带置信度的基于sEMG的无声语音识别研究
2020-09-29王鑫乔波杨梦
王鑫 乔波 杨梦


摘要:基于表面肌电信号(sEMG)的语音识别是通过面部放置的肌电信号传感器采集生物电信号进行处理识别,过程不依赖于声学信号, 可以避免外界噪声的干扰,可提高强背景噪声下通讯的准确性、可靠性以及适应场景条件的多变性,因此作为新的替代通讯方式在很多领域和场景被研究且应用。因为信号时间轴不一致而无法直接利用机器学习算法进行识别,本文提出了利用插值法来解决此问题。现有研究的识别结果没有提供可信度评估,在高风险领域应用不足,本文将一致性预测器(Conformal Predictors)应用于基于表面肌电信号的孤立汉字无声语音识别中,在提高了识别准确率的同时为预测结果提供可靠性评估和保障。
关键词: 肌电信号;无声语音识别;置信度;插值算法;一致性预测器
中图分类号:TN912.34 文献标识码:A
文章编号:1009-3044(2020)17-0003-04
Abstract:Silent speech recognition is based on the bioelectric signal collected by the sEMG sensor placed on the face, which is independent of the acoustic signal. It can avoid the interference of external noise, improve the accuracy and reliability of communication under strong background noise, and adapt to the variability of scene conditions. Therefore, as a new alternative communication method, it has been studied and applied in many fields and scenes. At present, the recognition of signal is based on the hidden Markov model, because the time axis of signal is inconsistent, so it can not directly utilize machine learning algorithms. This paper proposes an interpolation method to solve this problem. The existing research results do not provide confidence guarantee, and are insufficient in the high-risk field. In this paper, conformal predictors are applied to the isolated Chinese silent speech recognition based on sEMG signal, which improves the recognition accuracy and provides reliability evaluation and guarantee for the prediction results.
Key words:sEMG signal; silent speech recognition; confidence measurement; interpolation algorithm; conformal predictor
1概述
近二十年来,自动语音识别(Automatic Speech Recognition,ASR)在实际应用中取得了令人满意的发展,然而基于声学信号的语音识别仍存在一些固有缺点:(1)语音信号很容易被环境噪声干扰,在背景噪音下的语音识别性能会显著下降;(2) 声学信号的采集过程很难保持隐私或保密;(3)不适用于发声障碍人士。 表面肌电信号(surface electromyography,sEMG)是肌肉系统进行随意性和非随意性活动时产生的生物电变化经表面电极引导、放大、显示和记录所获得的一维电压时间序列信号,反映了神经和肌肉系统的功能和生理状态,并且从人体皮肤表面获取,不会对人体造成损伤,因此在多个领域获得深入研究和广泛应用,例如疾病诊断、假肢控制、远程操作机器人、康复治疗等[1]。话语声音的产生是一系列喉部肌肉和面部肌肉蔟活动协作完成的,肌肉的变化对应不同的活动状态,因此可以从表面肌电信号中提取特征进行语言或语义识别,识别不依赖于声学信号,自然避免了噪音或其他声波干扰,因此基于表面肌电信号的无声语音识别作为强噪音下的替代通讯方式被广泛应用,如飞行员在强噪音驾驶舱中进行指令控制[2],消防员在救火场景中与队员或指挥中心进行交互[3];基于肌电信号可以与语音信号同步采集,被研究用于为宇航员提供额外通讯方式[4];除此之外,因为说话人可以采用默读的方式述说指令或语句,也可以用来实现高保密性的人-机或人-人交互[5]。
