基于特征子集与特征区分度的生物认证方法
2020-12-25李劲松姚明海
王 娜,李劲松,姚明海
(渤海大学 信息科学与技术学院,辽宁 锦州 121013)
0 引 言
生物认证方法就是指智能系统通过人体自身具有唯一性的生物或行为特征来验证人的身份。由于人体生物特征具有唯一、可靠、安全的特点,已经受到广大科研人员的广泛关注。利用人体特征进行身份识别的方法已经成为了社会安全和网络安全等领域进行身份识别的重要手段之一。基于人体生物特征的身份识别在社会医疗、案件侦破、金融服务、网络销售、公司考勤等领域都有广泛应用[1]。但随着图像处理技术的快速发展,数据样本的采集也变得非常便捷,但是数字图像技术的发展也使得采集的数据样本的维度会非常高,高维样本数据在运算中很容易产生维数灾难[2]。
特征选择方法就是从采集到的数据样本中挑选出少量且具有代表性的数据,实现原始数据维数的缩减,去掉冗余和干扰信息,提高预测准确率,进而加强对学习结果的理解等。近年来,特征选择方法在模式识别[3]、生物认证[4]、数字图像处理[5]等领域受到广大科研工作者的广泛关注。近年来,国内外学者提出各种特征选择方法,大致可分过滤式、封装式和启发嵌入式[6]。过滤式方法通过对特征重要性打分来进行特征选择,方法简单、快速与学习算法无关。但是这种方法忽视了特征间的相关性。封装式方法通过训练和测试选定的分类器寻找特征子集,这种方法考虑了特征子集和分类器间的相互作用,但也需要付出较高的计算代价,容易出现过拟合。启发嵌入式方法将特征选择方法融入到学习模型构建过程中。因为封装式方法和嵌入式方法考虑到了和分类器的交互,因此在准确率上普遍优于过滤式方法,但过滤式方法具有简单、计算快速等特点,所以过滤式方法在特征选择中也占有很重要的位置。
通过对大量文献的分析和总结,在众多学者研究结果的基础上,提出基于特征子集与区分度的特征选择方法。首先利用随机子空间(random subspace method,RSM)和Fisher得分方法计算出特征排序,然后对其融合获得新的特征排序,最后根据顺序前向搜索方法筛选能够代表样本数据原始表达的特征子集。该方法既具备过滤式特征选择方法的简单、快速的特点,又具有封装式特征选择识别率高的特点;同时还考虑不同方法对特征进行打分后的融合策略。
1 相关方法
1.1 随机子空间特征选择方法
基于随机判别理论的随机子空间方法[7]采用随机抽样方式从原始特征数据空间中获得特征子集,被广泛应用到聚类分析、特征选择、降维等领域。RSM通过随机构建特征子空间,在构建的结果中发现最优结果。

