A multi-attention RNN-based relation linking approach for question answering over knowledge base
2021-01-12LiHuiyingZhaoManYuWenqi
Li Huiying Zhao Man Yu Wenqi
(School of Computer Science and Engineering, Southeast University, Nanjing 211189, China)
Abstract:Aiming at the relation linking task for question answering over knowledge base, especially the multi relation linking task for complex questions, a relation linking approach based on the multi-attention recurrent neural network(RNN) model is proposed, which works for both simple and complex questions. First, the vector representations of questions are learned by the bidirectional long short-term memory(Bi-LSTM) model at the word and character levels, and named entities in questions are labeled by the conditional random field(CRF) model. Candidate entities are generated based on a dictionary, the disambiguation of candidate entities is realized based on predefined rules, and named entities mentioned in questions are linked to entities in knowledge base. Next, questions are classified into simple or complex questions by the machine learning method. Starting from the identified entities, for simple questions, one-hop relations are collected in the knowledge base as candidate relations; for complex questions, two-hop relations are collected as candidates. Finally, the multi-attention Bi-LSTM model is used to encode questions and candidate relations, compare their similarity, and return the candidate relation with the highest similarity as the result of relation linking. It is worth noting that the Bi-LSTM model with one attentions is adopted for simple questions, and the Bi-LSTM model with two attentions is adopted for complex questions. The experimental results show that, based on the effective entity linking method, the Bi-LSTM model with the attention mechanism improves the relation linking effectiveness of both simple and complex questions, which outperforms the existing relation linking methods based on graph algorithm or linguistics understanding.
Key words:question answering over knowledge base(KBQA); entity linking; relation linking; multi-attention bidirectional long short-term memory(Bi-LSTM); large-scale complex question answering dataset(LC-QuAD)
Question answering over knowledge base(KBQA) is an active research area that allows answers to be obtained from knowledge base based on natural language input. Some KBQA systems have been intensively studied for simple questions, which can be answered by one fact in the knowledge base. Even though this task is called “simple”, it is actually not simple at all and is far from being solved perfectly. Moreover, the demand for complex question answering has increased quickly. Answering a complex question can require references to multiple related facts in the knowledge base.
An important line of KBQA research is the step-by-step pipeline method based on semantic parsing. Singh et al.[1]proposed a KBQA component framework to dynamically choose components to create a complete question answering pipeline. A KBQA pipeline consists of three key components:1) Entity linking, which linksn-grams to knowledge base entities; 2) Relation linking, which identifies the knowledge base relation(s) to which a question refers; and 3) Query building, which builds the structured query to obtain answers from the knowledge base.
Relation linking, linking the extracted relations from the input question to their knowledge base occurrences, is a core component of the KBQA pipeline. In this work, we propose a multi-attention recurrent neural network(RNN)-based relation linking approach that can deal with relation linking problems for both simple and complex questions. For the input question, entity linking, the basic component of the KBQA pipeline, recognizes the entity mentions and links them to the corresponding entities in the knowledge base first. Then, a classifier is used to judge whether the question is complex or not. Based on the judgement, different relation linking models are used. For a simple question, a one-attention bidirectional long short-term memory (Bi-LSTM) model is applied to detect one relation from the question. For a complex question, a two-attention Bi-LSTM model is applied to detect two relations from the question.
1 Related Work
Given a natural language question, entity linking and relation linking are the core tasks for question answering. There is a wide range of tools and research work in the area of entity linking. Mostly, research in this domain targets news corpora, documents and Wikipedia abstracts with long sentences. Based on a vector-space representation of entities, DBpedia Spotlight[2]uses the cosine similarity to rank candidate entities. AIDA[3]builds a coherence graph and applies dense subgraph algorithms for entity linking. Babelfy[4]uses the random walk and the densest subgraph algorithm to tackle the word sense disambiguation and entity linking tasks jointly. FOX[5]deals with named entity recognition based on ensemble learning. However, when these tools are applied to short text in a new domain such as question answering, the performance is limited. Considering short text, TAGME[6]recognizes named entities by matching terms with Wikipedia link texts and disambiguates the match using the in-link graph and the page dataset. KEA[7]begins with the detection of groups ofn-grams and a lookup of all potential candidate entities for eachn-gram. The disambiguation of candidate entities is based on local and context-related features.
