基于深度学习的低光彩码图像增强
2020-07-17方路平翁佩强周国民
方路平,翁佩强,,周国民
(1.浙江工业大学 信息工程学院,浙江 杭州 310023;2.浙江警察学院 计算机与信息技术系,浙江 杭州 310053)
作为新型识别码,彩码相比于传统二维码具有远距离识别、多识别等优点。彩码技术在国内尚处于起步阶段,对彩码的生成和读取尚不成熟。在计算机视觉任务中,目标检测和跟踪以及消费电子产品(如手持设备)都需要高质量的图像和视频。但是在实际识别过程中,由于亮度的影响,存在彩码图像无法识别以及错误识别的现象。因此,为保障彩码识别的准确性,对低光彩码图像进行针对性增强具有重要意义。
1 图像增强算法概述
目前,国内外关于彩码图像增强的算法相对较少,应对于低光图像的增强算法已有多种。例如,基于直方图均衡化[1]方法的基本思想是通过改变图像像素的分布,使各个像素之间的对比度增大,从而达到增强效果。该方法简单且容易实现,同时又有较快的响应速度,但是难以对不同程度的弱光图像进行针对性增强。后来,有研究者提出基于Retinex理论[2]的多尺度色彩恢复算法[3](Multi-scale Retinex,MSR),利用单尺度色彩恢复(Single scale Retinex,SSR)算法[4]对各个通道的图像先进行高斯滤波处理,再进行线性加权求和以获取增强后的图像。该方法能较好地提高图像对比度,但是应用在彩码图像上时会使彩码色块颜色产生偏移。除了以上两种经典算法,也有一些新的算法提出来。如牛万红等[5]提出了一种大律法结合信息熵迭代算法来针对低光彩码图像进行增强。先利用最大类间方差法(OTSU)确定初始阈值来分割彩码图像的前后景,再分别计算前后景信息熵,通过信息熵迭代获取最优分割阈值,再使用获取的阈值对彩码图像各个通道根据阈值进行二值化,最后合并各个二值化后的通道得到增强后的图像。该方法能够很好地还原彩码图像的色彩,但由于彩码背景颜色与有效色块存在差异,使得通过信息熵迭代的方式来获取最优分割阈值的方法没有达到预期效果,在应用于不同低光程度的彩码图像时,会产生不必要的噪点,影响后续的识别过程。Guo等[6]提出了一种简单的微光图像增强方法,即LIME(Low-light image enhancement via illumination map estimation)。该方法首先对弱光图像中每个像素的光照进行估计,获得初始的光照图像,再将获得的初始光照图像经Gamma变换后得到增强的光照图像,最后利用增强的光照图像实现了基于Retinex模型的增强图像。针对彩码的高精度要求,使用上述方法对低光彩码图像进行增强,尚且无法达到准确高效的效果,结果如图1所示。
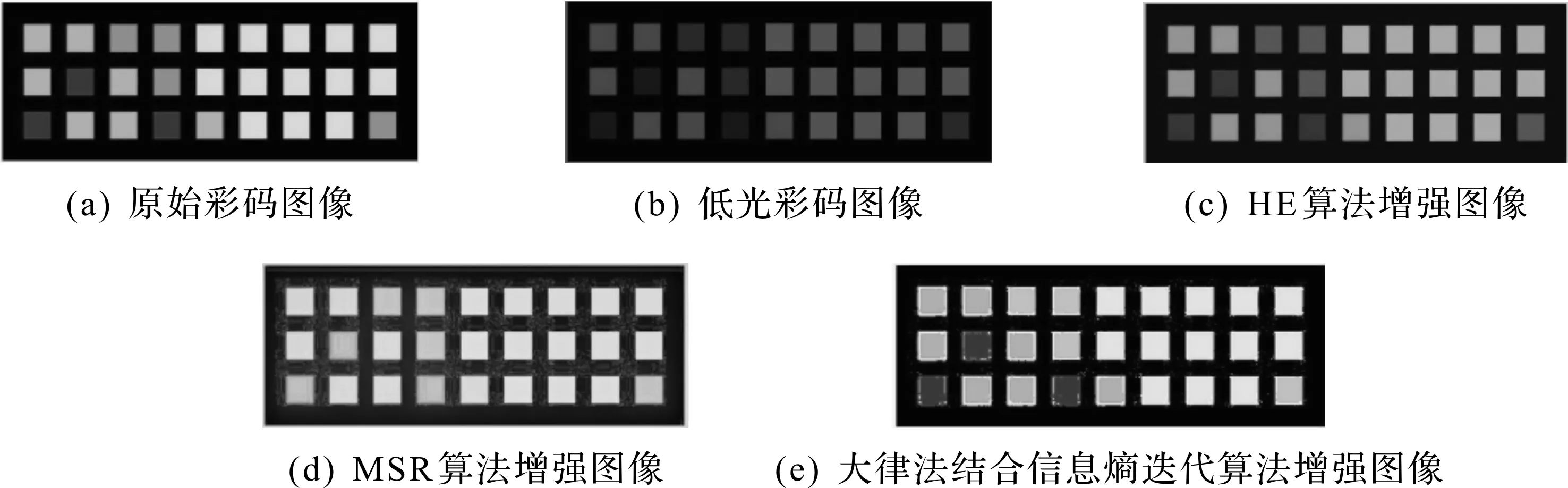
图1 传统算法实现Fig.1 Implementation of traditional algorithms
近年来深度学习发展迅速,在计算机视觉领域应用广泛,如图像识别[7]、图像分割[8]等;也有一些学者,尝试将深度学习应用于图像去雾[9],如Lore等[10]提出了一种基于深度学习的图像自适应增强和去噪方法,即LLNet(Low-light image enhancement net),直接使用现有的深层神经网络结构(即堆栈稀疏去噪自动编码器)来建立微光图像与相应增强图像之间的关系和进行图像去噪;Li等[11]通过建立低光图像数据集,对构造的网络进行训练,再通过训练好的网络,即LightenNet(A convolutional neural network for weakly illuminated image enhancement)达到图像增强的目的。
2 理论模型与方法
Retinex理论由Land[12]提出。物体的颜色是由物体对长波(红)、中波(绿)和短波(蓝)光线的反射能力决定的,而不是由反射光强度的绝对值决定的,同时物体的色彩不受光照非均性的影响,具有一致性。因此该模型假定物体的颜色由物体表面的反射属性决定,与光照强度无关。Retinex理论可以用函数描述为
S(x,y)=L(x,y)R(x,y)
(1)
式中:S(x,y)为人眼观察到的低照度图像;L(x,y)为反映外界光照环境的光照分量;R(x,y)为反映物体本质属性的反射分量。
光照分量决定像素的动态范围,反射分量反映成像物体的本质属性,R(x,y)通常为需要求解的增强图像。在对数域中,将光照分量从原图像中去除,便得到反射分量。照度分量只能通过近似估计获取。Retinex算法的一般流程如图2所示。

