基于ICNN和IGAN的SAR目标识别方法
2020-07-22仓明杰喻玲娟谢晓春
仓明杰, 喻玲娟, 谢晓春
(1.江西理工大学信息工程学院, 江西赣州 341000; 2.赣南师范大学物理与电子信息学院, 江西赣州 341000)
0 引言
近年来,卷积神经网络(Convolutional Neural Network, CNN)已广泛应用于合成孔径雷达(Synthetic Aperture Radar, SAR)目标识别。由于SAR数据采集难度大,用于目标识别的数据集通常较小,如MSTAR数据集[1-3]、极化SAR数据集[4-5],以及船只数据集[6-7]等,因此,基于CNN的SAR目标识别容易产生过拟合问题。为了解决该问题,4个方面的改进方法被提出。网络结构改进方面:Chen等提出用卷积层替代全连接层的方法[1];Pei等提出多视深度学习框架[8];Shao等提出基于注意力机制的轻量级CNN[9];Gao等提出双通道CNN[10]。数据集扩充方面:Ding等提出了3种数据扩充方法[11];Lu等提出了一种改进的目标旋转扩充方法[12]。迁移学习和CNN相结合方面:Huang等利用大场景图像对卷积自编码器进行训练,然后迁移到SAR图像目标识别[13];Wang等利用ImagNet数据集上训练好的VGG16模型迁移到SAR图像目标识别,然后用SAR数据对预训练好的模型进行微调[14]。无监督预训练和CNN相结合方面:卷积自编码器是一种无监督训练方法,先将训练好的卷积自编码器的编码器参数初始化CNN,然后再对CNN模型进行微调[15-16]。
生成对抗网络(Generative Adversarial Network, GAN)也是一种无监督训练网络,通过生成器和鉴别器两者之间的博弈,使得生成的图像难以被鉴别器鉴别[17]。目前基于GAN的SAR目标识别研究较少,Gao等提出一种包含多个生成器、一个鉴别器和一个多分类器的GAN,并应用于SAR图像目标识别[18]。本文采用多层特征匹配[19]的思想改进GAN,并采用多层特征合成的思想改进CNN,进而提出一种基于改进的卷积神经网络(Improved Convolutional Neural Network, ICNN)和改进的生成对抗网络(Improved Generative Adversarial Network, IGAN)的SAR目标识别方法。MSTAR实验结果表明,该方法比直接采用ICNN的方法,不仅具有较高的识别率,而且具有更强的抗噪声能力。
1 基于ICNN和IGAN的SAR目标识别方法
基于ICNN和IGAN的SAR目标识别方法如图1所示,先采用训练样本对IGAN进行无监督预训练,然后将训练好的IGAN鉴别器参数初始化ICNN,再利用训练样本对ICNN微调,最后利用训练好的ICNN进行测试样本的分类。该方法的详细步骤如下:
1) 将随机噪声作为IGAN的输入,经生成器G得到生成样本;
2) 将真实或生成样本输入到鉴别器D,D的输出为属于真实样本或生成样本的概率;
3) 利用后向传播算法更新G和D的参数,直到达到纳什平衡;
4) 将训练好的D参数初始化ICNN;
5) 利用带标签训练样本对ICNN微调;
6) 将测试样本输入到训练好的ICNN,得到其所属类别。
1.1 ICNN
传统的CNN包括输入层、隐藏层和输出层,其中,隐藏层又包括卷积层、池化层和全连接层。在CNN基础上,ICNN对隐藏层结构进行了改进,输出层仍为常用的Softmax分类器。ICNN隐藏层的改进之处主要有:1) 采用步长为s(s≥2,s∈N+)的卷积层替代池化层;2) 采用池化层以实现不同层次特征图的尺寸相同化;3) 增加特征合成层,将不同层次特征图进行合成。因此,ICNN的结构可以概括为卷积层、池化层、特征合成层、全连接层及Softmax分类层,如图1所示。由于特征合成层的运算为特征图的简单合并,接下来详细分析其他层的运算过程。
1) 卷积层


2) 池化层
ICNN的池化运算是将不同卷积层的输出特征图的尺寸相同化,以在隐藏层的最后一层实现不同层次特征的合成。假定第L+1层为特征合成层,则第l(1≤l≤L)层第j通道的特征图的池化运算结果为
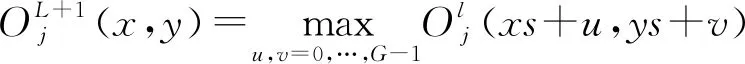
(2)
式中,G表示池化窗口大小,(x,y)表示第L+1层特征图的像素坐标位置。
3) 全连接层

