基于热重启机制的胶囊投影网络快速训练算法
2020-12-25张索非吴晓富
谢 奔,张索非,吴晓富
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京邮电大学 物联网学院,江苏 南京 210003)
0 引 言
在过去的十年,卷积神经网络(convolutional neural network,CNN)在包括图像分类、语义分割、目标检测、人脸识别等计算机视觉任务上都取得了不错的成绩[1-4]。尽管卷积神经网络在很多领域中都取得了重大突破,但是它仍然存在着一定的局限性,比如网络中的池化层会使得图像中的空间信息丢失等。为了解决上述问题,Hinton等人提出了胶囊网络[5],并在几个小型分类数据集(如MNIST[6])上取得了不错的性能,后续有一些工作者对其结构进行了研究[7-9],发现胶囊网络结构过于简单以及动态路由机制的计算过于复杂是导致其在大型分类数据集(如CIFAR10,CIFAR100[10])上没有传统的卷积神经网络性能好的原因。针对胶囊网络的这些局限性,文献[11]提出一种胶囊投影网络(capsule projection network,CapProNet)。该模型使用一组胶囊张成的子空间来表征实体,一旦一组胶囊子空间被学习到,模型即可将提取的特征投影到这组胶囊子空间上形成一组胶囊以用于分类任务。与文献[5]一样,胶囊的长度用于计算输入样本属于对应类别的概率,其方向则用于表示实体的一些其他属性,例如姿势、尺寸、纹理等。胶囊投影网络的另一个优点在于其可以很容易地嵌入到现有的神经网络结构上,融入了胶囊投影网络后的结构在多个分类数据集上取得了性能提升。
尽管胶囊投影网络在多个分类数据集上取得了不错的性能,但是这是建立在比较高的训练成本基础上达到的,而过高的训练成本会削弱模型的泛化能力。为了解决上述问题,受文献[12]的启发,该文引入一种基于热重启机制的随机梯度下降算法(stochastic gradient descent with warm restarts,SGDR)到胶囊投影网络的学习中,提出了一种基于热重启机制的胶囊投影网络快速训练算法,并在多个分类数据集上进行评估。
实验结果表明,该方法在降低训练成本的同时实现了比较好的泛化性能,例如,使用WideResNet[13]作为主干网与CapProNet结合后的网络模型在CIFAR10 与CIFAR100数据集上分别取得的最好结果为3.56%与18.73%,然而文献[11]中报道的在CIFAR10与CIFAR100数据集上分别取得的最好结果只有3.64%与19.83%。对应地,该方法使得模型训练完全收敛只需要300个epochs,相较于原论文的训练策略所需要的500个epochs,很大程度上降低了训练成本。
1 胶囊投影网络
1.1 网络结构
