基于瓶颈复合特征的声学模型建立方法
2020-11-14郑文秀赵峻毅文心怡姚引娣
郑文秀,赵峻毅,文心怡,姚引娣
(西安邮电大学 通信与信息工程学院,西安 710121)
0 概述
近年来,随着语音识别技术的迅速发展,特别是深度神经网络(Deep Neural Networks,DNN)在大词汇量连续语音识别中的成功应用,使语音的识别正确率得到了很大的提升。语音识别系统一般包含特征提取、声学模型和解码识别3个部分[1]。特征提取是将原始数据中提取有利于后续过程中语音识别的部分特征,消除大量冗余信息,对这些特征进行降维和去噪处理[2]。声学模型训练利用特征和标注训练模型来区分隐马尔科夫模型(Hidden Markov Model,HMM)状态,包括高斯混合模型(Gaussian Mixture Model,GMM)、深度信念网络(Deep Belief Networks,DBN)[3]、深度神经网络[4]和瓶颈-高斯混合模型(BottleNeck-GMM,BN-GMM)。
在DNN-HMM声学模型之前,GMM-HMM声学模型具有完善的理论知识体系,训练效率较高。传统的语音识别声学模型采用梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficient,MFCC)特征对GMM-HMM进行建模。但是MFCC特征具有短时的特性,容易受到环境中噪声的影响,鲁棒性较差,忽略了连续帧之间的相关特性[5]。为利用GMM-HMM的性能优势,文献[6-7]研究了一种具有狭窄中间层的瓶颈深度神经网络,从神经网络的瓶颈层提取BN特征来代替MFCC特征,并应用于GMM-HMM声学模型训练,构造出BN-GMM-HMM,实验结果表明,该模型与DNN-HMM声学模型相比具有相当的识别能力。
本文将深度神经网络提取的语音长时相关性和紧凑性特征与传统MFCC特征相结合,构造一种新的复合特征参数流系统。该系统采用成熟的GMM-HMM声学模型,并利用复合特征参数流进行GMM-HMM模型的重构,以提升系统的识别率。
1 声学特征的提取
1.1 基于深度神经网络的瓶颈特征提取