初始化:i←0,t←0,C←01×D,th,T
doi←i+1
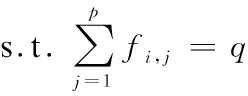
计算子空间fi的预测准确率si
如果si>th并且fi,j=1
则Cj←Cj+1,t←t+1,直到i=T
Cj←Cj/t
算法结束
输出:特征权重向量C
输出结果C表示随机子空间算法得到的特征权重向量,Cj越大说明该特征被选择的频率越高。
1.2 Fisher score
基于Fisher得分的算法是一种发现具备最好区分度的特征子集的有监督选择方法[8],其定义如式(1)所示:
(1)
1.3 顺序前向搜索算法
顺序前向搜索算法(sequential forward search,SFS)[9]是一个前向搜索算法,其核心思想是每次增加一个能使识别率得到提升的特征,直到识别率不再发生改变。
2 基于特征子集与区分度的特征选择方法
该文提出的特征选择方法,分别利用随机子空间RSM和Fisher得分方法给出两个不同的特征排序。然后对特征数据被选中的频率和特征数据的Fisher得分进行有效融合,产生一个新的特征数据的排序,最后利用SFS方法选出最终的特征子集。
算法流程如图1所示。
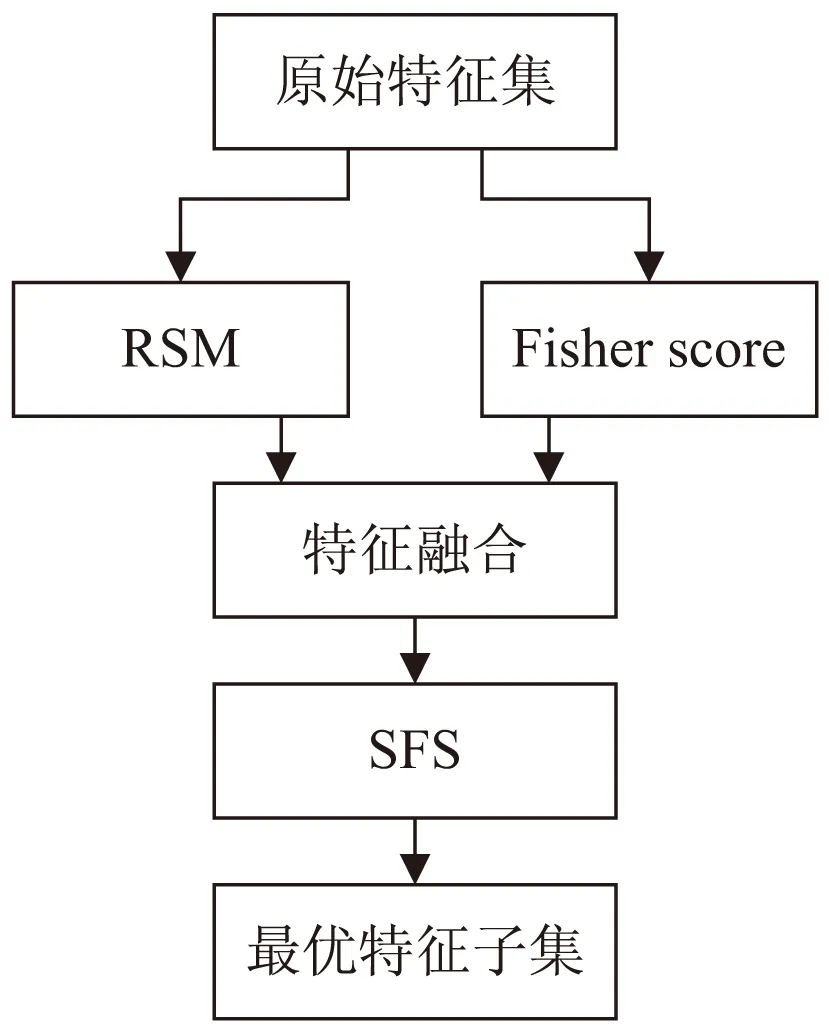
图1 算法流程
融合公式如式(2)所示:

(2)
经过了融合后,每一个特征都会拥有一个权重,根据权重可以得到一个初步的排序结果。权重越高说明该特征越重要,但是这些高权重的特征也有可能含有冗余信息,因此采用顺序搜索方法来剔除数据中的冗余信息,获得维度低、预测准确率高的特征。原始顺序搜索方法理论上也能够获得最优特征,但是原始顺序搜索算法的计算效率相对较低,不易实现。该文通过对特征先预排序,在此基础上采用顺序前向搜索算法可以明显地提高算法的搜索效率。
3 实验结果与分析
为了验证文中方法的有效性,实验中的数据采用生物认证领域中常用于算法验证的五个生物识别数据库,并在实验前数据库数据进行预处理。实验中将文中提出的方法同多种特征选择方法在选择出的维度最高不超过200维的前提下进行对比。为了验证特征选择方法的实际使用效果,采用K-nn分类算法来验证。使用样本预测的准确率(predictive accuracy,PR)作为评价算法有效性的标准,具体计算方法如式(3)所示。为满足统计规律中覆盖样本数量的要求,全部实验中都采用10次随机取样的方法对算法有效性的验证。每次的测试都使用50%的样本用于训练分类模型,剩余的50%样本作为测试样本进行分类模型的测试。经实验统计10次的随机采样已经基本覆盖了99%的实验数据都参与了分类模型的训练和测试过程,计算获得的平均PR为最后结果。
(3)
其中,Num为测试样本个数,RP为正确识别的样本个数。
3.1 在FERET数据库上的实验结果
FERET数据库[10]是由美国国防部发起的人脸识别项目(face recognition technology,简称FERET)数据库,在1993年到19997年创建,是生物认证领域普遍使用的算法验证数据库之一。FERET库共有1 428个采集样本的14 051幅面部灰度图像。对比实验中选择了来自72个人的432幅图像,每个人选取了6幅不同姿态的图像,实验前对这432幅图像进行了预处理,将图像大小调整为32×32像素。图2展示了部分实验用图。

