基于混合特征选择和超参优化的晶圆蚀刻缺陷预测方法
2020-10-12陈晋贤季颖娣林义征朱定海
陈晋贤,季颖娣,林义征,朱定海
(1.同济大学 电子与信息工程学院,上海 201804;2.中芯国际集成电路制造(上海)有限公司 信息技术处,上海 201203)
1 问题的描述
集成电路晶圆制造由于工艺复杂、工艺步骤多(3~400步)成为影响良率的主要因素,每一步缺陷都将对良率产生影响。其中,集成电路的蚀刻制程需要在晶圆上作出极细微尺寸的图案(Pattern),而这些图案最主要的形成方式是使用蚀刻(Etching)技术将微影(Lithography)技术所产生的光阻图形,线、面或是孔洞,以化学腐蚀反应的方式,或物理撞击的方式,或上述两种方式结合,精确地移转到薄膜上,从而定义出整个集成电路所需的复杂结构。蚀刻制程造成的生产质量问题主要包括残渣(residue)和凹坑(pits)两种缺陷,如图1所示。在半导体制造过程中,为保证半导体晶圆的生产质量,需要在进入下一生产环节前对产品进行缺陷检测。目前,半导体工厂通常采取抽测的方式或者只检测可能产生缺陷的产品,但是缺陷检测既耗费大量成本和时间,又无法对每一件产品进行检测。如何在尽量减少误报警的情况下对半导体产品缺陷进行及时的精准识别,对半导体产品的生产质量和生产周期具有非常重要的影响。由于半导体产品制程中各项机台运行参数变量能够在一定程度上实时反映制程状态信息,业务人员通常会根据经验采用单参数变量控制的方法进行缺陷检测。然而,制程上单参数变量的误导性质[1]使得单参数变量监测通常会产生大量的错误报警,这是由于产品缺陷是多个因素综合作用产生的结果,单一参数变量不能够完全反映制程状态的变化。

统计分析和数据挖掘的技术在半导体生产制造中的应用越来越成熟,基于多变量的数据挖掘方法在半导体行业已有许多应用,如图2所示为缺陷预测系统结构图。晶圆制程中的缺陷模式识别常用算法包括主成分分析(Principal Component Analysis,PCA)、混合模型、支持向量机(Support Vector Machine,SVM)、k近邻规则(k Nearest Neighbor,kNN)、神经网络算法(Neural Network,NN)等。文献[2]提出一种基于加权差分PCA的故障检测方法,该方法利用加权差分法消除原始数据的多模态和非线性特征,将PCA应用于预处理数据。文献[3]提出一种基于最近邻差分的核主成分分析,其采用最近邻差分规则消除多模结构,保证了制程变量能够服从多元高斯分布,使得核主成分分析能够更准确地获取到缺陷的系统状态。