2007年,GREZL等人[8]提出瓶颈的概念并在连续语音识别中成功应用。通过在BN-DBN引入瓶颈层减少了输出特征的维度,降低了后续的运算复杂度[9]。本文采用基于DNN模型的瓶颈声学特征,其训练与其他应用于语音识别的DNN训练程相似。输入数据为39维(12维滤波器输出值,1维对数能量和两者的一阶、二阶差分)、帧长为25 ms、帧移为10 ms、11帧拼接的MFCC特征[10]。
本文采用的DNN由输入层、5层隐层和输出层构成。相邻的两层神经元之间相互连接,层内神经元不连接[11]。基于BN-DNN的语音特征提取可以分为以下2个主要步骤:
步骤1建立DNN。DNN的训练分成神经网初始化和参数更新2个阶段,即预训练(Pre-training)和微调(Fine-tuning),建立一个训练好的DNN[12]。
1)Pre-training阶段:采用贪婪算法进行非监督的方法训练一个受限玻尔兹曼机(Restricted Boltzmann Machine,RBM),再通过从底向上的方式训练多个RBM,底层RBM的输出值作为高层的输入值,获得一个DBN网络。
本文RBM的能量函数为高斯-伯努利型,可表示为:
E(v,h;θ)=
(1)
其中,θ代表模型参数,vi代表第i个显层神经元,hj代表第j个隐层神经元,Wij代表第i个神经元和第j个神经元的连接权重,σi代表控制能量宽度的参数,bi代表显层神经元的第i个偏置,aj代表隐层神经元的第j个偏置。
利用梯度下降(Gradient Descent,GD)算法对RBM的对数似然概率logap(v,h;θ)进行计算,其推导公式为:
(2)
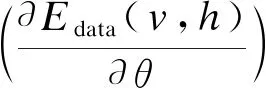
(3)
(4)
(5)

2)Fine-tuning阶段:在最后一个RBM处采取反向传播(Back Propagation,BP)算法对整个神经网自顶向下进行有监督地微调训练,完成DNN的建立。DNN的结构如图1所示。
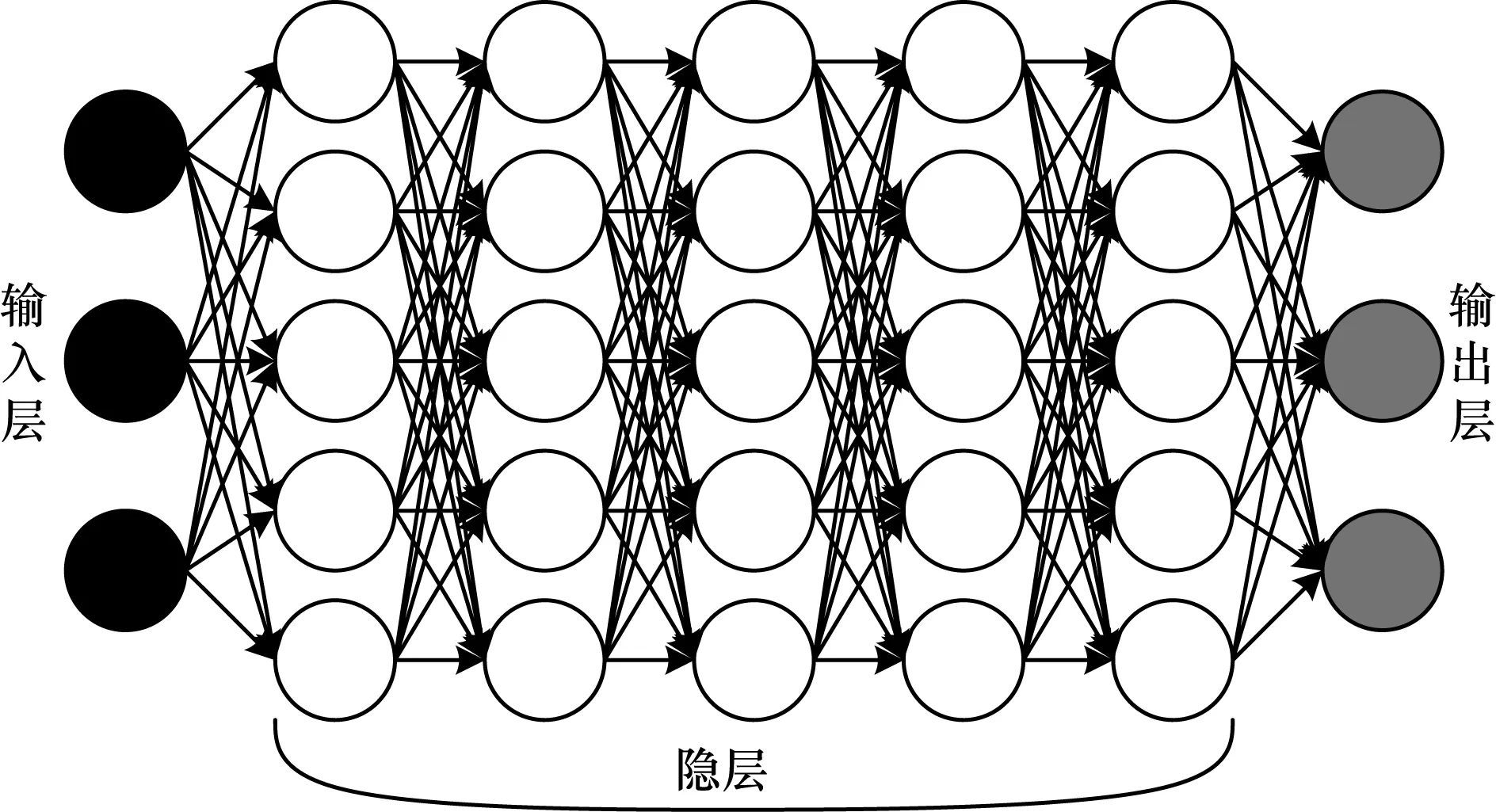
图1 DNN结构Fig.1 Structure of DNN
步骤2训练好DNN后,将瓶颈层后面网络移除,瓶颈层当作输出层获取BN特征[9]。BN-DNN结构如图2所示。