图2 FERET库中的部分人脸图像数据
由表1可以看出,文中提出的IFS方法在维数仅为100的前提下识别准确率就达到了80.4%,明显高于其他方法。
3.2 在ORL人脸数据库上的实验结果
ORL数据库[11]中包含了400幅人脸图像,这400幅图像是来自于40个人的不同面部表情图像。ORL库中的图像具有表情和轻微的姿态变化,是人脸识别算法验证实验中经常使用的标准数据库。对比实验中将ORL库中的图像进行了预处理,实验中将数据库中的人脸图像进行处理,图像大小调整为44×36像素,图3展示了部分实验用图。
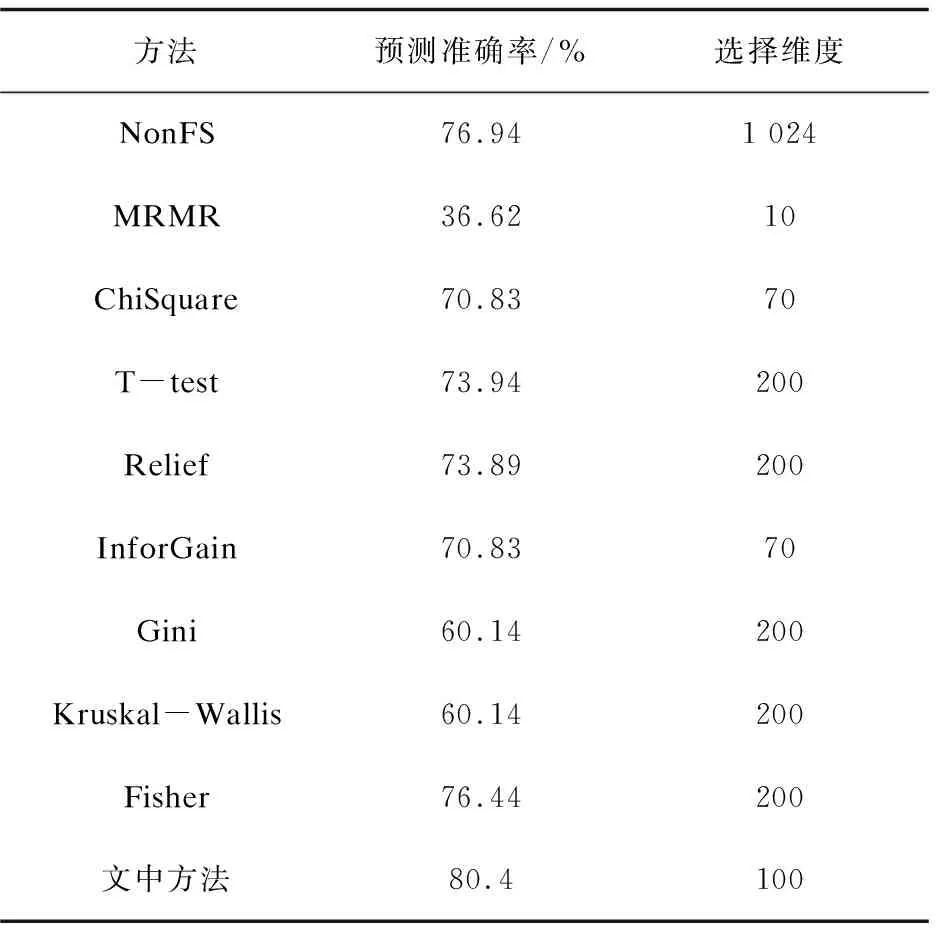
表1 在FERET数据库上的实验对比结果

