融合评分矩阵和评论文本的Deep-FRR评分预测模型
2020-11-25陈佳兴
侯 越,谢 斌,陈佳兴
(兰州交通大学 电子与信息工程学院,兰州 730070)
推荐系统已经广泛的应用于电子商务、视听娱乐、社交网络和新闻门户中,并且取得了极大的成功[1].协同过滤算法是推荐系统常用的技术手段,该算法通过用户-项目评分矩阵计算用户、项目间的相似度为用户进行推荐.随着互联网技术的飞速发展,推荐系统的用户和项目数量呈现指数级增长,用户打分项目不足项目总数的1%,致使评分矩阵极其稀疏,相似度计算趋于困难,使得推荐系统质量急剧下降.为缓解评分矩阵的稀疏性问题,研究人员提出了许多基于评分预测的推荐模型来填充评分矩阵.文献[2]提出一种基于矩阵分解(matrix factorization,简写为MF)的协同过滤方法,将每个用户和项目分别映射成两个隐含因子向量,以两向量的内积作为用户对项目的预测评分.为提升模型的性能,基于矩阵分解的改进模型相继出现.文献[3]提出一种基于概率论图模型(probabilistic matrix factorization,简写为PMF)的矩阵分解改进方法,该模型假设用户对项目的评分满足正态分布,通过最大似然估计来优化用户、项目的隐含因子矩阵,取得了较好的效果.
近年来,随着深度学习在自然语言处理、计算机视觉等领域的长足进步,许多学者开始将深度神经网络应用于推荐系统.文献[4-5]提出一种深度矩阵分解(deep matrix factorization,简写为DMF)模型,该模型将用户和项目的隐含因子向量输入神经网络得到预测评分.与传统矩阵分解模型相比,深度矩阵分解模型可以更好地学习到用户和项目间的非线性关系.文献[6-8]提出一种利用受限玻尔兹曼机(restricted boltzmann machine,简写为RBM)的方法解决评分矩阵的稀疏性问题,文献[9-10]采用自编码机(auto-encoders,简写为AES)的方法,通过用户-项目评分矩阵建模进行评分预测.
除了用户对项目的评分外,评论文本也包含了用户对项目的喜爱程度及项目自身的属性特征,因此,一些基于评论文本特征提取的评分预测模型被相继提出.文献[11]提出利用潜狄利克雷模型(latent dirichlet allocation,简写为LDA)提取评论数据集中用户和项目的隐含语义特征来进行评分预测的思路,文献[12]使用卷积神经网络(convolutional neural networks,简写为CNN)提取项目描述的文本特征,并结合PMF模型进行评分预测,但该方法仅考虑了项目的评论文本,却忽略了用户的评论文本.文献[13]提出一种Deep-CoNN(deep cooperative neural network)模型,该模型通过两个并行的CNN网络分别提取用户评论文本和项目评论文本的特征,并将这两个特征表示成低维向量,通过隐因子分解机来进行评分预测.
但既有的基于评论文本特征提取的评分预测模型仅考虑了评论文本本身,却没有充分挖掘评分矩阵中用户、项目隐含因子间的交互关系.基于此,提出一种融合了用户-项目评分矩阵和评论文本的深度学习评分预测模型(deep fusion of rating matrix and review text,Deep-FRR),其中,矩阵分解模块和深度矩阵分解模块用于提取用户和项目间的线性和非线性交互关系,卷积神经网络模块用于提取用户和项目评论文本中的潜在语义特征,然后在融合层实现三模块的融合,并通过全连接层进行评分预测.最后,采用五个亚马逊的公开数据集对本文的Deep-FRR模型和其它评分预测模型进行对比实验,并详细分析Deep-FRR模型的隐含因子数、词向量初始化方式对预测性能的影响.
1 Deep-FRR模型结构设计
将不同的深度学习模型进行融合可使融合模型拥有子模型各自的优点,从而提高模型性能.鉴于此,本文融合传统矩阵分解模块、深度矩阵分解模块、卷积神经网络模块,提出一种融合用户-项目评分矩阵和评论文本的评分预测模型Deep-FRR,其模型结构如图1所示,该模型采用矩阵分解模块和深度矩阵分解模块对用户和项目间的线性和非线性关系进行建模,同时使用卷积神经网络模块提取了用户评论文本和项目评论文本的语义特征,然后将评论特征向量、线性和非线性特征向量进行融合,最后通过全连接层进行评分预测.