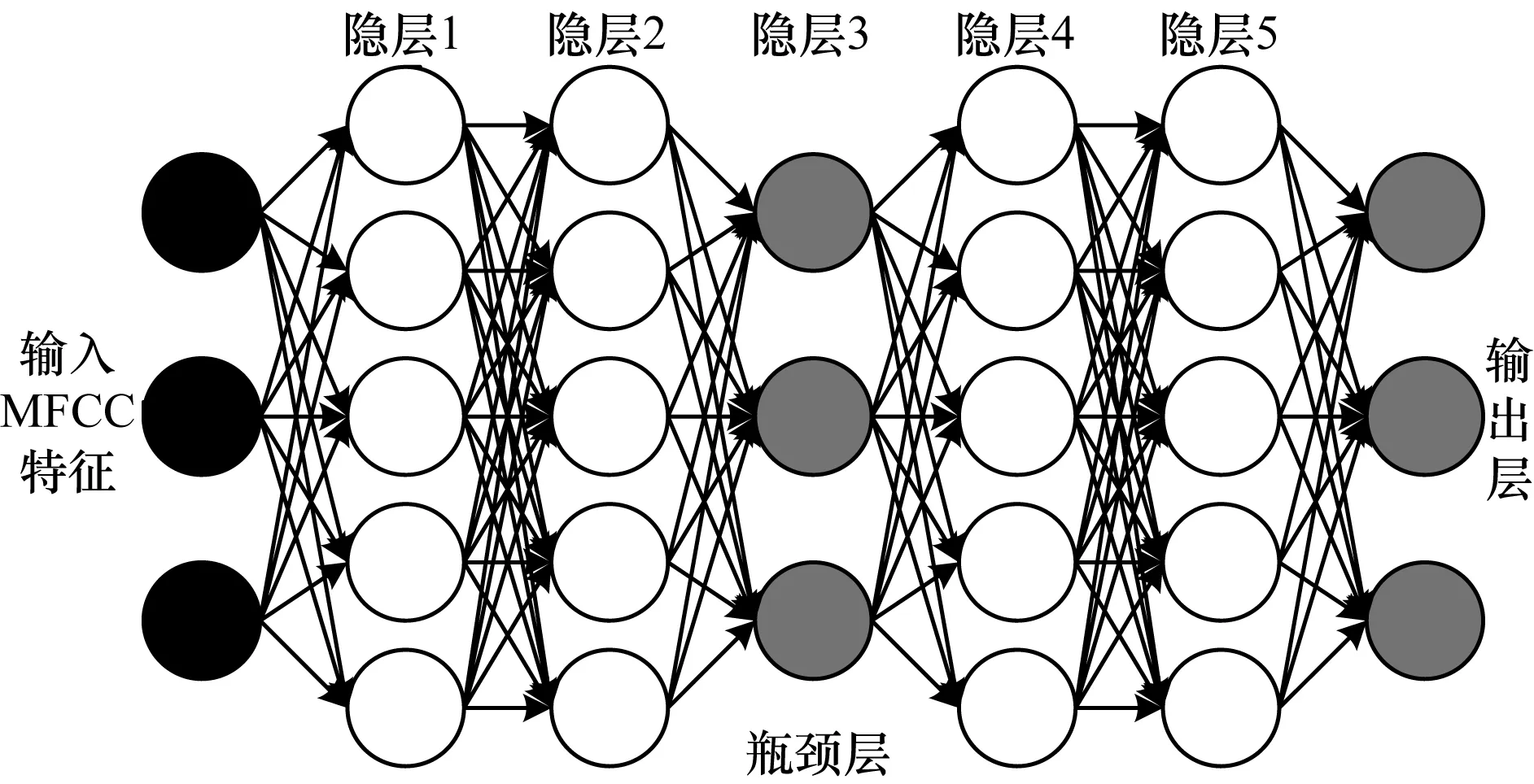
图2 BN-DNN结构Fig.2 Structure of BN-DNN
从图2可以看出[13],隐层3为瓶颈层,将提取的MFCC声学特征作为输入数据经过显层和隐层对网络进行无监督预训练,并采取BP算法对整个神经网由后往前进行有监督地微调训练,完成DNN的建立。训练好模型后,将隐层3之后的隐层4、隐层5及输出层去除,并将瓶颈层作为输出层。DNN具有强大的分类能力,可以从数据中学习更有利于特定分类任务的特征表示,因此提取出的语音瓶颈特征更有效。
1.2 新复合特征的构造
复合特征是指传统的短时特征和非短时差异特征复合后形成新的特征参数流。2010年,吕丹桔等人[14]提出将传统的短时特征如MFCC/PLP特征与采用ANN技术提取具有差异特征的MLP复合构成新的复合特征向量,利用构造出的复合特征GMM-HMM声学建模在汉语的声学特征的识别率上比单特征有了明显提高。2018年,周楠等人[15]在藏语的研究中进行了瓶颈复合特征的相关实验,结果表明,复合特征相比于单BN特征和DNN后验特征系统,识别率有了明显改善。本文采取DNN模型提取瓶颈特征与MFCC特征相结合构造出一个新的复合特征参数。
复合特征提取步骤如下:
1)对语音的原始数据预处理得到MFCC特征。
2)训练基于最大似然准则的GMM-HMM声学模型,并通过区分性训练优化GMM模型。
3)采用步骤2优化好的GMM模型对训练标注进行强制对齐,获取帧级标注用于DNN训练。
4)通过Pre-training初始化前面得到的DNN网络参数,并根据交叉熵准则Fine-tuning训练DNN网络。
5)移除上一步骤得到的DNN网络中瓶颈层之后的网络,将瓶颈层作为输出层,获取BN特征。
6)将上述步骤获取的BN特征和MFCC特征进行串接获取复合特征。
复合特征的流程如图3所示。
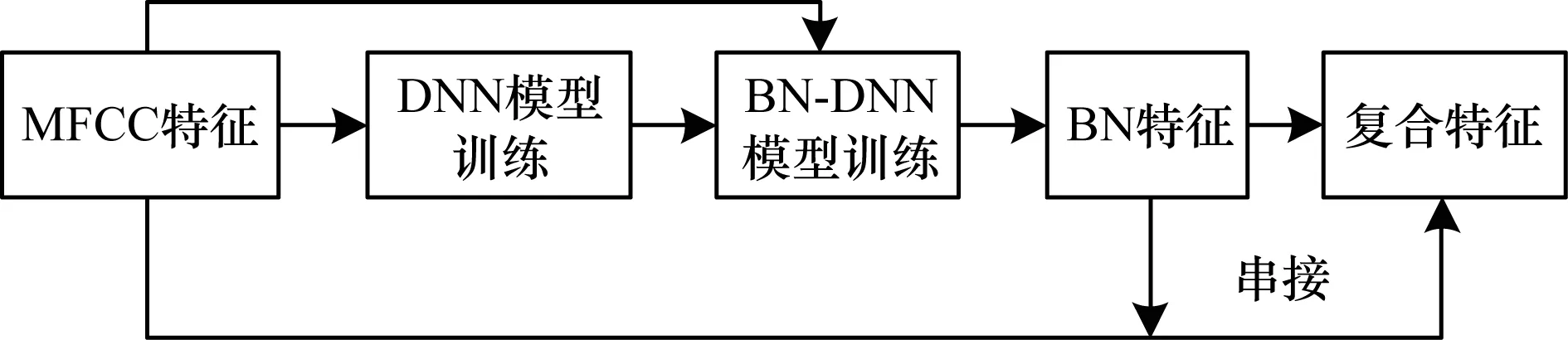
图3 复合特征的训练流程Fig.3 Training procedure of compound features
