基于深度学习的HEVC SCC帧内编码快速算法
2020-11-14张倩云李萌芳郑秀凤
黄 胜,张倩云,李萌芳,郑秀凤
(1.重庆邮电大学 通信与信息工程学院,重庆 400065; 2.光通信与网络重点实验室,重庆 400065)
0 概述
目前随着共享屏幕协作、远程桌面接口、云游戏、无线显示、在线教育等移动技术和云应用的发展,屏幕内容视频越来越受到人们的关注。2014年1月,MPEG小组发布一套扩展HEVC以满足屏幕内容编码的要求[1],基于早期公布的这些草案,VCEG和MPEG发布了联合征集建议书来编码屏幕内容[2],屏幕内容编码(SCC)扩展于2016年2月发布[3]。HEVC-SCC开发并采用了一些新的编码工具,包括自适应颜色变换(ACT)[4]、调色板模式(PLT)[5]和帧内块复制(IBC)[6]。与H.264/AVC相比,HEVC的比特率降低了50%[7],复杂度提高了5倍以上。因此,有必要研究快速算法以加速SCC编码器的实时应用。
目前研究人员提出了一些用于SCC的帧内编码的快速算法。文献[8]提出一种基于纹理主方向强度的快速帧内预测算法,根据每一深度层编码单元(CU)分布特点和每CU纹理主方向强度判断CU是否需要进行分割处理。文献[9]提出基于统计特征和编码信息设计2个分类树,包括早期编码单元(CU)分区树(EPT)和CU内容分类树(CCT)。文献[10]根据CU的纹理复杂度,对平滑简单的CU自适应地终止划分,对纹理复杂的CU跳过编码提前进行划分,减少CU深度遍历的时间。文献[11]提出一种在线学习方法,使用在线学习的贝叶斯决策模型来跳过不必要的模式以及进行快速CU大小决策。文献[12]根据相邻帧数据的时间相关性和帧内数据空间相关性初步确定当前CTU形状,利用前一帧同位CTU平均深度、当前帧已编码CTU深度以及对应的速率失真代价值决定CTU的最终形状。文献[13]将分区深度范围建模为一个多类分类问题,并尝试直接预测32×32块的深度范围。由于屏幕内容不包含传感器噪声,使其具有沿水平和垂直方向的像素精确度的特征,根据此特征,文献[14]基于速率失真成本提出CU早期分割和提前终止,以进一步降低编码器复杂度。文献[15]用图像梯度信息来粗略估计编码单元的纹理方向和纹理复杂度,其中纹理复杂度用来判断是否跳过当前划分深度的预测编码过程。