引入局部向量点积密度的数据流离群点快速检测算法
2020-11-14毛亚琼田立勤毛亚萍王志刚
毛亚琼,田立勤,2,王 艳,毛亚萍,王志刚
(1.青海师范大学 计算机学院,西宁 810008; 2.华北科技学院 计算机学院,北京 065201; 3.青海省基础测绘院,西宁 810000)
0 概述
在离群数据中可能隐含有价值的知识,并且其价值甚至可能超过正常数据,因此,离群点检测(也称为异常点检测)是数据挖掘领域一项重要的研究课题。离群点检测最主要的目的是检测数据集中不满足数据一般行为或模式的数据对象[1],其被广泛应用于网络入侵检测、WSN异常检测、医疗与电网监控[2]等领域。目前传统的离群点检测技术有基于统计、基于深度、基于距离、基于聚类、基于密度、基于分类等多种方法[3]。随着模式识别、机器学习和人工智能技术的不断发展,空间数据、高维数据以及时间序列数据的离群点检测被研究者关注,更多新颖且有效的离群点检测方法被提出,如基于密度偏倚抽样的离群点检测方法[4]、基于分区的离群点检测方法[5]、基于角度分布的离群点检测方法[6]、基于向量点积密度的离群点检测方法[7]、结合模糊粗糙集的检测技术以及结合自组织映射方法的离群点检测技术[8]等。
随着物联网技术的兴起,数据量和维度均呈上升趋势,高速、无限且动态的高维数据流在许多领域产生,同时数据流中数据的分布特征也随时间动态变化。这些特征要求数据流离群挖掘算法在有限内存下检测时仅能用一次或较少次数遍历数据,而传统针对静态数据集的方法需要多次扫描数据集才能完成检测,很难扩展到数据流的离群点挖掘[9]。现有的一些针对数据流的检测方法[10-12]由于“维度灾难”问题而对高维数据流的检测效果欠佳。基于角度[13]和基于局部向量点积密度的算法在高维空间中比基于距离的方法更稳定,但计算复杂度高达O(d2n2)甚至O(d2n3)(d为维度,n为数据点个数),计算开销太大。因此,提高高维数据流离群点检测的准确性和计算效率是当前研究的热点。