2 仿真实验与结果分析
2.1 GMM-HMM模型建立
本文采用三音素模型进行训练。三音素模型采用A_B_C形式,B为当前状态,A和C分别为前后状态,对三音素单元使用自左向右的无状态间跨越的三状态HMM,每个HMM拓扑结构前后都有一个开始状态和一个结束状态[17]。
基于最大似然准则的GMM-HMM声学模型,其输入为39维特征,帧长为25 ms,帧移为10 ms,HMM中的每个状态设置100个独立的高斯分量。
2.2 瓶颈特征的GMM-HMM模型建立
由DNN作为特征提取模块提取出BN特征并使用GMM-HMM进行声学建模所构成的系统称为级联系统[18]。首先训练一个DNN-bottleneck神经网络提取瓶颈特征。输入层神经元数目=输入特征的帧数×每帧的维数,即输入层节点429=39×11;隐层中的神经元数目通常设置应尽量大,使得它可以提升深度神经网络的性能,且除BN层以外,其他隐层的神经元数目相等;瓶颈层的神经元数目通常设置和特征的单帧维数一样。因此,本文的BN-DNN的结构表示为:429-[1 024-1 024-39-1 024-1 024]-429。最后,将得到的BN特征训练GMM-HMM模型,进行识别解码。
2.3 复合特征的GMM-HMM模型建立
复合特征的GMM-HMM模型的训练采用提取的39维BN特征和39维传统MFCC特征进行串接,得到78维高维度复合特征,经过主成分分析法(Principal Component Analysis,PCA)降维[19-20]后,获得39维的复合特征,重复2.2节中复合特征提取步骤中的步骤2的训练方法,训练复合特征的GMM-HMM声学模型并进行识别解码。复合特征的声学模型建立过程如图4所示。
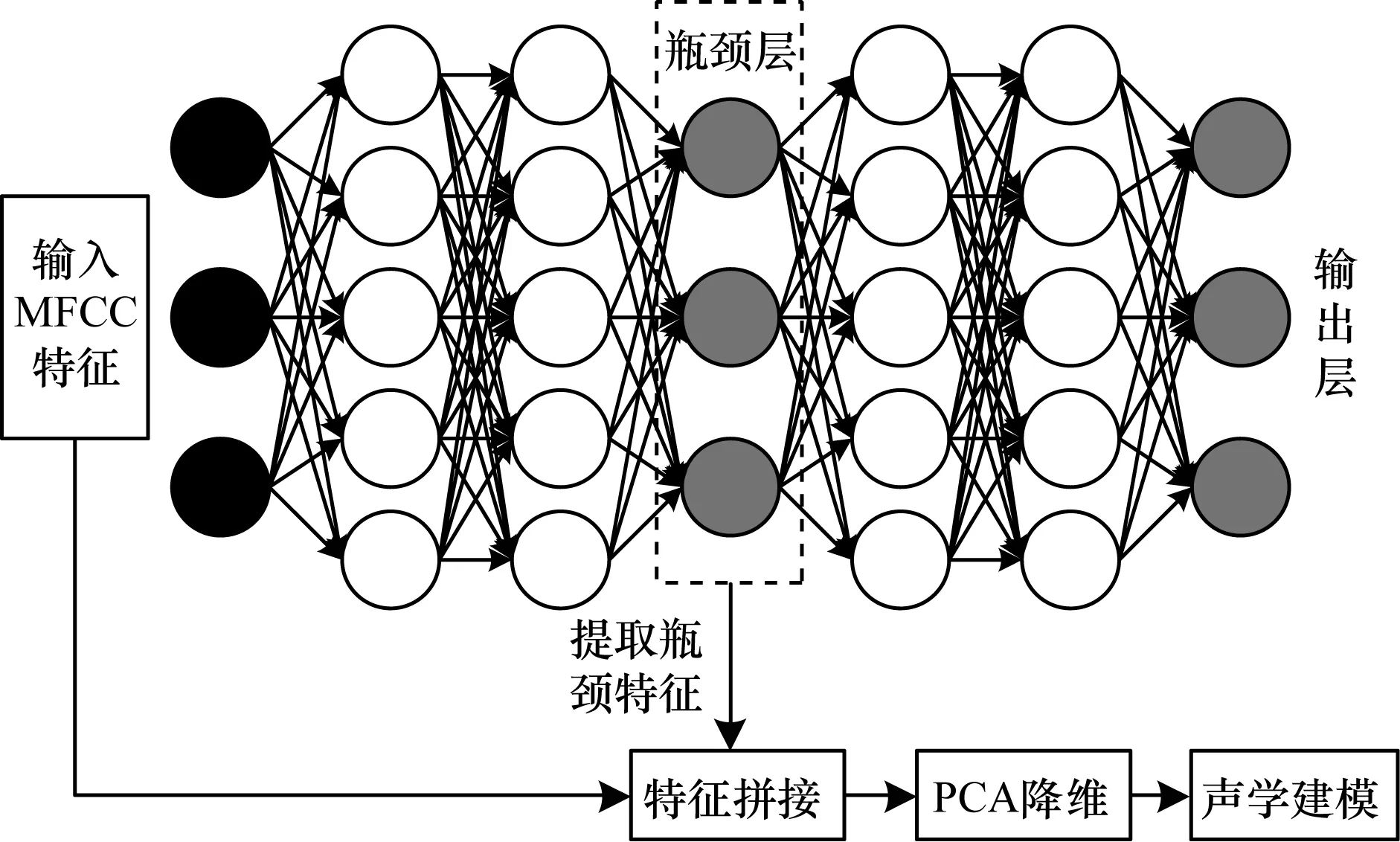
图4 复合特征的声学模型建立过程Fig.4 Process of acoustic model establishing with compound features
2.4 实验过程
实验过程如下:
1)数据集
