基于Skip-PTM的网页主题分类与主题变迁的研究
2020-07-13耿宜鹏鞠时光蔡文鹏
耿宜鹏,鞠时光,蔡文鹏,章 恒
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
1 相关工作
文本信息处理作为自然语言处理的一个研究领域,其主要研究内容包含:文本分类、文本聚类和文本建模.网页主题分类技术是文本信息处理的一个具体应用,广泛应用于搜索引擎、主动服务推送、信息过滤等领域,已成为管理和组织Web网页信息的关键技术之一.随着各站点数据井喷式的更新与增加,网页主题类型也会不断出现变化,同一站点的网页主题在不同的时间段上会出现变迁.例如以腾讯体育官方新闻数据为例,2019年10月“CBA赛事”相关的网页主题主要体现在“CBA季前赛”上,2019年11月相关的网页主题已从“季前赛”变迁到“CBA常规赛”.这种主题变迁的研究将为服务推送、数据统计等相关领域提供有效的帮助.
国内外已有研究人员从不同的角度对网页主题分类和网页主题变迁进行了研究,使用的方法主要分为:基于字符串的方法[1-4]和基于语料库的方法[5-8].
基于字符串的方法提出了一系列将字符与机器学习相结合的处理技术,主要包括网页表示、降维、Web网页主题分类以及网页主题分类的评估,这些技术被用于实现自动网页分类系统、自动目录维护系统等.
基于语料库的方法提出了一系列将概率主题模型和机器学习、深度学习相结合的网页分类策略,这些策略可以提取潜在页面信息特征,提高了网页主题分类的准确性和可信度.
文献[9]在主题分类时加入了主题时间分布的因素,根据网页主题的流行趋势提出了E-LDA模型,该模型通过挖掘潜在语义对网页文本进行主题分类,并完成不同时间分布上的主题分析.
综上所述,近些年来研究人员已对网页主题分类和网页主题变迁进行了相关探索与研究,但是仍然存在一些局限,主要包括以下方面:
1)基于字符串的网页主题分类技术难以对网页文本中潜在的语义特征进行提取,致使提取的特征难以全面的刻画主题分布,从而导致主题分类发生偏移;
2)基于语料库的主题分类技术在提取特征时虽然考虑到了上下文之间的关系,但是在表示主题向量时使用了不可直接解释的密集向量,不能被直接用来计算网页变迁;
3)对于网页主题变迁的研究尚不成熟,评价标准也不完善,需要人工对处理结果进行评判.
鉴于以上分析,本文提出了一种整合时间维度和主题维度的策略,该策略在时间维度对网页文本集进行离散化,然后对离散时间窗口上的页面信息进行分析,挖掘潜在语义.该策略可以对页面潜在语义信息特征进行提取,自动聚合语义相似的页面,完成网页主题分类;分析各时间窗口上的主题分布,计算主题分布间的相似度,可以推算主题类型的变迁.
2 网页主题分类方法的设计
网页主题分类技术离不开文本信息处理,其中与本文最直接相关的是文本建模.所谓的文本建模是指,通过一系列技术将人类语言转化成计算机可以处理的形式[9],现阶段的文本建模主要包括概率主题模型(Probabilistic Topic Model,PTM)和向量空间模型(Vector Space Model,VSM).向量空间模型的优点在于其特征表示和权值计算可以根据具体情况进行调整,但该类模型忽略了词与词之间的关系,只能从词的表面进行分析,不能深入挖掘词的语义;概率主题模型是一种新的文本表示模型,能够挖掘出文本中的隐含主题,广泛应用于信息分类和检索领域.
本文在设计网页主题分类方法时,吸取了LDA主题模型的优势,扩展了Mikolov等人[10]的词向量模型,提出了一种适用于网页主题分类的Skip-PTM模型.Skip-PTM模型在Word2Vec的Skip-gram模型基础上建模,由原来的使用词向量预测上下文词转变为使用上下文向量来预测上下文词.上下文向量是指文本中一个词的表示不仅与周围词相关,还与文本集中所有的主题分布相关.如图1所示,在网页文本Webpagei中,词Wj的表示不仅与该文本中的周围词W1,W2,…,Wk相关,还与Webpagei所属的网页文本集WebpagesSet中所有的主题分布相关.
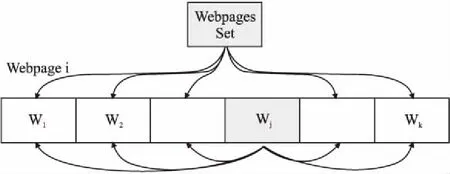
图1 词的表示过程示意图
Skip-PTM模型首先通过组合词向量和网页文本向量来构建上下文向量,其次基于上下文向量预测上下文词,最后得到主题及特征词.结构图如图2所示,该模型的训练结果是获得一组稀疏文本权重向量以及易于解释的网页主题矩阵.其中,网页文本权重向量代表不同主题向量的百分比,而网页主题矩阵由不同主题向量组成.

