以用户为中心的流数据处理应用构造方法
2020-12-25贾淑娟
贾淑娟,王 菁
(1.北方工业大学 数据工程研究院,北京 100043;2.大规模流数据集成与分析技术北京市重点实验室,北京 100043)
0 引 言
近年来,随着物联网的快速发展,在金融、电信、医疗诊治、城市应急和故障分析等领域中,由于面对持续到达的数据流,业务和用户需求随之不断的变化,使得人们逐渐意识到许多业务流程难以预先定义完备,应用的构造已从过去的由IT专业人员事先编制转变为以业务用户为中心的模式。以最终用户为中心的应用构造模式可以直接反映用户的业务需求,易于用户临机地构建业务流程。
在处理具有持续、时效性的物联网流数据时,传统的服务组合流程构造方法以控制流为中心,往往需要业务用户在构造流程过程中对其细节进行精确的定义,使得对业务用户的专业水平要求较高,使不具备专业IT知识和经验的用户难以完成构建。在面对海量、持续的物联网数据时,用户更加追求更简便快速的方式、显式地表达构建目标,从而利用已构造的应用分析并解决实际应用环境中的问题,这也是当前研究工作所面临的挑战。
针对上述需求,该文提出了一种可直接对数据视图进行操作的流程构造方法,使不具备专业IT知识编程的最终用户能够利用既有的资源即时完成对物联网实时流数据的流程构造。该方法对最终用户“屏蔽”服务组合流程构造的细节,易于用户理解和操作实时数据,降低了最终用户构造流程的复杂程度,提高了建模过程中的效率与准确性。
1 相关工作
随着物联网的快速发展,越来越多的对时序传感数据的分析被应用到求解实际问题中,国内外学者已就此问题进行了相关的研究。目前为止,已经有许多理论和方法应用于流处理的研究[1-4]。本小节通过对相关工作的比较,定性地分析文中方法的贡献。
近年来,国内外出现了一些基于流数据服务组合模型的面向最终用户的编程方法,目的是使不具备专业知识的人员也能操作流数据所形成的数据视图,进一步分析并处理物联网环境下的流数据应用[5-7]。最终用户编程(end-user programming)是指为非专业软件开发人员的用户提供一套技术以让他们能够在一定程度上创建或修改软件产品[8]。以业务数据编程元素构建服务和业务流程,可以使最终用户更方便快捷地操作业务数据,从而构建业务流程。