一种新的四元阵列融合声源识别方法
2020-11-09刘亚雷顾晓辉
刘亚雷, 顾晓辉, 甘 宁
(1.中国人民武装警察部队海警学院舰艇指挥系, 宁波 315801; 2.南京理工大学智能弹药技术国防重点学科重点实验室, 南京 210094)
目前,海警部队在探测海上目标方面主要依靠搭载的雷达、光电等设备,探测附近海域内船舶、岛屿等目标的方位信息。近年来中国海洋局势紧张,海警部队执行遂行多样化的任务也变得日益繁重,如在海上预警、搜救、维权执法等任务中,现有的雷达等无线电探测设备对近范围内、小体积移动目标存在探测盲区,而光电设备不仅存在探测距离的限制,而且还受到海上环境的影响,在低可见度、低信噪比下难以完成维权执法过程中相应的取证任务。声识别在不透光的环境里具有不可替代的优势。目前国外声识别技术已发展到第三代,如美国的“被动声识别定位系统”(PALS) 和瑞典的“索拉斯6”(Soras6) 全自动被动声识别系统均能在2~45 s内判定目标,可同时处理200个目标,20 km内最大探测误差为2%[1]。声识别具有不受地形、地物的影响,不受光线限制,具有可全天候工作、成本低、功耗低的特征。从理论上分析,其属于被动声识别的一类,也称为被动式声雷达[2],被动声目标识别通常经过声信号采集、预处理、特征提取、分类识别等步骤。国内外学者关于信号的预处理技术及特征提取主要集中在时域[3]、频域[4]、时频域[5]三个方面,其中以小波变换为基础的多种时频域信号预处理技术得到广泛应用[6-7],此外,结合典型环境特征,针对非线性、非平稳信号,文献[8-9]提出了一种基于经验模态分解理论的声信号预处理方法。