结合报文负载与流指纹特征的恶意流量检测
2020-11-14周志洪姚立红李建华
胡 斌,周志洪,b,姚立红,李建华,b
(上海交通大学 a.网络空间安全学院; b.上海市信息安全综合管理技术研究重点实验室,上海 200240)
0 概述
为保障网络通信中用户和企业数据信息安全,网络流量加密成为主流措施,应用SSL/TLS协议是实现此类网络流量加密的主要手段。加密流量可以在一定程度上保护私人信息的机密性和完整性,但也给网络恶意行为提供了庇护。2015年约有21%的网络流量被加密,而到2019年可能有超过80%的网络流量被加密,同比增长超过90%[1]。攻击者将网络加密传输协议作为隐藏恶意行为的工具。2018年思科公司对40多万的恶意软件进行分析,发现其中有超过70%的恶意软件在通信时使用了加密技术[2]。然而,自2017年6月1日起,《中华人民共和国网络安全法》正式实施[3],其中第三章第三十五条规定:关键信息基础设施的运营者采购网络产品和服务,可能影响国家安全的,应当通过国家网信部门会同国务院有关部门组织的国家安全审查。在审查的全过程中需对使用加密协议的网络流量进行审查,从而判断其是否进行恶意行为或遭受恶意攻击。
目前,学者们对网络加密恶意流量进行大量研究并取得了一定的成果。文献[4]提取TLS流量的侧信道特征作为统计数据,使用机器学习模型作为分类器。文献[5]通过检测与TLS流相关联的前向后向域名系统(Domain Name System,DNS)和HTTP流中的关键信息来判断恶意TLS流量,但该方法依赖于流量的五元组特征。文献[6]将原始流量用作卷积神经网络分类器的输入,识别不同应用的SSL流量,但该方法的数据集采集环境较单一。文献[7]通过n-gram方法将网络流中的域名字符串分段为多个重叠的子串并作为LSTM网络的输入,识别加密流量恶意域名,但该方法仅使用一种特征,因此无法对域名更新频率极快的恶意流量进行检测。在五元组信息复杂的网络环境下,若将恶意流量频繁更换的五元组信息作为重要特征,会对模型识别精度产生影响。若去除流量的五元组特征后使用上述方法检测加密恶意流量,则其识别率将会大幅降低。因此,本文提出一种加密恶意流量检测方法,将网络流量的多重特征归纳为报文负载特征和流指纹特征,使其在复杂网络环境下的差异性更大,并从两个特征维度[8]出发对网络流量的位置分布进行描述,同时使用逻辑回归模型进行复杂网络环境下的加密恶意流量检测。
