基于迁移学习和集成学习的医学短文本分类
2021-01-09张博孙逸李孟颖郑馥琦张益嘉王健林鸿飞杨志豪
张博,孙逸,李孟颖,郑馥琦,张益嘉,王健,林鸿飞,杨志豪
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
随着现代生物医学的快速发展,大量的临床医学数据呈现指数增长,且大多为非结构化文本。为构建临床试验筛选结构化文本,通过自然语言处理和机器学习的方法对临床试验筛选标准自动解析,并以此构建自动化筛选病人的系统是一个很有前景的研究热点,具有很大的实际应用前景和医学临床价值。临床试验是指通过人体志愿者也称为受试者进行的科学研究,筛选标准是临床试验负责人拟定的鉴定受试者是否满足某项临床试验的主要指标,分为入组标准和排出标准,一般为无规则的自由文本形式。临床试验的受试者招募一般是通过人工比较病历记录表和临床试验筛选标准完成,这种方式费时费力且效率低下。因此通过现有的深度学习等一些自然语言处理技术来实现临床试验筛选标准短文本分类系统具有重要意义。
本文旨在解决医学短文本分类问题,实验数据集选择的是中国健康信息处理会议(CHIP2019)评测数据,如图1所示,输入为一系列中文临床试验筛选标准的描述句子,输出为根据每一条临床试验数据返回筛选标准的具体类别。

图1 数据示例Fig.1 An example of data
传统的文本分类方法主要基于特征工程等机器学习方法,该方法需要大量的人工介入,需耗费大量的时间和精力,近年来,深度学习技术逐渐取代传统的机器学习技术成为文本分类领域的主流方法[1]。基于深度学习的自然语言处理技术主要有2013年Mikolov等人[2]提出基于神经网络的语言模型CBOW和Skip-gram并提出分布式词向量的概念。2014年Sutskever等人[3]提出Seq2Seq模型,通过一些深度神经网络模型构建编码器和解码器,常用的神经网络主要是长短时记忆网络。2017年Vaswani等人[4]提出transformer机制,其中的编码器和解码器是由基本的前馈神经网络和注意力机制堆叠形成。2018年Jacob等人[5]提出预训练语言模型BERT。2019年Facebook团队在BERT基础上进行优化提出Roberta预训练语言模型[6]。
本文提出的临床试验筛选标准短文本分类方法主要分为三个阶段,一是微调预训练语言模型,在此阶段使用的语言模型是BERT[5]和Roberta[6];二是微调分类模型,面向医学短文本分类任务将第一阶段得到的语言模型与神经网络模型进行结合构建医学分类模型,微调过程是针对结合后的整体模型即包含语言模型和神经网络模型,上述两个阶段的微调使用的数据集均为无监督领域相关的外部资源数据集;三是利用集成学习的知识来实现最终的医学文本分类,将第二阶段得到的多个分类器进行集成学习,通过投票方式和beam search ensemble算法选择出最佳的模型组合并将其作为医学文本分类系统的最终分类模型。实验结果表明本文方法的有效性,在CHIP2019评测三临床试验筛选标准短文本分类任务测试集上其F1值达到0.811 1。