本文采用TIMIT声学-音素学连续语音语料库来验证实验的有效性,共包含4.3 h的语音数据(其中包含1.1 h的NIST测试数据)。数据集中训练集包含462个不同发音人朗读的4 620个句子,测试集包含162个不同发音人朗读的1 620个句子,且训练集与测试集没有同一个说话人。
2)参数的设置
在Pre-training阶段,所有的RBM使用CD算法配合小批量随机梯度下降法进行训练,每一个mini-batch的大小为128,冲量因子设置为0.9,不使用权重衰减,学习率训练200代RBM。在Fine-tuning阶段,所有的参数设置和预训练阶段相同。
3)评估标准
本文将词错误率(Word Error Rate,WER)作为评估标准。WER的公式为:
(6)
其中,S为替换数,D为删除数,I为插入数,N为单词数。
2.5 结果分析
实验1隐层中神经元个数的最优设置
在实验1中,本文通过调整BN-DNN模型中隐层的神经元个数确定最佳的网络结构配置。隐层依次设置为256、512、1 024、2 048这4种情况,每个隐层神经元个数相同,且BN层神经元数目临时设置为39。不同神经元个数的模型性能比较如表1所示。

表1 不同神经元个数的复合特征声学模型性能比较Table 1 Performance comparison of composund features acoustic models with different numbers of neurons %
从表1可以看出,在DNN为五层隐层的情况下,除瓶颈层神经元数目为39外,其他隐层均为1 024时,新的复合特征建立的声学模型效果达到最佳。从而验证在2.2节提出的深度神经网络模型中,隐层神经元数目尽量大可以提升深度神经网络,在神经元数目达到1 024时,WER达到最小值13.75%,神经元数目继续增加,WER反而增加。所以,神经元数目并不是越大越好,五层隐层效果最好的神经元数目为1 024。
实验2BN层中神经元个数的最优设置
根据实验1确定隐层神经元数目为1 024,改变BN层中神经元的个数,分别设置为20、30、39及40这4种情况来确定BN层为39个神经元时是否为最优参数。不同BN层的模型性能比较如表2所示。