虽然早在1985年肌电信号就被引入无声语音识别的研究[6],但研究直到2001年才有突破性进展,研究者比较了时域、傅里叶、小波包、小波变换四种特征提取方式,采用线性判别分析进行分类进行0-9数字的识别,平均识别率达到90%[2]。随后针对大量以及连续信号的识别展开了许多的研究和实验,并证明通过sEMG进行连续语音识别是可能的[7]。Michael Wand等学者[8]建立了肌电信号数据库,由108 个词汇组成的50个基本句子,平均每句话的字准确率达到70%。 国内的研究起步比较晚,2005年戴立梅等人将sEMG应用于无声语音识别领域,实现10个数字的识别,平均识别率达到85%。2019年金丹彤等人将深度学习应用于汉语孤立词的识别,对10个汉字得到80%的平均识别准确率[9]。基于肌电信号的无声语音识别一般包括信号预处理、肌肉活动状态检测(分割),特征提取和识别四个步骤,目前的无声语音信号识别多是基于隐马尔可夫模型(HMM),但HMM模型的建立需要依赖一个较大的语音库,这在实际工作中占有很大的工作量,且模型需的存储量和匹配计算的运算量相对较大,虽然机器学习算法可解决此问题,但由于说话快慢的变化会使得信号的时间轴不一致,因此机器学习算法无法直接被应用,只能与HMM一起建立混合模型实现。本文利用图像识别领域常见的插值法解决了时间轴不一致性问题,使得机器学习算法可以直接应用于无声语音信号识别。在高风险领域,分类失败将导致严重的后果,利用可信度可以对识别结果的可靠性进行假设检验,定位识别错误所在,提高系统的识别率和稳健性[10][11]。基于转导推理的一致性预测 (Conformal Predictor,CP)是1998年Vovk等人[12]提出来一种基于柯尔莫戈洛夫(Kolmogorov)算法随机性理论的域预测机器学习算法,可以对预测结果進行可靠性评估和保障,本文将研究一致性预测器在基于肌电信号的孤立词的无声语音识别的应用,通过线性判别分析(LDA)优化特征后,10个汉字的分类识别准确率达99%,且同时可输出带置信度评估的域预测结果,为后续连续词识别提供支持。
2 原理和方法
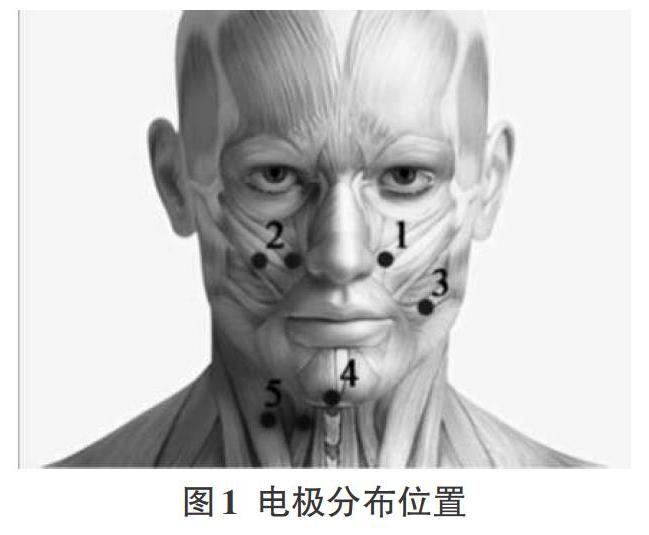
本研究使用表面肌电信号进行10个汉语单词的孤立词的识别,单词选用日常会话中的最常用的汉字。言语是多种面部和其他肌肉活动复杂结合的结果。根据解剖学研究[13],与言语相关活跃的肌肉数量很丰富,我们采用了先前研究中的电极位置[14],并进行了一些实验,确定使用五个通道捕捉肌肉信号,分别为:颧骨主、提角肌、颈阔肌、外舌和二腹肌前腹,如图1所示。电极使用标准的Ag/AgCl电极,使用NuAmps脑电放大器采集肌电信号,采样频率为250HZ。为了减少噪音,在采集过程中关闭了所有不必要的电源。实验采集了2位男性同学的肌电信号。在实验中,受试者以重复的方式默读词汇表中的单词,每个单词读20次,每个字之间有10秒的停顿,使肌肉得到充分休息。
基于肌电信号的无声语音识别一般包括信号预处理、肌肉活动状态检测(分割),特征提取和识别,如图2所示。本研究采用陷波滤波、带通滤波和基线漂移对信号进行预处理,然后手动进行信号分割,采用插值技术使信号长度达到一致。特征提取的目的是用一组有效的数据描述原始肌电信号。本研究使用信号的时域信息作为特征,利用线性判别分析对特征进行降维。分类识别步骤中对比了传统的离线模式机器学习算法和在线学习模式的一致性预测器。
3关键技术实现
3.1 信号预处理与分割
本研究采用陷波滤波、带通滤波对信号进行预处理。陷波滤波器(notch filter)用于消除普遍存在的电力线干扰。电力线干扰可以通过地面、空气等介质传输到人体,后由表面肌电信号采集装置采集。由于表面肌电信号相对较弱,电力线干扰很可能造成严重的影响,掩盖了表面肌电信号本身的特性。本研究使用自适应陷波滤波器来恢复干扰,然后将其从被测信号中消除。经研究电力线干扰被认为是50赫兹正弦信号和50赫兹余弦信号的线性叠加[15],本系统采用自适应算法调整两个信号的权值,使误差最小。sEMG的主要信息集中在20Hz-120Hz范围内。通过带通滤波可以保持20Hz-120Hz的信号,来消除电力线信号的高次谐波和其他环境噪声。