文本分类任务是自然语言处理领域经典任务之一,有着广泛的应用。医学文本分类技术可辅助医疗,构建结构化电子病例等医学数据,具有重要意义。近年来,一些经典的文本分类方法主要是基于深度学习模型,如Kim等人[7]提出多尺度并行的单层卷积神经网络(CNN)结合预训练词向量实现句子级别的文本分类,Hochreiter等人[8]为了解决原始循环神经网络(RNN)在训练时存在梯度消失和梯度爆炸问题提出长短时记忆神经网络(LSTM)进行文本分类。Yang等人[9]提出基于分层注意力机制的神经网络模型实现文档分类。上述方法在通用领域文本分类任务中起到了很大的作用,但在生物医学领域中的短文本分类任务中存在一定的局限性。主要原因有临床试验电子病历文本中含有大量的医学专业词汇;病历文本中存在的字符形式较多,包含中文、英文缩写,阿拉伯数字、科学计数法等;病历文本中在不同类别的短文本存在一定程度的重叠。因此,为解决上述问题本文提出一种基于迁移学习和深度学习的方法,采用微调技术,使在通用领域上表现好的模型在生物医学领域上也有较好的性能。
迁移学习对计算机视觉领域产生了很大的影响。应用在计算机视觉领域的模型大多是利用已有模型进行微调,很少从头开始训练,即在ImageNet, MS-COCO等大数据上得到预训练模型[10-13]。虽然深度学习模型在许多自然语言处理领域任务上达到了很好的效果,但是这些模型都是从头开始训练,需要花费大量时间和精力收集大型数据集和训练模型。目前应用到自然语言处理领域的迁移学习,主要是针对模型的第一层,通过微调预训练的数据,虽是一种简单的迁移学习技术,但是在实际应用中有很大的价值和影响,并可应用到各种深度学习模型中,但该方法仍需要从头训练主要任务模型,并将预训练词嵌入视为固定参数,限制了迁移学习方案的有效性。
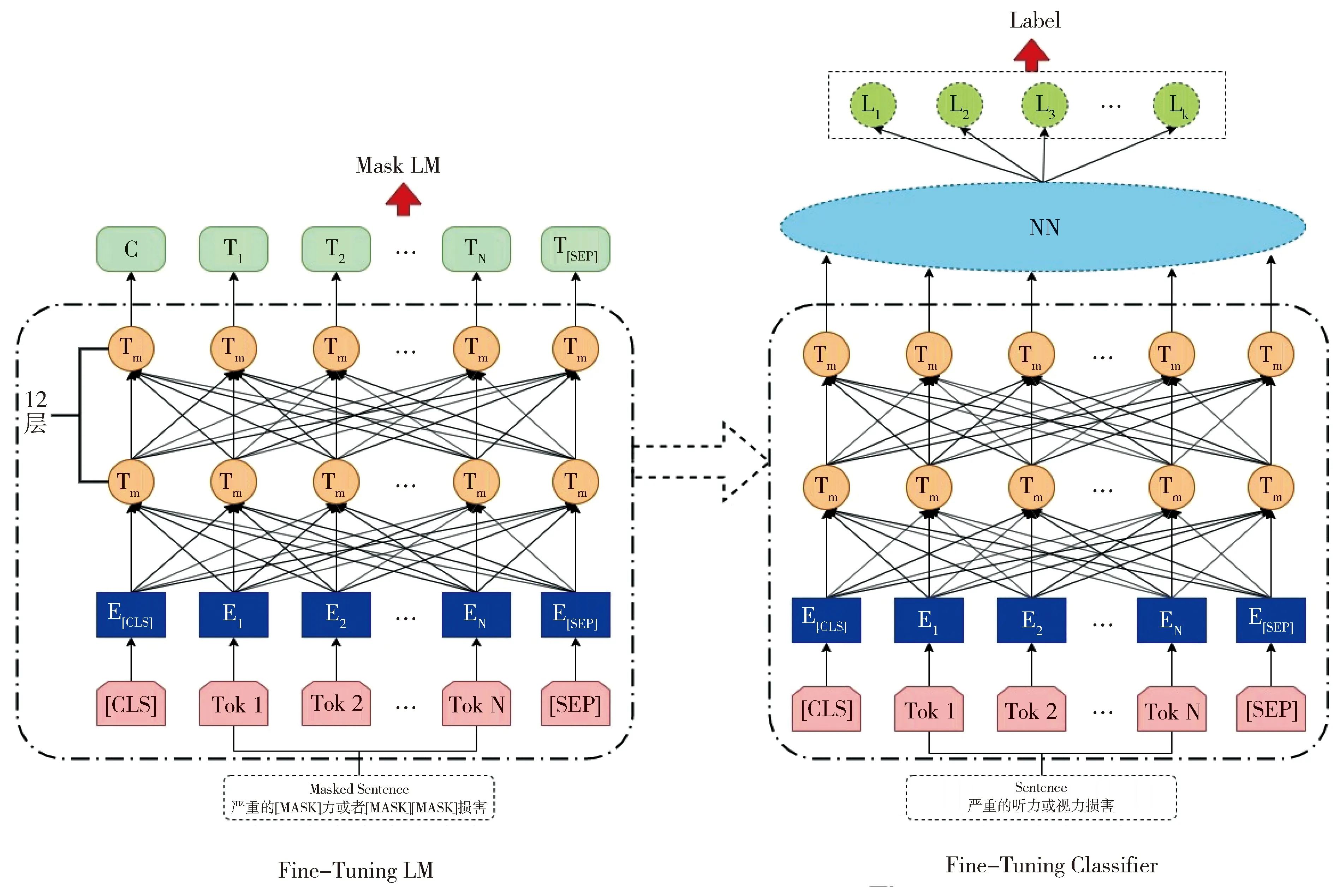
图2 模型框架Fig.2 Framework of model
目前的研究成果表明,预训练语言模型能够提升自然语言推断、语义相似度计算、命名实体识别、情感分析、检索式问答匹配等多个自然语言处理任务的性能。因此,针对上述问题,我们利用预训练模型,采用迁移学习技术来完成临床试验筛选标准短文本分类任务。根据自然语言处理领域最新研究,迁移学习较为有效的方案是进行模型微调,其中通用语言模型微调(ULMFiT)[14]在多个分类任务中表现出优越的性能,因此我们采用ULMFiT中的一些方法,如倾斜的三角学习率,逐层解冻等来提高医学文本分类系统性能和训练效率。
1 方法
1.1 模型框架
本文搭建的模型框架如图2所示,先对数据进行简单地预处理,得到中文临床试验筛选标准短文本描述,将其作为输入,按照字级别输入到预训练语言模型中,然后将语言模型中最后一层transformer的输出作为下游神经网络层的输入,再经过一些深度学习网络层学习文本特征,最后通过softmax函数得到分类结果。
本文的研究方案主要分为三个阶段:第一个阶段是使用预训练语言模型,并对语言模型进行微调;第二个阶段是将第一阶段得到的语言模型与神经网络模型进行拼接得到医学短文本分类模型,并对分类模型进行微调;第三阶段是将第二阶段得到的多个分类模型进行集成学习来提高总体的分类结果。
1.2 语言模型
1.2.1 预训练语言模型选择
本文使用的两个预训练语言模型均基于BERT模型方法,分别为Google发布的中文版 BERT-base, Chinese[5]和哈工大讯飞联合实验室发布的RoBERTa-wwm-ext, Chinese[15]。
1.2.2 语言模型微调
