数据挖掘方法在网络学习行为研究中的应用
2020-09-29蒋雯音张颖童亚琴
蒋雯音 张颖 童亚琴


摘要:随着网络在线教育的普及,网络教学过程中产生了大量数据资源。在对数据挖掘理论和技术研究的基础上,利用SPSS Clementine工具并分别采用关联分析、聚类分析和决策树分析三种数据挖掘方法,对网络教学平台学习者的学习行为数据进行挖掘分析,探究网络学习行为与学习效果的关联、不同类型学习群体的学习特征、网络学习行为规律,最后分析总结了研究网络学习行為对于促进高效网络学习、优化网络教学策略、辅助网络教学决策方面的现实意义。
关键词:数据挖掘;网络学习行为;关联分析;聚类分析;决策树分析
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2020)17-0017-05
1 引言
随着移动互联网、云计算、大数据等新一代信息技术的发展及在教育领域中的应用,网络教学方式迅速推广和普及,各大在线教学平台推出了慕课(MOOC)、小规模限制性在线课程(SPOC)新型网络学习课程。学习者在网络学习过程中,网络教学平台获取并存储了大量与其网络学习行为相关的数据(如访问次数、学习时长、学习进度、作业及测试情况、参与互动情况等),这些数据是分析网上学习效果的宝贵资源,然而却没有得到足够的重视。如何将网络教学过程中产生的大量学习数据资源,转化为对教学决策有价值的信息,提升网络教学的质量和效果,是一个值得探讨的问题。因此,对网络学习行为的分析与研究受到了越来越多的关注和重视。
数据挖掘(Data Mining,简称DM)又被称为数据库知识发现[1],一般是指从大量的数据中通过算法搜索发现隐藏于其中具有潜在价值的信息的过程,从而帮助决策者发现规律、预测分类、辅助决策。数据挖掘是当前数据分析领域中最活跃最前沿的地带,是一种深层次的数据分析方法。因此,利用数据挖掘方法对学习者的网络学习行为进行客观、科学的分析和研究,挖掘蕴含在数据中的丰富价值,为学习者、教师及学校提供精准的支持服务,为网络教学提供决策,具有现实意义和价值。
2 常用数据挖掘方法
2.1 关联分析
2.1.1 关联规则
关联分析的目的是为了挖掘隐藏在数据间的相互关系,即对于给定的一组项目和一个记录集,通过对记录集的分析,得出项目集中的项目之间的相关性[2]。用关联规则来描述项目之间的相关性,一般表示形式为:X→Y(规则支持度,规则置信度),其中X和Y分别称为前项和后项[3]。
关联分析后会产生许多规则集,判断规则有效性的指标是规则支持度(反映规则普遍性)和规则置信度(反映规则的准确度)。如果一个关联规则的支持度和置信度均大于设定的最小支持度和最小置信度阈值,那么就是强规则,即表示该关联关系是有意义的,关联分析就是对强规则的挖掘。
关联规则挖掘过程分两步:首先,寻找频繁项集,即找出那些出现频率大于等于最小支持度阈值的项集;然后,从频繁项集中找出满足最小置信度的关联规则。
2.1.2 GRI(Generalized Rule Induction)算法
