译者风格对比描写的多维分析途径*
2020-10-09华东师范大学赵朝永
华东师范大学 赵朝永
提 要: 语域特征是文本的一种重要属性,译本的语域变异由此成为译者风格描写的有效参照。多维分析法(MF /MD)能有效识别译本的语域类属并在不同语域维度上描写其倾向性特征,因此可用于对比基于同一原作的多译本语域特征,以考察不同译本的语域变异情况。译本语域维度差异及参与计算的因子差异均可作为译者风格的综合考察指标,其聚类共现能够反映出译者各自的语言风格乃至翻译策略。多维分析对译本语域特征描写和译者风格考察均具重要意义。
1.引言
译者风格研究是语料库翻译学的核心课题之一。近年来,得益于语料库语言学和语料库翻译学在理论探究、工具研发和范式创新上的成就,基于语料库的译者风格研究取得了长足进展(胡开宝、谢丽欣,2017;黄立波,2018)。基于同一原作的多译本对比已成为考察译者风格差异、揭示并解释译介规律的有效手段。经典文学作品的多译本对比成果尤为显著,如基于语料库的《红楼梦》霍、杨两译本对比(冯庆华,2008)、邦、霍、杨三译本对比(赵朝永,2014、2020b)以及乔、邦、霍、杨四译本对比(刘泽权、刘超鹏、朱虹,2011;赵朝永,2019)等。此外,董琇(2016)从词语、句子、篇章和文化四个层面对比《三国演义》罗慕士、邓罗两译本的译者风格,黄立波(2014)则借助语料库考察了《骆驼祥子》三个英译本中叙述话语翻译的译者风格差异。上述研究多从词汇、句法、语义和语篇等层面,通过“一本多译”的比照,对语料库译者风格和翻译语言特征描写进行了卓有成效的探索,但其不足之处也显而易见。语料库译者风格研究大多满足于对局部译者风格具体表象的描述,未对译者风格进行整体上的归纳(胡开宝、谢丽欣,2017: 16)。显然,局部风格并不等同于整体风格,多个指标的聚类有助于对译者风格进行更为系统的描写。当前国内语料库翻译学的翻译风格研究过于注重浅层语言特征的描写,多维分析的复杂统计方法使用较少(许家金,2018: 8),未来研究亟待新视野、新方法的引介。
2.基于语料库的译者风格对比研究: 进展与问题
译者风格研究是翻译文体研究的一个侧面,从历时角度看,其大体经历了修辞文体观、语言文体观、叙事文体观和语料库文体观四个阶段的变化(黄立波,2014)。每一种文体观的变化也伴随着理论视角、研究范式和研究手段的变革。自Baker(2000)率先提出译者风格的语料库研究方法后,基于语料库的译者风格研究迅速发展,较有代表性的研究有Olohan(2003)、Bosseuax(2004)、Winters(2009)、刘泽权、闫继苗(2010)、黄立波、朱志瑜(2012)、黄立波(2014)等。