慢阻肺知识图谱的构建研究与实现
2020-07-13贾辛洪宋文爱李伟岩陈志华常宗平
贾辛洪,宋文爱,李伟岩,王 青,雷 毅,陈志华,常宗平
1(中北大学 软件学院,太原 030051) 2(清华大学 信息技术研究院,北京 100084) 3(中日友好医院 临床医学研究所,北京 100084)
1 引 言
慢性阻塞性肺疾病是一种以不完全可逆性气流受限为特征的疾病,气流受限呈进行性发展,多与肺部对有害颗粒与气体的异常炎症反应相关.慢阻肺发病率高、知晓率低、控制率低,病死率相对高,是危害人类健康的重大疾病之一,病情严重时候会引发呼吸道感染,导致呼吸衰竭,严重患者会合并严重的肺部感染等原因去世.在我国,慢阻肺患者生活质量远远低于健康人群.慢阻肺也是“沉默的疾病”,发病初期无明显症状与不适感,但求医时已经发展到中度以上[1].目前大多数患者首诊出现在基层医院,但是有部分基层医院医生对其基础知识及技能掌握不足,使用设备不规范,导致患者错过最佳就医时间.
知识图谱(Knowledge Graph)是一种新的知识表示方法,本质还是语义网,基本原理是用图模型来刻画和描述现实世界中存在的各种实体或概念,建立这些实体之间的关系.国外最有影响力的知识图谱有:YAGO[2]是由德国MA Planck计算机科学院设计的.Freebase[3]是谷歌的知识图谱,类似于维基百科的创作,内容由用户添加.DBpedia[4]是从维基百科的词条里撷取出结构化的资料,以强化维基百科的搜寻功能.NELL[5]由卡内基-梅隆大学Tom Mitchell教授领导的团队构建.
国内的知识图谱从搜狗知立方开始.百度知心是百度的下一代搜索引擎.中国科学院中医药信息研究所基于已有的中医药学语言系统构建的中医药知识图谱[6],基于知识图谱的基因组流行病学可视化分析[7]等,有利于推动国家医学知识的分析与推理.但是目前现有的各种对医学信息学领域知识库的研究大多是基于互联网上公开的医学文献,这类知识虽然获取比较方便,但是较少将其与电子病历结合起来,导致知识比较局限,如何利用真实医学数据来构建知识图谱[8],获取更准确、更全面、更权威的知识成为医学知识图谱领域的研究需求.
2 相关技术
2.1 条件随机场模型
2001年,Lafferty等人结合最大熵模型和隐马尔可夫模型的特点提出了一种无向图模型条件随机场(CRF),它不仅解决了隐马尔可夫输出独立性假设的缺点,可以考虑上下文的特征;而且一定程度上解决了最大熵模型的标记偏置问题.
本文是将线性链条件随机出模型应用到了命名实体识别中,就是把输入的文本中的单词序列作为了观察序列X=(X1,X2,…,Xn),根据单词序列来推断最有可能的标记序列Y=(Y1,Y2,…,Yn).即在给定的观察序列X情况下,某个特定序列Y的概率为P(Y|X),根据定义有:
P(Y|X)=exp(∑i,kλktk(Yi-1,Yi,X,i)+∑i,lulsl(Yi,X,i))
(1)
其中,tk(Yi-1,Yi,X,i)表示转移函数,表示在序列X下序列Y在位置i-1及i对应的值转移概率,而sl(Yi,X,i)表示状态函数,表示在序列X下序列Y在位置i对应的值概率.另外λk,μl分别为两个函数的权重.若令sl(Yi,X,i)=sl(Yi-1,Yi,X,i),则转移函数和状态函数可以统一由特征函数表示,对特征在各个位置i求和,有:
(2)
再加上归一化,最终条件随机场的条件概率为:
(3)
其中:
(4)
2.2 BiLSTM模型
长短期记忆网络(LSTM)是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,克服了序列过长产生的梯度弥散问题.LSTM模型通过特殊的门结构使得模型可以有选择性的保留上下文信息,因此可以用它来识别医学上的实体.LSTM模型的结构可以形式化的表示为:
it=σ(Wi[ht-1,xt]+bi)
(5)
ft=σ(Wf[ht-1,xt]+bf)
(6)
(7)
(8)
ot=σ(W0[ht-1,xt]+bo)
(9)
ht=ot*tanh(Ct)
(10)
LSTM模型在信息处理只是将信息从前往后的处理,所得到的当前状态结果只考虑到了当前状态之前的信息而序列标注任务,当前状态之前的状态跟其之后的状态对于当前状态是同等重要的.命名实体的标签在确定时相互之间有强烈的依赖关系.双向LSTM(BiLSTM)结构可以很好的解决这种情况,所以为了有效的获取到上下文的信息,我们采用双向LSTM结构,双向LSTM对每一个句子采用顺序和逆序计算,将计算得到的两种不同结果向量拼接起来作为最终隐层表示,这样有利于更加准确预测当前的状态.