本文提出一种引入局部向量点积密度的数据流离群点快速检测(Fast outlier detection in data stream with Local Density of Vector dot Product,FASTLDVP)算法。当滑动窗口内有数据更新时,设计一种增量算法,在原有计算结果的基础上,只对受到影响的数据点进行增量更新,从而避免对全部数据点进行重新计算。此外,还设计2种优化策略和1条剪枝规则来减少r-邻域更新时窗口内各点之间距离计算的次数。本文拟通过设计FASTLDVP算法,以较小的计算代价达到与LDVP-OD算法相同的检测效果。
1 相关工作
文献[14]针对静态环境提出一种基于密度的局部离群点检测算法,其通过引入局部异常因子(Local Outlier Factor,LOF)表示每个数据对象的局部异常程度,即数据点的异常程度与其一定范围内邻居(kdist-邻域内的点)分布有关,kdist-邻域密度越大,该点成为离群点的可能性越小。算法中最耗时的是数据集中各数据点之间距离的计算,复杂度为O(d2n2)。文献[15]通过引入滑动窗口的思想提出n-INCLOF算法,仅更新当前滑动窗口内受影响数据点的LOF值。文献[16]提出一种基于加权聚类的数据流离群点检测算法。该算法对数据流的数据分布特征适应性较强,准确度较高,但是阈值设定较多,可能会对算法的有效性产生较大影响。上述算法能适应分布复杂的数据流,但是当数据流的维度或者kdist值不断增大时,需要进行大量的数据点之间距离的计算。
研究表明,在高维空间中角度比距离更加稳定[17]。文献[6] 引入角度方差异常因子(Angle-based Outlier Factor,ABOF)的概念,提出一种基于角度的离群点检测(Angle-based Outlier Detection,ABOD)算法。文献[13]将ABOD算法扩展至动态数据流应用中,提出基于角度的数据流离群点快速检测算法FASTDSABOD,其通过增量计算的方法动态更新每个数据点的ABOF,从而将时间复杂度从O(d2n3)降至O(d2n2)。虽然复杂度有所下降,但是其在有限的内存空间中依然无法处理大规模的数据集,并且对数据分布不规则的数据集识别效果欠佳。文献[18]在ABOD算法的基础上提出一种随机投影技术和乘积域AMS Sketch相结合的近似估计角度方差的方法FastVOA。该方法计算复杂度近似线性,但没有考虑任何权重因素的近似理解,虽然降低了计算复杂度,但是不能保证离群检测结果的准确性。