图2 Retinex算法一般流程Fig.2 Retinex algorithm general process
Retinex算法流程通过函数描述即可将式(1)转换为对数域,即
logS(x,y)=logR(x,y)+logL(x,y)
(2)
式(2)经转换变化之后可得增强后的图像R(x,y),即
R(x,y)=exp[logS(x,y)-logL(x,y)]
(3)
由式(2,3)可知:Retinex理论对图像增强的核心就是从原始图像S(x,y)中估计外界光照环境的光照分量L(x,y),最后得到反射分量R(x,y)。对光照分量估计的准确与否直接影响后续图像的增强效果。传统的基于Retinex理论的算法,如单尺度Retinex算法(SSR)无法兼顾图像细节增强和彩色保持的要求;多尺度Retinex算法(MSR)采用高斯环绕尺度估计光照分量,在保证图像细节的同时使增强后的图像出现“泛灰”而失真。因此笔者提出了基于卷积神经网络预测光照分量的方法,经过前期的数据集构建、模型构建和网络训练,能够有效地提高光照预测分量的准确度,从而提高后续图像增强的效果。
2.1 网络结构
笔者所提出的网络来自于在低水平视觉任务中的深度学习模型[13-14]。该网络的作用是学习一种映射关系,这种映射以弱光彩码图像为输入,对应的光照映射图像为输出,要求输入图像和输出图像大小相同。池化层会使得采样前后的图像大小不一致,影响网络任务的实现,卷积层会因为丢失边缘信息使得前后图像大小不一致,因此对所有卷积层需要进行必要的边缘填充,以保证图像大小始终不变。通过前3层卷积层提取输入图像特征信息,再用第4层卷积生成光照图像,最后运用Retinex模型进行图像增强,网络结构如图3所示。

