基于Spark的情感分析集成算法
2020-07-17王卫红金凌剑
王卫红,金凌剑
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
情感分析是指在给定的评论中确定评论者的情绪倾向,一般分为正面情绪和负面情绪。广泛使用的情感分析方法有以情感词典为基础的方法、以传统机器学习为基础的方法和以深度学习为基础的方法。情感分析是从一句简单的评论中得出评论者的情绪,是近年来自然语言处理的一个热门。Spark是一个优秀的大数据处理框架,相比较于Hadoop在速度、通用性、易用性、兼容性等方面都有更好的表现,同时Spark提供了各种机器学习算法,可以更好地进行数据分析[1]。随着社会的发展,传统的情感分析方法已经不能满足不断增大的信息量和人们对于准确性的要求。针对这两点,国内外学者进行了大量的研究[2]。Mogha等[3]基于Spark,比较了朴素贝叶斯、决策树、随机森林等算法的分类准确性,结果显示决策树算法的结果最好。Baltas等[4]在Spark平台下对Twitter数据进行情感分析,得出朴素贝叶斯的分类效果最佳。Hai等[5]在Spark集群中研究朴素贝叶斯和随机森林两种算法的分类结果,发现两种算法的准确率都不错。上面的文章都是在Spark平台上对不同算法进行的比较,并没有对算法的创新,更多的是在寻找最佳资源和最佳参数配置。Govindarajan等[6]基于朴素贝叶斯和遗传算法提出了混合的分类算法,此方法在精度上要比单独的朴素贝叶斯和遗传算法更好。虽然对于单独的朴素贝叶斯和遗传算法来说,测试时间由于数据维度的减少而减少了,但对于集成算法来说效率还有待提升。Sharma等[7]提出基于Boosting的SVM情感分析模型,Boosting算法由Kearns等[8]提出,这种算法可以有效地提高SVM模型的效率,使准确性显著优于单一支持向量机,可是这样一来算法的复杂度增加了,而且运算效率也不如从前。Dong等[9]基于神经网络,以自适应和递归的方法提出了AdaRNN,该算法的分析中加入了对上下文以及句子语法的标记,以自适应的方式传播,使情感分类具有关键词依赖性,提高了准确率,但同样也增加了复杂度。这几篇文章对算法作出了自己的改进,提高了分类的准确性,但同时也降低了效率。