图2 Skip-PTM模型结构图
(1)

(2)

为了保证pjk的可解释性,这里采用Softmax的方式保证其和为1且非负,公式(3)给出了pjk的计算过程,由公式可知pjk的计算与Ld密切相关.
Ld=λ∑jk(a-1)logpjk
(3)
其中,λ用于控制损失函数的权重;a用于控制主题分布权重的稀疏性,当a>1时,训练出来的权重较为稀疏,主题分布趋于集中.为了增强模型的可解释性,这里取α=k-1,k表示主题的数量.
3 网页主题类型变迁的研究
网页主题类型变迁是指同一网站在连续的时间段中,网页的主题类型会随着时间的变化而发生变迁,这种变迁包含了主题的出现、发展与消失.Skip-PTM模型在处理网页主题分类时能够发挥有效的作用,但是在处理网页主题类型变迁时,则需要对该模型进行一些改变.本文在Skip-PTM模型上加入时间信息,根据一定的时间粒度,将网页文本集离散到时间窗口上,然后在独立的时间窗口中,通过Skip-PTM模型获取网页的主题变迁趋势.
如图3所示,本文通过将网页文本集离散到时间窗口{T1,T2…Tn}上,对每个时间窗口T上的网页文本集单独使用Skip-PTM建模,从而得到每个时间窗口上的主题向量{P1,P2…Pn},其中P是由若干主题相关度组成.Skip-PTM模型在主题-词分布获取过程中,继承了LDA模型中无先验知识的特点,使得初始的主题-词分布的生成过程主要依赖于Dirichlet分布参数β.由于Dirichlet分布中各分量间的弱相关性,所以主题-词的概率分布接近随机[13,14],而网页主题的分布在时间维度上是连续变化的,假设同一主题的特征在不同的时间窗口上变化不大,则在相邻的两个时间段内,同一主题的主题-词分布变化相对较小.

图3 增加时间信息的Skip-PTM模型
本文根据图4所示的先验概率估计来设置当前时间窗口的先验概率.在时间窗口T上,计算所有的主题相关度,若该窗口上的某一主题不是新主题,且该主题的相关度小于一定值,则删除其对应的词分布,该分布被标记为φtemp,如公式(4)所示.
φT=(φtemp|δ)
(4)
其中,δ表示通过随机抽样的主题-词分布,将φT扩展到Nt,Nt表示时间窗口t中的预估主题数.从特征词的分布φt中采样,生成词wk的多项式分布如公式(5)所示.
wk=multi(φt)
(5)
其他训练过程与Skip-PTM模型相同.
使用L表示Skip-PTM模型中的全局损失函数,该损失函数表示为Skip-gram负采样损失函数与Dirichlet似然下文本权重损失函数[15]的和,如公式(6)所示.
(6)