1 加密恶意流量检测方法
1.1 数据集
一般而言,加密恶意流量按其特点、行为等分为恶意代码加密通信、恶意行为加密通信和恶意或非法加密应用3类[9],如表1所示。相比恶意代码可在本地计算机软件和硬件层面进行识别,恶意行为更多通过流量检测方式进行识别;相比恶意或非法加密应用,恶意行为的破坏范围更广、危害更大。因此,本文选用恶意行为加密通信所产生的加密恶意流量作为研究对象[10]。

表1 加密恶意流量分类
为对恶意流量和正常流量进行分类,需要使用逻辑回归模型对加密恶意流量数据集和加密正常流量数据集进行训练和测试。本文研究中的恶意流量数据集来自布拉格捷克理工大学的CTU13数据集[11]。该数据集包含13个不同僵尸网络样本在大量真实网络环境中捕获的僵尸网络流量、正常流量和背景流量,将所有场景中的恶意流量合并为恶意流量数据集,确保本文方法的泛化性。正常流量数据集来自布拉格捷克理工大学的CTU-Normal数据集,其选择CTU-Normal-21、CTU-Normal-23、CTU-Normal-24这3个数据集,它们由排名为Alexa[12]前1 000的网站所生成的HTTPS(HTTP on SSL/TLS)流量合并为正常流量数据集,数据格式为PCAP文件。CTU13数据集和CTU-Normal数据集构成如表2、表3所示。其中,总流量为样本中包含的恶意流量、正常流量、背景流量的总数,C&C恶意流量括号内数据为恶意流量在总流量中的占比,Total Size为总流量的实际大小。
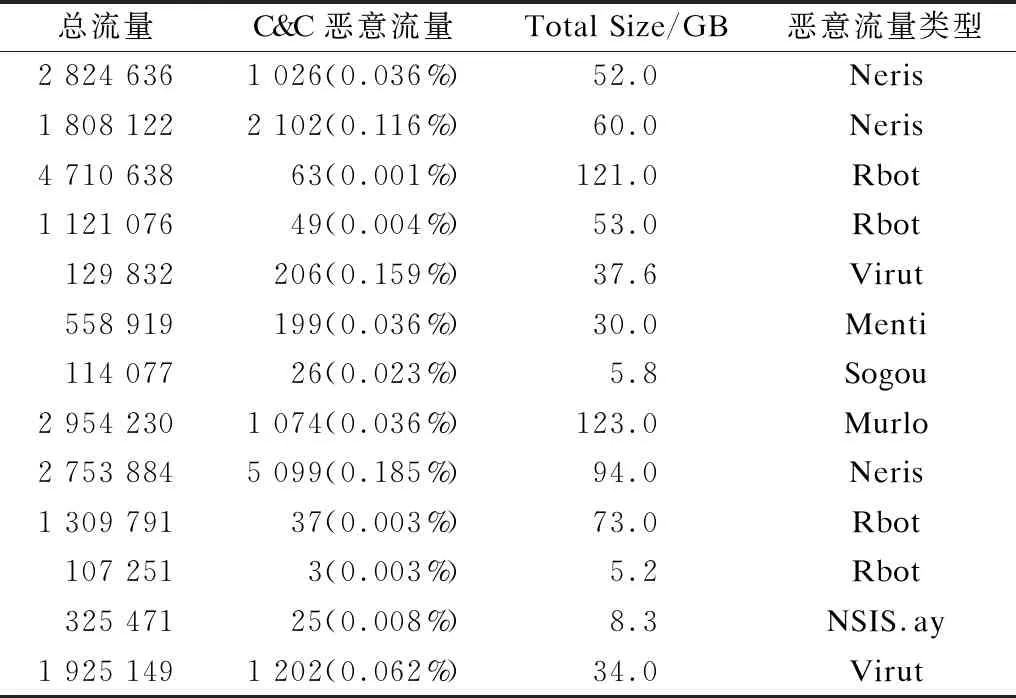
表2 CTU13数据集构成

表3 CTU-Normal数据集构成
由于本文研究目标是识别SSL/TLS流量中的恶意流量,需要更加精确的数据集,而这些数据集中包含了大量背景流量及非加密流量,因此需要先提取出其中的SSL/TLS加密部分作为研究对象,提取CTU13数据集中的C& C通信所产生的SSL恶意流量共0.698 GB,正常流量数据集大小为0.76 GB,正负数据集的大小满足了训练数据的平衡性。