基于语料库的译者风格研究可分为类比模式和平行模式两大类(黄立波,2018: 79),前者侧重于某一译者翻译作品在整体上与另一译者同类翻译作品的差异(如Baker,2000;黄立波、朱志瑜,2012),后者则重在关注不同译者对同一部源文本的同一目标语中的处理差异,也即“一本多译”或“多译本”研究,以考察译者对源文本中不同语言特征的规律性处理方式(如Bosseuax, 2004; Winters, 2009;刘泽权、刘超鹏、朱虹,2011;黄立波,2014;赵朝永,2020b)。此外,译者风格降维法分析(董琇,2014)也是对译者风格量化考察的有益探索。需指出的是,类比模式所考察的语言特征虽在一定时期具有稳定性,但同时也容易受到源语文本的影响,抛开源语的对比存在一定缺陷,因此同一原作的不同译本能够更有效地反应译者风格差异。
基于语料库的译者风格本对比既有借助单一指标的多译本局部对比,如报道动词(刘泽权、闫继苗,2010;赵朝永,2014)、“被”字句(胡开宝,2011: 116-121)与叙述话语(黄立波,2014)等,也有融合不同指标的多译本综合对比(如刘泽权、刘超鹏、朱虹,2011;赵朝永,2020b)。这两种模式均较多使用词汇量、词汇密度、句子难度等某一种或多种语言手段进行对比描写。基于语料库的译者风格描写已取得有效进展,语料库规模越来越大,分析指标越来越多,跨学科属性越来越明显。然而,译者风格并不等于若干局部风格的简单相加,因此译者风格研究更应当强调总体风格研究(global style),而不是局部风格(local style)考察。此外,基于语料库的译者风格对比不应局限于平均词长、平均句长、标准化类-形比等传统形式参数统计,而应当拓宽思路,向语义、语用、社会-文化等参数及认知语言学等视角(金胜昔、林正军,2016)拓展。同时,需借鉴语料库文体学、计量语言学、计算语言学等相邻领域的研究方法,拓宽翻译文体或风格研究的范围,使这一研究课题的方法论更加科学化和系统化(黄立波,2018: 77)。因此,当前研究的局限性不言而喻: 第一,计量指标相对单一,且仅关注译者风格某一侧面的描写;第二,统计指标之间缺乏关联性,聚类程度较低,缺乏多维度的定量与定性有机结合;第三,多重视原文参照,对参照目标语规范的语域变异缺乏重视。
