置信度辅助特征增强的视差估计网络
2022-08-09柳博谦刘嘉敏陈圣伦王智慧李豪杰
柳博谦,刘嘉敏,陈圣伦,王智慧,李豪杰
大连理工大学 国际信息与软件学院,辽宁 大连 116024
双目视差估计是计算机视觉领域中的一个重要方向,主要应用在自动驾驶、机器人导航、增强现实等任务中[1]。视差估计旨在对双目相机校正后的左右视图进行像素对匹配,估计的视差可以恢复场景的深度信息。该任务可以分为匹配代价计算、匹配代价聚合、视差计算、视差优化四个步骤[2]。在匹配像素点中,由于遮挡、低光照、弱纹理等干扰因素使估计高精度视差更具挑战性。
视差估计的本质是匹配问题,其目的是为左目视图每一个像素点在右目视图中寻找匹配差异最小的像素点。这里的匹配差异称为匹配代价。传统的估计方法可分为两类:基于全局的匹配和基于局部的匹配。基于全局的匹配首先构造一个全局能量函数用于约束匹配代价,最小化能量函数得到最优视差图[3]。Veksler[4]最先将基于图论的能量最小化理论引入到立体匹配领域。Boykov等[5]将图割问题(graph-cut,GC)引入到立体匹配中。全局的方法计算复杂度高,且难以找到全局最优解。基于局部的匹配,通过比较左右两图以待匹配点为中心的图像块的相似程度来确定匹配代价[6]。常见的相似程度的计算方法有绝对误差和算法(SAD)、误差平方和算法(SSD)以及归一化积相关算法(NCC)等。这些方法使用待匹配点不同的表示方法,比如像素灰度值、局部区域灰度值、Census变换等,来计算其匹配代价。这些方法计算复杂度低,但匹配块在纹理少的区域以及遮挡区域的效果不佳。因此,在局部匹配方法的基础上,Hirschmüller提出了半全局匹配法(semi-global matching,SGM)[7],该方法是立体视觉领域最经典的视差估计算法之一,通过不同方向的代价聚合操作来扩展匹配的比较范围。
随着人工智能的发展,基于深度学习的方法也应用在视差估计任务中。Žbontar提出的MC-CNN[8]利用深度学习来提取左右图像的特征,使用提取的特征来进行代价匹配及后续步骤。SGM-Net[9]利用神经网络来学习每个像素位置在SGM方法对应的聚合惩罚系数。上述方法使用深度学习提取特征,对传统方法进行辅助,但无法直接通过网络获取视差结果。
端到端的网络方法能便捷地解决视差估计问题,即仅通过一个深度神经网络输出视差图。在端到端网络的匹配代价计算中,计算一个表示特征匹配相似度的代价空间(cost volume)。Mayer等提出的DispNet[10]借鉴了光流估计网络FlowNet[11]构建一个存储左右图对应像素“相似程度”的一个代价空间。Pang等提出了一种新型的两级CNN结构[12],分别用于获得保留更多细节的视差图,以及对初始化的视差图进行优化。Yang等提出了SegStereo[13],将语义分割任务和视差估计任务结合起来。而Kendall等提出的GC-Net[14]是直接将左右特征进行串接,生成一个四维的匹配代价空间,之后使用三维卷积来实现匹配功能。PSMNet[15]在基于四维代价空间的网络框架中引入了空间金字塔池化层(spatial pyramid pooling),提升网络的感受野。Guo等提出的Gwc-Net[16]使用了一种新的代价空间构建方式,将分组的相似度和完整的特征这两类结合起来。