Wong等人[9]提出了面向最终用户编程的Marmite,该工作采用数据流为主、表格为辅的思想,这种方式允许用户编程时以直观的方式查看数据,需要将数据的状态显示地建模,建模过程中的数据描述和操作方式,要求用户关联输入输出且具有一定的IT知识,用户无法对表格直接进行操作。丁维龙[10]提出一种用户为中心、基于多视图合成的服务组合方法,通过体征数据模型显式建模业务数据,将服务组合的需求转化为在多个视图编程操作,并给出一种候选流程的构法,参照用户的视图操作合成服务组合流程。胡海涛[11]提出了一种适合业务用户使用的大粒度服务组合方法,该方法以一种大粒度、可重用的方式组合业务服务,提高服务组合的自动化程度和抽象层次。张婷[12]提出一种基于本体的服务组合方法,依据用户需求动态地组合原子服务,对物联网服务进行多视图建模。针对现实中存在的业务需求在问题求解过程中动态变化、逐渐明确的情况,张峰[13]提出了一种以用户为中心的即时服务组合方法,帮助用户快速找到所需服务。Sun[14]提出了一个基于可视化的REST服务组合框架,该框架使服务组合更方便,并提供高效可靠的服务。Oscar[15]开发了一种基于代理的服务组合模型,它允许系统通过有选择地过滤掉连续的数据流来补偿有限的资源。
尽管目前主流的研究方案在一定程度上解决了最终用户构建流程的困难,但对于普通用户来说仍存在不易操作性的问题,仍未解决物联网环境下对流数据处理的问题。
2 基本思想
2.1 整体设计
系统架构如图1所示,系统分为五个模块,分别是数据模块、通讯服务器模块、服务库模块、运行支撑环境模块和探索式服务组合环境模块,其中运行支撑环境主要由流数据应用引擎和应用管理两个组件构成,探索式服务组合环境中包含数据视图、流程视图、数据视图更新引擎和视图转换规则库。底层的传感器获取大量的流数据,通过通讯服务器转换为可供用户使用的数据服务,在服务组合环境中,将用户所需的流数据服务转化为数据视图,并且在运行环境的支撑下,用户可直接在数据视图上对其进行有目标的操作,根据用户的操作,系统会自动筛选调用视图转换规则库中的转换规则,并将其转换为对应流程结构上的服务节点,用户可根据探索式即“边构造边执行”的方式构造服务组合流程,在构造与执行流程结构的过程中,用户可对流数据进行分析与处理。
