基于多时长特征融合的人体行为识别方法
2020-07-17李甫宪
宣 琦,李甫宪
(浙江工业大学 信息工程学院,浙江 杭州 310023)
随着多媒体工具的普及与发展,产生了大量的视频数据,对视频中的人体行为进行识别逐渐成为计算机视觉领域的研究热点。对人体行为进行有效且精准地识别是许多智能服务的基础,如智能人机交互[1]、安防视频监控[2]、视频检索[3]等。在行为识别问题中,近年来大多数方法都采用2D卷积神经网络的变体——3D卷积神经网络作为基础,对从视频中等间隔采样得到的序列图像进行特征提取而后进行分类[4-5]。相对于2D卷积神经网络,3D卷积神经网络能够同时提取单张二维图像中的空间信息以及序列图像中的时间信息,结果表明结合利用时间维度信息能够有效地提升人体行为识别的准确率。尽管在许多学者提出的以不同方式利用时间维度信息方面取得了较大的进展[6-8],但仍存在不足的地方,即简单的3D卷积神经网络在每一个卷积层进行特征提取的时候,都采用具有固定时间长度的3D卷积核进行特征计算,使其无法利用视频中的不同时间长度的时间信息,从而影响了最终模型的分类性能。
为此,笔者提出了多时长特征融合模块,该模块能够有效地提取不同时间长度的动态行为信息,将这些特征信息融合后进行下一步的特征提取。同时,基于该模块设计了一个多时长特征融合的密集连接3D卷积神经网络,该网络能够有效地对人体行为进行识别。此外,提出了一种从2D神经网络到3D神经网络的迁移学习策略,使得模型训练时间大大缩短,同时分类性能取得一定提升。
1 研究背景
人体行为识别通常包含两个步骤:行为表征与行为分类。行为表征通常是将一段人体行为映射到特征空间,而行为分类则是针对映射生成的特征向量进行分类。Bobick等[9]提出将人体行为的动态信息分别映射成运动能力图特征和运动记录图特征,前者用来检测人体行为发生的位置,后者用来记录人体行为发生的过程,而该方法存在较大缺点,即对于从不同角度下记录的同种行为会生成差异较大的特征,使得其分类效果较差。
近年来,由于深度学习方法在计算机视觉领域的其他问题中表现优异,学者们逐渐提出基于卷积神经网络的方法对人体行为进行识别。卷积神经网络作为人工神经网络的典型代表,通常包含输入层、卷积层、池化层、全连接层和输出层,能够有效实现端到端的图像分类[10]、图像分割[11]、目标检测[12]等任务。常见的卷积神经网络是二维的,而人体行为是一个动态的过程,从单张图像中通常无法判断行为类别,因此其无法直接应用在人体行为识别任务当中。