Biber(1988)创立的多维分析法(Multidimensional Analysis,以下简称“多维分析”)可有效区分文本的语域(1)关于“语域”这一术语,英文中有对应的近义词style、genre、register,中文有“语体”“体裁”“语类”等,学界尚未就此形成统一认识。为避免术语混淆,本文暂不做区分,统一采用“语域”这一术语。多维分析法旨在探究“语域变异”(register variation),这也是文本采取该术语的另一原因。及语域子类,是文本语域特征对比的有效手段。多维分析的核心概念是语言特征的共现,即不同的共现模式可表征不同的潜在语域变异维度。自问世以来,多维分析受到学界一致认可,已成为语料库语言学界话语分析的代表性方法之一(江进林、许家金,2015)。自创立以来,多维分析已被用作比较口语与笔语语域特征差异(Biber, 1988; Van Rooy, 2008)、小说、论文、私人信函(Biber & Finegan, 1989)、对话、演讲和学术文章(McEneryetal., 2006)、法律英语(Asgharetal., 2018)等体裁。受其影响,国内学者借助多维分析开展实证研究,范围涉及学术语篇(雷秀云、杨惠中,2001;武姜生,2001)、中外科技论文摘要(曹雁、肖中华,2015)、商务英语(江进林、许家金,2015)、学习者书面语体(潘璠,2012;赵朝永、王文斌,2017)、汉语语体变异(刘艳春,2019)以及翻译语域特征(胡显耀,2010;赵朝永,2020a)等,多维分析已成为区别语域特征的有效手段。多维分析法不仅避免了以往单一或少数几个语言特征可能引起的语体分析的偏颇,也实现了定性与定量的有效结合(刘艳春,2019: 100)。
如上所述,基于语料库的译者风格对比虽已逐渐走向深入,但依然存在指标单一、描写片面、重定量轻定性及缺乏对目标语语域规范的参照等局限。因此,译者风格研究只有采用更为科学的计量工具和方法,才能实现研究手段的科学化和研究结果的可靠性(韩红建、蒋跃、袁小陆,2019: 91)。黄立波(2018: 80)将译者风格描写概括为三个视角: 翻译学视角、叙事文体学视角和计量语言学视角,根据Biber(1988)所设立的多维分析是上述三种类别的综合,能有效避免传统研究不足,对译者风格进行更为系统、综合、立体的描写。
3.多维分析法概述
1) 基本理念
Biber(1988)基于英语口语语料库(LLC, London Lund Corpus)和英语书面语语料库(LOB,Lancaster-Oslo-Bergen),通过两组文本的67个语言特征(如时态、体态、情态、词性、疑问句等等),考察了口语与书面语及其10多个子语域的区别性特征。