视听训练在日本学习者汉语焦点重音产出中的作用
2020-12-21张劲松王颖阳
张劲松,吴 静,王颖阳
(1.北京语言大学汉语国际教育研究院,北京100083;2.北京语言大学信息科学学院,北京100083)
1.引言
1.1 焦点与重音
焦点(focus)和重音(accent)是两个不同领域的术语。焦点是句法语义学层面的概念,国内外学者对这一概念的定义不尽相同,Ladd(1980)认为,焦点是语句中需要强调、突出的信息,根据语境又可以分为宽焦点和窄焦点。宽焦点是指整个句子都是焦点,而窄焦点是指句中的某个成分作为焦点。重音是韵律层面的概念,通常认为,重音是发音时比较用力且在语流中听起来相比其他音节更为突出的音节(林焘,1992),根据其作用范围可被称为词、短语或句重音。焦点的实现手段有词汇、句法及语音等形式,其中句重音是窄焦点的主要实现形式,亦称为焦点重音(focal accent,曹文,2010),它是人们语音交际中常用的重要手段。
从语音的声学表现来看,前人研究表明,汉语焦点重音具有“三区段”特征(赵元任,1968;曹文,2010;Xu,1999,2001;王蓓,2002;贾媛,2008),当焦点音节的声调为含有高音点的一、二、四声时,高音点上升且调域扩大;焦点后音高骤降且调域压缩,焦点前音高变化不大。当焦点音节为缺少高音点的三声时,大家报告的声学线索则有不同的看法:Xu(1999)发现焦点三声的低音点明显下降,王蓓(2002)则认为三声负载重音时虽有低音点下降但更多的表现为相邻音节的上升,贾媛(2008)则得出了焦点三声变化复杂没有规律性的结论。除了音高特征外,时长变化也是焦点重音的是重要辅助手段:大家一般都倾向于认为焦点音节往往时长显著加长(赵元任,1968;Xu,1999;贾媛,2008),而曹文(2010)则认为时长是音高的辅助手段,音高受限时时长会作弥补手段,音高特征存在时则有加强重音的作用。
1.2 研究背景
以往的研究显示在对外汉语教学实践中,焦点重音的教学是最薄弱的环节之一(鲁健骥,1984)。无论是母语语调为节奏重音的英语母语学习者(Chen,2012)、亦或音高重音的日语母语学习者(朱川,1997;肖瑶,2018)、或者声调语言的泰语母语学习者(刘妍李,2009;王功平,2018),甚或汉语方言之一的粤语学习者(鲁莎莎,2014)等,他们在学习汉语的焦点重音时都存在困难,表现出焦点重音音高升幅较小、时长延长不足和少有音高落差等问题(陈文芷,1981;杨立明,1989;肖瑶,2018)。焦点重音产出不到位问题被认为是“洋腔洋调”的重要原因(鲁健骥,1984;曹文,2010),改善重音教学效果是对外汉语教学的重要要求。
针对留学生在汉语焦点重音产出中存在的问题,已有的研究主要从以下两个方面寻找解决方法:
(1)语音学知识讲解为先:在向学生讲清楚焦点重音的语音特点基础上再进行焦点重音的产出教学(曹文,2010;林茂灿,2015)。
(2)听觉模仿为主:在课堂教学实践中,以听觉模仿为主,试图用比较法和模仿法来帮助学生产出焦点重音(林焘,1996;李晓朋,2012)。