文献[7]提出度量数据离群程度的局部向量点积密度算法LDVP-OD。该算法同时结合密度、距离和角度的离群度量方式的优点,在数据流离群点检测上有较高的准确性,但存在计算复杂度过高的问题(复杂度为O(d2n2))。
现有数据流局部离群点检测方法的主要区别在于离群程度度量方法和r-邻域确定方法的差异[19]。上述算法均存在对索引数据结构及邻域方法存在依赖性、重复计算和检测结果准确性依赖于参数设定和计算复杂度过高的问题,难以保证较高的运行效率。本文算法的改进主要是优化邻域的确定方法和离群因子的计算方法。
2 预备知识

定义1[7]r-邻域(r-neighborhood)
Dd中数据点o的r-邻域由与o点之间距离小于r的数据点组成,即:
Nr(o)={o′∈Dd|dist(o,o′)≤r}
(1)
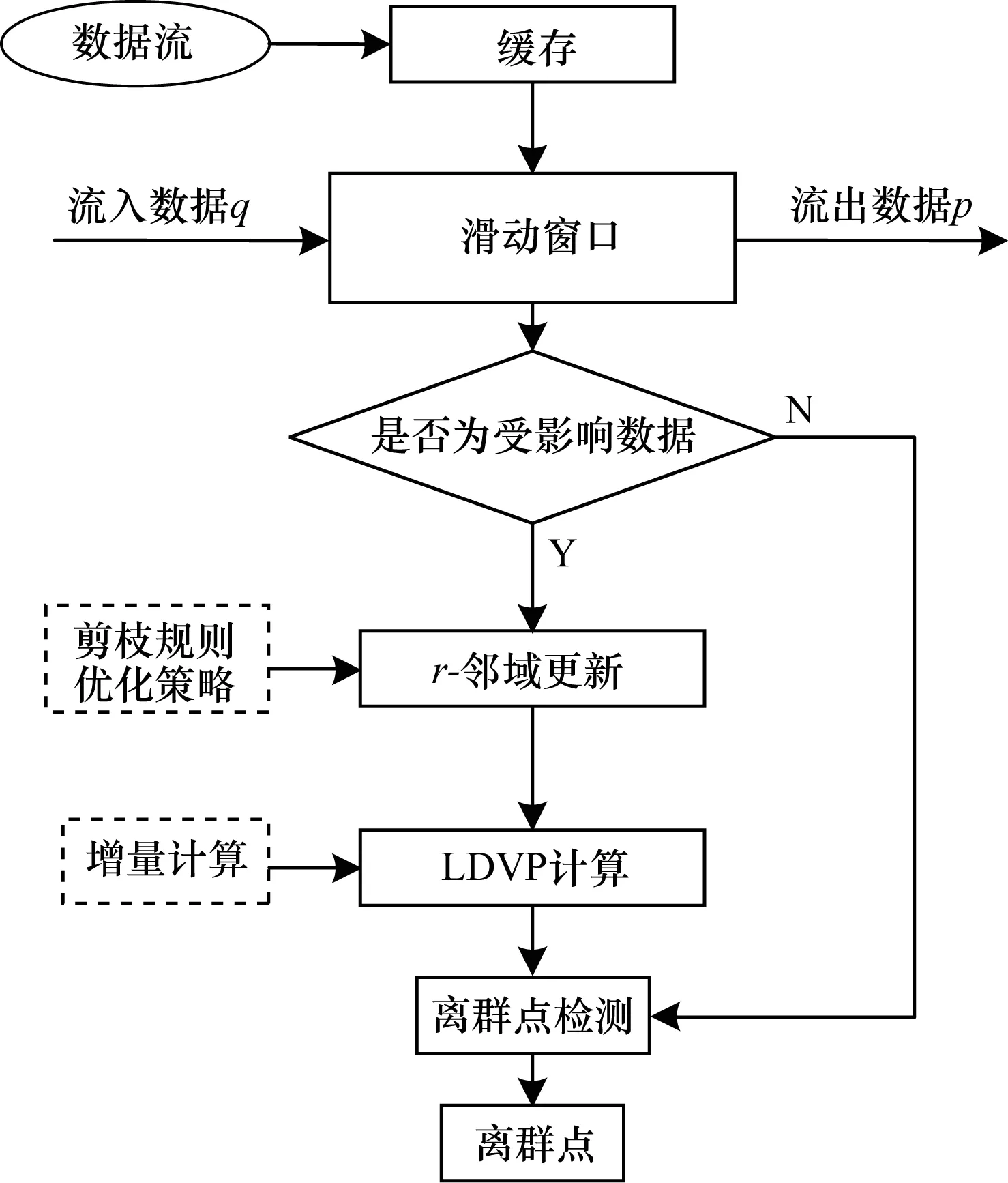
本文运用基于斜率和最大距离的思想,实时确定滑动窗口中数据点邻域半径的值。设kdist为数据点o与其第k个最近邻点的距离,所有数据点的kdist降序排列,取“谷底点”对应的kdist为邻域半径r,在一般情况下,k确定为4。当滑动窗口向前移动时,旧数据移除同时新数据流入,滑动窗口内数据点的邻域半径r变为r′,r′相对于r会出现r′>r、r′ 定义2[7]向量点积均值(Mean of Vector dot Product,MVP) (2) 定义3[7]局部向量点积密度(LDVP) 数据点o的局部向量点积密度定义为: (3) 在LDVP-OD算法中,每个数据点的LDVP值都与所处的r-邻域有关,当滑动窗口向前移动一位,旧的数据点被移除,新的数据点流入,窗口内数据点的r-邻域就会发生变化,相关数据点的异常程度也会受到影响。LDVP-OD算法对此的处理方式是:一旦窗口中有数据被移除或者新数据流入,重新查询窗口内所有数据点的r-邻域并重新计算LDVP。然而,由于LDVP的局部特性,滑动窗口的更新只会影响到少数数据点的LDVP值,而不会影响所有数据点的LDVP值。因此,本文提出一种增量算法,只对窗口内受影响数据点的LDVP值进行更新,并且受影响的数据点也不需要代价高昂地重新计算,只需在原有结果(包括r-邻域更新和局部向量点积密度计算)的基础上进行更新查询或累加计算即可。此外,在r-邻域查询时不可避免地会出现大量的距离计算,尤其当数据量很大或数据维度很高时,计算开销很大。