除了利用图像,通过向网络中引入稀疏视差信息可以对视差估计进行引导,从而提升视差图在其他位置的准确度。Poggi等提出一种视差引导方法[17],利用从外部传感器(比如LiDAR)获取的稀疏准确视差值来对代价空间进行增强操作。该方法可以提高网络在不同数据集下的鲁棒性,但是需要引入外部信息。当没有外部信息时,可以通过计算视差置信度,选取高置信度区域的视差作为特征增强的参考。因此,受到文献[17]的启发,本文提出了一种基于置信度的特征增强机制,对网络估算过程中产生的中间结果进行置信度的判断,预测视差估算的难易区域,对易匹配区域特征进行增强,从而辅助视差计算。置信度图作为特征增强参考的功能主要有两点:一是根据置信度筛选出需要增强的像素点;二是置信度的大小决定了特征增强的最大幅度。
1 方法
网络总体结构如图1所示,在基础网络结构中加入一个置信度估计子网络,估计视差图中间结果的置信度。在此之后,从置信度图中选取一些高置信度的像素点位置,在代价空间中对这些点上根据其中间视差结果进行增强操作。这样做的目的是将高置信度像素点及其视差信息引入到网络中,从而改善视差图的效果。
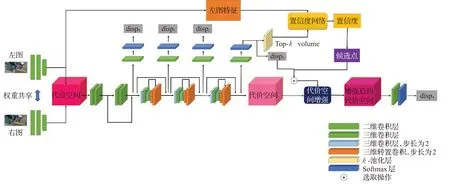
图1 网络整体架构Fig.1 Whole network structure
1.1 基础网络
网络可以分为基础网路、置信度估计子网络以及特征增强模块。其中基础网络可以是任意一个多阶段视差估计网络。这里使用的基础网络结构是Gwc-Net,可以分为四大部分:特征提取部分、代价空间构建部分、代价聚合部分和视差回归部分。
特征提取部分由初始网络和四组不同数量、不同形状的残差网络块以及融合网络构成。初始网络由3个带有批归一化(BatchNorm)和ReLU操作的连续卷积层构成,每个卷积层的大小为3×3,输出维度是32。其中第一个卷积层的步长为2。4个残差网络块的残差卷积层的个数、输出维度、步长、空洞系数不尽相同。每个残差卷积层包含带有BatchNorm和ReLU的基础层和只包含BatchNorm的残差层组成,基础层和残差层的尺寸都是3×3。第一个网络块包含3个输出维度为32的残差卷积层;第二个网络块包含16个输出维度为64的残差卷积层,除了第一个残差块的步长为2之外其余的步长都是1;第三个网络块包含3个输出维度为128的残差卷积层;第四个网络块中残差卷积层的个数和输出维度和第三个网络块相同,但是空洞系数为2。融合网络由一层带有BatchNorm和ReLU的3×3卷积层和一层1×1卷积层组成。在特征提取的时候依次将图像输入到初始网络以及四个残差网络块中。然后将第二、第三和第四个网络块的输出连接起来作为基础特征。最后将基础特征输入到融合网络中,得到连接特征。
在代价空间构建部分,Gwc-Net将3维代价空间构建和四维代价构建方法结合起来。即将基础特征按照通道进行分组,计算各个分组在不同候选视差下的特征相似度,然后和连接特征连接起来。这样做的目的是同时保留匹配结果以及完整的特征信息。这里的分组个数设为40,左右图像连接特征的通道数为12,因此代价空间的通道数为64。而在特征提取部分进行了两次下采样,因此代价空间的宽、高为图像的1/4,候选视差个数也是最大视差范围的1/4。
在代价聚合部分,使用三维卷积层和3个沙漏网络结构(hourglass)来实现代价聚合功能。沙漏网络结构的名称是从其形状得来的,它是由下采样操作和上采样操作结合。该结构最早是用于姿态估计[18],由于其网络结构,因而常常被用于像素级预测任务中。