文献[4]提出一种基于多向主成分分析的高斯时间误差,作为半导体故障检测指标。文献[5]提出一种基于主成分的高斯混合模型和评估制程状态的两个量化指标(负对数似然概率和马氏距离),并进一步使用基于贝叶斯推理的计算方法来提供制程失效概率。文献[6]基于将局部连续高斯混合模型和主曲线模型相结合的混合学习模型对晶圆表面缺陷进行识别。文献[7]提出一种用于半导体领域的实时故障检测系统,使用滤波方法进行特征选择,One-Class SVM分类算法进行缺陷类别的识别,并通过时间窗口的移动动态地更新模型。文献[8]提出一种基于样条回归和SVM的故障检测方法,该方法利用样条回归进行特征提取,然后基于提取的特征构建SVM分类器进行故障检测。文献[9]提出一种基于kNN加权距离的故障检测策略,在该方法中,样本到其第j个最近邻的距离的加权参数是第j个最近邻到其k个最近邻的平均距离的倒数,与kNN中的统计量相比,该方法中的新统计量既能消除多模态过程方差结构的影响,又能降低统计量的自相关性。文献[10]提出基于随机投影和kNN规则的故障检测方法,用于克服传统kNN的虚报、漏检问题、以及模型计算复杂度问题。文献[11]提出一种卷积神经网络模型用来寻找线索的根本原因,该方法使得第一卷积层的输出与原始数据的结构意义相关联,使得生产线人员能够定位表示过程故障的变量和时间信息。文献[12]提出一种基于缺陷特征的NN集成电路缺陷检测方法,并基于霍夫变换来评价缺陷的分散性。
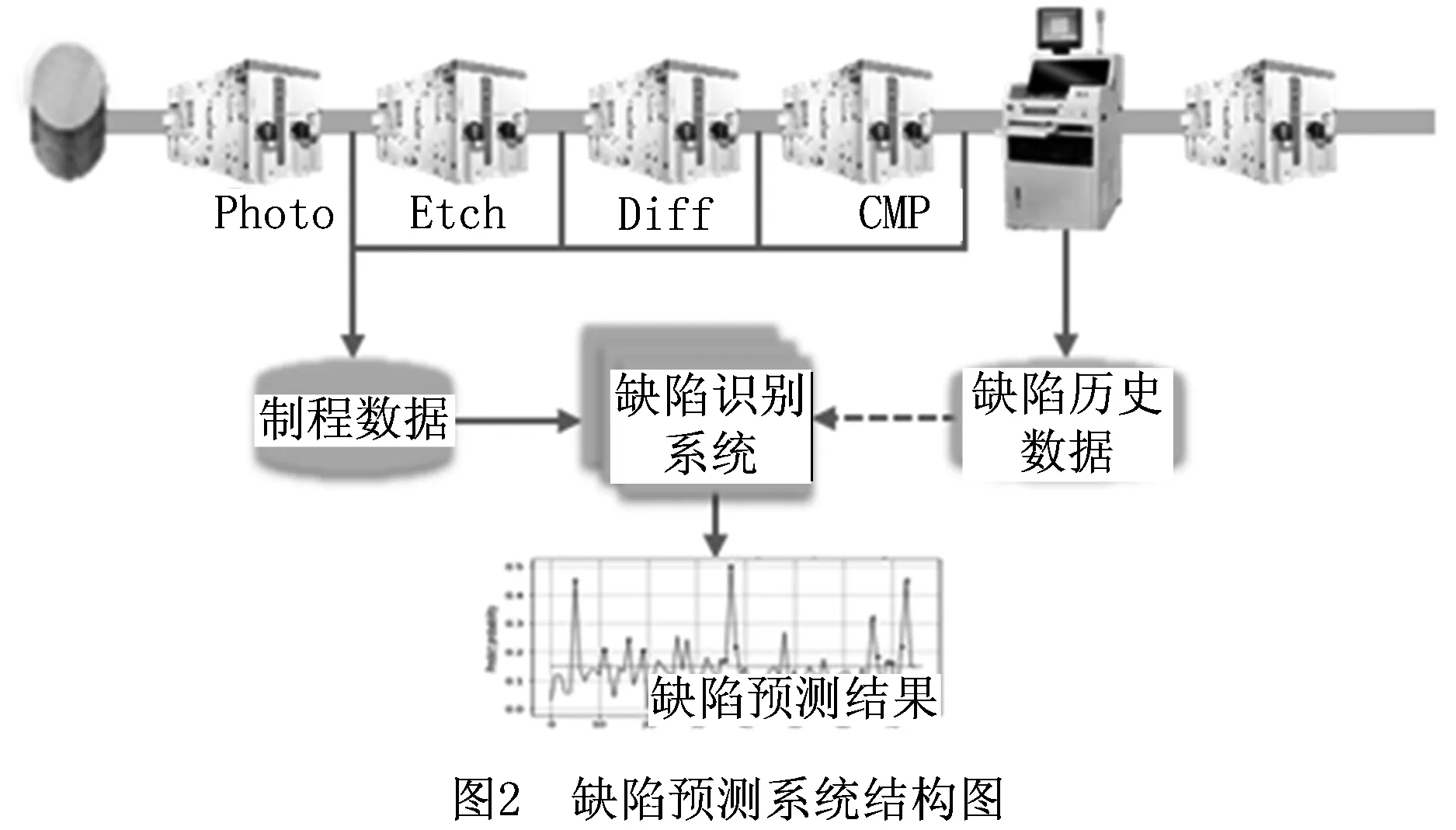
由于工艺的复杂性,晶圆制造过程中生成的高维度数据通常具有多噪声、多模态与线性不可分的特点。适当的特征处理对于半导体行业的建模非常重要,原因是一组最具统计意义的参数变量子集,不仅能够达到降维的效果,使模型泛化能力更强,减少过拟合,还能够增强对模型的理解。然而,上述文献对特征的处理并无完整有效的方法,仅覆盖到半导体制程数据3个特点中的1~2个方面,特征工程有进一步优化的空间。此外,上述文献几乎没有涉及模型的超参数配置优化问题,其模型超参数配置的优化带有一定的主观性色彩。
在该研究中,本文提出兼具稳定性选择方法[13]和Wrapper[14-15]特点的混合特征选择方法,覆盖到半导体制程数据具有高维多噪声、多模态与线性不可分3个特点。该方法首先利用基于随机森林[16]的稳定性筛选为特征评分;然后基于序列前向搜索方法搜索降序排序的特征,并依次创建支持向量机[17]分类模型,采用超参优化技术SMBO(sequential model-based optimization)[18]优化模型超参;最终选择模型表现最好,且特征数量最少的支持向量机模型进行缺陷预测。
