合作什么,去哪合作,与谁合作?
——专利视角下的校企合作对象选择系统构建*
2020-08-12冉从敬赵倩蓉
冉从敬,宋 凯,赵倩蓉,王 义
0 引言
在经济全球化时代,技术创新对推动经济发展具有重要意义,尤其在高新技术产业中,企业之间竞争激烈,对企业技术创造力提出更高挑战。随着新技术复杂度提高,单一企业完成技术创新的难度愈发增加。因此,自20世纪80年代以来,高校和企业之间的产学研合作行为大量涌现,已逐渐成为世界各国技术创新的主流模式。校企之间充分发挥彼此优势,鼎力合作,实现技术突破。1992年,由国家经贸委、国家教委和中国科学院联合组织实施“产学研联合开发工程”,这一工程对促进我国产学研合作、推动我国科技与经济的发展发挥了重要作用。2015年3月,《中共中央 国务院关于深化体制机制改革加快实施创新驱动发展战略的若干意见》发布,要求紧扣经济社会发展重大需求,着力打通科技成果向现实生产力转化的通道,把创新成果变成实实在在的产业活动[1]。2018年4月,《国务院关于落实<政府工作报告>重点工作部门分工的意见》发布,要求提供全方位创新创业服务,鼓励企业、高校和科研院所等开放创新资源,形成线上线下结合、产学研用协同、大中小企业融合的创新创业格局[2]。2019年1月,印发《国务院办公厅关于抓好赋予科研机构和人员更大自主权有关文件贯彻落实工作的通知》,要求各单位与企业通过股权合作、共同研发、互派人员、成果应用等多种方式建立紧密的合作关系,支持科研人员深入企业进行成果转化[3]。一系列政策的颁布表明,企业通过与高校展开合作,对推进资源的区域整合与共享,促进高校科技成果转移转化,推动企业科技创新和经济社会发展深度融合具有重要意义。高校在技术研发、人才资源、实验条件方面具有相对优势,而企业在技术转化、就业岗位、资金支持上具有独特优势,两者合作能实现优势互补,为推进科技创新发展提供了实践路径。
学者从多个角度对校企合作展开探讨。在研究校企合作影响因素方面,Rybnicek等系统论述影响校企合作的重要因素,如制度因素、关系因素、产出因素、框架因素[4]。Sjoo等采用系统性的文献综述和内容分析法总结了校企合作创新的影响因素,包含文化、合作经验、资源等[5]。刘桂锋等运用社会网络分析法绘制“211工程”高校与企业之间的产学研专利合作网络,并重点探讨了技术领域和地理距离对校企合作的影响[6]。刘继红等从高校科研人员角度,对校企知识转移途径及其影响因素进行了系统研究[7]。在研究校企合作的促进作用方面,Han等运用负二项回归法分析韩国135所高校技术转移的影响因素,提出高校应积极开展与民营企业的合作,以提升技术转移效率[8]。Nave等从企业家视角出发,借助于半结构化访谈法探讨校企合作对企业可持续发展的影响[9]。孙玉涛等以社会网络理论与资源基础观为基础,认为在高校与其他机构的研发合作过程中校企研发合作及其规模有利于高校技术转移[10]。王晓红等利用2007-2014年88所高校面板数据,采用Sys-GMM模型,实证研究校企合作对我国高校科研绩效的影响[11]。在研究校企合作演进态势方面,Lyu等基于社会网络分析法和空间分析法,探索我国中关村企业、高校和科研机构的合作创新发展趋势[12]。张珩等基于国家知识产权局公开的1985-2015年江苏省校企合作发明专利申请数据,运用社会网络分析法,分析专利合作网络结构及空间分布演化路径[13]。陆亦恺等以中国C9联盟高校为研究对象,运用社会网络分析法,探讨了我国高校专利合作的主要特征与模式[14]。许敏等基于71所高校与企业合作申请的发明专利数据,运用社会网络分析法,分析了专利合作网络空间分布特点与网络结构特征[15]。
