基于滑动语义串匹配(SMOSS)的汉语词义消歧
2020-07-13黄德根
王 伟,黄德根
(大连理工大学 电信学部 计算机科学与技术学院,辽宁 大连 116033)
1 引 言
词义消歧(WSD)是自然语言处理领域中的一个难点问题[1,2],至今仍没得到很好解决.现在自然语言处理研究已经深入到语义分析层次,因此对于词义消歧技术需求也就更加强烈.随着词义消歧研究不断深入,研究人员提出了很多方法以提高性能,包括采用一些深度学习的方法.Dayu Yuan等人[3]采用LSTM模型的词义消歧取得了较好效果.Alessandro Raganato等人[4]定制了从LSTM到编解码模型一系列的神经结构并在多语种上取得好的效果.杨安等人[5]提出利用无标注文本构建的词向量模型结合特定领域的关键词信息的词义消歧方法.Xue-Ren Sun等人[6]提出将原始词义消歧问题转换为文本分类问题后使用LSTM进行文本分类的消歧方法.Minh Le等人[7]对Dayu Yuan等人[3]的LSTM词义消歧方法进行深入研究并分析优缺点.李国佳等人[8]提出在词向量表示基础上通过获得多义词的上下文窗口向量的词义消歧方法.吕晓伟和章露露[9]提出利用向量表示的上下文和义项信息,通过融合语义相似度和义项分布频率的词义消歧方法.孟禹光等人[10]提出一种加入词性特征的语境向量模型的词义消歧方法.罗曜儒和李智[11]采用基于Bi-LSTM的语义向量表示歧义词语义信息,在生物医学文本中取得较好的消歧效果.此外,研究人员也提出了其他一些有特点的多种方法以提高性能.鹿文鹏和黄河燕[12]提出把歧义词所在的句子先经过句法分析后对依存约束集合进行适配的词义消歧方法.杨陟卓和黄河燕提出了采用语言模型优化传统有监督消歧模型的方法[13].杨陟卓[14]提出把同一篇文章中的含相同歧义词的句子作为歧义句的上下文语境进行消歧的方法.闫蓉和高光来[15]提出依据词性自动调整消歧上下文边界大小的消歧方法.ZHANG Chun-xiang等人[16]使用语义和句法信息提高了消歧性能.杨陟卓[17]通过假设歧义词的上下文的译文所组成的语境与原上下文语境所表述的意义相似,提出一种基于上下文翻译的消歧方法.史兆鹏等人[18]提出利用依存句法分析提取上下文的多义词及义项的多种特征的词义消歧方法.WANG Xin-da等人[19]提出利用同义词词典选取替代词代替目标词,通过模拟人的语义推理过程的词义消歧方法.Devendra Singh Chaplot等人[20]使用主题模型突破了通常词义消歧只能在一个句子或一定窗口宽度的范围内进行的限制,实现了把整个文档作为上下文并以线性速度运行的词义消歧.
本文提出了基于滑动语义串匹配的词义消歧模型.主要特点:1)使用词的语义码特征建立语义模板,解决传统词模板因模板长度增加而导致数据稀疏的问题,而且语义模板长度可以做到更长;2)采用弹性语义层级匹配策略,相对一些只选定固定语义层级匹配的方法,增加了匹配成功率;3)采用对多个匹配成功模板的得分计算,解决了武断选择某个单一匹配结果所导致的错误率高的问题.
2 模 型
基于滑动语义串匹配(Sliding Match of Semantic String,SMOSS)的词义消歧,主要包括两部分:一是建立N元语义模板库,二是基于滑动语义串匹配的词义消歧.
2.1 采用《同义词词林》分类标准
一般来说,词义消歧都是依据不同的语义分类词典进行的,比如《知网》(HowNet)、《同义词词林》和《现代汉语语法信息词典》等.本文选用哈工大研制的《同义词词林》扩展版,其编码体系共有12个大类,97个中类,1400个小类,采用5级表示.比如,“中学”编码“Dm05A08@”,表明“中学”属于D大类,m中类,05小类,A类词群,08原子词群,独立分类@.本文语义码只使用《同义词词林》扩展版编码的前四位信息(小类标准),比如“中学”编码对应“Dm05”.
