基于串行式融合的GA 与PSO 优化算法研究
2020-10-21李士心刘小钰
张 海,李士心,刘小钰
(天津职业技术师范大学电子工程学院,天津 300222)
当今科技发展形势下,单一智能优化算法已不能满足当下出现的大规模、多变量、多约束、多极化及非线性等复杂的问题,因此智能算法融合应运而生。遗传算法(genetic algorithm,GA)由美国 Holland 教授基于生物界优胜劣汰的自然选择现象,于1975 年提出的用于解决优化问题,又称进化算法,其过程简单,多用于函数优化、数据挖掘、图像处理等[1]。但GA 算法仍有局限性,如在多约束条件下收敛速度减慢,收敛精度不高等[2]。而粒子群优化算法(PSO)是一种通过对鸟类觅食过程的模拟进行优化的算法[3],其原理简单,用速度位移公式迭代即可实现,此外需调节的参数较少,粒子也具有记忆性,多用于组合优化、传感器网络、车辆调度等[1]。但随着智能优化算法的不断完善,其易陷入局部最优,难处理多维问题的缺点也暴露出来[3]。近年来,已有多位学者将其融合,主要形式有3种,分别为并行式混合,如Benvidi 等[4]提出用GA-PSO并行混合优化ANN 参数,并且利用该算法处理了吸光度数据和分析物浓度的关系,取得了很好的效果[1,4];嵌入式混合,如孙丽平[5]将 GA 算法嵌入 PSO 中用于改进蒙特卡罗滤波和递推贝叶斯理滤波结合的粒子滤波样本退化问题,并且实验证明了其有效性[1,5];串行式混合,如Zhang 等[6]提出在GA 算法完成后叠加PSO 来实现聚类,然而效果虽可实现,但依旧存在收敛速度慢等问题[1,6]。本文研究串行式混合下GA 与PSO 巧妙结合的原理,提出了一种改进GA 的串行结合方式,在保证计算精度的前提下,提高收敛速度。
1 遗传算法(GA)
遗传算法使用群体搜索技术,其所操作的对象以及问题的解均为种群。通过对当前种群施加一系列遗传操作来产生新一代种群,包括优选强势个体的选择、个体间交换基因片段产生新个体的交叉以及某位基因信息突变而产生新个体的变异等。以此逐步迭代进化直到产生最优解[7]。
1.1 变量初始化
群体规模太小不利于遗传性能的提升,规模大可减小其陷入局部最优,但也意味着复杂度提升,根据前人工作经验,此类问题的染色体数目设为NP=100较为合适。每条染色体上的基因数D=10,最大遗传代数G=1 000,交叉概率太大虽可增强搜索新区域的能力,但高性能模式易被破坏,故设Pc=0.8,而变异是为了增加种群多样性,在整个遗传算法中属辅助操作,变异概率过大会使得搜索的随机性增大[7],故设Pm=0.1,根据适应度函数要求可令基因值上下限分别为Xs=20,Xx=-20;并为初始种群和子种群赋空间,均为[D,NP]型,再利用下式随机获得初始种群
f=rand(D,NP)*(Xs-Xx)+Xx
1.2 染色体排序
根据适应度将各染色体升序排列,具体操作如下:①将各染色体的D 位基因值分别代入适应度函数,得出对应的适应度函数值。②利用sort 函数依据适应度函数升序的方式将各染色体排序。
1.3 遗传操作及种群合并提取
1.3.1 采用君主方案进行选择交叉操作