在信号的特征提取上主要有快速傅里叶变换分析、线性预测编码[10]、能量谱分析[11]、多频段谱分析[12]、基频分析法[13],对于分类识别方法的研究主要集中在神经网络[14]、特征参数匹配[15]、隐马尔可夫模型[16],上述方法在对于信号的预处理上存在模型线性化误差,将实际的环境噪声假设为高斯白噪声,对于特征信号的提取依赖于经验分析阈值判断而造成信息丢失,针对上述问题,科研人员分析了空气场目标声信号与语音信号的特征,得到了上述两类信号具有相似性的特性,因此,借鉴语音信号特征参数的提取方法来分析空气场声目标信息,并到达识别、定位甚至跟踪的目的成为近年来领域内的研究热点。
现结合海上多干扰、多噪声环境,为了提升海警部队维权执法的快速反应能力,完善海上取证的闭环过程,丰富执行海上预警、搜救等任务的手段,提出了一种基于梅尔频率倒谱系数-动态时间规整(Mel-frequency cepstrum coefficient-dynamic time warping, MFCC-DTW)的四元阵列声源识别方法,方法中四元声传感器成圆形均匀布置,阵列半径为0.5 m,各个传感器采用分布式方式独立采集声源信号,在系统坐标系下建立四元阵列有色噪声环境下的声源观测模型,给出四元阵列经验模态分解(empirical mode decomposition, EMD)融合分布式算法,有效抑制多通道下高频信号的干扰,基于MFCC-DTW方法,设计阵列信号特征提取与分类识别,并利用半实物仿真试验验证本文提出的EMD融合算法及阵列信号特征提取与分类识别算法的有效性。
1 阵列声信号EMD预处理
1.1 阵列观测模型