为此,本文在r-邻域查询时增加2个优化策略和1条剪枝规则来减少窗口内各点之间距离计算的次数。FASTLDVP算法流程如图1所示。为方便理解,本文将算法分成r-邻域更新和局部向量点积密度LDVP计算两部分分别进行论述。 图1 FASTLDVP算法流程 r-邻域更新的计算量来源于数据点之间的距离计算,本文使用欧式距离作为距离度量的方式。在该阶段,只对滑动窗口内有影响的数据点进行增量更新,并且使用2种优化策略缩小数据点邻域查询的范围,使用1个剪枝规则减少数据点之间距离计算的次数。 3.2.1 相关定义 定义4欧式距离 设d维空间中任意两点o=(o1,o2,…,od),o′=(o′1,o′2,…,o′d),两点间的欧式距离可定义为: (4) 定义5数据向量的模 数据集中每一个数据点映射到空间中可以看作1个d维向量,设o=(o1,o2,…,od)为数据集D中的数据点,则点o的模定义为: (5) 3.2.2 算法描述 以窗口内受影响数据点o为例讨论Nr′(o)的更新,即判断窗口内某点o′(o′∈D)是否属于Nr′(o)(o∈D)。算法主要步骤如下: 步骤1移除旧数据点p对窗口内数据的影响。仅点o的邻域Nr(o)(o∈Nr(p),p∈D)受影响。 步骤2将窗口内已有数据点相互之间的影响分为以下3种情况: 1)当r′>r时,点o更新后的邻域为Nr′(o)=Nr(o)+o′,o′∉Nr(o),o′∈D。利用优化策略1缩小点o′查询范围,同时使用剪枝规则1减小距离计算次数。 优化策略1新增点o′分布在Nr(o)中这些数据点的周围,即o′一定分布在Nr(o)中数据点的邻域内。因此,只需在Nr(o)中数据点的邻域内搜索,即可找到点o邻域新增的数据点。 剪枝规则1由定理1可以得出dist(o,o′)≥|M(o)-M(o′)|,则当|M(o)-M(o′)|>r′时,必定有o′∉Nr′(o),此时可直接对o′剪枝而无需计算dist(o,o′)。只有当|M(o)-M(o′)|≤r′时才需要计算dist(o,o′),通过dist(o,o′)≤r′进一步判断是否属于邻域。