将最小适应度值对应的染色体确定为君主染色体;确定每次交叉点个数为NoPoint=round(D*Pc),Pc位为交叉概率;并利用randint 函数生成一个[NoPoint,NP/2]型,元素均为1-D 内整数的矩阵PoPoint,用于提取交叉基因的位置。此时再将以上排好序的染色体组赋予子种群,并对子种群进行交叉操作:将君主染色体赋在NP 条染色体的奇数位,偶数位保持不变,再根据交叉点个数Nopoint 进行交叉。各染色体由前向后两两成对,每对染色体要交叉互换Nopoint 次,交叉互换位则从矩阵PoPoint 中选取。
1.3.2 基于概率的变异操作
逐个染色体、逐个基因进行遍历。对于染色体上基因,若rand 随机生成数小于变异概率,则该基因按如下方式变异
nf(n,m)=rand(1,1)*(Xs-Xx)+Xx
此处也可将粒子群算法的位置更新思想融入到变异算子[8]。
1.3.3 染色体重排序
对进行过遗传操作的子种群按照与以上相同的方式进行升序排列,再将排好序的子种群与原排好序的父种群的适应度函数值及其染色体组进行合并,并重新升序排列。取前NP 个染色体及其适应度函数值作为优化结果,最小的适应度函数值作为当代最优值。
1.4 迭代寻优
迭代上述过程G 次,将G 个适应度函数值绘成曲线。
2 粒子群算法(PSO)
粒子群算法通过对鸟类觅食过程的模拟,寻找最优解,可用于很多优化问题[9-10]。PSO 算法中的每个粒子肩负2 个值:位置和速度。粒子的位置表征可行解,速度用来决定粒子的运动方向和距离。此外,所有粒子通过跟踪自身经验极值和全局极值来更新自己的位置和速度[7]。
2.1 变量初始化
为与其他算法进行控制变量式对比,粒子群的种群规模也设为个数N=100,其维数设为D=10,最大迭代次数T=1 000;对于加速常数,即学习因子c1 和c2,根据粒子速度和位置的更新公式可知,这2 个学习因子分别调节粒子向个体最优极值pbest 和全局极值gbest 方向飞行的步长,也即决定粒子运行轨迹的个体经验和群体经验,一般设置c1=c2=1.5;惯性权重可控制粒子向新区域的探索能力和在原区域深度开发的能力,设w=0.8 时可使该算法有更快的收敛速度[7];根据适应度函数要求可确定粒子运动范围,即位置的最大值Xmax=20 和最小值Xmin=-20,另外为了避免粒子飞过优秀区域或是陷入局部最优,设定速度最大值Vmax=10,最小值 Vmin=-10。
2.2 种群初始化
种群初始化包括种群个体,个体最优位置和最优值以及全局最优位置和最优值。个体包含位置x 和速度 v 两个值,且矩阵 x 和 v 等型,均为[N,D]型,x =rand(N,D)*(Xmax- Xmin)+ Xmin,v 的生成方式与此类似,这样初始化得到每个粒子的位置和速度。对于个体最优位置p,由于前面工作已进行了初始化,只需将粒子的初始化位置赋予最优位置p,而个体最优值pbest 也可由初始位置x 代入适应度函数求得。对于全局最优位置g 和最优值gbest,将各个个体最优pbest与全局最优初始值比较,较小者作为全局最优值并将于此对应的个体最优位置作为全局最优位置。
2.3 种群更新
种群初始化后,需更新种群并不断进化才可实现寻优。包括更新个体的最优位置和最优值,全局最优位置和最优值,各粒子的位置和速度以及边界条件的处理。对每个粒子都要做如下更新。
2.3.1 个体的最优位置和最优值的更新
将初始化的位置代入适应度函数,将求得的函数值与对应pbest 值比较,若该函数值较小,则将该粒子的位置放于对应个体最优位置矩阵p 中,暂当该粒子的个体最优位置,且此时对应的个体最优值pbest 也更换为该函数值。