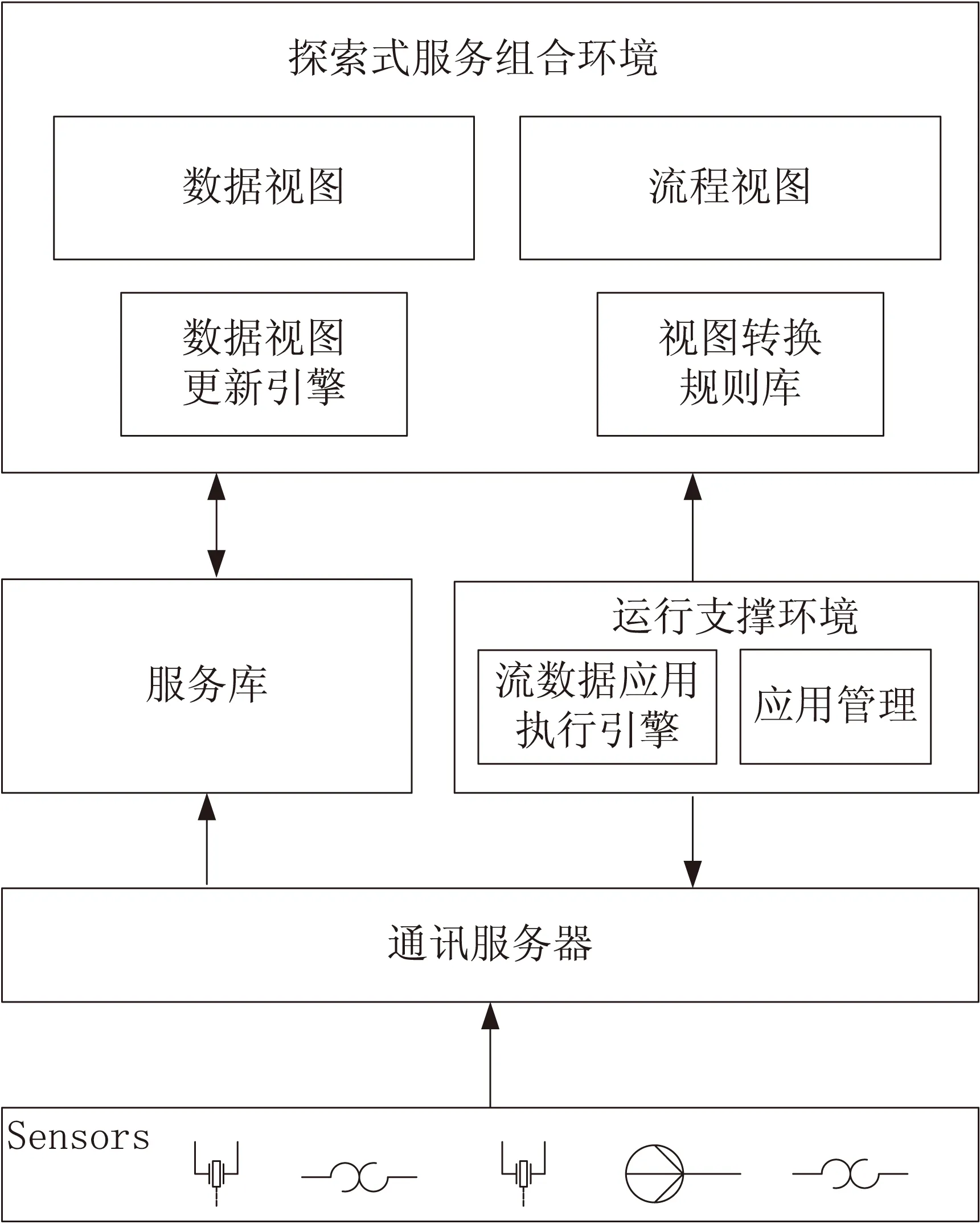
图1 系统架构设计
2.2 服务组合模型
业务流程的建模旨在为用户提供更加方便简单的操作方式,所以为用户提供不同的应用视图是非常重要的,文中提出数据视图与流程视图的服务组合模型。控制流相关的视图在分析解决实际问题中起着至关重要的作用,但用户在构造流程过程中,业务过程无法事先确定,业务细节也无法精确定义,所以在实际应用的背景下,用户直接操作数据视图更加方便也易于实现,流程视图能够帮助用户更好地了解整个活动的逻辑顺序且方便的进行即时调整。本节提供了如图2所示的服务组合模型的两个视图:构建和执行流程的流程视图、便于用户操作和控制的数据视图。
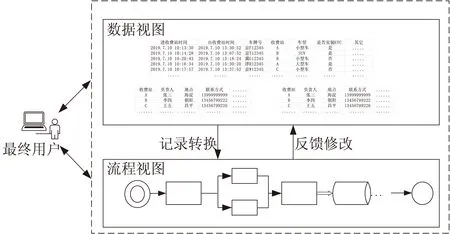
图2 服务组合模型
“示例编程”是一种常用的最终用户编程技术,通过用户在某实例数据之上的操作来记录可重用的用户操作序列,从而为用户生成可执行的程序。借鉴该思想,该文在构造流程结构时,允许用户在一个数据视图的基础上进行数据的处理操作,流程结构可将这些操作参数化后记录下来,生成一段组合脚本,可用来表示数据服务的组合逻辑。这一过程有助于流程重用,以后无需用户重复构建含有这些参数的服务组合流程,执行引擎会将用户的组合逻辑应用到新的流程结构之上。
2.3 数据视图形成的基本思想
2.3.1 流数据
流数据是一组顺序、大量、持续到达的数据序列,它是无边界的、瞬时的时序数据,具体而言,流数据是指带有时间戳、按到达时间有序排列的数据。源自同一场景的流数据具有相同的属性和模式,它可以用时间序列模型来表示,该模型概述为:令t表示任一时间戳,at表示在该时间戳到达的数据,流数据可以表示成{…,at-1,at,at+1,…}。
一个流数据的处理任务可以看作是由执行数据操作的“处理单元”集合之间通过数据“流”连接而成的有向非循环图,而数据视图的生成过程可以用扩展的非循环图(DAG)表示,扩展的DAG是一棵倒置树,称为操作树,它用来表示数据视图生成的计算过程。树中包含了许多节点,每个节点都包含有子节点(除叶子节点外)和父节点(除根节点外),其中叶子节点表示流数据,而非叶子节点表示对子节点执行数据操作的基本数据表,而根节点则为最终的数据视图,数据视图的生成过程是从叶节点的流数据开始,从下而上一层层地进行处理操作,一直到根节点的最后一次处理,最终得到数据视图。数据视图是查看流数据的一种方式,可以将它看成是一个移动的“窗口”,用户可以选择目标数据,从而对其进行操作,由于流数据是无边界且持续的时序数据,“窗口”被用来对执行的流数据进行输入的限制。