Relation linking is a relatively new research area compared to entity linking. SIBKB[8]represents a background knowledge base as a bi-partite and a dynamic index over the relation patterns included in the knowledge base. A relation linking component is proposed based on the semantic index. With the recent progress of deep learning, neural network (NN)-based methods have been introduced to the relation linking task. NN-based methods represent both the questions and the relations as semantic vectors. Then, the relation linking process can be converted into a similarity matching process between an input question and its candidate relations in a semantic space. The candidates with the highest similarity score will be selected as the final relations. The main difference among these approaches lies in the encoder model and the input granularity. The encoder model can be an RNN model or a convolutional neural network (CNN) model. The input granularity can be word level or character level granularity. ReMatch[9]characterizes both the properties in knowledge and the relations in a question as comparable triples, then leverages both synonyms and semantic similarity measures based on graph distances from Wordnet (https://wordnet.princeton.edu/). Yu et al.[10]proposed a hierarchical RNN enhanced by residual learning for relation detection. Both EARL[11]and Falcon[12]perform joint entity and relation linking. EARL implements two different solution strategies. The first strategy formalizes the problem as an instance of the generalized traveling salesman (GTSP) problem and solves it with an approximation algorithm. The second strategy uses a machine learning method in order to exploit the connection density between nodes in the knowledge graph. Falcon performs joint entity and relation linking of a short text by using a light-weight linguistic approach. It utilizes an extended knowledge graph created by merging entities and relations from various knowledge sources for candidate generation. Specifically, it leverages several fundamental principles of English morphology (e.g. compounding, headword identification) for candidate ranking.
Although there has been some research on entity and relation linking, solving the task of relation linking is still very challenging, especially the relation linking task for complex questions.
2 Method
In this section, we introduce the overall architecture of our approach, followed by our dictionary-based entity linking approach and the multi-attention RNN based relation linking approach.
2.1 Overview
The general framework of the proposed approach is shown in Fig.1. Let us consider an example to explain the underlying idea:How many developers make software for Unix-like operating systems? The entity linking component is expected to recognize the mention “Unix-like” as a named entity and link it to the corresponding entity “dbr:Unix-like” in the knowledge base. The relation linking component classifies the question into simple and complex categories. For a simple question, a one-attention Bi-LSTM is applied to detect one relation from the question. For a complex question, a two-attention Bi-LSTM is applied to detect two relations from the question.
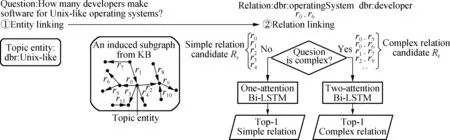
Fig.1 Overall architecture of the proposed approach