Biber的MDA分析工具首先自动识别并统计出67个语言特征的频数及每千词标准化频率,然后根据其在相应语域中的共现情况归纳为7个维度(2)维度1为交互性与信息性(involved versus informational production);维度2为叙述性与非叙述性(narrative versus situation-narrative reference);维度3为情境独立与情境依赖(explicit versus situation-dependent reference);维度4为显性劝诱表述(overt expression of persuasion);维度5为信息抽象与具体程度(abstract versus non-abstract information);维度6为即席信息组织精细度(online information elaboration);维度7为学术性模糊表达(academic hedging)。。各维度一般具有两种值,正负值表达的文本特征相反,起到区别文本特征的作用。如,维度1中的正特征因子得分越高,表明文本互动性越强,反之则文本信息性越强。维度2上的正特征因子得分越高,表示文本具有较强叙述性,反之亦然。由于维度7数据较少,其形成的维度与其余6个维度不具有可比性,在实际操作中通常舍弃。
2) 分析工具
Nini(2015)开发的多维标注与分析工具Multidimensional Analysis Tagger 1.3.1(以下简称MAT)复制了Biber(1988)多维分析模型,可对文本进行自动标注、特征提取和数据统计,并参照Biber(1989)判断出文本的语域类型。该工具运行要求在Windows操作系统下运行,须有Java环境。MAT与McEneryetal.(2006)提供的多维分析程序包不同,它使用了Biber(1988,1989)的67个语言特征和6个功能维度,且通过内嵌的“斯坦福词性赋码器”(Stanford POS Tagger)进行词性赋码。通过比较Nini(2015)和Biber(1988)两种方法所得的分析结果,证实了MAT可以有效复制Biber(1988)所提出的所谓分析全过程。而McEneryetal.(2006)的程序包只能提取58个语言特征,其词性赋码工具也与Biber(1988)不同,因此两者的研究结论在可比性上存在一定差距。
3) 操作步骤
武姜生(2001)曾对Biber(1988)的多维分析法有过详细介绍,此不赘述。以下着重介绍采用Nini(2015)MAT多维分析软件进行多译本语域变异分析的基本步骤。
(1) 创建语料库
MAT软件仅接受纯文本格式(ANSI与UTF-8均可),若文本格式不兼容,处理过程中会报错。文本的识别、整理和降噪方法可参照梁茂成、李文中、许家金(2010)。译文文本以每个独立的章节为单位,单独保存,整体形成一组文本,以便于后续对组数据进行显著性检验与回归分析。
