A New Matrix Factorization Model for Novel and Diverse Recommendation
2021-01-09ZHAOPengPENGFurongCUIZhihuaJINGXuechunRENKezhou
ZHAO Peng,PENG Furong,CUI Zhihua*,JING Xuechun,REN Kezhou
(1.School of Computer Science and Technology,Taiyuan University of Science and Technology,Taiyuan 030024,China;2.Institute of Big Data Science and Industry,Shanxi University,Taiyuan 030006,China)
Abstract:Modern recommendation algorithms focus on novel items and diverse recommendation list for attracting users. Because a collaborative filtering based recommendation algorithm usually generates similar items for accuracy, it is a challenge to find novel and diverse items while keeping accuracy.Most of the existing studies developed two-step recommendation models that optimize accuracy first and then diversity,and the two-step optimized model generated diverse items at the sacrifices of accuracy due to the conflict of the optimization goals (diversity and accuracy). We propose a new matrix factorization model, that simultaneously optimizes novelty, diversity and accuracy.The new constraint that makes the latent vector of the target user close to the average latent factors of the users who have rated long-tail items was developed for novel recommendations.And the other new constraint that makes each item latent close to the mean of all item latent, was designed for diversity recommendation lists.The comprehensive experiments were conducted on the Movielens100K, Epinions and Rym dataset. Experimental results demonstrated the superior performance in terms of accuracy, aggregate diversity, individual diversity and novelty to the state of the art models.
Key words:recommendation algorithm; novelty; diversity; matrix factorization
0 Introduction
With the advent of the data era, the problem of information overload has become increasingly apparent, and conversational information retrieval has been unable to meet user’s demands[1-2].The recommendation system(RS) was developed to generate personalized recommendation lists by users’ interest.RS was widely used in the e-commerce market, e.g. Taobao, Amazon[3], Netflix[4]. Good recommendations can help users buy more merchandise and bring profits.The most famous RS is the collaborative filter that suggests products by an user’s past preferences. The accuracy of the collaborative filter can be improved by defining different measures of similarity, e.g. content similarity[5], item similarity[6], user similarity[7]. The items that are similar to the user’s history can achieve high prediction accuracy.
However, the targeted user may be distracted by the repeated suggestions if they have bought similar items[8-10]. Users may treat the recommendation list as spam if a lot of similar items listed on it.Thereafter, we concentrated on how to recommend novel items and generate diverse items on the recommendation list[11-12]. The recommendation of high novelty and variety can not only attract targeted users but also improve the visibility of niche products. Most existing methods apply additional novelty filtering and diversity ranking strategies after a collaborative filtering strategy[13-16]. Those two-step models can improve novelty and diversity, but compromise accuracy and efficiency. In this work, we try to achieve an inherent balance among accuracy, novelty and diversity in a more efficient way.
We propose a novel matrix factorization (MF) model[17]by defining diversity and novelty constraints,named Divers and Novel Matrix Factorization (DNMF). The primary contributions of our work can be summarized as follows.
i Propose a recommendation model with a single-step structure that obtains a good trade-off among accuracy, novelty, and diversity.
ii Design constraints of novelty and diversity,so that they are optimized together with accuracy.
iii Extensive experiments on three data sets show that the model is more effective on accuracy, novelty and diversity than the algorithms that optimize accuracy first and then diversity.
The rest of the paper is organized as follows. In Section 1, we discuss the related work on existing recommendation algorithms and diversity enhancing measures. In Section 2, we briefly present the related preliminaries and our proposed model. In Section 3, the experimental setup, evaluation metrics, results and discussions are presented. Finally, the paper is concluded in Section 4.
1 Related work
In this section,we briefly discuss the development of recommendation algorithms from the solo criterion accuracy to multiple criteria. Furthermore, we review the existing works aimed at improving novelty diversity in RS.
In the literature, many techniques are dedicated to improving the accuracy of RS. Matrix factorization (MF) models have achieved state-of-the-art performance in many benchmark datasets and thus have attracted great interest. Classical matrix factorization models include singular value decomposition[18], probability MF[19], non-negative matrix factorization[20], and local matrix factorization[21]. They all believe that accuracy is the only performance criterion. However, some recent studies[10,22]have shown that this assumption is flawed, that is, it is difficult to obtain satisfactory feedback from target users. It is important to emphasize that considering multiple criteria for novelty and diversity is helpful to ensure a good user experience.