2.2 Entity linking
Entity linking is the first component of the QA pipeline, and the results greatly affect the following components. In general, entity linking is a two-step process to obtain the topic entity from the question. The first step is to recognize the named entity mention. The second step is to disambiguate or link the entity to the knowledge base. The general framework of the proposed entity linking approach is shown in Fig.2.
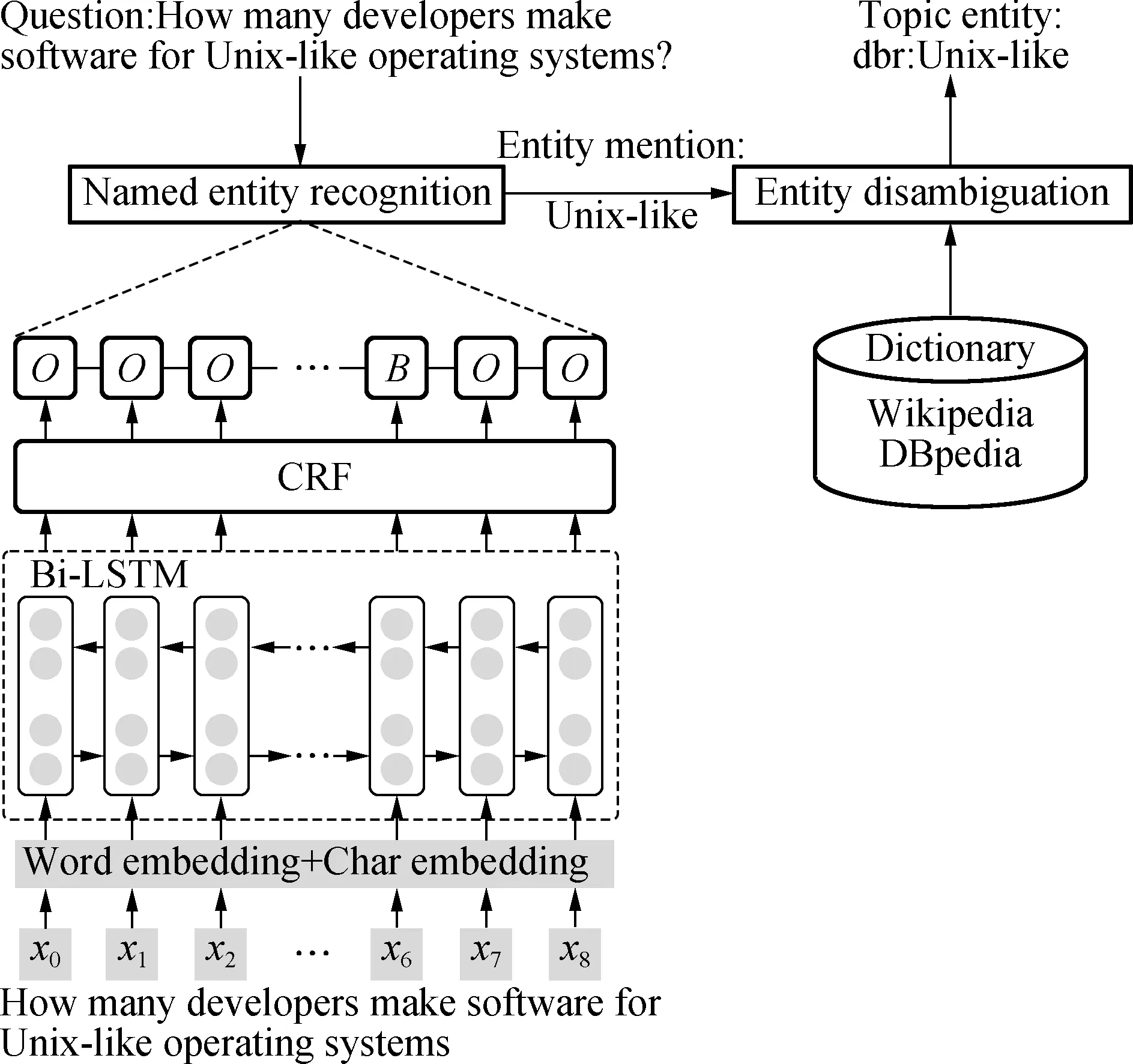
Fig.2 Architecture of the entity linking
For named entity recognition, we regard it as a sequence annotation task. We encode the question at the word and character levels to provide additional advantages in dealing with unknown or out-of-vocabulary (OOV) words. When a question sequence comes, the pre-trained word embedding and character embedding characters are retrieved to construct a matrix. Then, the Bi-LSTM is applied to generate an abstract representation of the question. Finally, an additional conditional random field (CRF) tagging model is used to detect the named entity mention. For the labeling of the mentions, the BIO tagging scheme (B=beginning of an entity, I=inside of an entity, O=outside of an entity) is used.
For entity disambiguation, we collect a dictionary on the surface forms of entities from entity pages, redirect pages, and disambiguation pages in Wikipedia. We can then generate candidate entities for the given mention on the basis of this dictionary and map these candidate entities in Wikipedia to the entities in the DBpedia knowledge base. For candidate entity ranking, we consider the edit distance and a few linguistic-based rules.
2.3 Relation linking
First, a classifier is used to judge whether the question is complex or not. Secondly, simple or complex relation candidates are obtained from the generated subgraph according to the complexity of the question. Finally, different attentive RNN models are applied to encode the given question and relation candidates and score the similarity between them.
The aim of the simple/complex classification is to build a binary classifier to efficiently predict whether a given question is simple or complex. The input of the classifier is the features of the question, and it contains the length of the question, the number of entities, and word POS tagging. After testing eight classifiers, we select logistic regression which performs outstandingly well to classify the complexity of the question.
For each questionq, we use the entity linking component to identify the topic entity, which can be simply regarded as the main entity of the question. After obtaining the topic entity, we collect its one-hop or two-hop relations according to the classification of the question. For a simple question, one-hop relations are collected to constitute a simple relation candidate setRS. For a complex question, two-hop relations are collected to constitute a complex relation candidate setRC.
According to the complexity of the question, we adopt different multi-attention Bi-LSTM models to detect relations. For a simple question, the one-attention Bi-LSTM model is applied to detect one relation from the question. For a complex question, the two-attention Bi-LSTM model is applied to detect two relations from the question.