(2) 语料的自动标注、特征提取和语域特征计算
MAT软件可先标注再分析,也可一步完成。自动处理完数据后,MAT提供了以下基础统计数据: ① 以“Corpus_Statistics.txt”命名的所有因子原始频次信息;② 以“Zscores.txt”命名的频数标准分(Z分数);③ 以“Dimensions.txt”命名的各文本维度分数(经过标准化处理的Z分数);④ 标记文本维度趋向的几张图表,标识出与当前文本最接近的语域趋向。更为详尽的操作步骤可参见Nini(2015)MAT软件的操作手册2—4页。
(3) 语域维度的呈现与解释
MAT对语域维度的描写以分析语言特征的“共现”模式为基础。多维分析利用统计学上的因子分析(factor analysis)来推断语域维度和共现特征。因子分析是一种多元统计方法,可将众多的语言特征变量通过聚类,合并为某一公共因子,即MAT分析中所要呈现的6个“维度”。每个维度与其下属语言特征的相关性表现为各语言特征在此项因子上的因子负荷(factor loading)。因子负荷超过 0.35 以上的“显性” 语言特征可视为具有共现关系。以第1维度“交互性与信息性”为例,其部分共现语言特征见表1。
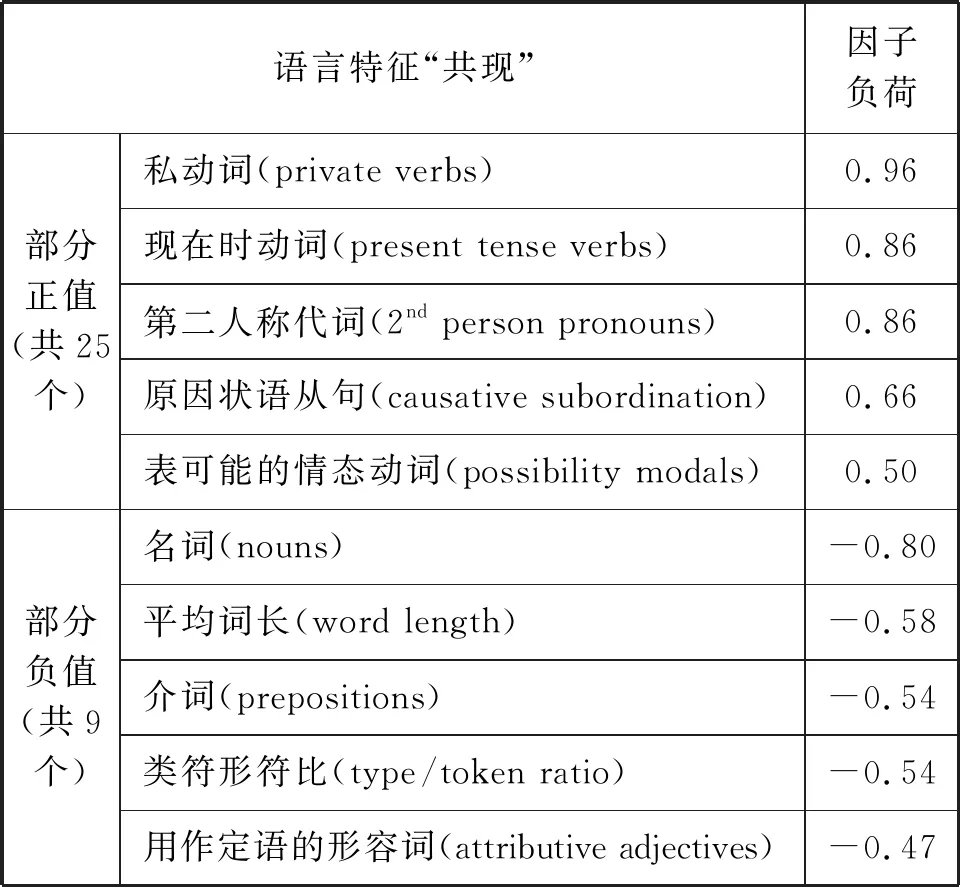
表1.维度1部分共现因子及因子负荷
维度1上共有34个因子参与计算,其中正值因子25个,负值因子9个。对于部分参与多个维度计算的因子,当其在其他维度上的负荷大于本维度时,将不再参与本维度的计算。维度1上共有6个因子(如条件状语从句、地点状语、无施动标记被动句等)在其他维度上的负荷高于本维度,因此被排除在外。此外,Nini(2015)仅采用Biber(1988: 77)Z分数均值高于1的因子,因此维度1上实际参与计算的因子仅有24个。由表1可知,因子负荷为负值的语言特征意义比较明显。名词、介词、词长、类符与形符比等特征具有信息含量高、表达准确的特点,在以传达信息为主的语篇(如说明性文章)中有着较高的分布频率,而较少出现在以人际功能为主的口语文本中。负荷值为正值的语言特征如第二人称代词、动词的现在时态以及私动词等。这些特征体现了语篇人际功能的交互性,情感性等属性,在语域中的分布规律与上述负荷值为负的语言特征正好相反,即两者呈互补分布。因此,维度1代表了人际交流功能与信息传达功能的对比。其余维度因子的共现可参见Biber(1988)第6章,此不赘述。
(4) 语域变异分析
根据MAT汇报的维度分数可对文本语域进行多维度的比较分析,即可描写各个维向的功能意义,也可按照维度分数的差异比较不同文本语域在各维度上的差异,具体可参见Biber(1988)第7章。