综上可见,目前已有研究集中在校企合作影响因素探索、校企合作促进作用分析以及校企合作发展态势揭示等方面,较少从合作对象选择的角度出发,探讨为企业提供最佳合作院校的选择策略。校企合作是为了把市场需求和整体利益联合起来,采取多种方法所进行的科研开发、咨询服务等经济合作活动,是技术创新上游、中游、下游的融合。在企业的重点研究领域,与具备较强研发能力的科研团队展开合作,能够进一步深化技术研究,拓展创新边界;在企业技术薄弱领域,通过校企合作可快速提升企业技术能力,进而推动高校科技成果转化。因此,制定精准的合作对象选择策略,对企业的技术创新以及高校科技成果转化具有重要的推动作用。基于以上需求,本文从企业视角出发,构建校企合作对象选择模型。由于一个技术领域中会存在多个子领域,如电动汽车技术存在电池系统、发动机、运行控制、传感器等多个子技术领域,所以,有必要从更加细粒度的层面探索校企合作对象的匹配路径。因此,当企业锁定一个技术领域,首先对高校专利文本进行检索,利用LDA模型进行主题建模,并结合K-means 算法实现专利文本聚类;企业依据自身研究重点及薄弱领域选择对应的子领域主题,以相似专利密度为指标对子领域主题下的高校进行排名,并以相似专利为媒介构建科研团队核心合作网络,从而确定企业在重点研究领域和薄弱领域下的最佳合作高校;在高校排名的基础上,借助相似专利密度指标,对高校中的科研工作者进行排名,发掘科研大咖,最终为企业锁定合作高校、建立校企产学研合作关系。在理论研究的基础之上,以校企合作对象选择模型为底层逻辑,构建相关的服务系统——IUC,实现将理论研究应用于产业实践,在人工智能环境下,解决校企合作中存在的3W问题,提高校企合作效率,进而推动企业技术创新、实现高校科技成果转化。
1 关键技术应用
1.1 主题模型
考虑到一个技术领域会涵盖多个子技术主题,在校企合作对象选择过程中,有必要对相应技术领域中的专利文本进行主题建模,明确其涉及的子领域主题。因此,本文采用LDA模型对专利文本进行主题提取。LDA模型假设词是由一个主题混合产生,同时每个主题是在固定词表上的一个多项式分布,这些主题被集合中的所有文档所共享,每个文档有一个特定的主题比例,从Dirichlet 分布中抽样产生。作为一种产生式模型,其结构完整清晰,采用高效的概率推断算法处理大规模数据,是目前研究和实践中使用非常广泛的一种主题识别模型[16]。
在主题发现与主题演化研究中,利用LDA模型能够展示主题抽取的结果,涵盖文档-主题概率矩阵、主题-词概率矩阵、主题相关词列表等。而应用LDA最大的问题是需要人工确定主题数目,主题数目的确定直接影响主题发现的效果。因此,本文利用主题之间的平均余弦相似度来度量主题结构的稳定性:调整主题数目、alpha值和beta值,令主题间平均相似度最小,对应模型最优。计算过程如下:

