基于预训练语言模型的中文知识图谱问答系统
2021-01-09王鑫雷李帅驰杨志豪林鸿飞王健
王鑫雷,李帅驰,杨志豪,林鸿飞,王健
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
问答系统是自然语言处理(NLP)领域中的一个研究热点,并且具有非常广泛的发展前景[1]。根据答案来源的不同,可以分为基于常问问题(Frequently Asked Questions,FAQ)的问答系统[2]、基于社区问答对的问答系统(Community Question Answering,CQA)[3]、基于知识图谱的问答系统(Knowledge Based Question Answering, KBQA)。其中基于知识图谱的问答系统以知识图谱为数据源。知识图谱可以看作是知识的结构化表示,由三元组(主语, 谓词, 宾语)构成,表示实体和实体间存在的语义关系。知名的英文知识图谱有Freebase[4]、YAGO[5]、DBpedia[6]等,中文知识图谱有百度知识图谱、搜狗知立方、北大的PKUBase等。而基于知识图谱问答的主要任务是给定自然语言问题,识别问题中的实体、语义关系,到知识图谱中检索并返回答案[7]。目前基于知识图谱的问答研究方法主要分为两类。
第一类是基于语义解析的方法。早期该类方法使用字典、规则和机器学习,直接从问题中解析出实体、关系和逻辑组合。但此类方法需要研究人员了解语言学相关知识还需要大量的标注数据,不易扩展到大规模开放领域的知识图谱问答任务中,泛化能力不强。随着深度学习在NLP领域的应用,目前将各种神经网络模型与语义解析策略相结合成为语义解析方法的主流。Yih等人[8]引进图谱信息进行语义解析,提出阶段查询图生成方法,该思想也被广泛应用到其他语义解析生成过程中。还有基于编码器-解码器的语义解析方法,例如Wang等人[9]使用序列到序列模型将问题翻译成多个关系的序列。北大Hu等人[10]则提出利用状态转移的原子操作来提升问题语义解析的结果。基于语义解析的方法通常使用分类模型进行关系的预测,但由于知识图谱中包含数十万种关系,训练集难以覆盖如此庞大规模的关系,使得基于语义解析的方法在知识图谱问答上受到限制。
而第二类是基于信息检索的方法,该类方法首先根据问题得到若干个候选实体,从知识图谱中抽取与候选实体相连的关系作为候选查询路径,再使用文本匹配模型,选择出与问题相似度最高的候选查询路径,到知识图谱中检索答案。早期主要是基于特征工程的方法,Yao等人[11]首先分析问题和抽取候选答案,然后生成问题特征和候选答案特征组合排序,此方法需自定义构建特征且对复杂问题处理效果不好。近年,基于表示学习的方法不断被提出且达到较好的性能。表示学习就是将问题和知识图谱中的候选实体映射到统一的语义空间进行比较。例如Dong等人[12]就是利用多柱卷积网络表示答案不同方面的语义信息。信息检索的方法将复杂的语义解析问题转化为大规模可学习问题。侧重于计算问题和候选关系的相似度,在关系选择上具有更好的泛化能力。除此之外,现在也出现一些新方法,如复杂问题分解、神经计算与符号推理相结合、利用记忆网络实现问答等。
