多层学习联合建模方法设计在气阴两虚型咳嗽证候的辨证诊断中的应用*
2021-01-09浙江中医药大学310053项莎特瞿溢谦叶含笑
浙江中医药大学(310053) 项莎特 瞿溢谦 叶含笑
【提 要】 目的 采用多层学习联合建模方法挖掘气阴两虚型咳嗽的辨证证候,以期为中医学习、研究临床辨证及诊断提供新的思路与方法。方法 联合采用随机森林、XGBoost及logistic回归三种机器学习算法,对767例咳嗽患者病案,运用Anaconda 3-5.2.0软件建立算法模型进行分析。结果 运用该方法所得的证候结果与文献记载的证候表现大体一致,主要为呛咳、乏力、口干、痰少而色白,燥苔、脉弱等证候。经交叉验证得出,XGBoost算法准确率为86.7%,随机森林为85.3%。结论 多层学习联合建模方法可弥补单独使用随机森林、XGBoost或logistic回归算法所产生的缺陷,尤其对于临床病案较少的小样本数据更为有效,该方法在一定程度上降低了重要变量丢失的可能性。
咳嗽为常见疾病,中医治疗该疾病的历史悠久,且对于临床检查无殊的咳嗽的疗效较为显著[1]。气阴两虚为致使原因不明、临床检查无明显病理性改变的咳嗽发作的病机之一。在当今大数据及人工智能的冲击下,探索新的中医学习、传承方式成为趋势[2]。通过机器学习提取判断事物属性特征,从而建立诊断模型的方式,成为了医学领域中蓬勃发展的一项研究[3]。此方法有助于从隐匿和重叠的证候中挖掘出其分布特点,从而预测疾病证型[4],同时可达到挖掘和学习中医临床辨证及诊断的目的。
因此,本研究气阴两虚型咳嗽患者的基础上,联合多模型机器学习算法,组成多层学习联合建模方法,对所采集气阴两虚型咳嗽的四诊信息进行挖掘和分析,从而为机器学习辅助开发新的中医学习方式提供参考。
资料与方法
1.数据来源
2018年1月-2018年12月就诊于浙江中医药大学门诊部的咳嗽患者病案。
2.纳入标准
(1)疾病名称为咳嗽,证型为气阴两虚;(2)复诊资料显示,该患者咳嗽症状缓解;(3)咳嗽的诊断标准同时参照《咳嗽的诊断与治疗指南》(2015)[1];(4)所采集的病案包含了完整的四诊信息。
3.排除标准
(1)复诊资料显示,咳嗽症状并未缓解者;(2)未见复诊信息者;(3)病案中四诊信息不全者;(5)咳嗽诊断标准不符合《咳嗽的诊断与治疗指南》者。
4.数据总量
采集咳嗽病例767例,其中气阴两虚型咳嗽病例为564例,非气阴两虚型咳嗽病例为203例。
5.数据预处理
将采集到的病案按姓名、证候、是否为气阴两虚型咳嗽,建立信息标签。证候名称标准化参照《中医药学名词》[5],录入excel数据表,共得到210个证候标签,并对各个证候进行语言规范化处理后,将信息采用“0”“1”变量赋值,是为“1”,否为 “0”。对疾病类型同样采用“0”“1”变量赋值,是气阴两虚型咳嗽为“1”,非气阴两虚型咳嗽为“0”。