在上述的背景下,笔者提出了一种以Spark平台为基础,结合多种算法的集成算法来进行英文评论数据的情感分析。首先对评论数据进行预处理,得出情感标签和评论内容;然后对评论内容进行分词处理,并去除停用词、标点符号和稀有词;接着使用改进后的TF-IDF算法获得特征向量,以AdaBoost算法对决策树和SVM进行弱分类器训练,最后将两种分类器的所有分类器根据权值集成为最终分类器,使用最终分类器得到最终分类结果。
1 文本数据处理优化
图1为文本数据处理流程图。先输入文本数据,然后筛除非法词,再筛除无影响词,接着提取特征向量并输出。
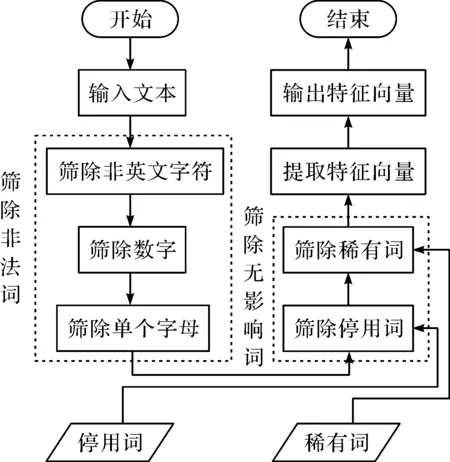
图1 文本数据处理流程图Fig.1 The flow chart of the text data processing
这里的特征向量提取使用了改进后的TF-IDF算法,此算法通过修饰情感词的副词来决定情感词的权重,关注了词与词之间的联系,这种内在联系可以使后续的处理效果提升。
1.1 筛除非法词
非法词包括不是英文字母的字符、数字和单个字母。将评论数据以空格为分隔符进行分词,使用正则表达式去除非英文字母的字符和数字。将剩下的单词进行长度计算,筛除长度为一的单词。
1.2 筛除无影响词
无影响词包括停用词和稀有词。停用词包括a、the、and、be、as等891 个与情感无关的词,稀有词指只出现过一次的词。将筛除非法词后的数据进行进一步的筛选,引入停用词表,将数据中的停用词删除。统计所有词汇出现的次数,将出现次数为一的也删除。
1.3 特征向量提取
笔者使用的是改进后的TF-IDF特征向量提取算法。词频-逆向文件频率(TF-IDF)[10]是一种在文本挖掘和向量化中常用的加权技术,它主要用来表现某个词语在某篇文章中的重要程度。TF-IDF实际上是TF与IDF的乘积。TF词频,指的是某个词语在某篇文章中出现的次数。IDF逆向文件频率用来衡量一个词语普遍重要性。任意一个特定词语的IDF,都可以用总文件数目除以包含该词语的文件的数目,再对上述结果取对数得到。某个词语在某个文件中的较高频率,以及该词语在所有文件中的较低频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。在TF-IDF的原理中,某个词语在某篇文章中出现的频率高,在其他文件中出现的频率很低,那么这个词语就具有很好的分类能力,适合用来分类。TF,IDF可表示为