2.2 建立N元语义模板库
第1步.按照语义词典,标注训练语料句子每个词对应的语义码;对于单义词,由机器自动按照语义词典的语义码一一对应标注;对于多义词,则根据词所在上下文信息,由人工从语义词典选择最恰当的语义码进行标注.对于由n个词构成的句子,这n个词对应的n个语义码{S1,S2,…,Sn}称为“语义码序列”.对于语义码序列中的一部分,则称为“语义码串”,简称语义串,比如,一个语义码串{S1,S2,S3,S4,S5}就是n长度的语义码序列{S1,S2,S3,S4,S5,…,Sn}中的一部分.
第2步.对每个语义码序列,按每移动一个语义码位置,以N个语义码长度(本文N=5)进行切分分组,即以“宽度为N的窗口”从每一个语义序列前端开始向后滑动,每滑过一个语义码位置,就从该窗口中抽取一个含有N个长度的语义码串,从已经标注好的训练语料中抽取的语义码串,称为“N元语义模板”.以此类推,把一个语义码序列中所有N元语义模板都提取出来.对于每个语义码序列中不足以按N长度划分的结尾部分,则按实际的长度提取,直到提取模板长度为1为止.由n个词构成的句子中可抽取n个语义模板(T1,T2,T3,…,Tn),见图1.比如,从句子“远在五千多年前,人类发明了文字.”提取的N元语义模板样例,见图2.其中“△”表明该模板是在句子的开头位置.
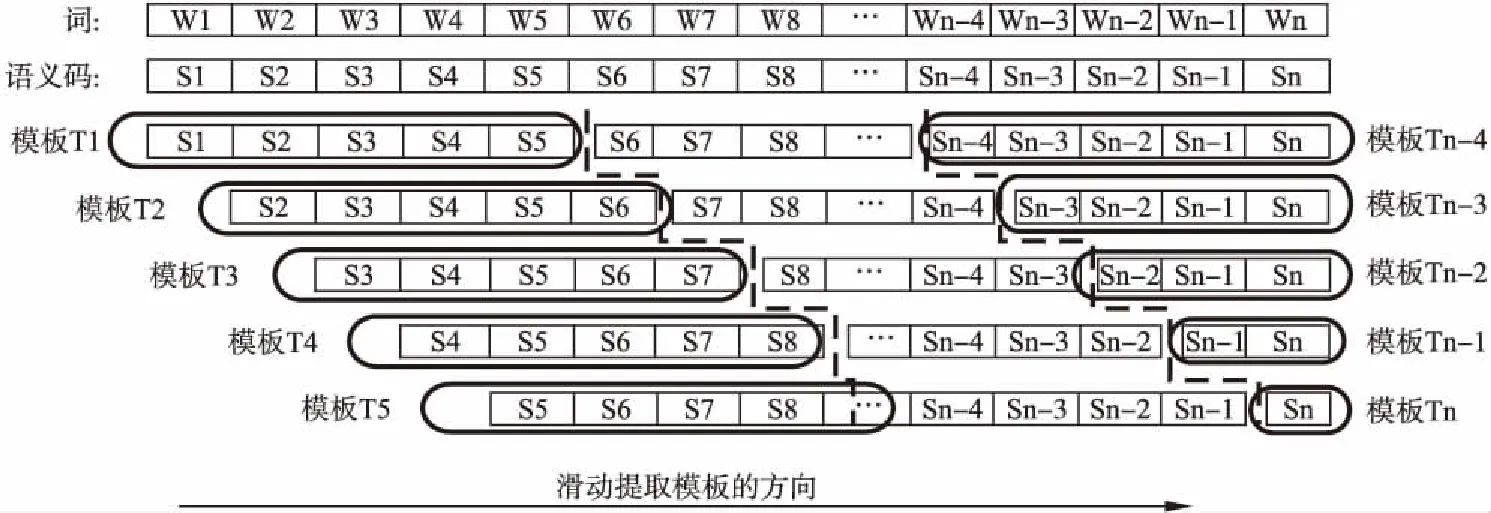
图1 从语义标注的句子中提取N元语义模板(N=5)的示意图
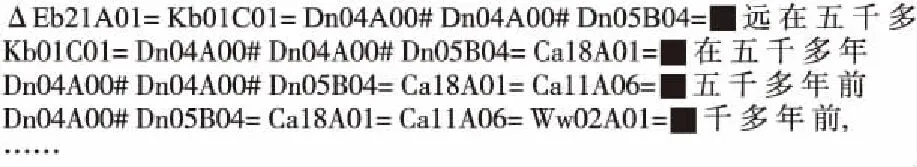
图2 从“远在五千多年前,人类发明了文字.”句子提取的部分N元语义模板
第3步.对语料库中的所有标注的句子都重复以上第1步和第2步操作,直至抽取所有的N元语义模板,从而建立一个N元语义模板库.
