一种高效的基于聚合索引的可搜索加密方案
2020-12-25王瑾璠齐竹云吕幸谕杨镕玮
刘 政,王瑾璠,齐竹云,吕幸谕,4,杨镕玮
(1.鹏城实验室,广东 深圳 518055; 2.深圳大学,广东 深圳 518061; 3.南方科技大学,广东 深圳 518055; 4.广州大学,广东 广州 510006)
0 引 言
伴随着互联网应用的快速发展,用户在网络环境中所产生的数据迅猛增长,云存储[1]逐渐成为了一种常用的数据存储方式。云存储技术给用户带来极大的便利,而云上数据的安全却持续面临着威胁[2]。当用户的数据以明文形式存储在云上时,云存储提供商或黑客将很容易查看用户数据,用户的数据安全和隐私将无法保障。因此,云存储场景下的数据安全和隐私保护成为近年来的热点话题。作为一种可行的技术路线,云存储的可搜索加密技术[3-4]是指在不解密状态下,对云上的加密数据进行基于关键词检索的方法。可搜索加密技术的引入,使得用户可以更好地保护数据安全及隐私,同时云存储服务商依然可以提供相关云计算服务。
不同于以往的“先解密,后检索”的密文查询方式,面向云存储的可搜索加密的检索过程是将搜索关键词加密后发送至云端,在云端完成搜索过程后,将包含加密关键词的文件返回到客户端。在整个加密搜索过程中,用户的数据全程处于加密状态,用户的检索关键字也被加密保护,因此用户的数据安全和隐私得到了保障。
1 相关工作
可搜索加密技术最早是由Song等人[5]在2000年提出,最初的可搜索加密方案不仅无法证明其安全性而且检索性能与数据库内数据规模线性相关。后续经过众多学者的深入研究,使得可搜索加密模型不断发展和完善。2003年,Goh等人[6]提出了利用布隆过滤器对每一个文件做一个索引,之后通过多重哈希函数将单个文件中的关键词映射到较短的比特数组。相比较之前的方案,这种方法查询速度快,但是却引入了查询时误判率。并且当文件更新数据内容时索引更新代价较大,因此主要适用于静态文件可搜索加密方案上。之后,Chang等[7]又提出了“数据字典”的设计以满足对文件内关键词的精确查找。2006年,Curtmola等[8]基于对数据大量检索后的状态分析提出了著名的反向索引(Inverted Index)结构。前期的可搜索加密研究工作主要聚焦于静态文件的可搜索加密,但是实际的应用环境中对于文件的修改、增加和删除等操作都是十分常见。因此,2012年Kamara[9]提出了动态可搜索加密方案,该方案支持关键词与文件的在线增加或删除。考虑到动态可搜索加密方案的性能,Kamara等[10]又在原有工作的基础上采用了红黑树数据结构优化查询速度。之后,2014年Hahn等[11]提出了新的可搜索加密方案,这种方案初始化时只构建基础的数据字典,后续伴随着更新和查询不断地更新可搜索密文结构。同时,Emil[12]和Cash[13]等都提出了各自的动态可搜索加密方案。
在其他方面,Damiani等[14-15]将可搜索加密技术应用与数据库上,Li等[16-18]针对模糊语句的可搜索加密查询做了进一步的研究。Nepolean等[19-20]又在可搜索加密方案上实现了多关键词排列查询和多维范围查询。Fu等[21-22]又提出了一种有效解决同义词查询的多关键词排序搜索问题。Xia等[23]针对文件动态增删做出改进,提出了一个可以动态进行文件增删的多关键词查询检索方案。