文献[16]提出一种基于神经网络(NN)的CU快速分区决策方案,使用CU低级统计特征(如子CU一致性、CU方差、CU颜色数等)作为NN输入来计算CU分区软判决。文献[17]根据当前编码单元下层的4个子编码单元的平均结构相似程度,来确定当前编码单元是否进行更深层次的划分。文献[18]提出一种快速模式决策算法,通过CU中的不同颜色数作为模式分类的特征。文献[19]根据当前CU与周围相邻CU和参考帧中当前位置CU的深度相关性,预测当前CU的最优深度。文献[20]提出一种基于深度学习的快速预测网络DeepSCC。其中DeepSCC-I将原始样本值作为输入进行快速预测,DeepSCC-II进一步利用固定CTU的最佳模式图来进一步降低计算复杂度。文献[21]结合屏幕视频的特征和帧内编码模式的空间相关性,有效地减少了帧内编码单元的模式搜索范围。以上方法大致可以分为两类:启发式方法和基于学习方法。对启发式方法可以根据一些中间特征简化CU分区的RDO搜索,基于学习方法利用机器学习来概括HEVC编码CU的分区规则,而不是对这些编码CU进行暴力RDO搜索。
但是以上基于学习的方法都是基于人工提取特征,所以本文考虑将深度学习用于CTU深度范围预测,利用大规模数据自动挖掘与CTU深度范围相关的大量特征,而不是有限的手工提取的特征。首先根据CU分区特性设计CNN架构,并编码足够数量的屏幕内容视频帧序列作为训练数据,然后训练CNN模型,对当前CTU的深度范围进行预测,减少不必要的深度遍历,降低编码的复杂性。
1 基于深度学习的SCC帧内编码快速算法
1.1 数据集准备
在屏幕内容标准测试序列中,所有测试序列被分为有运动的文本图表类(TGM)、动画内容类(An)和混合视频内容类(Mc)3类。不同类型的测试序列具有不同的内容特性,如运动文字图表类(TGM)的测试序列的帧以文字图表内容为主,而混合视频内容类(Mc)的测试序列的帧包含文字图表内容和自然视频内容。因此,本文挑选了不同分辨率内容特性的屏幕内容标准序列,在22、27、32、37这4个不同QP值条件下进行编码。将编码后的CTU深度信息保存并设置每个CTU的标签。训练数据帧的选取如表1所示。其中,训练集用来训练模型,验证集用来调节参数选择算法,测试集则用来在最后整体评估模型的性能。
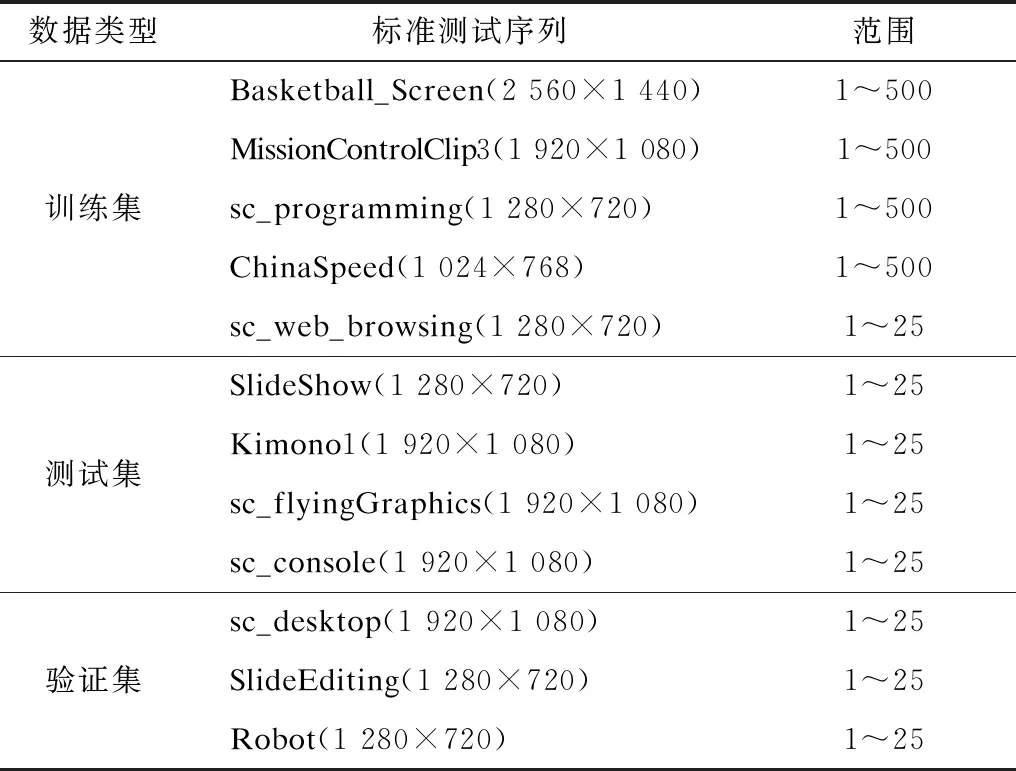