2.3 基于滑动语义串匹配的词义消歧
2.3.1 填写句子每个词的语义码得到语义码序列
按照语义词典,对于单义词的单个语义码,用“Sx”表示,多义词的多个语义码则用“Sx-1/Sx-2/Sx-3…”表示,见图3.比如,其中的第2个词和第6个词是多义词,它们的语义码都包含两个语义码.图3中语义码序列为“S1S2-1/S2-2S3S4…Sn-1Sn”.
2.3.2 提取N元语义码串并分组和分区
在按前一操作得到的语义码序列上,按每N元长度(本文取N= 5)提取所有语义码串,并对它们按水平方向分组和垂直方向进行分区.分组过程与建立N元语义模板库时提取N元语义模板过程相似,只不过这里每一组语义码串并不是一个N元语义模板而已.按水平方向进行分组后的n个语义码串(C1,C2,C3,…,Cn-1,Cn)和垂直方向进行分区的5个分区(1区、2区、3区、4区、5区)的示意图,见图3.
2.3.3 计算语义码串与N元语义模板的匹配得分
1)计算语义码串中的单个语义码的匹配得分
对于每个提取的N元语义码串中的语义码,在与N元语义模板库中N元语义模板的对应位置的语义码匹配时,两个来源不同的语义码是按照语义词典的编码格式从大类到小类的顺序依次进行匹配,先分别得到大类匹配得分MatchScore_Level(1)、中类匹配得分MatchScore_Level(2)和小类匹配得分MatchScore_Level(3),见公式(1).

图3 由n个语义码构成的语义码序列和按水平分组、按垂直分区的示意图
(1)
其中Xs表示语义码串的一个语义码,Xt表示与Xs对应的N元语义模板中的语义码;i= 1,2,3分别表示对应的语义码层级,每个层级得分的大类Big_Score、中类Mid_Score和小类Small_Score可定义为某一个指定常数.然后通过对三种分类层级的匹配得分加权求和而得到单个语义码的匹配得分MatchScore_Unit,见公式(2).
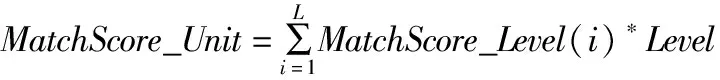
(2)
其中LevelWeight(i)为每类层级的权重,L值为加权求和时所包含的语义码类别,本文L= 3,即包含大类、中类和小类三种类型的加权求和.
2)计算整个语义码串的匹配得分
按照一个语义码串从开始到结尾顺序,对一个语义码串上的每个语义码的匹配得分进行加权求和,从而得到整个语义码串的匹配得分MatchScore_SemanticString,见公式(3).
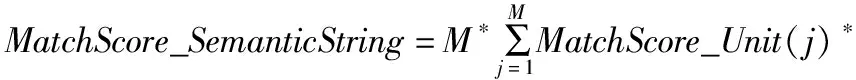
WordTypeWeight(j)*WordPositionWeight(j)
(3)
其中M表示当一个语义码串与一个N元语义模板从开始位置向后连续匹配时,语义码串上的语义码的匹配得分不为0时的最大语义码个数,M≤N,即语义码串的最大匹配长度;WordTypeWeight(j)为每个语义码的词类权重(比如把语义码对应的词按实词和虚词进行区别);WordPositionWeight(j)为语义码在模板上的位置权重(比如把语义码的位置按居于模板中心和边缘进行区分),本文选择当j=1或j=M时(也即是最长语义码的首尾两个边端位置),调整WordPositionWeight,其余情况不调整.
