多维度注意力和语义再生的文本生成图像模型
2020-12-25庄兴旺丁岳伟
庄兴旺,丁岳伟
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引 言
文本生成图像(text to image,T2I)是指生成与给定文本描述匹配的视觉真实图像。由于其在许多应用领域的巨大潜力,T2I已经成为自然语言处理和计算机视觉界的一个重要研究领域。虽然在使用生成对抗网络(GAN)生成视觉逼真的图像方面取得了重大进展,如文献[1-8]所示,但确保生成的图像与输入文本的语义对齐仍然具有很大的挑战性。
与基本的图像生成问题相比,T2I是以文本描述为条件的,而不是仅从噪声开始。利用GAN[9]的强大功能,提出了不同的T2I方法来生成视觉逼真的文本图像。例如,Reed等人提出了一种解决文本到图像合成问题的方法,即找到文本描述的视觉识别表示,并利用该表示生成真实的图像[10]。Zhang等人提出了在两个独立的阶段生成图像的Stackgan[2]。Hong等人提出了从输入文本中提取语义布局,然后将其转换为图像生成器,以指导生成过程[5]。Zhang等人提出在网络层次结构中引入了伴随的层次嵌套对抗性目标,它规范了中间层的表示,并帮助生成器训练来捕获复杂的图像统计信息[3]。这些方法都仅利用鉴别器来区分。然而,由于文本和图像之间域的差异,当单独依赖于这样一个鉴别器时,很难对语义一致性进行建模。最近,人们利用注意力机制[4]来解决这一问题,它引导生成器在生成不同的图像区域时关注于不同的单词。然而,由于文本和图像形式的多样性,仅在单词级别使用注意力并不能确保全局语义的一致性。T2I生成可以看作是图像字幕(或图像到文本生成,I2T)的逆问题[11-12]。如果T2I生成的图像在语义上与给定的文本描述一致,那么T2I重新描述的语义应该与给定的文本描述完全相同。基于这一观察,该文在MirrorGAN的基础上提出了一种新的文本到图像到文本的模型MirrorGAN++来改进T2I的生成。MirrorGAN++有两个模块:MCAM和STRM。MCAM是多维度的注意力协同模块,利用单词级别的注意和全局句子级别的注意逐步增强生成图像的多样性和语义一致性。STRM是语义文本再生模块,它可从最后生成的图像重新生成文本描述,在语义上与给定的文本描述对齐。对两个公共基准数据集进行的深入实验表明,在视觉真实性和语义一致性方面,MirrorGAN++优于其他方法。
1 相关工作
CycleGAN[13-15]可以让两个领域的图片互相转化[16-17],传统的GAN是单向生成,而CycleGAN是互相生成。MirrorGAN++部分灵感来自CycleGAN,但有两个主要区别:
(1)MirrorGAN++专门解决T2I问题,而不是图像到图像的转化。文本和图像之间的跨媒体域间隙可能比具有不同属性(例如样式)的图像之间的间隙大得多。此外,每个域中存在的不同语义使得保持跨域语义一致性变得更加困难。
(2)MirrorGAN++通过使用成对的文本图像数据进行监督学习,而不是从不成对的图像数据进行训练。此外,为了体现通过重新描述学习T2I生成的思想,使用基于CE的重构损失来规范重新描述的文本的语义一致性,这与CycleGAN中的L1循环一致性损失不同,后者处理视觉相似性。该模型是基于MirrorGAN的,然而,由于MirrorGAN对输入的文本是用RNN来处理,使用RNN生成的词嵌入和句嵌入表现没有BERT生成的好,所以选择用BERT来生成词嵌入和句嵌入,这样可以更好地提升模型生成图片的质量。对于语义文本再生模块,选用更加先进的图像字幕模型来更好地提升模型的语义一致性。
2 模型实现
如图1所示,MirrorGAN++集成了T2I和I2T模块,它利用了重新描述学习T2I生成的思想。生成图像后,MirrorGAN++会重新生成其描述,从而将其语义与给定的文本描述对齐。从技术上讲,MirrorGAN++由两个模块组成:MCAM和STRM。模型的细节将在下面介绍。