表1 训练数据帧选取Table 1 Selection of training data frames
1.2 CTU深度范围统计和标签设置
在现有的SCM软件中,采用穷举搜索方法通过检查当前CU的每种可能模式,并使用最佳模式比较当前CU的RD成本以及所有其递归子CU的RD成本之和来解决CU分区问题,导致了整个CU的划分过程存在大量计算冗余。本文考虑通过深度学习代替原有递归算法来确定CU分区,但由于IBC/PLT模式的存在,使得屏幕内容CU的划分不仅依赖于CU本身的特性,即使在纹理复杂区域可能不进行划分,这也成为有效确定CU分区的一个难点。
为在降低计算复杂度的同时保证减少视频质量的损失,本文考虑利用深度学习预测CTU深度范围,而不是直接确定最终CU划分结果,然后根据预测范围跳过和终止某些深度的RD代价值检查。这样使得在较高深度范围内,能够通过检查IBC/PLT模式后再确定最终划分,而不是直接确定CU分区而忽略这2种模式的影响。
本文研究屏幕内容标准序列中CTU深度范围的分布,根据所选训练数据帧编码后的结果进行CTU深度范围的统计,结果如表2所示。
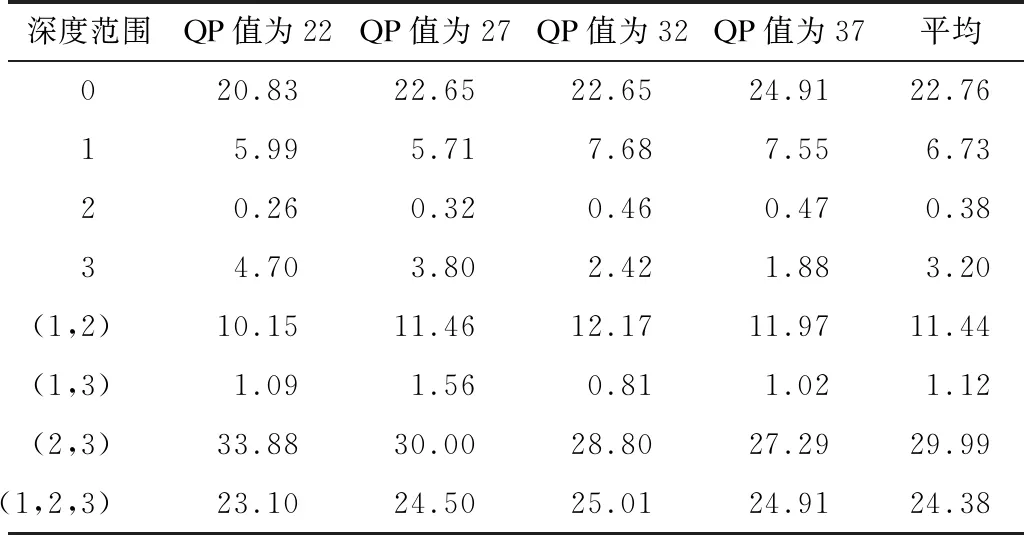
表2 CTU深度范围统计Table 2 Statistics of CTU depth range %
在表2中,0、1、2、3表示只包含深度为0、1、2、3之一的CU的CTU,(1,2)表示只包含深度为1和2的CU的CTU,(1,3)和(2,3)同理,(1,2,3)表示包含深度为1、2和3的CU的CTU。从表2可以看出,对于屏幕内容视频来说,CTU深度范围主要集中在深度0、(1,2)、(2,3)、(1,2,3)这4个范围内,其中,深度范围0、(2,3)、(1,2,3)占比都在20%以上,而深度范围1、2、3、(1,3)占比都在10%以下,特别是对于纯文本类视频,因为有大量文字内容及空白平滑区域,其CTU范围主要集中在低的深度0和较高的深度(2,3)。考虑到屏幕内容视频编码特性,由于屏幕内容视频编码中增加了IBC/PLT模式,根据预测分类标签跳过的深度越多,受IBC/PLT模式影响越大,并且深度范围2、3和(1,3)的占比较低,因此不考虑将这几类单独作为分类类型。而深度为1的占比虽然达到6.73%,但和深度范围0、(2,3)、(1,2,3)占比相比也较少。因此,为使预测分类更加准确,本文将CTU分为4类,如表3所示。