2.3.2 全局最优位置和最优值的更新
将更换后得到的pbest 值与已初始化得到的全局最优值gbest 作比较。若更换后的pbest 值小于初始化的gbest 值,将更换后的pbest 值对应的位置放入全局最优位置矩阵g 中,暂当全局最优位置。
2.3.3 粒子的位置和速度的更新
对该粒子的速度和位置做出更新,公式如下

式中:j 为某个粒子,j 取(1,N)。
在速度更新公式中,w*v(j,:)为粒子维持原先速度的惯性;c1*rand(p(j,:)-x(j,:))为粒子向个体最优位置靠近,即为自我认知;c2*rand(g-x(j,:))为粒子向全局最优位置靠近,即社会引导[7]。
此外,对于惯性权重w 可采用非线性动态自适应进行更新,以便很好地进行开发能力与探索能力的分配。
2.3.4 对边界条件的处理
对于该粒子上的每一位元素(位置、速度),若存在大于最大速度或小于最小速度的情况,即飞行速度不合理,则将该位的速度重新规范在规定的最大最小速度区间内,即 v=rand(Vmax-Vmin)+Vmin。同理,若存在大于最大位置或小于最小位置的情况,即超出了边界,将该位的位置规范进先前的区域内,即x=rand(Xmax-Xmin)+Xmin。
2.4 遍历寻优
当所有粒子遍历上述操作后,即完成了一代的更新。将这一代所得的全局最优值和最优位置进行记录。将遍历T 代后所得的T 个全局最优值绘制成曲线。
3 GA 与PSO 的串行式融合
3.1 先PSO后GA
先PSO 后GA 的结合方式使种群先经PSO 优化,可以得到很多接近最优解的个体,此时再利用GA 的交叉变异去改善种群,提升种群多样性,这样在很大程度上避免了陷入局部最优,并且可以快速准确地在接近最优解的个体中寻得最优值,实现全局快速寻优[11-12]。
初始化部分包括群体粒子个数、染色体数、粒子维数、基因数,粒子群最大迭代次数、遗传算法最大遗传代数;2 个相等的学习因子;限定粒子空间位置的最大值、最小值;约束粒子飞行跨度的速度最大值、最小值,惯性权重;遗传算法的交叉、变异概率以及初始种群和子种群赋空间。
先执行粒子群算法部分,借鉴单独使用PSO 的方式,可得到迭代T 代后的粒子群最优位置矩阵p。由于PSO 部分与GA 部分的初始矩阵互为转置关系,故此处只需要将PSO 优化后得到的最优位置矩阵p 转置后作为GA 的初始矩阵,即简单实现了PSO 与GA 的串行混合,此处的GA 部分也与前面单独使用GA 部分保持一致。最后将GA 迭代了G 代后,得到的各适应度值绘制成曲线。
3.2 先GA后PSO
对于先遗传算法后粒子群算法,也可借鉴以上做法,将单独使用GA 部分的执行结果作为单独执行PSO 部分的初始矩阵,也可实现GA 与PSO 的简单串行混合。初期采用GA 将随机初始化的粒子群个体进行优化,用以提高计算精度,而后采用PSO 向最优解均匀移动来提高收敛速度[13-14]。此处,本研究对GA 的优化方式做了进一步改进,以改良遗传算法在全局寻优方面的性能,即将随机初始化的粒子群个体的位置及速度经GA 优化一遍直接交由PSO 执行。
3.2.1 初始化