3)匹配时的未知词和有多个匹配结果的处理
a)未知词的语义码处理
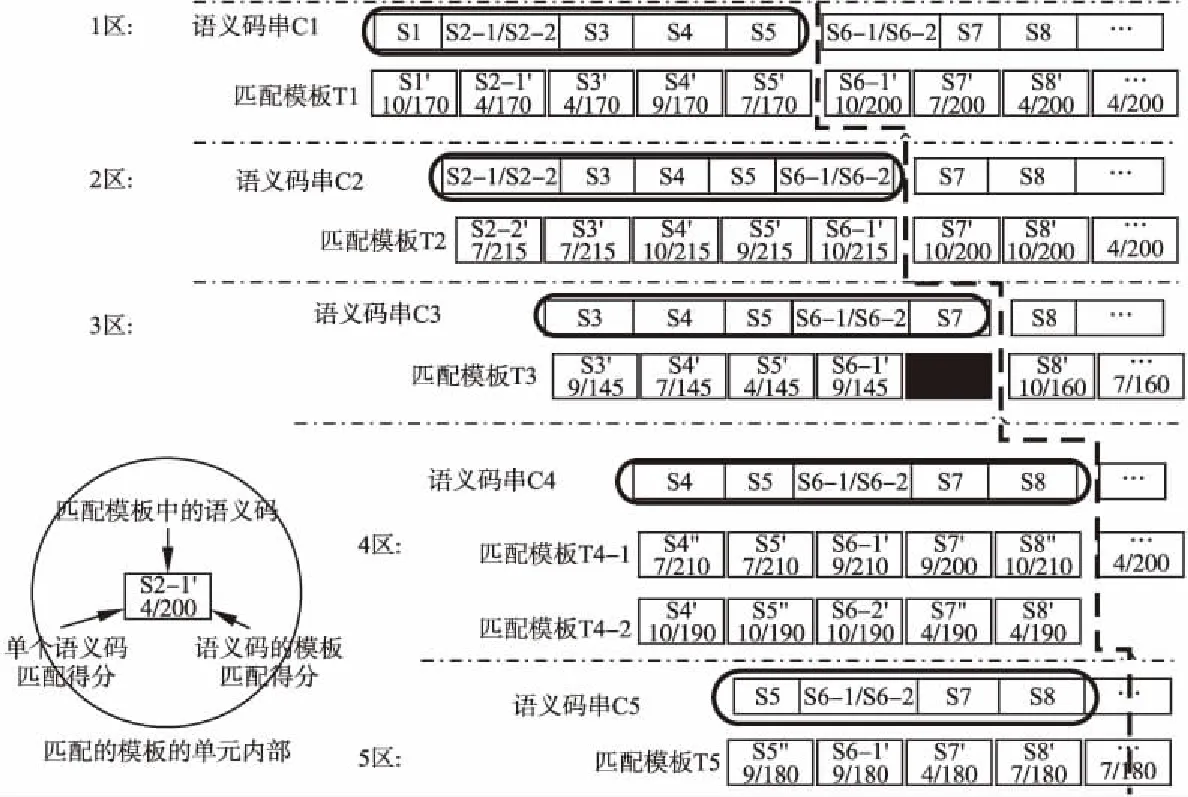
图4 N元语义码串与N元语义模板的匹配结果示意图
未知词的语义码,本文按照词性进行默认指定,如果为名词,则候选语义码“Aa00A00#,Ba00A00#,Ca00A00#,Da00A00#”;如果为动词,则候选的语义码“Fa00A00#,Ga00A00#,Ha00A00#,Ia00A00#,Ja00A00#”.
b)语义码串匹配时有多个匹配结果的处理
当一个N元语义串匹配到多个N元语义模板时,一律保留这些匹配的语义模板,见图4.其中第4个语义码串(C4)保留了匹配成功的多个语义模板(共2个,T4-1和T4-2).另外,图4也说明了匹配成功的长度不一定都是N长度的,比如第3个语义码串的N元长度是5,但是最大的模板匹配长度是N-1=4,结尾语义码(S7)的匹配为失败(即黑色填充表示的部分).