对于|M(o)-M(o′)|,M(o)已知,M(o′)可以在数据点o′流入滑动窗口时计算(每个数据点只需计算一次,计算复杂度为O(d2),d< 定理1设d维数据集D中任意两个数据点o、o′,〈·,·〉表示两向量的点积,则o、o′之间的距离dist(o,o′)满足: dist(o,o′)≥|M(o)-M(o′)| (6) 证明: 展开欧氏距离公式(见定义4): 将其代入式(5),得到: 又由: 可得: 因此: dist(o,o′)≥|M(o)-M(o′)| 证毕。 2)当r′ 优化策略2当邻域半径变小时,Nr(o)以外的所有数据点都不可能出现在Nr′(o)内,因此,只需将Nr(o)中满足dist(o,o′)>r′的点o′删除,即为Nr′(o)。 3)当r′=r时,窗口中任何数据点的邻域都不受r′影响。 步骤3新数据q流入时对窗口内数据的影响及自身邻域查询。由于o和q互为邻域,因此更新Nr′(o),o∈D同时可得到Nr′(q)。在距离计算时同样使用剪枝规则1。 r-邻域更新算法代码如下: 输入D,旧数据p,新数据q、r 输出N′r(o) 1.for each o(o∈D) do //步骤1,滑动窗口移除旧数据p 2.for each o∈Nr(p)do 3.N′r(o)←Nr(o)-p 4.N′r(p)←Nr(p)-o 5.end for //步骤2,将窗口内已有点的相互影响分为3种情况 6.if r′>r do//邻域增大 7.for each o′∉Nr(o),o′∈D do 8.if |M(o)-M(o′)|≤r′ do 10.if dist(o,o′)≤r′ do 11.N′r(o)←Nr(o)+o 12.N′r(o′)←Nr(o′)+o//两点互为邻域 13.end if 14.end if 15.end for 16.end if 17.if r′ 18.for each o′∈Nr(o),o′≠o do 19.if |M(o)-M(o′)|>r′ do 20.N′r(o)←Nr(o)-o′ 21.N′r(o′)←Nr(o′)-o//两点互为邻域 22.end if 23.if |M(o)-M(o′)|≤r′ do 25.if dist(o,o′)>r′ do 26.N′r(o)←Nr(o)-o′ 27.N′r(o′)←Nr(o′)-o//两点互为邻域 28.end if 29.end if 30.end for 31.end if 32.if r′=r do//邻域不变 33.nothing