在上述研究的基础上,该文提出了一种基于聚合索引的云存储可搜索加密方案。该方案具有以下特点:
(1)动态性:支持文件的在线添加或者删除;
(2)高效性:即使在方案初始化阶段或者搜索最坏的情况下仍能保持着较好的查询效率;
(3)安全性:该方案在更新时仅透露一个查找集合。
引入了聚合索引提升关键词的查询效率,通过使用聚合索引可以将单个文件的多个关键词通过聚合函数累加在一起形成聚合索引值,后续按照文件-聚合索引值存储形成一个新的索引表。新的索引表可以在查找过程中快速地定位到查询关键词所在的文件位置,大量减少关键词的比对次数,提升查询效率。在云存储实际业务场景的运用中,该方案具有明显优势。
2 基本方案
可搜索加密技术按照不同的使用场景可能有多种定义和模型,该文的主要研究内容是基于对称可搜索加密模型进行的。一个常见的对称可搜索加密模型定义如下:
2.1 系统模型
在传统的对称可搜索加密方案中,参与者可抽象为数据拥有者、用户和云存储提供商,操作流程如下:
(1)数据加密上传阶段:数据拥有者在本地使用对称加密方式对明文数据进行加密,将加密后的数据上传至云端服务器。
(2)生成检索陷门阶段:用户使用密钥和关键字生成对应的检索陷门,并将该陷门发送给云端服务器。
(3)密文检索阶段:基于收到的关键字检索陷门,云端服务器在密文数据库上对密文进行检索,并将满足检索条件的密文发送给用户。
(4)密文解密阶段:用户从云端获得返回的密文后,使用密钥解密密文。
可搜索加密技术可以分为对称可搜索加密方案和非对称可搜索加密方案,对称可搜索加密方案[1]具有计算量小、算法简单、计算速度快等优点。相对而言,基于公钥密码体制的非对称可搜索加密方案[24-25]则无需事先建立安全信道即可实现用户在公共网络中的保密通信和安全检索,但加密性能较低。考虑到云存储可搜索加密的实际应用情况,文中的研究工作主要围绕对称可搜索加密方案展开。
2.2 符号与定义
方案定义:一个安全的基于索引的动态可搜索加密方案包含的算法具体如下:SUISE=(Gen,Enc,SearchToken,Search,AddToken,Add,Delete,Dec)
(K,γ,σ)←Gen(1λ):一个概率算法,输入安全参数λ,输出密钥K,搜索索引γ和空的搜索历史σ。
c←Enc(K,f):一个概率算法,输入密钥K和文件集合f,输出加密后的文件集合c。
(σ',τw)←SearchToken(K,w,σ):一个概率算法,输入密钥K,关键词w和搜索历史σ,输出更新后的搜索历史σ'和搜索凭证τw。
(Iw,γ')←Search(τw,γ):一个确定算法,输入搜索凭证τw,文件密文集合C和搜索索引γ,输出文件标志符集合Iw和更新后的搜索索引γ'。
τa←AddToken(K,f,σ):一个概率算法,输入密钥K,文件f和搜索历史σ,输出添加凭证τa。
(C',γ')←Add(τa,c,C,γ):一个确定算法,输入一个添加凭证τa,一个加密文件c,加密文件集合C和搜索索引γ,输出更新后的密文集合C'和更新后的搜索索引γ'。
(C',γ')←Delete(ID(f),C,γ):一个确定算法,输入一个文件标志符ID(f),加密文件集合C和搜索索引γ,输出更新后的密文集合C'和更新后的搜索索引γ'。
f←Dec(K,c):一个确定算法,输入密钥K和一个文件密文c,输出解密后的文件f。