实验采用连续录入的方式,对词汇表的每一个单词,用户将重复说20次,所以一个记录将包含20段有效信号,需要将这些有效信号分割出来。尽管语音识别针对VAD(Voice Activity Detection)进行了大量的研究,但基于sEMG的SAD(Speech Activity Detection)在许多方面是一个更为困难的问题,多个表面肌电通道的使用使问题更加复杂,因为肌肉收缩优先于语音产生并提前时间不等, 很难定义语音相关活动的开始和结束,而每个通道的言语活动相关行为独立又互相受影响。本论文采用人工分割的方式筛选出所有有效信号段,总共获得1200多个样本,如表1所示。
3.2插值和特征提取
由于用户说话的快慢不同,导致有效信号的长度不一,本研究采用插值方法来规整信号的长度,通过对比最近邻插值法、双线性插值和双三次插值的效果,最终采用双线性插值将信号调整为每个通道370维的长度。
根据提取参数的方法不同,可以将信号分析分为:时域分析、频域分析和时频域分析。根据之前的研究,时域特征可以为识别提供足够的信息,获得更好的性能[16],本论文对信号进行时域分析。肌电信号是具有非平稳特性的生理电信号,在短时间范围内可以认为信号是稳态的,为了描述sEMG信号随时间变化的趋势,首先按照叠加窗技术进行分帧处理。根据信号采样率和实际分析的需要,我们取每帧信号长为30ms, 帧移为15ms,每帧信号加汉明窗以消除分帧带来的帧信号边缘的不连续性。接着提取帧内的四个时域特征值,分别为短时平均幅度、短时能量、短时平均过零率、短时平均幅值差。 从采集的5个通道的信号中共提取460维特征值。考虑到高维相关的精度和计算问题,利用线性判别分析(Linear Discriminant Analysis,LDA)方法从460个特征中选择了50个特征,该方法在脑组织分析[17]、语音识别[18]和人脸识别[19]等领域有着广泛的应用。
3.3 一致性预测器
3.3.1 一致性预测器原理
一致性预测器基于样本服从独立同分布假设的假设,预测过程可以采用在线学习的方式,过程中训练样本集是不断更新的,在对测试样本完成预测后,将测试样本和它的真实标签加入训练样本序列中,使得训练可以从零样本开始并逐步扩充训练集;也可以采用传统的机器学习的离线学习模式,即在固定的训练样本集上训练模型。
4 实验结果
本论文分别使用传统的分类算法K近邻、随机森林(RF)以及支持向量机(SVM)和CP-KNN、CP-SVM、CP-RF进行无声语音识别。在KNN中使用的距离是欧几里德距离。支持向量机的核函数是线性函数。随机森林中决策树的数量为500。所有实验均在10倍交叉验证程序中进行。
4.1 单值预测结果
实验先后使用460维全部特征和50维优化特征进行分类,对比了离线模式的CP-KNN、CP-SVM和CP-RF的单值预测结果和传统的KNN、SVM和RF的预测结果,如表2所示。结果显示,使用优化后的50维特征在预测中有更好的性能。对比多有的分类器,采用CP-RF识别的准确度最高,同时具有最大的可信度。
4.2 域预测结果
实验比较了三种CP分类器的在线模式下的域预测性能。为了比较不同显著性水平的域预测的精确度,我们统计了标签集的元素个数的中值,如图3所示。在显著性水平为5%时,CP-SVM的域预测的中值约为9,隨着显著性水平的增加而减小。相较于CP-SVM,CP-1NN和CP-RF输出精确度更高的域预测,即中值为1,但当显著性水平增加时,CP-RF的空预测增长率最小,如图4所示。
5结论
本研究实现了基于面部肌肉肌电信号的10个汉语孤立词的无声语音识别,通过使用插值技术解决信号时间轴不统一的问题,并将一致性预测器应用于分类识别,为预测提供可靠性评估和保障。实验表明基于随机森林的CP识别性能最好,在离线模式下分类精确度可达99.5%,可信度为99.8%,在线模式下,置信度水平为95%时仍可得到大量单一预测。证明一致性预测器可成功应用于孤立汉语单词识别。在今后的工作中可以探索如何利用CPs来提高汉语识别的鲁棒性以及将小词汇量孤立词识别扩展至连续词识别进而实现连续识别。
参考文献:
[1] MerlettiR,LoConteLR.Advances in processing of surface myoelectric signals:Part1[J].Medical andBiological Engineering and Computing, 1995,33(3):362-372.