而Ji等[13]首次将深度学习方法引入人体行为识别任务当中,提出将2D卷积神经网络扩展至3D卷积神经网络,使得卷积神经网络能够对序列图像进行特征提取,该方法预先获取每张图像5 种不同的信息:灰度信息、x方向梯度信息、y方向梯度信息、x方向光流信息、y方向光流信息,随后分别将其输入到3D卷积神经网络得到时间特征与空间特征,然后采用全连接层将特征映射为128 维的向量后进行分类。Simonyan等[14]提出双通道卷积网络框架,该框架包含两个独立的3D卷积神经网络,分别用于提取人体行为的空间特征和时间特征,其中空间特征主要从单张图像中提取,而时间特征主要从视频光流场中提取,将得到的两种特征以直接相加的方式融合后进行分类。Wang等[15]改进了Simonyan提出的方法,从单张图像中提取多尺度卷积特征,并计算以时间特征为中心的卷积响应特征,实现空间特征与时间特征的融合。双通道卷积网络框架存在一个较大的缺点,即提取空间特征与时间特征相互独立,仅在后续步骤进行融合,而空间特征和时间特征存在很大程度的关联性,独立计算将丢失部分信息。Donahue等[16]提出混合形式网络框架来同时进行空间特征与时间特征的提取,该框架包括卷积神经网络与循环神经网络,使用卷积神经网络对单张图像提取空间特征后将其输入循环神经网络提取时间特征,有效地实现空间特征与时间特征的共同提取。然而,以上几种方法在提取时间特征都采用具有固定维度的卷积核,使得其无法兼顾提取长时间时长、中等时间时长、短时间时长的时间特征,使得在大型人体行为识别数据集上的分类性能较差。
2 多时长特征融合卷积网络
2.1 3D卷积操作
3D卷积操作由2D卷积操作扩展得到,能够有效计算多张序列图像之间的特征以获取时间信息,如图1所示。
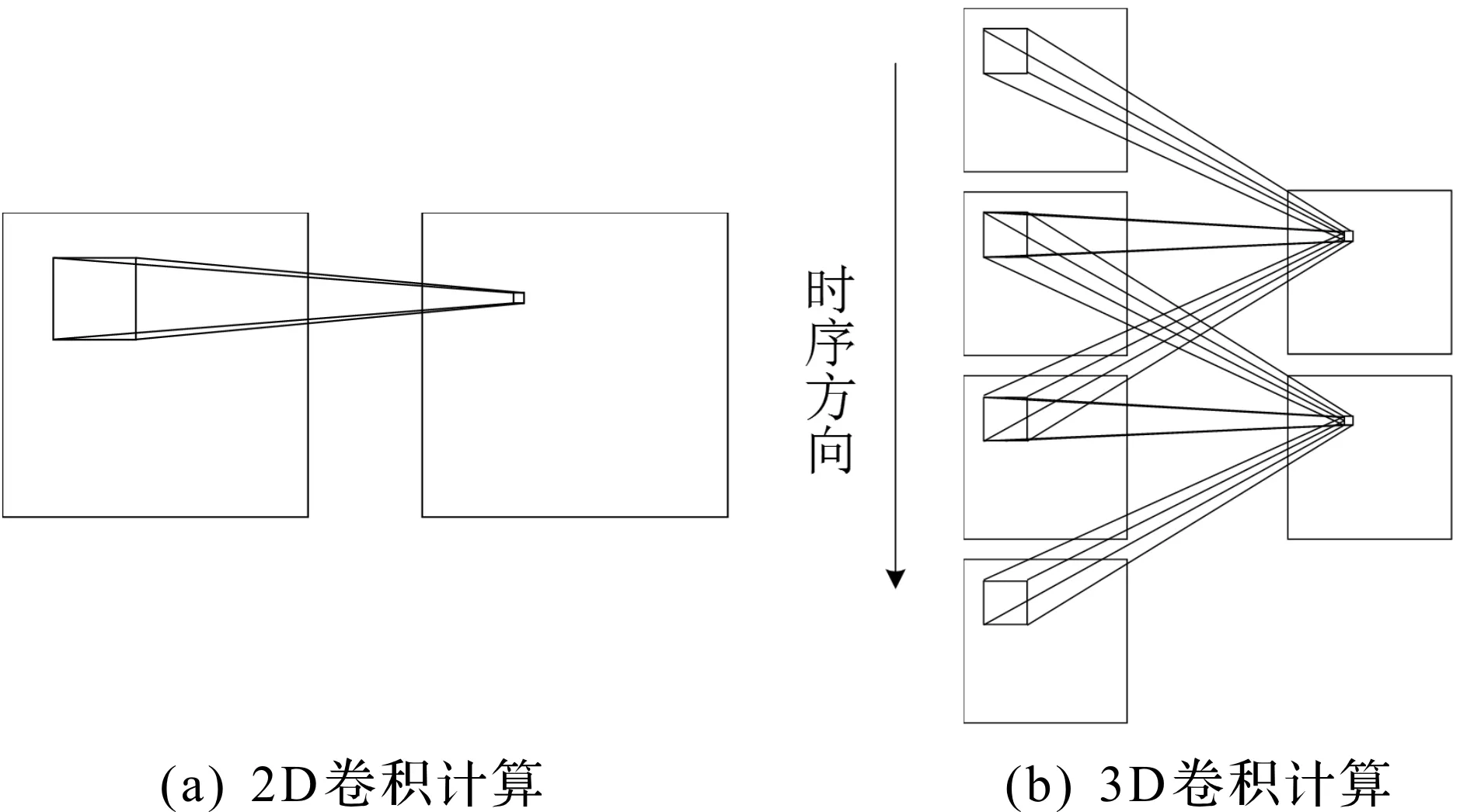
图1 不同的卷积方式Fig.1 Different convolution methods
在常规的2D卷积神经网络中,2D卷积操作主要用于提取单张特征图内的区域空间特征。假设单张图像I∈RH×W,卷积核W大小为S×S,则对该图像做2D卷积特征提取得到特征图f为
(1)
式中:f(x,y)为特征图f在位置(x,y)的值;w(Δx,Δy)为卷积核W在位置(Δx,Δy)的值;v(x+Δx,y+Δy)为图像I在位置(x+Δx,y+Δy)的值。而在3D卷积操作中,需要将多张图像堆叠成长方体后进行计算。假设视频中连续多张图像组成的长方体数据I∈RH×W×F,3D卷积核W大小为S×S×T,则对该长方体数据做3D卷积计算得到特征长方体数据f为