以上的语调教学方法主要适用于课堂教学。囿于课堂教学中教师与学生“一对多”的模式,这些方法耗时耗力且很难大范围推广。并且学生的语音练习大都发生在课堂之外,单凭关于焦点重音的理论知识以及听觉模仿方式,学生难以自检产出焦点正确与否,进而影响到其对于语调产出的掌握。
近年来,随着计算机语音技术发展,人们提出了利用人机交互方式,以实时图形的方式给出语音语调的视觉反馈,从而达到帮助学生不仅可以听到,还可以“看到”语调的目的,引导学生理解、模仿并掌握二语的语调。例如Anderson-Hsieh(1992)使用Visi-Pitch软件让学生同时对比教师和自己的基频曲线,通过修正二者之间的差异改善英语语调产出;Minematsu(2017)提出了一个日语语调视觉反馈教学系统,可以实时对比基于语音合成系统生成的基频轮廓和学生的发音参数,引导学生进行日语语调练习;Ding(2016)提出一种突出语调特征的可视化方案,可以用于研究及帮助二语学习者产出英语作为二语的语调。
相对于其他语言,针对基于实时图形视觉反馈的汉语语调教学研究则几乎是空白。曹文、王瑞(2010)曾经提出过利用音高曲线示意图的汉语双音节句焦点重音的教学方案,不过并没有付诸教学实践。由于汉语是声调语言,音高曲线不仅受到语调重音的影响,还要受到声调的调制,其可视化设计方案设计需要在表达语调作用之外,还要考虑声调的影响。能否设计出一套有效的可视化方案,尚是一个挑战。
基于以上考虑,本文以日本留学生为对象,研究可视化方法在汉语焦点重音训练中的应用,具体问题包括以下几个方面:(1)能否基于汉语焦点重音的声学表现设计一套有效的可视化方案?(2)视听训练能否帮助日本学生改善焦点重音的产出?(3)基于可视化的视听训练与传统的听觉模仿训练是否存在差异?如果存在那么差异又有什么具体表现?
2.汉语焦点重音的即时视觉反馈方案设计
针对语音语调的即时可视化视觉反馈方案,目前主要分为两类:一类是计算机实时提取学习者的声学参数并以图形形式展示给学生,目前主要是反馈语音的基频轮廓曲线,如Minematsu et al.(2017)的工作;另一类则是在声学参数的基础上进一步提取与音系特征有关的物理参数,再以特征凸显的方式示意给学生,例如在Ding(2016)的工作中,他们以“圆圈”图案表征每个音节,圆心的高度代表音节的平均音高,圆圈的直径代表音节的绝对时长。
比较上述两种视觉化方案,我们认为音系特征凸显示意方案更加合理。原因在于:一方面受限于学习者的语言能力和认知能力,输入语音中充满了众多的变量,如词汇、语法、音段、音高、时长、停延、能量等等,学习者难以即时处理语音频谱及基频轮廓曲线中众多的声学变量,从而影响学习的效果。另一方面,特征凸显原则是语音教学中被证明为行之有效的教学原则,例如李晓朋(2012)就认为教师应将夸张法与模仿法相结合,在示范重音发音时应将重音音节的音高和时长过分提高或增长,使学生留下深刻印象。因此,我们提出借鉴Ding(2016)中所使用的语调方案,根据汉语特点稍作修正,用于汉语焦点重音训练的视觉反馈。
i.在时间横轴-音高纵轴的xy二维平面上以圆圈代表汉语音节;