表3 CTU分类结果Table 3 Results of CTU classification
1.3 用于CTU深度范围预测的CNN架构
用于预测CTU深度范围的CNN架构由输入层、2个卷积层、1个最大池化层、1个连接层和2个完全连接的层组成。每层具体结构如下:
输入层:提取屏幕内容CTU的亮度信息,因为它包含大多数视觉信息。此外,为加快梯度下降求最优解的速度,所有输入像素矩阵的所有元素值都归一化为[0,1]。
卷积层和最大池化层:对于第1卷积层,并行应用内核大小为8×8、4×4和2×2的卷积核在3个分支上提取CTU深度信息的低级特征。本文将步幅(stride)设置为与卷积核的大小相同。上述第1卷积层的设计符合CTU分区的不同大小的所有可能非重叠CU。在第1卷积层后进行最大池化,保留显著特征,大小为4×4步长等核。然后并行使用3个内核大小为2×2的卷积核在3个分支上提取CTU分割的高级特征。
连接层:从最后一个卷积层产生的所有特征图被连接在一起,然后通过连接层转换为矢量。
完全连接层:连接层向量中的所有特性都流经2个完全连接的层,包括1个隐藏层和1个输出层。其中,最后一层为输出层,输出CTU分类标签P1、P2、P3和P4的概率,其中,概率最大的标签为最终分类标签。所有卷积层和隐藏的全连接层均由整流线性单元(ReLU)激活,最后输出用softmax函数激活。此外,在连接层和全连接层将QP值作为外部特征输入用于最终分类。应用具有动量的随机梯度下降算法来训练CNN模型。其中,损失函数调用TensorFlow中的softmax_cross_entropy_with_logits进行计算。CNN架构如图1所示。
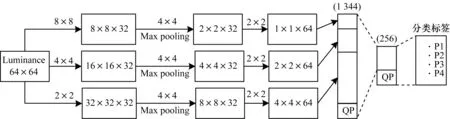
图1 用于预测CTU深度范围的CNN架构Fig.1 CNN architecture used to predict the depth range of CTU
在编码CTU时,首先根据CNN预测输出来进行CTU深度范围预测。当预测输出P1概率最大时,CTU深度为0;当预测输出P2概率最大时,CTU将深度限制在范围(1,2);当预测输出P3概率最大时,CTU将深度限制在范围(2,3);当预测输出P4概率最大时,CTU将深度限制在范围(1,3)。不同QP值下CNN模型准确率如表4所示。