2.3.4 按照语义码串的匹配结果确定最终语义码
1)得到每个区中每个词的各种语义码的最大得分
从第一个区开始,对每个区内所有匹配模板的语义码按照每个词位置进行垂直方向过滤.对于过滤后的不同类型语义码,分别列出不同区中语义码在模板匹配时的不同得分,见图5.
2)得到所有区中各种语义码的最大得分
对于每个词位置上的所有语义码,分别在N个区上进行垂直过滤后而得到每种语义码的最大匹配得分,按照专门算法计算每种语义码在所有N个区中的得分.专门算法中包括统计所有N个区对每一种语义码的投票数,规定每个区对每种语义码最多只有1个投票数,如果某语义码在某区不存在,那么该区对该语义码的投票数为0.同时考虑其他得分信息,比如在所有N个区中的在单个区中的最大得分,在所有N个区中的累计得分等,每个词的各种语义码的最后得分为FinalScore,见公式(4).
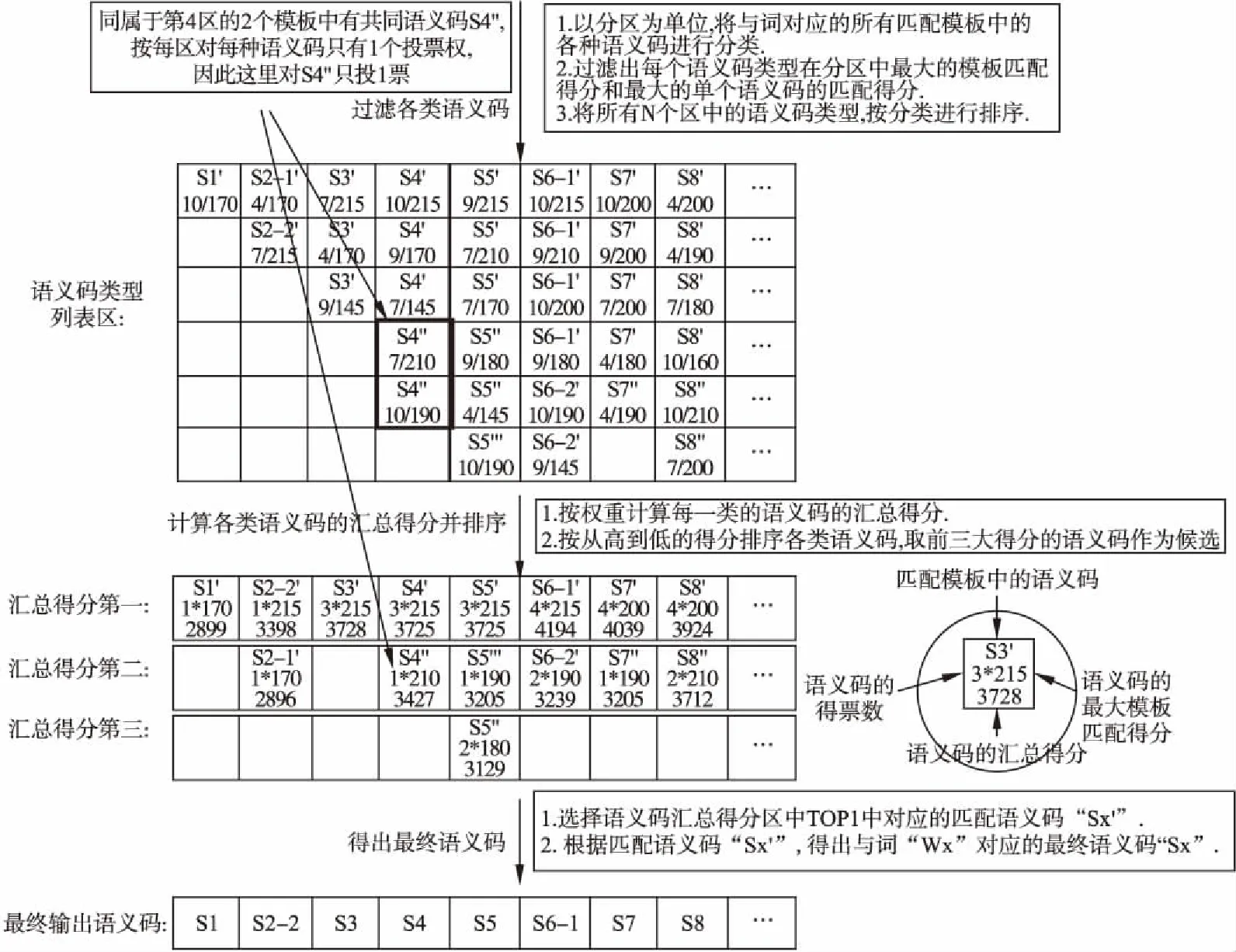
图5 通过过滤和加权计算确定最终语义码的示意图
FinalScore=λ1*VoteNum+λ2*MaxScore_T+λ3*AccumulativeScore_T
(4)
其中,VoteNum为所有区对该语义码的投票数;MaxScore_T为该语义码在所有N个区的范围内最大的单个区得分;AccumulativeScore_T为累计该种语义码在所有N个区中最大得分后的汇总得分;λ1、λ2、λ3为细分权重.