表2 不同BN层的复合声学模型性能比较Table 2 Performance comparison of composund acoustic models of different BN layers %
从表2可以看出,在BN层数改变的4种情况下,WER并没有太大的改变,在最大差距数目为39时,比20降低了0.11%,在最小差距数目为39时,比30降低了0.06%,但验证了BN层神经元数目为39时,根据新的复合特征建立的GMM-HMM声学模型性能最好。
实验34种不同特征的声学模型识别率的对比
MFCC特征、BN特征及新的复合特征进行GMM-HMM声学建模以及深度神经网络后验特征的识别结果对比如表3所示。

表3 不同模型识别的词错误率Table 3 Word error rate recognized by different models %
从表3可以看出,与其他语音特征相比,基于深度神经网络的瓶颈特征与传统MFCC特征的复合特征具有最佳的识别效果。相比单一的MFCC特征WER下降5.63%,与单一的瓶颈特征相比,深度神经网络后验特征具有相当的识别性能。而复合特征的识别效果相比于深度神经网络后验特征和单一瓶颈特征分别提高了3.56%和3.67%。这是因为当训练数据与测试数据相匹配时,使用BN特征相比于MFCC特征能获得更低的错误率,但是当训练数据与测试数据不匹配时,BN特征与MFCC特征复合才能获得更好的识别率。
3 结束语
本文针对TIMIT语音数据集连续语音识别,将语音数据中提取到的MFCC特征作为输入数据,经过最大似然准则训练GMM-HMM声学模型,并根据区分性训练优化GMM模型。通过预训练初始化参数并根据交叉熵准则微调训练DNN网络,移除训练好的DNN网络瓶颈层之后的网络,从而获取具有更强区分性的BN特征。将MFCC特征和BN特征进行串接,建立复合特征的GMM-HMM声学模型。实验结果表明,深度神经网络提取的BN特征在识别效果上比传统的MFCC特征更具优势,两者串接而成的复合特征的声学模型在识别率上有了大幅提升,从而验证了本文声学建模方法较优的识别性能。下一步拟将不同的深度神经网模型与传统的MFCC特征进行对比,构建复合的声学模型,以期获得更好的识别率。