虽然近年来有很多基于英文知识图谱的问答研究工作,但相应方法在中文知识图谱问答任务(CKBQA)实现过程中效果并不理想,主要存在两个挑战,一个是实体识别结果不准确。由于中文本身没有天然的分隔符,利用分词工具得到的识别结果词边界不正确,或者实体中出现嵌套、缩写、别名等情况导致错误的实体识别结果。此外,中文中同名实体过多也是实体识别效果不好的主要因素之一。目前中文的实体识别方法主要分为基于规则、基于特征的机器学习、基于神经网络的三种方法。相对来说,基于神经网络的方法在不需要大量人工构建的规则或者特征模板情况下,保证实体识别结果准确率的同时也有较好的泛化能力;CKBQA的另一个挑战是中文丰富的语言表达形式使计算机很难准确掌握问题语义,在关系匹配子任务中此点尤为突出,中文相对英文有更多近义词、同义词,只有用充分的语料训练模型才有可能识别出近义词之间细微的语义差异,但目前此类中文语料并不多。
2018年,谷歌公司提出预训练语言模型BERT(Bidirectional Encoder Representation from Transformers)[13]受到NLP领域广泛关注,并在NLP各项任务上取得了令人瞩目的成绩。本质上,语言模型就是求一个句子序列的联合概率分布。在预训练语言模型出现之前,语言模型的参数都是随机初始化的,是通过不断迭代训练得到的。而预训练的思想就是不再随机初始化模型参数,通过大规模的先验知识来对模型进行预训练得到固定的参数,再针对不同的下游任务语料对模型参数进行微调。目前基于预训练的思想也出现了很多BERT模型的变体。如:Facebook的RoBERTa[14]模型、百度的ERNIE(Enhanced Representation from Knowledge Integration)[15]模型、Yang等人提出的XLNet[16]模型等。其中,RoBERTa模型提出动态掩码机制和用更大的批大小来训练模型,ERNIE模型提出基于短语和实体的掩码策略并引入了对话语言建模机制(DLM),XLNet模型则利用自回归训练方式结合排列语言模型和双流注意力机制,在学习上下文的同时缓解掩码策略带来的数据偏差。这些预训练模型在训练过程中依靠大规模的无标注语料,能学习到丰富的词级别信息,获得更准确常见的分词实体识别结果,甚至可以学习到更深层的句子语法结构,语义级别的信息,有效提升了实体识别和关系匹配的结果。
因此,本文结合预训练语言模型实现CKBQA任务,并通过实验比较了不同预训练语言模型(BERT、RoBERTa、ERNIE、XLNet)及其与主流实体识别和关系匹配模型在中文知识图谱问答任务上的表现。同时提出一套流水线方法,在实体提及识别、实体链接、关系匹配子任务上提出新的框架,不仅能高效地实现问答,而且可以应用在其他中文知识图谱上,保证方法的泛化性。并通过CCKS2019-CKBQA测试集上的实验结果验证方法的有效性,最后基于本文方法实现了问答系统展示。