Motivated by the research, most of the existing methods design different ranking strategies to promote diversity in the recommendation list.In[23] authors design a weighted ranking strategy in which classical ranking measures (decreasing by rating) and measures based on topic diversification are fused. Authors in[24] construct a knowledge reuse framework to rank items, that generating the recommendation lists which balance accuracy and diversity. In [25] users are split into several groupsviaa clustering approach. Users in the same group have similar levels of tolerance for diversity.Furthermore, the work in[26] considers the task of personalized recommendation as a multi-objective optimization problem, where accuracy and diversity are conflicting optimization objectives. Wang et al[27]use the Item-CF algorithm to predict the ratings of unknown items for the target user and generate a candidate recommendation list. Then, a multi-objective evolutionary algorithm is applied to select the trade-off between accuracy and diversity. Authors in [14] design a novel multi-objective recommendation framework with a new crossover operator to rank items that have been evaluated ratings via the traditional CFs with extended nonlinear similarity model.
All the works discussed above are the recommendation model of a two-step structure that applies an additional ranking strategy after traditional CF schemes. The extra raking strategy has compromised the accuracy and efficiency. In this work, we propose a novel single-step MF model whose goals are accuracy, novelty, and diversity. The model generates a recommendation list using the classic ranking strategy (ordered ratings in descending magnitude) instead of additional and complex ranking strategies.
2 Proposed model
This section formulates the problem, then introduces the preliminaries and the proposed model.
2.1 Problem definition
As mentioned in section 2, novelty and diversity in the recommendation list are as important as accuracy. The three metrics of the recommendation system can effectively improve user satisfaction.
Accuracy is an import metric,which only focuses on items that are relevant to the target user. However, novelty and diversity are different from accuracy. The novelty in recommendations reflects the model’s ability to recommend long-tail pro-ducts. Long-tail products are items that are not familiar to target users or are unpopular. In addition, diversity reflects the number of items in different categories in the recommendation list. It exposes various items to target users, not just similar ones.
Obviously, it is a challenge to obtain the best of the three metrics by one model. We will balance them and find trade-off solutions.
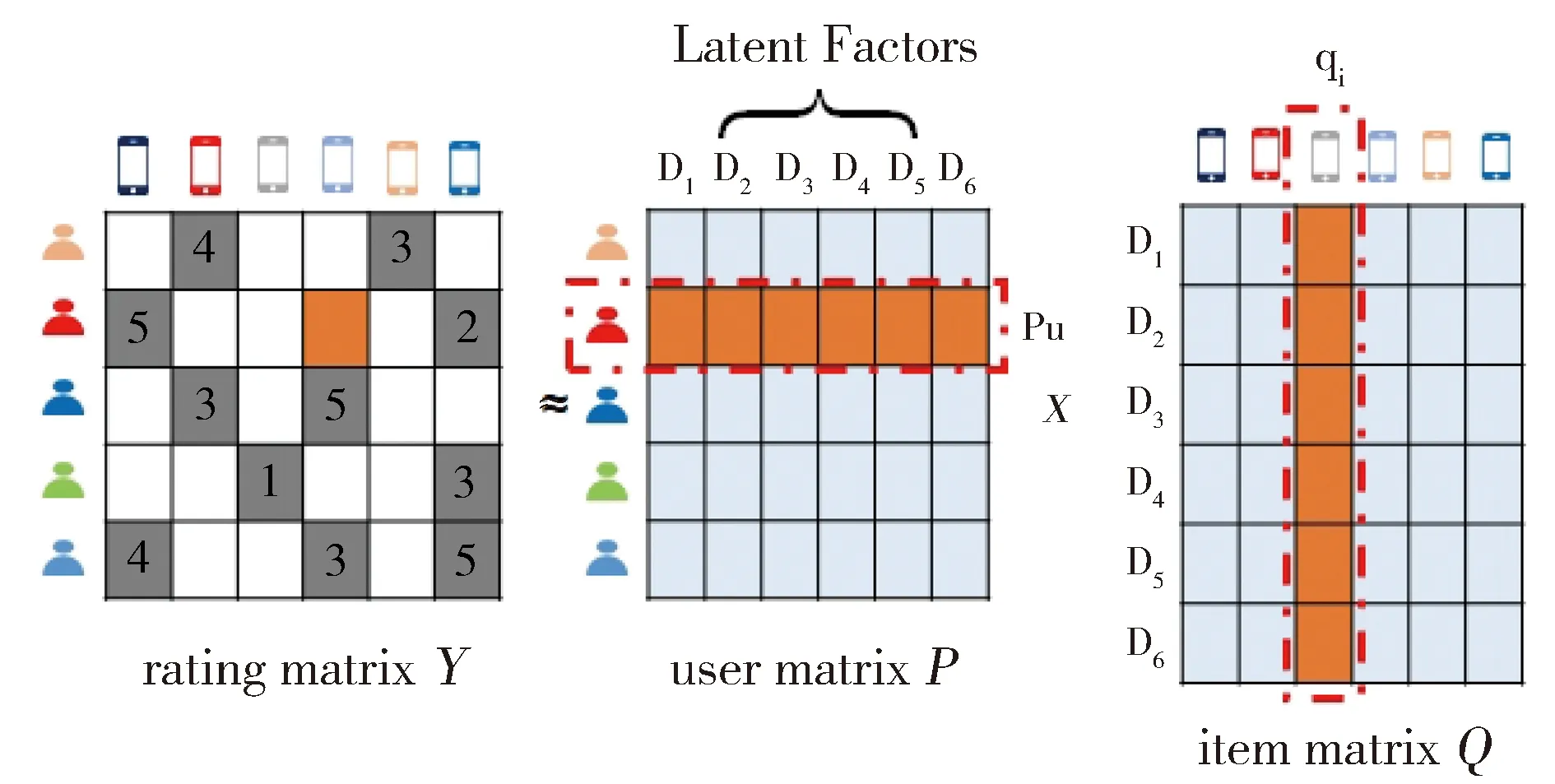
Fig.1 An example of the MF model
2.2 Preliminaries
The MF model usually outperforms traditional methods such as Content-based RS[5], User-based CF (User-CF)[7]and Item-based CF (Item-CF)[6]. Therefore, we introduce the MF model and then develop our model on it.