GRI算法是关联规则的算法之一,它采用深度优先搜索策略[3]:先确定一个后项Y进行分析,在分析后项Y时,依次分析该后项中包含的各个项目(Y1,Y2…Yn),在分析每个项目Yi时,又逐一分析其前项X所包含的各个项目(X1,X2…Xn),当前项中的每个项目Xi分析完,然后再分析下一个后项中的项目Yi,当后项中所有项目(Y1,Y2…Yn)全部分析完,就完成了对于一个后项Y的分析,分析完一个后项后再分析下一个后项,直至分析完所有后项。
2.2 聚类分析
2.2.1 聚类分析概述
聚类分析是按照个体特征的相似系数或者距离将他们分类,让同一个类别内的个体之间具有较高的相似度,不同类别之间具有较大的差异性[4],它属于无监督学习。通过聚类分析,可以了解数据的分布、比较分析各类的特征和规律,它在探索数据内在结构方面具有全面性和客观性等特点。
聚类分析中有不同的聚类算法,主要有划分聚类、层次聚类、基于密度聚类、基于网格聚类等,在实际应用中应根据不同的目标选择相应的聚类算法。
2.2.2 K-means算法
K-means是一种常用经典的划分聚类算法,它通过反复迭代调整类中心来划分样本所属的类,具体聚类过程[4]:
1)取K个初始质心:随机抽取K个点作为初始聚类的中心,来代表各个类;
2)把每个点划分进相应类:根据欧式距离最小原则,把每个点划进距离最近的类中;
3)重新计算质心:根据均值等方法,重新计算每个类的质心;
4)迭代计算质心:重复第2)步和第3)步,迭代计算;
5)聚类完成:类中心不再发生改变。
2.3 决策树分析
2.3.1 决策树概述
决策树算法的目的是通过向数据学习,实现对数据内在规律的探究和新数据对象的分类预测。决策树学习是已知数据类别的一种有监督学习,采用自顶向下的递归方法生成一种树型结构,树的最高层节点为根节点,中间各层的每个节点表示对于一个属性的判断或测试,每个分支表示一个判断或测试的输出,每个叶节点代表一种分类结果[5]。
生成决策树的过程就是不断分裂产生分支,每次选择可以得到最优分类结果的属性进行分裂,即经过这个属性的判断能使分裂后的子集中的记录尽可能的属于同一个类别,不断重复这一过程,直到达到停止分裂的条件。决策树算法的关键是分裂属性的选择以及分裂停止的判定。另外,由于异常数据等影响刚建立的决策树会过于复杂而出现过拟合的情况,导致预测不准确,因此需要通过剪枝对决策树进行优化[6]。
2.3.2 C5.0决策树
C5.0是一种经典的决策树算法,可生成多分枝的决策树或规则集,其目标变量为分类变量。C5.0决策树以信息增益率作为确定最佳分裂属性的标准,每次选择信息增益率最大的属性进行分裂拆分样本,每次拆分后的节点对应的子集继续根据另一个属性进行拆分,重复这一过程直到所有样本不能再被拆分为止。最后,从叶節点向上逐层进行剪枝优化,修剪掉那些没有意义的分支和节点[7]。
3 网络学习行为研究
3.1 研究内容
本研究利用职教云课堂平台上的一门SPOC课程的学习者网上学习数据作为数据样本,借助SPSS Clementine工具利用数据挖掘方法对学习者的网络学习行为进行研究,主要包括以下几个方面。
1)关联分析网络学习行为与学习效果关系
