轨迹特征融合双流模型的动态手势识别
2020-12-25陈姚节郭同欢
林 玲,陈姚节,3,徐 新,郭同欢
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430070;2.智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉 430070;3.冶金工业过程国家级虚拟仿真实验教学中心,湖北 武汉 430070)
0 引 言
手势识别作为一种重要的交互方式,由于更自然,直观和易于学习的特点,在虚拟仿真、手语识别等领域得到了大量应用。基于视觉的手势识别主要分为三个阶段:手势分割、特征提取和识别。
手势分割作为手势识别的基础,对后续手势识别工作有着至关重要的影响。传统手势分割利用肤色、轮廓从彩色图像视频中分割出手势,如Bao等[1]提出的利用肤色检测与背景差分的方法,Rahmat等[2]结合人手肤色与光照的实时手势分割,Dawod等[3]采用自由形式肤色模型进行的手势分割。以上方法进行的手势分割效果较好但易受光照、复杂背景的影响,影响后续的手势识别工作。
手势特征的提取是手势识别更为重要的阶段。Asaari等[4]根据提取的手形特征与纹理特征进行手势识别,由于复杂背景的影响准确率不高,刘富等[5]借助手形轮廓与几何特征提高了手势识别的鲁棒性,但要求手势手指分开,不具有普遍性。
现有的手势识别大多借助模式分类方法对手势进行识别,如Panwar[6]利用形状参数的位编码序列进行手势分类的方法、杨学文等[7]利用手势主方向和类Hausdorff距离模板匹配的手势识别方法等具有一定局限性,鲁棒性较低。近年来动作识别方法的迅速发展和许多大型数据集的引入,使得利用深度神经网络对动态手势进行有效识别成为可能。Molchanov等[8]引入了一种将归一化深度和图像梯度值结合起来的3D-CNN的动态手势识别方法。而后Molchanov等[9]又提出了一种3D-CNN,融合来自多个传感器的数据流进行识别。3D-CNN模型在视频处理问题上相比于2D-CNN更加有效,但是也会存在时间维度上的运动信息的丢失问题。
因此,该文利用Kinect深度信息修复后的深度图进行手势精确分割,并由此提取出动态手势的运动轨迹特征,构建一种通过自适应权值分配将动态手势的轨迹识别与手势时空信息识别结合的双流网络模型,利用该模型中的两种网络对动态手势的不同特征的识别优势提高动态手势识别率,并采用SKIG数据集测试模型识别性能。
1 动态手势特征提取
实验发现,当手部位置变化较大时就可以通过运动信息来识别,那么这些动态手势的识别就可以转换为对其空间运动轨迹的识别;而当手部位置变化较小时,其轨迹不能明显区分出各个动态手势,此时就需要利用动态手势的手形特征的变化进行动态手势的识别。因此在进行手势识别前,需要对动态手势进行手势分割和轨迹的提取。