图3 网络结构Fig.3 Network structure
考虑到图片太大会导致计算量增大,为便于网络更好地训练,所提出的网络输入和输出并非整幅图像,而是随机选取低光彩码图像的部分区域和与之相对应的光照映射图像为训练样本。输入低光彩码图像的部分区域,经网络模型预测后得到与其大小相同的光照映射图像。
为确定弱光照彩码图像与其光照映射图像之间的关系,通过输入的弱光彩码图像提取各通道像素,使用卷积层获取特征图像。提取方式可表示为
F1(P)=max(0,W1*P+B1)
(4)
式中:P为输入的图像;W1和B1分别为该层的权重和偏置;“*”为卷积运算符;max(0,x)为该层激活函数(RelU),以加快收敛速度和强化训练效果。
根据监督学习反向传播原理和随机梯度下降法,对损失函数(MSE)进行最小化训练,最终得到网络模型参数θ={W1,W2,W3,W4,B1,B2,B3,B4}。损失函数表示为
(5)
式中:N为该训练批次下训练样本数量;F为网络结构所学习到的映射关系;Ui为Pi弱光彩码图像对应的光照映射图像。
2.2 彩码图像增强方法
借鉴Guo的图像增强方法[6],通过Gamma校正调整网络模型预测的照明图,确定结果中的暗区。这些区域可以表示为
L(x)′=L(x)γ
(6)
式中:L(x)为笔者所提出的网络预测得到的光照映射图像;L(x)′为经Gamma矫正后得到的新光照映射图像;γ=1.7,是一个实验值。优化映射时,假设输入图像为n×n像素,局部区域具有相同的光照强度。Gamma修正以后,为了消除遮挡的影响,需要通过引导图像滤波[15]来使光照图像更加平滑。在引导图像滤波中,将输入图像的红色通道作为引导图像。最后,根据式(1,6)获得增强图像R(x)为
(7)
式中:I(x)为原始的弱光彩码图像;L(x)′为经网络预测、Gamma矫正以及引导滤波后得到的光照映射图像;R(x)为最终获得的增强后的彩码图像。
3 实验内容
3.1 数据集构建
训练笔者所提出的网络需要足够安全可靠的彩码数据图像。研究采用张恒丽等[15]提出的彩码生成方法。使用该方法生成的彩码图像(宽250 像素、长520 像素)第一层为白色背景,第二层为黑色背景色(宽180 像素、长480 像素)。黑色背景色中含有矩形的大小为30×30 像素的红、绿、蓝、黄4 色中有效的色块用以存储彩码信息。共生成200 张清晰彩码图像,将图像从RGB通道转到HSV通道,改变V通道系数,生成4 个不同等级的弱光彩码图像,再利用Retinex理论生成4个不同等级弱光彩码图像所对应的光照映射图像。如图4所示,图4(a,c)为通过图1(a)的原始彩码图像生成的弱光程度不同的若光彩码图像,图4(b,d)为利用Retinex理论生成的对应的光照映射图像。

图4 完整数据集图像实例Fig.4 Complete data set image
考虑到神经网络的计算量以及实际环境下光照不均匀的情况,假设图像局部的光照强度是均匀的,将生成的弱光彩码图像以及对应的光照映射图像进行切割裁剪操作。考虑到训练网络计算速度和预测效果,笔者选取了两种裁剪方式。
裁剪方式1将完整彩码图像的长等分20 份,宽等分10 份,得到25×26 像素的局部彩码图像,经计算得到160 000 张弱光彩码的局部图像作为数据集1。如图5(a)所示,左侧图像为低光图像,右侧为其对应的光照映射图像。