We take the complex question as an example to explain the process. The topic entity mention is replaced in the question with a token “
For each relationrinRC, we describe it from two levels, namely, relation level and word level, and transform each part to its trainable embedding to obtain their vector representations. The running question “How many developers make software for Unix-like operating systems?” is classified as a complex one. Hence, the relation candidate setRCcontains all two-hop relations connected to the topic entity. Take the two-hop candidate relation “operatingSystem·developer” for instance. We deal with the relations “operatingSystem” and “developer” separately and feed them into the two-attention Bi-LSTM model. For each input relation, we describe it from the relation and word levels. For example, the relation “operatingSystem” can be divided into “operating” and “system” at the word level. The relation level of the single word “developer” is the same as the word level. The word embedding is fed into the Bi-LSTM network. Then, we obtainri(i∈{1, 2}) by max-pooling the relation and word levels, respectively.r1represents the first relation aspect in relationr, andr2represents the second relation aspect.
Each word in the question is initialized to its word embedding. Then, the embedding is fed into the Bi-LSTM network to obtain the hidden representations,H=[h1,…,hL].Lis the length of the question. Each vectorhjis the concatenation between forward/backward representations at timej. We adopt the additive attention mechanism proposed in Ref.[13]. Each aspectri(i∈{1, 2}) of the relation pays different attention to the question and decides how the question is represented. The extentαijof the attention is used as the weight of each word in the question. Thus, for different relation aspectsri, the corresponding question pattern representationpiis calculated as
(1)
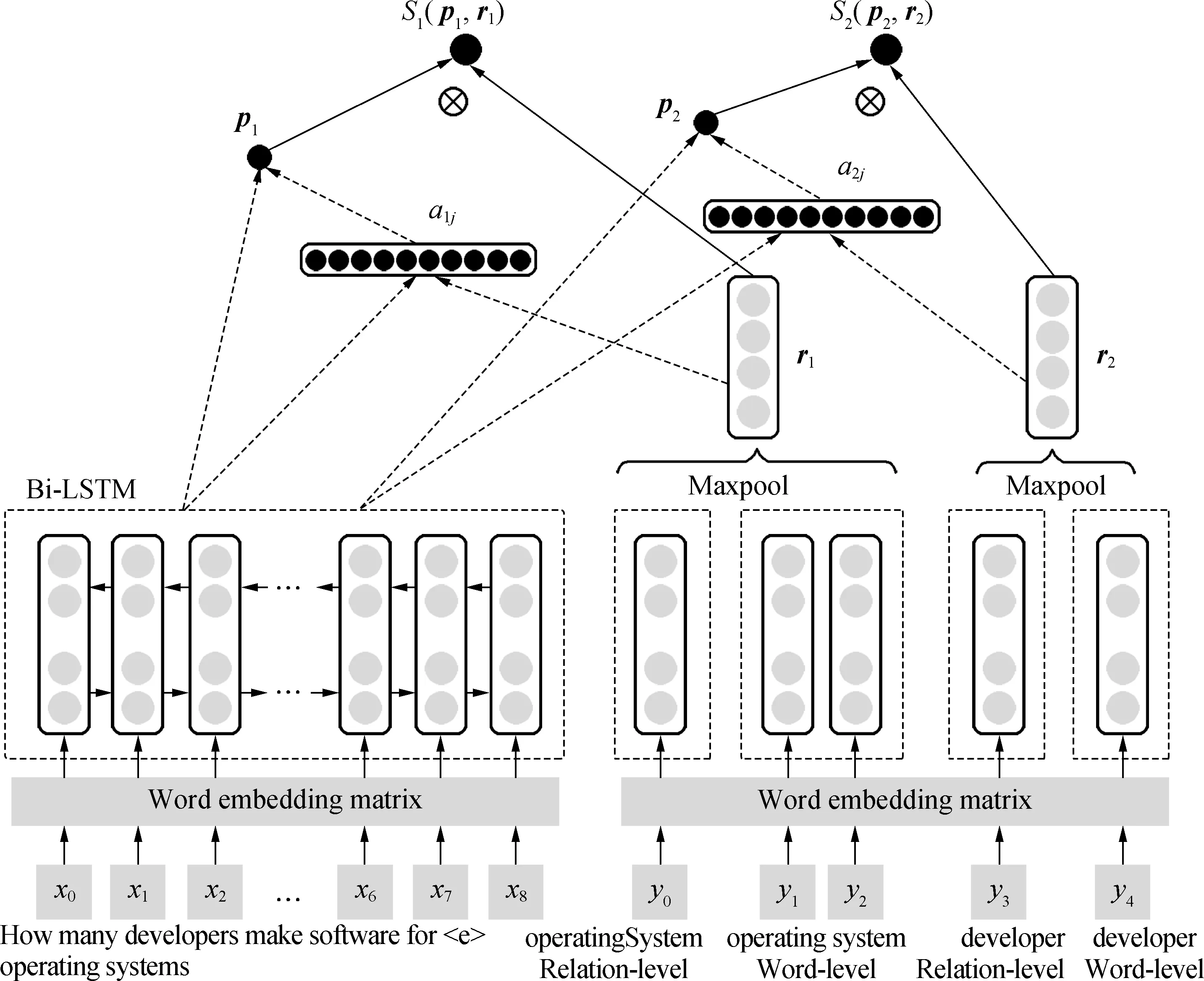
Fig.3 Architecture of the two-attention Bi-LSTM model
(2)
wij=vTtanh(WT[hj;ri]+b)
(3)
whereαijdenotes the attention weight of thej-th word in the question in terms of relation aspectri. Let the dimensions ofriandhjbemandn, respectively. Then,Wandvare the parameters to be learned withW∈Rc×(m+n),v∈R1×c(wherecis a hyper parameter).bis the offset.
At this point, we have the representations of question patternpiand relation aspectri. Their similarity is calculated by the following equation:
Si(pi,ri)=pi⊗rii=1,2
(4)
The operation ⊗ here is the dot product of two vectors.
We compute a matching scoreS(P,r) that represents the similarity between the question pattern and the candidate relation.
S(P,r)=sigmoid(WT[S1(p1,r1);S2(p2,r2)]+b)
(5)
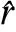
(6)