ii.圆圈圆心的x值代表音节在句中的序列号,y代表声调的特征点音高值。声调一、二、四声取高音点,三声则取低音点;
iii.圆圈的直径大小代表音节的时间长短;
iv.音高采用半音表示,且教师模板采取男性、女性两套发音人数据,用于减小说话人调域差异的影响;
v.时长采用相对时长表示,用于克服语速、音段、不正常停顿所造成的影响。
音高的赫兹-半音转换公式如下:

其中St表示半音,f0表示基频值,fref表示话者调域基频下限值。
相对时长的计算公式如下:

其中i、j表示音节序号,di、dj表示第i、j个音节的时长,dri表示第i个音节的相对时长。需要说明的是,二语学习者的语音中经常有不正常的停顿,这部分时间被剔除在总时长的计算之外。
音节的时间切分信息来自于语音识别系统。学生的语音输入计算机后,即经由语音识别系统进行强制对齐处理,得到声母、韵母层级的对齐信息,进而得到各音节的相对时长参数。
图1 给出了一个我们所开发的焦点重音可视化训练的交互界面示意图。在图中我们可以看到:界面分为三个部分,上部是同文异焦录音文本提示框,A 句为语境提示信息,B 句为发音文本,其中焦点词以红色提醒,按录音按钮即可录入声音;左下部为教师标准发音语调示意图,学生会被事先提醒注意高音点、音高落差及相对时长等主要声学特征,下面的播放按钮按下后会播放教师的发音;右下部为学生发音的语调示意图,在学生录音后即时呈现,供学生对比本次发音与标准音的相似与否,其下的播放按钮按下后可重复播放录入的声音。
3.实验一:视听方案合理性验证实验
为了评估上述所提焦点重音可视化方案的合理性,我们进行了基于视觉信息的焦点声学特征验证实验。基本方法是在如图1 所示的显示界面上,文本框给出同文异焦文本,在左右两个语调示意框内给出两个不同的焦点声学示意图,让汉语母语被试判断哪一个为同文异焦句B 文本对应的语音特征。本次实验不提供语音信号作听辨用。

图1:焦点重音可视化训练方案示意图
3.1 实验语料
实验语料为同文异焦句(吴宗济,2004)。考虑到双音节组合是语调的基本单元,且双音节可以蕴含句子的重音/焦点分布信息,可被认为是“语调核心单元”(曹文,2006),语料从双音节句入手,共有双音节句和三音节句。又因考虑到三声作为焦点时的声学表现在前人的研究中没有一致的结论,且三声低音点难以精准测量,本文实验的声调组合中排除三声。如此,双音节句中有9 种组合,涉及两种焦点状态(前焦、末焦),共18(=9×2)句话,三音节句首、末音节同调,可表示为TXT,其中T={一声,二声,四声},X={一声,二声,四声},三音节句中有9 种组合,涉及三种焦点状态(前焦、中焦、末焦),共27(=9×3)句话,实验语料总共45(=18+27)个短句。
3.2 实验被试
本次实验被试为10 名普通话水平二级甲等及以上的中国北方人,均为北京语言大学学生,平均年龄26 岁,皆无听力障碍。其中,男性4 名,女性6 名。
3.3 实验过程
实验界面由PowerPoint 呈现,屏幕内容如图1 所示,要求被试在没有音频辅助的情况下选出文本所对应的可视化图形。在正式实验之前,有关于汉语焦点重音声学表现知识的简单培训以及少量适应性质的练习。
