基于PCA图像粒化的多粒度图像分类模型研究
2021-01-09丁晓娜刘春凤刘保相
丁晓娜,刘春凤*,刘保相,2
(1.华北理工大学 理学院,河北 唐山 063210;2.河北科技学院,河北 保定 071000)
0 引言
随着计算机处理技术的完善,图像识别与分类研究得到很大发展,为人们生活带来极大便利。现阶段图像分类识别技术一般包括人脸识别、车辆分类、动物分类等[1-3]。人脸识别主要运用在安全检查、身份核验与移动支付中;物体分类主要是对动物、植物、车辆等进行分类[4-5]。图像分类一般分为四部分,分别是图像采集、图像预处理、特征提取、图像分类。信息科技的迅猛发展,积累了海量图像数据,如何快速、准确实现图像分类,挖掘出有用的图像信息是目前研究的关键。
粒计算方法是由Zadeh首次提出的一种新理念和方法,主要用于处理不确定、不精确、不完整的信息[6]。粒计算的实质是通过选择合适的粒度,来寻找一种较好的、近似的解决方案,避免复杂的计算,从而降低问题求解的难度[7]。Wang[8]和Hu[9]等介绍了粒计算的相关模型,Savchenko等人[10-11]提及了粒计算在图像处理方面的应用。采用信息粒化进行图像处理称为图像粒化,图像粒化是将图像按照一定规则提取转化为特征信息粒。目前,信息粒化的基础模型主要有三种,分别是基于模糊集的模型、基于粗糙集的模型以及基于商空间的模型[12],但是随着人们需求的增多,越来越多的粒化方法被提出。其中,主成分分析(PCA)因其较高识别率和简便性的优点被发掘用于图像粒化。周松锋、杨梦潇等人[13-14]将其用于人脸识别算法的研究,加快了样本训练速度,提高了模型鲁棒性。张里博等人[15]将PCA粒化方法带入多粒度的代价敏感三支决策识别中,提高了识别精度,随着研究的深入,PCA图像粒化将成为图像粒化的重要研究方向。
近年来,基于信息粒化进行图像识别的模型越来越多,人们致力于学习出一个稳定的,在各个方面都表现优秀的粒化方式,但只能找到多个有偏好的粒层。多粒度模型可以通过一定的规则将多个单粒度进行粒度提升,通过比较多个低层单粒度以及提升后的高层粒度得到较好的识别效果。粒度提升可采用集成学习进行,集成学习组合多个单分类器的分类预测结果,常用投票(Voting)和叠加式(Stacking)两种方法[16-18]。李珩等人[19]将Stacking与Voting进行了比较,发现无论基于Voting还是基于Stacking的组合分类方法,对于单分类器都是有帮助的,而基于Stacking的方法比基于Voting的方法更有效果。蒋明会等人[20]将Stacking的思想用于多粒度模型中,得到了相比单一粒度,更全面、立体和丰富的用户画像。