The model described above is trained with a ranking loss to maximize the margin between gold relationr+and other relationsr-in the candidate set:
(7)
whereγis a constant parameter.
3 Experimental Results
We use the LC-QuAD[14]question dataset in our experiments. LC-QuAD (https://figshare.com/projects/LC-QuAD/21812) contains 5 000 questions (4 000 for training and 1 000 for testing) with their intended SPARQL queries for DBpedia. DBpedia is an encyclopedic knowledge base, and the types of entities mentioned in the questions for DBpedia exhibit large variations. There are 5 042 entities, 615 relations, and multifarious entity types (for example, book, television show, company, and politician) in the dataset. We supplement the dataset with the entity mention and relation mention annotations(https://github.com/wds-seu/KBQA-multi-attention-RNN) to benefit the evaluation of each KBQA pipeline step. All reported experiments are run on the DBpedia 2016-04 version.
3.1 Results
We report and analyze the experimental results of the entity linking, relation linking components separately to show their effectiveness.
To evaluate the proposed entity linking component, we compare it against the state-of-the-art tools. We report the experimental results of the systems integrated in Gerbil[15]i.e., KEA[7], FOX[5], Babelfy[4], and AIDA[3]. Gerbil is a benchmarking framework for entity linking systems. These methods deal with entity linking task based on the graph algorithm or context-related features. We also report the performance of TAGME[6], DBpedia Spotlight[2], EARL[11]and Falcon[12]for entity linking. Most of these approaches (except Falcon) use state of the art machine learning techniques. It is important to note that Falcon utilizes an extended knowledge graph created by merging entities and relations from various knowledge sources for candidate generation.
Tab.1 lists the macro precision, macro recall, and macroF1of all systems on the LC-QuAD dataset. The performance of the compared systems listed in Tab.1 is obtained directly from Ref.[12]. The word embedding in our approach is initialized using two pre-trained word vectors, GloVe[16]and BERT[17]. GloVe is an unsupervised learning algorithm for obtaining vector representations for words. BERT, a pre-trained transformer network, is designed to pre-train deep bidirectional representations from unlabeled text. The results demonstrate that Falcon and our approach significantly outperform other systems. Our approach, whether initialized by GloVe or BERT, is superior to other methods in precision. When initializing with BERT, it performs better in both precision andF1value. The reason for Falcon’s better recall value is that it uses more external knowledge sources to generate candidates.