虽然Google训练BERT模型时使用的通用领域数据集是非常多样的,但是相对临床试验筛选标准短文本分类任务的数据仍有很多不同的分布。
因此,本文受迁移学习思想启发对上述两个预训练模型进行微调得到适用于生物医学领域的语言模型。微调过程中使用的数据集是通过相关爬虫程序爬取的213,154条关于临床试验筛选标准短文本数据,并选取CHIP2019评测任务三官方发布的数据集(包含训练集和验证集)做微调结果验证。
为了使BERT和Roberta两个语言模型参数适应医学文本分类任务,我们采用倾斜的三角学习率方法进行微调使模型在训练开始时快速收敛到参数空间的合适区域,再细化其参数。倾斜的三角学习率是指先线性地增加学习率,再根据公式(1)(2)(3)更新时间表形成线性衰减,如图3所示。

图3 倾斜三角学习率Fig.3 Slanted triangular learning rates
(1)
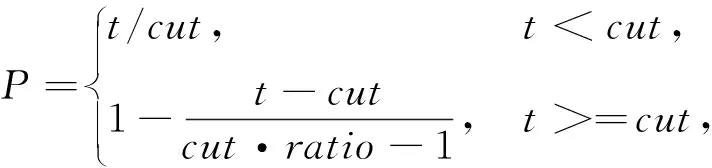
(2)
(3)
其中T是训练的总迭代次数;cut-frac 是增加学习率的迭代次数比例;cut 是学习率从增加到减少的临界迭代次数;p是一个分段函数,分别表示递增和递减的迭代次数比例;ratio 表示学习率最小时与最大学习率的比值,就是学习率的衰减比例;ηt表示迭代次数为t时的学习率。实验过程将cut-frac设定为0.1,ratio设定为32,ηmax设定为0.01。在使用该方法微调语言模型后,分类结果会有显著提升,在文中实验部分会具体论述。
1.3 分类模型
针对临床试验筛选标准短文本分类任务,我们使用了当前主流的四种神经网络分类模型来实现医学文本分类,使用的模型主要有卷积神经网络(CNN)[7],新型卷积神经网络(DPCNN)[16],长短时记忆神经网络(LSTM)[8]以及自注意力机制(self-attention)[4],将其与上述BERT和Roberta语言模型进行拼接最终形成的模型分类器有以下9种:bert-base, bert+bilstm+attention, bert+cnn, bert+dpcnn, roberta-base, roberta+attention, roberta+bilstm+attention,roberta+cnn, roberta+dpcnn,其中,“+” 表示把预训练模型最后一个transformer层的输出结果输入到分类模型的对应层中。base表示用预训练模型最后一个transformer的第一个token的值(即CLS)作为一个全连接层的输入直接进行分类得到的结果。
为了使上述分类模型适用于临床试验筛选标准文本分类任务,我们使用逐层解冻策略来对模型分类器进行微调。该策略最先提出用于ULMFiT模型[14]最后的分类器微调阶段。简单来说,该策略是指模型训练时不是一次微调所有层而是从最后一层开始逐渐解冻模型。逐层微调解决了因一次性微调所有层导致的致灾难性遗忘问题。研究表明最后一层会包括最通用的特征,因此,在训练时,先解冻最后一层(冻住其他层),在一个Epoch内微调所有未冻结的层,而不是所有层一起训练。然后在第二个Epoch内,再解冻倒数第二层来训练,以此类推。即,每个Epoch向下解冻一层,直至所有层都微调完毕,直到最后一次迭代收敛。