(1)
(2)
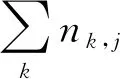
TFi,j-IDFi=TFi,j×IDFi
(3)
传统的TF-IDF算法存在明显的不足之处。它简单地认为文本频率小的单词就重要,而文本频率大的则没什么用处。这使得它不能很好地反应单词的有用程度,对于分类问题来说,最重要的是单词能够反应它所在的类,然而传统的方法没有考虑特征项在不同类别里的分布。同时传统方法不能很好地辨别情感词,也没有关联上下文的功能,程度副词如“很”“非常”等词在修饰情感词时应当提高情感词的得分。
根据上述的不足提出一种改进的特征提取方法,修改TF特征值的权重为
(4)
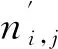
(5)
计算单词ti在各个分类中的平均词频为
(6)
则类间的离散度[11]用标准差与平均值之商表示为
(7)
当特征项只在一个类别出现时,离散度取值最大为1,当特征值在所有类别都出现时,离散度取值最小为0。综上所述TF-IDF可以转换为
(8)
最终对每一个特征项进行评估时就不是简单地将词频与逆文档频率相乘,而是考虑了情感词与程度副词的关系和特征项与类别的关系。
2 集成分类模型的构建
决策树(Decision tree)[12-13],作为一种归纳学习算法,其重点是将看似无序、杂乱的已知实例,通过某种技术手段将它们转化成可以预测未知实例的树状模型,每个内部节点都是对某个属性的一次测试,树中的每一条路径代表某个测试的输出,每条路径都有一个终点,称之为叶节点,每个叶节点则代表不同的类别。决策树算法的优势在于,它不仅简单易于理解,而且高效实用,构建一次,就可以多次使用,或者只对树模型进行简单地维护就可以保持其分类的准确性。支持向量机(Support vector machine)[14-15]是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。SVM使用铰链损失函数计算经验风险并在求解系统中加入了正则化项以优化结构风险,是一个具有稀疏性和稳健性的分类器。