3)选择所有N个区中得分最大的语义码为最终输出
选择每个词位置上匹配得分最大的语义码进行输出,从句子第一个词开始,直到输出整个句子上所有词的语义码,见图5.由于每个区中不同得分的语义码可能有很多,本文选择每个区中的得分由高到低的前TopX项(X值实验选定)参与后面的计算.其中最终输出的语义码为“S1,S2-2,S3,S4,S5,S6-1,S7,S8…”,多义词W2和W6消歧后的语义码分别为S2-2和S6-1.
3 实 验
实验语料:为了检验本文方法的效果,选用国际语义评测的中英文词汇任务SemEval-2007中的Task#5[21]进行实验.本任务共有40个歧义词,其中分别有19个名词和21个动词.评估任务共提供训练句子2686句,测试句子935句.
实验准备:为了有效验证本文方法和减少标注工作量,本文仅标注了训练句子中多义词的左右两边的N-1个词语的语义码,因为实际提取的模板也只是使用这部分信息.按照《同义词词林》扩展版的语义码和原语料给定的词性制约,自动地预先过滤掉那些不符合词性的候选语义码,然后对其中单义词进行自动标注,对多义词进行人工标注,整个标注的工作量为1人3天.
评测标准:采用评估标准中的宏平均精度(Pmar,macro average accuracy).
其中,N为所有目标词数,mi是对每一个特定词所标注的正确例句数,ni是对该特定词所有的测试例句数.
实验结果:多种选择方案后的实验结果见表1.
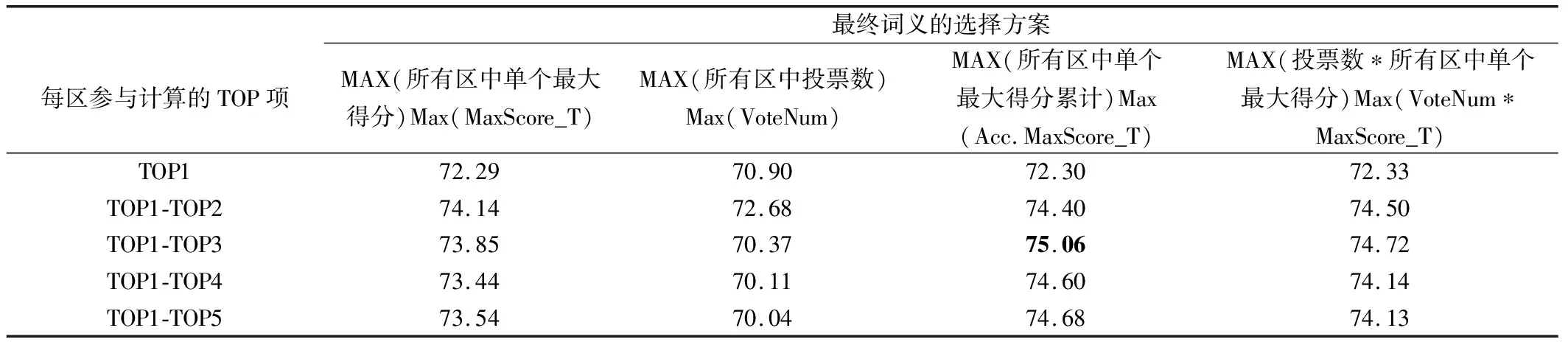
表1 多义词消歧精度(按4种方案测试)
4 实验结果分析
从表1结果来看,在选择每个区参与计算的TOP项时,如果只选择一个TOP项时,即选择TOP1时,效果最差.随着选择TOP项增多,性能逐渐提高,但当TOP项数超过一定值时,性能有所下降.根据当前的实验,选择的TOP项数为3时比较好.产生这个问题的原因,可能是每个区参与项数太少时,会硬性拦下了正确内容,而项数太多时,干扰的噪声又会增加,从而影响了整体性能.从所选择的不同实验方案来看,它们各有优势.对于选择所有区中的单个得分最大者,或者所有区中单个最大得分的累计得分最大者,都要好于单独选择投票数最大的方法.分析原因:单纯五个区投票最大票数是5,当存在多个并列结果时,系统只是顺序选择并列中的第一个,从而造成了性能下降.