在视差回归部分中,首先将代价空间输入到两层网络中,输出通道数为1的四维特征。该特征表示像素在所有候选视差下的匹配分数。由于在之前的步骤中进行了两次2倍下采样,在这里将该特征以及置信度图进行4倍上采样以还原到原尺度上。然后对每个像素点的所有匹配分数进行softmax计算,并根据其计算结果进行加权求和,得到最终的视差估计值。根据输入到沙漏网络之前的代价空间和3个沙漏网络输出的代价空间分别进行视差回归,得到4个中间视差图。根据这4个中间视差图,可以同时优化网络。其中,最后一个沙漏网络被用来估计置信度。首先,最后一个沙漏网络的部分输出被用来当作置信度估计子网络的输入之一。此外,最后一个沙漏网络估计出的视差被用来构建置信度的准确值。
1.2 视差置信度
在视差估计的场景中,存在这一些难以匹配的区域。比如在传统方法中,弱纹理的区域就是难以匹配的;而在深度学习方法中,由于需要对图像进行下采样和上采样,物体的边缘处很难预测出准确的视差。除此之外,在双目视差估计中存在着遮挡区域,即左图上有些区域在右图上找不到对应区域。为了找出这些难以匹配的区域并针对这些区域做优化,引入视差置信度的计算,根据置信度来判断哪些区域是难以匹配的。视差置信度是用来描述视差图的可信程度。作为系统的输出,视差置信度可以提供给人们来判断当前视差图有哪些区域是可信的。视差置信度的实际含义取决于其定义,可以分为以下几类:
第一类是基于匹配代价的置信度。这类置信度是根据最佳视差下的匹配代价和其他位置的匹配代价之间的关系计算出来的,表示的是视差匹配的二义性。比如peak ratio算法[19]:(其中,c1表示最佳视差下的匹配代价,c2表示次佳视差下的匹配代价,ε是一个非常小的正数)。
第二类是基于视差的置信度,一个例子是左右一致性(LRC)方法[20]。在此方法中根据左右图像匹配点在各自视差图下的视差值之差来判断置信度。
第三类是基于图像的置信度,这种置信度描述了直接影响匹配难度的图像属性,比如以当前像素为中心的图像窗口的纹理强度。
第四类是基于先验的置信度,这种置信度是与图片的颜色和视差是无关的,比如左图的最左边往往是找不到右图对应点的,因此属于低置信度。
第五类是基于视差误差的置信度,这类置信度经常在基于深度学习的方法中被使用。在这种情况下,置信度估计问题被当成像素级别的二分类问题。
其中,基于匹配代价的置信度经常在传统方法中使用,然而在视差回归所用到的匹配分数并不直接表示匹配代价,因此无法使用匹配分数作为匹配代价来计算置信度图。由于这个原因,基于匹配代价的置信度没有被使用。基于视差的置信度需要视差才能计算,因此未被使用。基于图像的置信度和基于先验的置信度无法描述视差估计网络中图像区域的匹配难度,因此也没有被使用。
综上,使用第五类置信度,即基于视差误差的置信度。因为区分图像中困难区域和简单区域的最直接的标准就是当前误差的大小,置信度高的地方代表误差小,此时可通过置信度判断误差是否过大。
1.3 置信度估计
使用基于误差的置信度,这个置信度值是通过一个置信度估计子网络估计而来。使用最后一个沙漏网络输出的视差误差来构建置信度的准确值:

其中,1(·)表示如果满足括号里的条件即为1,否则为0,d表示估计的视差,d gt表示准确视差,σ是阈值。
受到Kim等的视差置信度估计网络的启发[21],借鉴了其中的k-池化(top-kpooling)操作以及使用不同感受野的卷积层。不同的是,置信度估计网络不需要输入视差图,取而代之的是左图的特征。因此估计的置信度图是先验置信度图,其结果与视差值没有直接关系。使用的置信度估计网络如表1和图2所示。