(3)
4) Softmax分类层
假定目标总共有K类,将全连接层的输出进行Softmax分类,则输入样本属于第k(k=1, 2,…,K)类的概率为
(4)
在ICNN的训练过程中,采用后向传播算法进行网络参数的更新,并采用交叉熵作为损失函数,
(5)
式中,qk表示训练样本的真实分类结果。如果训练样本的标签为k,则qk=1;否则,qk=0。
1.2 IGAN
传统的GAN包括生成器G和鉴别器D两部分。IGAN是在GAN的基础上,按照1.1节中ICNN的结构进行了改进,对D增加了特征合成层,如图1所示。其中,D的结构包括卷积层、池化层、特征合成层以及全连接层;G包括全连接层和反卷积层。
IGAN的工作原理和GAN相同,表现为G和D两者之间的博弈。G的输入为噪声z,服从先验分布pz(z),输出为生成样本G(z);D的输入为真实样本x或生成样本G(z),输出为属于x或G(z)的概率。若x服从分布pdata,G(z)服从分布pg,则G的目标是使生成样本的分布pg尽可能接近pdata,而D的目标是正确区分x和G(z)。因此,IGAN的目标函数可表示为

Ez:pz(z)[log(1-D(G(z)))]
(6)
在IGAN训练过程中,分别对D和G进行训练。当训练D时,先固定G的网络参数。一方面,对x而言,期望D(x)最大;另一方面,对G(z)而言,期望D(G(z))最小,即最大化1-D(G(z))。当训练G时,固定D的网络参数,G的目标是期望D(G(z))最大,即最小化1-D(G(z))。
此外,进一步采用特征匹配方法提高IGAN的稳定性[19]。假设F(x)表示D中不同层的特征,则G的特征匹配损失函数为
Lfeature_match=‖Ex:pdata(x)F(x)-Ez:pz(z)F(G(z))‖
(7)
2 ICNN和IGAN的结构参数
本节采用上节提出的方法,对MSTAR数据集(详见第3节)进行SAR目标识别。按照ICNN和IGAN的前向传播过程,详细地介绍它们的结构参数。
2.1 ICNN
ICNN包括6个卷积层、2个最大池化层、1个特征合成层、1个全连接层和Softmax分类层,所有卷积核的大小均为5×5,每个卷积层后采用LReLU激活函数,如图2所示。ICNN的前向传播过程和各层参数如下:

图2 ICNN的结构和参数
1) 输入为一幅128×128的SAR图像,经过第一层16个s=2的卷积核卷积后,输出为16幅64×64的特征图;
2) 经过第二层32个s=2的卷积核卷积后,输出为32幅32×32的特征图;
3) 经过第三层64个s=2的卷积核卷积后,输出为64幅16×16的特征图;
4) 经过第四层128个s=1的卷积核卷积后,输出为128幅16×16的特征图;
5) 经过第五层256个s=2的卷积核卷积后,输出为256幅8×8的特征图;
6) 经过第六层512个s=2的卷积核卷积后,输出为512幅4×4的特征图;
7) 将步骤4)得到的特征图,经过大小为4×4且s=4的最大池化层后,输出为128幅4×4的特征图;
8) 将步骤5)得到的特征图,经过大小为2×2且s=2的最大池化层后,输出为256幅4×4的特征图;
9) 将步骤6)~8)得到的特征图进行合成,输出为896幅4×4的特征图;
10) 将合成特征图展平,并经过全连接层,输出为1×10的矢量;
11) 经过Softmax分类器输出目标所属类别的概率。
2.2 IGAN
IGAN的鉴别器D和ICNN的隐藏层结构参数相同,生成器G包括6个反卷积层和2个全连接层,前5个反卷积层后采用ReLU激活函数,最后1个反卷积层后采用tanh激活函数,如图3所示。为了减轻反卷积层带来的棋盘伪影,所有卷积核的大小均为4×4。G的前向传播过程和各层参数如下:
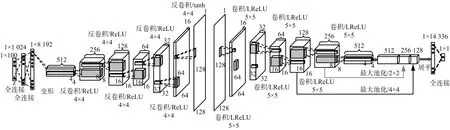
图3 IGAN的结构和参数
1) 随机产生1×100的噪声,经过2个全连接层后,输出为1×8 192的矢量;
2) 将矢量变形为512幅4×4的图像,经过第一层256个反卷积核反卷积后,输出为256幅8×8的图像;
3) 经过第二层128个反卷积核反卷积后,输出为128幅16×16的图像;
4) 经过第三层64个反卷积核反卷积后,输出为64幅16×16的图像;
5) 经过第四层32个反卷积核反卷积后,输出为32幅32×32的图像;
6) 经过第五层16个反卷积核反卷积后,输出为16幅64×64的图像;
7) 经过第六层1个反卷积核反卷积后,输出为1幅128×128的图像。
3 实验结果
实验采用的MSTAR数据集共包括10种不同类别的地面目标,其光学图像及相应的SAR图像如图4所示。MSTAR训练集和测试集中包含的各类目标的数量如表1所示,显然,共有2 747个训练样本和2 425个测试样本,训练集为17°下视角数据,测试集为15°下视角数据。实验前将所有的SAR图像切割成128×128大小,且保持目标在图像中心。实验按照采用全部的数据集、减少训练样本数、加不同比例的噪声,以及加不同功率的噪声四种情况分别进行。为了验证基于ICNN和IGAN方法的有效性,将其与直接采用基于ICNN的方法进行对比。