(2)
式中:f(x,y,t)为特征长方体数据f在位置(x,y,t)的值;w(Δx,Δy,Δt)为3D卷积核W在位置(Δx,Δy,Δt)的值;v(x+Δx,y+Δy,t+Δt)为堆叠图像长方体I中第t+Δt张图像在位置(x+Δx,y+Δy)的值。图1中3D卷积计算的时间方向维度T设定为3。
2.2 多时长特征融合模块
常见3D卷积神经网络在某一卷积层内都使用大小统一的卷积核来进行特征提取,然而这种设定无法有效提取时间跨度不同的动态行为特征。为此,笔者提出了多时长特征融合模块,该模块由多个互相独立的3D卷积计算、融合计算与平均池化计算所组成,其中每一个3D卷积计算都使用了不同时间跨度的3D卷积核,如图2所示。
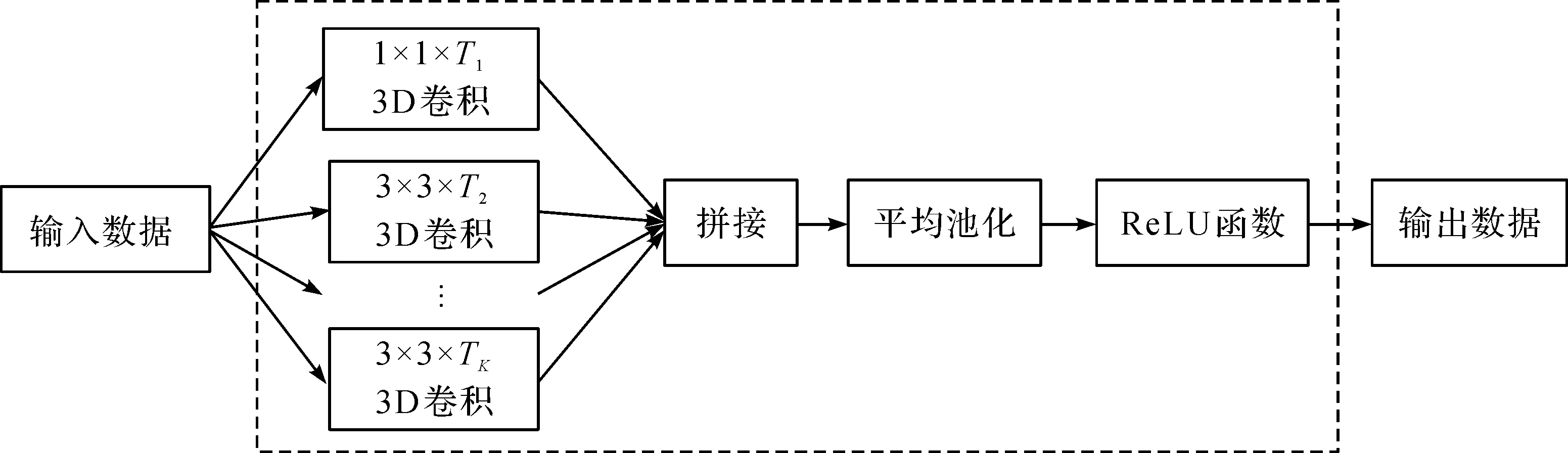
图2 多时长特征融合模块Fig.2 Multiple duration fusion block
对于输入数据x∈RH×W×F,在经过K个分别独立的3D卷积核Wi计算后分别产生对应的特征长方体数据fi为
fi=Gconv(x,Wi)
(3)
式中:Gconv为3D卷积计算的函数;x为输入数据;Wi为第i个3D卷积核的参数矩阵,且i∈K。由于3D卷积核有不同的时间跨度,则产生的特征长方体的时间维度大小也不同,即f1∈RH×W×T1,f2∈RH×W×T2,fK∈RH×W×TK。将具有不同时间跨度信息的多个特征长方体数据fi做融合得到融合特征fv为
fv=Gconcat(f1,f2,…,fi)
(4)
式中:Gconcat为拼接操作;得到的融合特征fv∈RH×W×(T1+T2+…+TK)。为减小特征长方体的大小,需要对融合特征进行平均池化计算得到favg为
(5)
式中:n为池化区域中元素个数;fv(xi,yi,ti)为特征长方体fv在位置(xi,yi,ti)的值。为增加特征的表达能力,引入非线性激活函数得到多时长特征融合模块的最终输出x′为
x′=GReLU(favg)
(6)
式中GReLU为ReLU函数。通过该模块计算能够有效地提取不同时间跨度下的动态行为特征,将更多的行为类别信息进行映射。
2.3 密集连接模块
训练卷积神经网络过程中,常采用反向传播算法对网络参数进行更新,从而会出现梯度消失等问题,导致网络模型分类性能下降[17-19]。因此,在设计网络模型时候,引入了密集连接模块以减轻梯度消失现象,同时更加有效地复用训练过程中产生的行为特征信息,其结构如图3所示。