(5) 显著性检验及相关性分析
语域变异的对比分析需借助SPSS统计分析软件对MAT报告的维度分与Z值进行显著性检验,并通过多元线性回归确定影响每个维度语域变异的共现因子,以深入挖掘所有67个语言因子的“共变”信息,从而更加综合、系统地判断导致文本语域变异的因素。线性回归对于多译本对比尤为重要,是发现及解释译者风格差异的一种有效手段。
4.案例分析: 《金瓶梅》埃译本与芮译本语域变异对比分析
我们选取经典文学作品《金瓶梅》的三个英文译本(埃杰顿译本、奥米尔译本和芮效卫译本,以下分别简称“埃译本”“米译本”“芮译本”)作为案例,借助Nini(2015)MAT软件对译本进行多维分析,以进一步展现多维分析法对多译本风格对比描写的有效性。关于两译本和四译本的对比范式,可参照赵朝永(2019,2020a)。
1) 语料情况
语料由埃译本、米译本、芮译本三部分组成,其中埃译本、芮译本为100回全译本,米译本为节译本,仅有49回。三译本均按自然章节切分为多个文本,语料详情如下。
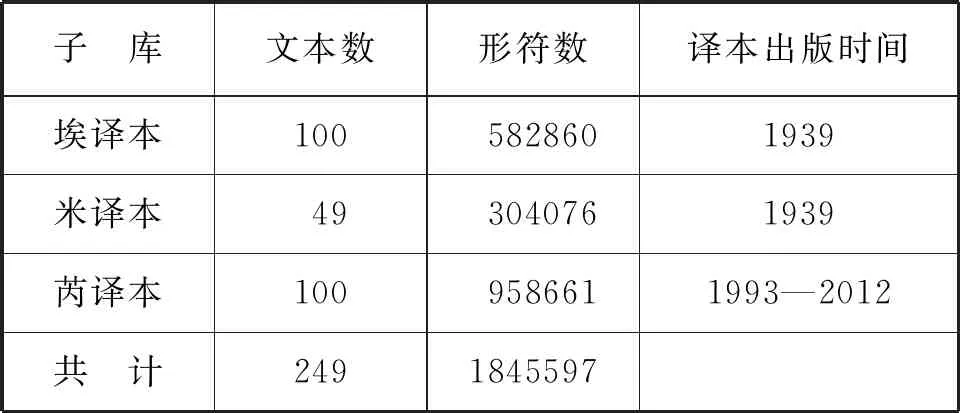
表2.语料库构成(3)本文在赵朝永(2020a)基础上,再次对埃译本和芮译本的语料进行整理与校核,对可能引起统计误差的个别专有名词拼写方法做了统一处理,以最大程度较少误差。因此,文本个别统计数据较之前文有微调,但两个译本整体语域特征、维度倾向及译本间的维度差异均保持不变。
2) 译本维度趋向
根据MAT软件汇报的维度分数,可将三译本的维度差异转换为图表(见图1),限于篇幅,软件汇报的维度趋向图从略。埃译本被归入“虚构性叙述”(Imaginative Narrative)语域,而米译本和芮译本均被归入“普通叙述说明”(general narrative exposition)语域,前者主要包括“爱情小说、普通小说、悬疑小说”等子类;后者则通常包括“新闻报道、评论、传记”等子类,所涵盖文本带有非文学色彩。
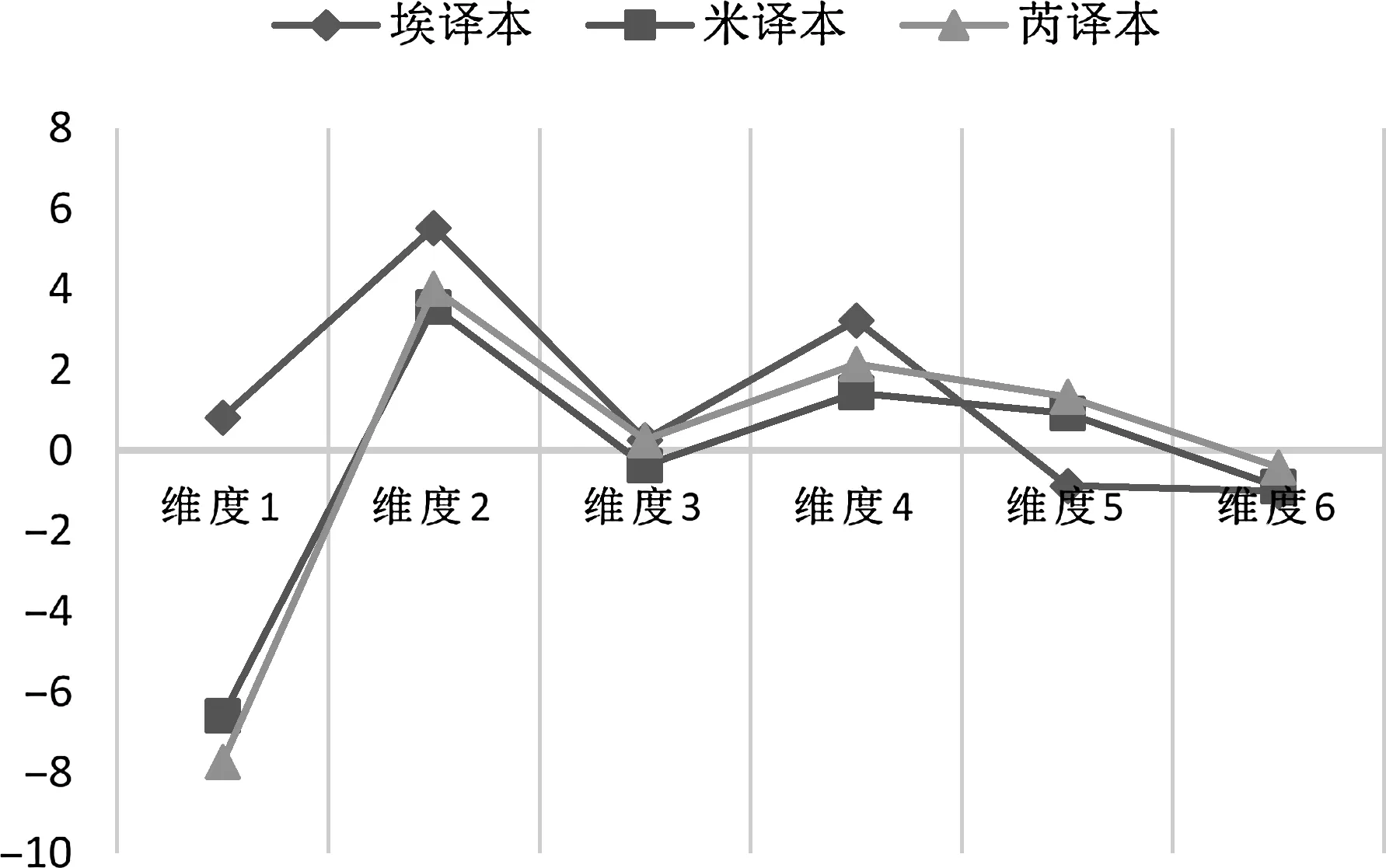
图1.《金瓶梅》三译本语域维度差异
3) 译本维度差异对比
我们使用SPSS软件对三个译本的维度分数进行方差分析(2个译本对比可使用独立样本T检验)。结果显示,三者在维度1上呈现出明显差异,埃译本信息性弱但交互性强,而米译本与芮译本均为信息性强于交互性的文本,且二者的信息性程度无显著差异。在维度2上,三者均呈现出较强的叙述性,这符合其作为小说的语域特征。其中,埃译本的叙述性相对最强,芮译本与米译本依序次之。在维度3上,埃译本与芮译本表现出情境独立特征,而米译本则倾向于情境依赖。