2.3.2 数据视图的实现方法
图3表示一棵基于扩展的DAG的操作树,这棵树表示数据视图DV的生成过程,处理单元在获取输入的流数据S0,S1,…,Sn后触发相关的操作,该操作包括数据转换、处理及产生输出,处理单元负责接收来自流数据源的数据,形成基本数据表,最终生成数据视图。
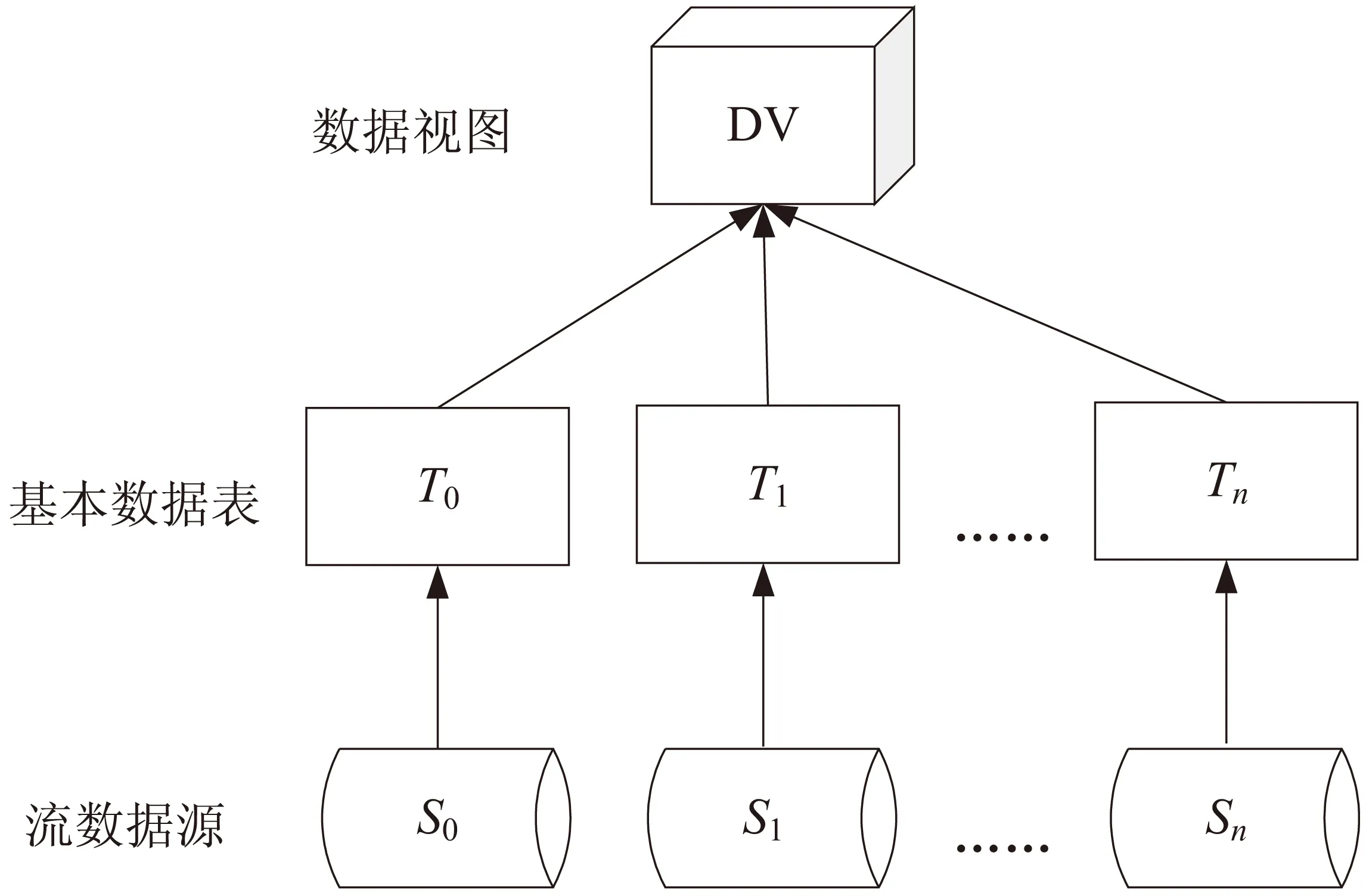
图3 数据视图的生成过程
由于流数据是一组顺序、大量、持续到达的数据序列,它是无边界的、瞬时的时序数据,即流数据是不断变化、不断更新的,为了确保数据视图数据与源数据的实时性与一致性,在每一个处理单元中执行一些数据操作,包括数据转换、处理及产生输出数据,这些操作可用流数据处理规则表达。流数据处理规则主要体现在转换规则,转换规则定义了一个由基本处理单元的运算操作构成的执行计划,这些运算符描述了处理单元所执行的包括过滤、连接、聚集等在内的数据操作,执行计划由用户自定义或由系统自动进行。
这棵倒置树表示数据视图DV的计算过程,数据视图是在基本数据表之上建立的表,它的结构和内容都来自基本数据表,它依据基本表存在而存在。一个数据视图可以对应一个基本表,也可以对应多个基本表,它是数据表的抽象和逻辑意义上建立的新关系,流数据源S0,S1,…,Sn对应基本数据表T1、T2,对收集的数据表经过合并、聚集等处理运算得到数据视图DV。
当然,图3只是列举了简单数据视图的形成过程,在物联网环境中,对于源源不断的实时流数据会经过更多的步骤,形成更加复杂的数据视图,但形成的方法与其类似,推而广之,该文不再进行赘述。
2.4 数据视图的构建操作
在数据视图中,将流数据进行服务化封装后,用户对其进行集成应用的过程就是对这些数据服务进行组合的过程。根据示例编程的思想,用户导入(import)已经封装好的数据服务并配置其参数,用户在构建流程过程中调用数据服务,其返回的实例化数据以表格的形式呈现给用户,用户在这些样例表格上进行数据的操作和处理,进一步映射为目标流程结构。