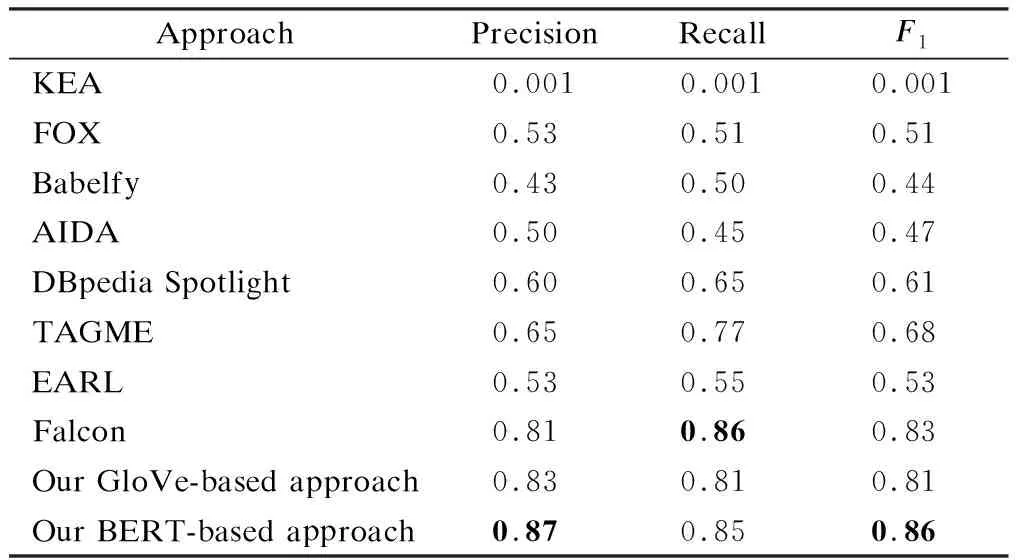
Tab.1 Macro precision, recall, and F1 values of entity linking approaches
In the process of relation linking, we evaluate different models to prove that the one-attention Bi-LSTM model is applicable to simple questions and that the two-attention Bi-LSTM model is applicable to complex questions. Among the 1 000 testing questions in LC-QuAD, there are 366 simple and 634 complex questions, respectively. On the basis of the assumption that the simple/complex classification is completely correct, we evaluate the Bi-LSTM model without attention and with one attention separately on the simple question dataset. We also evaluate the Bi-LSTM model without attention, with one attention, and with two attentions on the complex question dataset. We set the embedding dimension to 300 in training process, and all word embedding is initialized using the pre-trained GloVe here. The comparison results are shown in Tab.2.
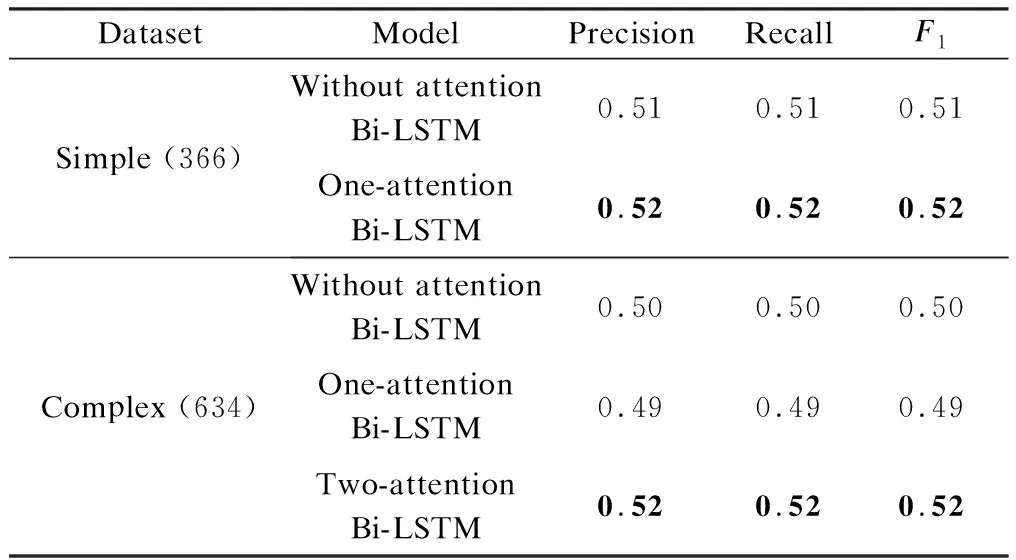
Tab.2 Macro precision, recall, and F1 values of different models on simple and complex LC-QuAD datasets
We observe that the results with attention are better than those without attention for simple questions. Hence, adopting the attention mechanism in the Bi-LSTM model can improve performance. For complex questions, the results of the two-attention Bi-LSTM model that separates two relations are better than those of the one-attention Bi-LSTM model or the model without attention. It means that, merging two aspects of the relation into one attention or without attention is not appropriate for complex questions.