表4 不同QP值下CNN模型准确率Table 4 Accuracy of CNN model under different QP values %
从表4可以看出,在QP=27时,与文献[13]的准确率84.505%相比,本文所提模型准确率有所提高。
2 屏幕内容CTU深度预测快速算法流程
基于深度学习的SCC帧内编码快速算法流程如图2所示。
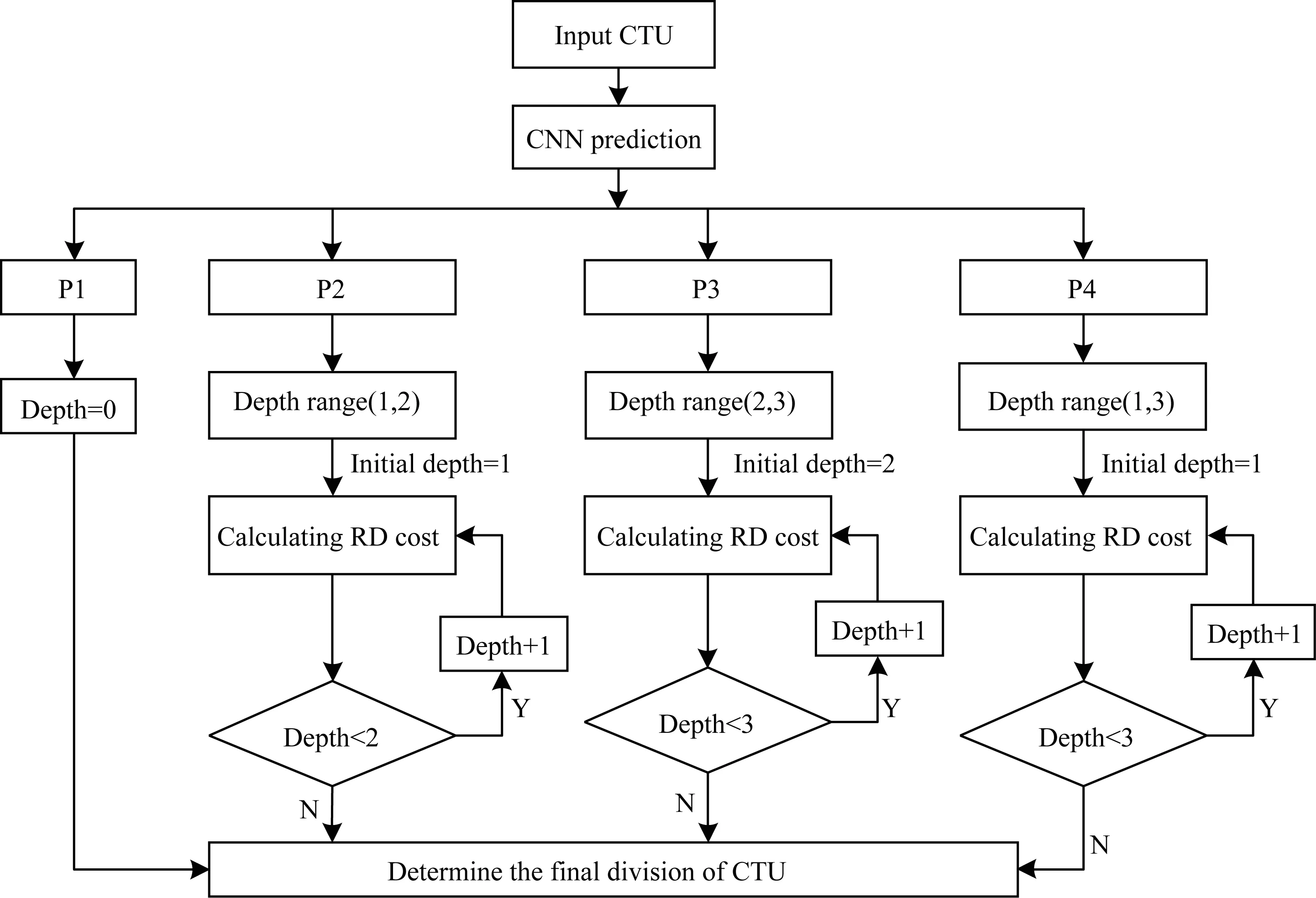
图2 CTU深度预测快速算法总体流程Fig.2 Overall procedure of CTU depth prediction fast algorithm
CTU深度预测快速算法具体描述如下:
1)读取屏幕内容CTU,提取CTU的亮度像素信息作为CNN模型的输入信息。
2)调用CNN模型,输入CTU亮度像素信息,其中,输入像素矩阵的所有元素值都归一化为[0,1],加快梯度下降求最优解的速度。
3)CNN模型输出CTU各个类别标签的概率,其中概率最大的标签为CTU的最终类型标签,并根据该标签预测CTU深度范围。
4)在编码过程中,根据预测的CTU深度范围,跳过和终止某些深度的RD代价值计算,加快编码速度。
5)确定整个CTU最终深度。
3 实验结果与分析
为评估本文提出算法性能,将本文算法在HEVC参考软件HM-16.10+SCM-8.0中进行实现。对11个选定的标准测试序列进行编码(测试序列中选为训练帧的帧不在性能评估范围内)并进行性能评估。测试环境配置为:Intel®CoreTMi5-4590 CPU @ 3.30 GHz,内存为8.00 GB,操作系统为Windows10 64位,实验工具为 Microsoft Visual Studio 2010。QPs={22,27,32,37},在通用测试条件下,实验采用全I帧编码。运用BDBR[22]、BDPSNR和时间节省百分比ΔT来对算法性能进行评估。ΔT的计算公式如下:
其中,Tref和Tpro分别表示SCM-8.0的编码时间和本文算法的编码时间。不同QP值下本文算法性能如表5所示。与SCM-8.0相比,在全I帧编码后,本文算法总时长平均减少了48.34%,BDBR上升了2.59%,同时BDPSNR仅下降了0.14 dB。其中,序列slideshow编码时长减少达到了67.03%,这是因为该序列中包含大量的PPT演示内容,并且纹理简单,存在大量平滑区域,在调用CNN模型进行CTU深度预测时,预测的深度范围中有大量集中在较低的深度,因此在进行CU划分时,减少了较高深度的遍历,跳过了大量RD代价值的计算,所以时间减少最多。而对于纹理复杂的序列,如sc_web_browsing、ChineseEditing等,由于在序列中包含大量的文本内容,在调用CNN模型进行CTU深度预测时,预测的深度范围中有大量文本内容集中在较高的深度,因此跳过了较低深度的遍历,但是由于较高深度的计算复杂度更高,因此时间节省没有纹理简单的序列多。在全I帧条件下,本文算法与文献[16,18,21]的性能对比如表6所示。与文献[16]相比,本文在BDBR和时间节省方面都有了一定程度的降低。与文献[18,21]相比,本文算法减少了更多的时间,BDBR也仅分别增加了1.66%和1.9%。从编码时间角度来看,本文算法优于文献[18,21]算法。
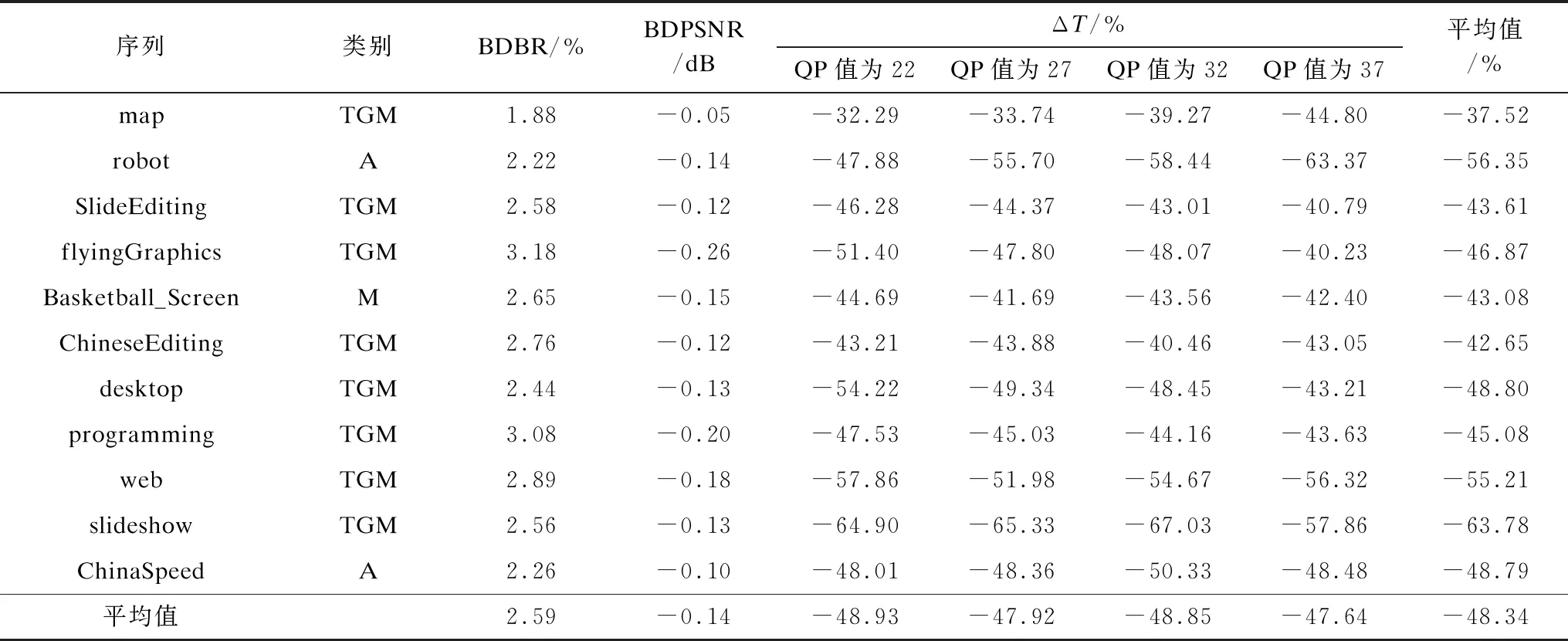
表5 不同QP值下本文算法性能Table 5 Performance of this algorithm under different QP values

表6 不同算法性能对比Table 6 Performance comparison of different algorithms %
4 结束语
本文提出一种基于深度学习的屏幕内容编码帧内CTU深度范围预测算法。首先对标准屏幕内容测试序列进行编码,收集大量的训练样本,然后设计与CU分区相适应的CNN架构,训练用于预测CTU深度范围的CNN模型,最后在SCM8.0中调用训练好的CNN模型预测CTU深度范围,根据预测出的深度范围,跳过和终止某些深度的RD代价值的计算,以降低编码复杂度。实验结果表明,在图像质量几乎保持不变的情况下,与SCM-8.0相比,本文算法编码时间减少48.34%,加快屏幕内容编码。下一步将在本文研究的基础上对 CNN模型进行训练,增加对CTU深度有影响的时间和空间因素的考虑,以降低BDBR来保证SCC的高实时性。