采用GA 对每个粒子的初始位置、速度、个体的最优位置、个体最优值进行优化,并将优化后的值作为执行PSO 部分的初始值。将单个粒子初始位置、速度、最优位置、最优值矩阵合并为A,并利用sortrows 函数将整体按照初始单个粒子最优值(适应度值)升序排列为B。
将适应度值低的前一半粒子直接放入下一代,将后一半粒子放入Cross 中进行一系列遗传操作。
①基于概率的交叉操作。若由rand 函数随机生成的数小于交叉概率且利用randint 函数生成的一行一列数组中的某位元素为1 时,则将后一半粒子两两成对地把元素为1 对应位交换,实现基于概率的交叉。
②基于概率的变异操作。将粒子总数与变异概率的乘积作为迭代上限,并将粒子维数与变异概率之积作为要变异的位数,再利用randint 函数从[1,N/2]和[1,D]中随机选取要变异的粒子体积元素位进行取反变异,反复迭代实现基于概率的变异操作。
3.2.2 遗传算法优化
将更换后得到的pbest 值与已初始化得到的全局最优值gbest 作比较。若更换后的pbest 值小于初始化的gbest 值,将更换后的pbest 值对应的位置放入全局最优位置矩阵g 中,暂当全局最优位置。
3.2.3 Cross部分的更新
①将进行过交叉变异的位置代入适应度函数中,将其函数值放入Cross 中粒子最优值处,然后与原B中后N/2 个粒子的对应值比较。若该函数值小于B 中对应值,则将该函数值对应的位置放入Cross 对应最优位置矩阵,否则将B 的该值对应的最优位置放入Cross 对应最优位置矩阵处。
②经过以上更新后,Cross 的最优位置矩阵处全部为各粒子的最优位置,再将这些最优位置代入适应度函数,所得值放入对应最优值处,此时得到Cross 的最优位置及最优值。
③将Cross 与B 中后半部分进行合并,再次利用sortrows 函数对最优值进行升序排列,将排序所得前N/2整体投入下一代与原来直接进入下一代的粒子群体组成由GA 优化后的粒子群,也即执行PSO 的初始值。
3.2.4 粒子群算法的对接
执行PSO 部分包括依次迭代更新个体最优位置、最优值,更新全局最优位置、最优值,更新个体的位置、速度、边界条件的处理以及记录历代全局最优值等,均与单独执行PSO 部分完全一致。
该结合方式相对于以上所述的先单独执行上文的GA 部分再单独执行上文的PSO 部分,优势是显而易见的,该结合方式不需要GA 多次迭代,只需一次优化即可,节省了大量寻优时间,同时全局寻优性能也有所提升。
4 Matlab 仿真测试与结果分析
4.1 基准测试函数
算法的性能比较往往需要基准函数来验证,本研究中选取了 Sphereh 函数,Rastrigrin 函数,Ackley 函数3 个常用的基准测试函数[15]。
(1)Sphere 函数

该函数在xi=0 时取得最优值0,函数曲面平滑,对称,单峰。
(2)Rastrigrin 函数

该函数在xi= 0 时取得最优值0,为非线性多峰值函数,具有极多局部最优点,极难优化。
(3)Ackley 函数

该函数在xi= 0 时取得最优值0,为多峰值函数,具有较多的局部最优点。
4.2 各优化算法的函数测试结果及分析
本研究要比较的算法分别为GA,PSO,PSO-GA,GA-PSO,*GA-PSO(改进GA-PSO)。本实验在Matlab 环境下,利用3 个基准函数对5 种算法分别验证,将每个函数的5 种寻优过程置于同一比例图中,分别如图1—图3 所示。此外,为便于对其性能进行对比,还将各算法在各函数上的平均目标函数值及平均收敛迭代次数值绘于同一表中,平均目标函数值及平均收敛迭代次数对比如表1 所示。