胶囊投影网络是文献[11]中提出的一种新型神经网络结构,不同于文献[5,14],胶囊投影网络通过学习一组胶囊子空间表征一组实体类,胶囊子空间的学习是为了将主干网提取的特征投影到上面形成一组胶囊用于分类任务。同样地,胶囊的长度可以用于计算输入样本属于对应类别的概率,其方向则用于表示实体的一些其他属性,例如姿势、尺寸、纹理等。与原始胶囊网络结构不同的是,胶囊投影网络可以作为分类层(classification layer)嵌入到多种现有的神经网络结构(例如ResNet[15]、WideResNet[13]等)中来帮助网络更好地学习特征,以提高网络的性能。
一个典型的胶囊投影网络与主干网络相结合的结构如图1所示。这里以CIFAR10数据集为例,首先,给定输入图片,经过一个主干网提取出特征x∈d;然后,当胶囊投影网络学习到10个胶囊子空间S={S1,S2,…,S10}后,可以将特征x分别投影到这些子空间上得到10个胶囊[v1,v2,…,v10]∈10×d,这里d指胶囊的维度;
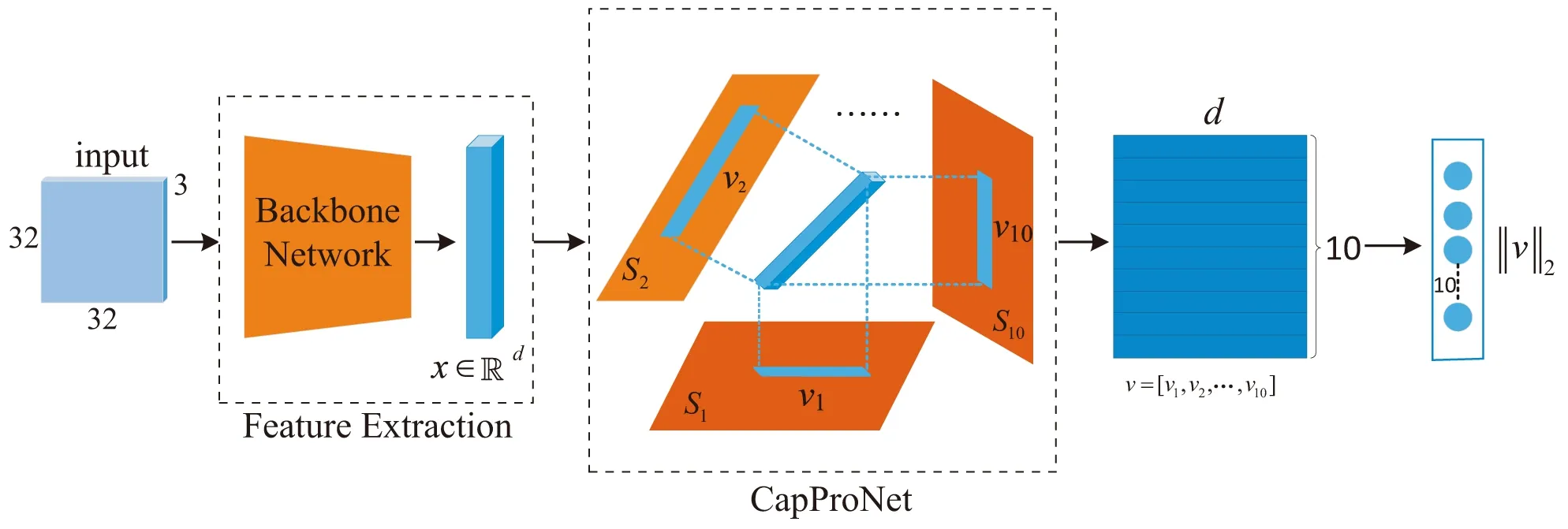
图1 主干网络与胶囊投影网络结合后的网络结构
最后,可以通过计算这些胶囊的长度‖v‖2得到输入图片属于对应类别的概率,其中长度最长的胶囊对应最终的分类结果。
1.2 特征在胶囊子空间上的投影
处于网络结构核心位置的是胶囊投影算法,这一部分将详细对该算法进行一个说明。假设输入样本有L类,这样胶囊投影网络需要学习L个胶囊子空间,即{S1,S2,…,SL}。假设主干网提取出输入样本的特征x∈d,为了学习到一定的特征表示,将x分别投影到L个胶囊子空间上,从而得到L个胶囊[v1,v2,…,vL],每个胶囊的长度用于表示输入样本属于对应类别的概率。
对于每个胶囊子空间而言,网络通过学习一个权重矩阵Wl={w1,w2,…,wc}∈d×c,使用权重矩阵的列向量作为基向量构建子空间,即Sl=span(Wl)。这样特征在胶囊子空间上的投影可通过式(1)得到:
(1)
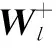
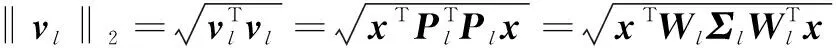
(2)

2 基于热重启机制的胶囊投影网络快速训练算法
基于热重启机制的梯度下降算法(SGDR)[12]通过将SGD优化器与热重启机制相结合在多个分类任务上取得了不错的效果。所谓的热重启机制是指在网络训练的时候人为设定一个重启周期Ti,每达到这个周期,将重新启动初始学习率进行训练,同时模型的每次重启使用上一次重启的参数作为初始化,其本质上就是一个学习率的调整。该文通过将SGDR算法与胶囊投影网络相结合,提出了一种基于热重启机制的胶囊投影网络快速训练算法。
对于基于热重启机制的胶囊投影网络快速训练算法,采用余弦退火方案来调整学习率,从而达到热重启的作用。对于每次迭代,采用式(3)调整学习率:
(3)
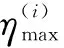
(4)