[2] Chan A D C,Englehart K,Hudgins B,etal.Myo-electric signals to augment speech recognition[J].Medical & Biological Engineering & Computing, 2001,39(4):500-504.
[3] Betts B J,BinstedK,JorgensenC.Small-vocabulary speech recognition using surface electromyography[J].Interacting With Computers, 2006,18(6):1242-1259.
[4] Jonas Dino. Ames Technology Capabilities and Facilities[EB/OL]. https://www.nasa.gov/centers/ames/research/technology-onepagers/human_senses.html
[5] Kapur A , Kapur S , Maes P . AlterEgo: A Personalized Wearable Silent Speech Interface[C]// the 2018 Conference,2018.
[6] Sugie N,Tsunoda K.A speech prosthesis employing a speech synthesizer-vowel discrimination from perioral muscle activities and vowel production[J].IEEE Transactions on BiomedicalEngineering, 1985,BME-32(7):485-490.
[7] Lopez-Larraz E,Mozos O M,Antelis J M,et al.Syllable-based speech recognition using EMG[C]//2010AnnualInternational Conference of the IEEE Engineering in Medicine and Biology,August31-September 4, 2010. Buenos Aires. IEEE, 2010: 4699-4702.
[8] Schultz T,WandM.Modeling coarticulation in EMG-based continuous speech recognition[J].Speech Communication, 2010,52(4):341-353.
[9] 金丹彤. 基于表面肌電信号的无声语音识别算法研究[D].浙江:浙江大学,2019.
[10] 刘镜,刘加.置信度的原理及其在语音识别中的应用[J].计算机研究与发展,2000,37(7):882-890.
[11] Jiang H.Confidence measures for speech recognition:a survey[J].Speech Communication,2005,45(4):455-470.
[12] Vovk V, Gammerman A,Shafer G.Algorithmic Learning in a Random World[J].2005:xvi.
[13] Smith K K.Anelectromyographic study of the function of the jawadducting muscles inVaranusexanthematicus (Varanidae)[J].Journal of Morphology,1982,173(2):137-158.
[14] Maier-Hein L,Metze F,SchultzT,et al.Session independent non-audible speech recognition using surface electromyography[C]//IEEE Workshop on Automatic Speech Recognition and Understanding,2005.,November 27, 2005.SanJuan,Puerto Rico. IEEE, 2005: 331-336.
[15] Chan A DC,Englehart K,Hudgins B,etal.Myo-electric signals to augment speech recognition[J].Medical & Biological Engineering & Computing, 2001,39(4):500-504.
[16] Schultz T, Walliczek M, Kraft F, et al. Towards Continuous Speech Recognition Using Surface Elec- tromyography. Bmj, 2006(29).
[17] Sch?ferKC,Balog J,SzaniszlóT,etal.Real time analysis of brain tissueby direct combinationofultrasonicsurgical aspiration and sonic spray mass spectrometry[J].Analytical Chemistry, 2011,83(20):7729-7735.
[18] Sakai M,Kitaoka N,Takeda K.Feature transformation based on discriminant analysis preserving local structure for speech recognition[C]//2009 IEEE International Conference on Acoustics,Speech and Signal Processing,April 19-24,2009. Taipei, Taiwan, China. IEEE, 2009: 3813-3816.
[19] BelhumeurPN,HespanhaJP,KriegmanDJ.Eigenfaces vs.Fisherfaces:recognition using class specific linear projection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997,19(7):711-720.
[20] Phinyomark A,HuH,Phukpattaranont P,etal.Application of linear discriminant analysis in dimensionality reduction for hand motion classification[J].Measurement Science Review, 2012,12(3):15-22.
【通聯编辑:唐一东】