1 模型及方法
提出的方法(如图1)包含以下五个模块:问题分类、实体提及识别、实体链接、关系匹配、桥接与答案检索。在问题分类、实体提及识别和关系匹配模块中设计不同模型进行比较。
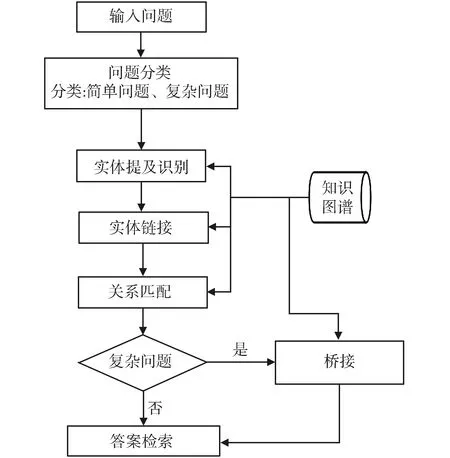
图1 问答系统结构Fig.1 Structure of question answering system
1.1 问题分类
将问题分为简单问题和复杂问题两类,通过训练集提供的查询语句对问题进行标注。例如,一个问题:“英国什么时候国庆?”,查询语句为“select?x where {<英国-(大不列颠及北爱尔兰联合王国)> <国庆日>?x.}”,将此类只涉及单个三元组的问题定义为简单问题,标注为0;而问题:‘拜仁的西班牙球员都有谁?’,查询语句为“select?x where {?x <所属运动队> <拜仁慕尼黑足球俱乐部>.?x <国籍> <西班牙-(西班牙王国)>.}”,将此类涉及两个及以上三元组的问题定义为复杂问题,标注为1。用标注好的语料训练模型,模型命名为 BERT-classify,如图2所示。
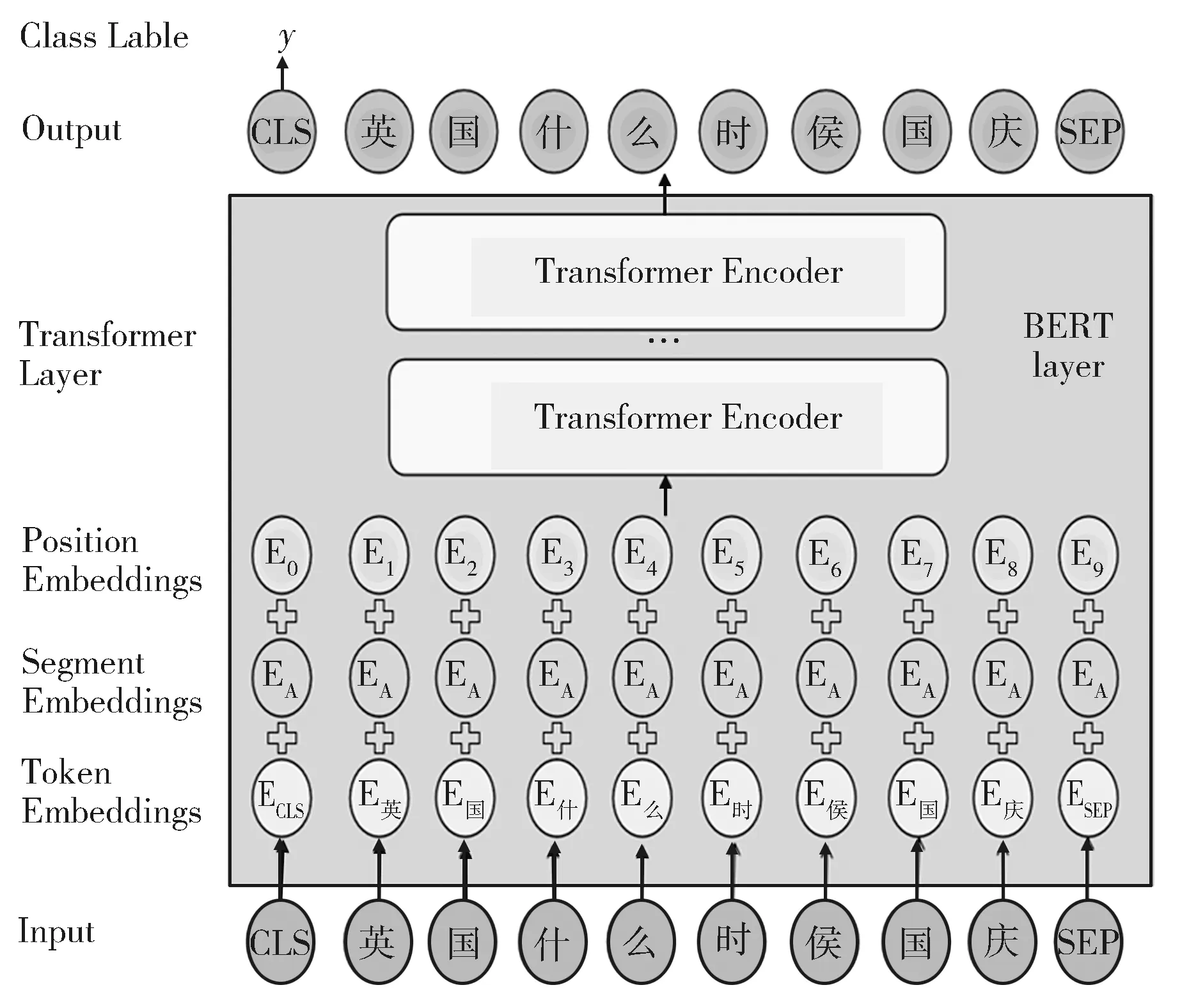
图2 BERT-classify的模型结构Fig.2 Structure of BERT-classify model
其他预训练语言模型都是基于Transformer体系结构对输入序列进行编码,模型结构相同,只是训练机制不同。因此以下其他模块也都只对BERT相关模型做介绍。模型输入向量由三部分组成:Token Embeddings表示词向量,Segment Embeddings用来区分不同的输入句子,Position Embeddings表示词在句子序列中的位置信息。而且,BERT在输入句子序列前添加一个特殊的[CLS]标记(该标记对应的输出向量可作为整个输入序列的语义表示,通常用作分类任务),在句子序列后添加一个特殊的[SEP]标记(用于句子分割)。模型首先将一个问题q处理为词序列形式:
Qq={[CLS],q1,q2,…,qn,[SEP]} ,
(1)
n为句子序列长度,选择[CLS]标记对应的隐藏层输出作为问题表示,再将其输入到一个多分类层,得到预测结果:
H[CLS]=BERTlayer(Qq)[CLS],
(2)
Ppred=softmax(H[CLS]WT+b) ,
(3)
其中,softmax是概率归一化函数,Hq∈RD,W∈RK×D和b∈RK×1是要学习的权重,D在本文是768,为BERT模型隐藏层的维度,K是分类标签的个数。
损失函数使用多分类交叉熵:
(4)
1.2 实体提及识别
实体提及识别模块的作用是识别出给定问题中的主题(话题)实体。本模块主要包括词典分词、实体识别、属性值识别三部分。
1.2.1 词典分词