为了使基于热重启机制的胶囊投影网络快速训练算法更好地提升模型性能,初始设置Ti=0为一个相对比较小的值,例如将其设置为总的训练预算的1/10,在下一次重启前再乘上一个乘数因子Tmult,以变化重启周期Ti。通过这种动态改变重启周期的方式来促使网络模型快速找到最优解,以降低训练成本。

图2 算法示例
这里,通过一个例子来说明基于热重启机制的胶囊投影网络快速训练算法的具体设置,如图2所示。将初始学习率设为0.1,同时令Ti=0=10,Tmult=2,当训练的epoch达到10时,此时学习率ηt=10=0,这时由于Tcur=Ti=0,所以在下一次重启前需要将Tcur设置为0,这样学习率ηt将重新回到初始学习率,网络也将重新回到初始状态进行训练,同时将Ti=0乘上一个乘数因子Tmult=2,从而得到下一次重启的周期为Ti=1=Ti=0Tmult=20,以此类推,直到训练结束。基于热重启机制的胶囊投影网络快速训练算法通过这种反复重启来促使网络模型快速找到最优解,从而在提高网络的性能的同时也降低了训练成本。
3 实 验
本节通过实验来验证基于热重启机制的胶囊投影网络快速训练算法可以有效地提升网络模型性能。
3.1 数据集
实验中采用CIFAR数据集来评估所提出的方法。CIFAR数据集包含50 000张像素为32×32的图片作为训练集,10 000张像素为32×32的图片作为测试集。CIFAR10数据集中的所有图片来源于10类目标,CIFAR100数据集中的所有图片来源于100类目标。
3.2 主干网络
实验中选取多种主干网络来评估性能,例如ResNet[15]、WideResNet[13]、Densenet[17]和ResNet(pre-activation)[18]。将主干网络的最后一层分类层用胶囊投影网络 (CapProNet)替代,同时将结合后的网络在所给数据集上进行端到端训练,训练后的模型在测试集上测试得出测试结果。为了书写方便,将主干网标记为X,这样所有主干网络与胶囊投影网络结合后的网络结构可以记为CapProNet+X。
3.3 不同SGDR配置对性能的影响分析
根据第2节的介绍可以发现,不同的SGDR设置对网络模型性能影响很大,同时由于SGDR设置的不同,模型在收敛的时候所需要的epochs也不一样。例如,当Ti=0=10,Tmult=2时,根据图2可以看出,模型可能是在第310个epoch收敛的比较好,又比如,当Ti=0=50,Tmult=1时,模型可能是第400个epoch收敛的比较好,所以为了找到促使胶囊投影网络收敛最好,同时训练成本也较少的设置,就不同SGDR配置对模型性能的影响做了一个消融研究。
选取以下几种设置进行消融研究:(1)Ti=0=1,Tmult=2;(2)Ti=0=10,Tmult=2;(3)Ti=0=20,Tmult=2;(4)Ti=0=50,Tmult=1;(5)Ti=0=100,Tmult=1;(6)Ti=0=200,Tmult=1,使用CapProNet(c=2)+ResNet110网络结构在CIFAR10数据集上进行训练测试,测试结果如表1所示。