基于以上分析,本文提出了改进多粒度图像分类模型,并采用Kaggle公布的图像数据集进行验证,使用模型对卧室,厨房,办公室,海岸,森林,山脉,野外,高速公路,市区,街道,高层建筑十一类图像进行分类。在进行图像预处理后得到低层信息粒,使用Stacking算法进行粒度提升,避免了单一粒度所带来的偏爱问题,大大提高了图像分类效率。
1 多粒度图像分类模型
Stacking模型是一种集成方法,它将多个分类器线性组合,解决了目前大多数单分类器模型在处理问题时有明显偏好的问题,而融合了Stacking思想的多粒度模型充分继承了这一优点,在人物画像、图像识别方面表现突出。本文在蒋明会等人[20]提出的多粒度人物画像的模型基础上,结合PCA粒化方式提出了多粒度图像分类模型。
1.1 Stacking模型
Stacking模型是多粒度图像分类模型的基础,它是Worlpert教授于1992年提出的一类集成学习方法。该模型共分为两层,从原始训练集中学习的若干个基分类器为0-层,从基分类器的结果获取输入的此分类器为1-层,该层将0-层中每个基分类器的结果组成一个新数据集作为输入,用于训练次级分类器[21]。
Stacking模型为了避免产生过拟合,在训练基分类器时采用k折交叉验证,将原始训练集分为k个大小相同的集合,每次选取k-1个集合进行训练,训练出的模型在未选取的集合上进行验证,将验证集上得到的结果作为1-层的输入。如图1所示的Stacking模型选取了1个基分类器进行分类,采用3折交叉验证法,即将0-层训练集分为3个大小相同的集合,每次选取2个集合(黄色部分)进行训练,并在未选取的集合上进行验证,得到的验证结果作为下一层的输入,从而减小过拟合现象,增加分类准确率。
1.2 多粒度图像分类模型
改进多粒度模型就是在Stacking算法的基础上,根据多粒度人物画像模型的原理提出的图像分类算法。多粒度模型是指数据在多个不同层次的粒度下进行表示,并使用不同粒度下的数据进行实验,形成对比实验,从而生成识别效率较高的结果[20]。改进多粒度模型主要融入PCA粒化方法优化0-层信息粒,提高了输入数据质量,增大了分类精度。模型首先主要采用高斯滤波对原始数据进行图像预处理,滤除图像噪声,然后采用PCA粒化方式进行粒化,得到0-层信息粒,将其输入基分类器实现粒度融合,得到1-层信息粒,最后输入次级分类器完成图像分类过程。
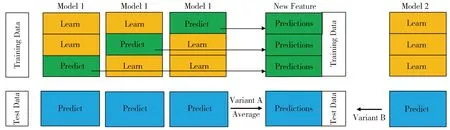
图1 Stacking算法结构Fig.1 Structure of stacking algorithm
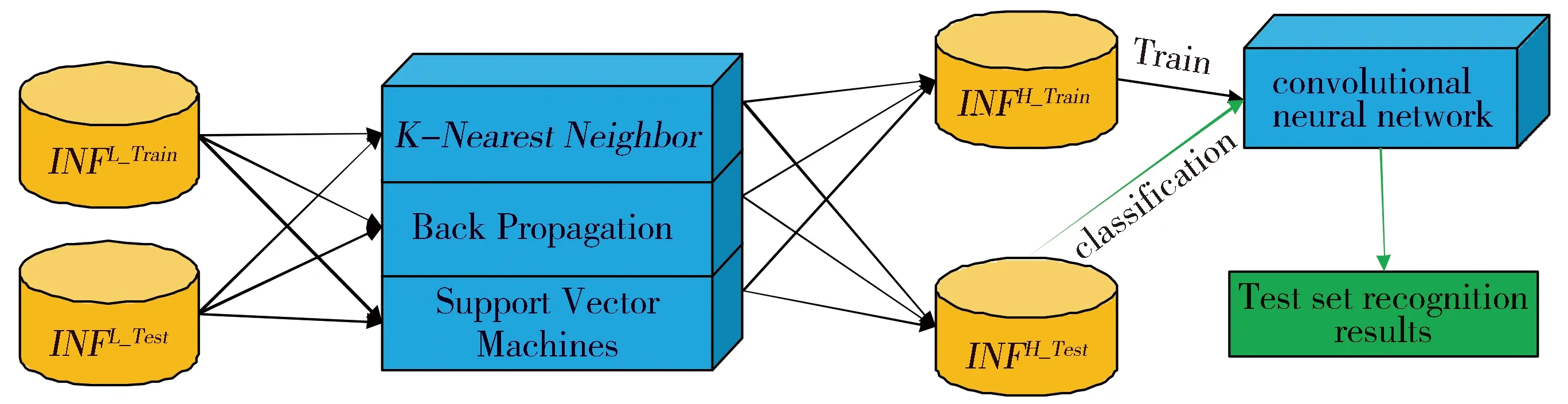
图2 多粒度图像识别模型Fig.2 Multi-granularity image recognition model