2 模型构建
2.1 混合特征选择方法
混合特征选择方法的步骤为:首先利用基于随机森林的稳定性筛选为特征评分;然后基于序列前向搜索方法搜索降序排序的特征,并依次创建支持向量机分类模型,采用超参优化技术SMBO优化模型超参;最终选择模型表现最好且特征数量最少的支持向量机模型进行缺陷预测。其中,随机森林是一种基于决策树和自助采样技术的随机特性集成机器学习方法,对于噪声数据具有很好的鲁棒性,且对高维数据具有优异的特征选择能力[16]。而建立在VC维理论及结构风险最小化原理基础上的支持向量机,能够有效地对多变量、多模态和线性不可分的数据点进行分类[19],并且为模式识别问题提供了良好的泛化能力。由于模型自身超参对模型的表现具有重要影响,工程上常用的调优方法包括手工调整与随机搜索方法,而SMBO则是一种通用的适用于分类和连续超参数的随机优化算法,相对于手工调整、随机搜索方法,SMBO具有更优的表现。为此,本文采用能够以较少的搜索次数自动获得较优的推荐超参的SMBO超参优化方法作为超参调优方案。混合特征选择方法的具体构建步骤如下:
(1)根据Bootstrap抽样方法从全部样本中随机抽取N组数据子集,数据子集的集合表示为:
B={B1,B2,…,BN}。
(2)分别对N组数据子集建立随机森林分类模型,N个随机森林分类模型集合表示为:
RF={RF1,RF2,…,RFN}。
其中:RFi为基于第i组数据子集建立的随机森林分类模型,i=1,2,…,N。RFi是一组决策树{hi(X,θk),k=1,2,…,K}的集成,其中X为特征向量{x1,x2,…,xi},{θk}是表示决策树节点特征的独立同分布随机向量。
(3)获取N组随机森林分类模型对每个特征的打分:
П={П1,П2,…,ПN}。
其中Пi为第i个随机森林模型对每个特征的打分向量,i=1,2,…,N;
(4)每个特征取N次的平均得分作为该特征的稳定性得分:
(5)根据特征的稳定性得分对特征的进行降序排序,排序结果表示为:
Mall={M1,M2,…,MF}。
其中:Mj为基于前j个特征创建的SVM分类模型,j=1,2,…,F,F为特征总数,Mj求解过程如下:设训练数据集为Ttrain={(X1,y1),(X2,y2),…,(Xn,yn)}时,Xn为j维特征向量,SVM通过求解下述目标函数最优问题得到最优解:
s.t.