PCAP文件由不同传输层数据包组成,将相同源和目的IP的数据包合并形成一个单向流,将相同IP的数据包合并形成双向流。文献[13-14]指出双向流在流量识别中表现更出色,因为双向流保证了数据的完整性,且能从双向流中获得服务器和客户端信息。双向流的形成过程具体如下:
in.source address=out.destination address
in.destination address=out.source address
in.source port=out.destination port
in.destination port=out.source port
in.protocol=out.protocol
(1)
1.2 五元组特征规避
由于近几年加密流量攻击的增加,防御者提出应对加密恶意流量的指纹识别方法,因此恶意行为也试图通过频繁改变五元组信息进行伪装并规避检测[15]。大部分研究将一个完整的流特征分为五元组特征和自定义特征:五元组特征即一个流量会话的客户端IP地址、客户端端口号、服务器IP地址、服务器端口号和协议;自定义特征根据研究内容由研究者自行定义,一般是对于需要识别的目标流量影响较大的特征。五元组特征相当于一个流量会话的身份ID,而自定义特征相当于一个流量会话的指纹。
研究人员需要保证自定义特征的稳定性以达到高识别率。稳定性是指同一类样本的某一特征变化在一个可识别的范围内。对于将通信流量伪装为SSL/TLS加密协议的恶意样本,其产生的流量自定义特征具有稳定性[16],与正常的SSL通信相比,在加密恶意流量协议、支持的密码套件和扩展字段数等方面有较大差异[17]。但对于一个恶意样本产生的恶意流量,或者同一类型僵尸网络产生的恶意流量,它们的五元组特征不稳定。若同一个样本运行在不同地点和网络环境下,则客户端和服务器端的IP地址不同。为规避传统基于规则的恶意流量识别软件的检测,恶意样本或者僵尸网络主机通常会混淆端口或者使用随机端口,但会造成五元组中的端口特征不稳定。由此可见,恶意样本或僵尸网络生成的SSL/TLS通信流量的五元组特征不稳定,不适合作为逻辑回归模型学习的特征。若使用这些特征,则会降低模型辨识性特征的密度,使得模型拟合过慢,导致整体识别度下降。