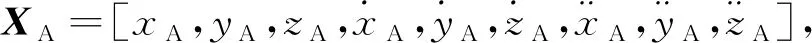
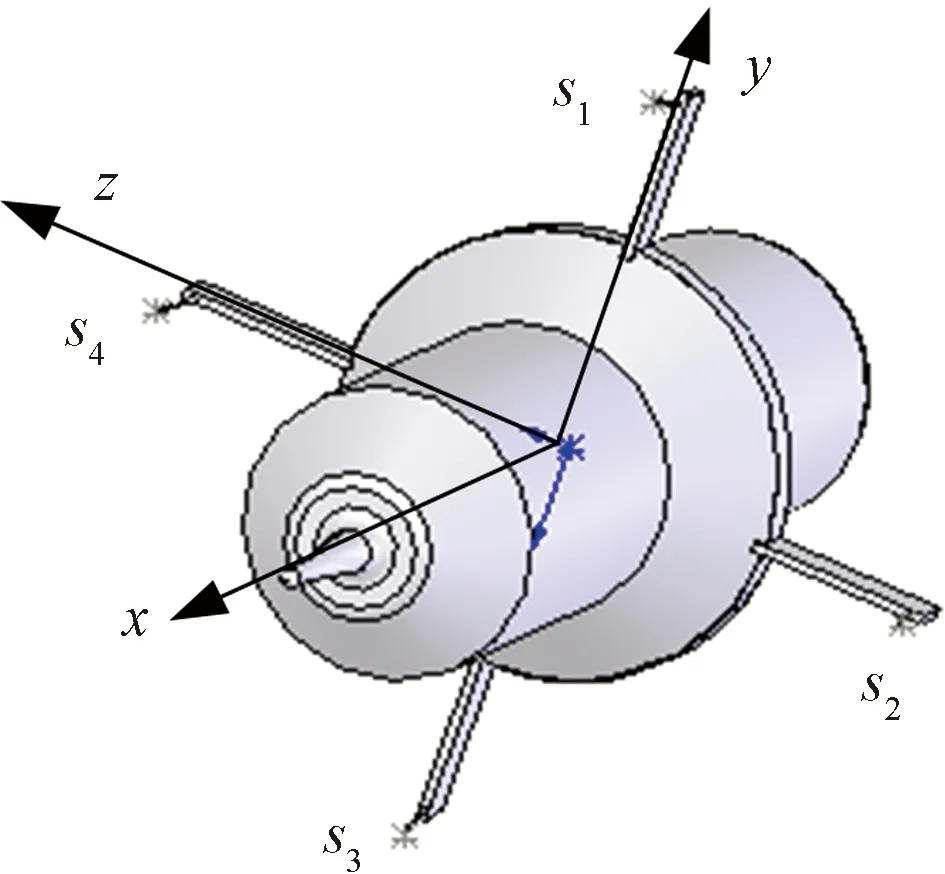
图1 声传感器阵列布置结构图Fig.1 The layout of acoustic array’s sensor array
如图2所示,基于系统坐标系下,在k时刻阵列检测声源目标模型为
Z(k)=hk-1(Xk)+ξ(k)
(1)
式(1)中:
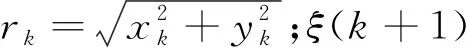
Z(k+1)=hk(Xk+1)+D(k+1)ξ(k)+
V(k+1)
(2)
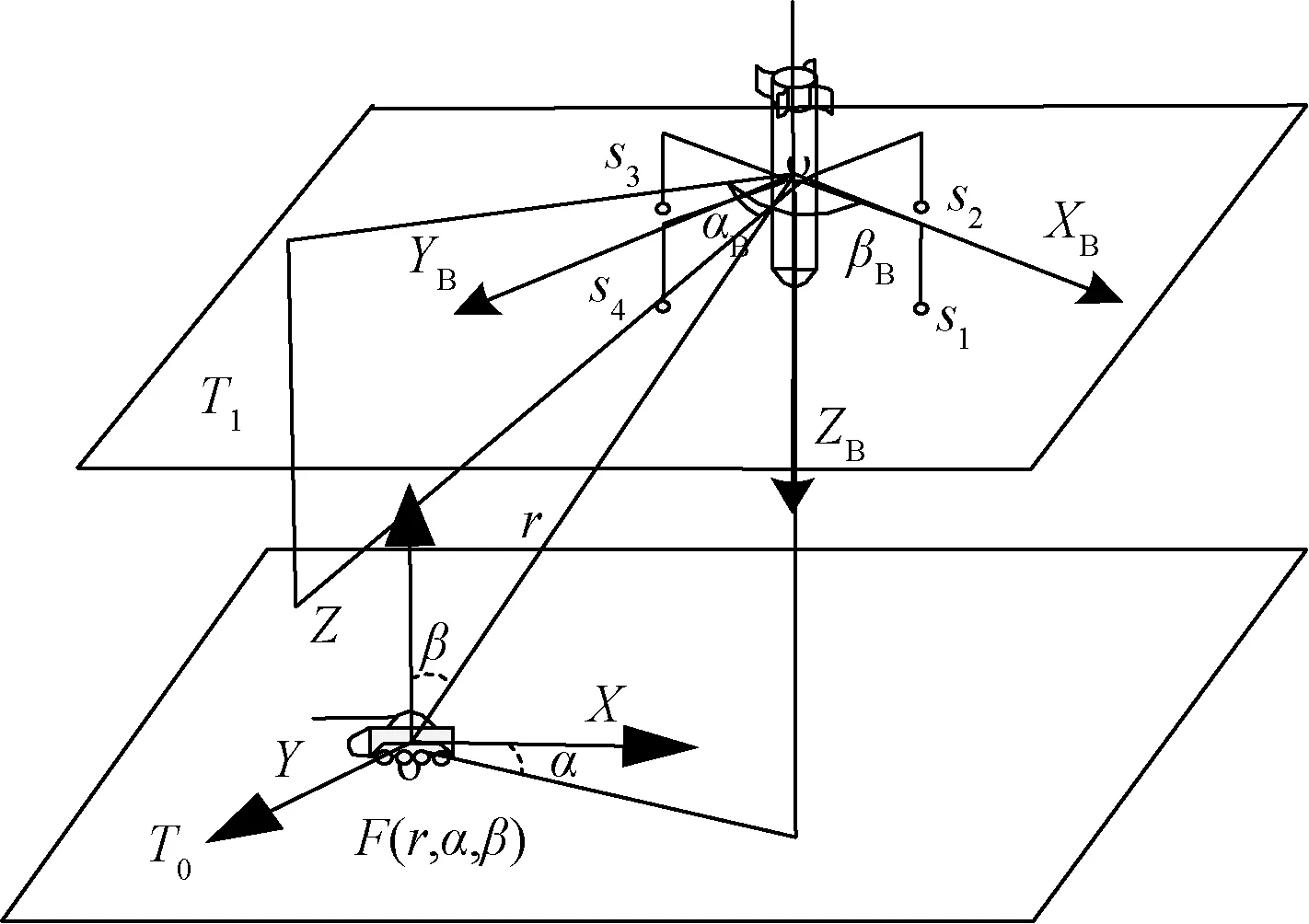
图2 声传感器阵列对声目标信号检测图Fig.2 The acoustic sensor array detects the acoustic signal
1.2 四元阵列EMD融合算法
如图3所示为四元阵列声信号EMD融合算法流程图,其步骤如下:
(1)由式(2)得到阵列观测信号Z(k):基于EMD对Z(k)分解,获得n个IMF分量,记为:IMF1,IMF2,…,IMFn。
(2)对IMF1,IMF2,…,IMFn分别逐次快速傅里叶变换(FFT)变换,获取IMF的频谱特征,如各个分量的主频、频带范围,频谱功率等参数。
(3)基于目标声谱特性,提取IMF分量阈值δimf。

上述阵列声信号EMD融合算法考虑了环境有色噪声对系统的干扰,针对阵列观测非线性、非高斯观测模型,利用目标信号的频谱特征提取基本模式分量(intrinsic mode function, IMF),理论上不仅抑制了高频噪声的干扰程度,而且能够有效地保持原始声源目标信息特征,使得信号不失真。