To illustrate the effectiveness of the attention mechanism clearly, we visualize the attention distribution of the question words in the question encoding process (see Fig.4). Color depth represents the attention weights, a darker color indicates a higher attention weight. From the simple question example, we can observe that the one-attention model is able to capture the attention properly. For the complex question, each question word learns a different weight for different relation aspects.
To evaluate our relation linking component, we apply the multi-attention Bi-LSTM model on the basis of the results of our simple/complex classification. The results of our proposed relation linking approach in comparison with four baselines are listed in Tab.3. These baselines are SIBKB[8], ReMatch[9], and the recently released EARL and Falcon systems. Both SIBKB and ReMatch leverage semantic similarity measures to perform relation linking. EARL applies both the graph algorithm and machine learning for relation linking. Falcon utilizes an extended knowledge graph and a linguistic understanding method.
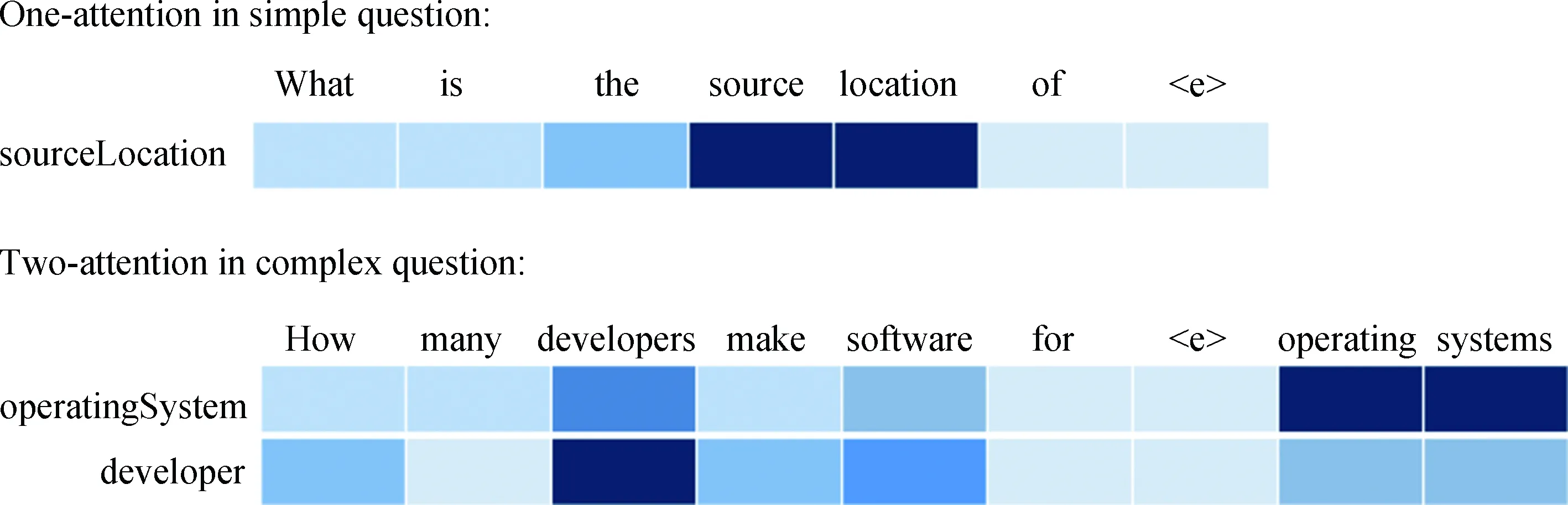
Fig.4 Visualized attention heat map
Our evaluation metrics are the same as those of Falcon. We list two experimental results of our relation linking component. Our RL (golden EL) employs our relation linking component on the basis of the golden entity linking outputs. Our RL (our EL) employs our relation linking component on the basis of our entity linking (BERT) component outputs. From the results, we observe that our independent relation linking component outperforms the state-of-the-art results by Falcon. Despite the error propagation caused by entity linking, the results of our relation linking component are still promising. The experimental results show that it is difficult to obtain better results by only relying on semantic similarity or graph algorithm. Although Falcon leverages external resources to obtain a better recall value, its accuracy is limited by its linguistic methods. Our multi-attention RNN model can better deal with the relation linking task.