利用关联分析GRI算法对主要网络学习行为与学习效果之间的关系进行分析,探究不同学习行为对学习效果产生的影响。
2) 聚类分析学习者群体特征
利用K-means聚类算法将学习者划分为几大类型群体,挖掘同一类型群体中学习者的行为共性、不同类型群体之间的学习行为特性及差异。
3)决策树分析网络学习行为规律
利用决策树C5.0算法挖掘网络学习行为规律,构建决策树模型预测不同网络学习行为可能产生的学习效果,同时可以将学生分成不同层次,进而分析不同层次学生的网络学习行为特点。
3.2 数据挖掘方法应用
3.2.1 学习行为重要性分析
通过对云课堂平台上获取到的学习者学习数据的前期数据预处理后,共有456条样本作为分析对象。以各种学习行为作为输入变量,学习者的期末考核成绩作为输出变量,先找到对输出变量影响较大的输入变量,便于后续建模,因为过多的输入变量会产生共线性问题,筛选出有效的输入变量既可以提高模型稳定性,也能提高模型精确度。
利用“建模-特征选择”节点,分析出对输出变量有显著意义的输入变量如图1所示,可以看出对学习者的学习效果即期末考试成绩有重要影响的学习行为有:对学习资源的各种交互(包括问答、评价、笔记、纠错)、在线学习中的参与次数(包括提问、讨论、投票、头脑风暴、测验、课前课后参与、评价、总结等)、课堂表现(各类线上活动得分)、作业、学习时长。其他变量(如学习进度、考勤、访问次数等)在本样本中的标准差极小,即这些学习行为差异性非常小,因此不作为后续建模的输入变量。
3.2.2 网络学习行为与学习效果的关联分析
通过对各种学习行为重要性分析,选入8类学习行为作为建立关联模型的输入变量,由于这些输入变量都是数值型变量,因此选用关联分析中的GRI算法,对不同学习行为和学习效果进行关联分析。
1)关联分析建模
利用“建模-GRI”节点构建关联分析模型,选择自行指定建模变量,其中关联规则的前项为8类关键学习行为对应的8个变量,后项为考试成绩等级,这里将考试成绩分成A-优秀、B-良好、C-及格、D-不及格四个等级。
关联分析中,需要设定两个阈值即最小置信度和最小支持度,这里把最小支持度设定为10%,最小置信度设定为80%,分析后得到的置信度和支持度均大于给定阈值的关联规则即为强规则。另外,为防止关联规则过于复杂,指定前项中包含的最大项目数为4,生成关联规则的最大数目为10,GRI算法的参数设置如图2所示。
2)分析结果
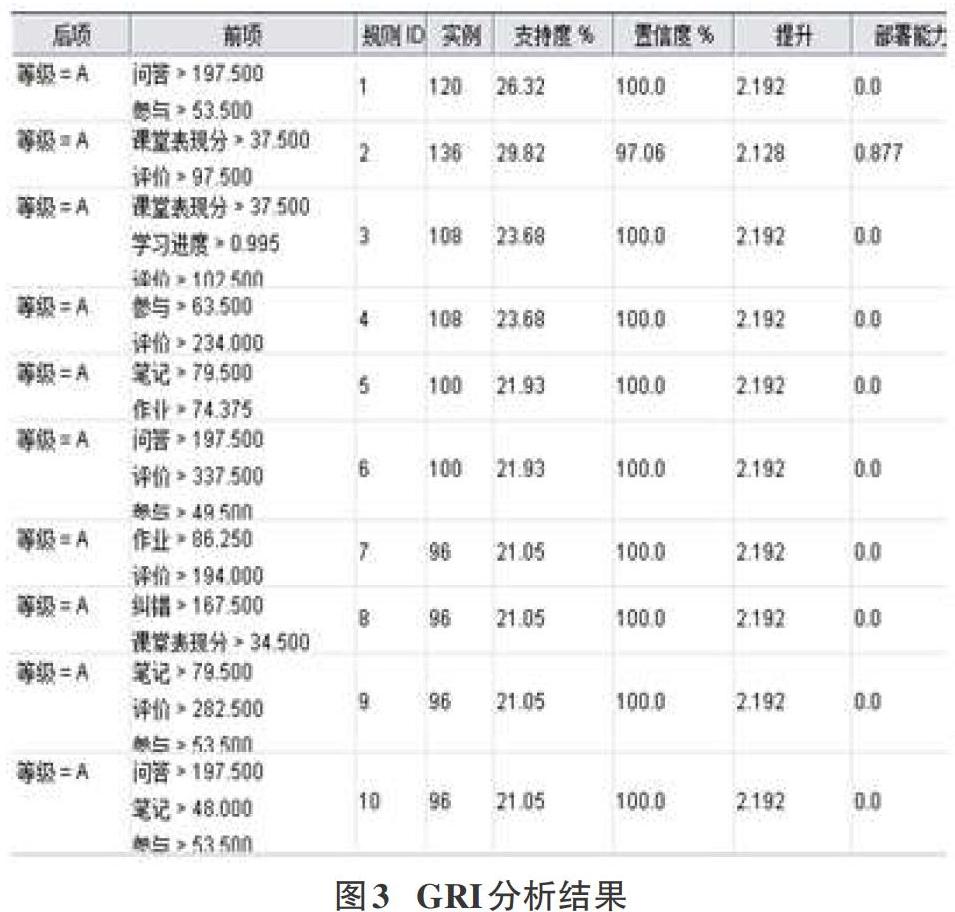
通过GRI算法关联分析,我们得到了关于后项成绩为A即优秀的10条关联规则,如图3所示。这些规则的置信度基本都达到了100%,说明规则的准确性较高;最大的频繁项集大小是3;提升度都大于1,反映了前项中的学习行为对后项中的学习效果有促进作用。