图1 用于文本到图像生成的模型MirrorGAN++示意图
2.1 MCAM:多维度的注意力协同模块
首先,引入文本编码器,将给定的文本描述嵌入到本地单词级特征[18]和全局句子级特征中。如图1最左边的部分所示,BERT[19]用于从给定的文本描述T中提取语义嵌入,其中包括单词嵌入w和句子嵌入s。
w,s=BERT(T)
(1)
其中,T={Tl|l=0,1,…,L-1},L表示句子长度,w∈RD×L,s∈RD,D是w和s的维数,由于文本域的多样性,组合较少的文本可能具有相似的语义。因此,使用条件增广方法[2]来增广文本描述。这将产生更多的图像文本对,具体来说,使用Fca来表示条件增强函数,并获得增广后的句子向量:
sca=Fca(s)
(2)
其中,sca∈RD',D'为增广后的维数。
下一步将三个图像生成网络依次叠加,构造一个多级级联生成器。采用了文献[4]中描述的基本结构,因为它在生成真实图像方面具有良好的性能。在数学上,使用{F0,F1,…,Fm-1}表示m个视觉特征变换器,{G0,G1,…,Gm-1}表示m个图像生成器。每个阶段的视觉特征fi和生成的图像Ii可以表示为:
(3)

首先,使用文献[4]中提出的单词级注意模型来生成一个注意词的上下文特征。它以词嵌入w和视觉特征f作为每个阶段的输入。词嵌入w首先被感知层Ui-1作为Ui-1w转换成视觉特征的公共语义空间,然后将其与视觉特征fi-1相乘,得到注意力得分。最后,通过计算注意力得分与Ui-1w之间的内积,得到注意词的上下文特征:
(4)
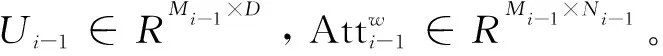
然后,提出了一个句子级注意模型,在生成期间对生成器实施全局约束。通过与单词级注意模型的类比,将增广的句子向量sca通过感知层Vi-1转换为视觉特征的潜在公共语义空间Vi-1sca。然后,将其与视觉特征fi-1进行元素相乘,得到注意力得分。最后,通过计算注意力得分与Vi-1sca的元素相乘得到注意句上下文特征:
(5)
2.2 STRM:语义文本再生模块
就像之前说的那样,MirrorGAN++包含一个语义文本再生模块(STRM),用于从生成的图像中重新生成文本描述,该图像在语义上与给定的文本描述对齐。具体来说,使用了一个自下而上和字幕模型相结合的注意力模型[20]作为基本的STRM的体系结构。
其中,自下而上的注意模型(使用Faster R-CNN)用于提取图像中的兴趣区域,获取对象特征。预先将它在ImageNet[21]上训练。而字幕模型用于学习特征所对应的权重(使用2个LSTM模块)。
在自下而上的注意力模型中,把最后阶段生成器生成的图像Im-1送入这个注意力模型中,如下所示:
(6)
其中,vi是一个视觉特征,在字幕模型中用作输入。

图2 字幕模型的示意图

(7)
其中,We表示一个词嵌入矩阵,它将文字特征映射到视觉特征空间,∏t是输入单词的独热编码。
(8)
其中,Wva∈RH×M,Wha∈RH×M,wa∈RH是学习参数。