然而,现阶段大部分研究仍将五元组特征作为检测SSL/TLS加密流量的主要特征。在样本数较少且采集环境单一的情况下,加密流量的五元组特征高度相似,而在样本数较多且采集环境复杂的情况下,加密流量的五元组特征无规律性。这导致了检测同一类僵尸网络,不同数据集训练出的模型检测效果不同。采集环境单一的数据集训练出的模型采用相同数据集进行检测,分类效果较好,但一旦应用不同网络环境的同类数据集进行检测,其检测效果则会大幅降低,然而现阶段研究多数实验使用采集环境单一的数据集。由于其特征提取无法满足复杂网络环境下的加密恶意流量识别,因此需要一种排除非稳定性特征的特征提取方式。本文采用五元组特征规避法,将所有会话流量的IP地址和端口号采取一致化处理,使其不具备特征性。
1.3 报文负载特征
报文负载就是从报文内容层面对信息进行筛选和处理,从而得到这一维度的流量特征。SSL/TLS协议握手协商阶段流程如图1所示,启动TLS会话后,客户端向服务器发送ClientHello数据包,其生成方式取决于构建客户端应用程序所使用的软件包和方法。如果接收连接,则服务器将使用基于服务器端库和配置以及ClientHello消息中的详细信息创建ServerHello数据包进行响应,之后服务器端发送Certificate、ServerKeyExchange和ServerHelloDone完成ServerHello的消息发送。客户端收到消息后会利用Certificate中的Public Key进行ClientKeyExchange的Session Key交换,之后发送ChangeCipherSpec指示Server从现在开始发送的消息都需经过加密,最终以Finished结尾。服务器收到消息后发送同样性质的消息进行确认,之后便按照之前协商的SSL协议规范收发应用数据,其中握手协商阶段的报文内容为明文,应用数据传输阶段的内容为密文。传统方法采用中间人破解的方式审查SSL/TLS流量的密文内容,不仅时间耗费长,且违背了加密流量的初衷。但由于TLS协商是以明文的方式进行传输,因此可以从报文内容层面使用Hello数据包中的详细信息对客户端应用程序进行指纹识别。
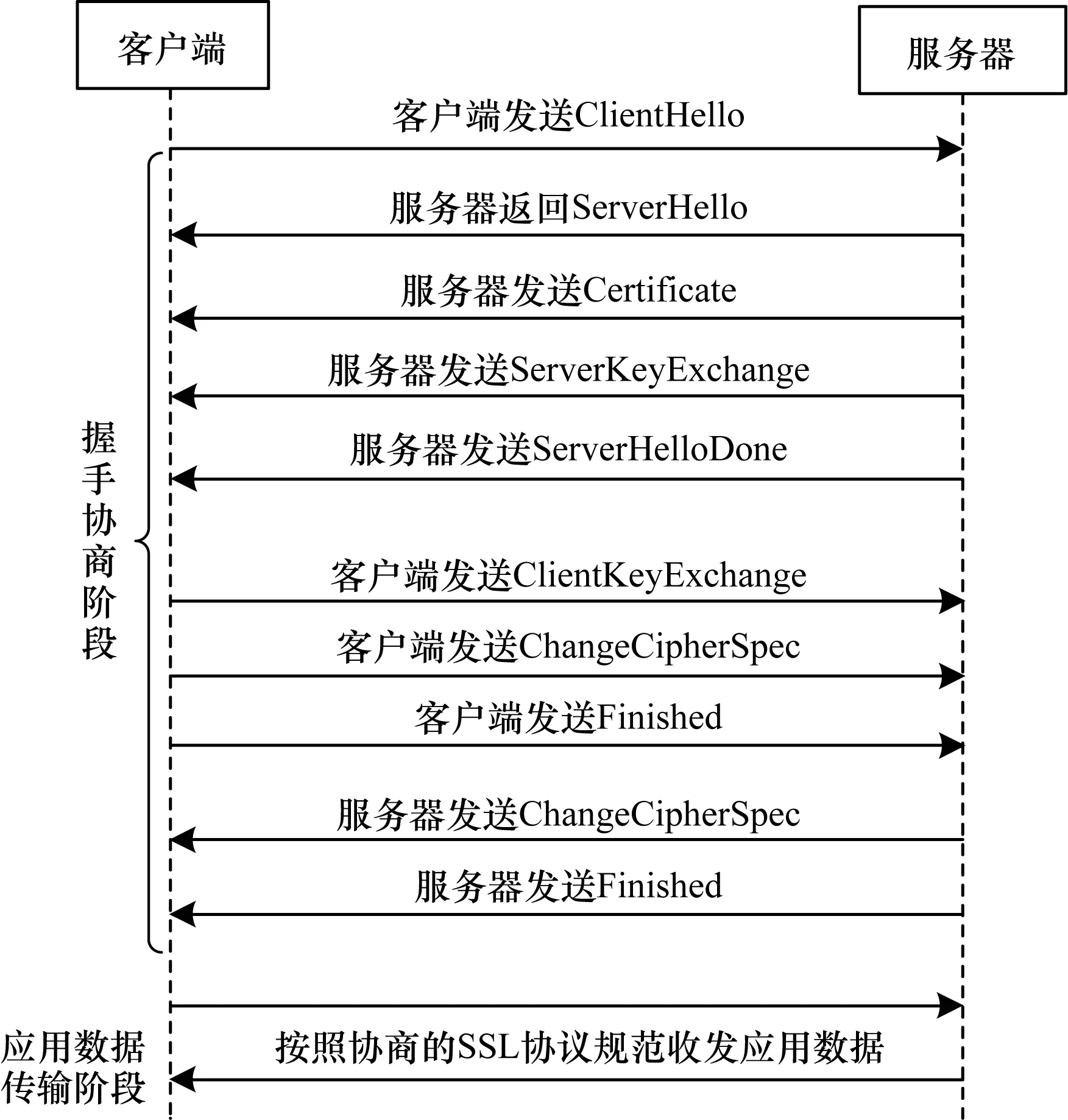
图1 SSL/TLS协议握手协商阶段流程