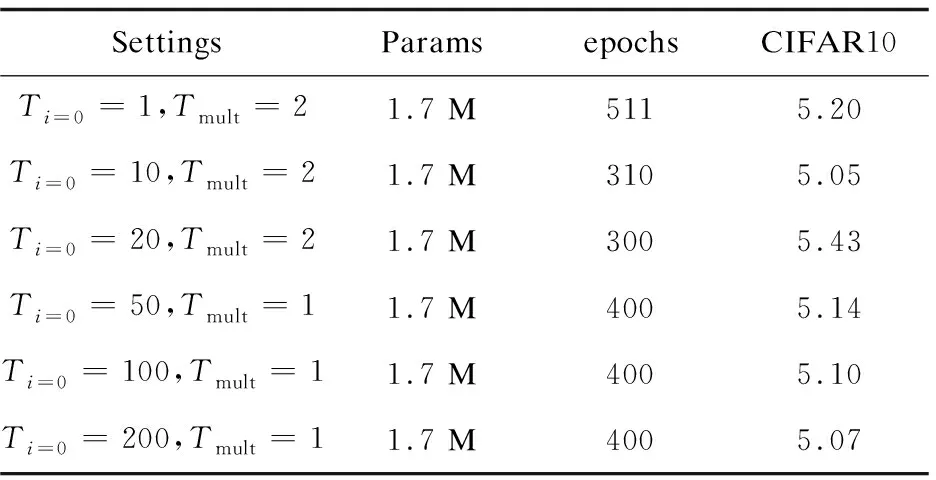
表1 不同SGDR设置条件下CapProNet(c=2)+ResNet110网络在CIFAR10上的测试错误率
从表1可以发现,尽管Ti=0=20,Tmult=2设置的训练成本最低,但是其在CIFAR10数据集上的分类错误率是这几种设置中最高的,相比之下,Ti=0=10,Tmult=2设置在比其训练成本多10个epochs的条件下在CIFAR10数据集上获得了最低的错误率,错误率达到了5.05%,这样在降低训练成本的同时获得了比较好的性能。所以在接下来的所有实验中采用了Ti=0=10,Tmult=2设置来训练网络模型。
3.4 CIFAR10数据集上的分类结果
评估了CapProNet+WideResNet28-10、CapProNet+ResNet110、CapProNet+Densenet100-12和CapProNet+ ResNet164(pre-activation)四种网络结构在CIFAR10上的性能。实验结果如表2所示,与原论文报道相比,该方法实现了更高的性能,在CIFAR10上最好的性能达到3.56%,相比于原论文,减少了2%的错误率。更重要的是比原训练框架减少了接近40%的训练成本,原训练框架需要500个epochs,而我们的仅需要大约300个epochs,这在很大程度上降低了训练成本。

表2 不同网络结构在CIFAR10上的测试错误率
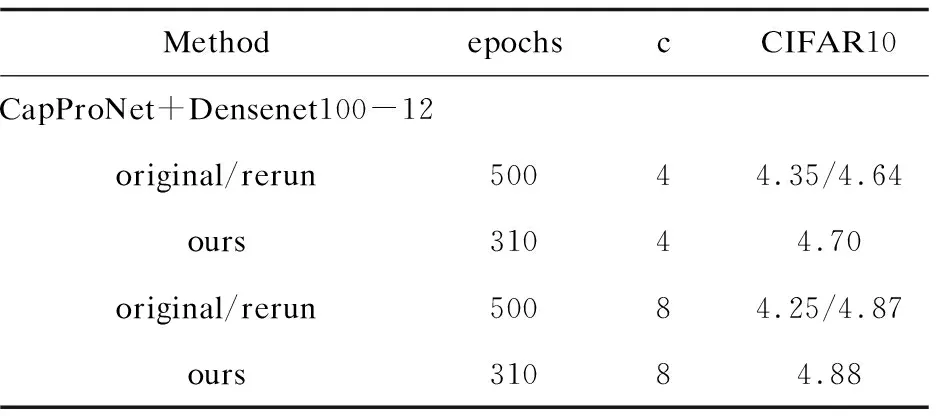
续表2
注意对于CapProNet+Densenet100-12和CapProNet+ResNet164 (pre-activation)网络结构,用500个epoch无法复现原论文报道的结果,所以为了保证公平比较,在表2中报道了原论文报道结果与复现的结果,标记为original/rerun,尽管所提方法并没有达到比较好的性能,但是用更少的训练成本达到了与原论文相当的结果。
3.5 CIFAR100数据集上的分类结果
同样评估了CapProNet+WideResNet28-10、CapProNet+ResNet110、CapProNet+ Densenet100-12三种网络结构在CIFAR100上的性能。实验结果如表3所示,与3.4节一样,也报道了原论文与复现的结果,标记为original/rerun。从表中可以看到,在CIFAR100数据集上最好的性能是18.73%,相比于原论文,降低了6%的错误率,更重要是,该方法比原训练框架减少了接近40%的训练成本,在减少训练的总预算的同时,提升了模型的性能。

表3 不同网络结构在CIFAR100上的测试错误率
3.6 学习曲线的可视化