基于上述策略思想,我们将前50%个Epoch按照比例依次解冻,后50%个Epoch将所有权重一起训练。实验过程中设置了Epoch=10, Roberta语言模型有12个transformer层和1个词嵌入层,因此在我们的模型训练过程中,不是每个Epoch内解冻一层,而是5个Epoch内依次解冻13层,即5/13个Epoch解冻一层。在本文后续的实验部分会进行消融实验分析来论证该策略的有效性。
1.4 集成学习
考虑到不同分类模型会学习到不同的文本特征,因此本文采用投票机制和集成学习来提高整个医学文本分类系统的性能。针对上述9种分类模型进行集成学习得到相应的模型组合,模型之间进行内部投票得到最终的分类结果。在集成学习过程中我们提出了一种模型集成算法beam search ensemble。
随着模型数量的增多,从所有模型组合中选取最优结果所耗费的时间呈指数级增长,且无法对模型合理分配投票权重。因此我们提出一种beam search ensemble算法,即将beam search算法应用到融合模型中并对其进行了一些改进,具体算法如图4所示。该算法有效减少了时间复杂度,可使单个模型重复投票,充分考虑了性能好的模型的优势,以及降低性能差的模型所带来的偏差,有效更新了投票权重,并且在泛化能力上优于全部的模型融合,在文中实验部分有具体对比。
在实验过程中我们将beam search ensemble算法中的beam size参数设为3,得到最佳组合模型为bert-base,bert+dpcnn, bert+lstm+attention, roberta+attention, roberta+cnn * 2, roberta+dpcnn, roberta+lstm+attention,即这7个模型之间进行投票得到的集成模型效果最佳,F1值达到0.811 1。
2 实验结果与分析
2.1 数据集及任务
基于迁移学习和深度学习的临床试验筛选标准短文本分类研究任务来源是中国健康信息处理会议(CHIP2019)评测三任务,具体任务为根据官方给定事先定义好的44种筛选标准类别和一系列中文临床试验筛选的标准描述句子,结果返回每一条筛选标准的具体类别,示例如表1所示。
本文使用的数据集有CHIP2019评测三任务发布的数据集和通过爬虫方式获得的领域相关外部资源数据集。其中,官方发布的数据集包含训练集,验证集和测试集,按照大约3∶1∶1的比例划分,训练集和验证集包含人工标注的句子类别标签,属于有监督数据。我们获取的领域相关的外部资源数据集属于无监督数据,即不含有句子类别标签。数据集数量统计如表2所示。实验过程中先对所有数据集进行简单地去重等预处理,无监督数据集主要用于模型微调,有监督数据集用于模型的训练和验证。

表1 任务示例
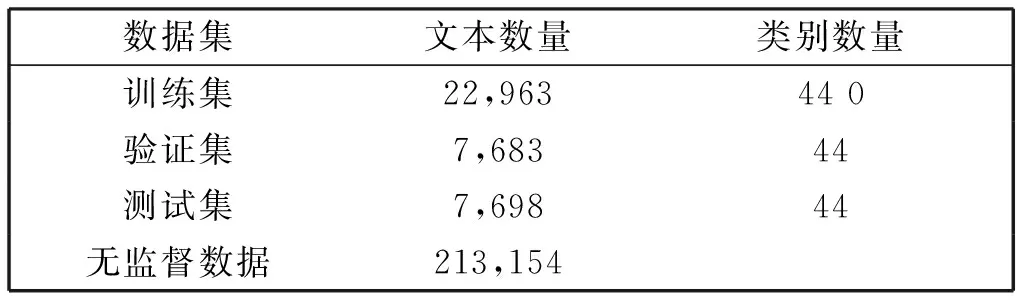
表2 数据统计
2.2 评价指标
本任务的评价指标包括宏观准确率(Macro Precision),宏观召回率(Macro Recall),AverageF1值。最终排名以AverageF1值为基准。假设我们有n个类别,C1,…,Ci,…,Cn,则准确率Pi、召回率Ri和AverageF1值的计算公式(4)(5)(6)如下:
(4)
(5)
(6)
其中TP(Ci)表示正确预测为类别Ci的样本个数,P(Ci)预测为Ci的样本个数,T(Ci)为真实的Ci的样本个数。