1.1 深度图修复
由于Kinect传感器获取的深度图像中存在大量噪声以及深度信息缺失导致的空洞,而动态手势的识别又依赖于手掌在运动过程中的手部形态与精确位置。因此为避免在进行手势分割时,因深度图中的噪声、空洞引起的分割误差进而导致后续的识别误差,笔者首先做了文献[10]中的工作,对采集的深度图像进行初步修复。利用待修复像素点周围时空域的深度数据,对深度图中存在的噪声以及空洞点进行修复,保证后续分割工作中能得到完整的手部形态和精确的空间位置。
1.2 手势分割
手势分割的目的是将手部区域从复杂背景中分离出来。在基于计算机视觉的手势识别技术中,复杂背景下的手势分割非常困难。特别是在单目视觉情况下,这主要是由于背景各种各样,环境因素也不可预见。
修复后的深度图像中手部轮廓完整、没有明显的噪声干扰,因此可以利用深度图中手掌部分的灰度值与深度图中其他位置的灰度值的差异来提取手部感兴趣区域输入网络进行训练,提高动态手势识别准确性。正常情况下,当人位于Kinect设备的可视区域内做手势时,手掌部分与Kinect相距最近,灰度值与图像中其他部分也会有较大差异,如图1(a)所示。由此可以借助手势的深度图像,计算生成灰度直方图,如图1(b)所示。灰度图中横坐标表示灰度级,纵坐标表示各个灰度值的像素在图像中出现的次数。

图1 深度图像灰度直方图示例
通过观察灰度直方图分析发现,灰度直方图中第一个波峰对应灰度值即手掌部分对应灰度值。为准确把手掌区域和手臂、手腕部分区分开,将在第一个波峰灰度值左右波动3以内的像素点保留,其他像素点像素置为255。由此就得到了分割后的手势图,如图2所示。
1.3 轨迹提取
利用1.1节分割得到的手势图,计算图中手部质心坐标来代表手在图像坐标系下的坐标。计算采集的手部质心坐标序列中横坐标的最大值xmax、最小值xmin和纵坐标的最大值ymax、最小值ymin,给定一个标志flag和由实验得到的质心坐标波动阈值P=20:
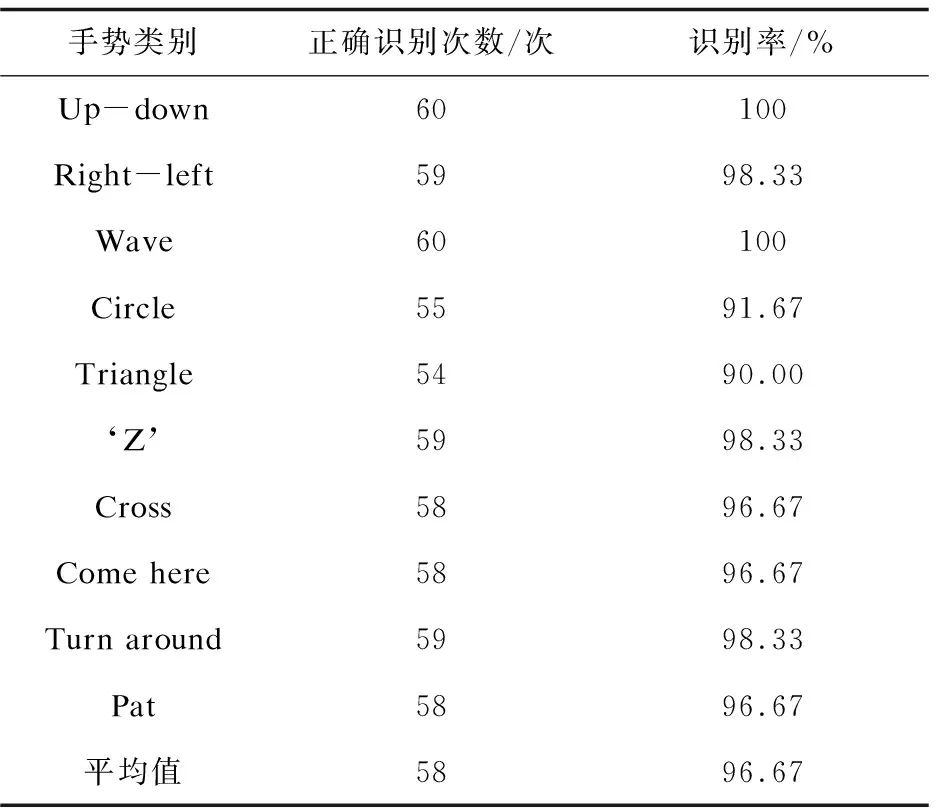
当xmax-xmin 图2 分割后的手势图 当xmax-xmin≥P或ymax-ymin≥P时,flag=true,可以用轨迹对动态手势进行识别。此时,为保证轨迹特征具有平移和比例不变性,将手势的运动轨迹,即质心坐标的变化轨迹,整体平移到图像中心位置,并生成动态手势轨迹图。具体过程如下: (1)计算手势轨迹所占区域的中心位置坐标(x0,y0)。计算公式如下: (1) (2)由于网络的输入设置为150×150大小的图片,故计算x0、y0与75的差值得到对应的轨迹坐标平移距离,即可将轨迹整体平移至图像中心位置。 (3)绘制轨迹序列散点图,拟合轨迹曲线,生成动态手势轨迹图。 采集8帧深度图像代表挥手手势一次来回摆动,经分割后的手势图如图3所示。 图3 代表挥手手势一次来回摆动的8帧手势图 由整个挥手手势的手势图序列中的手部质心坐标生成轨迹图的过程如图4所示。 图4 挥手手势轨迹图生成 CNN是一种前馈神经网络[11],基本结构包括特征提取层和特征映射层。在图像以及视频处理方面,CNN有明显的优势。相比于静态手势,动态手势还包含了时间维度上的运动信息,因此必须采用3D-CNN同时学习手势视频流中的空间特征与时间特征。而一个动态手势从开始到完成的持续时间大约为2~3秒,3D-CNN并不能将动态手势视频中的每一帧都输入网络进行学习,只能选取一定数量的图像帧代表该动态手势。因此,为防止选取不当导致关键帧信息丢失产生的分类错误,且鉴于CNN在提取静态空间结构的优势,该文采用3D-CNN对动态手势进行时空信息识别,并采用2D-ResNet融合手势轨迹信息识别,构建自适应权值分配的双流网络模型,实现动态手势的识别。网络模型结构如图5所示。 图5 融合轨迹识别的双流模型结构 多模态识别系统使用多个数据流进行训练,并在测试期间对多模态观测结果进行分类,单模态识别系统仅使用一个模态数据进行训练和测试[12]。该文采用了第三种类型,使用一个3D-CNN模型接收来自多种模态的数据并融合学习,即利用多模态数据提高单个网络的测试性能。在动态手势识别系统中可用的模式流通常是空间上和时间上对齐的。例如,运动采集设备采集的深度图像和RGB图像以及光流通常是对齐的,即使数据以不同的模态出现,但它们代表的语义内容是相同的。 该文引用文献[13]的3DCNN模型框架,构建双卷积池化网络。该网络利用两个连续的卷积层保留并传递每个动态手势的特征信息,但3D卷积层又是3D-CNN中高时空复杂性的主要来源,因此在3D卷积核上设置L2正则,以避免在神经网络深度有限的前提下,因卷积层密集提取产生过拟合情况。两次卷积操作后添加池化层操作,在保持特征不变性的条件下有效减少参数数量。在每层卷积之后,设置标准化层实现数据归一化操作。在3D卷积之后设计激活函数,激活函数产生非线性操作,进一步增加神经网络的复杂性。由此,利用Kinect同时获取彩色数据与深度数据生成图像,对齐裁剪后再对深度图进行手势分割,将分割后的手势图序列与彩色图序列都作为3D-CNN的输入数据对网络进行训练,保证网络获得更高识别精度的同时不会带来参数增加的影响。将待识别的手势序列输入训练好的该网络即可得到手势的时空信息识别结果。 由于CNN模型结构会对网络的特征表达能力产生影响,近年来,用于图像识别的深度网络如AlexNet、GoogLeNet[14]、VGGNet[15]、ResNet[16]等被相继提出。