用户对数据视图的操作主要包含对数据表的操作和数据表中的列操作,具体的操作定义及文字说明如表1和表2所示。

表1 用户对数据表的列操作

表2 用户对数据视图中数据表的列操作
2.5 流程视图
流程视图用于记录用户构造服务所执行的操作顺序和数据依赖关系,它可以表示为节点和边表示的有向图:G(V,E),其中V是数据流程图记录的一组服务节点集合,它支持顺序、循环、分支等流程结构,以及提供回退、断点调试等功能,方便用户更改数据操作。将节点分为三类:开始与结束节点、数据节点、基本活动节点。
开始与结束节点:由数据结构的知识可知,有向图是一种非线性的数据结构,它不是一对一的结构关系,而是多对多的关系,可能有多个出入节点,这种逻辑结构不易理解与研究,所以人为地引入一对具有开始和结束标志的节点。开始状态节点start标志用户构造流程的开始,是流程结构的唯一入口点,它的特点是无直接前驱节点。流程的结束状态节点end为流程执行结束的标志,是流程结构的唯一出口点,它的特点是无直接后继节点。
数据节点:对于数据节点而言,其输入节点是start,本身为结束节点,流程可从中获取节点的属性信息,从而获取数据的结果。
基本活动节点:每个基本活动节点都有输入和输出端口,表达了流程结构的逻辑关系,相对于其他节点而言,某一基本活动节点的输入端口是目标端口,而输出端口是源端口。基本活动节点可以由一个三元组的方式表示:opNode=
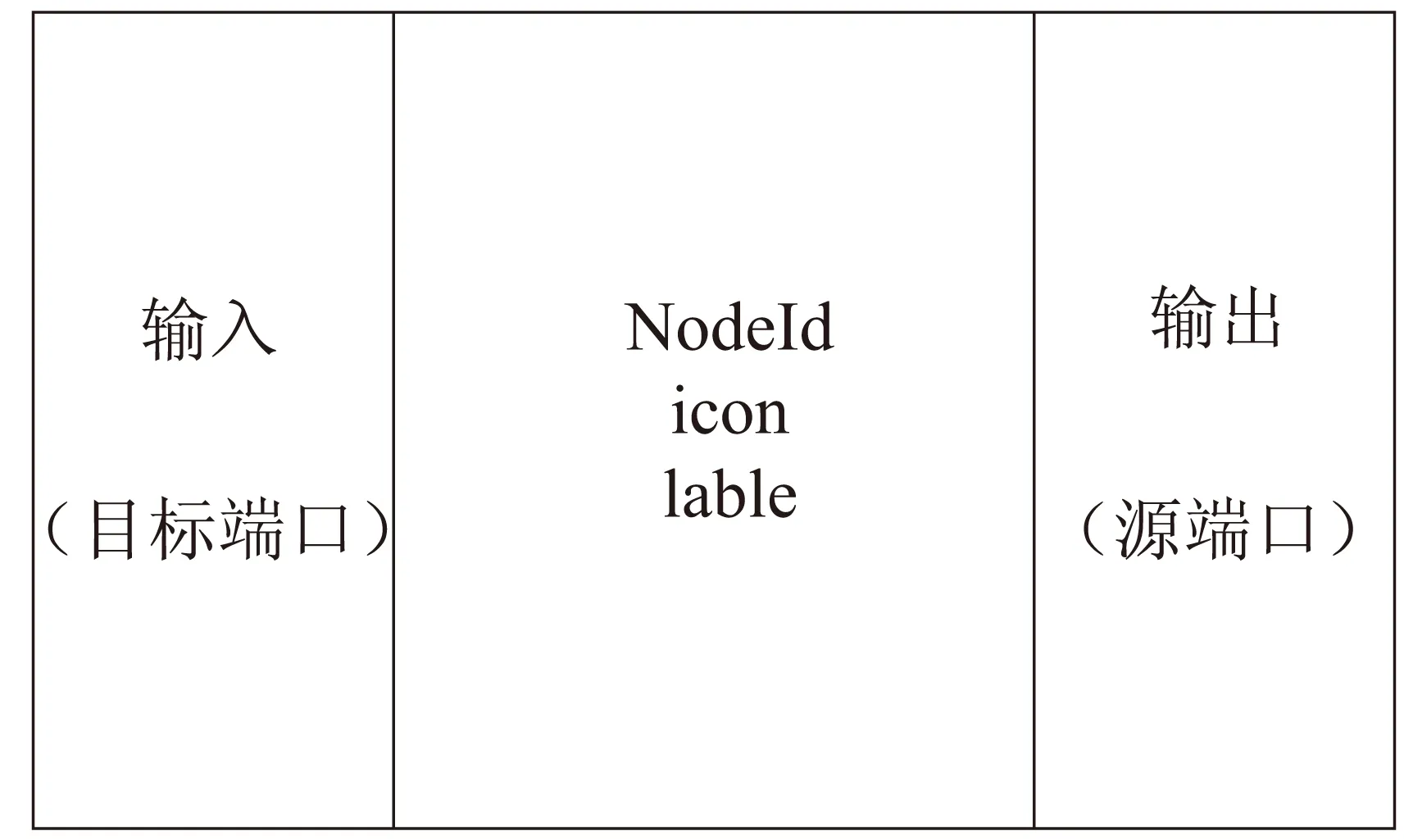
图4 基本活动节点示意描述
E是表示节点之间关联的一组边的集合,它由关联的两个点唯一确定,并且将它标识为四元组的形式:e=
2.6 数据视图转换规则
流程结构用于记录最终用户在数据视图上的操作,当用户执行操作时,参照并筛选声明数据相关的规则,系统自动地合成流程结构,并在流程视图中呈现,转换为流程视图上的服务,即每进行一次操作就会转换为流程片段上的一项具体服务。
将用户可操作的数据视图转换为流程视图,生成的流程结构不仅用于分析流数据,而且能够记录用户的操作轨迹。流程结构将服务进行组合,并将已构造好的服务组合存储在服务库中,以便用户再次构造服务时,可直接从服务库中获取。若结果未达到用户预期,用户可返回流程结构中的某一步骤进行调整和处理,而无需重新开始构造服务组合流程,实现流程片段的重用,可以节省资源空间和分析数据的时间。