词典分词需要构建辅助词典,构建方法如下:
(1)实体链接词典:实体链接词典为文本中的实体提及到知识图谱中实体的映射;
(2)分词词典:通过实体链接词典中的所有实体提及,以及知识图谱中所有实体构建;
(3)本任务是开放域的知识图谱问答,因此将网络上常见的中文实体词典作为外部资源引进,共包括电影、明星、动漫、美食等21个领域词典。
根据辅助词典利用分词工具得到候选实体提及。但仅用分词工具得到的结果存在一定错误,如嵌套实体通常只保留较长的情况——问题“大连理工大学校歌是什么?”,正确的分词结果应当为“大连理工大学 |校歌|是|什么|?”,但由于词典中存在更长的实体“大连理工大学校歌”,因此得到错误的实体提及。针对这样的问题,本文增加了实体识别模型来改进候选实体提及结果。
1.2.2 实体识别
本模块基于不同预训练模型设计实体识别模型。构建实体识别训练数据时将查询语句中的标注实体提取出来,还原为实体提及。例如,一个问题“英国什么时候国庆?”,将查询“select?x where{<英国-(大不列颠及北爱尔兰联合王国)> <国庆日>?x.}”中的实体<英国-(大不列颠及北爱尔兰联合王国)>还原为问题中的实体提及“英国”。本文采用实体识别任务中常用的”BIOES”标注策略,B I E 分别表示长实体的头部,中间和尾部,S表示单一实体,O表示非实体。
BERT-ner模型结构如图3,由BERTlayer、BiLSTM层[17](双向长短时记忆网络)和CRF层[18](条件随机场)构成。其中BERTlayer结构与图2相同。
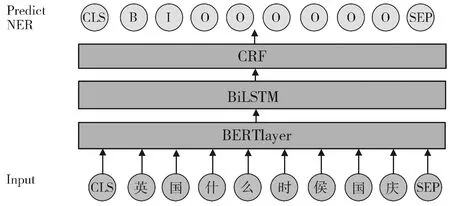
图3 BERT-ner的模型结构Fig.3 Structure of BERT-ner model
将问题序列输入到BERTlayer中,得到每个单词的表示:
Hq=(H[CLS],H1,H2,…,H[SEP]) 。
(5)
Hi(i=1,2,…,[SEP])为第i个单词对应的BERT层输出。再将其送到BiLSTM层和CRF层预测标签序列,这样能对标签进行全局优化提升实体识别结果。
B=BiLSTM(Hq) ,
(6)
C=CRF(B) 。
(7)
根据CRF层预测的概率分布结果,取概率最大的标签作为实体识别结果。
1.2.3 属性值提及识别
问题中包含的属性值规范性较低,可能无法直接与知识图谱对齐,因此上述基于词典分词的方式不适用。本文针对不同类型的属性值,使用不同方式进行识别:
(1)书名、称号或数字:构建正则表达式;
(2)时间属性:还原为知识图谱中规范的时间表达,如“1989年九月”还原为“1989.09”;
(3)模糊匹配属性:建立字到属性的映射字典,统计问题中字对应属性出现的总次数进行筛选。
1.3 实体链接
实体链接是将实体提及对应到知识图谱中的实体。对于候选实体提及,本文首先过滤掉词性为语气词、 副词等的提及(考虑到这类词语通常不会是实体)。使用实体链接词典,将实体提及对应的所有实体加入候选实体中。对于属性值提及中的每个属性,由于抽取时已经与知识图谱对齐,故直接将其加入候选实体中。本文设计两组特征提升候选实体筛选结果:
(1)实体提及特征:实体提及的长度(该实体对应的实体提及字数),实体提及的词频,实体提及的位置(该实体对应的实体提及距离句首的距离);
(2)实体特征:实体两跳内关系和问题重叠词的数量,实体两跳内关系和问题重叠字的数量,实体的流行度(实体的一跳关系数量),实体的类型,实体的重要度(知识图谱中包含该实体的三元组数量)。
在训练集上,将标注的正确实体标为1,其余候选实体标为0,使用逻辑回归模型对上述特征进行拟合。在测试集上,使用训练好的模型对每个候选实体打分,保留分数排名前n的候选实体。
1.4 关系匹配
在CCKS2019-CKBQA任务中,70%以上的问题只包含一个主语实体且最多包含两个语义关系。因此,对于每个候选实体,抽取与其相连的单跳关系和两跳关系作为候选的查询路径,形式如 (entity,relation)或(entity,relation1,relation2)。再将候选路径与问题进行文本匹配,根据匹配的得分筛选候选路径。
传统上,文本匹配模型(如Siamase[19]模型)被用来学习自然语言问题和候选查询路径间的相似度,更侧重于学习同一语义不同表达间的相似性,需要大规模的语料作为支撑,模型的性能受到语料规模的约束。而预训练语言模型正是在大规模语料上通过无监督训练得到的神经网络模型。因此,本文基于不同预训练的语言模型,设计关系匹配模型,在训练集上对文本匹配模型进行微调。在微调过程中,由于预训练模型是基于自然语言训练的,而生成的候选查询路径是不符合自然语言逻辑的。因此,本文将候选查询路径还原为人工问题。 例如,(侯赛因,出生地)被还原为“侯赛因的出生地?”。对于训练集每个问题,正确关系路径标为 1,并随机选择三个候选查询路径作为负例,负例标为0。将自然语言问题和人工问题拼接,训练模型,关系匹配模型结构与问题分类模型结构相同,依然以[CLS]标记对应的输出作为文本的语义表示,不同的是在输入部分要输入两个序列,以[SEP]标记分割,如式(8)。在测试集上,使用预训练模型对所有的自然语言问题-人工问题对进行打分。
RA,B={[CLP],qA,[SEP],qB,[SEP]} ,
(8)
其中qA是自然语言问题,qB是人工问题。
1.5 桥接及答案检索
本文定义的简单问题是单实体单关系问题,复杂问题可分为单实体多关系问题和多实体问题。通过上述模块的处理,既可以解决单实体单关系简单问题,也可以解决部分单实体多关系复杂问题。因此本文针对复杂问题中的多实体问题设计了桥接方法。具体做法是对每个问题,保留前30个单实体的查询路径(entity1,relation1)。对这些查询路径,到知识图谱中进行检索,验证其是否能和其他候选实体组成多实体情况的查询路径(entity1,relation1,ANSWER,relation2,entity2),如存在,将其加入候选查询路径中。最后,将单实体情况排名前三的查询路径和本模块双实体情况下得到的查询路径与问题计算重叠的字数,选择重叠字数最多的作为最终的查询路径,认为其在语义和表达上与问题最相似。根据得到的查询路径构建SPARQL语句在图谱中检索答案。