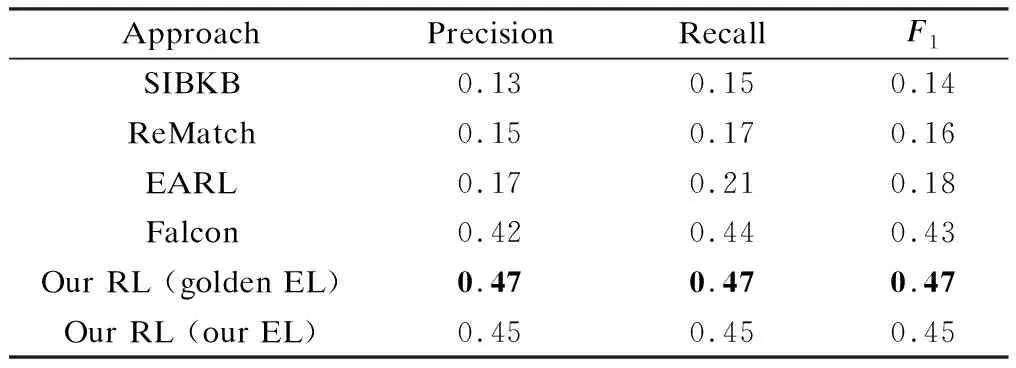
Tab.3 Macro precision, recall, and F1 values of relation linking approaches
3.2 Error analysis
For error analysis, we list some question examples in Tab.4 (the named entity mentions are underlined), for which our approach does not output correct results.

Tab.4 Failure analysis results
The first part of the samples is the failure of the entity linking component, which means that we fail to recognize the correct entity mentioned in the question. Such occurrence is common when the mention is too long or too sketchy, such as the long mention “Warwick railway station, Perth” in Q1, the acronym mention “Sci-fi” in Q2, and the long mention “1997 canadian grand prix” and the omitted mention “94 spanish one” in Q3. There are also failures which links the mention to the entity with the same name but the wrong type. For example, the mention “Jim Harris” is linked to the wrong entity “Jim_Harris_(politician)” instead of “Jim_Harris_(entrepreneur)” in Q4.
The second part of the samples is the failure of the simple or complex classification for the question. For example, Q5 is a simple question with a type constraint. However, it is incorrectly recognized as a complex question. The incorrect classification leads to the incorrect results of the following components.
The third part of the samples is the failure of the relation linking component, which has the largest proportion. One cause is the error propagation; for example, the wrong entity linking results for Q6 and Q7 lead to the failure of relation linking. Another cause is that implicit relation is difficult to detect. For the simple question Q8, the surface form “are known as” is not identified as relation “nickname” correctly. The surface form “before” in Q9 is not identified as relation “previousWork” correctly. The causes of wrong relation linking for complex questions are varied because large numbers of two-hop relation candidates compound the difficulties of relation linking. For the complex question Q10, we incorrectly detect the relation “creator·voice” instead of “voice·voice”.
4 Conclusions
1) For entity linking, which is an essential component for relation linking, we train a Bi-LSTM-CRF model to recognize entities mentioned in a question and link them to the entities in the knowledge base based on a dictionary.
2) We propose a relation linking approach based on the multi-attention RNN, which can deal with the relation linking problem for both simple and complex questions. We first classify questions as simple or complex questions. On the basis of the classification, we apply different attention-based Bi-LSTM models for relation linking.
3) The experimental results show that our entity and relation linking components achieve the best reported macro precision on the LC-QuAD dataset.
4) In future, we plan to improve the relation linking results for complex questions. We also intend to consider aggregation constraints to generate final structured queries for the questions.
杂志排行

Journal of Southeast University(English Edition)的其它文章
- Bandwidth-enhanced dual-polarized antenna with improvedbroadband integrated balun and distributed parasitic element
- UAV trajectory planning algorithmfor data collection in wireless sensor networks
- Q-learning-based energy transmission scheduling over a fading channel
- Time optimization for workflow scheduling based on the combination of task attributes
- Centre symmetric quadruple pattern-based illumination invariant measure
- Flexural behaviour of SFRRAC two-way composite slab with different shapes