MF belongs to the latent factor model, which assumes that the behavior of user purchasing is guided by several factors, known as the latent factors[28]. Under this assumption, each of the users and items is modeled as a vector of latent factors. To illustrate the theory of MF, we consider an example shown in Fig.1. Useru’s predicted rating for itemiis obtained by the inner product of their latent factor vectors (puandqi). Equation (1) seeks the best latent factor vector representation of users and items by minimizing the error of prediction ratings and applying the L2 regular term to avoid overfitting.
(1)
In Equation (1),Yuiis the real rating given by useruto itemi;Ris the observed rating set;puandqiare the useru’ s and itemi’ s latent factor vector respectively;λ1andλ2are regularization parameters.
In the matrix factorization model, the rating matrixYis factorized into two low-rank matrices,i.e. user latent factor matrixPand the item latent factor matrixQ. The matricesPandQare respectively composed of latent factor vectorspuandqi. Our model is based on the MF formula, and its matrix form is as follows.
(2)
Yis the rating matrix;Wis an indicator matrix, that the element with a value of 1 represents the observable rating and 0 is the unobservable rating;PandQrepresent the latent factor matrix of users and items, respectively;λuandλvare regularization parameters.
Through the loss function of Equation (2), the user profileUdescribes the history behaviors of users. Thus, the predicted items are highly aligned with users’ history preferences. It ensures high accuracy while ignores novelty and diversity.In order to obtain high novelty and diversity while optimizing accuracy, we propose a new MF model.
2.3 MF of novelty and diversity
Novelty is closely related to the visibility of long-tail products. If the latent factor vector of the user matches the characteristics of the long-tail products, it will increase the exposure of long-tail products. Diversity is introduced based on the assumption that if each item is represented by a similar latent factor vector, then all items have the same probability of being recommended. Consequently, a broader (diverse) spectrum of items is provided to target users.We firstly model novelty and diversity and then introduce the proposed model.
2.3.1 Novelty constraint
Another regularization term is derived under the assumption that if the user can accept long-tail products, a higher novelty can be obtained. Long-tail products are not popular.In this work, we define the long-tail items like the 20% items with the least number of ratings in the dataset.In the previous study, the latent factor of a user is trained by his/her historical ratings. In our model, not only the observed ratings of a user are used, but also the ratings of long-tail items are used to train the latent factors. This strategy can be formulated as a novelty constraint, as shown in Equation (3).