yi(wjXi+bj)≥1-ξji,ξji≥0,i=1,2,…,n。
其中:wj为超平面法向量,Cj是惩罚参数,ξi为松弛变量,bj为超平面截距。
本文利用核函数将原特征向量X根据映射函数Ø(X)映射到高维特征空间H,实现线性可分,并应用拉格朗日对偶算法求解约束最大化问题,得到分类决策函数:
其中:aji为拉格朗日乘子最优解;K(Xi,X)为核函数,满足条件K(x,z)=Ø(x)·Ø(z),其中x∈X,z∈X。
根据Mj的在测试数据集Ttest={(Xt1,yt1),(Xt2,yt2),…,(Xtm,ytm)}上的分类结果评价模型,Mall的模型表现表示为:
P={P1,P2,…,PF}。
其中:Pj为第j个SVM分类模型的模型表现,j=1,2,…,F,F为特征总数。
(7)根据步骤(6)的模型表现,选择模型表现最好且特征数量最少的特征组合与相应的SVM模型作为最优特征组合与SVM模型:
Optimal={j*=min(subscript(max(P))),Mj*}。
混合特征选择兼具稳定性选择方法和Wrapper特点,原因是稳定性选择方法结合二次抽样和选择算法,在不同的数据子集和特征子集上运行特征选择算法,不断重复,得到每个特征的重要性程度的稳定性得分,但是最终的特征选择的阈值仍需人为设定,缺少了特征子集的选择机制;而Wrapper特征选择方法在选择特征的过程中直接根据分类器在测试集上的性能表现来评价该特征子集的优劣,能够得到较高模型表现的特征子集,但由于Wrapper特征选择的随机性,致使其优化特征子集存在稳定性不足的问题。混合特征选择方法首先利用稳定性选择方法为特征打分,其次使用Wrapper方法提供特征选择机制,既能够为稳定性选择提供特征子集选择机制,又能够解决Wrapper的随机性问题,弥补了两种方法的不足。
2.2 蚀刻缺陷预测系统
基于上述混合特征选择方法,图3展示了晶圆蚀刻缺陷预测系统的数据流。首先收集晶圆蚀刻制程数据和对应的缺陷数据。在进行缺陷预测之前需通过空值处理、异常值处理、数据标准化等数据预处理过程确保建模数据的质量,并基于数据预处理后的数据进行混合特征选择,得到优化后的特征子集和支持向量机识别模型。为确保模型能够适应数据随时间的变动,混合特征选择模型需进行定期更新。最后,根据优化后的特征子集和支持向量机模型对晶圆蚀刻制程数据进行缺陷预测,如果晶圆的预测结果为缺陷,则报警,预测结果为正常,则进入下一道工序。
2.3 SMBO超参优化方法
SMBO是一种通用的适用于分类和连续超参数的随机优化算法,其基于少量历史量测数据连续构建代价很小的代理模型来逼近代价巨大的适应度函数超参数的表现是适应度函数返回的结果[19]。SMBO运用代价很小的代理模型来逼近适应度函数的性质,使其非常适合应用于适应度函数估计代价巨大的领域。James Bergstra等[20]就手工调整、随机搜索与SMBO方法对神经网络模型超参数的优化效果进行了对比,发现在一定的计算代价下,基于SMBO超参数优化的神经网络模型具有更优的模型表现。SMBO运用抽样技术和代理模型技术获取适应度函数的最优超参数,具体算法如下:
算法1SMBO算法。
输入:适应度函数f及其超参配置空间Θ;样本集П;代理模型S;获取函数AC。
输出:优化后的超参H*与相应的模型表现p*。
1.H← Sampling(Θ)#使用抽样方法在超参空间Θ中抽取n组超参H
2.p←fH(П)#使用H配置适应度函数的超参,得到对应的模型表现p
3.Fort←1 to T:#设置迭代次数
4.M←S(H,p)#构建代理模型
5.H′←AC(M,H)#运用获取函数取得下一组超参H′
6.p′←fH′(П)#估计使用H′配置的适应度函数f的模型表现p
7.(H,p)←(H,p)∪(H′,p′)#将(H′,p′)并入(H,p)中
8.Return(H*,p*) #返回优化后的超参H*与相应的模型表现p*
获取函数能够自动平衡已知良好表现区域的局部优化和相对未知区域的超参数的尝试,从而避免超参数过早收敛。本文将使用适应度函数超出模型表现阈值的期望EI[21]作为获取推荐超参数的标准,因为EI已被证明在许多场景下均表现良好。
本文选择TPE(tree-structured Parzen estimator)方法[20]作为本项研究的代理模型,因为TPE是一种优良的代理模型。TPE不是通过计算代理模型表现的后验分布PM(p|H)来获取模型表现与超参数之间的关系,而是通过转换超参数的生成过程来构建PM(H|p),以用非参数密度来取代超参数的先验分布。基于代理模型TPE的SMBO方法的期望提升度:
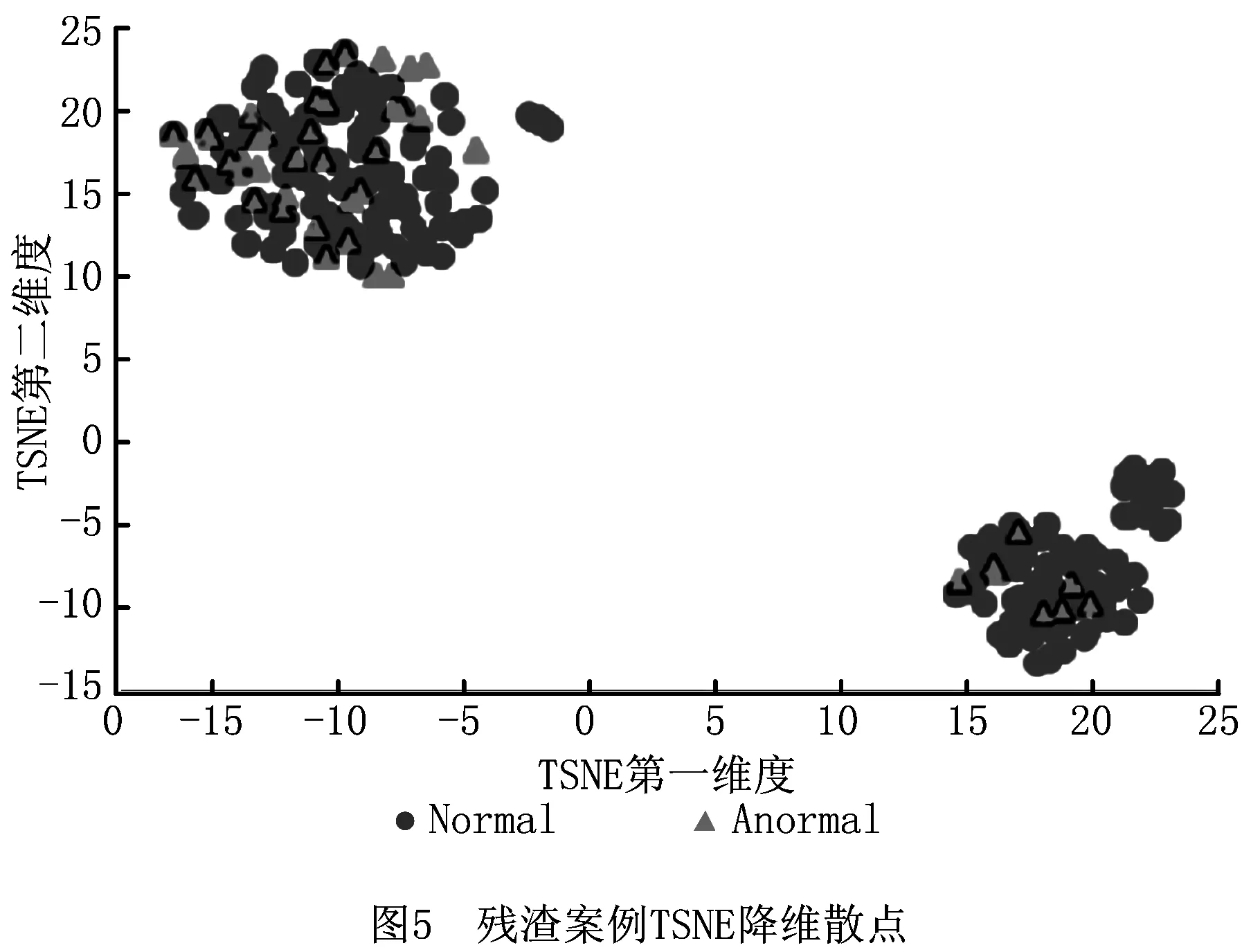
其中:p*为已知(H,p)中最好的超参数表现,γ=P(p 本文基于中国大陆某家领先半导体企业的蚀刻制程机台数据,分别就残渣缺陷和凹坑缺陷的识别问题,验证本文所提方法。对于半导体行业的缺陷预测,业务上更关心敏感性(Sensitivity),因为漏报有缺陷的产品可能造成产品报废的后果,所以本文应该在保证模型敏感性的基础上,提升模型预测的准确率(Accuracy)。表1模型评估混淆矩阵的敏感性和准确率的表达式分别为:Sensitivity = TP/(TP+FN),Accuracy = (TP+TN)/(TP+TN+FN+FP)。 表1 模型评估混淆矩阵 目前,对于晶圆生产蚀刻工序中的残渣缺陷和凹坑缺陷是基于单变量方法进行监控,即当该变量超出预设规格范围时,机台会自动报警,报警后业务人员需要对报警机台生产的产品进行缺陷检测,但是误报警率超过85%,存在检测成本较高、生产效率低下的问题。