可利用关联规则考察分析哪些学习行为符合哪条关联规律,如规则1反映了“问答>197.5、参与>53.5”的学习行为与“等级=A”有关联关系,由此可认为具有这些学习行为表现的学习者成绩倾向于优秀的可能性较高。从分析得到的其他关联规则中,还可以发现各种不同的学习行为与“等级=A”之间的关联性。关联规则是对样本隐含规律的一种归纳和总结,这些规律体现了大部分学习者学习行为和学习效果的相互关系和影响,但值得注意的是,这些关联规则是基于特定训练样本集得出的,同时,由于关联规则本身并没有关于预测精度和误差的评价指标,因此通常不直接用于预测[3]。
3.2.3 网络学习行为聚类分析
根据已有网络学习行为数据类型特点,我们采用K-means聚类分析研究不同学习群体的学习行为特征。
1)聚类分析建模
利用“建模-K-Means”节点建立聚类模型,指定聚类数目为4类,同时输出各样本与所属类中心点的距离以及各个类中心点间的距离。以“聚类-1”这种字符后加数字形式表示聚类后的各类名称。选择“简单”模式即默认的参数进行聚类,聚类的迭代次数20,容忍度为0表示当最大的类中心偏移量小于0时停止聚类,满足两个条件中的一个即停止聚类。集合编码值可对分类型变量重新编码后调整其权重,由于分析的变量都是数值型,这里就不用设置,模型的参数设置如图4所示。
2)分析结果
聚类结果如图5所示,其中显示了四类包含的样本量、各变量的均值和标准差以及各类中心与其他类中心的距离,可以看出聚类-1和聚类-4之间的距离短,即两类较相似,而聚类-2和聚类-3较相似。
可以把聚类分析得到的四类结果看成四类学习群体,利用“图形-网格”节点,生成成绩等级和四类群体的关系如图6所示,保留强关系后发现,群体2和群体3中成绩优秀较多,群体1和群体4中成绩良好的较多,这也符合上面得到的各类之间的相似度。
以图形矩阵的形式显示各类中各变量的特征如图7所示,最后一列红色五边形表示八种学习行为在各类之间存在显著差异,从图中可以更直观地反映不同学习群体的学习行为特征,从而分析挖掘同一类型群体中学习者的行为共性、不同类型群体之间的学习行为特性及差异。如成绩优秀比例较高的群体2和群体3的学习行为主要特征是学习过程中对于学习资料的笔记、评价、问答等较多,而学习时长相比较群体1则较少,说明学习中的思考、互动对于学习效果有一定促进作用。
3.2.4 网络学习行为决策树分析
下面通过构建基于C5.0算法的决策树模型来挖掘网络学习行为规律,预测不同网络学习行为可能产生的学习效果。
1)决策树分析建模
建立模型前,利用“字段选项-分区”节点先把样本集随机分割成训练集和测试集两部分,训练集用于建立和训练模型,测试集用于估计模型的误差。
利用“建模-C5.0”节点构建决策树模型,C5.0算法能生成决策树,还可以生成推理规则集,使用推进方式即boosting 技术和交叉验证法建立模型,以提高模型预测精度和稳健性。C5.0决策树模型参数设置如图8所示。
2)模型结果
构建C5.0决策树模型的结果如图9所示,左图是从决策树上直接获得的推理规则,可以看到每个节点所包含的样本量及置信度;右图是生成的9层深度决策树(取部分),树的第一个最佳分组变量是评价,并以此形成二叉树,到下一层分别以学习时长和作业为分组变量继续往下生长。