(7)
其中,cj,wi,wl,wj分别表示为上下文向量、预测目标词向量、负采样向量和中心词向量.
单独时间窗口上的Skip-PTM模型可以挖掘潜在语义信息、区分主题,并将网页主题聚类在指定的时间维度上.在时间窗口{T1,T2…Tn}上分别独立使用Skip-PTM模型训练各网页文本集,得到各时间窗口对应的主题向量{P1,P2…Pn}.由于主题向量{P1,P2…Pn}之间不具有明显的相关性,因此本文对训练后的主题向量进行处理,使用马尔可夫过程来分析主题变迁,发现新的主题.
利用马尔可夫过程[15,16]的思想,假设一个时间窗口内的主题分布只与前一个时间段内的主题分布相关.比较时间窗口Ti和时间窗口Ti+1内的主题分布,在主题分布中若两主题的相似度小于预定阈值,则认为这两个主题为同一主题;若时间窗口Ti中的主题与时间窗口Ti+1中的任何主题都不相似,则视为新的主题.
主题的表示是与词空间中词分布相关的[11],所以主题间的相似性可以转化为词空间中向量间的相似性,这里使用余弦距离作为相似度的计算公式,如公式(8)所示:
(8)
其中,Zr,Zs表示待比较的两个主题,wi表示主题中的词向量.为了计算网页文本的新主题的分布,我们假设该时间窗口上的主题-词分布是固定的,即负采样公式[17]是不变的,其余的过程与Skip-PTM模型训练过程相同,主要步骤如下:
1)参数初始化:为网页文本中的每个单词w指定一个主题标识z.
2)根据负采样公式对网页文本中每个单词的主题进行抽样,并对网页文本进行更新.
3)重复2),直到负采样收敛到一定的时间窗口.
4)计算网页文本的主题分布,即主题共现频率矩阵.
5)计算网页文本中前K个主题所占比例,如果这些主题的比例小于阈值Q,则认为该网页文本出现了新主题.
由于改进的Skip-PTM模型是按照时间窗口来划分网页文本集的,因此时间窗口长度的选择是模型的关键点.如果时间窗口长度太长,就很难发现新的主题,比如突发新闻.但是如果长度太短,时间窗口中的网页文本集可能不足以训练模型,为了解决这个问题,本文将长度设置为一个固定的值.
4 实验与分析
本文利用搜狗实验室语料数据和新闻数据进行实验,通过数据预处理得到以下格式的文档集:
在数据预处理基础之上进一步对数据格式进行清洗,本文使用Stanford CoreNLP对这些网页信息进行处理,处理内容包括删除特殊字符、去除标点和中文分词等工作.本文所有代码都是由Python编写的,运行在Ubuntu系统上.
Skip-PTM模型中网页信息聚类方法的核心部分是LDA模型,因此首先利用LDA来验证聚类分析的效果.Fan等[8]人利用搜狗实验室语料库中近8000条新闻数据进行实验,这些报道被手动标注为9个类别.在LDA模型中,设置主题数K=9,参数α=0.5,β=0.1进行1000次的迭代.在相同的数据集中,本使用Skip-PTM模型进行实验,取各自的实验结果中相似的五条主题-词分布作对比.
实验结果如表1所示,根据表中主题-词分布不难发现,主题分别代表教育、科技、旅游、经济、医疗.从分布中可以看出,Skip-PTM模型下的部分词权重有所变化,并且潜在的特征词也被挖掘出来.例如 “topic 3”中的“机票”作为“旅游”主题潜在特征也被挖掘出来.将实验结果与人工标注的结果进行比较,使用误报率(False Alarm Rate,FA)和漏检率(Missed Detection Rate,MD)作为模型结果的评价指标,其中误报率和漏检率的计算过程见公式(9)和公式(10).
表1 LDA模型和Skip-PTM模型下的主题-词分布比较
Table 1 Comparison of Topic-Word distribution between LDA model and Skip-PTM model

Topic1Topic2Topic3Topic4Topic5专业(0.014433)公司(0.018203)旅游(0.018122)市场(0.020114)医院(0.019543)学生(0.012514)技术(0.013301)游客(0.006070)国家(0.016701)患者(0.018360)大学(0.010961)企业(0.012376)北京(0.004961)发展(0.016653)治疗(0.012501)LDA模型学校(0.009819)创新(0.012092)城市(0.004882)经济(0.010572)吃(0.004848)考生(0.009687)产品(0.008412)旅行社(0.004088)中国(0.006540)病人(0.004676)教育(0.009314)网络(0.006893)酒店(0.003744)企业(0.005124)出现(0.004498)工作(0.009141)科学(0.006476)游(0.003693)问题(0.004914)药(0.004188)职业(0.006145)业务(0.005580)中国(0.003643)政府(0.004694)疾病(0.004030)学生(0.014673)创新(0.017639)旅游(0.017491)市场(0.019044)医院(0.017369)专业(0.014528)公司(0.016955)游客(0.008657)经济(0.017120)治疗(0.015742)学校(0.012116)企业(0.014954)机票(0.008350)建设(0.016225)患者(0.015262)Skip-PTM模型大学(0.011965)产品(0.011923)城市(0.005672)企业(0.010452)病(0.004916)课程(0.009531)科技(0.010358)旅行(0.004588)财政(0.008797)病人(0.004825)教育(0.009093)科学(0.009347)酒店(0.003938)政府(0.005246)专科(0.004751)考试(0.007644)发展(0.007809)客栈(0.003184)问题(0.004242)药(0.004338)学历(0.006924)方法(0.005858)团购(0.003007)公司(0.003911)医护(0.004113)
FA=FP/(TP+FP)
(9)
MD=FN/(TP+FN)
(10)
其中FP表示把非主题错误检测为正确主题的数量;FN表示把正确主题检测为错误主题的数量;TP表示正确检测主题的数量.
误报率反映了检测器检测到的某类别目标中,误检目标数量所占比例;漏检率则反映了遗漏检测目标数量所占比例.误报率和漏检率的对比图分别如图5和图6所示,从这两个比较图中可以发现,Skip-PTM模型的主题分类效果比LDA模型效果有所提高,但由于Skip-PTM模型是由LDA模型改进而来,所以实验结果继承了LDA模型的分布趋势.
目前,关于新主题发现与主题类型变迁的评价标准尚不完善,只能依靠人工来处理.本文从中国的各大门户网站上抓取了500多篇文章和最近热门主题的评论.这些材料从2019年6月到10月,分为五个时间段,每个时间段一个月,计算后得到的主题分布如表2所示,表中列出了“5G”和“贸易战”的相关词汇.
根据同一主题在不同时间段的词汇分布,可以看出主题的发展趋势.例如,在“5G”的主题上,焦点从6月的“5G牌照的发放”变迁到10月的“5G套餐的发布”,其中,词汇分布上第一个词“5G”表示了主题,其他词表示了主题的发展;在“贸易战”的主题上,焦点从6月的“特朗普提出了加征关税”发展到7、8月份的“贸易谈判与升级”,最后到10月份的“重回正轨”,其中词汇分布上“中美”、“贸易”是表示了主题,其他词汇表示了主题的变迁.
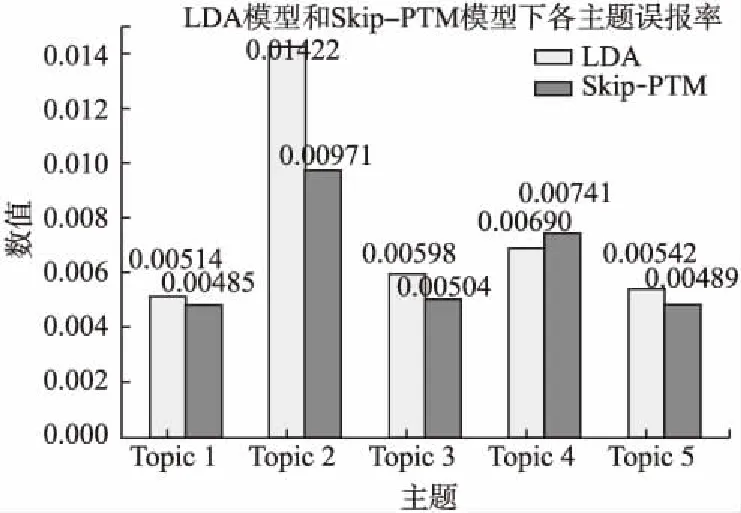
图5 误报率比较图