2.3 实验设置
2.3.1 超参数设置
我们模型训练的轮数设置为10轮,输入序列长度设置为128,衰减权重设置为0.001,学习率设置为0.000 05,每一轮保存一次模型,随机种子设为914,优化器选择为Adam[17]。分类模型中一些神经网络层参数超参数设置如表3所示。
2.3.2 损失函数
因临床试验筛选标准短文本数据中含有44种类别,存在严重的样本类别不均衡的问题,例如在训练集中“bedtime”类别只存在14个样本数据,而“disease”类别存在5 127个样本数据。此外,该任务还存在其他简单与复杂样本问题,例如“age”类别样本存在较为明显的关键字且训练集数量较多,较为容易区分,为简单样本,但有一些样本如“体检发现有任何显著的临床疾病症状者”存在多重含义和多个关键字等问题,较难区分它为“Symptom”类别还是“Laboratory Examinations”类别。为解决样本不平衡以及区分简单与复杂样本问题,我们使用He Kaiming和RBG提出的焦点损失函数focal loss[18]。Focalloss函数首次提出后被应用在图像领域的目标检测任务中,它是在标准交叉熵损失的基础上修改得到的。Focal loss函数通过减少易分类样本的权重来使得模型在训练时更专注于难分类的样本,如公式(7)所示。

表3 神经网络参数设置
FL(Pt)=-αt(1-Pt)γlog(Pt),
(7)
其中,αt表示每个类别的权重系数,Ct表示训练集中第t个类别的个数,γ为调制系数,实验时设置γ=2。由公式可以看出,当一个样本被分错时,Pt非常小,因此调制系数γ就趋于1,即相比原来的损失基本没有改变。当Pt趋于1的时候(此时分类正确而且是易分类样本),调制系数趋于0,也就是对于总的损失贡献很小。当γ=0的时候,focal loss就是传统的交叉熵损失,当γ增加的时候,调制系数也会增加。其核心思想是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献,这样既能调整正负样本的权重,又能控制难易分类样本的权重。
为了解决临床试验筛选标准文本数据集44种类别中的少类别问题,同时又要避免过度关注,αt参数选取如公式(8)所示。
αt= 2max(log Ct)-log Ct。
(8)
2.4 结果与分析
最终使用了9种神经网络模型来进行文本分类,对不同的具体模型分别使用5折交叉验证,所得模型对测试集进行预测,取5个预测结果的加权平均值作为最终预测结果,每个模型分配的权重值为其在交叉验证时得到的F1值。最后通过投票法对上述的9个模型做最后的模型融合,选取最佳模型组合。9种模型单独进行临床试验筛选标准分类结果如表4所示,其中,bert-base表示用最后一个transformer的第一个token的值(即CLS)做为一个全连接层的输入得到的分类结果。bert-lstm-att表示用bert的最后一个transformer层的输出作为LSTM的输入并加入注意力机制得到的实验结果,其他模型结果记录方式同上。

表4 实验结果