在(1)式中,Sim(PA,PB)表示专利文本A 和专利文本B之间的余弦相似度,利用LDA模型能够提取文档-主题概率矩阵。某个主题在一篇文章中的概率分布,可视为该主题对当前文献的支持度,支持度越大,表示该文献内容越趋向于该主题,因此一篇文章可表示成多个主题的概率分布P=(T1,T2,…,Tn)。Si表示每个主题T对文献P的 支 持 度,则P=(T1,S1;T2,S2;…;Tn,Sn),简记为P=(S1;S2;…;Sn)。比如,两篇专利文本的主题概率分布为: (0.02857,0.02857, 0.171428, 0.02857, 0.02857,0.02857, 0.02857, 0.02857, 0.457142,0.171428) 和 (0.0125, 0.0125, 0.0125,0.0125,0.0125,0.0125,0.0125,0.0125,0.8875,0.0125),则依据(1)式计算主题相似度结果为0.888。avg_Sim(structure)表示所有专利文献的平均相似度,K表示文献数量,平均余弦值在0和1之间,值越小,表明主题结构最优。
1.2 聚类算法
在明确技术领域涵盖的主题后,需要将专利文本划归到子技术主题中,整个划分过程为无监督方式。因此,本文采用聚类算法实现对专利文本的划分。考虑到每一项专利进行技术探讨时,技术主题具有专一性、深入化的特征,所以在进行聚类时将一件专利仅划入一个主题类团中。聚类分析是知识发现中的重要研究内容,旨在将数据集合划分为若干个类,使得类内差异小,类间差异大。本文采用的K-means 算法,是数据挖掘十大经典算法之一,由J.MacQueen于1967年提出,具有简单、容易实施、时间复杂度接近线性的优点,且对大规模数据挖掘具有高效性和可伸缩性,被广泛应用于文本聚类的研究中[17]。文档-主题概率矩阵,利用K-means算法进行文本聚类,设置聚类数和初始聚类中心,设置迭代次数,实现专利文献的聚类划分。
1.4 共现分析
1.3 文本聚类
在文本聚类方面,由于文本向量维度高,具有稀疏性,不同簇之间的差异性较大,因此可能导致聚成一簇的文本之间的非相似性。同时,应用K-means算法存在随机选取初始聚类中心导致聚类结果不稳定的现象,往往容易陷入局部最优解的问题,导致较差的聚类结果。所以,如何获得合适的初始聚类中心,并在保证算法结果稳定性的同时保持其准确性,对提升算法的聚类性能尤为重要。因此,本文将LDA 模型和Kmeans算法融合实现专利文本聚类,利用LDA提取的文档-主题概率矩阵,将每篇专利文献表示成各主题下的概率分布,降低文档向量的维度;然后在K个主题所在的维度上确定初始聚类中心,理论上保证了选择的初始聚类中心是基于概率确定的,并进一步用这K个初始聚类中心对专利数据集进行聚类。主要计算过程如下:
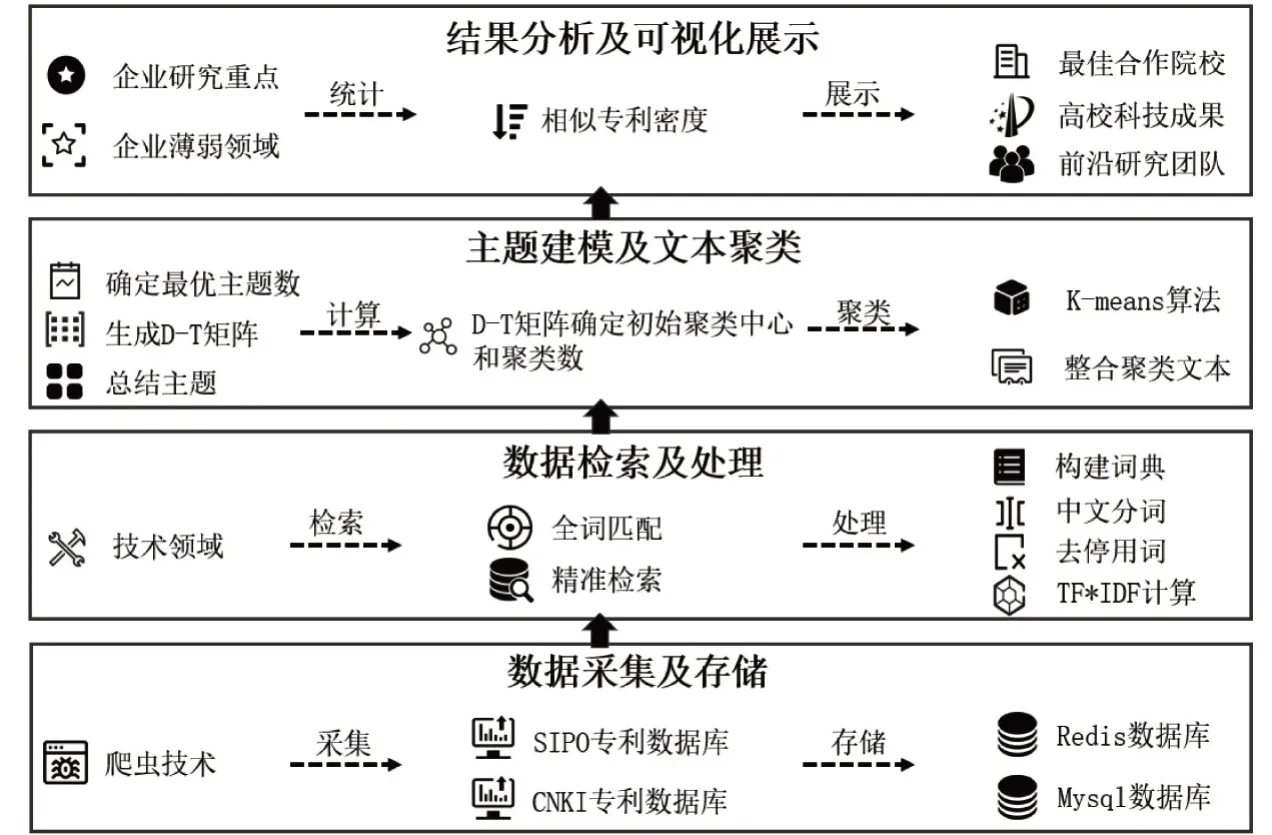
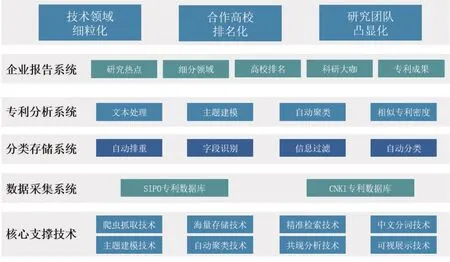