图3 密集连接模块Fig.3 Densely connected block
对于输入数据x∈RH×W×F,该模块共产生i个中间特征长方体数据fi为
fconv=Gconv(xi-1,Wi)
(7)
fi=GReLU(fconv)
(8)
式中:Gconv为3D卷积计算的函数;xi-1为第i个中间层的输入数据;Wi为第i层的卷积核参数矩阵;GReLU为ReLU函数。其中密集连接得到的中间层输入数据xi为
xi=Gconcat(x,f1,f2,…,fi-1)
(9)
式中Gconcat为拼接操作。该模块最终得到的特征长方体数据x′为
x′=H(Gconcat(x,f1,f2,…,fi))
(10)
式中H为密集连接模块计算的函数。
2.4 多时长特征融合密集连接网络
多时长特征融合密集连接网络模型采用多时长特征融合模块与密集连接模块交替连接的方式,具体结构如图4所示。其中k为待分类视频类别数。

图4 网络模型结构Fig.4 The model architecture
对人体行为视频进行等间隔采样得到16 张序列图像作为网络的输入数据,每张图像大小为224×224。首先使用卷积核大小为7×7×3的3D卷积计算将序列图像数据映射至特征空间,再对得到的特征长方体进行最大池化计算;紧接着使用4 个密集连接模块和3 个多时长特征融合模块交替连接对其进行动态行为特征的提取,其中多时长特征融合模块使用3 个独立的3D卷积计算,3D卷积核大小分别为1×1×1,3×3×3,3×3×4,密集连接模块分别设定6,16,24,16 个中间层;经过多个特征融合模块与密集连接模块的计算得到最终特征fu。对特征fu进行分类,得到概率向量y为
y=Gs(fu,θs)
(11)
式中:Gs为softmax函数;θs为参数矩阵。其中yi∈(0,1]表示该视频属于第i种行为的概率。
2.5 迁移学习策略
直接在目标数据集上训练网络模型将消耗大量的时间,同时容易产生过拟合现象使得模型分类性能降低。将已经严格训练过的2D卷积神经网络与参数随机初始化的3D卷积神经网络进行混合训练,可以有效地实现迁移学习,节约大量训练时间,同时提升模型分类性能。如图5所示,假定一个已经在ImageNet数据集上预训练的2D卷积神经网络M和一个未经过训练的3D卷积神经网络N,利用序列帧图像与视频片段之间的对应关系,同时使用这两种数据对网络M与N进行训练。