由于SSL协议在构建不同应用程序时使用的软件包和方法不同,因此其生成的ClientHello包中的元素也不同,但是这些元素在每个客户端会话之间保持静态,可构建指纹以识别后续会话中的特定客户端[18]。本文选取ClientHello和ServerHello报文中的Version、Cipher、Extension、EllipticCurvePointFormat、EllipticCurve元素作为报文负载的特征,如表4所示。这5种元素的组合数据不仅在任何特定客户端的静态识别方面具有较强的可靠性,且相比评估单个密码组件的方法提供了更细粒度的识别结果及差异更明显的SSL指纹[19]。将5种元素的组合数据归一化为专有的报文负载特征:
X正=[x1,x2,x3,x4,x5]
(2)
其中,X正为报文负载特征向量,x1、x2、x3、x4、x5分别为Version、Cipher、Extension、EllipticCurvePointFormat和EllipticCurve所代表的向量。

表4 报文负载特征
1.4 流指纹特征
流指纹是指流在时间和空间上的统计特征及包到达间隔时间、包长度等流量特征。本文将包长度、包到达间隔时间[20-21]及能够提供应用程序数据编码信息的字节分布数据作为流指纹特征[22]。
1)包长度和包到达间隔时间。本文首先将数据包长度和包到达间隔时间数据离散为相同大小的窗口,对于包长度数据使用大小为150 Byte的窗口,当数据大小为[0 Byte,150 Byte)时放入第1个bin,数据大小为[150 Byte,300 Byte)时放入第2个bin,以此类推。然后构造矩阵A[i,j],计算第i个bin和第j个bin之间的转换次数。最后对A进行标准化处理,确保得到一个合适的马尔科夫链并将A作为该项数据的特征。
2)字节分布。字节分布是一个长度为256的数组,其对流中每一个包的有效负载中的每一个字节值进行计数。将该计数除以数据包有效负载中发现的字节总数,可以得到每一个字节值出现的概率。不同应用程序的字节分布提供了大量关于该应用程序数据编码的信息。此外,字节分布还可以提供SSL/TLS协议握手信息包与整个流的负载比、握手信息的字节组成以及字节的香农熵和平均偏差。
将这两项的组合数据归一化为专有的流指纹特征:
Y侧=[y包,y字]=[A标,y字]
(3)
其中,Y测为流指纹特征向量,y包、y字分别为包长度和包到达间隔时间以及字节分布所表示的向量,A标为A[i,j]标准化处理后得到的关于包长度和包到达间隔时间的向量。