3 慢阻肺知识图谱的构建流程
本系统慢阻肺知识图谱是由Schema(概念层)和数据层两个部分实现的,如图1所示.
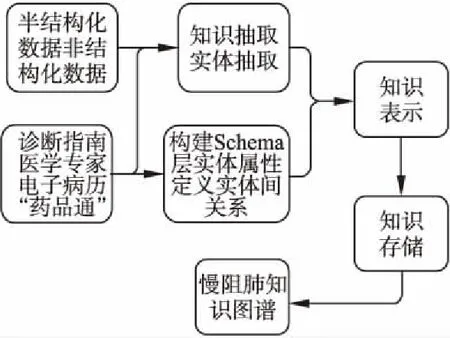
图1 慢阻肺知识图谱构建流程图
1)Schema层的构建.概念层的构建结合了慢性阻塞性肺疾病诊治指南,电子病历的信息,专家医生的意见等多方面信息.
2)数据层的构建.本阶段包括以下几个部分:
a)半结构化数据抽取,比如获取“药品通”中关于慢阻肺药品说明书信息;
b)非结构化数据抽取知识,比如获取电子病历中慢阻肺症状的信息
c)知识表示,本系统用的是Neo4j数据库支持的属性图来进行表示.
d)知识存储,用Neo4j图数据存储.
3.1 概念层的构建
Schema层是构建知识图谱的框架,Schema就是要找出一个领域内的数据模型,涉及到这个领域里面有意义的概念类型以及类型的属性,以及类型之间关系.
本系统慢阻肺知识图谱的概念层主要是参考慢性阻塞性肺疾病诊治指南以及在领域专家的帮助下设计实现的.概念层主要包括慢阻肺相关的实体,慢阻肺相关的实体属性以及慢阻肺相关实体的关系等部分.
慢阻肺相关医学实体(E):慢阻肺相关医学实体指的是在能够唯一标识各种医学的实体.通过慢阻肺指南可以知道涉及到的实体有,慢阻肺疾病实体,慢阻肺诊断实体,慢阻肺药品实体,慢阻肺检查实体,慢阻肺症状实体等等.
慢阻肺医学关系(R):指的是慢阻肺医学实体间相互之间的关联.
结合慢阻肺指南,在中日友好医院专家的帮助下,可以清楚的知道慢阻肺知识图谱涉及到的关系,整理出以下慢阻肺医学关系类型.
a)commonDrug(疾病常用药品)
b)needCheck(疾病所需检查)
c)hasSymptom(疾病症状)
d)subclass(疾病与上一级父类关系)
e)acompanyWith(疾病并发疾病)
f)hasAttribute(实体拥有的属性)
3.2 数据层的构建
慢阻肺知识图谱数据层的构建属于知识抽取部分,就是将从慢阻肺的电子病历,网站如“药品通”等中的数据抽取出来,然后将其与Schema中的概念对应.但是由于数据来源的不同,以及知识的表达方式的不同,不同数据需用不同的方法表达,主要包括半结构化数据,非结构化数据等.
3.2.1 数据源
本系统的数据主要涉及到中日友好医院呼吸科的慢性阻塞性肺疾病的电子病历,《慢性阻塞性肺疾病诊治指南(2013年修订版)》[9],“药品通”网站上关于慢阻肺的药品说明书的信息.
3.2.2 慢阻肺指南分析
慢性阻塞性肺疾病诊治指南中涉及到了慢阻肺的定义,发病机制,病理学原理,病理学表现,病理生理学改变,危险因素,临床变现,实验室检查及其他检测指标,诊断与鉴别诊断,慢阻肺的评估,慢阻肺的治疗等等,指南中涉及到了慢阻肺疾病的方方面面,而目前现有的系统大部分是直接分析已有数据库中表的联系来定义实体间的关系,造成构建的知识图谱的概念层不是很完善,会有知识的缺失,但是使用指南构建概念层可以相对的避免这方面的问题,从而使得系统更加的完善,具体.
3.2.3 从半结构化数据中抽取
本系统关于慢阻肺所使用到的药品说明书是通过网页爬虫从“药品网”获取,进行数据的清洗,解析,由于网站上的数据就规范,可以对获取到的数据直接通过规则匹配获得,比如药品的名称,药品的成份,性状,功能主治,用法用量,不良反应等等,根据概念层时对药品类定义,也就获得了关于药品的“属性-属性值”关系,但是系统中还涉及到其他比如慢阻肺疾病的症状,虽然诊治指南上也有,但是还不是很全,所以需要对慢阻肺电子病历中关于疾病症状的数据进行抽取,比如患者的主诉等是一段文本,就需要对非结构化数据进行知识的抽取,本文将使用CRF与医学词典相结合的命名实体识别方法进行实体的抽取.