为此,本文基于历史上有报警并检测的晶圆样本进行建模,在单变量报警的基础上进行二次报警,将目标量化为:Sensitivity≥95%、Accuracy≥55%。 蚀刻缺陷建模预测所需的数据包括大量的机台传感器参数和晶圆蚀刻缺陷检测结果数据两部分。数据准备过程如下:①选择与目标变量晶圆蚀刻缺陷相关的制程传感器参数数据;②根据晶圆标识,将传感器参数数据与蚀刻缺陷检测结果数据进行数据整合;③对整合后的数据删除空值率超过60%的机台参数;④删除含有空值的样本;⑤删除为常量的机台参数;⑥标准化样本数据。 经过上述数据准备阶段,对于残渣案例,本文得到共20个机台参数,327片晶圆,其中异常样本数为48。由图4可以看出,每个主成分的贡献率均比较低,前85个主成分的累积贡献率仅为90%,表明与残渣缺陷相关的320个机台参数之间的相关性太低。由图5可以看出,TSNE(t-distributed stochastic neighbor embedding)两维散点图中具有明显离群点,而异常样本和正常样本杂糅在一起,呈现出严重的线性不可分性,且点的分布呈现出两个团簇,从而表明残渣样本数据的分布存在多模现象。 对于凹坑案例,本文得到共430个机台参数,2 650片晶圆,其中异常样本数为23。由图6可以看出,每个主成分的贡献率均比较低,前105个主成分的累积贡献率仅为90%,表明与凹坑缺陷相关的430个机台参数之间的相关性太低。由图7可以看出,TSNE两维散点图中同样具有明显离群点,而异常样本和正常样本杂糅在一起,呈现严重的线性不可分性,且点的分布呈现出多个团簇,表明凹坑样本数据的分布同样存在多模的现象。 为解决半导体机台参数高维度、多噪声、多模态与线性不可分的问题,在本项研究的特征选择和模型构建阶段,使用本文提出的混合特征选择方法。由于随机森林的泛化误差取决于单棵树的分类能力与树之间的相关性,并且会随着树的数量增加趋于收敛[16]。为了获取足够稳定的特征得分,本文使用1 000棵树,深度为30的随机森林分类器基于全样本进行稳定性选择,迭代10 000次,得到特征的稳定性得分,排序后如图8所示。 由于SVM模型自身包含惩罚系数、核函数选项、模型迭代次数、分类阈值等超参数,而这些超参数对模型在训练数据集和测试数据集上的表现具有重要影响。由此,在此项研究中使用上述SVM的超参数设置,基于步长为1的序列前向搜索降序排序的特征,依次创建支持向量机模型并采用SMBO超参优化方法优化,采用5折交叉验证方法评价模型,最后从所有SVM模型中选择模型表现最好,且特征数量最少的特征集合作为最优特征子集。 最终通过混合的特征选择方法,本文得到基于混合的特征选择的模型在测试数据集上的平均性能表现图(如图9)。结合Sensitivity首要,Accuracy次之的业务要求,发现残渣缺陷识别案例取前123个特征时,SVM的模型性能能够更好地满足业务要求,此时模型在测试数据集上的平均表现为Sensitivity=100%,Accuracy=68.5%。