基于嵌入式NLP的铁路车务术语语音识别方法
2020-11-25黄大吉林海香
黄大吉,林海香
(兰州交通大学 自动化与电气工程学院,兰州 730070)
2015年9月至2016年4月,连续发生了3起因车务值班员的操作不熟练而引起的操作违规、列车区间停车、擅自调整调度计划等类事故,为防止此类安全事故的再次发生,2016到2017年,铁总连续发了3个文件,明确提到车站需要配备相应的仿真演练设备,以确保上岗车务值班员素质达标,持证上岗.铁路车务仿真培训系统应运而生,但无论是基本作业还是应急处理,在实际工作中值班员都需要与各个岗位进行语音交互,而现有仿真培训系统中都未能实现语音交互[1-2],语音识别的引入,可以解决这一问题.
但现有的语音识别软件对车务术语的识别准确率不尽人意,例如科大讯飞、百度、中科信利等,并没有针对铁路行业的识别库.文献[3]对比了科大讯飞、Siri、Cortana以及百度的语音识别率得分,Cortana的综合得分最高,科大讯飞的识别率最稳定.本文通过实际测试,运用科大讯飞识别铁路车务专用术语的准确率仅为50%,这远远达不到要求.所以急需研发一种提高铁路车务术语语音识别准确率的方法.
自然语言处理是人工智能的一个分支,使机器像人一样对接收到的语言进行理解并反馈[4-5].近几年来,NLP不断与语音识别(automatic speech recognition,简写为ASR)、语音合成(text to speech,简写为TTS)等语音技术相互结合形成新的研究分支.文献[6]设计了一种基于NLP和ASR的电信业务软件;文献[7]完成了嵌入式人机语音交互系统的研究,把NLP与ASR结合运用到了服务机器人的语音交互;文献[8]则把研究扩展到了智能家居领域.
本文提出一种基于嵌入式NLP的铁路车务术语语音识别方法,运用NLP的方法来提高铁路车务术语的ASR准确率,并将嵌入式设计与传统培训系统相结合,以实现培训人员与仿真系统的语音交互.
1 NLP简述
NLP一般分为词法、句法、语义、语用以及篇章分析[9].第一部分是词法分析,包含去除停止词、中文分词和词性标注;第二部分就是利用从第一部分得出的结果理解出整个句子的框架结构进行句法分析;第三部分是在前两部分的基础上对输入文本的整体意思进行语义分析;语用和篇章分析是在第三部分的基础上利用上下文或者整篇文章进行分析.对自然语言的研究分为开放领域和特定领域,开放领域的研究设定可以解决任何主题的问题,本文研究的是特定领域,即铁路车务用语语音识别后文本的处理,使其满足铁路车务术语并能被系统识别.
随着NLP与ASR的越发成熟,NLP与ASR的两个重要方向是基于PC机的大词汇量识别和嵌入式的自然语言处理,尤其是嵌入式的自然语言处理,渐渐发展到了铁路行业.吴萍等[10]将NLP与ASR应用于火车票查询系统;翁湦元等[11]设计了一种铁路语音识别引导购票系统;潘梁生[12]针对铁路机务部门的“车机联控”,设计了一种列车车载识别系统.但前两者,更多倾向于开放领域的识别,而后者,并未真正实现与列车运行监控装置的联调,其准确率有待进一步考证.
把语音识别引入到了车务仿真培训系统中,但仅仅使用语音识别不能解决铁路车务专业术语的识别率问题.针对现有车务仿真培训系统对标准用语的语音识别准确率低的问题,本文提出了一种基于嵌入式NLP的车务术语ASR方法,将NLP与ASR、TTS等语音技术应用到铁路车务仿真培训系统的语音交互中,其整体流程如图1所示.
车务值班员输入语音,通过无线传输至科大讯飞云识别转化为文字信息,然后经过分词,把句子切分为一个个词串;接着进行铁路专有词处理,生成符合铁路标准用语的词串信息;然后通过语义分析,转化为标准的词义块后输入计算机识别;最后结合TTS技术播放出来,完成语音交互.