从模型结果,我们发现学习者在评价、作业、课堂表现方面越突出以及学习时长越长,成绩为A优秀的置信度达到94%以上;而对于评价和学习时长方面表现较差的学习者,成绩为C合格的置信度为100%。将模型结果连到数据流中,并用“表”节点查看预测结果如图10所示,可以查看各样本的预测值($C-等级)和预测置信度($CC-等级),因此,通过决策树模型可以预测不同网络学习行为可能产生的学习效果。
4 小结
利用数据挖掘方法对学习者的网络学习行为进行分析和研究,挖掘蕴含在数据中的丰富价值,可以帮助我们找到网络学习行为与学习效果的关联,了解各類学生的学习特征,掌握网络学习行为规律,从而为学习者、教师及学校提供精准的支持服务,为网络教学提供决策,具有现实的应用价值。
4.1 有利于学习者调整学习状态、改善学习习惯,促进高效的网络学习
对于学习者,可以根据学习行为的分析结果,与其他学习者的比较,检查自己的学习情况,更全面清楚地了解自身的优势和不足,并调整下一步的学习计划和策略、改善学习习惯,从而进行更高效的网上学习活动。
4.2 有利于教师优化教学策略、开展个性化教学和实施科学的学习评价
对于教师,能准确掌握学习者的学习状态、学习风格和偏好、知识掌握程度等信息,从而采取有效的教学策略,引导、帮助学习者学习。同时,教师可根据不同类型学习者的网络学习行为特征,为各类学习者制定不同的学习计划和教学策略,提供的个性化学习资源以及不同类型的教学服务。另外,对学习者的网络学习行为进行跟踪、记录、分析和可视化,使学习评价更全面、真实和科学。
4.3 有利于指导网络学习资源开发和网络教学平台的建设和改进
对网络学习行为数据的挖掘分析能深入了解学习者使用学习资源的行为方式和习惯,帮助资源设计者开发出符合学习者学习方式和习惯的网络学习资源,为学习者提供更多资源获取渠道、多种处理和使用资源的方法。同时,通过了解学习者使用平台的方式,有助于平台设计者改进、健全网络教学平台,提高平台的个性化和智能化。
本文对数据挖掘方法应用于网络教学进行了初步研究,尚存在有待改进的地方,今后将会继续深入数据挖掘技术在教育教学方面的研究与应用,为促进信息技术与教学深度融合,探索建立信息化教学模式,构建和实施智慧课堂等方面提供借鉴和参考。
参考文献:
[1] Bing Liu. Web 数据挖掘(第2版)[M].北京:清华大学出版社,2012.
[2] 赵子江.数据库原理与SQL SERVER应用[M].北京:机械工业出版社,2006.
[3] 薛薇,陈欢歌.Clementine数据挖掘方法及应用[M].北京:电子工业出版社,2012.
[4] 数据挖掘-聚类分析总结[EB/OL].[2018-10-27].https://www.cnblogs.com/rix-yb/p/9851514.html.
[5] 第3章_分类与决策树[EB/OL].[2017-08-09].https://max.book118.com/html/2015/0709/20732251.shtm.
[6] 陈萍. 数据挖掘技术在网络教学中的应用研究[D].广州:广东技术师范学院,2015(5):12-14.
[7] 李庆香. 数据挖掘技术在高校学生成绩分析中的应用研究[D].西南大学,2009.
【通联编辑:王力】