从表4中可以看出,在语言模型后拼接神经网络模型组成分类器在一定程度上可以提高分类结果。不同的神经网络模型得到的分类结果不尽相同,但总体差别不大,具体实验结果还与语言模型有关系。在BERT预训练语言模型中,拼接LSTM与注意力机制模型效果最优,在Roberta预训练语言模型中,拼接CNN模型效果最好。因最初考虑到可能会出现上述实验结果,即不同的预训练模型与不同的深度学习神经网络模型进行拼接会得到不同的实验结果,每个单个模型从临床试验筛选标准短文本数据集中学习到的知识特征是不同的,这样集成之后的模型之间可以结果互补使整个分类系统的性能得以提升。9个模型全部集成学习得到分类结果的F1值为0.809 9,比单个模型(roberta-cnn)最优结果高出0.36%,比单个BERT模型结果高出1.35%,证明模型集成的有效性。用我们提出的beam search ensemble算法进行模型集成时得到的最佳模型组合为bert-base,bert+dpcnn, bert+lstm+attention, roberta+attention, roberta+cnn * 2, roberta+dpcnn, roberta+lstm+attention这7个模型。这7个模型被分配了不同的投票权重后集成得到的结果比所有模型共同集成结果高出0.12%,充分论证了beam search ensemble算法的有效性。
2.5 微调有效性分析
为了验证微调模型以及微调方案的有效性,我们进行了消融对比实验。实验结果如表5所示。
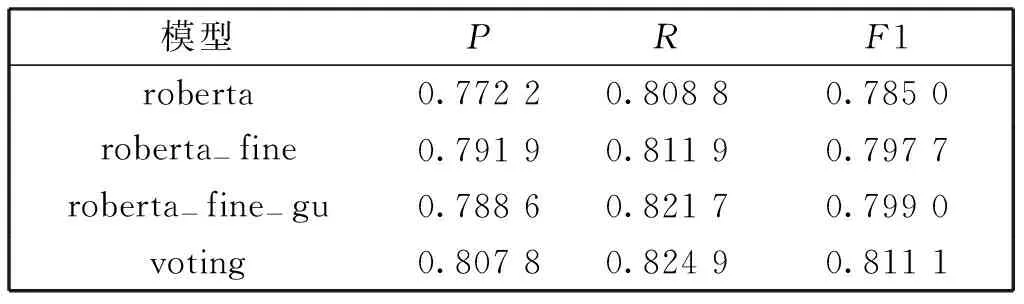
表5 消融实验结果
roberta-fine表示只对预训练语言模型进行微调,通过与不进行微调的实验结果(0.785 0)对比可知,微调语言模型可使分类结果提高1.27%,充分说明了微调模型的有效性。roberta-fine-gu表示在微调分类器模型时,采用逐层解冻方案来实现模型的快速收敛。通过与不进行任何微调的单个roberta模型相比,分类结果提高了1.40%,与只进行语言模型微调的roberta-fine相比提高了0.13%,因而证明了模型微调(包括语言模型微调和分类器模型微调)的有效性。
2.6 与其他模型集成对比分析
本文集成模型与评测比赛中其他模型实验结果比较如表6所示。

表6 其他模型实验结果
评测第一名采用的方案是基于BERT与模型融合的短文本分类方法。该方法采用了BERT模型和一些当前主流的深度学习模型进行集成。评测第二名采用的方案是一种基于预训练模型的医学短文本分类方法。该方法与本文大体相同,不同的地方是其最终没有用到改进的beam search ensemble算法来寻找最佳的模型组合。评测第三名采用的方案是基于BERT融合多特征的临床试验筛选标准短文本分类。该方法是通过采用BERT等一系列预训练语言模型集成和抽取一些文本特征来提高分类结果,融合的特征主要有句法特征、词性标注特征和关键词特征等。通过以上实验结果分析可知本文方法得到模型的有效性。
3 结论
本文提出一种基于迁移学习和集成学习的医学短文本分类方案,利用相关领域外部资源数据对语言模型和分类模型进行微调,在微调过程中利用了斜三角学习率和逐层解冻的微调方法,最后用模型集成学习来提高医学文本分类系统的性能,在模型集成过程中提出了改进的beam search ensemble 算法,该算法可以选出最佳分类模型组合从而可以提高了分类结果,其F1值达到0.811 1。
未来将继续利用迁移学习的一些知识,并尝试在神经网络分类模型算法上有所改进,进一步提升医学文本分类系统的性能。