作为一种特殊的服务组合,已构建好的流程结构被封装成可重用的组件,使得再次构建服务时直接将组件集成到应用中,以实现特定的应用途径。用户主导流程的构造、执行与结束,在这个过程中根据定义的转换规则构造数据流程,本节给出数据视图转换为流程视图的转换规则。具体操作对应的规则定义如表3所示。

表3 用户操作及其对应的转换规则
在流程执行过程中根据其反馈的信息及对应的转换规则信息进行决策,并将决策结果反馈给数据视图,这一过程在流程重用和服务推荐方面起到至关重要的作用,资源空间得以有效利用,减少重复不符信息的出现,为后续流程结构的高效构造做出贡献。
3 实 验
3.1 实验环境与数据
实验使用三台CentOS 7.6版本的 Linux操作系统搭建了Storm1.1.1 环境,Strom集群配置均为4核CPU、16 GB内存,并且由1个nimbus主节点、2个 supervisor 从节点构成。LoadRunner模拟收费站车道采集收费数据,自行研发的数据接入服务CCS (concurrent connection stream)充当Kafka和LoadRunner之间的通信服务器,用于接收LoadRunner发送的收费数据并传输给Kafka消息中间件。实验中采用的原始数据为某省所有收费站2019年7月1号到31号的真实收费数据,基础数据为某省高速公路站点数据,通过LoadRunner模拟成实时数据。
3.2 实验结果
用户在操作数据视图时产生流程视图,产生的这一流程形成storm集群上的流处理任务,从而不断更新数据视图模块,实现数据视图的动态更新,将LoadRunner并发数量设置为2 500条(相当于2 500个流数据源),发送频率设为1条/秒,用来模拟收费站车道采集收费数据数量为2 500条,频率为1条/秒,采集高速公路联网收费系统上报的实时数据。
在数据视图中,用户可根据自己的需求选定一个时间段对采集的收费站流数据进行数据分析,在流数据形成的数据视图S1中,选择数据视图的操作方法,对其直接进行操作。