图6 漏检率比较图
本文计算了每个时间窗口上五个主题所占比的值,从而得到了如图7所示的变迁趋势图,图中可以发现一些可解释的现象:“英国脱欧”主题在十月份热度回升,对应于最近的英国脱欧再次延期;“区块链”主题在十月份出现阶梯式上升,对应于最近国家提出的“把区块链作为核心技术自主创新重要突破口”相关政策.
表2 “5G”和“贸易战”的相关词汇表
Table 2 “5G”and “trade war” related words

六月七月八月九月十月5G5G5G5G5G商用商用通信基站手机工信部芯片手机通信套餐5G芯片通信芯片手机网络通信物联网电信电信移动终端终端首款芯片营业厅基站基站元年终端终端中美中美中美中美中美贸易贸易贸易贸易贸易特朗普刘鹤特朗普新一轮谈判贸易战关税重启股市关税特朗普逆差经济关税特朗普磋商出口特朗普谈判反制重回经济谈判升级磋商推迟
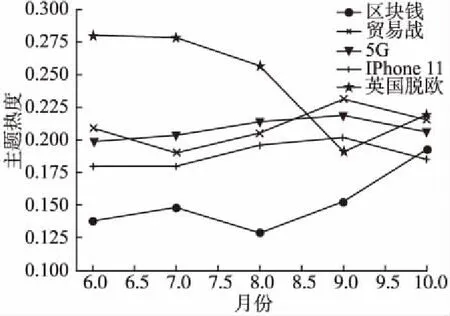
图7 主题变迁趋势图
5 总 结
本文结合LDA模型和Word2Vce中Skip-gram模型优势,提出了一种适用于网页主题分类的Skip-PTM模型,该模型能够挖掘网页信息隐含语义,实现网页主题分类.针对网页主题类型实时变迁的问题,本文改进了Skip-PTM模型,将网页文本集离散到不同的时间窗口,在各时间窗口上使用Skip-PTM模型独立建模,分析各时间窗口上各主题相似度,实现网页主题类型变迁的研究.实验表明,该模型能够有效地聚类语义相关的页面信息,实现网页主题分类,完成主题类型变迁的分析与研究.针对网页主题分类变迁的应用可以涉及多个领域,例如,通过用户浏览页面变化,可以掌握用户在一段时间内的兴趣转变,这种转变可以提高运营商主动服务推送的准确性.
在未来的工作中,将继续对挖掘出来的网页类型变迁趋势做进一步的分析,力求获得较高的实用性价值.