need to do 34.end if //步骤3,滑动窗口流入数据点q 35.if |M(o)-M(q)|≤r′ do 37.if dist(o,q)≤r′ do 38.N′r(o)←Nr(o)+q 39.N′r(q)←Nr(q)+o//一个循环,同时可得到新增点//p的邻域 40.end if 41.end if 42.end for 局部向量点积密度(LDVP)计算的过程中存在大量重复计算。本文通过设计一种增量算法,将MVP增量计算公式(见定义6)中重复计算的部分保存为中间结果,方便下次直接使用。该算法并不改变定义2中MVP的计算结果,核心思想是用运算规则的分配率合并同类项来避免重复计算,对计算过程做一种简单而有效的优化。 3.3.1 相关定义及推理 定义6MVP增量计算公式 ACC-MVP(o′)= (7) 其中,pi,pj∈Nr(o){o′},pi≠pj。 推理1增量计算公式ACC-MVP的计算结果与向量点积均值MVP完全等价。 通过给出从MVP公式(定义2)到ACC-MVP公式(定义6)等价的推导过程,可验证此定理,具体如下: 3.3.2 算法描述 表1列出了FASTLDVP算法在连续检测期间用于存储中间结果的数据结构。 表1 增量计算数据结构 将MVP累加计算公式(见定义6)中重复计算部分存储在中间结果数据结构中,如式(8)和式(9)所示: (8) (9) 由此,点o′的向量点积均值通过以下公式计算: (10) 对于邻域内任意点o′的向量点积均值,当邻域内有数据点被删除时,点o′的中间结果只更新与删除点pi有关的计算。同样地,当邻域内有数据点新增时,点o′的中间结果只更新与新增点pj有关的计算。更新中间结果后使用式(10)计算向量点积均值,最后使用定义4对邻域中各数据点的局部向量点积密度进行计算。算法伪代码中没有提及的还有新增点的向量点积密度计算,新增点的计算通过定义2和定义3进行常规计算。FASTLDVP算法代码如下: 输入旧数据pi,新数据pj; 输出LDVP(o) 1.for each o′(o′∈Nr′(o)) 2.if point pideleted from Nr′(o) do 3.tempart1-=(o′k-pjk) 5.end if 6.If point pjinsert into Nr′(o) do 