2 嵌入式NLP算法
2.1 嵌入式技术
为了与传统车务仿真培训系统更好地结合,运用嵌入式技术,设计了运用NLP算法的车务仿真调度电话,该调度电话能直接与传统仿真培训系统相连接,节约了成本.
以飞凌OK6410开发板为基础搭建硬件平台,结合Intel Loihi547文本处理芯片进行自然语言处理,配上SYN6288语音播放芯片实现语音合成.OK6410开发板采用ARM11系列的S3C6410微处理器,提供了飞凌FIT-LCD4.3 LCD显示屏、256MByte的RAM、2GByte的ROM、音频接口、声卡模块、TTL电平和RS232电平的串口,支持Nand-flash和SD卡两种启动方式[13].硬件平台结构如图2所示,语音识别模块、自然语言处理模块、语音合成模块共同完成了系统的语音交互功能.
2.2 分词与纠错算法
1) 基于词典的改进正向最大匹配分词算法
分词是NLP的基础,提高分词的正确性与效率至关重要.研究表明[14],在非限定性领域,正向最大匹配的错误率仅为0.5%,而应用到铁路行业内,其正确率将大幅提高,所以本文提出一种hash函数结合正向最大匹配的分词算法,提高了分词效率.
本文应用于铁路车务场景,为减少停止词的数量,建立一个专用于此场景的词典.结合《铁路技术管理规程》、《铁路行车组织规则》以及收集到的车务培训系统中的规范语的正确与错误语料,收录了包含举例车站名称、专有名词等在内的2 000个词,存入文本文档中.为了便于词与词各种属性的查询,把文本中的词存于内存中,即词库的初始化.
定义数组dictionary[]和hash[],前者用来存放所有的词,后者用来存放key值相同的词,即只要key值相同的词都存放于相同的数组hash[key]中.具体流程:
① 获取词库中词的首字w和长度L;
② 用MD5算法计算w对应的MD5值,得出value值,即
value=MD5(w)+L;
(1)
③ 定义哈希函数key=value%n,由于本文词库规模相对较小,取n=300;
④ 将词的key值存储到相应的hash[key]中,并重复上述过程,直到所有的词都存储在hash[]中.
初始化结果如图3所示,其中:hash[i]表示第i个数组;Cij、Sij分别表示hash[i]中的第j个词及其属性.
通过以上的初始化,所有首字相同且字数相同的词都被存储在同一链表中,能快速定位关键词,这样有利于缩短算法的运行时间.改进的分词算法基本原理如图4所示,具体过程如下:
a. 定义输入:带切分的字串T,最大词长L;输出:切分后的字串T’;
b. 令P指向T首部,T’初始化为空;
c. 计算length为P至T尾部的长度,如果length=0则至h,反之则下一步;
d. 在dictionary[]中搜索以P为首字的词,如果搜索不到则将后移一位P,返回c,反之则下一步;
e. 设置最大词长为L,当length的值大于L时,赋值length=L;
f. 在P后提取长度为length的字符串t;
g. 计算P指向的首字和长度为length的key值,在hash[key]对应链表中查找字符串t,如果存在则在T’中添加t并赋予词性,同时P后移length的长度,返回步骤b;否则令length减一,在P后提取长度为length的字串t,重复步骤g,直到length=0时,将P后移1个单位,返回c;
h. 返回切分后得到的字串T’.