因为梯度提升决策树算法(Gradient boosting decision tree)在各方面的优越表现[16-17],让笔者明白了决策树算法的迭代能够有效提高算法的准确性。SVM基于结构风险最小化的学习技术,使它在很多数据集上都有优秀的表现,特别是在平衡的数据集上具有较好的分类性能和泛化能力,因为笔者使用的是较平衡的数据且AdaBoost又是一个迭代的算法,所以选用它们两个作为弱分类算法。
AdaBoost算法是一种提升方法,将多个弱分类器,组合成强分类器,由Yoav Freund和Robert E Schapire在1995年提出[18]。作为一种Boosting方法,AdaBoost在很多算法上都有着不俗的表现[19-22]。它主要是将前面一个弱分类器分错的样本进行权值加强,然后使用权值更新后的样本来训练下面一个新的弱分类器。在每轮训练中,用样本总体训练新的弱分类器,产生新的样本权值以及该弱分类器的话语权,一直迭代直到达到预定的错误率或达到指定的最大迭代次数。通过第一步和第二步的操作,分别得出决策树算法和SVM算法的弱分类器,最后通过第三步将两个算法的弱分类器集成为一个强分类器模型。步骤如下:
1) 训练数据(每个样本)的权值赋予。设有N个样本,则每一个训练的样本点最开始时都给一个一样的权值w,值为1/N,其权值表达式为
D1=(w11,w12,…,w1i,…,w1N)
(9)
式中:D1为第1次迭代每个样本的权值;w1i为第1次迭代时的第i个样本的权值;N为样本总数。
2) 训练弱分类器。设进行m次迭代,此时的权值为Dm,此时的基本分类器为Gm(x)。计算Gm(x)在训练数据集上的分类误差率为
(10)
式中yi为训练数据中的类别标签。可以知道误差率就是被误分类样本的权值之和。根据误差率可以计算各分类器的权值,也就是基本分类器在最终分类器中的权重为
(11)
然后更新训练数据的权值,在训练过程中,如果某个样本的类别已经确认,那么在下一次训练中,它的权重就被降低;相反,如果某个样本的类别还没有确认,那么它的权重Dm就得到提高,其计算式为
Dm+1=(wm+1,1,wm+1,2,…,wm+1,i,…,wm+1,N)
(12)
i=1,2,…,N
(13)