3 基于聚合索引的可搜索加密方案
在本章节,将从采用的数据结构、索引信息和具体算法三个部分详细阐述基于聚合索引的可搜索加密方案。
3.1 使用数据结构
在本方案中,构建索引表的过程中采用的数据结构有链表和哈希表。对于链表L,使用len(L)来表示列表的实际存储的元素个数,x∈L表示列表中包含x元素,位置在i的元素表示为L(i)。对于哈希表Map,其存储结构是k-v形式的键值对,而存储在Map键值为k的元素表示为Map[k]=v,v可能是一个元素,也有可能是一个链表。
3.2 索引信息
新方案采用了三个索引表来支持服务端的查询功能,三个索引表分别是数据字典、反向索引和聚合索引表。
数据字典γf用于记录每个文件存储的具体的关键词信息或者关键词加密后的信息。设初始情况下文件集合为f=(f1,f2,…,flen(f)),设fi的关键词为fi=(wi1,wi2,…,wilen(fi)),对应的关键词密文集合为ci=(ci1,ci2,…,cilen(ci)),文件标识符为ID(fi)。以文件标识符的关键词作为哈希的键值,将文件内关键词密文集合经过哈希运算后以链表形式存储在数据字典中。
反向索引表γw用于记录重复搜索关键词所对应的文件集合,对于每一个已经搜索过的关键词,可以通过查询γw提升对重复关键词的查找效率。
最后,在本方案中引入了新的聚合索引表γc来优化查询性能,具体过程为在数据字典的基础上对于每一个文件所有的密文关键词利用质数哈希函数生成唯一的大质数,并且将单个文件中生成的所有质数累乘后以文件ID为键保存在哈希链表γc中。在后续检索过程中,通过使用质数哈希函数将关键词哈希成质数,再通过聚合索引表γc快速判断关键词是否在文件中。
证明:假设质数w不在集合A中并且MAmodw=0,则w必定是MA的一个因数,而w又是一个质数,因此w必定是MA的一个质因数。假设中质数w不在集合A中,与假设矛盾,因此w一定不在集合A中。
聚合索引原理:
(2)对于新的查询关键词w,其搜索陷门为τw。令Pw=H'(τw),Pw为经过质数哈希函数后生成的质数;
(3)如果Pw属于聚合索引值中的一部分,即Pw∈(p1,p2,…,pn),则AcmodPw=0,否则AcmodPw>0。
3.3 具体算法
假设有抗不可区分选择明文攻击的对称加密方案SKE={Gen,Enc,Dec},一个输入长度为λ,输出长度任意的伪随机数生成器G,一个伪随机函数F:{0,1}λ×{0,1}*→{0,1}λ,一个随机数生成器H:{0,1}λ×{0,1}*→{0,1}λ,一个质数哈希函数H′: {0,1}λ×{0,1}*→{0,1}λ。
文中构建的方案SUISE=(Gen,Enc,SearchToken,Search,AddToken,Add,Delete,Dec)描述如下:
(1)(K,γ,σ)←Gen(1λ)。
初始化三个哈希表γf,γw,γc。生成两个λ比特长的二进制串k1←Gen(1λ),k2←{0,1}λ,初始化一个集合σ,返回(K,γ,σ),其中K=(k1,k2),γ=(γf,γw,γc)。
(2)c←Enc(K,f)。
对输入的文件f,输出c=SKE.Enck1(f)。
(3)(τw,σ')←SearchToken(K,w,σ)。
K=(k1,k2),对于输入的关键词w,计算w的搜索凭证,将τw=Fk1(w)添加到σ中,最后返回τw和更新后的σ'。