(1)通过设置不同的主题数目、alpha 值、beta值,经过多轮主题相似度计算迭代,确定最优主题数目K;(2)利用LDA模型对P 篇专利文献进行主题建模,生成P*K 维的文档-主题概率矩阵;(3)对每一个技术主题,首先计算该主题对P篇专利文献的平均支持度Si(0 通过文本聚类,能够实现子技术主题下的高校专利文献聚类;划分在同一主题类团下的专利文献可视为相似文献,根据相似专利密度指标可进行高校排名。而在一件专利中,通常包含多个发明人,作为专利核心技术的掌握者,这也正是校企合作中企业真正合作的对象。因此,本文通过共现分析,探寻高校中的核心研究团队和科研大咖。“共现”是指文献中特征项描述的信息共同出现的现象,而共现分析是将各种信息载体中的共现信息定量化,以揭示信息的内容关联和特征项所隐含的寓意。专利文献中专利发明人之间的共现频次体现了其关联程度,依据发明人共现分析构建合作网络,能够为企业探寻高校核心研究团队和科研大咖提供指引,从更加微观的层面为企业明确合作对象。 图1 校企合作对象选择模型 在主题模型、文本聚类、共现分析等技术的支持下,本文从企业视角出发,构建了校企合作对象选择模型(见图1),帮助企业在明确研究重点和薄弱领域的前提下,从更加细粒度的子技术主题层面,以相似专利密度为指标,探寻最佳合作高校。并在此基础上,进一步发掘高校核心研究团队、科研大咖和科技成果,实现提升校企合作效率,促进企业技术创新,推动高校科研成果转化的目标。 从图1 可以发现,整个模型共分为4 大部分,涵盖“数据采集及存储→数据检索及处理→主题建模及文本聚类→结果分析及可视化展示”的全过程。具体内容如下: (1)数据采集及存储。精准的校企合作匹配需要专利大数据的支持,为了能够获取足够的专利数据支撑,利用爬虫技术对SIPO专利数据库或CNKI专利数据库进行数据抓取,抓取的数据仅用于学术研究使用。在抓取过程中,数据缓存在Redis 数据库中,然后循环从Redis 读取数据,写入到Mysql中以支持服务系统建设。 (2)数据检索及处理。从企业视角出发,当企业检索某一技术领域,则服务系统会从Mysql数据库中进行检索,对题目和摘要字段进行全词匹配,构成匹配数据集。进而对匹配数据集进行自然语言处理,实现分词、去停用词以及TF*IDF词权重计算。分词所参照的词典是基于专业文献关键词所构建的全学科领域词典,以保证对不同技术领域数据集分词的有效性。而根据TF*IDF词权重计算的结果,采用五分位算法,去除概率在16%区间内的无效词,以获取更优的主题建模效果。 (3)主题建模及文本聚类。以检索到的匹配数据集作为实验语料,首先利用LDA模型进行主题建模。在主题建模过程中,根据以往研究中语料库规模与设置的主题数目经验,将主题数目设置在5-50个之间,alpha值及beta值固定为0.5和0.2。通过反复迭代计算,利用余弦相似度计算结果确定当前实验语料的最优主题数目,生成文档-主题概率矩阵(D-T矩阵),以及每个主题下最相关的20个词用于解释主题。根据初始聚类中心的计算过程,利用D-T矩阵确定初始聚类中心,进而利用K-means算法实现专利文本聚类。 (4)结果分析及可视化展示。基于主题展示,企业从细粒度层面确定自身研究重点和薄弱领域,并选择子技术主题发掘最佳合作高校及高校背后的核心研究团队。在分析过程中,以相似专利密度作为排名指标,对子技术主题下的高校相关专利进行统计。企业在选定某所高校后,将进一步对该高校的专利进行更微观的分析:首先针对发明人进行共现分析,构建合作网络展示核心研究团队;进而以相似专利密度为指标,对发明人进行排名,凸显科研大咖,并对科研大咖的个人资料、合作网络、科技成果进行展示。需要说明的是,因为高校科研人员数据库构建复杂度较高,本文没有将其作为研究重点实现突破。 