基于机器学习的心律失常检测模型研究
2020-10-30张文宇
杜 权,张文宇
(辽宁科技大学 计算机与软件工程学院,辽宁 鞍山 114051)
心血管疾病是中老年人群中常见的疾病之一,其死亡率已超过癌症等恶性疾病,占因病死亡原因构成的40%以上,已成为人类健康的第一杀手[1-2]。研究表明,在该疾病初期常伴随心律失常现象[3],因此心律失常的检测和诊断措施,对预防和治疗心血管疾病具有重要意义。
心电图(Electrocardiogram,ECG)是记录人体心脏电活动的可视时间序列[4-5],在临床上广泛用于心脏相关疾病检查,并形成了比较完善的ECG判断标准[6]。常规心电图诊断均由医生目测实现,既增加医生工作强度,其结果又严重依赖个体经验差异,进而影响心电图识别效果,极易出现漏检误检现象。为此许多学者尝试使用计算机的相关技术来实现对心电图自动检测,以充分利用医疗数据资源,提高诊断效率,从而预防心血管疾病的发生。
近十几年来,诸多心律失常检测的计算机方法被提出。例如:频域分析法使用频谱作为特征参数来对心律失常检测[7];小波变换法通过心律信号不同尺度上的变换规律来进行检测[8];经验模态分解法通过心电数据的时间尺度特征,来获得本征波动模式,然后进行筛选[9];循环谱分析法通过利用循环谱技术提取心电信号谱相相关系数作为特征进行检测[10]。以上这些传统心律失常检测的方法均是根据心跳信号设计特征,并将其输入到模型中进行分类,检测的准确率很大程度上依赖于专家经验的特征设计[11-12],其模型的可扩展性及自学习能力均受到很大限制。近几年来,深度学习已经在许多领域取得成功,在语音识别领域的发展已较为成熟。本文所研究的心律信号与语音信号相似,都是时序序列,因此,本文使用一维卷积神经网络(One-dimensional convolutional neural network,1D-CNN)的深度学习方法来检测心律失常,为医疗临床应用奠定基础。
1 心电信号集及其预处理
本文采用的数据集来自MIT-BIH心律失常数据库。该数据集已经过分段,每一段有187个数据对应着一个节拍的心跳。数据集将心律信号分成5个类别,各个类别特征如图1所示。N代表正常心跳、S代表室上型早搏、V代表心室早发性收缩、F代表心室搏动与正常搏动的融合、Q代表不可归类。
该数据集分为训练集和测试集。训练集中正常心跳的个数为72 471,室上型早搏的个数为2 223,心室早发性收缩的个数为5 788,心室搏动与正常搏动融合的个数为641,不可归类的个数为6 431。测试集中正常心跳的个数为18 118,室上型早搏的个数为556,心室早发性收缩的个数为1 448,心室搏动与正常搏动融合的个数为162,不可归类的个数为1 608。
如果直接使用该数据集来训练机器学习模型,就会出现“偏爱”某些数值较大的时间点,而忽略数值较小的时间点,最终降低检测准确率。为了消除某些时间点数值较大的影响,本文在训练机器学习模型之前对心电数据采用极差变换法进行归一化处理[13],以使各时间点的心电数值处于同一数量级。
2 支持向量机心律失常检测模型
支持向量机(Support vector machines,SVM)最初是为了解决二分类问题而提出的有效方法,无法直接解决多分类问题[14]。在心律失常检测中,5种类别的心律检测是一种多分类问题。如何使用SVM将二分类方法扩展到五分类方法,成为本文心律失常检测的重要研究内容之一。
SVM多分类处理的思想有两种:第一种是一次性解决多分类问题,将SVM的两分类思想应用到多分类中,对分类函数进行优化,构建一个多值分类模型,使模型具有直接处理多分类的能力。第二种是将多分类问题分解为多个二分类问题,构建多个二分类器组成一个多分类器。本文采用的是第二种思想,构建多个二分类器一对一方法来解决心律失常多分类问题。
SVM一对一多分类方法最早是由Knerr提出的,也是目前较为常用的多分类方法。对于本文心律失常五分类问题,建立检测模型的主要思想是:在任意两类别之间构建一个SVM二分类器,一共需要10个分类器;生成每一个二分类器,只需要训练心律失常数据中某两类数据,然后组合得到的10个二分类器就能解决该五分类问题。在训练i、j两类样本间的二分类器时,应用的核心数学模型
式中:w和b则是确定超平面的参数;yi表示类别标签;φ(x)表示核函数;C代表惩罚因子,用于控制分错样本带来的损失;σi代表松弛因子,其可使分类界限存在一定范围的弹性。