表1 置信度网络结构Table 1 Structure of confidence network
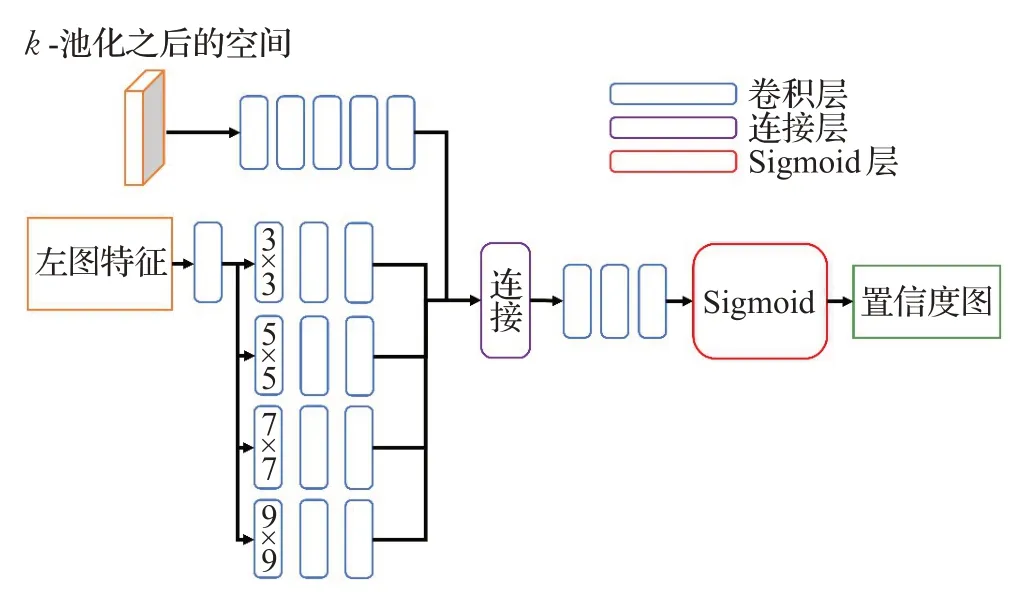
图2 置信度子网络架构Fig.2 Structure of confidence sub-network
首先将代价空间进行k-池化操作。在视差回归之前,需要将代价空间的通道数转换成1,这时代价空间表示的是像素点在每一个视差下的匹配得分。k-池化的操作就是在每一个像素的视差维度下选取其前k个值,从而将视差维度下的尺寸置为k。这里取k=5。k-池化的目的是保留匹配的二义性信息,同时减小模型所需内存。在此之后,对k-池化之后的代价空间以及左图的特征分别处理。这样做的目的是同时使用图像信息以及匹配二义性信息。将k-池化之后的空间送入到五层卷积网络结构,输出一个16通道的误差特征。对于左图特征,先经过一层卷积网络,再分别输入到4个子网络中,每个子网络包含一层n×n卷积,一层3×3卷积和一层1×1卷积。这里的n分别取3、5、7和9,这样做的目的是尽量提升感受野的尺寸。然后将这4个子网络的输出连接起来。最后将其和误差特征连接,送入三层卷积网络,进行sigmoid运算得到最终的置信度图。
1.4 特征增强操作
在估计出置信度图之后,在置信度图上找一些置信度足够高的点,然后通过这些点在当前估计视差下的代价空间进行增强操作。待增强点的选取策略如图3所示。首先将图像分为m×m大小的图像块,在图像块中选取一个像素作为候选像素,这样做的目的是扩大增强区域的分布。如果候选像素的置信度满足大于等于σ1或者属于前σ2的条件,则在该点处进行增强操作。这里设置m=2,σ1=0.95,σ2=10%。增强操作的幅度满足以估计视差为中心的高斯函数。特征增强公式如下:

图3 待增强点的选取策略Fig.3 Selection strategy of pixel for enhancement
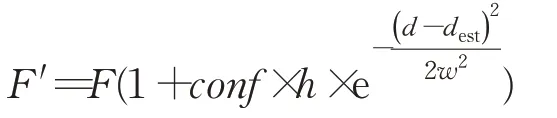
其中,F和F′分别表示增强前后的特征;conf表示置信度;d表示视差范围内的每一个离散视差值;dest表示用于增强的视差,在此处是估计的视差;h和w是高斯函数的参数。这里设置h=10,w=10。
特征增强的目的是增大像素点在正确视差下的特征,从而将高置信度的视差信息引入到网络中。特征增强的效果如图4所示。在每一个像素上,候选视差与估计视差值越接近,对应特征值增强幅度,即所乘的倍数就越大。其最大增强幅度与置信度成正相关。特征增强的本质是将可靠的中间视差值代入到网络中去,从而对网络进行引导。

图4 特征增强的效果Fig.4 Effect of feature enhancement
1.5 损失函数
网络的损失函数如下:
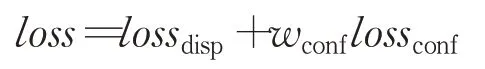
损失函数分为两个部分:视差损失函数lossdisp和置信度损失函数lossconf。视差损失函数使用的是L1损失函数,置信度损失函数lossconf使用的是二值交叉熵损失函数。

其中,w0、w1、w2、w3、w4分别取0.5、0.5、0.7、1.0、1.0。在构建置信度准确值的时候,将σ设为0.1。
2 实验