基于校企合作对象选择模型,能够为企业提供“技术主题→合作高校→科研团队→科研大咖→科技成果”五维立体的全景化分析。在明确技术领域后,依据当前高校在该技术领域各个方向上的成果形成多个子技术主题,企业根据自身研究重点和薄弱环节进行选择,最终匹配最佳合作高校,并进一步发掘高校中的核心研究团队及科技成果。为了验证模型的有效性,以及模型的应用效率,本文以对象选择模型为逻辑支撑,构建原型系统,以此提升校企合作效率。 为了验证所提模型的有效性和合理性,本文将理论研究与产业实践相融合,基于校企合作对象选择模型的逻辑流程,构建校企合作对象选择服务系统——IUC,实现了专利数据库信息抓取,专利数据多维分析以及在人工辅助基础上的分析报告撰写,为推动校企合作提供系统支持。 IUC系统通过智能爬虫跟踪采集专利数据库最新数据,实现数据自动获取。字段自动识别、海量数据存储、领域主题抽取、文本自动聚类、指标统计分析等,在技术领域细粒度层面,对高校排名、核心团队、科研大咖、科技成果进行可视化呈现,并生成校企合作对象选择分析报告,实现技术领域细粒化、合作高校排名化、研究团队凸显化的全流程式服务,解决校企合作过程中存在的“合作什么?去哪合作?与谁合作?”的3W问题,切实提升校企合作效率。IUC系统架构见图2。 图2 校企合作对象选择服务系统—IUC系统架构 (1)核心支撑技术。系统涉及的核心技术贯穿从“数据采集→数据处理→数据存储→数据分析→数据应用”的全过程,涵盖爬虫技术、数据库技术、自然语言处理、主题模型、文本聚类、知识图谱等,从细粒度层面为精准的校企合作提供技术支撑,保证系统分析结果的合理性,为企业提供全景化的分析结果。 (2)数据采集系统。目前IUC系统专利数据主要来源于CNKI 专利数据库,采用Scrapy+Redis+MySql 分布式爬取专利数据。通过Python3.6 和Scrapy,配合自动化测试工具Selenium,构建了专利数据爬虫。 (3)分类存储系统。通过分布式爬虫爬取的数据以json格式存储在内存数据库Redis中,通过参数设置确保专利数据缓存到内存中时实现去重;通过Mysql创建数据库和对应的数据表,设置发明人、摘要、申请人、申请号、发表时间等字段;利用Python 中的pymysql 包将Redis 缓存数据导出至Mysql;并采用Twisted框架的连接池实现数据插入Mysql的异步化,最终实现专利数据存储,为IUC系统提供数据支持。 (4)专利分析系统。在文本处理模块,应用开源技术jieba-analysis(java版),自定义词典数据来源于多学科专业文献中的关键词部分组成,通过jieba-analysis实现中文分词、去停用词以及TF*IDF计算的整个自然语言处理过程;在对专利数据集进行主题建模阶段,应用开源技术LDA4j实现LDA主题建模;在主题建模过程中通过迭代计算平均主题相似度,确定最优主题数目,并利用KUMO开源技术实现主题词云展示;在确定最优主题数目后,利用文档-主题概率矩阵确定初始聚类中心,并基于开源的K-means 算法实现专利文本聚类;以相似专利密度为指标对主题类团内的高校进行排名,基于开源技术Echarts 实现高校排名、合作网络等结果的可视化呈现。 (5)企业服务系统。