式中:Dm+1为下一次迭代时的样本权值;wm+1,i为下一次迭代时第i个样本的权值;Zm为归一化因子,使得所有样本对应的权值之和为1,可表示为
(14)
3) 强分类器的构建。每次训练结束都会得到一个弱分类器,通过计算它们的误差率来确定它们在最终分类函数中的话语权。误差率高的弱分类器话语权低,误差率低的弱分类器话语权高。换言之,误差率低的弱分类器在最终分类器中占的比例较大,反之较小。这里得到的弱分类器有两种,分别是决策树弱分类器和支持向量机弱分类器。因为两种分类器的权值可能处于不同数量级,所以将它们的权值分别进行标准化操作,其计算式为
(15)
(16)
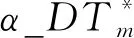
(17)
式中:G_DTm(x)为决策树弱分类器;G_SVMm(x)为支持向量机弱分类器。得到最终分类器为
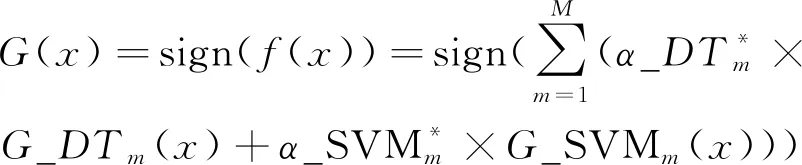
(18)
算法的实现流程如图2所示。
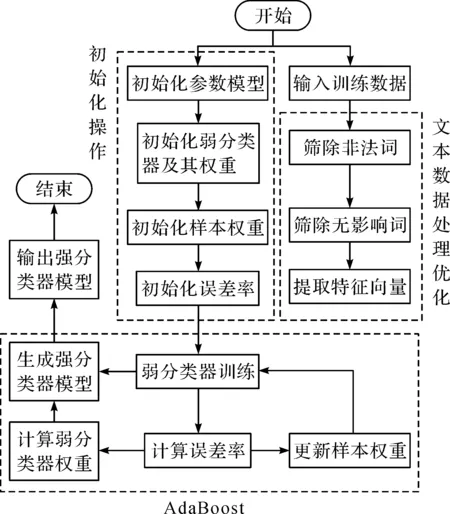
图2 集成算法的实现流程图Fig.2 The implementation flow chart of the integration algorithm
3 实验及结果分析
3.1 实验环境
本实验采用Hadoop和Spark分布式架构来进行实验,实验中使用的软件版本和环境配置如表1所示。
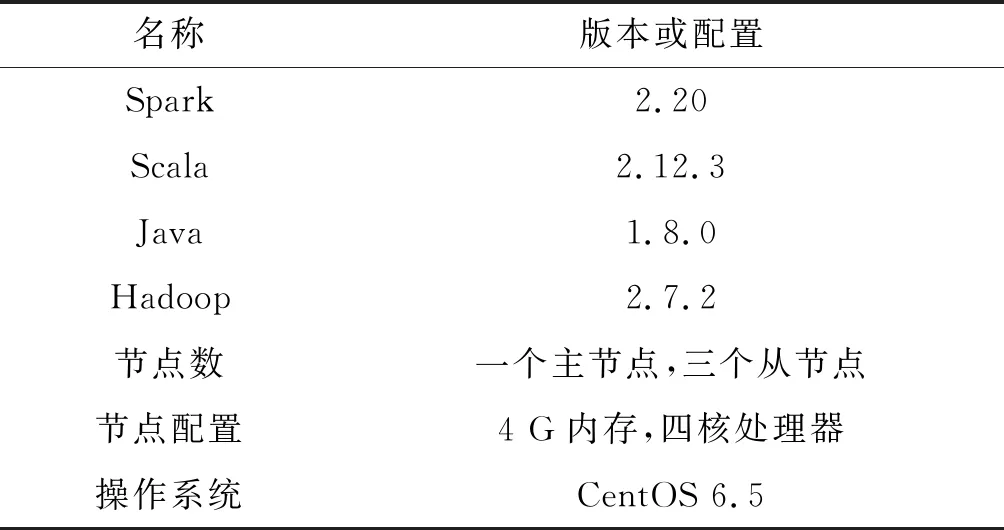
表1 实验环境Table 1 Experimental environment
3.2 实验数据
笔者数据采用kaggle[23]网站中Amazon用户的英文评论。选取了训练数据100 000 条,其中包含正面情绪数据和负面情绪数据各50 000 条;测试数据10 000 条,其中包含正面情绪数据和负面情绪数据各5 000 条。数据包含两个部分,一个是区分正负面情绪的标签,_label_1表示负面情绪,_label_2表示正面情绪;另一个是评论的内容。
3.3 耗时性能实验
根据1.3节中改进的TF-IDF算法和2节中的集成分类模型,针对不同的分布式平台进行了实验,如表2所示。
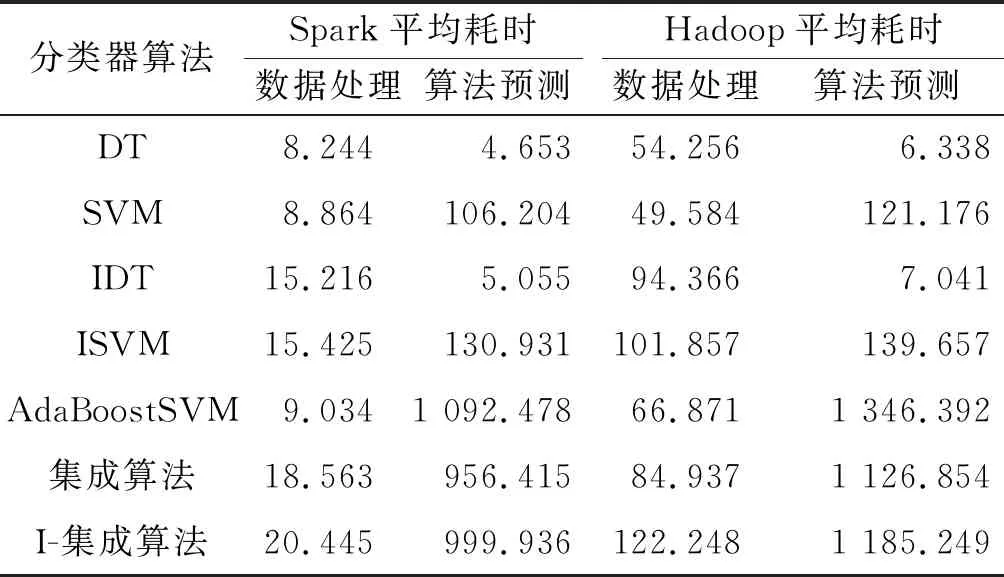