卷积核更小化、网络层更深化成为卷积网络结构的一大发展趋势,这种发展趋势使得图像的识别精度更高,模型的计算效率更快。在所有深度网络模型中,残差网络(ResNet)因独特的残差结构,极大地加速了神经网络的训练,模型的准确率有比较大的提升,推广性也非常好,从而得到了广泛的应用。它通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络只需要学习输入、输出差别的那一部分,简化学习目标和难度,一定程度上解决了信息损耗、丢失和梯度消失、梯度爆炸等问题。 引入跳跃连接将目标函数F(x)+x的拟合转变为残差函数F(x)的拟合,将输入与拟合残差叠加代表网络输出,增强了网络信息流通,降低了数据信息的冗余度。由此,通过训练经典的ResNet50网络对动态手势的轨迹图进行识别就得到了该手势轨迹识别的结果。 在经过上述工作后,已经得到了两种网络的最优识别结果,但由于ResNet网络只能对产生轨迹的动态手势识别分类,对没有轨迹变化只存在手形变化的动态手势无法识别;而3D-CNN虽然可能丢失动态手势时间上的运动信息,但对某些动态手势仍能通过其时空信息进行有效识别。因此这里不宜采用求平均后取概率最大手势的方法得到双流网络的最终识别结果,应根据每个手势样本的具体情况估计出网络识别结果的置信度,依据该置信度计算权值,因此该文提出一种自适应权值分配策略为其分配权值,再由经典的加权平均模型得到识别的最终结果R。计算公式如式2所示,其中w为给网络赋予的权值,f为各个网络的输出。 R=wsfs+wefe (2) 首先根据1.2中的flag值确定当前动态手势是否产生轨迹:(1)当flag=false时,无法通过轨迹直接将动态手势分类,设置ResNet网络权值为0,3D-CNN的识别结果即为双流网络的最终结果;(2)当flag=true时,即两种网络都能对动态手势进行有效识别,此时根据网络识别结果的置信度为其分配权值,方法如下。 一类动态手势可以用一组特征的组合来代表,每种特征又单独形成特征空间,而不同类别的手势又可能出现相同特征,因此形成了特征重叠的区域。当一个手势样本被网络识别后,识别结果中各个类别的概率相差不大时,认为该手势样本处于特征重叠区域;而当识别结果中概率相差较大、较为分散时,认为该手势样本属于非特征重叠区域。这样,就将样本空间分成了特征重叠区域和非特征重叠区域两部分。 (3) (4) 由高斯参数估计手势样本属于每种手势类别的后验概率pj(j=1,2,…,J),将它们组成向量P={pj|j=1,2,…,J},其中J为手势类别数。这样,就生成了由后验概率估计值组成的J维欧氏空间。