图3 ORL库中的部分人脸图像数据
由表2可以看出,文中提出的IFS在维数仅为100时就具有较好的预测准确率。虽然其他方法也取得了较高的预测准确率,但是在维度选择上IFS方法要明显低于其他方法。
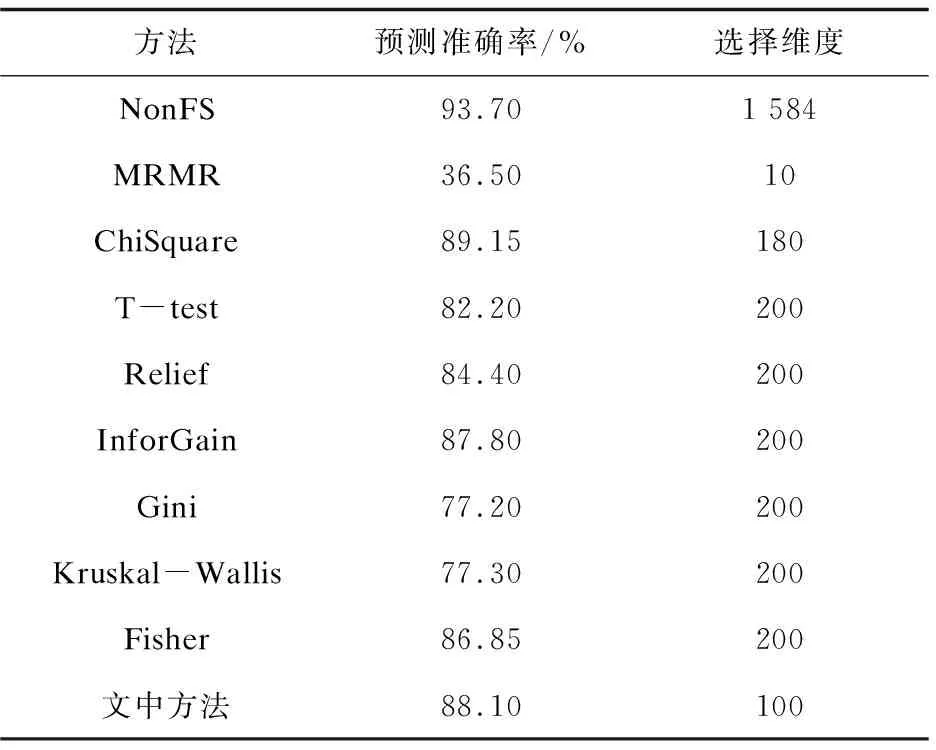
表2 在ORL数据库上的实验对比结果
3.3 在CMU PIE人脸数据库上的实验结果
CMU PIE数据库[12]中包含了41 368幅人脸图像,这些图像是来自于68个人的不同面部表情图像。CMU PIE数据库中的图像包括了在不同姿态、光照和表情的轻微改变,是生物认证研究领域非常重要的测试数据库。文中采用文献[13]的方法对数据进行预处理,每个样本选取相同姿势、相同表情和有差异性光照的21幅进行实验,实验前对这些图像进行了预处理,将图像大小调整为32×32像素,图4展示了部分实验用图。

图4 CMU PIE 库中的部分人脸图像数据
分析实验结果可以看出,所有方法的实验效果都很好,这是由于该数据库中人脸图像自身的问题,全部特征选择方法的识别率均达到了90%以上,个别算法达到100%。但文中提出的特征选择方法在选取维数相对较少时就取得了较好的实验效果(见表3)。
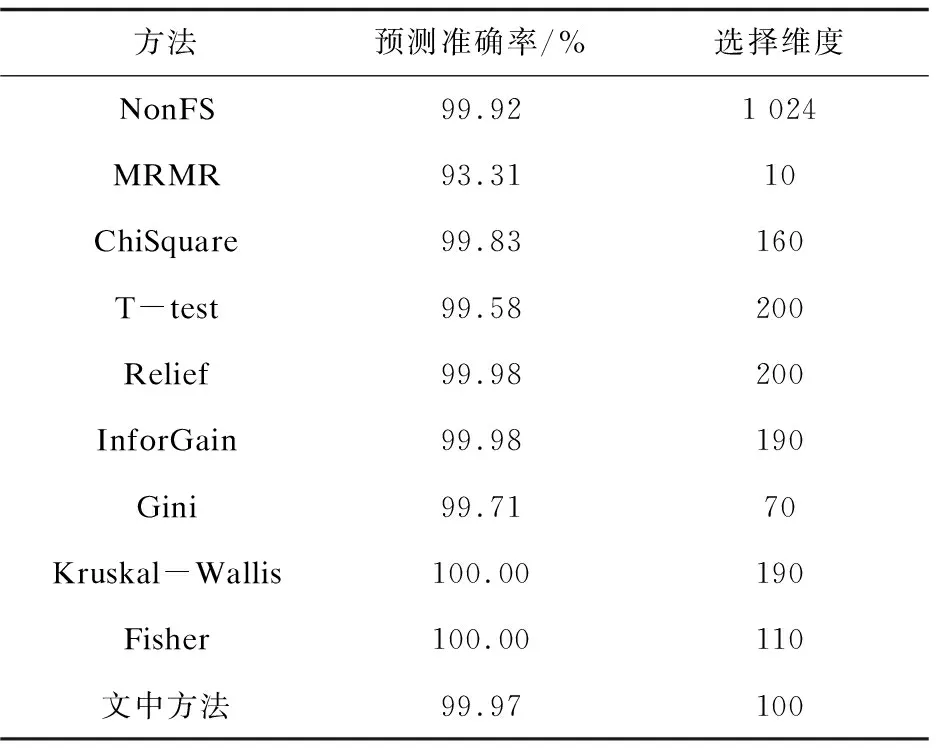
表3 在CUMPIE数据库上的实验对比结果
3.4 在扩展的YaleB人脸数据库上的实验结果
扩展的YaleB库[14]中共有38人的2 432幅人脸图像,平均每个样本约64幅图像,扩展的YaleB库中的图像也包括面部表情差异和光照差异。实验前对这些图像进行了预处理,将图像大小调整为32×32像素。图5展示了部分实验用图。