在实验中,首先用户导入某省高速收费站数据,选择最近一周(非节假日)这一时间段的高速收费站的收费信息及车辆情况,在大量流数据形成的数据视图DV中,根据小型车和大型车这一条件在数据视图的属性列中进行筛选,分别得到两个不同车型信息的数据视图,可查看通过此收费站的所有小型车和大型车的车辆信息,包括其车牌信息,在筛选后的两个数据视图上分别进一步对本地车牌及外地车牌进行分组操作,查看通过此收费站点的小型车本省车辆信息、小型车外省车辆信息、大型车本省车辆信息及大型车外省车辆信息。用户可构建自己的满意的“个性化”数据视图,分析并统计本地及外地车辆的通行信息,根据这一分析预测未来一段时间(非节假日)的车辆通行情况,通过分析大量实时的流数据预测未来车辆通行情况。对数据视图的操作实例过程如图5所示。

图5 对数据视图的操作实例
在用户操作数据视图的过程中,根据转换规则自动记录用户的操作轨迹,生成对应的流程结构,用户导入收费站数据时,底层的流程结构自动生成源节点和import节点,并生成两条边,当用户选定一个实时更新的数据服务时,底层的流程结构自动生成select节点;用户根据两种不同的车型做过滤操作时,底层流程结构生成过滤后的数据视图节点filter1和filter2,对过滤后的两个视图再分别根据省份条件进行分组时,流程结构上新增group1节点和group2节点,产生两个分组,操作对应生成的流程结构如图6所示。用户可根据筛选分组后的结果选择最优解,并将两个含有过滤条件的流程结构保存在系统中,这一过程有助于流程重用,以后无需用户重复构建含有这些参数的服务组合流程。

图6 流程结构的生成
综上,用户对数据视图进行一系列操作的同时,被“屏蔽”的底层也已构建出这些操作所对应的流处理的流程结构,产生的结果可用于进一步的数据分析,及对某一时间段的车辆通行情况的预测。经过上述操作,用户间接完成了对服务组合流程的构造。
4 结束语
物联网环境下,针对用户直接构造以控制流为中心的服务组合流程方面的挑战,提出了一种可直接对数据视图进行操作的流程构造方法,为用户屏蔽了底层流程的构造细节,降低了用户构建应用的复杂程度。给出了流数据产生数据视图的具体过程及数据视图产生流程视图的转换规则,且定义出用户在数据视图上所做的操作,体现以最终用户为中心的基本思想。该方法为用户提供简单易用的编程方法,提高了建模效率与准确性,为最终用户编程方法的研究做出了进一步的贡献。