1.1 矩阵分解模块
给定一个用户-项目评分矩阵R,矩阵分解的目标是将R近似分解成两个隐含因子矩阵PN×K和QM×K的乘积,即R≈PTQ,其中:N表示用户数量;M表示项目数量;K代表隐含因子数目.假设有3个用户和4个项目,且隐含因子向量的维度为3,则矩阵分解过程可用图2表示.
通过矩阵分解,每个用户u和项目i可以分别用一个K维的隐含因子向量pu和qi表示,则用户u对项目i的预测评分被表示为对应隐含因子向量的内积,即
(1)
然后通过随机梯度下降法最小化式(2)的损失函数来分别求解隐含因子矩阵.
(2)
其中:rui表示用户u和项目i的真实评分;λ1和λ2分别表示用户隐含因子向量pu和项目隐含因子向量qi的正则化系数;Iui是指示函数,如果用户u对项目i有评分,则Iui=1,否则Iui=0.
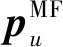
(3)
式中:⊙符号表示将两个向量求内积.
1.2 深度矩阵分解模块

(4)
式(4)中,令z0=f(pu,qi)=pu⊕qi,表示将两个K维向量拼接成一个2K维向量,然后将z0输入h层神经网络σ1,σ2,…,σh,wh代表第h层神经网络的权重,bh代表第h层的偏置,ah代表第h层的激活函数,这里使用ReLu激活函数,具体过程如下:
(5)
1.3 卷积神经网络模块
Deep-FRR模型利用图3所示的两个并行的卷积神经网络分别从用户评论文本和项目评论文本中提取了用户u和项目i的评论文本特征[15],由于两个卷积神经网络对评论文本的处理方法相同,下面仅对提取用户u的评论文本特征的过程进行说明.
对每个用户u,把他所有的j条评论组成一个评论集合Du={du1,du2,…,duj},然后对Du进行去停用词、分词处理,再通过word2vec[16]技术将Du映射成n×k的词向量矩阵Cn×k,并将此词向量矩阵Cn×k作为卷积神经网络输入层的输入,其中:n表示评论集Du中的单词数;k表示词向量的维度.
然后,卷积层通过大小为h×k的滤波器以步长1自上而下滑动来提取词向量矩阵Cn×k的局部特征,如式(6)所示.
ci=f(ω·xi∶i+h-1+b),
(6)
其中:f是ReLU函数;ω代表卷积核;xi∶x+h-1代表Cn×k中从i到i+h-1共h行词向量;b是偏置项.通过卷积层,最终得到词向量矩阵Cn×k的局部特征矩阵C=[c1,c2,…,cn-h+1].
对卷积层之后得到的局部特征矩阵采用最大池化的方法,用最大特征代替局部特征,得到局部特征的最优解oi:
oi=max{c1,c2,…,cn-h+1}.
(7)
之后,将所有局部特征的最优解拼接起来得到用户u的评论文本局部特征表达Ou=[o1,o2,…,on].
将Ou输入全连接层,得到用户u的评论文本特征向量du:
du=wu·Ou+bu,
(8)
其中:wu表示全连接层的权重;bu代表全连接层的偏置项.

(9)
1.4 融合层
(10)
(11)
其中,w和b分别表示全连接层的权重与偏置.
2 实验设计
2.1 实验数据与实验平台
在亚马逊的5个商品评论数据集上进行实验,数据集的基本情况如表1所列.由表1可知,5个所选数据集全部为高稀疏程度数据集,符合模型所需实验要求.实验所用平台为Windows10 64位系统,Intel-i5 CPU,16GByte内存,开发环境为python3.6,并使用了Keras 2.2.4深度学习框架.

表1 亚马逊商品评论数据集Tab.1 Amazon product review dataset
2.2 实验参数设置
模型参数选取的好坏直接影响评分预测精度,经多次实验验证,表2中各类模型参数设置能显著提升模型预测性能.

表2 模型参数设置Tab.2 Parameter setting
2.3 评价指标
实验采用均方误差(mean-square error,简写为MSE)作为评价指标,MSE越小代表模型的性能越好,MSE的计算公式如下:
(12)
其中:T代表测试集样本数.
2.4 对比实验模型
将提出的Deep-FRR模型与下列评分预测模型进行对比实验:
1) MF:矩阵分解模型.