图5 裁剪数据集图像示例Fig.5 Tailoring data set image example
裁剪方式2考虑到裁剪方式1所得图像的数据量较大,使得计算机每次训练读取文件的时间较长。同时,该裁剪方法会存在大量的白色背景色的弱光图像,可能会影响网络的训练。因此,提出裁剪方式2来避免上述情况。首先,将生成的弱光彩码图像压缩为原图像大小的1/2;随后,为忽视白色区域裁剪出黑色背景部分的图像;最后,通过重叠、裁剪得到大小为50×50 像素,数量为12 800 张的弱光彩码的局部图像作为数据集2。如图5(b)所示,左侧图像为低光图像,右侧为其对应的光照映射图像。
3.2 网络实现
笔者所提出的网络结构通过Python语言和Matlab程序实现。在训练阶段,每一层卷积的权重都是通过高斯随机分布进行初始化,偏差设置为0。初始学习速率为0.01,每1 000 次迭代学习速率降低0.5。计算机CPU为IntelCorei7-4590,主频为3.3 GHz,内存为12 GB。
3.3 实验内容分析
为确保后续彩码图像增强效果的可靠,首先考虑不同数据量的数据对网络模型的训练是否会产生影响。实验中将数据集2形式的弱光彩码的局部图像数据量分别设定为12 800,9 600,3 200 张。分别采用这3 个数据量的数据集对网络模型进行训练,记录每个数据量训练网络模型时的迭代次数以及对应的损失函数值,折线图如图6所示。

图6 不同数据量训练的损失函数图Fig.6 Training loss function diagram of different data quantity
图6中数据集1,2,3分别表示3 200,9 600,12 800 张弱光彩码局部图像的实验对象。由图6可知:不同数据量的数据集在训练网络模型时迭代多次以后均趋于平缓稳定的状态,且所得到的网络模型的损失函数值相近;12 800 张弱光彩码局部图像对应的数据集3在训练网络模型的过程中能够较早的进入稳定阶段且振荡幅度相比于数据集1和数据集2较小。因此训练数据集的数据量并不会对最终实验结果产生过大的影响,但较大的数据量能够使网络模型快速地进入稳定状态。
为避免网络模型训练的迭代次数影响后续模型对光照图像的生成,将构建的数据集1,2分别进行训练,记录迭代次数与损失函数的值,得到迭代次数与损失函数值的关系如图7所示。

图7 损失函数折线图Fig.7 Line graph of loss function
由图7可知:在训练过程中,损失函数值随着迭代次数的增加不断下降,迭代次数到达500 次以后损失函数值趋于平缓,损失函数值处于相对稳定状态。因此,在模型训练中,迭代次数大于500 次之后,模型结果会相对稳定,迭代次数对彩码图像增强效果的影响相对较小。
笔者所提出的网络参数及结构能够实现对低光彩码图像增强。为研究不同网络参数对弱光彩码图像增强的效果以及对计算效率的影响,尝试更改网络参数,通过MSE损失函数值判断网络训练的效果。网络结构为4 层卷积,通过改变每一层的卷积核大小和提取的特征层数研究网络的预测效果,设定每层间的卷积核大小和提取的特征层数用“-”连接。对25×26 像素大小的数据集1进行卷积层数为4的多种不同网络参数的训练,分别更改特征向量为16-8-4-1,32-16-8-1,64-32-16-1,128-64-32-1,以及更改卷积核大小为7-7-1-5,3-7-1-5,其MSE值如表1所示。对50×50 像素大小的数据集2做了同数据集1一样的训练,结果如表2所示。

表1 25×26像素数据集1网络实验结果Table 1 Network experiment results of data set 1

表2 50×50像素数据集2网络实验结果Table 2 Network experiment results of data set 2
由表2可知:随着卷积次数的增加可以获得更好的MSE性能,然而过多地增加卷积次数对网络性能的改善是有限的。通过增加或者减少卷积核的大小所获得的MSE会发生改变,这可能是由于卷积核大小不同影响了模型的结构,从而导致性能不同。权衡了性能和复杂性,笔者选择一个中间网络结构作为基本网络结构。由表1可知:合理的卷积核大小设置可以令预测结果更好。比较表1,2可知:在相同网络结构下,25×26 像素大小的数据集1训练结果优于50×50 像素大小的数据集2。
分别用数据集1和数据集2预留的测试图像对模型进行预测,将输入图像、预测图像以及标签图像进行比较,比较结果如图8,9所示。