(4)(Iw,γ')←Search(τw,γ)。
根据采用的三个索引γ=(γw,γf,γc),然后判断γw中是否含有键值τw。
(a)如果有Iw=γw[τw],γ'=γ。
(b)否则令ac=H'(τw),γc中逐条记录即γc[ID(fi)]对ac取余,判断结果是否为0。如果取余结果为0,则对于密文集合c'=γf[ID(fi)],其中对于每一个密文关键词ci∈c',ci=li‖ri验证Hτw(ri)是否和li相同,相同则将ID(fi)加入到Iw中。
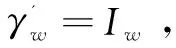
(5)αf←AddToken(K,f,σ)。
对于给定的K=(k1,k2),f是一个包含了文件中唯一关键词的集合,即f⊆f',f'=(w1,w2,…,wlen(f))。使用伪随机函数G生成一系列伪随机值s1,s2,…,slen(f),同时生成一个空的列表x和一个初始化为1的数字index,对于每一个wi∈f'进行如下操作:
(a)计算wi对应的搜索陷门,即τwi=Fk1(wi);
(b)如果τwi在之前检索历史集合σ中,则将τwi加入到x中;
(c)令ci=Hτwi(si)‖si;
(d)index=index*H'(τw)。
最后添加γc[ID(f)]=index,对集合c'=(c1,c2,…,clen(f))按照字典序排序,然后返回αf=(ID(f),c',X)。
(6)(C',γ')←Add(τa,c,C,γ)。
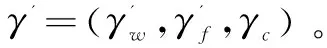
(7)(C',γ')←Delete(ID(f),C,γ):
给定γ=(γw,γf,γc)
(a)对于存储在γw的每一条链表记录e,如果ID(f)∈e,则从e中移除ID(f)对应的记录节点;
(b)之后再从密文数据库中移除密文c,密文数据库更新为C';
(c)移除γf中键为ID(f)的链表并删除键值;
(d)移除γc中键为ID(f)的记录。
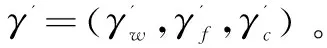
(8)f←Dec(K,c)。
对于给定的K=(k1,k2),数据输出解密后的文件f=SKE.Deck2(c)。
4 安全性能分析
在本方案中,希望尽量降低在查询、更新和删除操作中泄露原有数据信息给服务端的可能性。因此,详细地评估新方案中这些操作过程的安全性。
做出如下定义:假设有文件集合F,基于该文件集合的查询历史可以定义为一个二元组(F,phrase),F代表查询文件集合,phrase代表历史查询集合。
(1)索引表的隐私性。
为了提供高效率的查询性能,采用了多个基于哈希链表的数据结构存储相关索引信息。索引表存储的信息都进行了加密处理,这样可以避免明文的索引泄露F及phrase的特征信息(包括文件的内容或用户隐私)。因此,云服务提供者或者对手在没有获取密钥的情况下是无法得到索引存储内容的原有信息。
证明:假设这里有一个非统一对手A=(A1,A2)。k∈N,k是一个安全参数。根据k生成密钥K,K=KeyGen(1k)。之后,A1根据密钥参数作为输入生成(stA,H0,H1),stA是一个根据A状态生成的字符串。下一步,选择β←{0,1},令Hβ=(Fβ,phraseβ),生成方案中的索引表集合Iβ和密文结构Cβ。对于2≤i≤q,通过搜索陷门生成函数生成Tβ,i并作为查询凭证。同样的,令β'←A2(stA,Iβ,Cβ,Tβ)。