2 实验设置与结果分析
2.1 实验设置
本文实验基于CCKS2019-CKBQA数据集。该数据集来自北京大学和恒生电子有限公司共同发布的中文开放域知识图谱问答任务。数据集中标注的数据抽自于评测官方提供的开放域中文知识图谱 PKUBase。数据划分、三元组统计分别如表1、表2所示。实验结果用准确率(Accuracy)、精确率(P)、召回率(R)和F1值等指标来评价。

表1 CKBQA数据集划分

表2 知识图谱知识数量
2.2 参数设置
不同模块BERT模型参数如表3,其他预训练模型参数设置与对应模块BERT模型参数相同。

表3 不同BERT模型的参数设置
2.3 实验结果与分析
由表4问题分类的准确率可以看出,几种预训练模型的问题分类性能相差不大,因为ERNIE模型在训练时额外引入了对话语言建模机制,可以更好地理解中文问题细微的语义表示,因此ERNIE-classify结果稍好。分析部分错误样例发现,很多复杂问题被错分为简单问题。原因是问题中的实体在知识图谱中具有别名。如:测试集中问题“哥哥出生于什么地方?”,查询为“select?ywhere {?x<别名> "哥哥".?x<出生地>?y.}”,根据标注策略,其被定义为复杂问题,实际上通过实体链接模块后,别名已对齐,将“哥哥”链接到知识图谱中的“张国荣-(华语歌手、演员、音乐人)”实体。查询单个三元组(<张国荣-(华语歌手、演员、音乐人)> <出生地>?x)即可得到答案。

表4 不同预训练模型在问题分类任务上的性能比较
在表5的实体识别结果中,预训练语言模型比中文实体识别最好的模型Lattice-LSTM[20]效果还要高1.5-2.5个点。证明预训练语言模型能更准确地识别词边界信息,得到更精确的实体。但所有预训练模型的F1值都没有到70%,主要原因是标注的正确实体是知识图谱中的规范表现形式,如果将预测出的实体与知识图谱对齐的话,识别结果就会有很大提升。在此模块中XLNet-ner模型、RoBERTa-ner模型、ERNIE-ner模型识别效果都强于BERT-ner模型,是由于BERT模型是基于大规模语料中词共现来预测实体,而XLNet模型相对BERT的WordPiece分词方法使用了SentencePiece方法,优化了对中文分词的效果。RoBERTa模型的动态掩码机制对相同样本考虑到了更多的掩码可能,提升了实体识别性能。ERNIE模型效果最好,是由于其训练时加入了先验语义知识,此外ERNIE模型不仅仅对随机字符mask还对句子中的短语mask,这样能学习到单词与实体之间的关系。因此,ERNIE模型能更好地识别出短语。例如,问题“战国四大名将之首的外号是?”,正确的实体是“四大名将之首”,BERT-ner模型识别出来的是“四大名将”和“首”两个实体,而ERNIE-ner模型能准确识别为短语。