改进多粒度模型将图像处理后得到的0-层信息粒,选取70%作为0-层训练信息粒INF0-Train,其余的作为0-层测试信息粒INF0-Test。然后通过粒度提升融合成1-层信息粒,分别得到1-层训练信息粒INF1-Train,1-层测试信息粒INF1-Test。最后在多层表示下进行后续模型训练工作。其图像识别模型架构如图2所示。
在进行粒度提升时,需要选取三个合适的分类模型作为基分类器来提高图像分类质量,本文选取应用较为广泛的K近邻(K-Nearest Neighbor,KNN)算法、BP(Back Propagation)神经网络算法、SVM(Support Vector Machines)算法三种图像分类算法进行试验,原因如下:
① KNN算法无须参数估计,适合对稀有事件进行分类,特别是对于多分类问题。同时,该算法对数据没有假设,准确度高,对异常点不敏感[22]。
② SVM算法在小样本训练集上能够得到比其他算法好很多的结果,该算法也是目前最常用的图像分类效果最好的分类器之一,因其优秀的泛化能力以及本身的优化目标结构化风险最小所以选取SVM算法作为其中一个分类器[23]。
③ BP神经网络具有任意复杂的模式分类能力和优良的多维函数映射能力,可解决简单感知器不能解决的异或等问题,因此将其作为一个分类器[24]。
将BP神经网络、KNN、SVM三个子模型进行排序,第i个子模型记为SubModel-i,将INF0-Train随机均分成k份,第i份记为INF0-Train-i,用INF0-Train分别减去INF0-Train-i剩余的数据,训练子模型SubModel-i,使用训练的子模型对INF0-Train-i进行识别,识别结果记为INF0-Train-pre-i,同时识别INF0-Test,识别结果记为INF0-Test-pre-i。将得到的INF0-Train-pre-i(i=1,2,…,k)进行样本维度拼接,得到SubModel-i的高层训练粒度表示INF1-Train-SubModel-i;将产生的INF0-Test-pre-i(i=1,2,…,k)进行样本维度求均值,得到SubModel-i的高层测试粒度表示INF1-Test-SubModel-i。将产生的INF1-Train-SubModel-i(i=1,2,…,k)进行特征维度拼接,即拼接后总样本数目等于每个拼接的样本数目,但拼接后每个样本的特征维度是参与拼接的各样本特征维度总和,得到高层训练信息粒INF1-Train;同 理 产 生 的INF1-Test-SubModel-i(i=1,2,…,k)进行特征维度拼接,得到高层测试信息粒INF1-Test。
将0-层产生的INF1-Train作为训练集对1-层卷积神经网络进行训练,然后将INF1-Test输入训练好的1-层卷积神经网络,识别INF1-Test。
2 基于PCA图像粒化的数据处理
在利用模型进行图像分类前,需要先对图像数据进行预处理、PCA粒化,从而提高训练精度,文章选取Kaggle公布的图像数据集进行实验,数据集中包含卧室、厨房、办公室、海岸、森林、山脉、野外、高速公路、市区、街道、高层建筑十一类图像,分类难度较大。