图5 扩展的YaleB库中的部分人脸图像数据
表4列出了不同方法的最高平均准确率,可以看到文中提出的特征选择方法在维数相对较低时就具有最高的识别准确率。

表4 在扩展YaleB数据库上的实验对比结果
3.5 在CASIA虹膜数据库上的实验结果
CASIA虹膜库是由中国自主创建的用于生物识别验证的数据库,CASIA虹膜库包含了108只眼睛的756幅虹膜图像,图6展示了部分实验用图。CASIA虹膜库是生物认证领域应用最广泛的全公开数据库,已有全球800多家科研机构申请使用该数据库,近些年CASIA虹膜库已成为世界生物认证领域重要的数据支撑。对比实验中采用文献[15]中的数据处理方法对数据库中的图像进行了处理,提取了感兴趣的区域来验证实验效果。

图6 CASIA 库中的部分人脸图像数据
通过表5的实验可以看出,所有方法在选取200维特征数据的前提下识别率都不是很高。出现这一情况的主要原因在于实验前虹膜图像的系列预处理,这些预处理操作包括了在图像中定义感兴趣区域、压缩图像比例等,数据维数变为了原来的1/75。由于数据预处理的效果较好,图像中的噪声数据和冗余数据已经基本被去除,这使得其他方法出现过收敛现象。即使这样文中方法与其他方法相比仍然取得了较好的实验效果。

表5 在CASIA数据库上的实验对比结果
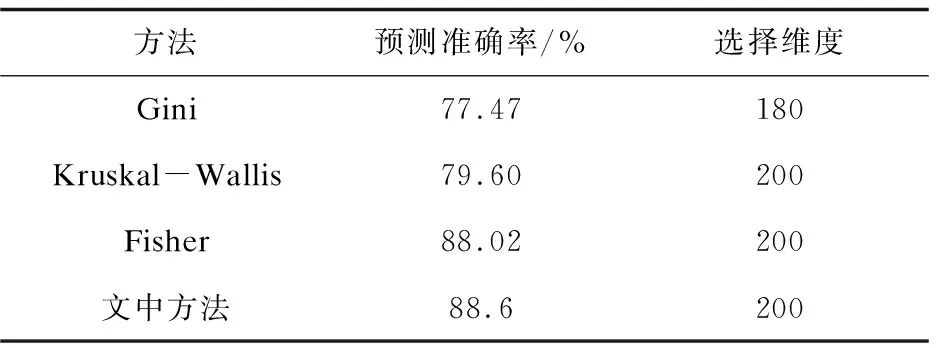
续表5
4 结束语
通过对比实验可以看出,提出的基于特征子集与特征区分度的生物认证方法适用于不同类型的数据库,并且在所有的对比实验中都在较低维数下取得了非常好的预测准确率。但在实际应用中还应当针对不同的实际问题进行详细分析。在该方法中特征权重的计算采用的是Fisher得分法,在今后的研究工作中应该对特征选择采用自适应的评价算法,相信会进一步提高算法的预测效果。