表1 MSTAR数据集

图4 10类目标的光学图像及相应的SAR图像
网络训练前,在基于ICNN和IGAN方法中,随机初始化IGAN的G和D网络参数;在直接采用基于ICNN的方法中,随机初始化ICNN的参数。两种方法在训练过程中,设置批尺寸大小为64,并采用Adam算法[20]完成网络参数的更新。为了保持对抗平衡,IGAN的G和D的更新次数比设定为1∶2。
1) 采用全部的数据集
采用全部的训练和测试样本进行实验,基于ICNN和IGAN的识别方法得到的10类目标的混淆矩阵如表2所示,该方法与直接基于ICNN的方法得到的各类目标的正确识别率及平均正确识别率如表3所示。结果表明,基于ICNN和IGAN方法的平均正确识别率为98.72%,而直接基于ICNN的方法的平均正确识别率为97.32%,即前者比后者高1.4%。

表2 基于ICNN和IGAN的SAR目标识别结果

续表2

表3 两种方法的实验结果对比
2) 减少训练样本数
当训练样本数从100%减少到10%,而测试样本数量不变时,两种方法得到的平均正确识别率随训练样本数减少的变化情况如图5所示。结果表明,当训练样本数大于30%时,两种方法得到的平均正确识别率都较高;当样本数减少至30%时,基于ICNN和IGAN的方法和直接基于ICNN的方法得到的平均正确识别率分别为96.37%和92.78%。当样本数低于30%时,两种方法得到的平均正确识别率都下降比较快,其原因是多数方位角下的训练样本被丢弃,网络难以学习到各方位角下的目标特征。

图5 平均正确识别率随训练样本数减少的变化情况
3) 加不同比例的噪声
定义噪声比例为SAR原图像中的像素单元被噪声取代的数量占所有像素单元数量的比例[1]。若噪声服从均匀分布,则加入5%、10%、15%、20%噪声后的SAR图像分别如图6(a)~(d)所示。采用100%、50%、30%的训练样本和100%的测试样本分别进行实验,当噪声比例从5%增加到20%时,两种方法的平均正确识别率随噪声比例的变化情况如图7所示。结果表明,两种方法的平均正确识别率随噪声比例的增加而降低。此外,在训练样本数相同的情况下,基于ICNN和IGAN的方法比直接基于ICNN的方法具有更高的识别率,即前者比后者具有更强的抗噪声能力。

图6 加不同比例噪声后的SAR图像

图7 平均正确识别率随噪声比例增加的变化情况
4) 加不同功率的噪声

图8 不同信噪比的SAR图像

图9 平均正确识别率随信噪比下降的变化情况
4 结束语
本文针对基于CNN的SAR图像目标识别中,因数据集小易产生过拟合问题,提出了一种基于ICNN和IGAN相结合的方法。该方法先用训练样本对IGAN进行无监督预训练,然后将训练好的IGAN鉴别器参数初始化ICNN,再利用训练样本对ICNN微调,最后利用训练好的ICNN进行测试样本的分类输出。为了验证该方法的有效性,采用MSTAR数据集分别进行了全部数据集、减少训练样本数、加不同比例噪声和不同功率噪声的实验。实验结果表明,基于ICNN和IGAN的方法比直接基于ICNN的方法,不仅具有更高的平均正确识别率,而且具有更强的抗噪声能力。