图9 数据集2预测结果示例Fig.9 Prediction results of data set 2
由图8,9可知:数据集2的标签图像的色块边缘有较多的噪声点,导致网络预测得到的光照映射图像的背景与色块无法达到明显的分割;数据集1的标签图像的色块边缘噪声点较少,使得网络预测所得到的光照映射图像能够明显的区分彩码色块部分和背景部分。因此,25×26 像素大小的数据集1能够更好地达到图像增强的效果。
3.4 算法有效性验证
为验证所提算法的有效性,对计算机合成的低照度图像和实际低照度图像分别进行实验。从客观和主观两方面进行对比分析,对比HE经典算法、MSR算法和大律法结合信息熵算法的优劣情况。首先,对合成的弱光照图像进行定性比较。这些低光彩码图像是基于Retinex模型合成的。随机选取了两张未进行训练的完整彩码图像生成不同程度的弱光图像,分别运用上述所提的方法对该图像进行增强。
实验选取PSNR,SSIM,MSE作为客观评价指标:PSNR表征图像的失真程度,其值越高,失真程度越小;SSIM表征图像结构信息的完整性,其值越高,增强后图像与原始图像的结构特征越相似;MSE表征增强后图像与原始图像之间的差距,其值越小说明增强后图像越接近原始正常光照图像。图像1,2的实验结果如表3,4所示。

表3 图像1的客观指标Table 3 Objectiveindicators of picture 1

表4 图像2的客观指标Table 3 Objectiveindicators of picture 2
由表3可知:笔者所提出的算法其SSIM指标高于其他算法,说明对弱光彩码图像进行增强处理后能够很好的保存图像信息。PSNR和MSE指标同样证明了笔者所提出的算法相比其他算法有更好的结果,验证了所提算法的有效性。
运用HE算法、MRS算法、大律法结合信息熵算法对图像1,2进行增强,分别与笔者实验结果进行比较,结果如图10所示。

图10 合成弱光图像增强结果Fig.10 Synthetic low light image enhancement results
由图10可知:与生成的弱光彩码图像相比,上述4 种增强算法都达到了图像增强的效果。HE算法较好地保持了色彩,但在不同弱光程度的输入图像的情况下,该算法并不能作针对性的增强,导致了左侧图像仍然存在曝光不足的现象,是一种增强程度不足的表现;MSR算法应用于弱光彩码图像时,在输入任何弱光程度的图像情况下,其增强效果相似且令彩码色块色彩失真使整张图像存在泛黄的现象;大律法结合信息熵算法相比于以上两种增强算法,其增强效果较为完整,但在色块边缘产生了各种颜色的噪点,会影响彩码识别结果;笔者所提算法,相比于以上算法不仅对不同程度的弱光图像实现了针对性的增强,同时也保持各个色块的色彩信息基本不变,能有效防止彩码识别的错误,但是仍存在局部区域增强效果不完整的情况,如左图最右侧部分,可能是由于该算法的损失函数为均方误差,使其预测结果并不能涵盖所有图像像素点。
为验证笔者所提算法对实际情况的弱光彩码图像也有效果,在真实环境下拍摄了光照不足的彩码图像作为输入图像来做对应的增强处理,结果如图11所示。

图11 现实弱光图像增强结果Fig.11 Real low light image enhancement results
由图11可知:HE算法能在保证图片原有色彩的情况下,较好地增强图像亮度,但仍然存在增强不完全的情况;MSR算法则过度地增强了图像亮度,使得彩码图像颜色泛白,因而彩码色块颜色也产生了失真的结果;大律法结合信息熵算法将彩码色块的信息丢失,仅保留了彩码图像的外观,同时在色块边缘还存在噪声点;笔者算法与HE算法相比,对原始图像有更加完整的增强效果,在保证彩码色块的色彩信息完整的情况下,使增强后的图像更为平滑;相比其他3 种传统算法,对弱光彩码图像增强的效果更好。
4 结 论
在彩码识别中,存在各种程度曝光不足的弱光彩码图像。为解决这一问题,笔者首先从传统图像增强算法出发,对弱光彩码做针对性增强,然后利用Retinex理论特性生成弱光彩码图像,对其光照映射图像进行卷积神经网络训练,最后通过训练的网络预测弱光彩码图像对应的光照图像来作针对性的增强。实验结果表明:笔者所提出的算法能较好地增强弱光彩码图像,同时也尽可能保留了彩码图像的信息。因此,笔者所提出的增强效果算法能有效地应用于低光彩码图像识别,具有一定的借鉴意义。今后将继续优化网络模型,进一步优化图像增强后局部暗区域的现象。