(3)

2.3.2 Diversity constraint
We assume that users’ purchasing decisions are affected by the latent factor vector (qi). The item vector is independent and identically distributed (i.i.d.) and obeys normal distribution.The mean is the mathematical expectation of this normal distribution. Its mathematical expression is as follows.
(4)

If the latent vectors of items are similar, they have similar probabilities to be recommended to the target user. The diversity constraint makes each item vector close to each other by pushing them closer to the mean vector. It is formulated as follows.
(5)
Whereqiis the latent factor vector of itemi. The subsequent experiments show that it can effectively improve diversity in the recommendation.
2.3.3 Proposed MF model
We add the constraint of novelty and diversity to the MF model as additional regularization term, as shown in Equation(6).
(6)
This objective function can simultaneously optimize novelty, diversity, and accuracy. The regularization parameterλdandλnare used to tune the balance between accuracy and regularization terms (novelty and diversity).The previous two-step model optimized the accuracy first and then the diversity.Since the optimization of diversity will seriously damage the accuracy, and the model does not take any remedial measures, so that the accuracy is limited. Our model simultaneously optimizes novelty, diversity, and accuracy so as to minimize compromise on accuracy.Furthermore, it is easier than two-step models to obtain trade-off solutions.
3 Experimental results
In this section, we present the datasets and experimental setup. The comparison experiments are conducted for evaluating the new MF model.
3.1 Datasets
Three real-world datasets are adopted to evaluate the performance of the proposed algorithm, namely, Movielens100 K, Epinions and Rym (Rate Your Music).In the Movielens100K and Epinions data sets, the user’s ratings on items are divided into five levels. Rym, a music rating data set, the ratings range from 1 to 10. The ratings are very sparse as shown in Table 1. Especially for the Epinions dataset, the available rating is less than 0.1%. In order to better capture the balance between multiple evaluation criteria, we select a subset of the three datasets which consists of users who have rated more than 100 times and corresponding items, as shown in Table 1.

Table 1 Statistics of the Abridged dataset
3.2 Evaluation criteria
We choose Precision as the metric for accuracy evaluation. Precision(Pre) is the proportion of items relevant to an user over the size of the recommendation list.We consider items that are rated equal to or greater than 4 as related items. Precision is calculated as Equation (7).
(7)
Where,Uis the set of all users in the test dataset;Luis the recommended list of useru,Turepresents the set of items which relevant to useru.
The diversity is assessed by two different criteria, namely individual diversity and aggregate diversity. The individual diversity (ID) is a measure evaluated from the user’s perspective and reflects the number of items in different categories in the recommendation list. It is defined as in Equation (8).
(8)
Whereiandjrepresent different items in the recommendation list (i≠j);sim(i,j) is their cosine similarity. TheIDis defined as the mean of the diversity of all user recommendation lists. A higherIDindicates a broader (diverse) spectrum of items on the recommendation list.
The aggregate diversity (AD) criterion reflects the ability to recommend various items. It is defined as the total number of unique items in the recommendation lists of all users. A higher value indicates that the system has higher coverage, that is, more items are visible to users. It is expressed as follows.
(9)
where |·| is the cardinality. The above formula reflects the total number of unique items in the recommendation lists of all users.
The novelty in recommendations reflects the model’s ability to recommend long-tail products.A higher value of novelty indicates that more unpopular (or new) items are recommended to users.It can be defined by Equation (10).
(10)
WhereRirepresents the number of times, that itemiwas rated in the dataset.The popular items have a high value ofRi. If they are recommended, it will lead to reduced novelty in recommendations.
3.3 Comparison algorithms
We compare our algorithm with six different algorithms, that focus on accuracy (ProbS), diversity (HeatS), and seeks a balance between diversity and accuracy (HHP, BHC, BD, DiABlO).
(1) ProbS[29]:It’s a diffusion-like recommendation model that mimics material diffusion on user-object bipartite networks and focuses only on accuracy.
(2) HeatS[30]:It’s a diffusion-like recommendation model.The difference is that it emulates the heat conduction process and tends to allocate the user’s total resources to niche items.
(3) HHP[31]:This is a nonlinear hybrid model of the previous two algorithms (HeatS and ProbS), which takes into account both the accuracy and diversity of the recommendation results.
(4) BHC[32]:This work modifies from original HeatS and makes a good trade-off on accuracy and diversity.
(5) BD[33]:It is a balance diffusion model based on the optimal hybrid coefficients of HeatS and ProbS. It is also a recommendation model that balances accuracy and diversity.