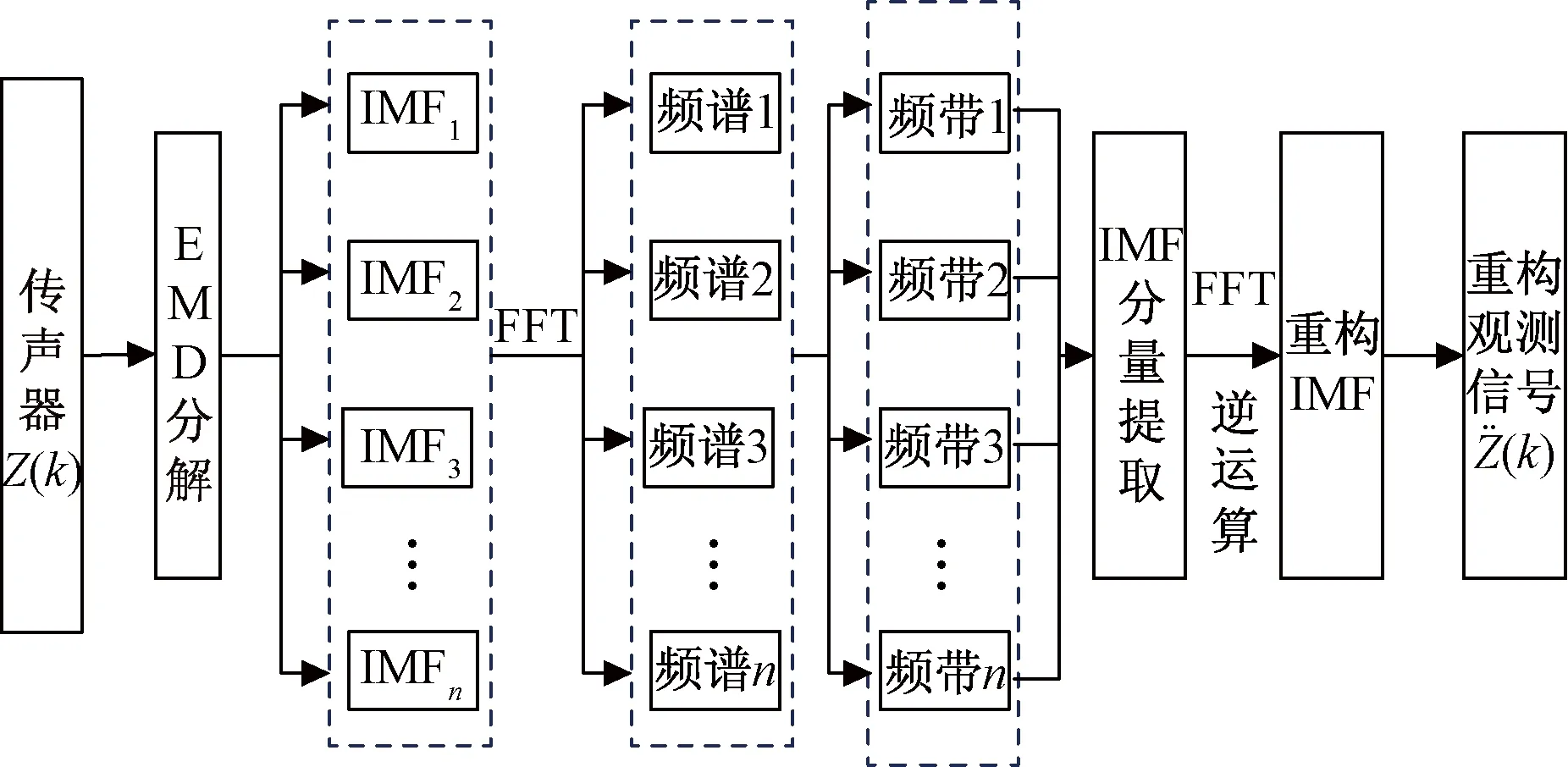
图3 声阵列EMD融合算法Fig.3 The EMD fusion algorithm of acoustic array
2 阵列信号特征提取与分类识别
2.1 MFCC阵列信号特征提取
MFCC属于声纹识别技术,文献[1]证明了MFCC对于低空声目标识别的有效性,本文结合海上实际环境及阵列声信号特征,提出以下三点假设:①目标声信号可用短时过零率、幅度特征、声道共振峰来描述;②目标声信号为空间点声源,球形传播,属于媒质振动传播模式;③目标声信号是有限带宽的频率声信号。如图4所示为本文基于上述假设的MFCC阵列信号特征提取算法。

图4 MFCC阵列信号特征提取流程图Fig.4 The array signal feature extraction flowchart for MFCC
(1)时域采样(预加重):此步骤主要是为了提升信号的高频分辨率,其滤波器结构函数(传递函数)可设为H(z)=1-αz-1(α∈[0.9,1]),其中α为加重系数,本文后续半实物仿真取值α=1。
(3)FFT离散功率谱计算:具体计算公式为
(3)
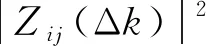
(4)
(4)归一化比例融合:首先对多元传感器Eij(Δk)进行归一化比例融合,具体计算如下:
(5)
(5)Mel滤波器:计算Eij(Δk)通过Mel滤波器的能量Si(j,Δk):
(6)