图1 5 种算法在Sphereh 函数上的寻优过程比较
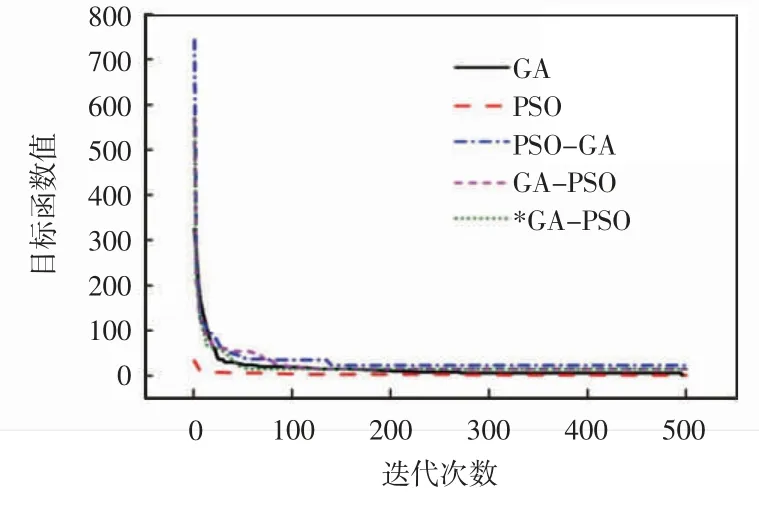
图2 5 种算法在Rastrigrin 函数上的寻优过程比较

图3 5 种算法在Ackley 函数上的寻优过程比较

表1 平均目标函数值及平均收敛迭代次数对比
由图1 和表1 可知,上述5 种优化算法的平均目标函数值均达到了很高的精度,而且其迭代收敛次数也均在100 代以内。由于Sphere 函数平滑、单峰且无其他局部极小值,因而PSO 的易陷入局部极值的缺点并未显露,反而利用其原理简单、参数少、粒子具有记忆性等优点,使寻得的最优值优于GA 算法。混合算法相对于PSO 在计算精度和收敛速度上均有所提升,其中PSO-GA 表现最优;还可以看出,*GA-PSO 相对于GA-PSO 计算精度相差不大,但由于改进GA 使用了对随机初始粒子优化次数锐减的方法,进而也相对提高了*GA-PSO 的收敛速度。
由图2、图3 和表1 可知,对于多峰函数而言,以上单优化算法的缺点被暴露,与此同时,融合算法的优势也更加明显。GA 算法由于其操作的盲目无方向性,使得收敛迭代次数居高不下,但其计算精度方面的性能却较为优秀。PSO 虽早早收敛,但却使其陷入了局部最优值。对比PSO 与GA-PSO 发现,前期经GA 的迭代,已在全局范围内寻得次优解,此时再利用PSO 均匀朝最优解移动的特点,使得GA-PSO 收敛精度及收敛速度均有所提升,但可以发现提升效果并不明显,这是由于前期GA 在迭代过程中以及后期PSO在移向最优值的过程中,它们的缺点依旧存在,使得收敛精度和收敛速度并没有急速提升。
对比GA 与PSO-GA 发现,种群先经PSO 优化,可以得到很多接近最优解的个体,此时再利用GA 算法的交叉变异去改善种群,提升种群多样性,这样可以在很大程度上避免了陷入局部最优,并且可以快速准确地在接近最优解的个体中寻得最优值,实现全局快速寻优,由以上实验结果发现,对于多峰函数优化问题,PSO-GA 表现尤为突出,无论是收敛精度还是收敛速度,相对于GA 算法均有明显提高。
此外,对比 GA-PSO 与 *GA-PSO 发现,*GA-PSO相对于GA-PSO 计算精度相差不大,但由于改进强化后的GA 算法对随机初始粒子只实施一次优化便交由PSO 去向最优解均匀移动,在一定程度上提高了*GA-PSO 的收敛速度。
5 结 语
GA 算法的交叉变异等操作可以极大丰富种群的多样性,但多约束情况会使得整个迭代过程变得漫长,求解精度也远远不够,本研究中对GA 算法的优化方式提出改进,使得其优化能力极大提升,优化次数有效减少,收敛速度也明显提高;粒子群算法利用其均匀朝着最优解移动的特点,可以在初步优化后得到很多接近最优解的个体,但面临多维问题时依旧会有陷入局部最优值的可能。本研究对以上单一算法的串行式融合,有效避免了各自的弊端,并成功地结合了各自的优势,使得求解精度、收敛速度及全局稳定性均有极大提升。此外,为了探索研究出效果更佳的优化算法,课题组下一步要做的工作是将粒子群算法的位置更新思想融入到变异算子,将惯性权重w 采用非线性动态自适应进行更新等。