模型的选择、建立与运用
1.多层学习联合建模方法
在机器学习的众多算法中,随机森林、XGBoost算法具有较高的计算效率,且在一定程度上能有效防止模型的过拟合[6-7],因此,与支持向量机、决策树、logistic回归等算法相比,随机森林、XGBoost在疾病预测中具有较高的准确度[8-10]。
随机森林采用集成学习的思想,使用决策树作为弱分类器,组合多个决策树形成具有较好效果的强分类器。该算法的准确率可与Adaboost相媲美[11]。采用随机森林模型可以通过计算每棵决策树的袋外数据误差,及对袋外数据所有样本的特征随机加入噪声后的袋外数据误差,得出样本特征变量的重要性[7]。
梯度提升决策树(gradient boosting decision tree,GBDT)是XGBoost的基础算法,它包含一个迭代残差树的集合,每一棵树都在学习前N-1棵树的残差,将每棵树预测的新样本输出值相加起来就是样本最终的预测值。不同于常用的梯度提升决策树在优化时仅用一阶导数信息,XGBoost对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数,使得XGBoost得到良好的结果[12],并在许多机器学习和数据挖掘挑战中得到广泛认可[13]。
在采用机器学习挖掘辨别是否为气阴两虚型咳嗽的重要证候时,采用随机森林结合XGBoost算法进行特征提取。但是,随机森林、XGBoost均无法得出指标的方向性影响[14],将两种算法所得的重要证候特征,再次使用logistic回归模型进行建模。由此,可得到由多模型组合而成,用于辅助学习中医辨证及诊断的新模型,命名为多层学习联合建模方法。
2.多层学习联合建模方法的运用
将经过预处理的数据输入Anaconda 3-5.2.0软件,删除决定性单一输入后,可将210个证候特征缩减至63个,再经随机森林及XGBoost算法的运算,最终根据权重的高低排序,截取经两种算法运算后,各自所得结果的前35个证候特征及其相应的权重值。所得的两组证候特征结果中,具有29个重合变量。将此29个证候特征再次采用logistic回归算法进行建模,最终得到辨别气阴两虚型咳嗽的重要证候特征。同时采用10折交叉验证法,对算法进行准确性评估。(见图1)

图1 多层学习联合建模方法流程图
结 果
表1和表2分别为经随机森林、XGBoost算法所得气阴两虚型咳嗽证候的前35个重要证候。表3为重合的29个证候经logistic回归算法后所得结果,所得权重为正值的变量,归属为气阴两虚型咳嗽的重要辨证证候;所得权重为负值的变量,归属为非气阴两虚型咳嗽的重要辨证证候。