式(6)中:HΔk(j)为梅尔滤波器在Δk时刻内第j帧的传递函数。
(6)计算离散余弦变换(discrete cosine transform,DCT)倒谱:对Si(j,Δk)取对数,计算离散余弦变换得到一组系数,并去掉直流成分即可得到每帧MFCC参数。
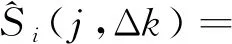
(7)
式(7)中:n为阵列信号每帧需要的MFCC特征参数个数,后续半实物仿真取n=15。
2.2 阵列信号DTW分类识别
目标声源信号具有的随机性,每个声源目标都具有不同的声信号特征。此外,声信号也受到环境因素的干扰,引起声信号特征参数的变化,从而降低目标的识别率,因此,在目标信号分类识别过程中,首先要对阵列观测信号进行时间规整,采用对输入的阵列信号进行伸长或缩短直到与标准模式的长度一致手法,这个过程就称为动态时间规整(DTW)。如图5所示,为本文阵列信号DTW分类识别流程图。
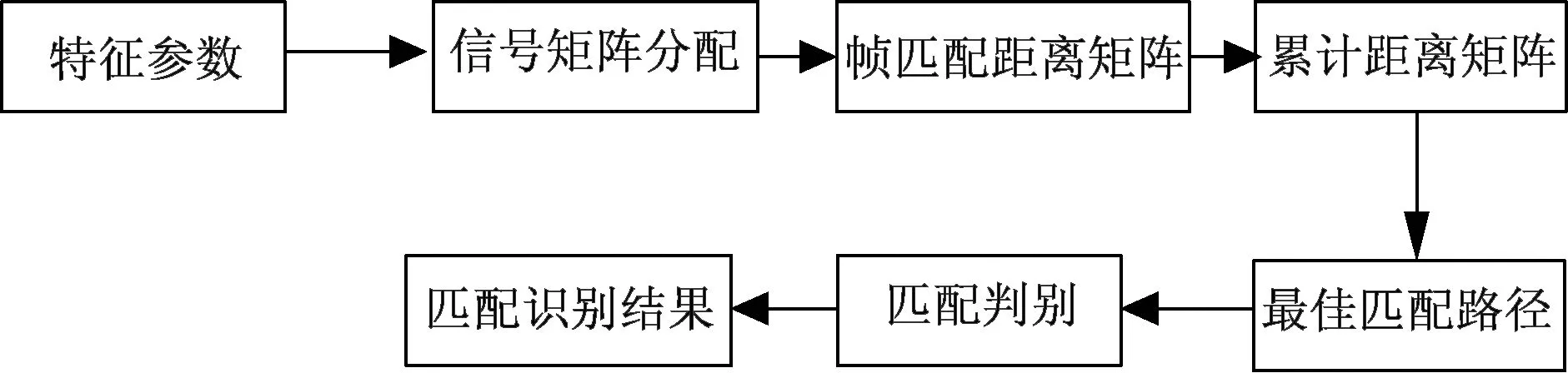
图5 阵列信号DTW分类识别流程图Fig.5 The array signal classification and recognition flowchart for DTW
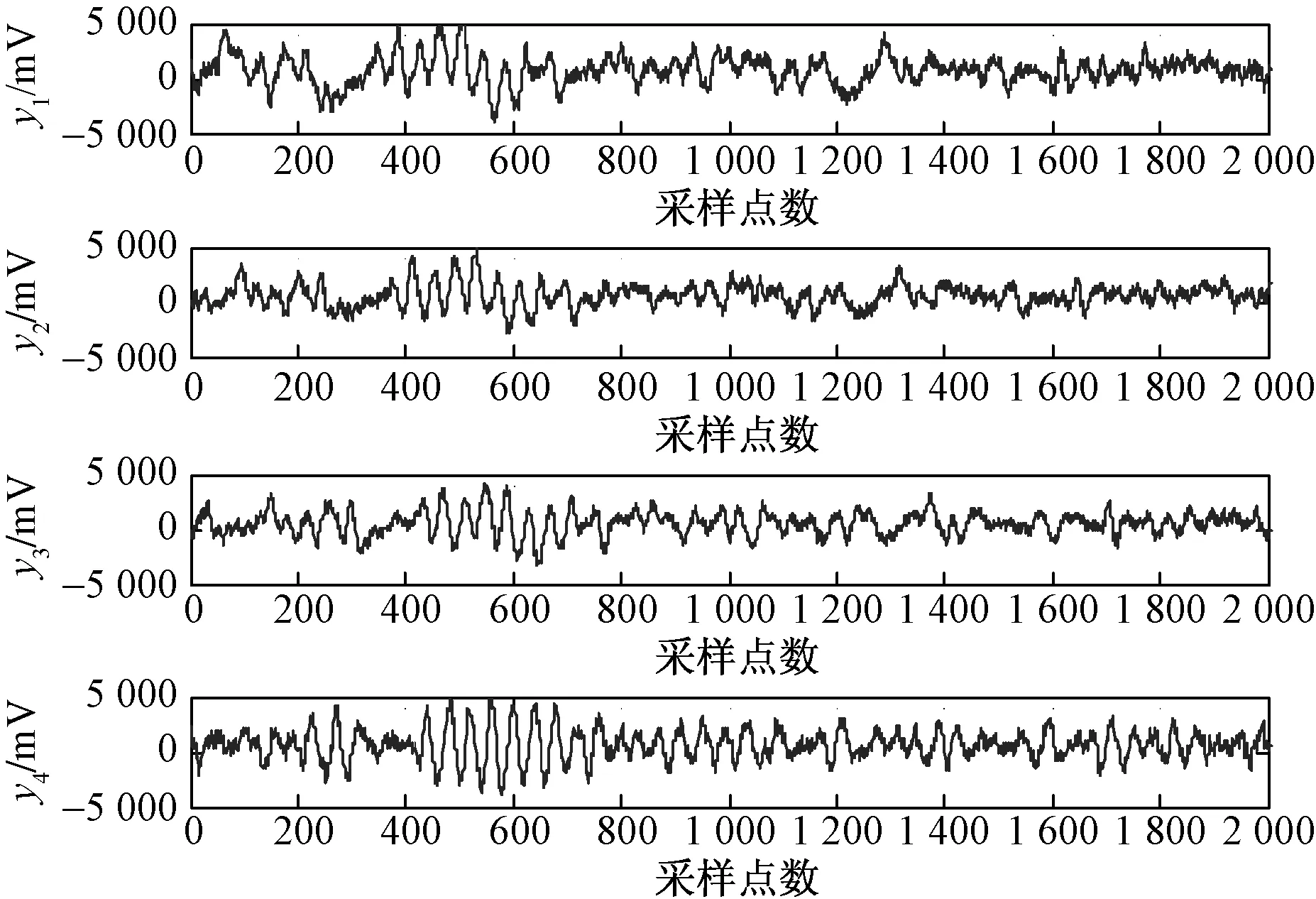
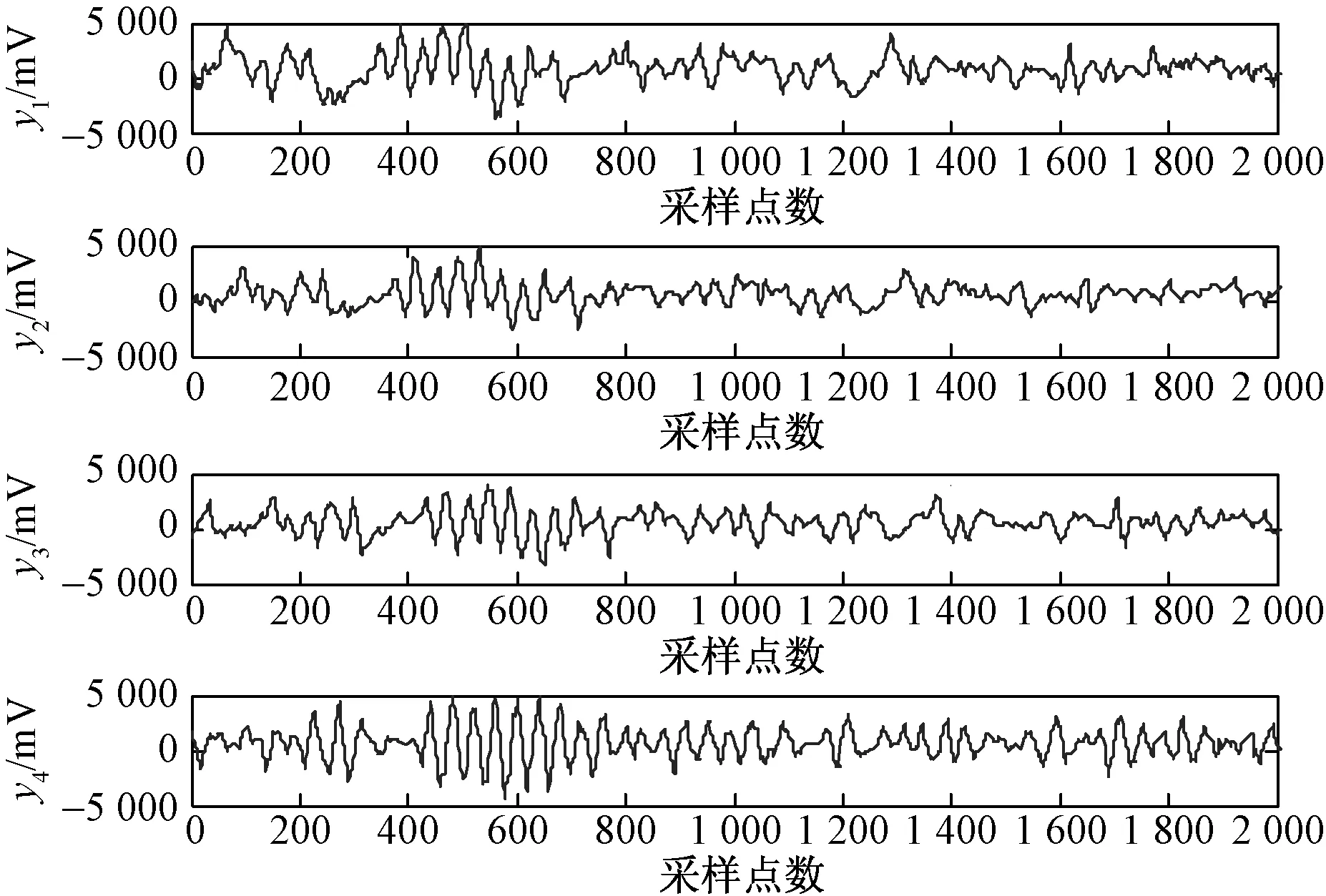
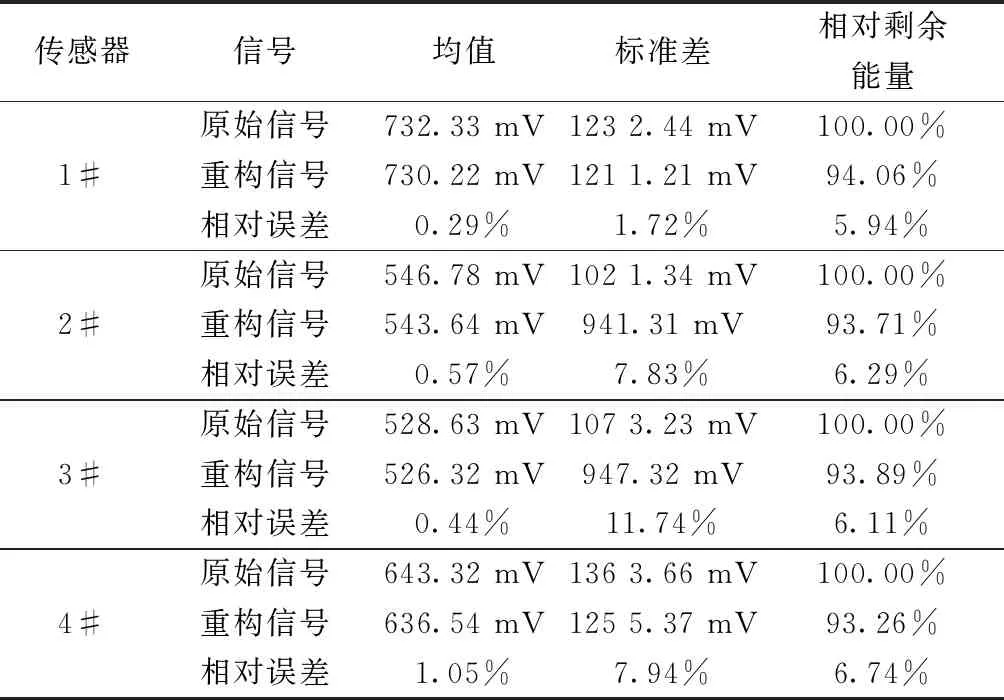