3.4 实验结果
10 名被试关于图示信息判断结果的正确率如图2 所示,个人正确率在88%到100%之间,平均值为96%。

图2:汉语母语者判断正确率
3.5 讨论
验证实验结果显示,母语者可以仅凭借可视化程序所呈现的图形来准确判断汉语焦点所在的位置(实验中96%的准确率),这表明本文所使用的焦点可视化方案能够有效地作为焦点的视觉表征。我们如果使用该可视化方案作为焦点重音训练的视觉提示线索,作为留学生语音学习过程中的视觉反馈,应该能够起到“可理解性输入”特征的作用(Krashen,1981)。根据Krashen 的输入假说理论,这种特征作为略高于学习者现有水平的可理解性输入,可以激活学习者已有的知识,将能够帮助学习者理解所学内容并最终提高语言能力。
4.实验二:日本学生焦点重音的视听训练与听觉训练
为了考察上文所提出的焦点重音视觉反馈方案对于留学生习得汉语重音的作用,我们开展了基于此方案的重音视听训练实验。为了对比,我们做了另外两组对照实验,一组听觉组参加传统听觉模仿的重音训练实验,另一组普通对照组则只参加实验的测试。
4.1 实验方法
4.1.1 实验语料
实验语料分为训练语料、测试语料和泛化测试语料三部分,设计思路与实验一基本一致,均为同文异焦句和与之同文本的自然焦点句。基于教学“由易到难”的原则,训练语料按句子长度分为双音节、三音节和五音节句。其中,双音节句共9 种组合,焦点模式分前、后及无三种,总计27 句话(=9×3);三音节句为首、末音节同调的TXT 格式,共9 种组合设计,36 句话(=9×4)。五音节句不可避免地涉及到词重音,同样被设计为首、末双音节同调,可表示为TT`XTT`,其中T/T`={一声,二声,四声},共9 种组合设计,36 句话(=9×4),X 被固定为高平调“飞”,选用高平调的原因是:可以帮助日本学生最大程度地练习声调的升高与降低。因此训练语料总共99(=27+36+36)句。测试语料与训练语料结构相同(均为同文异焦句),数量相同但所选音节不同。
音节的选取遵循以下原则:(1)选HSK5级以下较为简单的词汇和汉字;(2)尽量不选日本学生习得困难的声韵母,如后鼻音韵尾,辅音 l、r、zh、ch、sh 等。
为了避免训练过程中的练习效应,在训练结束后,通过17 个同文异焦句对被试进行泛化测试。泛化测试语料与测试语料相比,或是句子结构相同但音节数不同,或是句子结构和音节数均不同。
4.1.2 被试
实验被试为24 名北京语言大学在读日本留学生,均出生于日本,母语为日语,学习汉语 1~3 年,HSK 水平 4~5 级,平均年龄 22 岁,均无听力障碍。他们被随机平均分配到视听组、听觉组及对照组中。其中,视听组有8 名被试 (2 男 6 女),听觉组有8 名被试 (2 男6女),对照组有8 名被试(1 男7 女)。
4.1.3 实验流程
整个实验采用“前测-中测-后测”的设计,流程示意图如图3 所示。实验周期为8天,第1 天、第8 天仅做测试,其余6 天两个训练组每天进行45 分钟左右的视听或听觉训练,对照组则不参与任何训练,第4 天训练后加做一次中间测试。具体内容如下:

图3:实验流程示意图图
·培训:三组被试皆参加实验前的培训。由实验主试借助Praat 软件对其进行汉语声调音高特征、焦点重音声学特征、语音感知、焦点产出测试等基本知识和概念进行指导。
·前测/中测/后测:被试依据测试语料的同文异焦句文本进行录音,保存为16K 采样率的wav 文件。录音在安静的录音室进行。
·泛化测:被试依据泛化测试语料录音,保存为wav 文件。
·视听/听觉训练:训练时,每个句子的引导界面如图4 所示,界面提供引导句文本、语音提问、以及增加语境自然度的相关图片。学生录入自己的发音后,听觉组可以对比标准发音和自己的差异,反复练习;视听组则进入图1 所示的焦点重音可视化训练界面,再进行对比练习。训练期间,主试在旁监督,如果有音段或声调错误,则予以指出让被试改正。
泛化测结束后,我们对三组被试进行了问卷调查,问题主要围绕着关于产出焦点重音的意识、自我满意度等主观感受。
4.2 实验数据处理
通过母语者听辨、声学参数分析、被试问卷调查三种方法对母语者及日本被试的前测、中测、后测和泛化测数据进行分析。
·母语者听辨:日本被试每个句子焦点表达的正确与否,由3 名语言学专业的汉语母语者通过听辨来判断,三人不一致的情况下采用少数服从多数原则。
·声学参数分析:提取以下音高和时长参数来考察日本被试的焦点重音产出的发展情况。
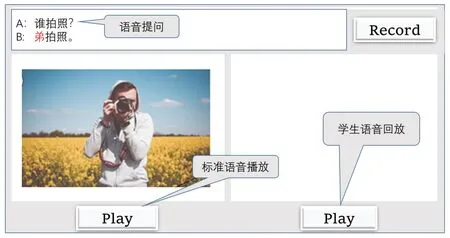
图4:训练引导界面示意图
·焦点音节相对时长的话者规一化z分数
·被试问卷调查:统计问卷调查的被试主观感受。
·统计检验:以重复测量方差分析及事后多重比较分析为主。
4.3 实验结果分析
4.3.1 焦点重音产出情况分析
基于汉语母语者的听辨结果,图5 给出了日本被试焦点重音产出错误率。图中横轴表示不同的测试阶段,纵轴表示错误率。整体而言,两组训练组(视听、听觉)的产出错误率在中测、后测阶段都显著下降,而对照组则趋势平缓,变化较小。比较两组训练组,则试听组错误率下降幅度更大。
对视听组和听觉组的数据进行事后多重比较分析,结果显示,前测和中测(t=0.520,p=0.045;t=0.48,p=0.001),前测和后测(t=0.625,p=0.01;t=0.49,p=0.001) 均存在显著性差异,中测和后测(t=0.105,p=0.473;t=0.01,p=0.802)均不存在显著性差异。分别对前测、中测及后测这三个时间点上的数据进行分析,结果发现,在前测时,三组均无显著性差异,在中测时,视听组与对照组存在显著性差异(p=0.003),视听组与听觉组无显著性差异(p=0.496),在后测时,视听组与听觉组、视听组与对照组均存在显著性差异(p=0.011,p=0.001)。
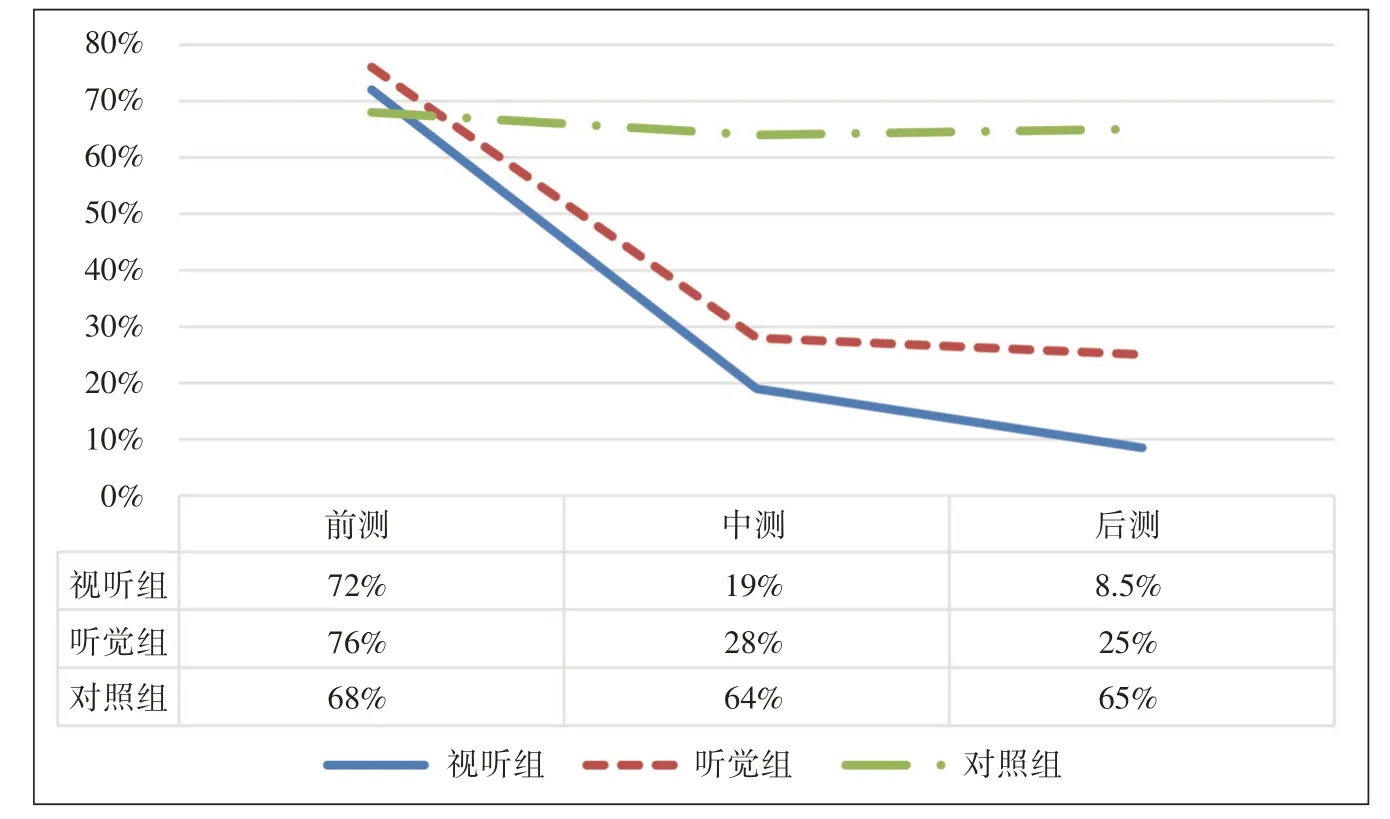
图5:三组被试前、中、后测焦点重音产出错误率
泛化测试的正确率如图6 所示,视听组、听觉组与对照组的正确率分别为91%、72%和54%,统计分析的结果发现视听组与对照组差异显著(p=0.006),但听觉组与对照组之间无显著性差异。