因此,经多层学习联合建模方法运算后,最终得出判定咳嗽属气阴两虚型证型的重要证候有呛咳、乏力、口干、气急、反复咳嗽、咽中痰少、痰色白、自汗、盗汗、头晕、裂纹舌、薄苔或少苔、燥苔、脉弱、脉弦(图2)。经10折交叉验证法,得出XGBoost准确度为86.7%,随机森林为85.3%。

表1 基于随机森林所得气阴两虚型咳嗽证候的重要性排序
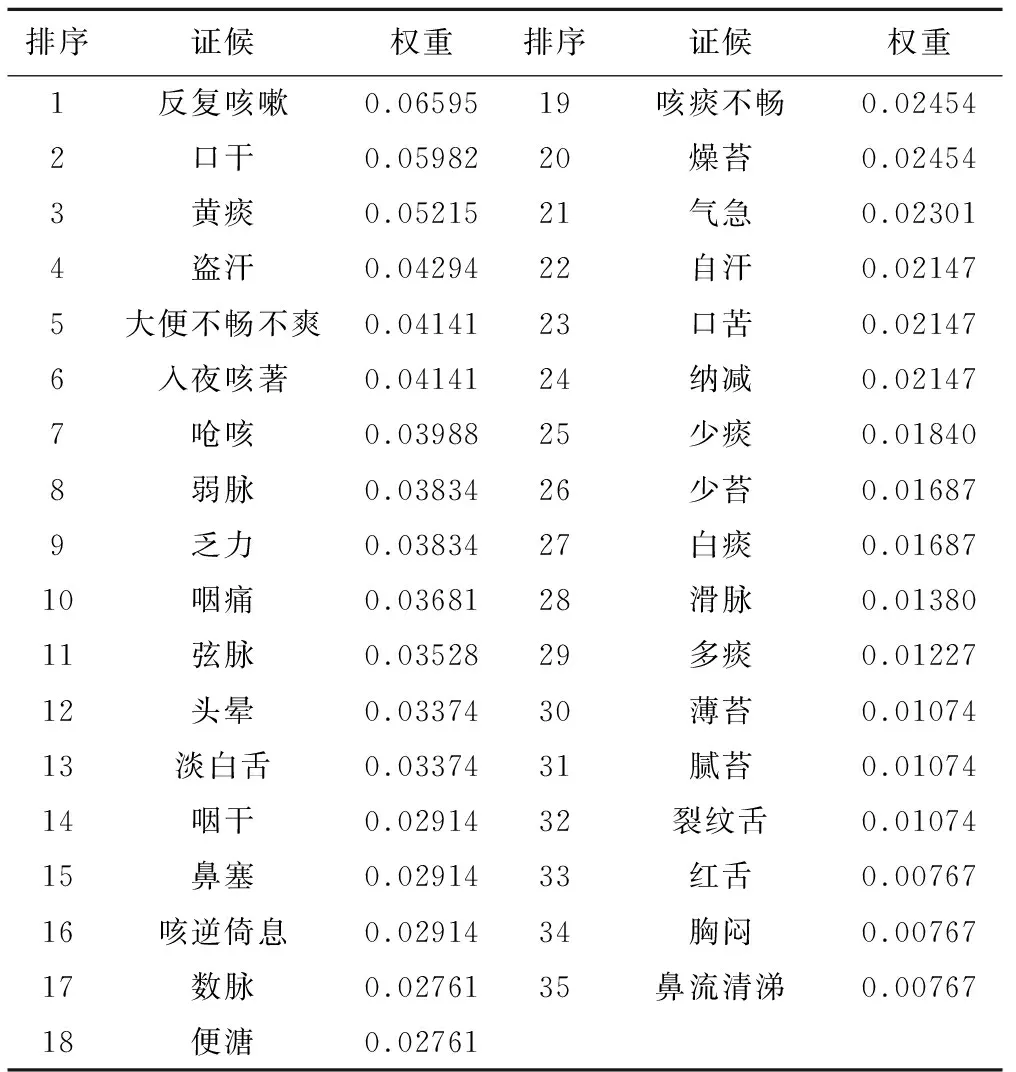
表2 基于XGBoost所得气阴两虚型咳嗽证候的重要性排序

表3 基于logistic回归模型所得气阴两虚型咳嗽证候的结果
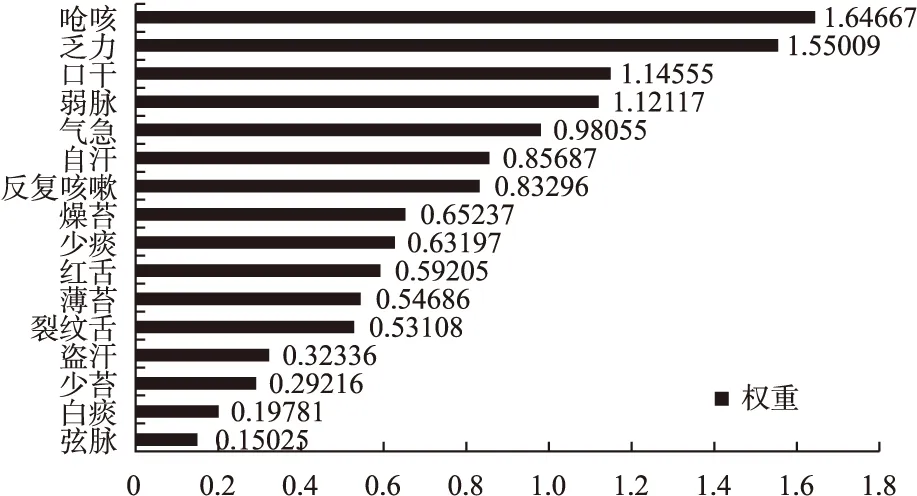
图2 辨证气阴两虚型咳嗽的重要证候
讨 论
1.多层学习联合建模方法所得证候与中医相关理论探讨
通过多层学习联合建模方法所得出的气阴两虚型咳嗽的重要证候结果,与临床文献报道[15-18]及《中医病证诊断疗效标准》[19]记载的证候特征大致相同,主要为乏力、口干、反复咳嗽、自汗、盗汗、痰少色白、舌红、苔薄或苔少、苔干燥、脉弱、脉弦。在此基础上,本研究尚且发现呛咳、气急、裂纹舌亦为气阴两虚型咳嗽的表现证候。
2.多层学习联合建模方法的优势
在机器学习中,由于随机森林在每次划分时,考虑的属性较少,因而该算法在大型数据库上更为有效,但对于小样本,其准确度有所下降[11]。而XGBoost对于小样本的特征提取,效果明显优于随机森林、支持向量机、logistic回归等算法[20]。本研究采用随机森林联合XGBoost算法,找其重叠证候,既能弥补随机森林对于小样本的准确率较低的缺陷,又可进一步提升XGBoost结果的准确性,从而得出较为满意的证候特征结果。此外,在数据维度较大的前提下,仅采用logistic回归算法,会使得一些对辨证影响较大的相关证候被丢失,而影响较小的证候反而得到意义[21],故通过随机森林和XGBoost降维,可剔除相关性较小的证候,弥补logistic回归算法的不足。
综上所述,本研究所采取的多层学习联合建模方法,具有以下特征:为3个模型联合使用的多模型算法;可辅助中医学者学习,研究临床疾病的辨证及诊断;能在临床疾病样本较少,维度较大的情况下,确保较高的准确性。因此,该方法用于挖掘中医疾病证型的重要证候特征值得推广。
3.多层学习联合建模方法的展望。
该方法虽能确保较好的准确度,但可能仍存在一些对辨证影响较小的证候被提取。因此,在解决该问题时,可考虑优化此模型结构,经logisitic回归算法后得出的证候,再经专业人士判定,得出最终较为满意的结果,即采用人机互助的模式,以减弱机器学习刻板化的缺点,增强该模型的灵活性,进一步提升结果的准确性。