2 实验结果与分析
实验首先从原始数据集中提取TLS流量并对其进行统一的双向流化处理,然后规避流的五元组特征信息。将这部分流按照原始标签分为CTU13恶意流量数据集和CTU-Normal正常流量数据集。将CTU13作为复杂网络环境下的恶意流量数据集,其中的CTU13-9数据集作为单一网络环境下的恶意流量数据集;将CTU-Normal-21、CTU-Normal-23、CTU-Normal-24作为复杂网络环境下的正常流量数据集,其中的CTU-Normal-21作为单一网络环境下的正常流量数据集。本文只从两类单一网络环境下的数据集中提取流量的报文负载和流指纹特征,经过一系列整合和标准化操作后,输入逻辑回归模型进行训练,并最终使用复杂网络环境下的数据集进行验证。加密恶意流量检测流程如图2所示。
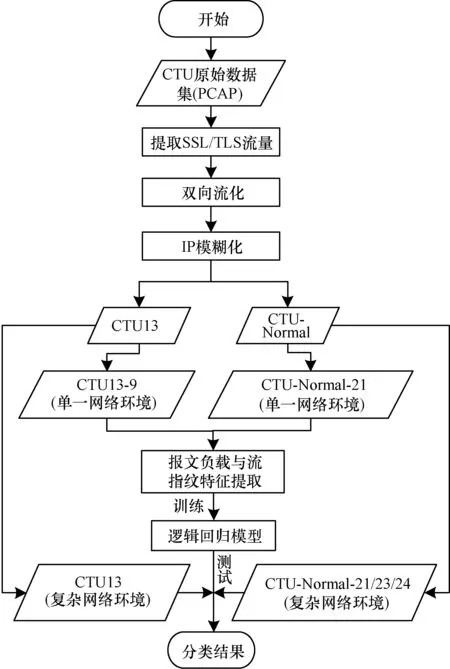
图2 加密恶意流量检测流程
2.1 实验评价指标
在测试过程中需要对逻辑回归模型性能进行评估,对于二分类问题可将每一个样例根据真实情况与预测情况的组合划分为真正例(True Positive,TP)、假正例(False Positive,FP)、真反例(True Negative,TN)、假反例(False Negative,FN)4类[23],如表5所示。假设数据总数为S,则有:
S=TP+FP+TN+FN
(4)

表5 二分类问题的分类结果
本文定义准确率(Accuracy)为分类正确的样例数占总样例数的比例,计算公式如式(5)所示。将精确度(Precision)、召回率(Recall)和F1-measure作为性能评价指标,计算公式如式(6)~式(8)所示。精确度和召回率表示分类器在每个类别上的分类能力,准确率反映了分类器的整体性能,F1-measure是精确度和召回率的综合评估指标,其值越高,表示分类性能越好。
(5)
(6)
(7)
(8)
2.2 结果分析
在实验中分别选取CTU13-9数据集和CTU-Normal-21数据集作为单一网络环境下的恶意流量数据集和正常流量数据集,选取全部恶意流量数据集和正常流量数据集作为复杂网络环境下的恶意流量数据集和正常流量数据集,并以7∶3的比例来划分训练集和测试集。