7.tempart1 +=(o′k-pjk) 9.end if 11.LDVP(o)+=e-ACC-EMP(o′) 12.end for 3.4.1r-邻域更新算法复杂度 当v,p,q,p′,q′,d,n′< 3.4.2 LDVP计算算法复杂度 滑动窗口内所有数据点的LDVP计算算法复杂度为O(wn′d)+O(n′2),其中,n′表示邻域内数据点个数,w表示受影响数据点个数。 综上所述,本文利用优化策略缩小受影响数据点邻域查询范围,使得v,p,q,p′,q′,d,w,n′< 理论推导本文算法可以在不影响准确率的情况下提高算法效率。本节主要针对FASTLDVP算法的运行效率,利用3组实验对其进行验证。实验环境为Pentium®Dual-core CPU,主频2.2 GHz,内存4 GB,操作系统为Window7。实验数据包括仿真数据集和真实数据集。算法采用Java语言实现。用文献[20]中所提到的数据集产生方法生成5 000条维度为(10,50,100,200)的仿真数据集,分析算法中剪枝过程对不同维度数据的影响,同时使用真实数据集分析算法中剪枝过程对大数据量数据执行效率的影响,并分别对LDVP-OD[7]、FASTDSABOD[13]以及文献[16]算法的运行效率进行对比。真实数据集选用KDD CPU99数据集中的5×104条数据。为使评估结果更准确可信,对FASTLDVP算法的实验结果取100次运行结果的均值。 本组实验主要探讨r-邻域更新环节中增加的优化策略和剪枝策略(简称剪枝)对算法带来的影响。实验对比了相同维度不同数据量,以及相同数据量不同维度的数据在增加剪枝过程前后FASTLDVP算法执行效率的变化情况。 如图2所示,在相同维度(d=15)不同数据量的情况下,数据量较小时剪枝前后算法运行时间相差不大,但随着数据量大规模增大,剪枝后算法的运行时间远少于剪枝前算法的运行时间。 图2 FASTLDVP相同维度不同数据量下剪枝前后的运行时间 如图3所示,在相同数据量(n=5 000)不同维度的情况下,剪枝前维度较小算法执行速度快,随着维度增加,距离计算量增加,算法执行效率降低。增加剪枝后,由于剪枝了大量不必要的距离计算,因此运行效率得到提高。 