2) PMF:概率矩阵法分解模型.
3) DMF:深度矩阵分解模型.
4) Deep-CoNN:采用了两个CNN网络分别提取用户评论文本和项目评论文本的特征来预测评分的模型.
表3为不同模型间的对比,√表示模型使用了该项,×表示模型未使用该项.由表3可知,MF模型和PMF模型仅使用了评分矩阵,而DMF在使用了评分矩阵的基础上,采用了神经网络进行建模,Deep-CoNN模型仅使用了评论文本,而模型Deep-FRR同时使用了评分矩阵和评论文本作为神经网络模型的输入.

表3 不同模型对比Tab.3 Comparison of different models
3 模型精度分析
实验选择80%的数据集样本作为训练集,用剩余20%的数据集样本作为测试集,通过表4中的参数分析,将隐含因子数K设为75,词向量初始化方式设为GloVe-Trained,上述模型在测试集上的MSE对比结果如表5所列.从相对提升百分比来看,同一数据集上Deep-FRR模型的MSE较其他最优预测模型提升明显.
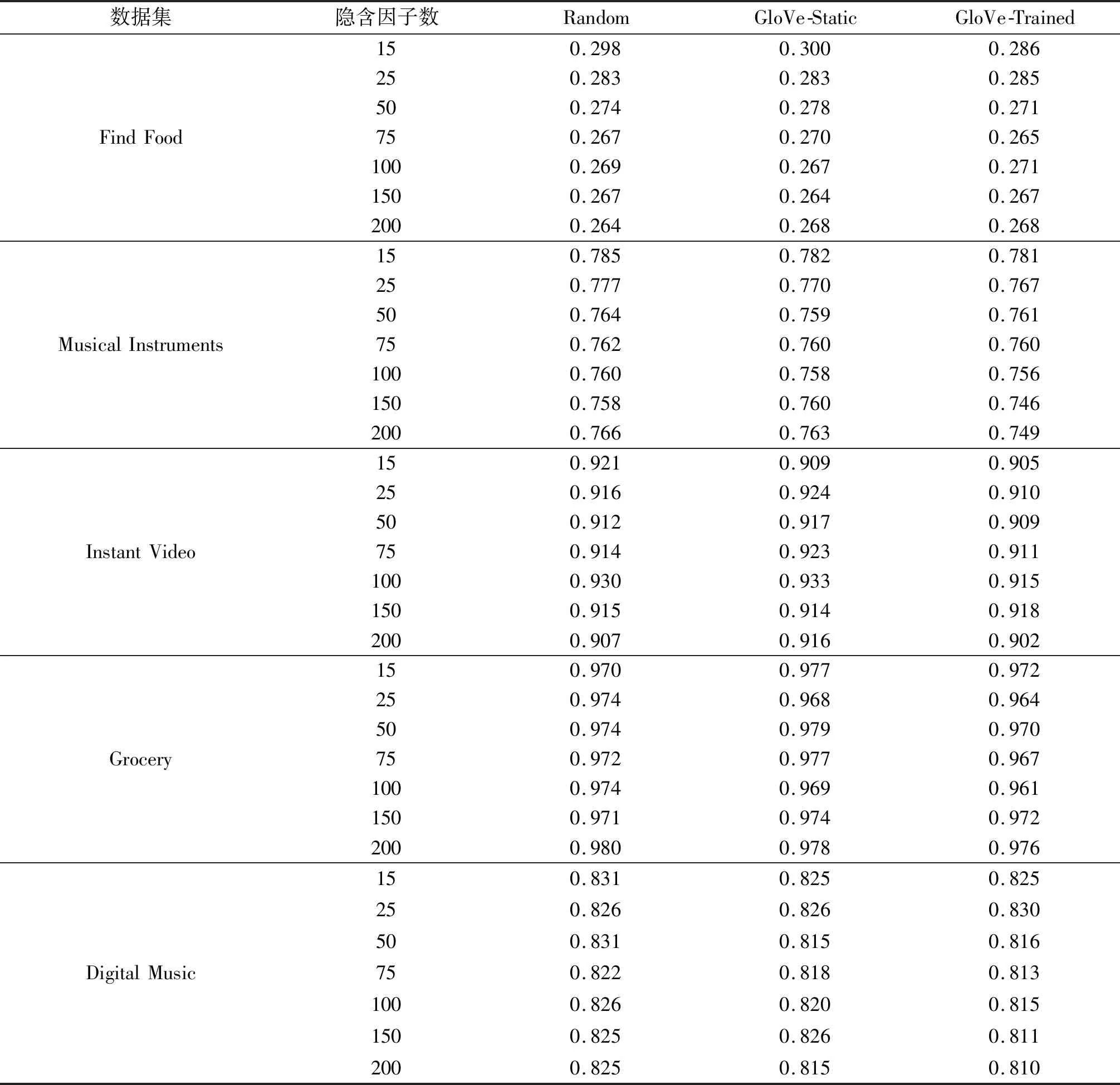
表4 不同参数实验结果Tab.4 Experimental results under different parameters
从与其它模型的比较来看:基于神经网络的预测模型如DMF、Deep-CoNN的预测精度均高于MF模型和PMF模型,说明采用了神经网络的预测模型拥有更强的非线性拟合能力;基于用户和项目评论文本特征提取的Deep-CoNN模型在测试集上的表现优于仅使用项目评分矩阵的模型MF、PMF和DMF,而本文提出的融合了项目评分矩阵及项目和用户评论文本的Deep-FRR模型在测试集上的预测精度均高于上述模型,且相对于Deep-CoNN模型的提升最高可达14%,说明Deep-FRR模型可以同时学习到用户-项目间的线性和非线性交互关系以及用户评论文本和项目评论文本中的语义表达.
4 Deep-FRR模型影响因子分析
由模型训练过程可知,隐含因子数和词向量初始化方法分别影响着Deep-FRR模型矩阵分解模块和文本特征提取模块的性能,为研究这两个关键参数对Deep-FRR模型性能的综合影响,选择不同的隐含因子数和词向量初始化方法在5个数据集上进行多次实验,其中隐含因子数从{15,25,50,75,100,150,200}中选择.词向量的初始化方法有以下三种:
1) Random:随机初始化每个词的词向量,然后通过后续的训练去动态的调整.
2) GloVe-Static:使用GloVe预训练的词向量,在训练过程中不再调整该词向量.
3) GloVe-Trained:使用GloVe预训练的词向量,并且在后续训练模型的过程中不断自动调整.
4.1 词向量影响分析
表5是不同参数条件下,Deep-FRR模型在5个数据集上的预测精度对比.由表5可知,在不同隐含因子数下,使用预训练词向量GloVe-Static和GloVe-Trained的模型,总体性能优于使用随机初始化词向量的模型,说明在数据集稀疏的情况下,使用预训练词向量,可以更好地挖掘评论文本中隐含语义特征.而使用了GloVe-Trained的模型综合表现要优于使用GloVe-Static的模型,说明在使用预训练词向量之后再根据数据集自身的特点进行动态的微调,可以使模型获得更好的性能.

表5 不同模型的实验结果Tab.5 Experimental results of different models
4.2 隐含因子数影响分析
为分析隐含因子数对模型性能的影响,根据上述结论选择了GloVe-Trained方式初始化词向量,并比较不同隐含因子数下Deep-FRR模型在5个数据集上的预测精度差异,其结果如图4所示.
由图4可知,随着隐含因子数的增加,除Instant Video数据集之外,Deep-FRR模型在其它4个数据集上的MSE整体呈下降趋势,因为Instant Video数据集中用户数和物品数目很少,所以在隐含因子数较小的情况下能够学习到用户和物品之间的交互关系.由于太多的隐含因子数目会使模型的参数数量增多,在训练时会消耗更多的计算机资源,因此,经过综合考虑,在实验中将隐含因子数设为75较为合适.
5 结论
提出了一种融合用户-项目评分矩阵和评分文本的Deep-FRR评分预测模型,该模型可同时学习用户-项目间的线性、非线性交互关系及用户、项目评论文本中的语义特征表达.实验结果表明,本文Deep-FRR模型具有更低的预测误差,选取隐含因子数75和GloVe-Trained词向量初始化方法能有效提升预测精度.鉴于机器硬件性能受限等原因,本次实验在模型文本处理模块仅选择了部分评论文本进行了特征提取,而没有采用全部评论文本,因此,未来将在机器性能提升的条件下在更大数量的文本数据集上进行实验,以进一步提升模型的预测精度和性能.