2) 铁路专有词纠错
引入识别可信度概念,定义百分百正确识别的词的可信度为1,百分百错误识别的词的可信度为0,可信度的范围为0~1,其具体值为识别正确的次数与总的识别次数的比值.通过统计现有的语音识别软件对车务值班员口呼信息的输出结果,可以得到比较正确的语句与大量错误的训练语句,例如:原文为“兰州西站,6道轨区段出现红光带,影响D1402次接车”,科大讯飞识别结果为“兰州西站,6导轨/捣鬼/岛柜区段出现虹光/宏光/鸿光带,影响动1402次接车/街车/借车”.从中可以发现大都是专业词汇或者平时交流中不常用的词出现错误,例如:“兰州西站”、“出现”、“区段”、“影响”、“次”的识别率较高,而“道轨”、“红光带”、“动”、“接车”等专业词汇或者需要特殊转换的词的识别率极低.考虑到铁路领域标准用词的有限性,根据语音识别结果,人为挑选识别率高的词,其可信度均为1,识别率低的词和其他词,其可信度均为0.例如例子中识别结果用可信度表示为11,10110,10111110.由此,只对可信度为0的词进行查错和纠错.
纠错框架如图5所示,创立一个铁路专用词汇列表库,其包含5个数据库:上下词模式库、边界词库、正确词汇库、错误词汇库以及对比词汇库.采用模式匹配的方法对可信度为0的词进行纠错,具体步骤为:
a. 通过训练识别后的文本和标准文本,形成纠正词汇库(正确词汇库、错误词汇库和对比词汇库)和替换词汇库(上下词模式库和边界词库).
b. 对于铁路专用术语,例如“红光带”、“道岔”等,匹配纠正词汇库,然后根据三个词汇库之间的映射关系,保留正确词,纠正错误词.
c. 对于特殊替换词,例如车次号中的“D”、“Z”等以及“道轨”应为“DG”等,继续匹配替换词汇库,例如“动”的右边界词为数字,则替换为“D”.
2.3 语义识别
语义分析旨在系统考核,考核值班员与其他岗位的语音交互信息操作流程是否满足标准.现有的语义分析有概念从属理论和模板匹配语义分析两种[15].概念从属理论认为只要表达的语义相同即为正确,无论表达方式几何,其由有限语义块组成的语义表达式只有一个;模板匹配语义分析是对关键信息进行抽取来理解语义.本文运用模板匹配语义分析,实现系统识别.
经过分词和纠错流程得到带有词性标注的词串,并得到一个词的上下词词性与边界词性,系统运用模板匹配语义分析,直接抽取关键词信息进行考核评判即可.例如,值班员口呼“6DG区段出现红光带”,系统只要能抽取到“6DG”和“红光带”,即系统认为值班员口呼正确.
3 实验测试与对比分析
下文中所涉及到的实验指标[16]正确率P、召回率R和综合评价指标F1值定义如下:
(2)
(3)
(4)
其中:N1表示实际正确识别的个数;N2表示总的个数;N3表示系统认为正确识别的个数.
由于铁路车务术语的语料库规模较小,本文测试时采用交叉验证的方法使训练语料达到最大化.不区分训练集和测试集,把500句样本随机分为50份,每份10句样本,测试时把其中一份作为测试样本,其他为训练样本,统计各组的正确率P、召回率R和F1值.
3.1 准确率测试
图6为各系统识别的P、R、F1的总体分布图.由图6(a)和图6(b)可知百度和科大讯飞的识别分布大都集中在45%~55%,科大讯飞的分布更为紧密,且比百度语音在更小的区间有较少的分布,说明虽然其两者识别准确率差不多,但是科大讯飞识别时有较少的语料没有被识别出来,识别性更加稳定,这也是本文选取科大讯飞的识别结果作为系统输入的原因.从图6(c)可以看出,传统的结合了语音识别的仿真系统虽然准确率有所提高,集中分布在60%~70%,但和百度语音识别存在相同的问题,即分布松散、在更小的区间有较多的分布,造成有较多的语料没有被识别出来.图6(d)为本文研究的系统,准确率有了极大的提高,集中分布在了90%~95%的区间,减少了未被识别的语料的数量,具体的识别结果见表1.