式(1)是通过样本点与超平面的几何距离最大化转化而来的。据此,分类问题即转化为,在允许存在一定误差的情况下,求解最优的w和b,进而确定最优分类超平面。由于上述问题求解复杂,故运用拉格朗日乘子将其转换为对偶问题,进而求解得到i和 j两个类别之间最优分类函数
式中:αi表示样本对应的拉格朗日乘子,这些不为零的αi就是样本所对应的支持向量。
分类器构造完之后则进入分类和投票决策环节。对测试集样本xi依次使用所有二分类器进行判别,如果fij(xi)>0,则正例得一票,如果fij(xi)<0,则负例得一票,当所有二分类器都遍历完之后,根据得票的情况来判断待测样本xi所属类别。图2表示心律失常信号五分类SVM的判别过程,从分类器到类别之间的连线表示该样本可能被判定的类别。最后输出得票最多的类别。
因为本文所用的数据样本为非线性可分的样本,所以需要通过核函数来实现从低维到高维空间的映射。SVM核函数的选择对于其检测心律失常的性能表现有着至关重要的作用,应用不同的核函数,检测效果有很大差异。常用的核函数有:线性核函数、高斯核函数、多项式核函数、sigmoid核函数。
在心律失常分类的相关分析中,通常使用准确性(ACC)、特异性(SPE)和敏感性(SEN)作为评价模型性能的指标,计算式如下
式中:TP代表真阳性;TN代表真阴性;FP代表假阳性;FN代表假阴性。ACC是被正确分类的心律所占的比例。SPE是正常心律被正确分类所占比例。SEN是非正常心律被正确分类所占比例,衡量模型对病例的识别能力。
目前如何针对特定领域数据选择合适的核函数仍未有定论,故本文对常用的4种核函数进行实验,实验结果对比如表1所示。选择高斯核函数,测试集上检测准确率、特异性和敏感性分别为85.28%、85.08%和86.22%,检测效果最优。图3为SVM多分类混淆矩阵,从中看出只有类别V分类正确率较高,S、Q两种类别中较多样本被误判为N类,造成此结果的原因在于心电数据通过高斯核函数的高维映射之后,仍不可避免地存在许多样本线性不可分现象,致使检测准确率不尽如人意。
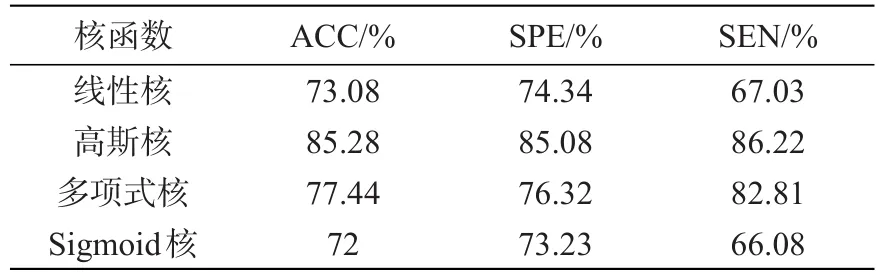
表1 SVM不同核函数各指标比较Tab.1 Index comparison of different kernel functions
3 随机森林心律失常检测模型
随机森林(Random forest,RF)算法是一种集成学习方法,其基本结构单元是决策树,将多颗决策树集成在一起进行学习,输出得票最多的结果用于分类与回归。随机森林检测心律失常的流程如图4所示,分为4个步骤:(1)对心律失常数据训练集进行有放回地抽样,产生130个大小为1 000的数据集;(2)从每个心律信号样本的187个特征中随机抽取150个特征;(3)生成130个特征维度为150的最优分割决策树;(4)依据每一棵分类决策树输出的检测类别,采用少数服从多数的投票方式输出得票最多的类别作为最终检测结果。
本文对心律失常检测效果影响较大的两个参数——树的个数与深度进行调整实验,结果如表2所示。经过实验对比,建树的个数与深度分别设置为130和30时,心律失常检测效果比较理想,在测试集上准确率达到88.33%。
最终检测结果的混淆矩阵如图5所示。N、S、F、Q类别识别准确率均高于支持向量机模型。然而,实验过程中发现,该模型在训练集上的准确率接近98%,远高于在测试集上的准确率,这说明随机森林模型在心律失常检测上存在较为严重的过拟合现象,故模型的泛化能力有待进一步提高。同时,测试集上的88.33%准确率说明易造成漏诊误诊问题,故该模型还不能较好地应用于心律失常检测实践。
4 1D-CNN心律失常检测模型
卷积神经网络最初大多被应用在图像处理[15]、目标检测[16-17]等方向,网络的输入是图像原始像素构成的二维矩阵,网络卷积核、特征图等也都是二维结构。随着卷积神经网络应用范围的逐步扩大,现在也被应用在数据序列[18]处理领域。
心电信号虽然是二维数据,但其中一个维度表示时间序列,无需参与卷积处理,因此,输入是一维向量,网络内的卷积核、特征向量也是一维结构,因此称为1D-CNN模型。它包括卷积层、池化层、过渡层(Flatten层)、全连接层(Dense层)、多分类层(Softmax层)等5个基本结构。
卷积神经网络的卷积层和池化层完成关键的数据特征提取功能。卷积层由若干个卷积核组成,每个卷积核参数是由反向传播算法反复迭代确定的。卷积层的表达式
式中:为第l层的第i个卷积核的特征向量;k为卷积核的大小;第l层的第i个卷积核的权重;f()为非线性激活函数。