以上结果表明,在训练日本学生产出汉语焦点重音的实验中,视听训练优于听觉训练,这种优势在中测时就已显现,在后测时达到最大化,并且这种产出效果可以泛化到新的句子结构中。

图6:视听组、听觉组与对照组泛化测正确率
4.3.2 声学参数分析
为了考查视听训练及听觉训练在提高汉语焦点重音产出中的具体表现,以下从焦点音节高音点、调域、时长三个方面的声学参数展开讨论,下文图7~9 中横轴皆表示不同测试阶段,纵轴表示经规一化处理的声学数据。
(1)焦点音节高音点发展变化
焦点音节高音点z 分数的发展变化如图7所示。总体而言,视听组、听觉组和对照组都呈上升趋势,视听组上升幅度最大,听觉组在中测时达到最大值,随后基本保持不变,对照组的上升幅度最小。视听组在中测时已达到母语者水平,并在后测时达到最优训练效果,听觉组在后测时也达到母语者水平,但与视听组相比差距较大。
对各组日本被试的数据进行事后多重比较分析,结果显示,无论是视听组还是听觉组,前测和中测(p=0.000,p=0.001)均存在显著性差异,中测和后测(p=0.238,p=0.857) 均不存在显著性差异。分别对前、中、后测这三个时间点上的数据作统计分析,结果显示,前测时三组被试与母语者(p = 0.000,p = 0.000,p = 0.000) 均差异显著,中测时视听组与听觉组、视听组与母语组无显著差异,后测时视听组、听觉组分别与母语者差异不显著,但视听组与听觉组(p=0.008)差异显著。

图7:焦点音节高音点发展变化图
以上结果说明,视听训练和听觉训练均能有效帮助被试提高焦点音节高音点的产出,视听训练的效果优于听觉训练。对照组也有提高,但是幅度较小,推测改善来自于测试的重复效应。
(2)焦点音节音域发展变化
焦点音节音域z 分数的发展变化如图8 所示,三组日本被试呈现出不同的发展趋势。视听组不断上升并在后测时达到了母语者的水平,听觉组先上升后下降,在中测时达到了母语者水平,但在后测时回落到最初水平,对照组基本保持不变。

图8:焦点音节音域发展变化图
对日本被试的数据进行事后多重比较分析,结果显示,视听组前测和中测(p=0.013)存在显著性差异,中测和后测不存在显著性差异,听觉组前测和中测(p=0.000),中测和后测(p=0.000)均存在显著性差异,前测和后测不存在显著性差异。分别对前、中、后测这三个时间点上的数据作多重测量方差分析,结果发现,前测时三组被试均与母语者差异显著,但彼此间差异不显著,中测时视听组和听觉组分别与母语者差异不显著,但听觉组与视听组(p=0.039)差异显著,后测时视听组与母语者之间差异不显著,但母语组与听觉组(p=0.000),视听组与听觉组 (p = 0.000) 差异显著。
以上结果说明,视听训练可以提高被试焦点音节音域的产出能力,听觉训练在短期内可以看到效果,但经过几天的训练又迅速退步,可见并不能真正提高被试音域的产出能力。对照组没有明显改善效应。
(3)焦点音节相对时长发展变化
焦点音节相对时长z 分数变化趋势如图9所示,总体的趋势为:视听组基本保持不变,听觉组于中测后快速上升,对照组中测上升但后测又回落到较低水平。