表2 不同平台下不同算法的耗时
表2记录了Hadoop平台和Spark平台对于不同算法在数据预处理和算法预测上的平均耗时。其中IDT和ISVM表示使用了改进后的TF-IDF算法,I-集成算法不但使用了改进后的TF-IDF算法还将决策树和SVM集成,而集成算法仅仅集成了决策树和SVM,使用的还是传统的TF-IDF。从整体数据上看,Spark无论是在数据处理上的耗时还是算法预测上的耗时都少于Hadoop平台。单个比较数据处理的耗时来看,Spark在数据处理上的速度是Hadoop的好几倍;而从算法预测的耗时上看Spark的优势并不明显。
此处还添加了名为AdaBoostSVM的集成算法[24],此算法采用基于SVM的AdaBoost算法。从实验数据上看:由于使用传统的TF-IDF算法,且没有集成其他算法,所以在数据处理上的耗时与SVM算法相差不大,与笔者的集成算法相比要少。而从算法预测耗时上看:无论是在Hadoop平台还是Spark平台,此算法就比笔者的集成算法要多不少。
如图3所示,笔者还实验了不同的节点数对于耗时的影响,这里主要使用的是集成算法在两大平台的耗时。对于两大平台来说,一开始的耗时是随着节点数的增加,耗时也减少,到了一定节点数之后节点数对于耗时的影响就不大了。
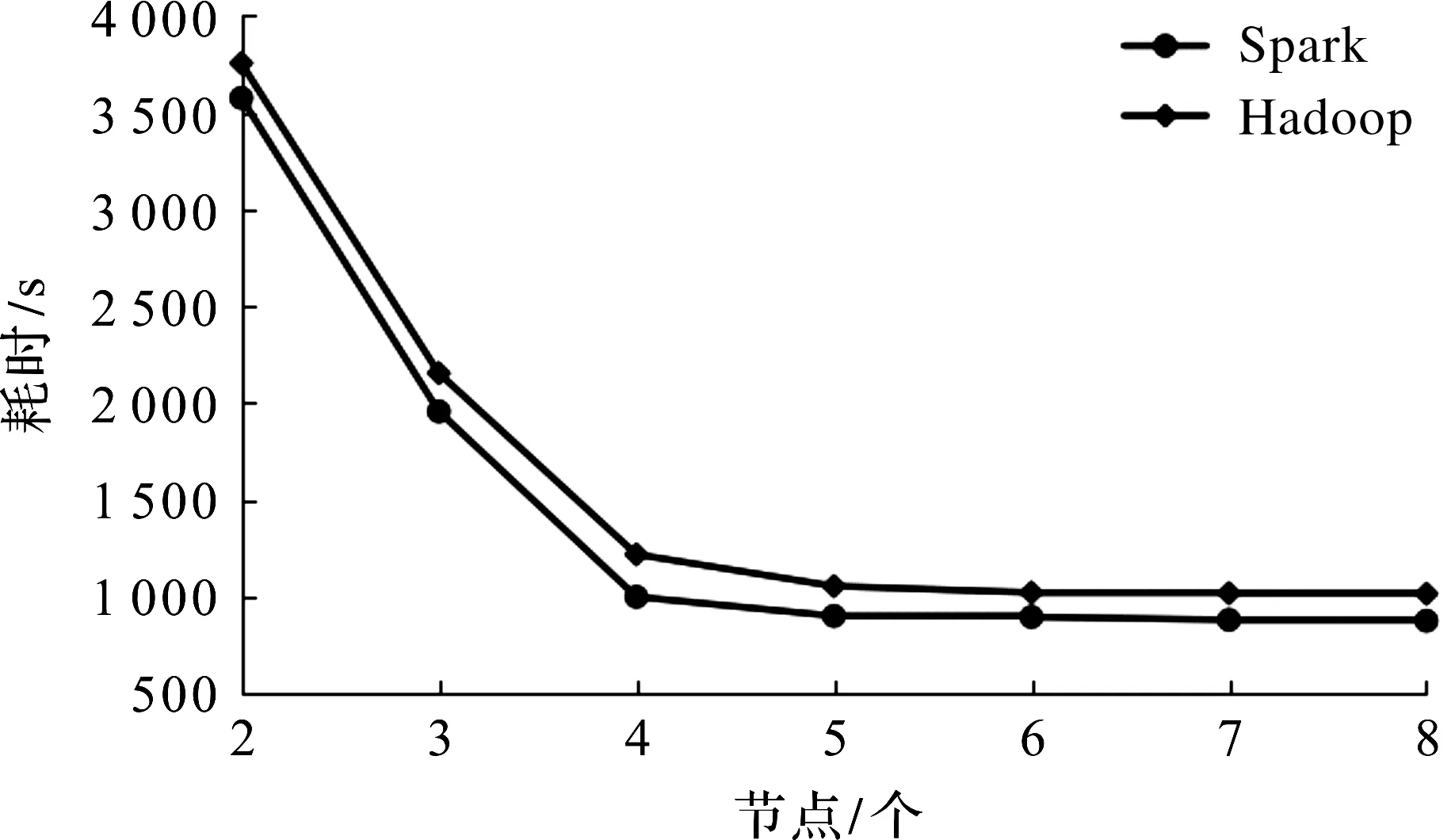
图3 不同节点数的耗时Fig.3 Time-consuming of different number of nodes
3.4 准确性实验
对于不同的算法,进行了情感分析的分类实验,图4展示了不同算法的分类准确率。其中DT和SVM算法都使用了原始的TF-IDF算法,而IDT和ISVM算法都使用了改进后的TF-IDF算法。从图4中可以看出:使用了改进后的TF-IDF相比较传统的TF-IDF来说,在SVM算法上的准确率提高了8%,在决策树算法上的准确率提高了将近10%。集成算法使用的是传统的TF-IDF在准确率上相比较于使用了改进后TF-IDF的IDT和ISVM算法来说提升并不明显,而I-集成算法不但使用了改进后的TF-IDF,还集成了两个算法,在准确率比集成算法高了近4%。由此可知改进的TF-IDF算法对集成算法有加强的效果。对于AdaBoostSVM集成算法,在实验中可以看到它的准确率与笔者的集成算法相差不大,甚至有所不如,而与I-集成算法相比较来说就低了不少。