将网络在Scene Flow数据集上进行训练和评估。Scene Flow数据集是由Freiburg大学[10]提出,包含35 454张训练图和4 370张测试图。数据集图像是由Flyingthings3D、Driving和Monkaa这三类合成场景视频截取而来,尺寸是960×540。由于是合成数据集,Scene Flow数据集的图像具有稠密的准确视差值。
使用PyTorch来实现网络,使用的优化器是Adam优化器,其中β1=0.9,β2=0.999。一共训练18轮,初始学习率0.001,在10轮、12轮、14轮降低到原来的1/2。在训练的时候,在图像上随机截取大小为512×256的图像块,并将最大视差设为192。
使用以下指标来评价视差估计方法:平均点误差(EPE)和Th1。平均点误差指的是平均视差误差;Th1表示视差误差大于1个像素的点所占比值。这两个指标值越小代表效果越好。
不同实验配置下的实验结果如表2所示,选取最佳的实验配置结果进行后续的比较。
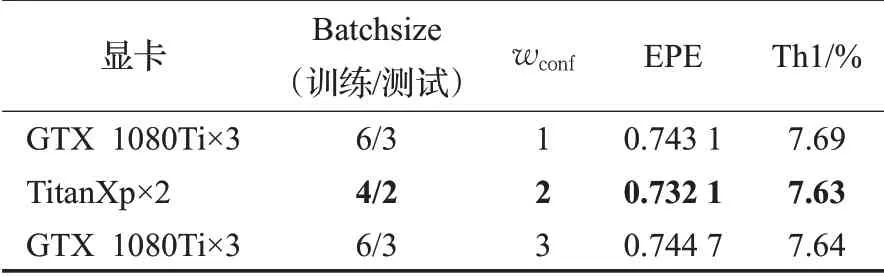
表2 不同配置下Scene Flow测试集结果比较Table 2 Comparation on Scene Flow dataset from different configurations
为了更全面的评估本文方法的效果,本文方法和近年来的一些经典方法进行了比较。此外,为了验证特征增强的作用,比较特征增强前后对应的视差结果。在Scene Flow数据集上的对比结果如表3所示。
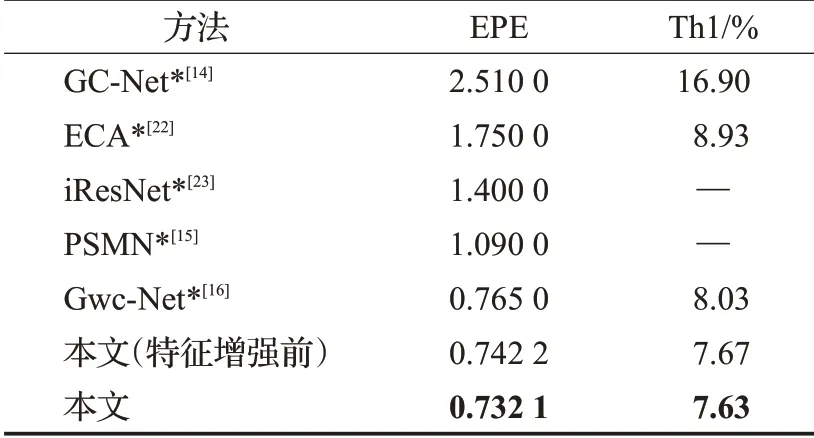
表3 Scene Flow测试集结果比较Table 3 Comparation on Scene Flow dataset
从表3中可知,相比于基础网络Gwc-Net,本文方法在EPE上和Th1这两个指标上是更优的。EPE是0.732 1,比Gwc-Net方法降低0.032 9;Th1是7.63%,比Gwc-Net方法降低0.4个百分点。此外,还比较了特征增强前后的视差图误差,发现特征增强后的视差图误差要小于增强之前的,证明了特征增强操作的有效性。EPE比特征增强前降低0.010 1;Th1比特征增强前降低0.04个百分点。
视差估计可视化结果如图5所示,置信度估计可视化结果如图6所示。由图6可知,估计出来的置信度分布可以描述不同区域图像的匹配难度,从而指导待增强点的选取。

图5 Scene Flow视差可视化结果Fig.5 Visualization of disparity result on Scene Flow dataset

图6 Scene Flow置信度可视化结果Fig.6 Visualization of confidence result on Scene Flow dataset
3 结语
针对双目视差估计问题中局部困难估计区域,本文提出了置信度辅助特征增强的视差估计网络。在基础网络结构中增加了置信度估计子网络来估计置信度图,之后在置信度图中选取一些置信度较高的点进行特征增强操作,即大幅度增强该点在估计视差处的特征值。通过增强特定位置的特征值,可以实现将高置信度像素点及其视差信息引入到网络中的功能,从而提升网络的性能。在接下来的研究中,将从两个思路来改进。首先是提高置信度图的质量,目前的置信度结果是比较模糊的,具有改进空间。此外,目前的特征增强方法可以和其他任务结合起来,例如实例分割任务。通过对置信度图改进和利用,可以进一步提升视差估计的精度。