池化层的作用是特征筛选,以减少特征向量,从而降低参数数量,避免过拟合。常规的池化方法包括最大池化和平均池化两种方式,邻域内特征点选择最大的特征为最大池化,邻域内特征点取平均值为平均池化。由于最大池化能选择较明显的特征,保留更多心律纹理信息,因此本文选择最大池化方法来进行特征筛选,即按照步长将上一层的输出划分多个区域R,选取区域R内所有特征点的最大值为区域R的主值,即
Flatten层通常用在卷积层到全连接层之间,把上一层多个输出平展为一维长序列。全连接层(Dense层)的作用有两个:第一,是将前面提取的特征做非线性变换,然后提取这些特征之间的关联;第二,把输出长度降到与心律类别的个数一样,便于之后的五分类。全连接层里输入与输出的关系为
式中:WT表示全连接层的权重;b表示偏置。
全连接层包含多个神经元,该层每个神经元都与上一层每个节点连接,因此该层的权值参数是最多的。
Softmax层用于多分类结果的输出,其每个类别的概率计算式为
式中:xi为Dense层的输出;n为心律类别的个数。它将多个神经元输出映射到(0,1)范围内,通过pi大小来进行多分类,当pi最大时,此时的类别为第i类。
1D-CNN心律失常检测模型的结构与各层网络设定如表3所示。表3中输入的大小和心律数据一致为187,神经元的个数设置为5,卷积核的大小设置为5,步长为1,经过每个卷积层和池化层之后输出的数据维度不断减小,然后经过Flatten层将数据平展为一维,方便之后的Softmax层进行五分类操作。Conv1D表示一维卷积层,网络共使用三层Conv1D来提取输入序列的特征。考虑到经过卷积和池化之后不可避免地存在信息丢失的问题,因此本文在Add layer 1与Add layer 2处引入了残差结构,将前几层的信息与当前信息进行越层连接,以此保证信息的完整,提高模型的学习效率。传统卷积神经网络的激活函数是Sigmoid,因为该函数曲线左右两端趋近于平稳,易在误差深层传播中产生梯度消失问题,致使模型寻优易陷于局部最优,故本文所建立的1D-CNN模型中其激活函数选择为Relu,其在零坐标处进行明显分段,进而有效地提高了模型寻优速度及范围。
该模型的超参学习率可通过对比实验确定。学习率分别设置为0.1、0.01、0.001、0.000 1,实验结果如表4所示。当学习率为0.001时,各指标最高。在此基础上,迭代次数设置为200时,准确率基本趋稳定。该模型准确率趋势曲线如图6所示,迭代次数小于50时,随着模型参数的大幅调整,准确率快速上升;迭代次数介于50到150之间时,因模型的损失函数已趋于极值附近,故参数调整幅度较小,准确率缓慢提升;迭代次数介于150到200之间时,准确率已趋于平稳,在迭代次数为200时,测试集上的准确率达到97.17%,此时结束迭代。训练集和测试集的准确率曲线高度吻合,说明该模型具有良好的泛化能力。

表3 1D-CNN各层网络参数Tab.3 1D-CNN network parameters of each layer

表4 1D-CNN中不同学习率实验结果Tab.4 Experimental results of different learning rates in 1D-CNN
该模型在测试集上的分类混淆矩阵如图7所示。5种类别识别率均高于支持向量机模型,N、S、V、Q类别识别准确率均高于随机森林模型。其实验结果对比如表5所示,传统模型SVM和RF检测的准确率、特异性和敏感性均没有1D-CNN高。以上实验结果及分析表明,1D-CNN模型在心律失常检测问题上,其能更新神经元解决非线性问题,自动提取心律数据的特征信息,并且其模型比较容易建立、具有较高的准确率及较好的泛化能力。因此,1D-CNN模型已可应用于心律失常检测实践。
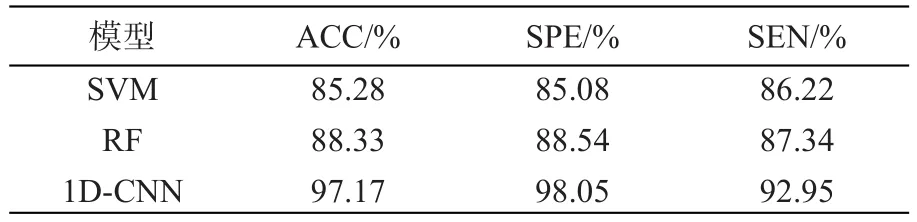
表5 3种模型实验结果Tab.5 Experiment results for three models
5 结 论
心律失常检测是预防心血管疾病的有效手段,利用计算机技术对其进行精确检测具有重要的临床意义。本文基于MIT-BIH心律失常数据集,使用一种深度学习的方法对5种不同类型的心律进行自动检测,并使用SVM、RF作对比实验。实验结果表明,1D-CNN模型能自动提取心律特征并且具有良好的检测性能,准确率、特异性和敏感性分别达到97.17%、98.05%和92.95%,具有较好的泛化能力,效果明显好于支持向量机与随机森林模型,已达到实际医疗临床应用要求。