计算训练样本与测试样本间的距离,即模板匹配,此过程为DTW 算法。本文中,测试样本信号参数共有N帧矢量,取训练样本信号M帧矢量,M (8) 本文设计了四元阵列融合声源识别半实物仿真试验,如图6为四元声阵列试验平台,图7为试验布置示意图,声传感器型号为HY205,灵敏度为50 mV/Pa,采样频率为62.5 kHz,声阵列半径为0.5 m。试验中采集了3个不同型号的飞行器,飞行高度为200~300 m。每个样本点2 048个,样本时间为32.768 ms,在空中悬停、空中匀速运动、空中匀加速飞行等三种运动状态下分别采集样本数为30、40、50个作为样本总量。采用本文提出的四元阵列信号EMD融合及阵列信号特征提取与分类识别算法,开展半实物仿真试验。 图6 可变结构的声阵列Fig.6 The acoustic array of variable structured 本文采集了飞行器在上述三种运动状态下的阵列信号, 不失一般性,本节选取飞行器在匀速飞行状态下的阵列信号进行融合处理。如图8、图9所示为信噪比SNR=10 dB下某类型飞行器匀速状态下四路观测信号及EMD融合处理结果。对比融合处理前后阵列信号波形图可知,融合处理后信号有效抑制了高频信号的干扰,剔除了信号中的“毛刺”现象,同时也保持了原始信号的波形图,时域信号具有不失真性。 图7 声阵列试验平台Fig.7 The test platform of acoustic array y1~y4为1#~4#传感器信号图8 飞行器匀速状态下四路观测信号Fig.8 The four observation signals of the aircraft at a constant speed y1~y4为1#~4#传感器信号图9 