(9)
Language LSTM的输入包括图像特征和Attention LSTM的输出,由下式给出:
(10)
词的概率分布为:
(11)
其中,Wp∈R|∑|×M,bp∈R|∑|是学习的权重和偏差。
2.3 目标函数
根据普遍的做法,首先采用了两种对抗性损失:视觉和真实的对抗性损失和文本图像对语义一致性的对抗性损失,定义如下:
在模型训练的每个阶段,生成器G和鉴别器D交替训练。特别是生成器Gi在第ith阶段通过最小化损失进行训练,如下所示:
(12)
其中,Ii是在第i阶段的分布pIi中采样生成的图像。第一项是视觉和真实的对抗性损失,用来区分图像是真实的还是虚假的。第二项是文本图像对语义一致性的对抗性损失,用来确定图像和句子语义是否是一致的。
进一步提出了一个基于CE的文本语义重构损失,以在STRM的重新描述和给定的文本描述之间对齐语义。从数学上讲,这种损失可以表示为:
(13)
值得注意的是,在STRM预训练期间,也使用了Lstrm。当训练Gi时,从Lstrm到Gi的梯度通过STRM反向传播,其网络权重保持不变。
使用AttnGAN的DAMSM损失[4]LDAMSM来测量图像和文本描述之间的匹配度。LDAMSM使生成的图像更好地依赖于文本描述。
生成器的最终目标函数定义为:
(14)
其中,λ1和λ2是调节文本语义重构损失和DAMSM损失的相应权重。
鉴别器Di被交替训练,以避免被生成器骗过去,将输入分为实输入和假输入。与生成器类似,鉴别器的目标函数包括视觉和真实的对抗性损失和文本图像对语义一致性的对抗性损失。在数学上,它可以定义为:

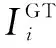
鉴别器的最终目标函数定义为:
(16)
3 实验研究
在这一部分中,进行了大量的实验,以评估提出的模型。首先将MirrorGAN++与之前的T2I方法,如GAN-INT-CLS[10]、StackGAN[2]、StackGAN++[22]、PPGN[23]、AttnGAN[4]和MirrorGAN[8]进行比较。然后,介绍了对MirrorGAN++中MCAM和STRM的关键部分的消融研究。
3.1 实验方案
3.1.1 数据集
在两个常用数据集上(CUB bird数据集[24]和MS COCO数据集[25])对模型进行评估。CUB bird数据集包含8 855个训练图像和2 933个测试图像,包含200个类别,每个鸟图像有10个文本描述。COCO数据集包含82 783个训练图像和40 504个验证图像,每个图像有5个文本描述。两个数据集使用文献[2,4]中的方法进行预处理。
3.1.2 评价指标
首先,Inception Score[26]被用来衡量生成图像的客观性和多样性。使用文献[2]提供的两个模型来计算分数。然后,使用文献[4]中引入的R-precision来评估生成的图像与其相应文本描述之间的视觉语义一致性。对于每个生成的图像,使用其真实的文本描述和从测试集中随机选择的99个不匹配描述来形成文本描述池。然后,在计算R-precision之前,计算了池中每个描述的图像特征和文本特征之间的余弦相似性。R-precision的值越高表示生成的图像和输入文本之间的视觉语义一致性越高。Inception Score和R-precision按文献[2,4]计算。
3.1.3 实现细节
MirrorGAN++总共有三个生成器,最后两个生器采用MCAM,如式(3)所示。逐步生成64×64、128×128、256×256像素的图像。使用预训练的BERT[19]计算文本描述中的语义嵌入。词嵌入D的维数是256。句子长度L是18。视觉嵌入的维度Mi设置为32。视觉特征尺寸为Ni=qi×qi,三个阶段的qi分别为64、128和256。增广后的句嵌入D'的维度设置为100。文本语义重构损失的损失权重λ1设置为20,DAMSM损失权重λ2在CUB bird数据集中设置为5,在MS COCO数据集中设置为50。
3.2 实验结果与分析
在本节中,将定量和定性地与其他方法进行比较。首先,对MirrorGAN++使用CUB bird和COCO数据集的Inception Score和R-precision与之前的文本生成图像方法[2,4,8,10,22-23]进行比较。然后,对MirrorGAN++和之前的方法进行了主观视觉比较,以验证MirrorGAN++的有效性。
3.2.1 定量结果
将MirrorGAN++与CUB和COCO测试数据集上的其他模型进行了比较,结果见表1和表2。

表1 不同模型在CUB和COCO数据集下的IS(越高越好)
如表1所示,MirrorGAN++模型在CUB数据集上IS达到了4.82,远优于其他方法。与MirrorGAN相比,MirrorGAN++将CUB数据集的IS从4.56提高到4.82(提高5.70%),将COCO数据集的IS从26.47提高到31.49(提高18.96%)。实验结果表明,MirrorGAN++模型生成的图像质量更好。
如表2所示,MirrorGAN++与MirrorGAN相比将CUB数据集的RI提高了0.91%,COCO数据集的RI提高了1.42%。较高的RI表明,MirrorGAN++生成的图像和输入文本之间的视觉语义一致性较高,进一步证明了所采用的语义文本再生模块的有效性。

