale B[13], CMU PIE[14]and Driver[4]face databases. In this paper, all cropped face images and experimental settings are the same as those in Ref.[1]. The recognition rates of Tabs.1 and 2 are the same as those in Ref.[1] (i.e. Tabs.Ⅲ, Ⅳ and Ⅴ in Ref.[1]) except for the proposed method. Tabs.1 and 2 list average recognition rates of the compared methods on the Extended Yale B, CMU PIE and Driver. Fig.4 shows some used images from Extended Yale B, CMU PIE and Driver face databases.
The Extended Yale B face database[13]contains grayscale images of 28 persons. 64 frontal face images of each person are divided into subsets 1 to 5 with illumination variations from slight to severe. Subsets 1 to 5 consist of 7,12,12,14 and 19 images per person, respectively. As the deep learning feature requires a color face image, three RGB channels use the same grayscale image for the experiments on the Extended Yale B.
The CMU PIE[14]face database incorporates color images of 68 persons. 21 images of each person from each of C27 (frontal camera), C29 (horizontal 22.5° camera) and C09 (above camera) in CMU PIE illum set are selected. CMU PIE face images show slight, moderate, and severe illumination variations. According to Ref.[14], the pose variation of C29 is larger than that of C09.
The simulative Driver database[4]was built to research the identity recognition problem for drivers in intelligent transportation systems and can be regarded as a practical scenarios-based face database. This database incorporates 28 people with each containing 22 images (12 images indoors and 10 images in cars).
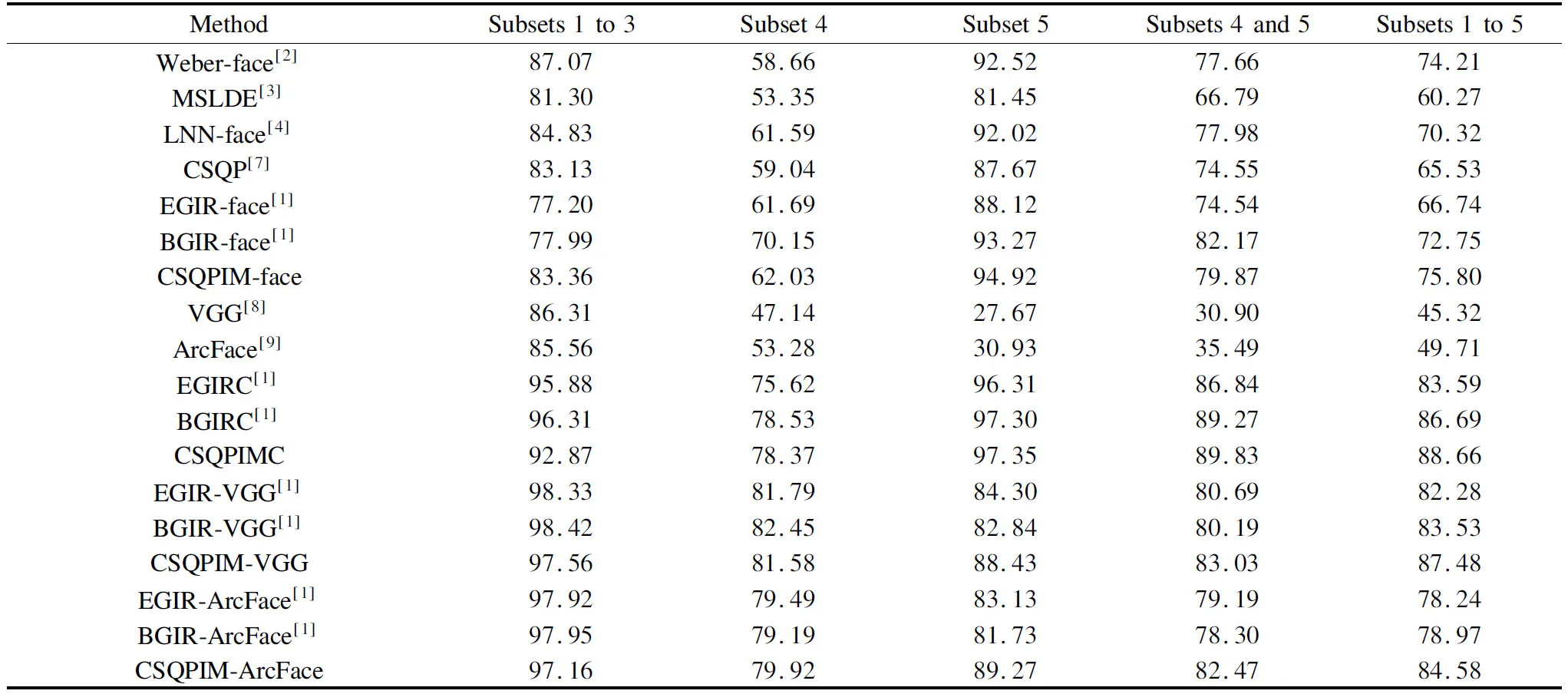
Table.1 The average recognition rates of the compared methods on the Extended Yale B face database %

Table.2 Average recognition rates of the compared methods on the CMU PIE and Driver face databases %