飞行器匀速状态下EMD融合处理结果Fig.9 The EMD fusion processing results of the aircraft at a constant speed 表1所示为SNR=10 dB 原始阵列信号与IMF重构信号的数理统计表。本文从均值、标准差以及相对剩余能量值三个指标在时域上统计了阵列信号与重构信号的特征。可知,均值参数的相对误差在1%以内,信号的标准差参数至少提高了11.74%,融合处理后信号的相对剩余能量值在93.26%以上,从数理统计特征上证明了融合处理信号保持了原始信号的时域特征,为后续特征参数提取及识别分类奠定了有效基础。 本文在前文的研究基础上,采用相同的声目标识别硬件系统,硬件组成具体详见文献[17],在半实物仿真中,分别采用本文的特征提取及分类识别方法与文献[17]的方法进行对比,统计了两种算法的一次识别周期、识别率、样本数、训练数等信息,如表2所示。 表1 飞行器匀速状态下IMF重构信号的数理统计Table 1 The IMF mathematical statistics for reconstructed signals of the aircraft at a constant speed 由表2可知,同一类型飞行器在空中悬停、空中匀速运动、空中匀加速飞行等三种运动状态下识别率不同,其中空中悬停状态下飞行器的识别率最低,匀加速飞行状态下飞行器的识别率最高,这主要是由于在声源被动识别中,声能是主要参数特征,且在匀加速飞行状态下,目标声信号的特征更加丰富、明显。在相同样本及目标初始观测信号下,不同运动状态的飞行器本文算法相对于文献[17]算法,识别率提高了4%~17.5%,说明了本文算法在识别率上的优越性。