通过保证Pr[β'=β]≤1/2+negl(k),而negl(k)可以忽略不计,可以确保新方案是语义安全的。同时新方案能够很好地保证文件关键词及索引信息不会泄露给服务端,从而保护了数据安全及用户的隐私。
(2)搜索陷门生成的安全性。
在新方案的查询过程中,为了确保原有查询关键词不会被用户泄露,使用了伪随机的加密和哈希算法对原有查询关键词进行混淆。因此,服务端无法通过基于关键词生成的搜索陷门猜解原有查询关键词的内容信息。
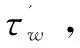
(3)云端存储文件的安全性。
在本方案中,用户存储在云上的数据全程均处于加密状态。文件拥有者或者得到文件拥有者授权的用户通过密钥对加密存储的文件进行解密而获得明文,但密钥的生成、分发和加密、解密过程,均不是在云上完成的。因此,云服务提供商并不掌握用户对文件进行加密的密钥,无法解密用户文件。由此可以得出结论,在本方案中,用户的文件在云端存储的过程中是安全的。
5 性能分析
5.1 空间复杂度分析
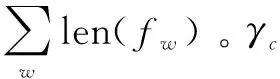
5.2 时间复杂度分析
假设m为γf中存储的所有关键词的总量,m'为γf中存储的唯一关键词总量。在本方案中,在经过一段时间运行后所有关键词都被检索过,此时时间复杂度经过均摊后为O(m/m')。
考虑到数据库所有关键词都是独一无二的情况下,新的方案相比较之前反向索引的方案,在整体方案初始化运行情况下使单个关键词的查询时间复杂度从O(n*len(fi))降到O(n+len(fi)),其中len(fi)代表了单个文件平均关键词的个数。
5.3 查询时间测试
测试数据集包括50个英文文档,从100个文档中剔除英文标点符号后用空格将单词隔开。其中每个文件只选出前100到900个不同关键词作为文件内容。每次实验中对于所有文件中每个文件选出的所有关键词逐个进行检索以确保整体方案性能的稳定性。
实验环境在Intel Core i7-8565U CPU 1,99 GHz,16 GB内存,windows10 professional系统环境下进行, 开发环境为java JDK1.8,开发工具为Eclipse(版本为2019-06(4.12.0))。实验过程中选取了基础的数据字典、反向索引和提出的聚合索引方案进行单个关键词查询时间对比,结果如表1所示。
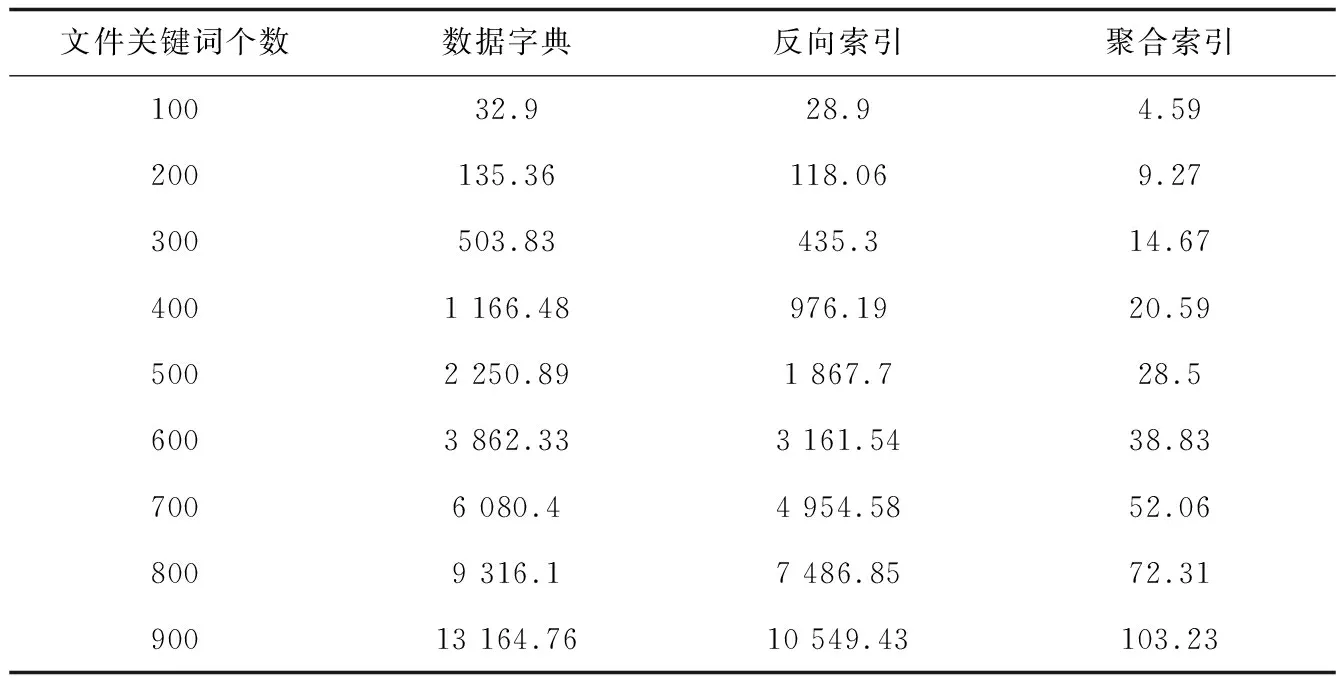
表1 不同方案在不同文件关键词个数下的查询时间 s

图1 不同方案的查询时间和文件关键词个数的关系
图1是根据单次查询所消耗时间进行绘制的折线图,横轴为给定不同的关键词数量,纵轴为单次查询所消耗的时间经过以10为底对数运算后的结果,不同标注的线代表了不同的方案。
6 结束语
针对云存储场景中的数据安全和隐私保护问题,提出了一种高效的基于聚合索引的加密搜索方案。在该方案中,查询过程中的关键词比对次数大幅度减少,查询性能得到优化。对该方案进行了理论分析和实现,实验结果表明,该方案相较于现有方案展示出了更佳的查询性能,同时提供了良好的动态更新能力和安全性能。