图5 迁移学习示意图Fig.5 Schematric illustration of transfer learning
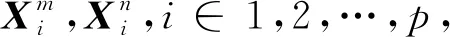
(12)

(13)

(14)

(15)
式中Gconcat为拼接操作。对特征fmn进行二分类得到匹配特征向量y为
y=Gs(Gfc(fmn,θfc))
(16)

3 实验分析
实验在搭载NVIDIA GeForce GTX 1080 Ti图像处理器、Intel(R) Core(TM) i7-6700 CPU的服务器下运行。模型代码基于Tensorflow框架编写实现。模型训练采用Adam优化算法,初始学习率设定为0.000 1,每训练20 个轮次后缩小到1/10,从而使得其能够更好地收敛。损失函数Ltotal为
(17)
实验数据采用人类行为视频UCF101数据集与HMDB51数据集。UCF101主要取自Youtube视频网站,共包含101 种不同的行为类别;HMDB51主要取自电影片段,共包含51 种不同的行为类别;具体信息如表1所示。

表1 数据集信息Table 1 The details of datasets
由于数据集中行为视频每秒传输帧数值(FPS)为30,直接对这种视频进行连续图像提取(即采样间隔为1),将无法包含完整的行为信息,使得分类效果变差。为此,笔者对比了不同的采样间隔下该网络模型的分类性能,如表2所示。
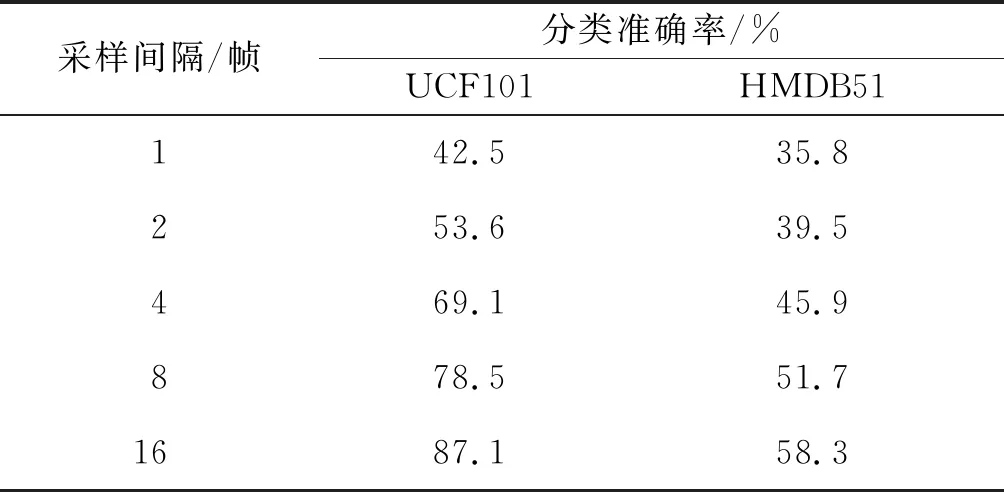
表2 不同采样间隔下的分类准确率Table 2 Classification accuracy with different sampling intervals
通过实验结果发现:采样间隔为16时模型能够获得最好的分类性能。在后续实验当中,都采用这种设定。为了验证多时长特征融合模块和密集连接模块的有效性,对比了不同网络模型结构下的分类性能。为了保证网络模型的一致性,不采用笔者设计的模块,将采用常规3D卷积计算替代,实验结果如表3所示。由表3可以看出:相比常规3D卷积计算,多时长特征融合模块能够更加有效提取动态行为特征,显著提升模型分类性能,分类准确率提升了18%左右。此外,密集连接模块同样使得模型分类性小幅度提升了3%左右。
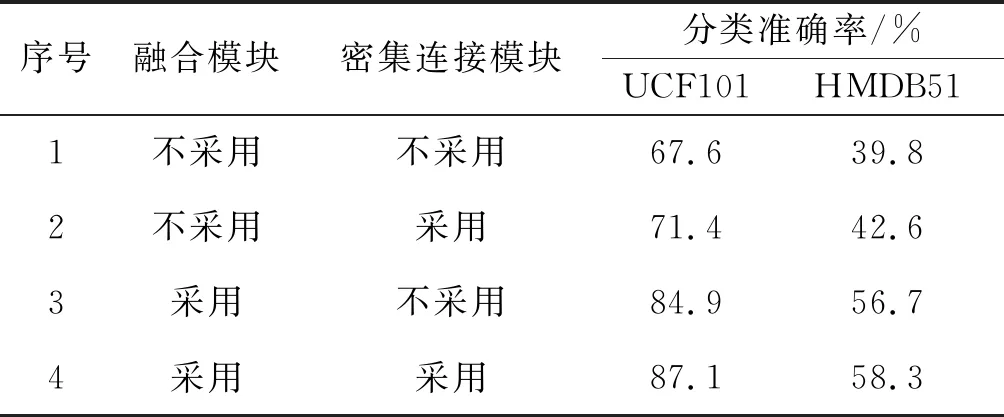
表3 不同网络模型结构的分类准确率Table 3 Classification accuracy with different models
此外,为了评估迁移学习策略对模型分类性能的影响,对比实验结果如表4所示。相比采用随机初始化参数的方法,采用迁移学习策略对模型进行预训练能够提升模型分类性能。

表4 不同参数初始化策略的分类准确率
4 结 论
对于视频中的人体行为识别任务,针对现有3D卷积神经网络无法有效同时提取具有不同时间长度的动态行为特征的问题,笔者提出了多时长特征融合模块,该模块由多个具有不同时间维度的3D卷积计算组成,有效地提取了长时间时长、中等时间时长、短时间时长的多种动态行为特征,并结合密集连接模块提出了基于多时长特征融合模块的密集连接卷积神经网络,端到端地实现了对人体行为的准确识别。同时,提出了一种3D卷积神经网络预训练策略,有效地实现了从2D到3D到卷积神经网络的迁移学习,显著缩短模型训练时间,提升模型分类准确率。
