基于语料库的词法能产性量化研究
2020-10-20刘思凡
刘思凡

摘 要:为了探讨词法能产性与日本留学生词汇习得之间的关系,本文采用语料库的方法,基于“BCC北京语言大学现代汉语语料库”,对汉语中类词缀“家”内部派生的能产性进行量化研究,又进一步考察了“N+家”的派生,并将结果与“北京语言大学HSK动态作文语料库”中日本留学生使用“家”的情况进行对比。最后根据以上数据提出假设:对于词法能产性高的派生词,留学生使用情况普遍较多,习得情况较好,反之亦然。在能产性相同的前提下,构词数量多的派生词,日本留学生使用情况普遍较多,习得情况较好,反之亦然。
关键词:词法能产性 “家”类词缀 语料库 词汇习得
引言
日本作为同属汉字文化圈的国家,日语和汉语有许多相似之处,日本留学生学习汉语能发挥积极的正迁移作用。中日两国都有“家”的概念,且又以同一字形做标记,随着语义空间的拓展,“家”逐渐语法化,由单纯的地点名词拓展出了表示某一类人的类词缀用法。“家”根据前置语素的不同可划分出不同的词法模式,而不同的词法模式的词法能产性也不尽相同。构词法对二语学习者的词汇习得具有很大帮助,进而影响文本阅读水平的提升,因此词法能产性的高低对留学生词汇习得的影响同样也值得研究。本文将借助BCC文学语料库对汉语“家”派生词的能产性进行量化研究,再将统计结果与HSK动态作文语料库中日本留学生使用“X+家”的情况进行对比分析,探讨词法能产性与词汇习得之间的关系。
一、研究思路及方法
本文为量化研究,通过BCC文学语料库计算类后缀“家”内部派生的各类能产性系数,具体操作步骤如下:首先,统计各类鬼类后缀只出现一次的词语数量(Hapaxes),记为n1;第二步,统计各类“家”类后缀词频总和,记为N;第三步,统计各类“家”类后缀构词总数;第四步,根据Baayen&Lieber(1992)提出的P=n1/N公式计算n1在N中所占比例,即可得出家类后缀内部的各类能产性系数,并进行排序;最后,在HSK动态作文语料库中按“词语搭配”检索“家”作为类后缀的语料,按照不同词法模式进行分类,并对照能产性排序,分析能产性系数与词汇习得之间的关系。
二、类词缀“家”内部的词法能产性差异
首先计算“X+家”内部的词法能产性系数,“家”的次级词法范畴可分为“N+家”、“A+家”、“V+家”。统计结果如表1所示:
根据表 1 的统计结果显示,“N+家”、“A+家”和“V+家”的能产性系数分别为0.0029、0.0025和 0.05。由此可见“A+家”的能产性系数最高,“V+家”的能产性系数最低。
此外,Baayen(1992)指出,确定一个词法加工过程的能产性,除了计算其能产性系数之外,还必须考察其所构成词语的数量,两者互为补充。这一能产性被称为“总体能产性”。因此,综合这三类词法加工类型的能产性系数及义构词数量,我们可以得出类后缀“家”内部的词法能产性的排序,综合以上统计结果,我们可以得出以下结论:
在类后缀“家”的派生中,“A+家”与“N+家”的派生相对能产,构词能力丰富,“V+家”的派生相对不能产。类后缀“家”的内部词法能产性排序依次为PA+家> PN+家> PV+家,另一方面,類后缀“家”的构词总数排序依次是N1N+家> N1V+家> N1A+家。综上考察了类后缀“家”内部的词法能产性差异,能产性排名与构词数量排名出现了不一致的情况,为进一步研究类词缀“家”的能产性对学生词汇习得效果的影响,接着对构词数量最多的“N+家”进一步细分,分析其能产性的内部差异。