在维度4上,三者均展现出显性劝说特征,这与文本中存在大量对话有一定关系,该特征为所有小说文本所共有,但三者显性劝诱的程度不同,由高到低依次为埃译本、芮译本和米译本。在维度5上,芮译本和米译本表现出较高的信息抽象程度,埃译本则表现出较高的信息具体程度。从维度6上的数据可知,三者表现出较低的即席信息组织精细度,其中米译本相对高于另外两个译本,而埃译本和芮译本之间不存在区别。
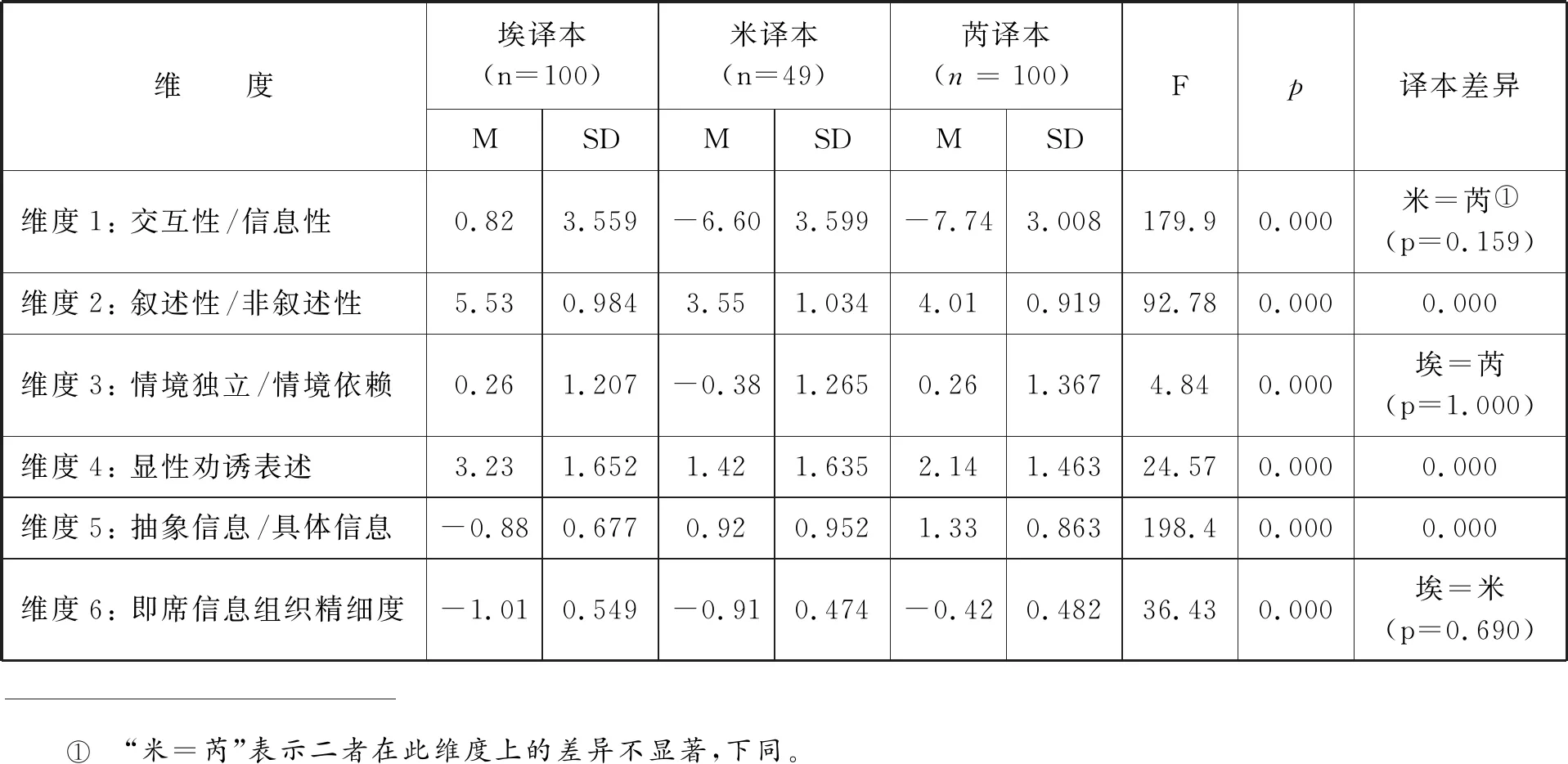
表3.《金瓶梅》三个英译本语域维度差异分析
4) 单一维度内影响因子回归分析
为进一步考察参与维度计算的因子之间的“共变”情况,我们借助SPSS软件对每个维度对应的变量进行了逐步回归,以确定三组文本在3个具有显著差异维度上的影响因子。限于篇幅,仅选取米译本的维度1作为案例。维度1上共有34个变量,其旨在区分文本的交互性与信息性。结果显示,米译本共有24个变量进入回归方程,其中预测强度最佳的5个变量为“名词(不含名词化及动名词)(NN)”“现在时(VPRT)”“类符 /形符比(TTR)”“平均词长(AWL)”及“私动词(PRIV)”。

表4.维度1逐步回归模型整体效果参数表
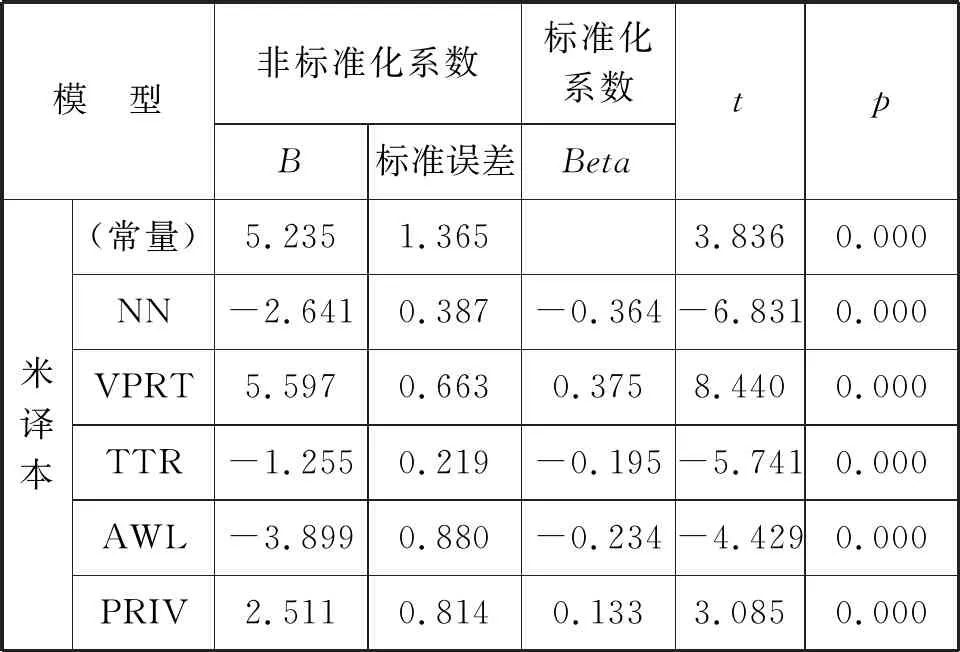
表5.米译本维度1逐步回归系数表
由表4、表5可知,米译本前5个变量对维度1具有良好的预测作用(R2=0.955),即五个变量的“共现”能解释该维度95.5%的变异。表4显示,“现在时”与“私动词”回归系数为正值,“名词(不含名词化及动名词)”“类符 /形符比”与“平均词长”回归系数为负值,其标准化回归方程为: 维度1=-2.641*NN + 5.597*VPRT-1.255*TTR-3.899* AWL + 2.511*PRIV。这表明米译本倾向于较少使用“现在时”“私动词”这类体现交互性的词,而较多使用体现信息性的“名词(不含名词化及动名词)”“类符 /形符比”与“平均词长”。这一结果反映出米译本信息性较强,结合原文的语体特征可知,译本相对偏离了小说文本应有的交互性特征,呈现出“叙述说明”的特点。
需指出的是,除上述单一维度共现因子的回归分析外,还可将参与维度分计算的所有67个因子设为回归的变量,在更大范围内观察本维度以外因子的“共变”情况,以充分利用和挖掘数据。韩红建、蒋跃、袁小陆(2019: 91)指出,文本数据挖掘、计量风格学、计算语言学和计量语言学领域的一些成熟算法在国内外语料库语言学和翻译界尚未发挥大的作用。多维分析呈现的多种数据信息更是如此,有待研究者根据研究目的和文本特点进行充分利用。