2.1 图像预处理
多粒度图像分类模型进行图像分类时需要先进行数据预处理,使用高斯滤波去除噪声,高斯滤波是一种线性平滑滤波,广泛应用于图像处理的滤除噪声过程。高斯滤波就是对整幅图像进行加权平均的过程,每一个像素点的值,都由其本身和邻域内的其他像素值经过加权平均后得到。高斯滤波的具体操作是:用一个模板(或称卷积、掩模)扫描图像中的每一个像素,用模板确定的邻域内像素的加权平均灰度值去替代模板中心像素点的值。图像经过高斯滤波去噪后的结果如图3所示。
2.2 PCA图像粒化
图像粒化是多粒度模型运行的前提,它将图像按照一定规则转化为相应的特征信息粒,转化为信息粒的过程称为信息粒化。信息粒化将一个整体问题粒化为若干个信息粒,然后将每个信息粒看作单独的一部分进行研究,它在解决不精确、不明显以及复杂问题等方面有独特优势。图像粒化的本质是特征信息粒化,为了更加准确的提取图像中的有效信息,张里博等人[18]提出了PCA粒化法,它能根据给出的一张图像重构出一系列从粗粒度到细粒度的图像,本文采取主成分粒化的方法处理图像。主成分分析算法的主要思想是找到一系列垂直的坐标轴以投影初始数据,并且投影后的数据在新的坐标轴上方差递减。假设所有图像满足零均值的条件,对于一个m维的单位向量u1∈Rm,u1Tu1=1,样本图像都能投影到该向量上,投影后样本的方差可以表示为:
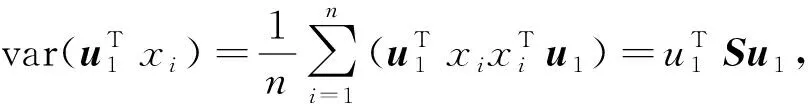
(1)
其中,S是原始数据的协方差矩阵,
在单位向量的限定下,求出投影后数据的方差关于u1的最大值。采用拉格朗日乘子法来求解,令d1为一个拉格朗日乘子问题转化为一个无约束优化问题,如公式(2)所示:

(2)
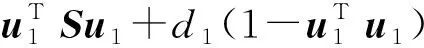
Su1=d1u1,
(3)

图3 高斯滤波去噪前后对比Fig.3 Comparison before and after gaussian filter denoising
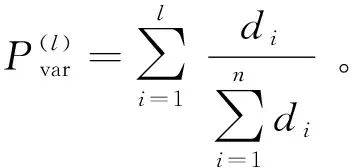
(4)
以上得到的是第l步的图像,类似地可以依次得到从粗粒度到细粒度的一系列图像。对于一个图像样本,假设已经按照上面的方法得到了主成分矩阵U={u1,u2,…,um},即可根据这m个主成分重构图像。重构过程中,选择的主成分越多,图像粒度越细。
对于一个样本,用到的主成分越多,数据包含的信息越多,重构数据保留方差的百分比越高,图像粒度越细,图4展示了主成分粒化法得到的不同粒度图像,可以看出从粗粒度到细粒度的粒化图像的不同区分度。随着粒度的不断提升,图像越来越近接原始图像。