表2 不同模型在CUB和COCO数据集下的RI(越高越好)
3.2.2 定性结果
对于定性评估,图3和图4显示了MirrorGAN++和之前模型生成的文本到图像合成示例。与GAN-INT-CLS、StackGAN 和AttnGAN相比,STRM-AttnGAN++方法生成的图像质量更高,细节更多,文本图像的语义一致性也更好。这是因为MCAM和STRM有助于生成具有更多细节和更好语义一致性的细粒度图像。

图3 不同的模型在CUB测试集上的文本生成图像
在单主题生成方面,即图3中CUB数据集上生成的样本,MirrorGAN++模型更好地突出了图像的主题鸟并且细节呈现得更丰富,MirrorGAN++方法能够更好地理解文本描述的逻辑,并呈现出更清晰的图像结构。例如,图3的第1列、第2列和第4列中AttnGAN生成的示例的鸟的头部到图片的外面,而文中模型就没有这个问题。
在多主题生成方面,即图4中的COCO数据集生成的样本,当文本描述更复杂且包含多个主题时,生成图像更具挑战性。MirrorGAN++根据最重要的主题精确地捕捉主场景,并合理地安排其余的描述性内容,从而改善了图像的整体结构。例如,在图4的第2列需要标识浴室所需的组件,而MirrorGAN++是唯一一种成功的方法。还可以看出,图4的第3列和第4列中GAN-INT-CLS、StackGAN 和AttnGAN生成的示例的形状看起来很奇怪并且缺乏一些细节,而文中模型要好很多。
视觉结果表明,MirrorGAN++方法生成的图像质量更高,细节更多,文本图像的语义一致性也更好。

图4 不同的模型在COCO测试集上的文本生成图像
3.3 消融研究
MirrorGAN++关键部分的消融研究:接下来对所提出的模型进行消融研究。为了验证STRM和MCAM的有效性,通过在MirrorGAN++中移除和添加这些成分进行了几个比较实验。结果见表3和表4。

表3 不同权重设置下的MirrorGAN++IS结果

表4 不同权重设置下的MirrorGAN++RI结果
首先,参数很重要。在CUB数据集上,λ2设置为5,当λ1从5增加到20时,IS从4.03增加到4.82,RI从45.77%增加到71.43%。在COCO数据集上,λ2设置为50,当λ1从5增加到20时,IS从21.15增加到31.49,RI从59.36%增加到89.01%。将λ1设为20作为默认值。
没有MCAM和STRM(λ1=0)的MirrorGAN++已经比StackGAN++[22]和PPGN[23]取得了更好的效果。将STRM集成到MirrorGAN++中会进一步提高性能。IS在CUB中从3.87分提高到4.71分,在COCO中从19.78分提高到30.37分,RI呈相同趋势。值得注意的是,没有MCAM的MirrorGAN++已经超过了之前的AttnGAN(见表1),后者也使用了单词级的注意力。这些结果表明,STRM在帮助生成器获得更好的性能方面很有效。具体来说,STRM从最后生成的图像重新生成文本描述,在语义上与给定的文本描述对齐。此外,STRM与MCAM的结合进一步提高了IS和RI,使最后的结果超越了MirrorGAN。这些结果表明,提出的改进的多维度的注意力协同模块MCAM和语义文本再生模块STRM是非常有效的。
4 结束语
提出了改进的多维度的注意力协同模块MCAM和语义文本再生模块STRM,以解决具有挑战性的T2I生成问题。MCAM具有从粗到细生成目标图像的级联结构,利用本地单词注意和全局句子注意逐步增强生成图像的多样性和语义一致性。STRM通过从生成的图像中重新生成文本描述来进一步监督生成器,使该图像在语义上与给定的文本描述对齐。通过对两个公共基准数据集的深入实验,证明了MirrorGAN++优于其他方法。