三、“N+家”内部的词法能产性差异
根据在BCC文学语料库中检索出的“N+家”的词,按照名词词基和造词语义的不同,三级词法范畴可划分为“学科名词+家”、“领域名词+家”、“普通名词+家”和“贬义名词+家”。其中“学科名词+家”表示在某学科的具有专业知识的人,“领域名词+家”表示擅长某领域或在某领域具有一定成就的人,“普通名词+家”表示具有某种特质或某种倾向的人,以及“贬义名词+家”表示从事某种不好活动的人;其次分别统计语料中三级词法范畴中Hapaxes的数量(n1)、词频总数(N)及义构词总数(N1)。最后根据 P=n1/N 公式计算出其内部的能产性系数,如表2所示:
根据表2的统计结果,能产性最高的为“贬义名词+家”,其次为“其他名词+家”,“领域名词+家”的能产性最低。这说明即使在同一词法范畴内的派生词,由于词基和派生词的语法属性和语义的不同,也会存在内部的能产性差异。
四、词法能产性差异对日本留学生词汇习得的影响
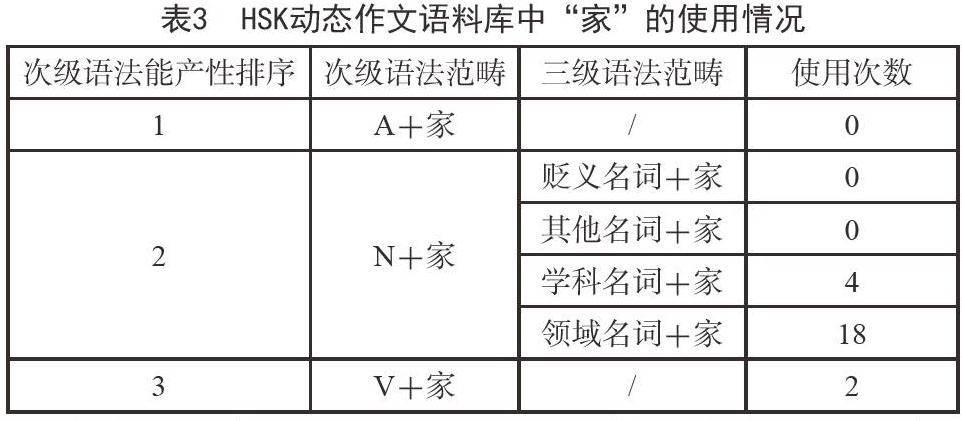
为了研究词汇能产性的高低是否会对日本留学生学生词汇的习得产生影响,进而影响其阅读文学作品的能力,本文对HSK动态作文语料库中日本留学生使用类后缀“家”的情况进行了统计。具体操作如下:首先在 HSK动态作文语料库中按“词语搭配”检索“家”,删除多余的句子,只保留作为类后缀的词语。其次,按照词性和短语结构进行分类,并对照能产性系数表进行排序。统计情况如表3:
如表3的统计结果所示,由于HSK动态作文语料库中的语料数量较少,“家”作为类后缀出现的次数共有24次,其中“A+家”和“V+家”仅分别出现了0次和2次。由于“N+家”出现的次数较多,本文从“N+家”内部的词法能产性差异入手,试图对词汇能产性的高低与学生词汇的习得的关系提出基本假设。
结语
本文对类后缀“家”内部的词法能产性进行了量化研究,经统计得出了能产性的差异为 PA+家> PN+家> PV+家。通过对“N+家”派生构词的进一步研究,发现同一词法范畴内
的派生词,受前置语素的词基和语义的影响,也会存在内部的能产性差异,能产性最高的为“贬义名词+家”,其次为“其他名词+家”和“学科名词+家”,“领域名词+家”的能产性最低。根据HSK动态作文语料库中“家”的使用情况文试图提出一个基本假设:对于词法能产性高的派生词,留学生使用情况普遍较多,习得情况较好,反之亦然。在能产性相同的前提下,构词数量多的派生词,日本留学生使用情况普遍较多,习得情况较好,反之亦然。
本文的量化研究针对类后缀“家”的派生构词,未来还需借助语料库对汉语中占绝对优势的符合构词的能产性进行进一步探索。此外,本文仅通过语料库的方式对词法的能产性与日本留学生词汇习得之间的关系提出了基本假设,未来还需要通过实证研究证明这一假设。
参考文献
[1]Baayen H. Quantitative aspects of morphological productivity. In Geert Boojj and Jaap van Marle (eds).Year book of Morphology 1991. Dordrecht: Kluwer, 1992:109-149.
[2]张未然.2015.基于语料库的汉语词法能产性量化研究——以“儿、子、性、化、家”的派生为例[J].云南师范大学学报(对外汉语教学与研究版),13(4):62-67.