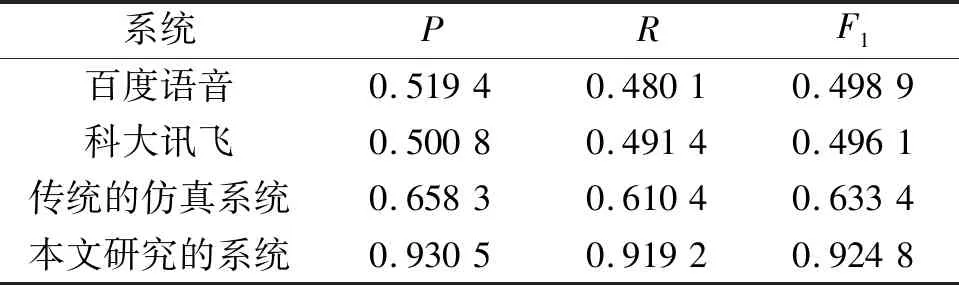
表1 各系统具体识别结果Tab.1 Specific identification results of each system
3.2 运行时间测试
从语料库中随机选出20组来进行运行时间的测试,同时确保每组的总字数大似接近.对这20组数据分别用正向最大匹配分词算法和本文改进的分词算法进行分词,得出每组中每条语句的运行时间,再计算平均时间,得到的结果如图7所示.
由图7可知,改进的正向最大匹配分词算法缩短了近50%的运行时间,其中第7、9、11组运行时间较短,通过对比语料进行分析可得这3组中停止词较少,因为未改进的分词算法出现一次停止词,就要遍历一次词库而进行不必要的运算,而改进的正向最大匹配分词算法,利用hash结合正向最大匹配只运算一次就将停止词去除,提高了算法运行时间.对比加入人工自定义词典后,除第2组和第8组略高外,总体运行效率进一步提高,原因在于本文自定义词典时,结合了收集到的车务培训系统中规范语的正确与错误语料后,进一步减少了停止词,缩短了运行时间.
4 案例应用
将基于嵌入式NLP的铁路车务术语语音识别方法运用于哈尔滨南上行发车场道岔区段红光带的接车作业培训.车务培训系统通过TDCS(train dispatching command system)下发调度命令,联锁场景布置,TDCS下发接车命令,值班员收到接车命令排列进路,发现6号道岔区段显示红光带,通过调度电话,向助理值班员通话检查6DG红光带.接着值班员与电务、工务通话,分析6DG区段红光带的原因,并给出应急处理,系统实时记录值班员操作记录与语音交互信息,最后系统判分,给出培训建议,系统截图如图8所示.
对比现有的仅加入了语音识别的车务仿真培训系统,从图9中看到,传统系统语音识别为“6导轨区段出现宏光带”,出现了“导轨”和“宏光”这两个不符铁路术语的词,而本系统通过自然语言处理后识别为“6DG区段出现红光带”,可以看到,不仅把“导轨”和“宏光”这两个词正确识别了,还把“道轨”替换为了“DG”,更加符合铁路标准用语.
运用本文方法的车务仿真调度电话系统已在哈尔滨、西安、成都等多个车站的职教中心投入使用.主要用于车务值班员、助理值班员、信号员等岗位培训,在部分车站作为选拔车务作业岗位人员的辅助系统.
5 结论
针对应用于非特定行业的语音识别软件对铁路车务术语识别准确率低的问题,本文提出了一种基于自然语言处理的车务术语语音识别方法,通过实验分析,得出以下结论:
1) 该方法以科大讯飞云识别的识别结果为输入,经过改进的分词算法、车务术语库纠错以及模板匹配的语义分析,输出最后结果,并将嵌入式设计直接与传统系统结合,节约了成本.
2) 相比于传统的带语音识别系统63.34%的识别率,运用本文方法的系统则为92.48%,识别率提高了29.14%.
3) 提出改进的正向最大匹配分词算法,利用hash结合正向最大匹配只遍历一次就将停止词去除,提高了算法运行时间.
由于本文的语料规模较小,需要不断地扩充具有广泛代表性的语料库,进而提出更高效的标注方法.