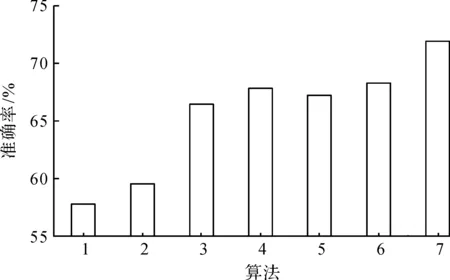
1—DT;2—SVM;3—IDT;4—ISVM;5—AdaBoostSVM; 6—集成算法;7—I-集成算法。图4 不同算法的分类准确率Fig.4 Classification accuracy of different algorithms
对于上述的实验,集成算法的迭代采用的都是20 次,同样的迭代次数难免会对集成算法的最好结果会有影响,所以对于不同迭代次数下集成算法的准确性也需要进行研究。
如图5所示,当迭代在5~20 次时,集成算法的准确率随迭代次数的增加而增加,而迭代超过20 次之后,集成算法的准确率基本不再变化。同时在迭代达到30 次之后,所花费的时间比30 次之前要长几百甚至几千倍。
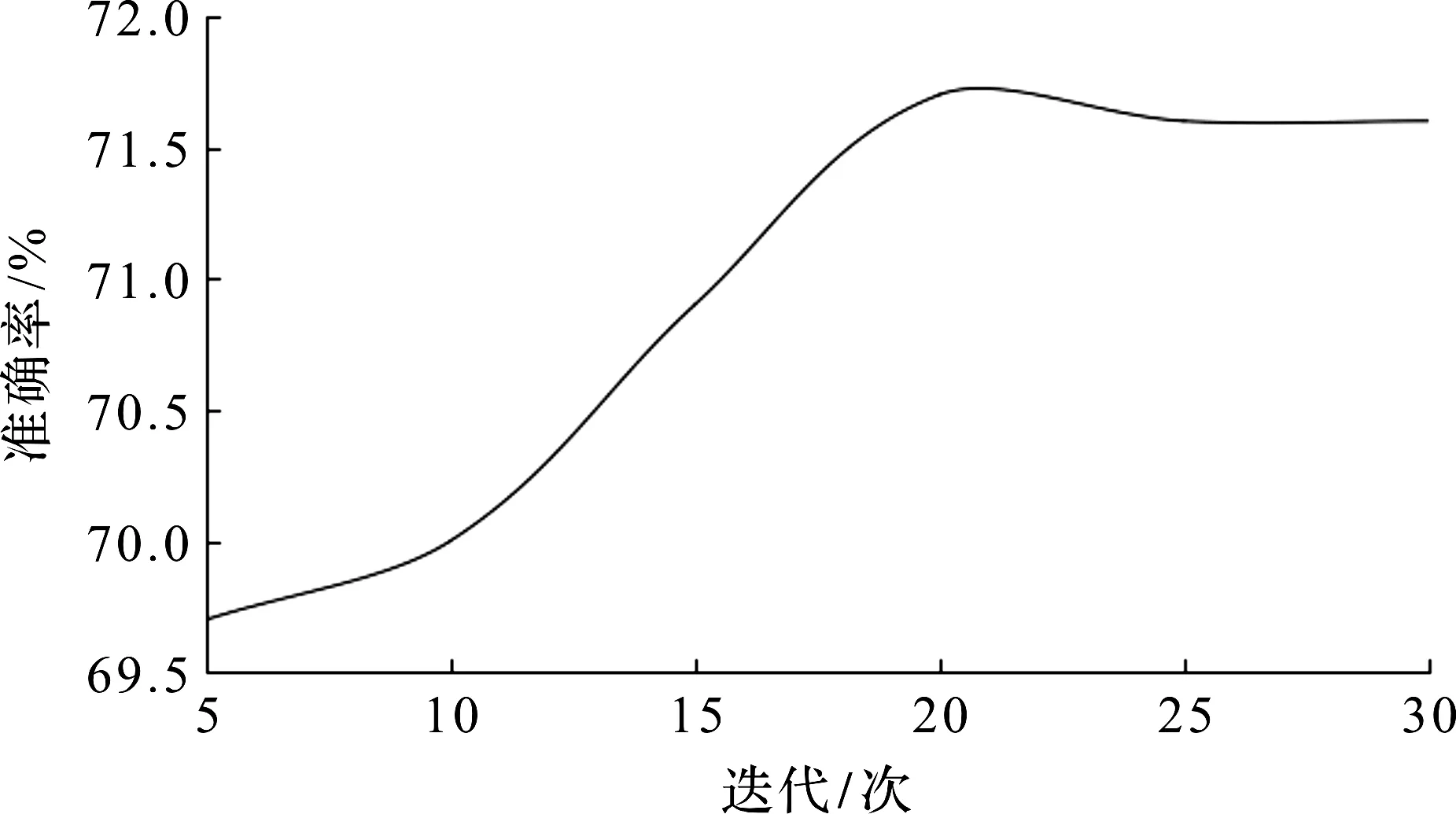
图5 不同迭代次数下集成算法的分类准确率Fig.5 Classification accuracy of ensemble algorithm under different iterations
4 结 论
通过对大数据分类方法的研究,在Spark平台的基础上,提出了一种情感分析集成算法。该算法采用改进后的TF-IDF算法提取特征向量,并使用类似AdaBoost算法的方式将决策树算法和SVM算法集成。同时对于不同平台的耗时和不同节点数的耗时,还有不同算法的准确率以及不同迭代次数对于集成算法准确率的影响进行了实验。从实验结果来看:Spark在数据处理上比Haoop快,但两者在算法运行速度上相差不大;两个平台对于节点数的增加耗时都会减少,但到达一定节点数之后耗时就基本不会减少;集成算法对于其他原生算法来说准确率提高不少;迭代次数的增加会对集成算法的准确率有所提高,但次数达到一定大小后准确率也会趋于平稳,同时随着迭代次数的增加,耗时也会不断增加,到了后期耗费的时间可能会成几百上千倍地增加。从整体结果上看:集成算法虽然相比较基本算法准确率有所提高,但从其他更高级算法的来看还远远不够,下一步可以继续改进特征向量提取算法,集成更加优秀的基本算法或者减少集成算法的耗时。