将单一网络环境产生的流量作为训练数据集训练逻辑回归模型,若以流量的五元组信息和报文负载或者流指纹信息作为分类特征,那么五元组特征会在逻辑回归模型的分类权重中占比较大,其主要原因为仅凭五元组特征就能够精确地分类出不同流量,但该模型对于频繁变换五元组特征(主要是IP地址和端口号)的加密恶意流量毫无抵抗力。为规避该问题,本文利用将报文负载或者流指纹作为分类特征的逻辑回归模型,其检测准确率相比采用五元组的逻辑回归模型约下降17个和12个百分点,检测结果表6和图3所示。可以看出,以单一网络环境产生的流量为训练集,选取的特征中包含五元组的逻辑回归模型比不包含五元组特征的逻辑回归模型F1-measure结果约提升16个百分点,说明五元组特征对于分类结果的影响较大,在逻辑回归模型分类权重中占比较大。

表6 单一网络环境下包含和不包含五元组特征的逻辑回归模型检测结果
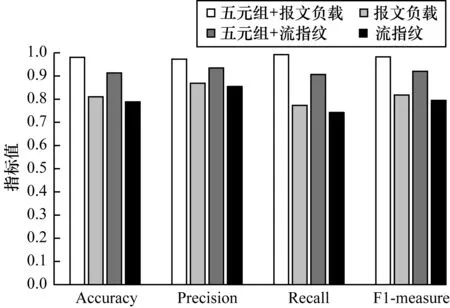
图3 单一网络环境下4种特征提取方式的检测结果
若按照传统方法选取流量的五元组特征和某一维度特征(报文负载特征或流指纹特征),且模型训练数据集由单一网络环境下采集的数据构成,其分类效果对于单一网络环境下采集的测试数据集具有较好的分类效果,主要原因为五元组特征非常重要,但对于不同网络环境下采集的测试数据集,分类效果会显著降低,其主要原因为五元组特征训练出的模型不适用于复杂网络环境,检测结果如表7、图4所示。可以看出,单一网络环境下包含五元组特征的逻辑回归模型只适用于测试单一网络环境下的数据集,若使用包含五元组特征的逻辑回归模型测试复杂网络环境下的多个数据集,则其检测准确率约平均降低35个百分点。

表7 单一和复杂网络环境下包含五元组特征的逻辑回归模型检测结果
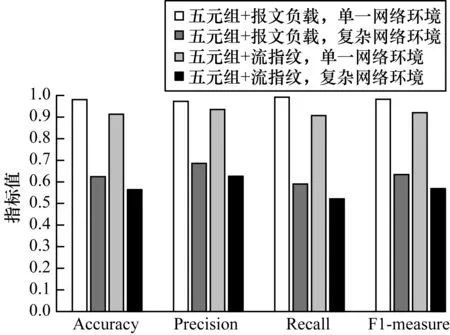
图4 单一和复杂网络环境下2种特征提取方式的检测结果
本文将流量特征中的五元组特征模糊化,而将报文负载与流指纹的联合特征作为分类器模型的输入,检测结果如表8、图5所示。若将加密流量的报文负载特征与流指纹特征各自独立训练模型,则准确率仅分别为80.99%和78.82%[4]。本文将所有流量特征归类为报文负载特征和流指纹特征后,从两个维度对流量进行刻画,并使用这两个维度的特征训练逻辑回归模型,最终得到的结果在单一网络环境和复杂网络环境下均能够达到97%以上的检测准确率,相比复杂网络环境下使用五元组与报文负载特征的传统检测方法提升36.05%。