对每一个特征向量P,都有一个欧氏空间中的点与其对应。当P越接近P1/J={(p1,p2,…,pJ)|pj=1/J,∀j}时,手势样本位于特征重叠区域的可能性越大,对应识别网络的权值越小;P越远离P1/J时,例如当某一pj接近于1,而其他概率接近0时,手势样本位于特征重叠区域的可能性越小,对应识别网络的权值越大。对各个网络识别结果都利用上述方法计算P与P1/J的欧氏距离dn,融合时就可以根据dn给网络分配不同的权值,而后加权融合即可得到双流网络的识别结果。权值计算公式如下: wn=dn(P,P1/J) (5) 由于加入了ResNet网络对动态手势轨迹进行识别,并且将分割后的手势深度图处理后与彩色图两种模态的数据同时训练3D卷积网络,因此该文采用Sheffield Kinect Gesture (SKIG) Dataset[17]RGB-D手势数据集中的10种动态手势类型,利用Kinect 2同步获得彩色数据与深度数据,重新制作数据集。数据采集由6人完成,每人每种手势执行10次,每种模态各600个动态手势视频,并按照8∶1∶1的比例将数据集随机划分为训练集、验证集、测试集。对除测试集外的深度视频,按照1.1的手势分割方法将手掌部分分割出来,然后平均选取8帧图像代表该动态手势。再按照1.2中所提方法从分割后的手势图序列中计算质心坐标得到轨迹序列并生成轨迹图。数据集样例如图6所示。 图6 数据集样例 为防止网络在训练过程中出现过拟合现象,有必要对数据集进行数据扩充。分别对ResNet网络和3D-CNN的输入数据进行扩充。对3D-CNN的输入数据采用以下两种数据扩充策略:(1)在同一个手势视频的完整帧序列中,选用不同的帧作为采集的第一帧,平均采集8帧图像代表该手势;(2)将代表一个手势的8帧图像进行相同方向相同角度的旋转。以上两种方法扩充后共2 160个手势。对ResNet网络的输入数据即动态手势轨迹图进行一定比例的放大与缩小,最终动态手势轨迹图包含1 080张。实验结果表明,利用数据扩充后的数据集对网络模型进行训练,增强了网络的泛化能力,提高了网络的识别率。 该文基于Keras深度学习开发框架,利用GPU并行加速对两个网络单独进行训练。数据集中80%作为训练集,剩余的20%作为验证集,并且将训练集随机打乱。在ResNet网络中,网络的输入为根据动态手势运动轨迹生成的大小为150×150×3的图像,调整大小至224×224×3。在3D-CNN中,将采集的代表一个手势的8帧150×150的图像序列作为输入数据,网络每次迭代分批次处理大小为32,并采用Adam方法对网络进行优化。训练周期设为128,每迭代5个批次就对测试集进行一次测试,待网络训练至最优时,将2个网络的识别结果,在决策级以加权融合的方式判定所属的动态手势类别。 