本文选取200个成成分分量对图像进行粒化,将得到的结果输入基分类器进行分类,图5展示的是对图3中(a)、(b)、(c)、(d)的四个图像进行PCA粒化的结果。
3 实验结果及分析
将基于PCA粒化处理过的图像输入基分类器中,通过粒度融合得到1-层信息粒,然后将其输入次级分类器卷积神经网络中进行图像分类。实验数据选用Kaggle公布的图像数据中的440张作为训练集,110张作为测试集(每个种类的图像选取10张),图像像素为112×92。实验硬件在Win7系统Matlab. R2014a上进行。三个子模型BP神经网络,KNN,SVM以及本文改进的多粒度融合模型对数据集图像分类识别的效果如表1所示。
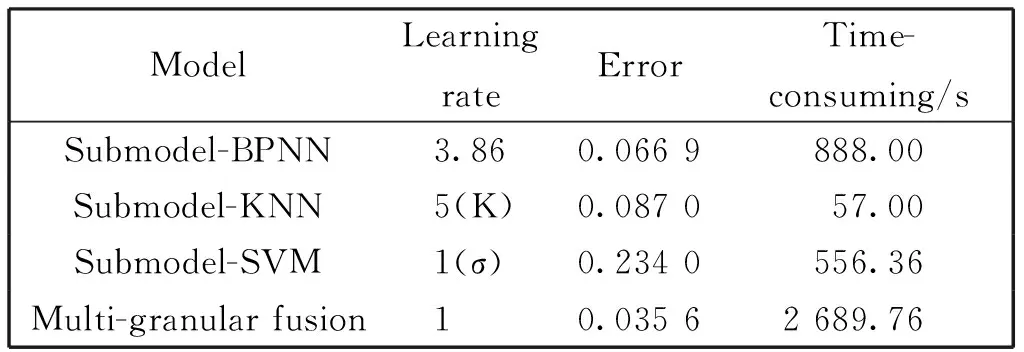
表1 各个模型对图像的分类识别效果
由表1可知多粒度融合模型分类误差最低为0.035 6,但是模型训练所消耗的时间最长为2 689.76 s。每个子模型与多粒度融合模型对图像的识别效果直观表现如图6-图9所示。
从图6中可以看出,样本训练中迭代次数达到998次时均方误差不再减小,此时均方误差为0.066 9。从图7中可以看出当K值为5时误差最小为0.087 0。从图8中可以看出σ值的不断增大分类误差也随之变大,当σ=1时误差最低为0.234 0。从图9可以看出多粒度融合模型对图像的分类误差最低为0.035 6。由此可知,多粒度图像分类模型的分类效果很好,有一定的研究意义。

图4 PCA法从粗粒度到细粒度的粒化图像Fig.4 Granulated images by PCA from coarse-grained to fine-grained
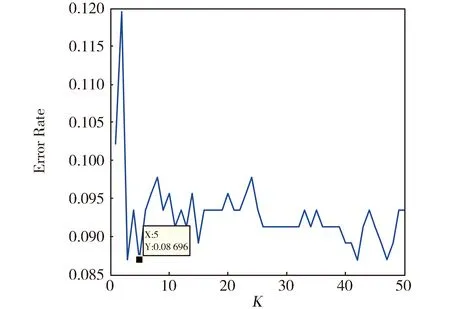
图7 KNN不同K值下的分类误差Fig.7 Classification error underdifferent K values of KNN

图8 不同σ值下SVM分类误差Fig.8 SVM classification error under different σ values
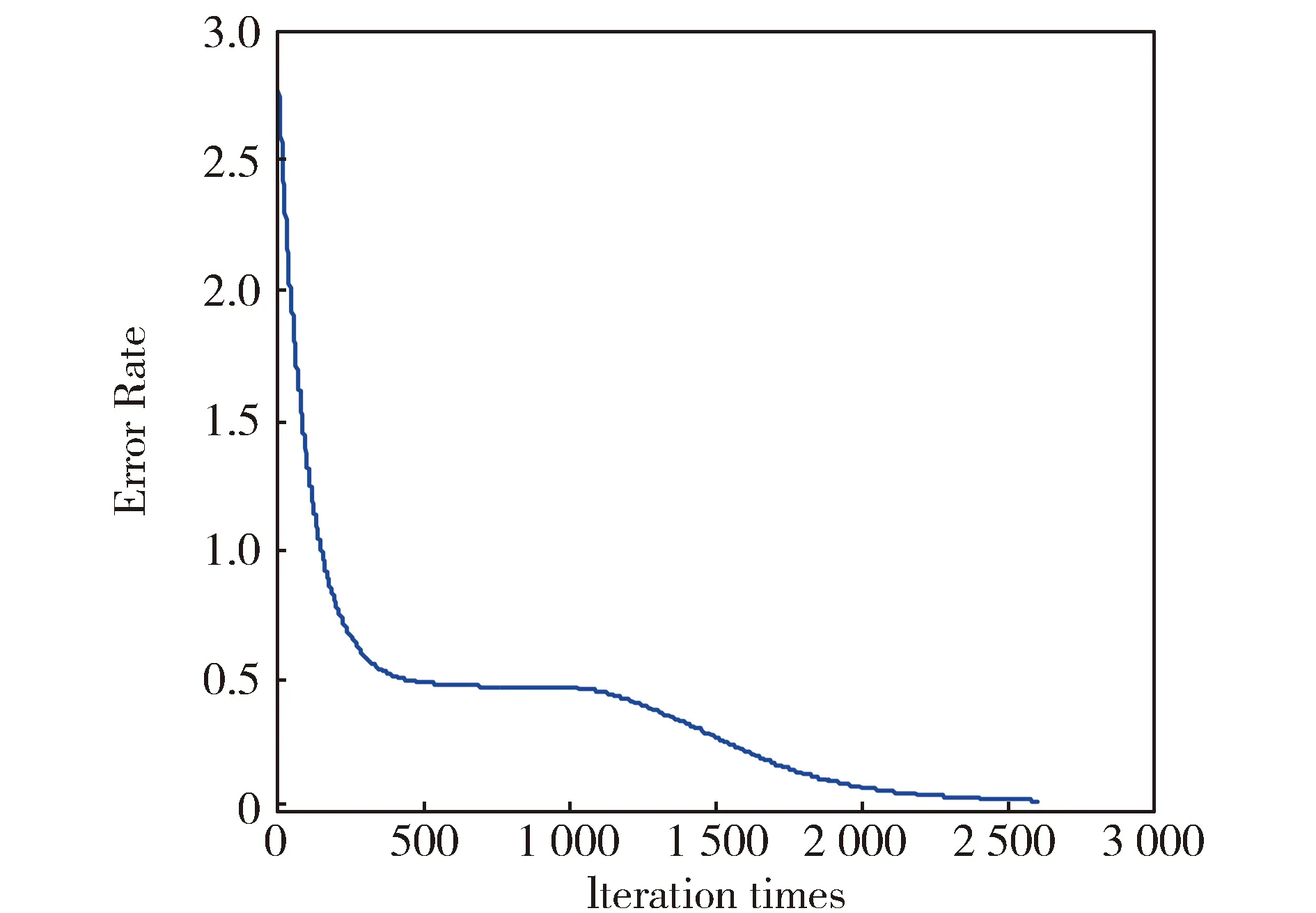
图9 多粒度融合模型训练误差Fig.9 Training error of multi granularity fusion model
4 结论
本文提出的基于PCA图像粒化的多粒度分类模型,选取BP神经网络、KNN和SVM作为基分类器,卷积神经网络作为元分类器。用PCA粒化高斯去噪处理后的数据,将粒化后的数据训练各个分类器。实验结果表明,多粒度融合模型对图像的分类效果好于各个子模型的分类效果,且多粒度融合模型的分类误差较小,为0.035 6,有一定的研究价值。但是模型的训练耗时最长为2 689.76 s,如何在保证分类准确率的前提下减少训练时间将是我们接下来的研究工作。