为了更好地展现提出的算法的有效性,将使用提出的算法的网络模型的学习曲线与原论文网络模型进行一个对比。这里选取了CapProNet+ResNet164(c=4)与CapProNet+Densenet(c=4)在CIFAR10数据集上训练得到的模型。
图3与图4分别为CapProNet+ResNet164(c=4)与CapProNet+Densenet(c=4)在CIFAR10数据集上的学习曲线,其中ours表示使用提出的算法学习得到的模型,original则表示原论文的模型。由图可见,使用提出的算法的模型可以更快地寻找到最优解,相比于原论文的模型需要500个epochs才能完全收敛,而提出的算法第310个epochs就可以完全收敛,这也进一步证明了提出的算法的有效性。
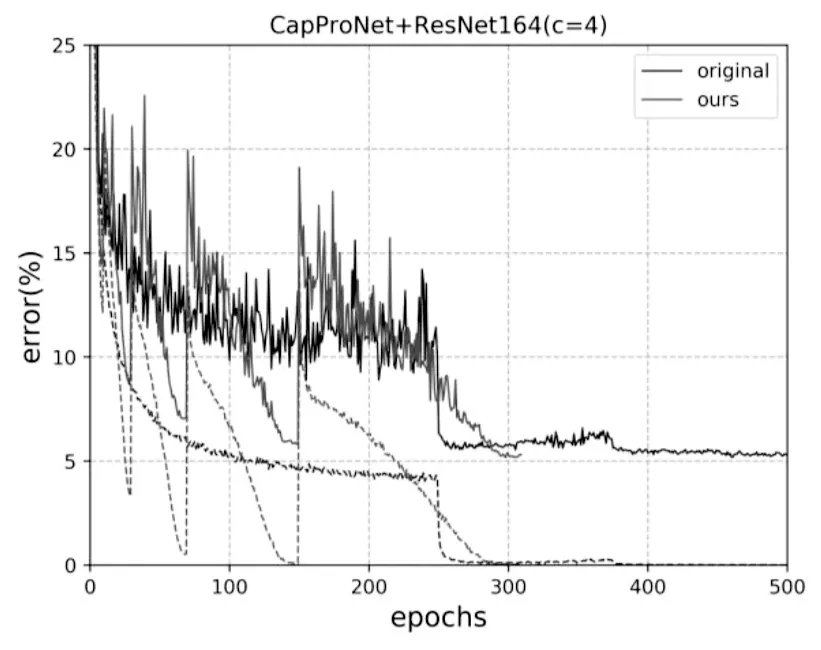
图3 CapProNet+ResNet164(c=4)模型的学习曲线

图4 CapProNet+Densenet100-12(c=4)模型的学习曲线
3.7 消融研究
在这一部分,进一步探究在网络训练过程中通过增加epochs来获得更高性能的方法。考虑以下三种网络结构:CapProNet+WideResNet28-10、CapProNet+ ResNet110、CapProNet+Densenet100-12,将所有的模型在CIFAR10数据集上使用630个epochs训练,同时为了公平比较,使用相同的训练成本重新训练原论文中的模型,二者实验的超参数保持一致。实验结果如表4所示,总体来说,提出的算法实现了比原论文更好的性能,在CIFAR10上最好的性能达到了3.41%,相比文献[4]报道的最好成绩降低了6%的错误率。这些结果表明,提出的方法使用更高的训练成本可以达到更好的泛化性能。

表4 不同网络结构在CIFAR10上的测试错误率
3.8 SGDR算法的兼容性
实验证明,所提出的算法在收敛速度与分类性能上均超过了原胶囊投影网络模型。但是这并不能代表SGDR算法应用于所有深度神经网络结构都可以收敛的很好,为了证明算法不具有普遍应用性,将SGDR算法应用于ResNet110与ResNet164(pre-activation)两种结构上,不同结构在CIFAR10上测试的结果如表5所示。正如表5所示,相同的网络模型下,使用SGDR算法的结果远不如不用SGDR算法的结果,这也证明了SGDR算法并不适用于所有深度神经网络结构。

表5 不同训练策略在CIFAR10上的测试错误率
4 结束语
将基于热重启机制的随机梯度下降算法引入到胶囊投影网络的学习中,提出了一种基于热重启机制的胶囊投影网络快速训练算法,并分别在CIFAR10与CIFAR100数据集上进行了性能评估。实验结果表明,该方法在降低训练成本的同时还获得了比较好的泛化性能,因此,基于热重启机制的随机梯度下降算法可作为胶囊投影网络的一种标准训练算法,推动这种网络模型的进一步发展以及应用。目前的胶囊投影网络只用于分类任务中,在未来可以进一步探究其在目标检测、人脸识别与行人重识别等任务的可能性。