从结果出错的地方来看,一些是权重值不合理造成的,这个日后可继续优化;还有一些,就是与训练语料中提取的所有模板都不匹配而导致的错误,如果连匹配最底层的一级(大类)语义码的模板都不存在,即使想通过语义码来扩展那也无法成行.对于这种问题,还是需要扩充相应标注语料才能解决,本文方法虽然具有“取一个词=>得到一个语义码=>覆盖多个词”的能力,并可通过弹性匹配来解决一定的数据稀疏问题,但是若整个训练语料中连原始的同义词都不存在,也就自然谈不上扩展和覆盖了.因此,从这个意义上讲,用于训练的语料规模还是越大越好.
5 相关研究的对比
为了与其他方法对比,表2中列出了目前已知使用SemEval-2007评测标准的一些方法.
对于表2中结果,XING[22]使用了词性、指定词性的词、浅层句法分析的短语、《同义词词林》词范畴信息等,该方法由于使用了外部浅层句法分析资源,因此容易受到浅层句法分析质量的影响.杨陟卓等[13]使用大规模语料(1998年半年《人民日报》和搜狗新闻数据语料库)训练语言模型,然后利用综合模型进行消歧,该结果是在给定训练语料之外再加其他外部语料进行训练后的测试结果.杨陟卓[17]将训练语料的上下文和测试语料的上下文分别翻译后再通过贝叶斯消歧模型进行消歧,该方法需要依赖外部翻译资源,因此容易受到翻译质量的影响.本文方法除了使用《同义词词林》语义编码词典外,没使用其他的资源和复杂特征,因此可以不受外部资源影响而独立工作.即使在只利用语义模板本身语义信息和较少上下文标注信息(目标词左右4个词的语义码),在处理过程不复杂的情况下,就取得与对比方法相接近的效果.而且,若是对于一个句子中同时有多个歧义词需要消歧时,只要它们是在一个模板长度覆盖内,我们方法就可一次并行地消歧多个目标词,而不用逐个歧义词分别模板匹配,这将大大提高消歧效率,特别适合于全文所有词的词义消歧.
表2 相关其他方法的对比
Table 2 Comparison with other methods

方 法PmarXINGYUN[22](2007)SRCP_WSD74.90杨陟卓,黄河燕[13](2014)Optimized_ME75.30杨陟卓[17](2017)Method_275.97本文SMOSS75.06
6 总 结
本文提出一种基于滑动语义串匹配(SMOSS)的汉语词义消歧方法.其先从经过语义码标注的训练语料中提取N元语义模板,以建立语义模板库;然后滑动地将测试句中的N元语义码串与N元语义模板匹配,通过目标歧义词左右两边N-1个语义码的定位匹配,确定了该目标歧义词的词义.该方法使用词的语义码建立模板,比使用词建立模板具有更好的覆盖度,而且3级层次的语义码格式可以更适合弹性匹配,这都有效缓解了有监督学习方法中数据稀疏的问题.从本文使用SemEval2007 Task#5评测实验来看,即使仅使用目标词左右N-1词长度的语义码信息,在没使用其他的复杂特征和依赖复杂的外部资源的情况下,也可以达到接近于目前该标准最好的性能,充分表明该方法的简洁性和有效性.以后我们将在优化参数上继续挖掘潜力,以期能能更好地提高词义消歧性能.