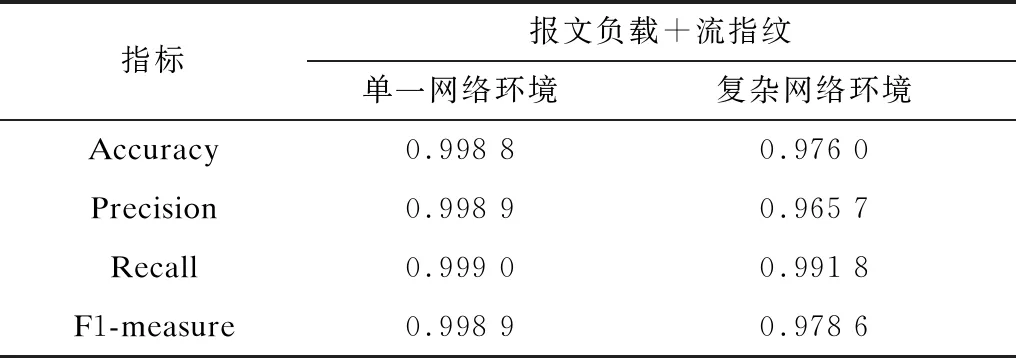
表8 单一和复杂网络环境下包含联合特征的逻辑回归模型检测结果
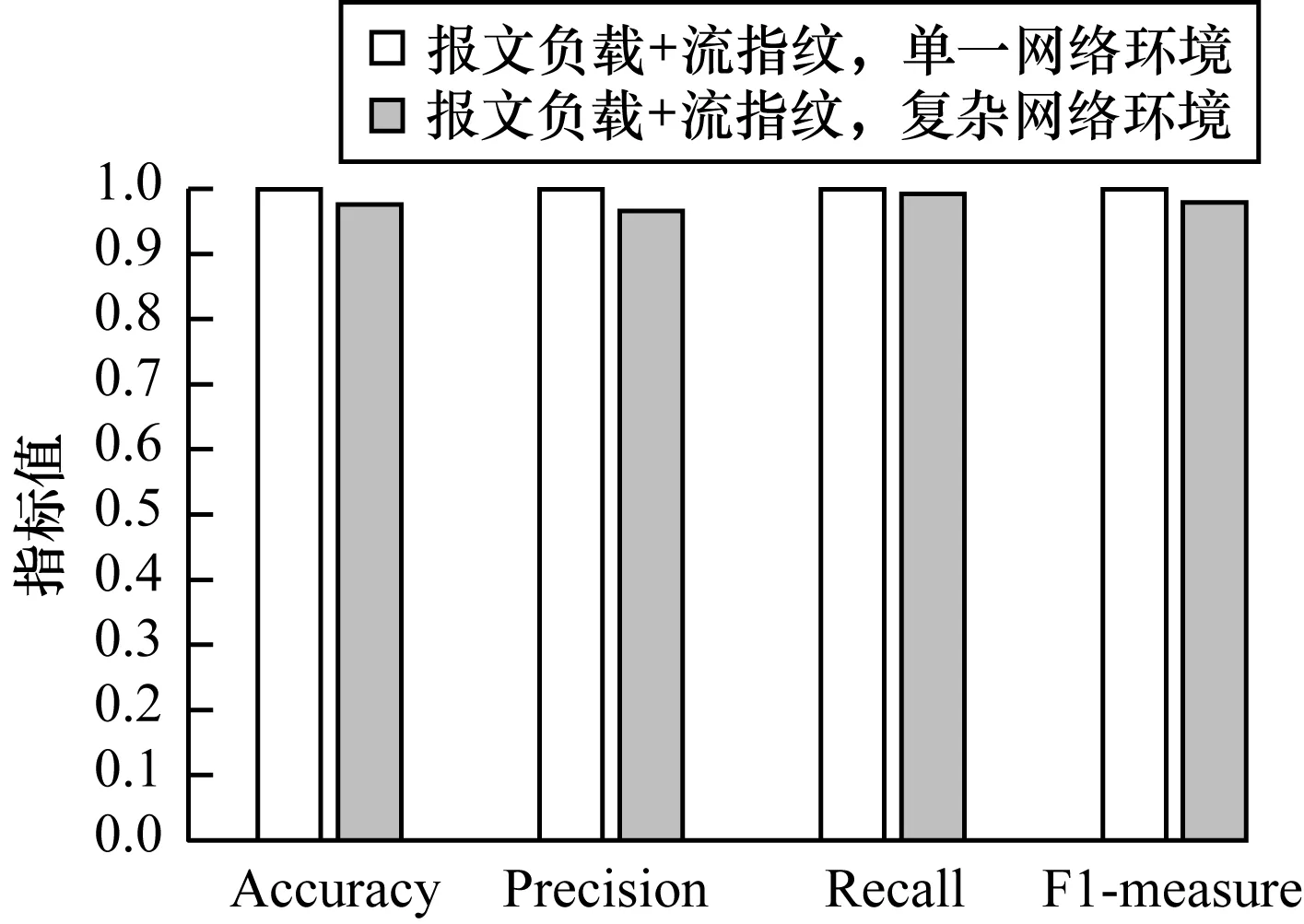
图5 单一和复杂网络环境下联合特征提取方式的检测结果
本文将两个维度的流量特征归一化后,在二维平面坐标上给出复杂网络环境下所有加密流量的位置分布,如图6、图7所示。可以看出,恶意流量的报文负载特征和流指纹特征归一化值主要集中于(0.00,0.05)和(0.00,0.10)∪(0.80,1.00),正常流量的报文负载特征和流指纹特征归一化值主要集中于(0.0,0.1)。由于复杂网络环境下的正常流量来自不同网站的正常SSL/TLS通信流量,其TLS的Version、Cipher、Extension、EllipticCurvePointFormat、EllipticCurve 因各自SSL证书不同而差异较大,因此归一化值分布于(0.0,1.0),而恶意流量因为无法获得正规渠道的合法SSL证书,只能采用版本较旧的SSL/TLS协议且支持的密码套件及扩展字段也较少,所以归一化值分布区域有限。
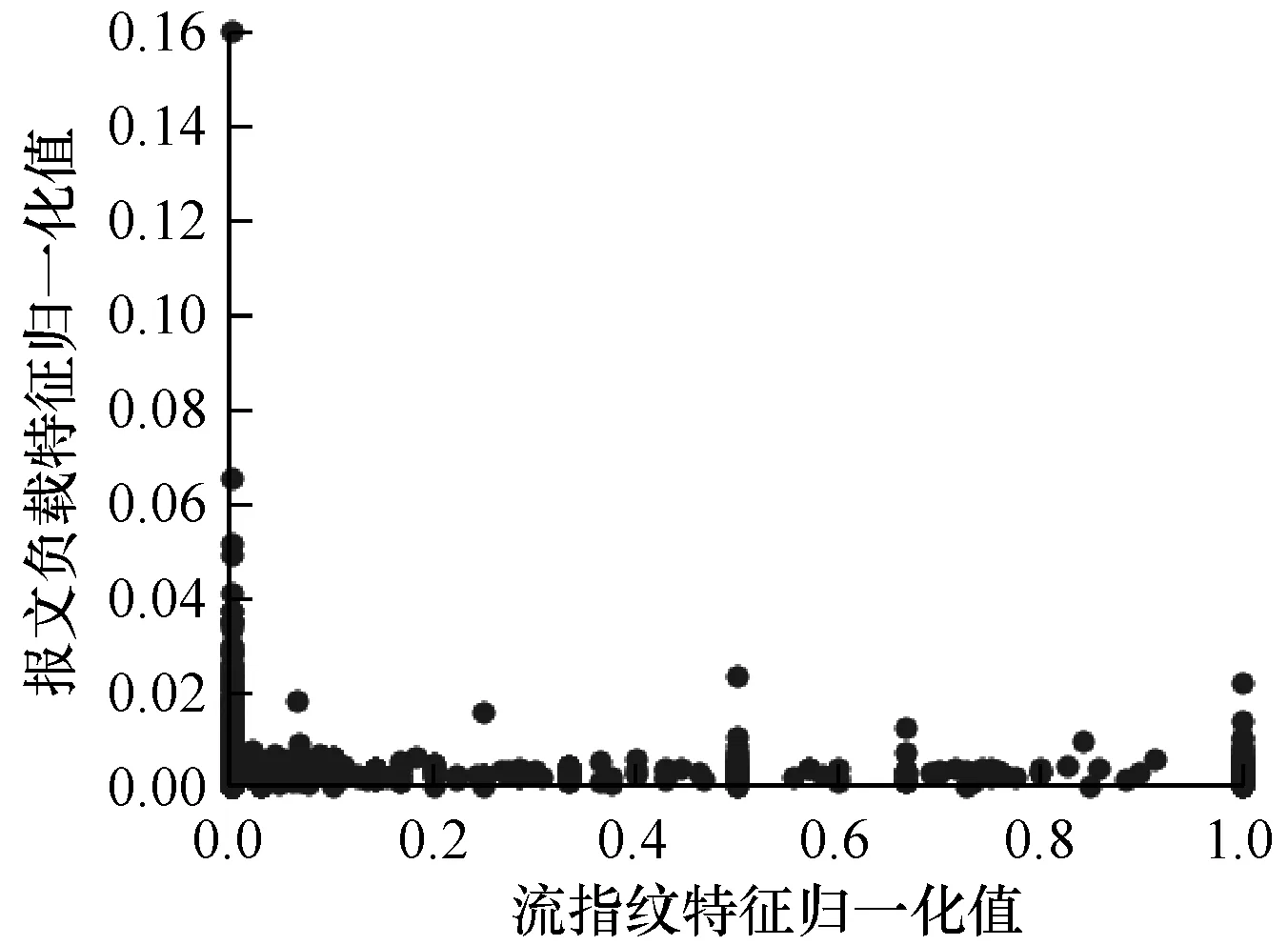
图6 联合特征描述的SSL/TLS加密恶意流量分布
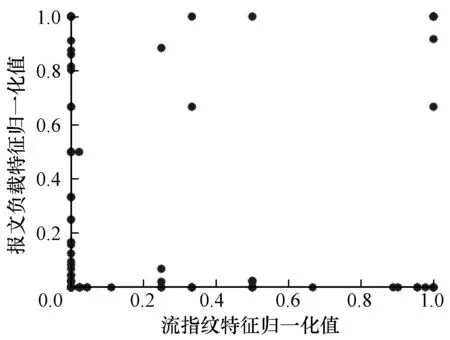
图7 联合特征描述的SSL/TLS加密正常流量分布
3 结束语
本文提出一种基于逻辑回归模型训练加密流量报文负载特征和流指纹特征的恶意流量识别方法。通过加密流量预处理及IP地址和端口号规避操作后,将选取的特征归类为报文负载和流指纹特征,并以单一网络环境中的恶意流量为数据集训练逻辑回归模型,同时不依赖加密流量的五元组特征,从而识别出复杂网络环境流量中的恶意流量。实验结果表明,本文方法提高了逻辑回归模型对于复杂网络环境流量的检测准确率,且只需从单一网络环境流量中训练逻辑回归模型,泛化性更强。下一步将在加密流量标签未知的情况下对原始加密流量进行聚类,并根据聚类特性对流量安全性进行评估,实现复杂网络环境下未知类型的恶意流量检测。