实验计算机配置为Intel Core i5,内存32 GB RAM,环境配置Windows10+python3.6.8+Tensor-flow1.8.0+CUDA9.0,训练使用显卡NVIDIA GeForce GTX 980Ti,并采用Kinect 2.0设备采集手势数据。实验分为两部分: (1)用测试集中60组动态手势单独测试训练好的两个网络的识别效果。其中,ResNet网络对除Come here、Turn around、Pat以外的7种动态手势识别进行测试,结果如表1所示;3D-CNN对数据集中的10种动态手势识别结果如表2所示。 表1 ResNet网络识别结果 表2 3D-CNN识别结果 由表1可以看出,Resnet50因其强大的学习能力使得在文中自制的轨迹图像数据集上的平均识别率达到了97.38%。其中,当Right-left手势执行不规范时,轨迹与Wave手势有一定的相似性,正确率略微低于其他手势。同时,3D-CNN对数据集中10种动态手势的平均识别率也达到了96.67%。其中,Circle、Triangle两种手势因手型一致,在只提取8帧代表该动态手势的情况下存在误识别,故正确率低于其他手势。 (2)对由两种网络构成的双流网络模型进行测试,并将文中方法与近几年相关方法在SKIG数据集上的识别准确率与平均消耗时间进行对比,如表3所示。 表3 不同方法在SKIG上的准确率对比 由表3可以看出,文中方法不仅在SKIG数据集上的识别率达到99.52%,相比于现有识别率最高的方法提升了0.45%,也能较快地识别出动态手势。 为避免由于单个3D卷积网络特征提取不充分而导致的误分类,且鉴于CNN在提取静态空间结构的优势,引入ResNet网络从合成的轨迹图像中提取动态手势运动信息,与二模态训练的3D卷积网络构成一种更加复杂的双流网络结构来提高动态手势识别的准确性与鲁棒性。实验结果表明,与现有的在SKIG数据集上的方法相比,该方法的识别率更高、鲁棒性更强。虽然提出的双流网络提升了一定的识别率,但识别速度仍需要进一步提高。


2 融合轨迹识别的双流模型
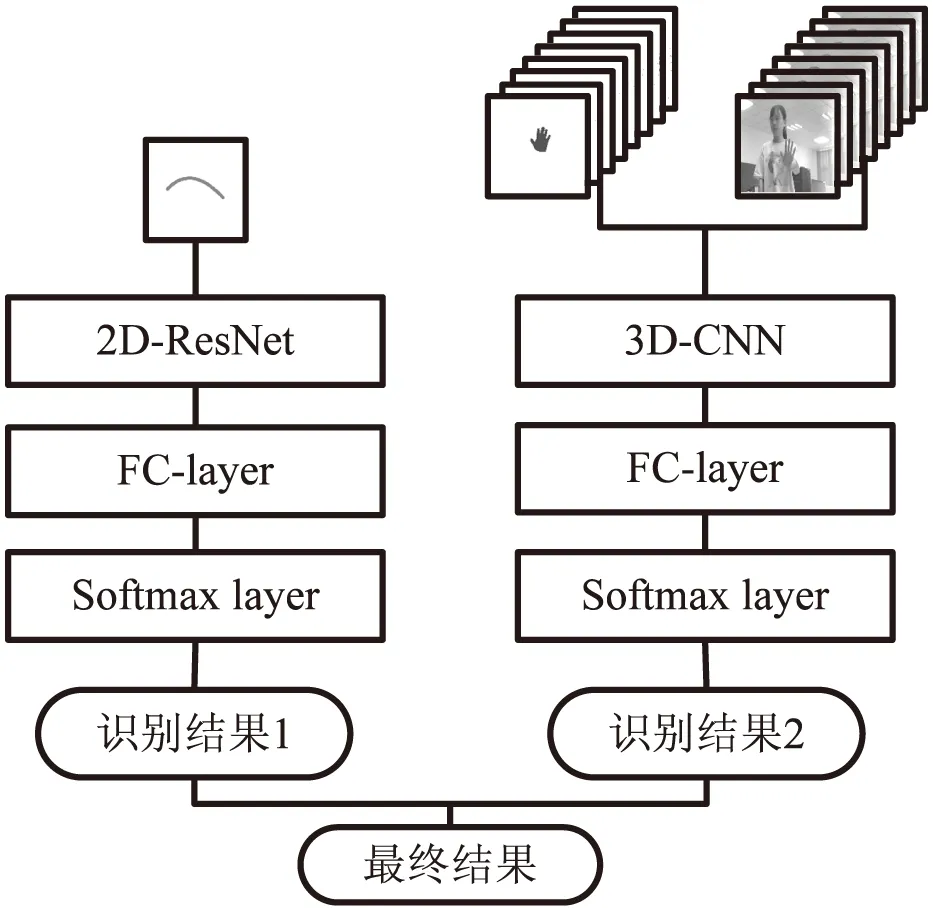
2.1 时空信息识别
2.2 轨迹识别
2.3 融合策略
3 双流网络的自适应权值分配
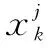
4 实验及结果分析
4.1 数据集
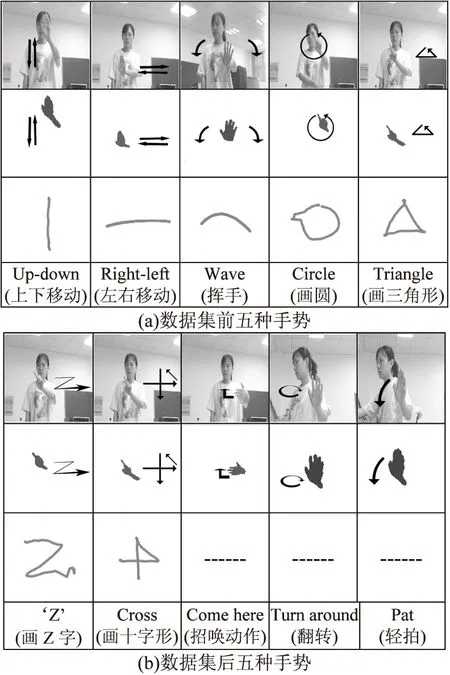
4.2 数据扩充与训练
4.3 实验结果分析
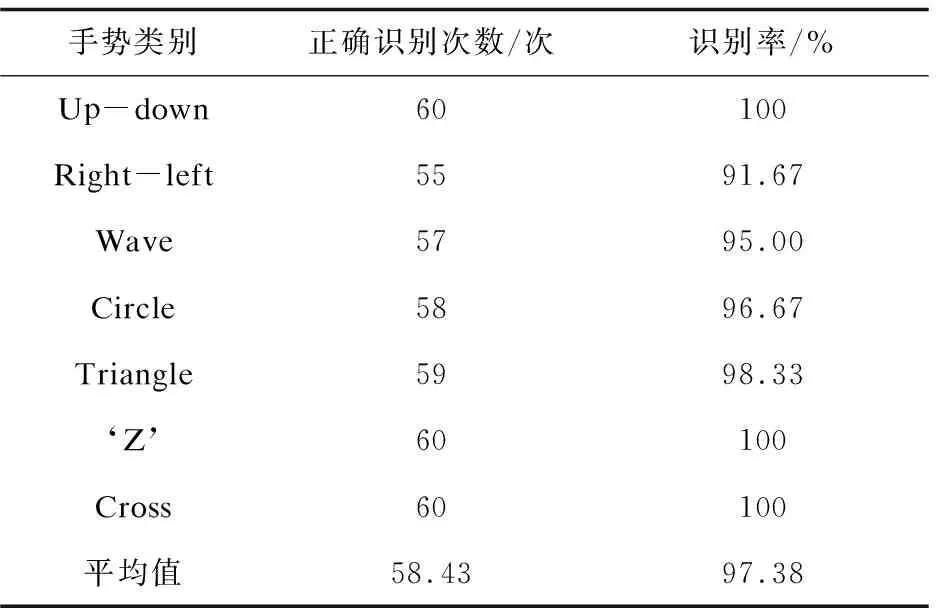

5 结束语