图3 FASTLDVP相同数据量不同维度下剪枝前后的运行时间 FASTLDVP算法与LDVP-OD、FASTDSABOD、文献[16]算法在不同数据量下的运行时间对比如图4所示。 图4 4种算法的运行时间对比 图4结果表明,当数据量较小时,FASTLDVP算法和其他算法的运行效率相差不大,但是随着数据量的大规模增加,FASTLDVP算法的运行效率逐渐高于LDVP-OD和FASTDSABOD算法。FASTDSABOD与LDVP-OD算法的运行时间更多地消耗在数据点间的距离计算以及复杂公式的重复计算上。FASTLDVP算法由于只计算受影响数据点,且增加了数据剪枝环节,因此避免了不必要的距离计算和向量点积计算,从而大幅降低了计算复杂度,并且较LDVP-OD和FASTDSABOD算法,这种优势将随数据量的增加而表现得更明显。FASTLDVP和文献[16]算法运行时间相近,并且随着数据规模的增大,运行时间的增长也较为相近。但在不同数据规模下,文献[16]算法的运行效率略高于FASTLDVP算法。 本文提出一种针对动态数据流的离群点检测算法FASTLDVP。利用局部离群检测的特点,设计一种增量计算方法,只对受影响数据点进行增量更新,同时通过优化策略和剪枝规则减少邻域查询时数据点之间距离计算的复杂度。理论分析和实验结果表明,该算法能以较小的计算代价达到与LDVP-OD算法相同的检测效果,适合于高维数据流的异常检测。由于数据流的数据分布是随时间变化的,因此如何在动态数据流中快速准确地捕捉到概念漂移,将是下一步的研究方向。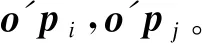
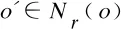
3 FASTLDVP算法
3.1 设计思想
3.2 r-邻域更新
3.3 局部向量点积密度计算


3.4 复杂度分析
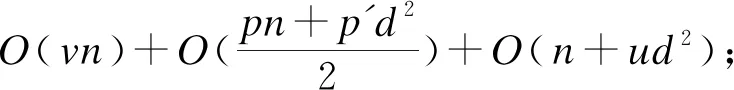
4 实验与结果分析
4.1 剪枝策略和优化策略对算法的影响
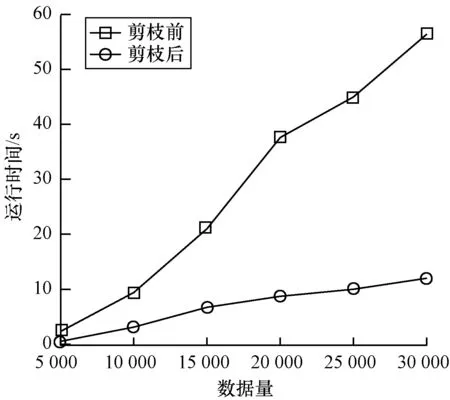
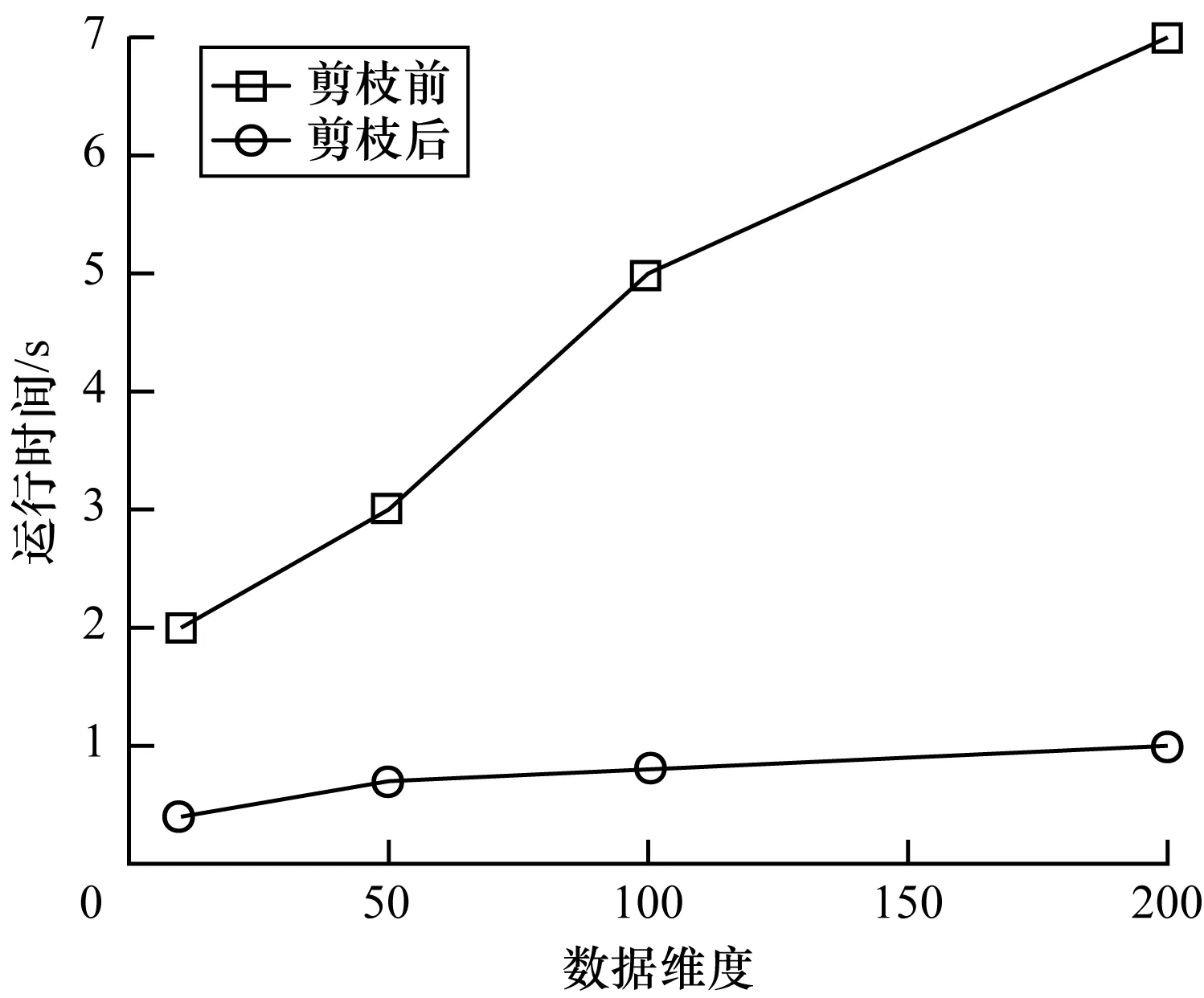
4.2 算法整体效率分析
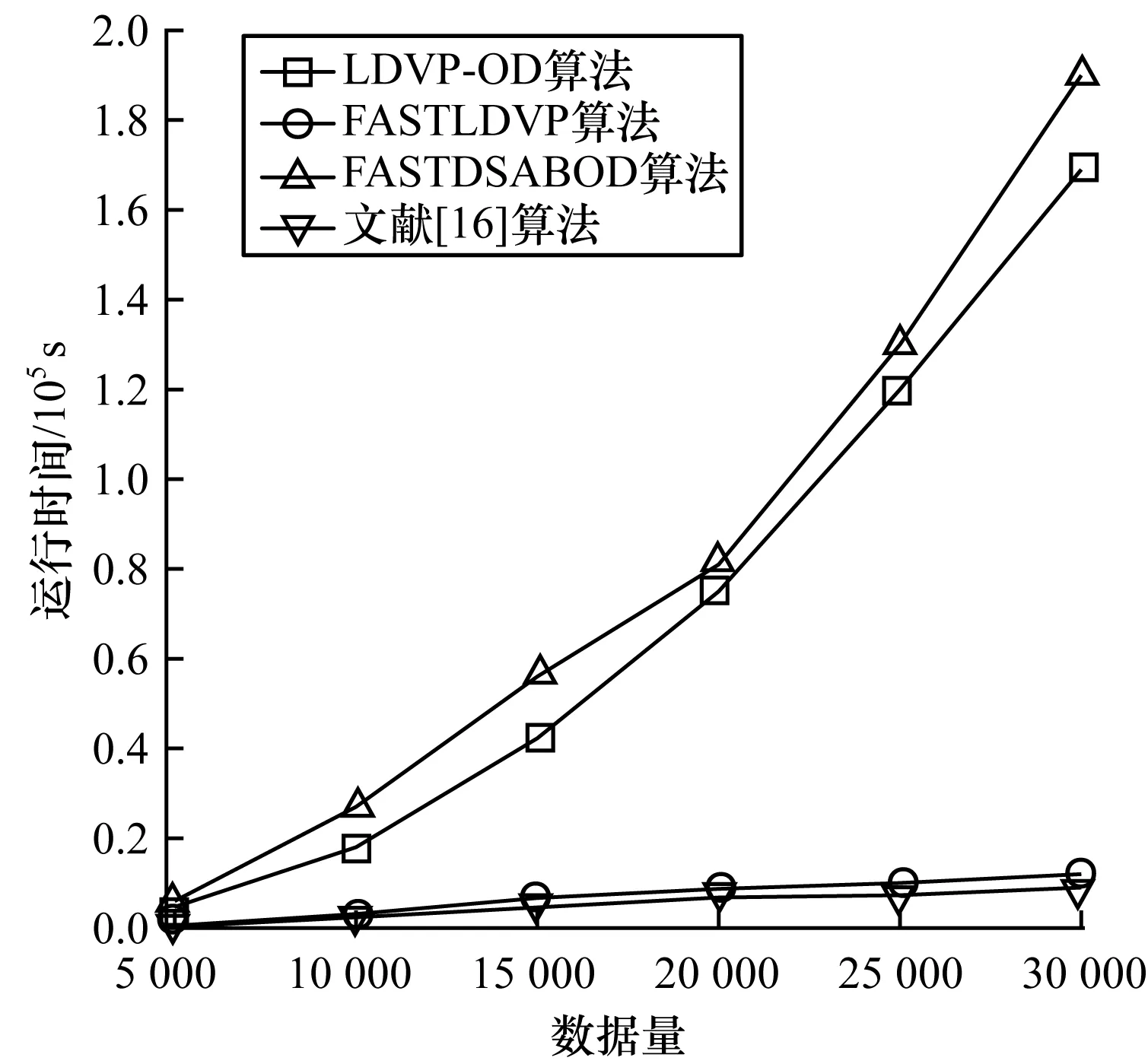
5 结束语