IUC服务系统展示前端采用开源技术BootSrap框架,整个业务处理层的实现基于SpringBoot框架;采用Spring MVC与RESTful技术实现对外开放接口,利用AJAX异步请求技术以及JSON技术来实现前后端的数据交换;数据访问层则采用MyBatis作为ORM框架,在内置分析算法的支撑下,实现技术领域细粒化、合作高校排名化以及研究团队凸显化。企业依据平台分析结果,可通过人工辅助的方式,生成全景化、深入化的校企合作分析报告。 图3 IUC首页技术领域搜索 本文以“众安信息技术服务有限公司”作为模拟企业对象,“众安科技”作为国内首家互联网保险公司——众安保险的全资科技子公司,一直聚焦于人工智能、区块链等领域的基础技术研发。而“区块链”被认为是继蒸汽机、电力、互联网之后的下一代颠覆性技术,目前是各界所关注的焦点。因此,选择“区块链”作为检索技术领域,当“众安科技”注册登录平台后进入IUC服务系统首页(参见图3),在搜索框输入“区块链”进行分析。 图4 “区块链”主题抽取词云展示(部分) 目前IUC的测试专利数据来源于CNKI专利数据库,在数据抓取过程中,申请人限定为“大学”;学科限定为农业科技、医药卫生科技、信息科技、经济与管理科学四大门类;时间为2017年1月1日至2019年9月1日,通过智能爬虫共抓取到186,708条数据。“众安科技”输入技术领域后,IUC以此作为关键词进行检索,为保证检索的精准度,对专利名称和摘要进行全词匹配,共检索到654 条数据,生成数据集;进而进行主题建模,通过平均余弦相似度迭代计算,当主题数为10个时,平均余弦相似度最小,主题结构最优。生成主题词云,见图4。 “众安科技”可根据自身在区块链领域的专利申请情况,确定重点研究领域及薄弱领域,依据主题建模结果展开进一步分析。一方面可以选择在其重点研究领域具备同等竞争力的高校,深化重点领域的研究深度;另一方面,针对自身研究薄弱的技术领域,选择对应合作高校加以提升,在高校科研团队的支持下,实现薄弱领域的突破,既节约了企业的研究成本、提升了企业的科技竞争力,也能够推动高校科技成果的转移转化,实现科技成果到产业应用的跨越。“众安科技”选择“主题2→数据存储”进行分析,依据文本聚类结果和相似专利密度指标,对子技术主题下的高校进行排名,结果见图5。 分析图5 发现,在“主题2→数据存储”中,“广东工业大学”“暨南大学”“浙江大学”的相似专利密度为6件、5件、5件,可作为“众安科技”在区块链数据存储技术领域合作中重点关注的高校。在此基础上,从更微观的层面分析高校中的核心研究团队,为企业提供更为细粒度的合作对象指引。例如,当“众安科技”选择查看“广东工业大学”时,分析结果见图6。 图5 主题2-高校相似专利密度排名 图6 广东工业大学核心科研团队 分析图6可发现,依据发明人共现分析构建的合作网络,在“主题2→数据存储”中,“广东工业大学”形成以“张浩川—余荣”和“何少伟—张俊”等为核心的两支研究团队。以“张浩川—余荣”为核心的研究团队规模最大,科技成果最多,是“众安科技”需要重点关注的科研团队。依据相似专利密度指标,对发明人进行排名,其中张浩川是“广东工业大学”在“主题2→数据存储”中的科研大咖,在合作网络中也占据核心位置。“众安科技”可选择查看科研大咖的详情,参见图7。 图7 广东工业大学科研大咖简介 科研大咖页面(图7)呈现张浩川的基本资料,包括教育背景、所处位置、研究重点及联系方式。