对日本被试的数据进行重复测量方差分析,结果发现:视听组内部存在不显著性差异,听觉组前测和后测之间(p=0.043)、中测和后测之间(p=0.038)均存在显著性差异。分别对前、中、后测这三个时间点上的数据作进行重测量方差分析,结果发现,前测时三组被试分别与母语者存在显著差异(p=0.045,p=0.047,p=0.03),中测时视听组与听觉组分别与母语组存在显著性差异(p=0.041,p=0.036),但母语者与对照组之间不存在显著性差异,后测时视听组、对照组分别与母语组存在显著性差异(p=0.036,p=0.043),但母语者与听觉组之间不存在显著性差异。
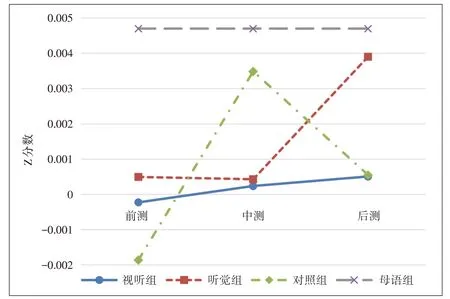
图9:焦点音节相对时长发展变化图
这说明视听训练不能改善学习者的焦点时长,我们推测可能是受音高特征影响,被试关注视点更多在于高音点。听觉组在中测时相对时长延长并在后测时达到了类似母语者的水平,一个可能的原因是他们借助音高来表达焦点的能力有限,需要用时长来弥补,形成补偿机制,这与曹文(2010)的结论相似。对照组在中测时由于掌握了焦点音节时长更长这一理论知识,机械地将音节时长拖长,但在后测时回落显著,不过仍高于前测,这说明延长焦点音节时长对日本学生而言并没有以往研究(史有为,2012)中所认为的那么难。
4.3.3 日本学生反馈分析
图10 为日本学生关于焦点重音产出能力自我评价分数的示意图。横轴为7 度量表分数,纵轴为三个组别。三组被试在试验后的评分均高于训练前,说明视听训练和听觉训练均能提高被试的焦点产出能力,视听训练的效果更优,对照组自我评价得分的小幅增长,主要得益于练习效应和实验前的指导。

图10:日本学生焦点重音产出能力自我评价分数示意图
5.总结和讨论
针对对外汉语教学实践中焦点重音教学困难的问题,本文提出了一套突出语调特征的可视化教学方案,并以日本留学生为被试进行了教学实验,结果表明使用此套方案进行发音训练的试验组学生在正确率上取得了显著改善,表明了该方法的有效性。回应引言中提到的三个问题,下面进行进一步的讨论。
(1)能否基于汉语焦点重音的声学表现设计一套有效的可视化方案?
根据前人研究的结果,汉语焦点重音的声学特征具有“三区段”特征。基于此特征,我们参照Ding(2016)中的语调图示方案,设计了凸显焦点音节高音点、音节时长以及音高落差特点的视觉即时反馈方案,并通过汉语母语者的视觉辨别实验,证明此方案有助于母语者准确判断汉语焦点的位置。
(2)视听训练能否帮助日本学生改善焦点重音的产出?
通过三组被试,我们对比了视听训练、听觉(模仿)训练及无训练三种方式对于焦点重音产出的影响。实验结果表明,无论是视听训练,还是听觉训练,效果都显著好于对照组,这表明两种方法都有助于改善焦点重音的产出。在两种训练方法中,视听训练取得了更高的正确率,表明参加视听训练的被试能够更好地掌握焦点重音正确的产出方式。另外,泛化实验表明改善的产出能力,还可以泛化到新结构的句子中。
(3)基于可视化的视听训练与传统的听觉模仿训练是否存在差异?如果存在那么差异又有什么具体表现?