然而由于本文算法采用了EMD融合处理及MFCC-DTC特征提取及分类识别技术,在计算的复杂度上明显增加,一次识别周期提升,计算量增加,随着单片机集成技术的发展,此类问题能够得到有效的解决。 (1)在阵列观测声源信号预处理中,本文给出了一种基于EMD的四元阵列融合算法,通过对三种运动状态下的飞行器阵列信号分析可知,融合处理后的信号在均值数理统计参数的相对误差在1%以内,信号的标准差参数至少提高了11.74%,相对剩余能量值在93.26%以上,证明了融合处理后信号保持了原始信号的时域特征,有效抑制了高频信号的干扰,剔除了信号中的“毛刺”现象。 (2)本文基于MFCC-DTW方法,设计了阵列信号特征提取与分类识别算法,通过半实物仿真试验,对三种运动状态下的飞行器进行了分类识别,对于不同运动状态下的声目标识别率不同,目标声能是主要参数特征,此外,在与前文的对比试验中,本文提出的识别算法识别率提高了4%~17.5%,证明了本文算法在识别率上的优越性,同时本文算法一次识别周期提升,计算量增加。 表2 三类飞行器在不同运动状态下的识别对比Table 2 The identification comparison of three types for aircraft under different motion states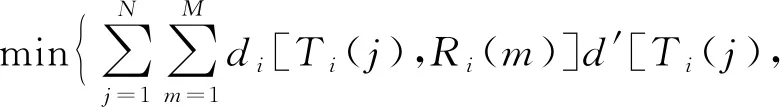
3 半实物仿真试验
3.1 试验基本条件

3.2 半实物阵列信号EMD融合处理

3.3 半实物阵列信号特征提取与分类识别
4 结论