对其参与申请的专利进行词云展示,揭示其历年专利申请情况。“众安科技”可根据详情选择关注此科研大咖,将其添加到人才库中,以备进一步合作。选择研究团队可查看该科研人员与哪些人员产生过合作,见图8。 图8 广东工业大学科研大咖合作网络 从图8中可得,张浩川与余荣、倪伟权等10位科研人员有过合作,参考发明人合作网络,此11位成员构成了子技术领域下的核心研究团队,而张浩川在整个团队中处于核心位置。因此,当“众安科技”计划在“主题2→数据存储”中展开校企合作,可通过张浩川发掘到以其为核心的广东工业大学研究团队。校企合作一方面可以促进企业技术创新,另一方面也能推动高校科技成果转化,所以“众安科技”通过查看科研大咖的相关科技成果,在推动企业技术发展的同时,也对其中的高价值专利进行转化,有利于扭转当前高校科技成果转化难的困境,推动高校科研团队的技术成果转化为产业价值。 通过以上分析可知,“众安科技”获取了高校在区块链领域下重点研究的10个子技术主题,从细粒度层面,根据自身研究重点和薄弱领域,探寻子技术主题下的最佳合作高校,进而以相似专利为媒介,发掘了高校核心研究团队以及科研大咖。IUC服务系统为“众安科技”提供了“技术主题→合作高校→科研团队→科研大咖→科技成果”五维立体的全景化分析结果,解决了企业在校企合作中存在的3W问题:What(合作什么)、Where(去哪合作)、Who(与谁合作)”,提升了校企合作效率,为促进企业科技创新,推动高校科技成果转化提供了实践路径。 本文从企业视角出发,以校企合作对象选择作为研究重点,在主题模型、文本聚类、共现分析等核心技术支撑下,构建了校企合作对象选择模型;并在此基础上,以对象选择模型为逻辑支撑开发IUC服务系统,以“技术主题-合作高校-科研团队-科研大咖-科技成果”五维立体方式展示全景化的分析结果,解决了企业在开展校企合作过程中存在的3W 问题,为提升校企合作效率提供系统支持。主要研究内容如下: (1)在核心技术研究层面,以Scrapy+Redis+MySql为技术手段实现智能爬虫,为IUC服务系统提供数据支撑;利用主题间平均余弦相似度解决LDA最优主题数目确定问题;将LDA模型与K-means算法融合,解决文本聚类过程中存在的初始聚类中心随机选取问题,提升了专利文本聚类效率。 (2)在对象选择模型构建层面,构建了以“数据采集及存储→数据检索及处理→文本建模及文本聚类→结果分析及可视化展示”为主要内容的逻辑模型,为IUC服务系统的开发提供了逻辑流程支撑。 (3)在IUC系统开发层面,以“众安科技”为企业对象,以区块链为技术领域,展示了全景化的分析结果,为“众安科技”在区块链领域开展校企合作提供了决策支持。 需要说明的是,高校科研人员数据库构建难度较大,需要通过高校+科研人员的方式逐一抓取数据,才能实现科研大咖基本信息展示;此外,在中文自然语言处理过程中词典的构建以及K-means算法初始聚类中心的确定方法都有待进一步改进,以提高分析结果的准确性,这将是今后研究的重点。本研究团队将把IUC服务系统代码开源,提供完整的说明文档供其他研究团队参考利用,通过不断完善当前平台功能,为提升我国校企合作效率、促进我国科技创新贡献更多力量。2 校企合作对象选择模型构建
3 校企合作对象选择服务系统——IUC实现
3.1 系统架构
3.2 核心功能展示





4 研究总结及展望