3.2.4 从非结构化数据中抽取
本系统需要从电子病历的入院情况,如主诉等一段非结构化的文本中进行命名实体识别来抽取实体,现在对于命名实体识别的方法主要分为以下:基于词典和规则的方法,基于统计机器学习的方法,基于深度学习的方法[10,11]或者是将其中的两两结合这样可以将它们的优点结合.经典算法有隐马尔可夫模型(Hidden Markov Mode,HMM)[12],支持向量机(Support Vector Machines,SVM)[13],条件随机场(Condi-tional Random Fields,CRF)等等.
4 实 验
4.1 数据来源
目前对于慢阻肺这种疾病的电子病历的数据没有现有的标注,所以本系统以中日友好医院呼吸科的病历为来源.对好日友好医院呼吸科提供的数据进行清洗,实验时一共有中日友好医院的996份电子病历,人工标记了300份电子病历,按照3∶1的比例随机划分为训练集和测试集.
4.2 疾病实体的标注
本系统需要对预处理后的数据进行格式转换,按照BMESO 对语料进行标志.标记为 SIGNS-B、SIGNS-M、SIGNS-E、TREATMENT-B、TREATMENT-M、TREATMENT-E、BODY-B、BODY-M、BODY-E、S、O,分别标志症状的开头、症状的中间、症状的结尾、治疗的开头、治疗的中间、治疗的结尾、身体部位的开头、身体部位的中间、身体部位的结尾、单个症状词和其他词.表 1 为使用 BMESO 标记实体的举例.
表1 BMESO标注
Table 1 BMESO distancepole

句子患者咳嗽、咳痰BMESO标记00SIGNS-BSIGNS-E0SIGNS-BSIGNS-E
4.3 实验流程
将标注好的数据使用预训练字向量,将其作为作为embedding层输入,这里采用的是word2vector工具基于skip-gram方法训练字向量,其中的embedding的维数m为150.如有一个序列X=(X1,X2,…,XT),一共有n个字,对于每一个字XT,用其对应的字向量YT=(y1,y2,…,y150)表示,那么BiLSTM的输入就可以表示为Xnm,输出结果为前向传递LSTM的输出与后向传递LSTM的输出的拼接,以此作为CRF的输入,在CRF层是通过过去状态的输入及输入所属的状态来预测当前输入所属的状态,为了在得到更好的模型结果,在训练时采用Adam优化器使整个模型的损失达到最小.本实验流程如图2所示.
实验的核心代码如表2所示.
4.4 性能评价
实验采用的是机器学习常用的评价指标precision(准确率)、recall(召回率)和F值三个指标来评价试验的性能.具体定义如下:
(11)
(12)
(13)

图2 BiLSTM-CRF模型

表2 核心代码
4.5 实验结果与分析
通过实验,如表3所示,分析可以得到,基于深度学习的模型比传统的机器学习效果要好,这是因为CRF算法的结果跟选择的特征有关,而相关特征的选择又是有人参与设定,会出现局限性.BiLSTM比LSTM的效果要好,因为LSTM是考虑当前状态之前的信息,没有考虑当前状态之后的信息,而在命名实体识别的过程中,当前状态的之前与之后应该是同等重要,因此BiLSTM更加适合命名实体识别.BiLSTM-CRF明显要比单独使用时效果要好,因为CRF构造字符间的特征对应关系,而LSTM/BiLSTM层的输出矢量归一化,使得向量泛化.所以BiLSTM-CRF的在命名实体识别效果最好.
表3 实体识别结果
Table 3 Entity identification results
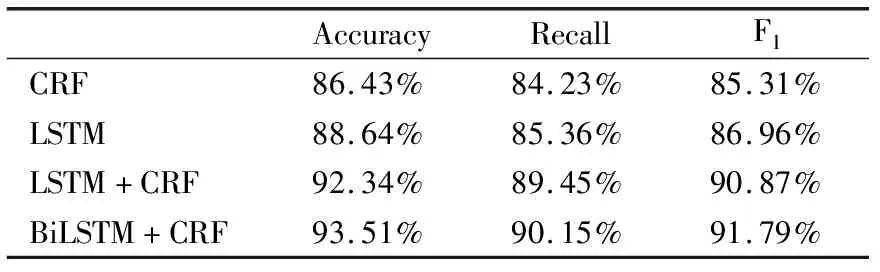
AccuracyRecallF1CRF86.43%84.23%85.31%LSTM88.64%85.36%86.96%LSTM+CRF92.34%89.45%90.87%BiLSTM+CRF93.51%90.15%91.79%
5 结束语
本文主要是针对我国目前慢阻肺患者和电子病历较多,但是在偏远地区缺乏有经验的医生,病人对慢阻肺缺乏正确的认识,而知识图谱无论是在知识的展示方面还是知识的检索方面都有很好的效果,因此需要构建慢阻肺的知识图谱,本文主要从知识图谱构建流程以及其中涉及到的医学命名实体识别问题以及解决解决方案间的比较,通过做实验知道各种方案的差异.下一步工作将持续完善更新知识图谱、以及将以本知识图谱为基础设计开发关于慢阻肺的自动问答等辅助诊治系统.