同理,发现凹坑缺陷识别案例取前250个特征时,SVM的模型性能能够更好的满足业务要求,此时模型在测试数据集上的平均表现为Sensitivity=100%,Accuracy=81.4%。 表2所示为6种蚀刻缺陷识别方法分别在残渣缺陷和凹坑缺陷验证数据上的结果。表2中,从残渣缺陷案例6种方法预测结果的对比中可以发现,与现有的单变量制程控制方法相比,基于混合特征选择的晶圆残渣缺陷预测方法将Accuracy提升了43.8个百分点,而基于随机森林特征筛选的SVM模型只将Accuracy提升了35.9个百分点,无特征选择的SVM模型仅将Accuracy提升了25.4个百分点。与半导体缺陷识别研究中常用的kNN和NN相比,SVM在残渣缺陷识别上表现更优。由此可见,本文所提方法在残渣缺陷预测上明显优于其他方法。综上所述,影响该晶圆蚀刻制程残渣缺陷的主要因素是排名前123的特征。 表2 蚀刻缺陷识别模型在验证数据上结果对比 表2中,通过凹坑缺陷案例6种方法预测结果的对比可以发现,与现有的单变量制程控制方法相比,基于混合特征选择的晶圆凹坑缺陷预测方法将Accuracy提升了80.4个百分点,而基于随机森林特征筛选的SVM模型只将Accuracy提升了73个百分点,无特征选择的SVM模型仅将Accuracy提升了66.5个百分点。与kNN和NN相比,SVM在凹坑缺陷识别上表现更优。由此表明,本文所提方法在凹坑缺陷预测上明显优于其他方法。综上所述,影响该晶圆蚀刻制程凹坑缺陷的主要因素是排名前250的特征。 有效地预测晶圆生产蚀刻制程中的缺陷,对提升质量和缩短生产周期有着非常重要的影响,但仅使用单变量参数对残渣缺陷的预测收效甚微。针对晶圆蚀刻制程机台参数高维度、多噪声、多模态与线性不可分的问题,本文提出一种基于随机森林、SVM和SMBO的混合特征选择和建模解决方案,并通过蚀刻制程残渣缺陷和凹坑缺陷预测案例验证了其有效性和优异性。实验结果表明,基于混合特征选择的晶圆蚀刻制程缺陷预测相对于单一的特征选择方法具有更高的稳定性和更严密的逻辑性,可以得到更高的缺陷识别准确率,且优于常见的kNN、NN缺陷识别模型。 在本项研究中,混合特征选择模型仍旧存在一定的预测误差,识别的敏感性和准确率有进一步提升的空间,再者所提模型是针对蚀刻制程中的缺陷预测,对于其他制程中缺陷识别的适用性还有待验证。后续工作将尝试从如下两方面对缺陷识别进行更深入的研究:①通过组合预测的方法进行缺陷识别,即通过多个模型的组合,获取更多的数据内在信息,从而增加缺陷识别的敏感性和准确率;②对该混合特征选择方法在半导体制程缺陷识别中的普适性进行研究。3 实证研究

3.1 数据探索



3.2 模型结果



4 结束语