Fig.4 Some images from Extended Yale B, CMU PIE, and Driver face databases
4.1 Experiments on the Extended Yale B face database
The Extended Yale B face database is has extremely challenging illumination variations. Face images in subsets 1 to 3 have slight and moderate illumination variations, where subsets 1 and 2 face images have slight illumination variations, and subset 3 face images have small scale cast shadows. Face images in subsets 4 and 5 have severe illumination variations, where subset 4 face images have moderate scale cast shadows, and subset 5 face images have large scale cast shadows (or severe holistic illumination variations).
From Tab.1, CSQPIM-face outperforms EGIR-face, BGIR-face, MSLDE and LNN-face on all Extended Yale B datasets, except that CSQPIM-face lags behind BGIR-face on subset 4 and subsets 4-5, and LNN-face on subsets 1-3. Although moderate scale cast shadows of subset 4 images are not as severe as the large-scale cast shadows of subset 5 images, moderate scale cast shadows incorporate more edges of cast shadows than large scale cast shadows as shown in Fig.4. Edges of cast shadows of face images violate the assumption of the illumination invariant measure that illumination intensities are approximately equal in the local face block region.
CSQPIMC performs better than CSQPIM-face. There may be two main reasons. One is that multi CSQPIM images contain more intra class variation information than the single CSQPIM image, and the other one is that ESRC is more robust than NN under illumination variations. CSQPIMC outperforms EGIRC and BGIRC under severe illumination variations such as on subset 5, subsets 4-5 and subsets 1 to 5, whereas CSQPIMC slightly lags behind BGIRC on subset 4.
VGG/ArcFace was trained by large scale light internet face images, without considering severe illumination variations, and it performs well on subsets 1 to 3, but is unsatisfactory under severe illumination variations such as those on subsets 4 and 5. CSQPIM-VGG performs better than EGIR/BGIR-VGG on subset 5, subsets 4 and 5 and subsets 1 to 5. CSQPIM-ArcFace outperforms EGIR/BGIR-ArcFace on all Extended Yale B datasets except on subsets 1 to 5. Despite CSQPIM-VGG/ArcFace being unable to attain the highest recognition rates on all datasets, CSQPIM-VGG/ArcFace achieves very high recognition rates on all Extended Yale B datasets. Hence, the proposed CSQPIM-PDL model has the advantages of both the CSQPIM model and the pre-trained deep learning model to tackle face recognition.
4.2 Experiments on the CMU PIE face database
Some CMU PIE face images are bright (i.e. slight illumination variations), and others are partially dark (i.e. with moderate and severe illumination variations). Illumination variations of CMU PIE are not as extreme as those of Extended Yale B. From Fig.4, images in each of C27, C29 and C09 have the same pose (i.e.,frontal, 22.5° profile and downward, respectively), whereas images in each of C27+C29 and C27+C09 incorporate two face poses (i.e.,frontal pose and non-frontal pose).
From Tab.2, CSQPIM-face achieves very high recognition rates on C27, C29 and C09, and performs much better than EGIR-face, BGIR-face, MSLDE and LNN-face on all CMU PIE datasets. However, CSQPIM-face lags behind VGG/ArcFace on C27+C29 and C27+C09. It can be seen that CSQPIM-face is very robust to severe illumination variations under a fixed pose, whereas it is sensitive to pose variations. Although CSQPIM-face outperforms EGIR-face, BGIR-face, MSLDE and LNN-face under pose variations, these shallow illumination invariant approaches perform unsatisfactorily under pose variations.
However,CSQPIM-VGG/ArcFace performs very well on all CMU PIE datasets, which illustrates that the CSQPIM-PDL model can achieve satisfactory results under both severe illumination variations and pose variations. Hence, the CSQPIM-PDL model is robust to both illumination variations and pose variations. As CSQPIM-face is superior to EGIR-face and BGIR-face under severe illumination variations, CSQPIM-VGG/ArcFace is slightly better than EGIR-VGG/ArcFace and BGIR-VGG/ArcFace on C27, C29 and C09, whereas they achieve a similar performance on C27+C29 and C27+C09, since VGG/ArcFace is the dominant feature under pose variations.
4.3 Experiments on the Driver face database
The Driver face images were taken under manually controlled lighting. From Fig.4, illumination variations of Driver face images are slight and moderate, and not as severe as those of Extended Yale B and CMU PIE. From Tab.2, CSQPIM-face achieves rational recognition rates on Driver, whereas it lags behind other illumination invariant measures such as EGIR-face, BGIR-face, LNN-face, and MSLDE. Moreover, the CSQPIM-face even lags behind CSQP, which means that the CSQPIM-face cannot tackle slight and moderate illumination variations well. Hence, CSQPIM-VGG and CSQPIM-ArcFace lag behind EGIR/BGIR-VGG and EGIR/BGIR-ArcFace on Driver.
5 Conclusion
This paper proposes a CSQPIM model to address severe illumination variation face recognition. CSQPIM-face achieves higher recognition rates compared to the previous illumination invariant approaches EGIR-face, BGIR-face, LNN-face and MSLDE under severe illumination variations. CSQPIMC is effective for severe illumination variations due to the fact that multi CSQPIM images cover more discriminative information of the face image. Furthermore, the proposed CSQPIM model is integrated with the pre-trained deep learning model to have the advantages of both the CSQPIM model and the pre-trained deep learning model.
杂志排行

Journal of Southeast University(English Edition)的其它文章
- Mechanism of coconut husk activated carbon modified by Mn(NO3)2
- Gorenstein dimensions for weak Hopf-Galois extensions
- Research on replacement depth of black cotton soil based on cracking behavior of embankment
- Pricing decision of green supply chain under the game competition of duopolistic retailers
- Design of cost allocation rule for joint replenishment with controllable lead time
- Effect improvement of drug pricing reform based on multi-channel coordination