(6) DiABlO[34]:It’s a matrix factorization model that incorporates additional constraints. It can also promote diversity while maintaining accuracy.
3.4 Comparison of latent factors
In the LFM, the number of latent factors has a great impact on performance. Fig.2 demonstrates the criteria under different numbers of latent factors (k).
The latent factors represent user preferences and corresponding characteristics of items. The DNMF tries to search for the appropriate latent factor vector, that not only meet the novelty and diversity but also ensure accuracy.Therefore, the more latent factors to search, the harder it is to find their exact expression. Although the accuracy of the proposed algorithm (DNMF) is slightly lower than the DiABlO, other criteria are higher than it. This is the effect of additional regularization term. For the sake of higher accuracy, we set the number of latent factors to 5 (K=5) for subsequent comparison experiments (Fig.2).

Fig.2 Impact of the number of latent factors on algorithm performance.(a),(b),(c) and (d) show the accuracy, AD,ID andNovelty values on different sizes of latent factor k.
3.5 Performance comparison
To evaluate the efficiency of the proposed model (DNMF), each comparison algorithm (mentioned in Section 4.3) are performed on three data sets.The comparison results are illustrated in Tables 2,3 and 4.
By analyzing the results of Tables 2, 3 and 4, we can draw the following conclusions.
(1) The accuracy of all algorithms on the Epinions and Rym data sets is lower than that on Movielens100K, while the novelty and diversity are higher. This is because there are more ratings on Movielens100K (as shown in Table 1). Better accuracy can be obtained on a dataset with more training data.

Table 3 Comparison of RS models for Epinions data set

Table 4 Comparison of RS models for Rym data set
(2) Even though algorithm performance has changed in different datasets, our algorithm always obtains the best performance.Our model can get the best accuracy on the three datasets because the proposed model optimizes accuracy, novelty and diversity in single-step. Other two-layer models compromise the accuracy in the step of optimizing diversity. Although the accuracy of DiABlO is closest to our algorithm, other criteria of it are far worse than that of ours.
(3) In comparison with ProbS, our algorithm is superior in all evaluation criteria. It is worth noting that ProbS is an algorithm focused on accuracy. However, our algorithm is more accurate than it while staying ahead on other criteria. As shown in Table 2, we achieve a 0.06 increase in precision as compared to ProbS and provide a 385 increase in AD.
(4) The HeatS is slightly better than our algorithm in novelty and diversity, but its performance is greatly reduced in terms of accuracy criterion. This is because it only pays attention to diversification, and the promotion of diversity can seriously compromise accuracy. Although our algorithm is not as diverse as HeatS, it can still provide sufficiently diverse recommendations while maintaining high accuracy.
(5) Although the aggregate novelty and diversity of BD are slightly better than that of ours, its accuracy and individual diversity are worse than that of ours. Other algorithms are affected by data sparsity, criteria such as diversity have improved greatly, but accuracy has dropped significantly. However, our algorithm maintains good accuracy while improving criteria such as diversity.

Table 5 Performance ranking of
We count the performance ranking on each data set as the final metric to evaluate algorithms. The results of performance ranking are shown in Table 5. Each element in the table represents the accumulated sum of sorted values of corresponding algorithms. The sorted values are obtained by the ranking of each algorithm on each criterion. As we all know, the smaller the ranking value, the higher the ranking. As shown in Table 5, the ranking value of our algorithm on each data set is the smallest. DNMF has a value of 8 on the Movielens100K data set, but values of 13 and 14 on the Epinions and Rym data sets, respectively. This is due to the effect of data sparseness and the gap between algorithms becomes smaller.In summary, our algorithm achieves higher overall performance than other algorithms.
4 Conclusion
In this work, we propose a new MF model that incorporates two additional regularization terms.It tries to search for the appropriate latent factor, that not only meets the novelty and diversity but also ensures accuracy.Then, it generates a recommendation list using a classic ranking strategy instead of additional and complex rank strategies. We validate the effectiveness of our algorithm on three publicly available datasets and compare it with six algorithms.The results show that our algorithm can obtain the best performance and can achieve significant improvement in novelty and diversity with minimal compromise on accuracy.
Although our method can effectively optimize novelty, diversity and accuracy, its performance on a single criterion is not the best. Therefore, we will improve the model to make up for the above defects.