实验中,两种训练方法都显著改善了焦点重音的产出正确率,由图5 可见,两种训练之后平均错误率下降都超过50%。不过,二者之间也存在程度差异:听觉(模仿)训练的改善为51%,视听训练则为63.5%,视听法的改善效果显得更显著。由图6 泛化测的结果更可见:视听法结果的正确率比听觉(模仿)法高近20%,进一步验证了视听法的优越性。考察训练结果的细节,由图7 和图8 可见:视听法训练对于提升焦点音节高音点和音域范围都持续有效,而听觉(模仿)训练法对于音高这两个关键特征在后期都出现了下降和衰退现象。由图9 的相对时长结果可见:视听组的时长特征几乎没有改善,而听觉组则在后期取得了接近汉语母语者的性能。
针对以上结果原因开展分析,我们认为与以下几种因素有关:视听的多通道性、输入的可理解性、视觉的监控性和选择性注意。首先,视听的多通道性认为多模态(视觉、听觉)的信息有利于促进语音的感知和产出。无论是在视听,还是在听觉(模仿)训练方法中,系统提供的语音及视觉信息在训练过程中都充当了“可理解性输入”(Krashen,1981)的角色,有利于帮助学生加强对于焦点重音声学特征的理解,从而有助于提高产出的正确性。相较于单纯的教师语音线索,直观生动的焦点重音视觉信息更易于学生对于所学对象的理解。正如诸多前人的工作所示,基于多模态信息的视听训练效果往往优于基于单一声学刺激的听觉训练(Massaro,1998;Hardison,2003;Hazan,2005;洪炜,2019)。
其次,虽然在某些前人研究中对于视觉信息的贡献尚有异议(贾琳,2013),但是本文所设计的焦点重音视听训练方法不仅仅为学习者提供了关于焦点重音易于理解的多模态输入信息,更提供了一种针对学习者语音产出正确与否的即时正音反馈信息。如图1 所示,左边提示了教师语音的关键特征,右边则即时描绘学习者的练习语音特征。通过视觉比对,学习者可以获得关于刚才发音质量的主观评价。这样的视觉信息即充当了提醒学生修正发音错误的“监控者”的角色,起到了日渐受二语教学届广泛重视的纠正性反馈的作用(Hossein 2017),正与“监控假说”(Krashen,1981)中“有意识的监控才能使二语者不断地修正、练习从而最终转换为直觉性习得”的观点相符合。
再次,学习者的选择性注意机制可能也在其中发挥了重要的作用。人的一切心理活动都以注意为前提(Kahneman,1973),如果同时给被试呈现多个维度的信息,他们可以选择性地注意其中一个维度。从实验结果来看,视听组被试的选择性注意可能聚焦于焦点音节的音高特征上,而对于表征时长的圆周周长采取了忽视策略。对于听觉组的日语母语学习者而言,母语经验中的时长敏感机制令他们选择性地优先注意焦点音节的时长变化,虽然初期的语音学知识培训令他们注意到焦点音高的特征,但是这一能力随着时间进程逐渐有所退化。
最后,本研究有两点值得注意的地方:(1)实验二的结果与最初的可视化设计的预期不完全相符:可视化图形中,焦点音节高音点和时长均为凸显的视觉信息,但实验二的结果表明视听组被试更关注高音点而忽视时长。这可能是因为视觉通道的信息量较大且彼此间形成注意资源竞争,容易形成高知觉负载(Lavie,1995),在实际听感上较为突出的高音点捕获了被试大部分注意力,时长信息因此被忽视。(2)声学参数结果和听辨结果不完全相符:听辨结果显示听觉组的训练效果在后测时达到最佳,但在声学参数上,仅相对时长与这一结果相符,高音点和音域与之不相符合。这可能是因为停顿的作用,听觉组可能由于难以产出焦点,在焦点前有较长时间的停顿,而这无意中与重音前增加停延边界(曹剑芬,2002)这一规律相符。
6.余论
本研究尚存在不少待改善的空间:1)为了对比视觉信息与听觉信息在焦点重音产出中的作用,更为严谨的做法应是在仅有视觉信息的情况下考察被试的训练效果。2)本研究实验语料均为经过设计的陈述句,但王韫佳等(2006)认为相比自然语料,较为简单的实验句语料可能会掩盖研究问题的复杂程度,以后的研究可以加入适当的自然语料及其他语气的语料。3)在声学参数的选择上,本研究中将焦点音节的高音点作重要衡量指标之一,但有研究认为二声、四声的升幅也是汉语焦点重音的表现(Shih,2000)。以上反思对后续研究应有一定的启发。