5) 译本维度差异影响因子整体分析
为进一步呈现两译本差异,还可通过独立样本t检验,两两对比参与语域维度计算的67项语言因子。由于埃译本和米译本同年问世,且译者均为英国人,可比性较强,我们检验了参与其维度计算的67个语言特征。结果显示,二者具有显著差异的因子多达53个(79.1%)。限于篇幅,下表仅列出差异较大的前15个因子(见表6)。
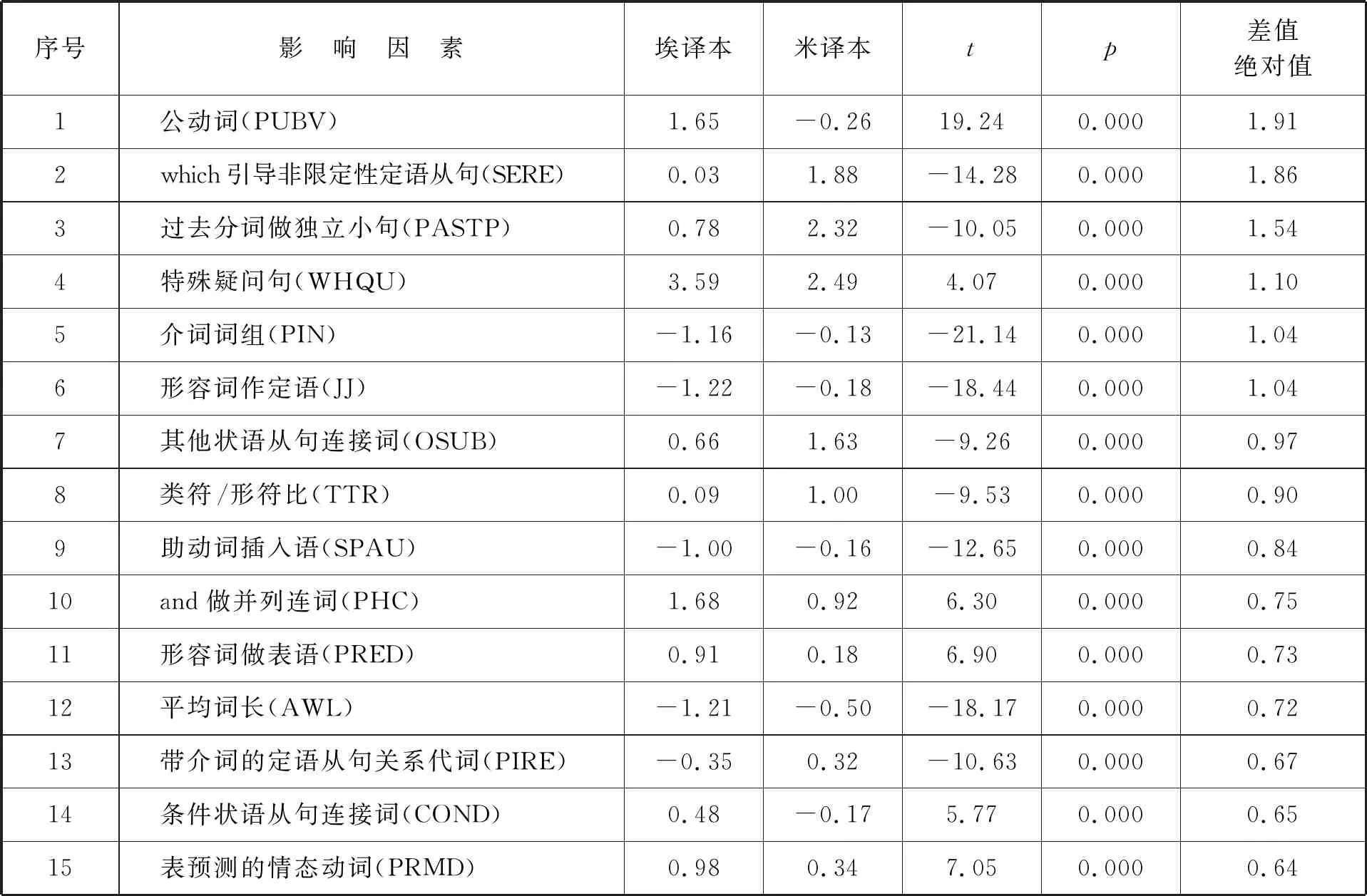
表6.埃译本与米译本差异最大的15个语言因子
结合前文分析可知,埃译本交互性和叙事性特征更明显,信息具体程度高,情境独立程度高,劝诱特征明显,相对更符合小说文本的体裁特征,且倾向于通过更为简明、生动的语言展现原文情节,具体表现为更多使用特殊疑问句、一般过去时、公动词及表强化的副词等(赵朝永,2020: 291)。米译本信息性强,解释说明特征更为明显,信息抽象程度高,倾向于通过更为抽象的信息转释原文的语言与文化,具体表现为多使用非限定性定语从句、多去分词做独立小句、各类状语从句、并列成分以及较高的词汇密度等。因此,总体而言,米译本已相对偏离小说文本的体裁特征,出现了语域变异。需指出的是,上述差异的产生同译者的翻译目的、对待源语文化的态度及整体翻译策略息息相关。埃杰顿以寻找心理学研究材料为目的,重在呈现原作的“故事性”,并不关注源语文化内涵的传递,其据此制定了将原作向目标语文体规范靠拢的策略,其译本由此更加符合小说文本的语域特征。米奥尔译本的目标群体是受过教育的读者,整体风格偏正式,且由于是节译本,概括性较强,其译文因而更较强的信息性和抽象性,而交互性与叙述性则相对较弱。由此可见,译本语域特征是译者翻译风格乃至译者主体性的综合体现。
5.小结
基于语料库的多译本语域变异多维分析是一种涉及类比-平行、语际-语内的综合分析模式。多维分析能有效区分文本的语域变异情况,且能够将影响文本语域差异的语言因素一一展现出来,这一方法对多译本风格的定量对比与定性分析均具有重要意义。多维分析方法使译者风格描写从静态转向多译本之间动态对比,从局部描写转向整体考察,从相对于源语的译语风格,转向进入目标语参照系统后的语域变异考察。限于篇幅,本文仅侧重介绍基于MAT的多维分析操作,对于造成译本在不同语域维度的具体差异及动因,仍需根据研究目的结合定性分析深入探究。多译本语域变异对比是参照目标语的语域对译本进行描写,而对语域变异的动因分析则需回溯原文,并将影响译者风格的内部主体性因素(如译者翻译动机、目的、对待源语文化和原作的态度、个性特征等)及外部客观因素(如时代背景、赞助人、合作人、诗学等)。就此,我们将另文探讨。