表5 不同预训练模型在实体识别任务上的性能比较
对于实体链接模块,本文在测试集上针对构建的特征进行了消融实验。实验结果如表6,可以看出:实体提及的特征和实体的特征对候选实体筛选均有帮助。只保留top5的候选实体,可以得到与保留全部候选实体接近的召回率,并且可以有效降低噪音和后续计算量。

表7 不同关系匹配模型的性能比较
通过表7的实验结果得到:在关系匹配模块上,基于预训练语言模型的结果大幅优于一般的文本匹配模型Siamase(49.7%)。主要因为测试集中有60%的问题包含不可见关系。而预训练语言模型在其训练过程中可以学到大量关系的表示,即使对不可见关系也有一定的预测能力。此模块中,基于ERNIE的关系匹配模型同样效果最好,优于其他基于预训练模型的匹配模型。当加入桥接方法和进行重叠字数匹配后,实验结果都有所提升。
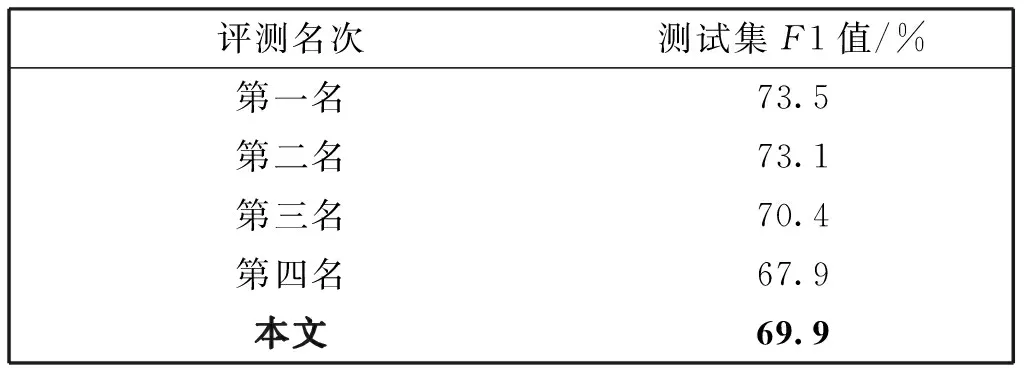
表8 测试集F1值比较
本文最终在测试集上达到了69.9%的F1值。表8为当时评测时F1值结果。由于此数据集为评测数据集,参赛队伍会构建大量人工特征规则,通过多模型融合来提升结果,所以与本文方法没有直接可比性。但本文方法仍能优于评测第四名(67.68%),达到接近评测第三名(70.45%)的性能,在保证模型结构简单的同时证明了本文提出方法的有效性。
通过不同模块不同预训练语言模型表现的结果可以看出,基于ERNIE模型效果全都是最好的,说明在中文问答任务上,ERNIE模型可以更好地学习到中文文本的语义表示,更适合处理中文文本。因此可以尝试在其他中文NLP任务上应用ERNIE模型作为底层编码器验证效果。
最后基于本文提出方法实现了开放域图谱问答系统展示,在输入框中输入问题,如:“清华大学的校长是谁?”,可看到系统能返回正确简洁的答案。系统访问链接为:http:∥www.medicalqa.xyz:5005/.展示效果如图4所示。

图4 问答系统服务页面Fig.4 Online question answering system
3 结论与展望
本文通过实验验证了ERNIE语言模型更适合应用在中文图谱问答任务中。同时本文在实体提及识别、实体链接、关系匹配子任务上提出的新框架有助于高效精确地识别匹配结果。并通过在CCKS2019-CKBQA测试集上的结果验证方法的有效性,最后基于本文方法实现了问答系统展示。
虽然模型在回答简单问题上可以有较好的性能,但是在解决复杂问题时,本文方法只能解决部分双实体问题,对涉及更多实体的复杂问题也无法处理。在实体链接部分保留全部结果的召回率是93.1%,说明仍有很多实体没有被识别出来,所以在后续的研究工作中可以考虑对复杂问题进行语义解析,通过构造复杂问题查询图来提升模型回答复杂问题的能力,并融入知识图谱的全局信息,如利用transE[21]、transH[22]等知识图谱建模方法来提升候选实体提及的结果。
