Fast-PPO:最优基线法的近端策略优化算法
2020-07-13陈佳黎刘保生杨郭镳
肖 竹,谢 宁,陈佳黎,刘保生,姜 峰,杨郭镳
(电子科技大学 未来媒体中心 计算机科学与工程学院,成都 611731)
1 引 言
最近,针对强化学习(RL)提出了几种不同的神经网络函数逼近算法[1,2].主要的常用算法有深度Q学习[3,4],Vanilla策略梯度(PG)[5],信任区域策略梯度(TRPO)[6]和近端策略优化算法[7].Q学习算法[8,9]可以很好地应用在动作离散的学习环境中,但不能在动作连续控制的基础上表现良好.Vanilla策略梯度方法在数据效率和鲁棒性方面都较差.信任区域策略梯度算法[6]相对复杂,与包含噪声或参数共享的架构不兼容.近端策略优化算法使用惩罚来改进过大的优化,在信任区域策略梯度算法方法的基础上获得更好的采样复杂性[10].
由于近端策略优化算法是一种新的强化学习的策略梯度(PG)方法[11],因此可以采用提高策略梯度方法效率的手段来改进近端策略优化算法,包括基于参数的探索和最佳基线[12],我们选择使用最佳基线来提高效率.我们的想法启发于最先进的策略梯度方法、策略梯度和基于参数的勘探(PGPE)以及最佳基线减分(将方差正则化技术与基于参数的勘探和最佳基线相结合)[12].在实践中,在策略梯度方法中使用了最佳基线,从经验上帮助发现策略更新的正确方向.
NPC(Non-Player Character)行为的传统做法是通过脚本或行为树来操纵的.冗长的规则表通过分析NPC周围环境的信息来确定其下一个行为.然而,随着游戏的更新、设计和维护,调整这些规则表是非常耗时的.就最近强化学习算法的实际应用而言,强化学习与神经网络的结合[13]广泛应用于NPC在视频游戏中的智能决策,通过在NPC达到其预期目标时提供奖励来训练,并非手动定义观察到的动作图.例如,Wu和Tian[14]将卷积神经网络(CNN)部署到A3C中,在部分可观测的3D环境中训练一个智能对象,从最近的四个原始帧和游戏变量中,根据课程学习[15]的方法,从简单的任务开始,逐步过渡到更难的任务,预测下一步行动和价值函数.
因此,我们将提出的强化学习算法用来控制NPC在游戏中的行为,以证明我们提出的方法比其他方法更有效.实验分为三个阶段.第一阶段,四个强化学习算法(Fast-PPO、PPO[7]、PG[16]、R-PGPEOB[17])都在同一个游戏中使用.我们可以看到,无论环境是离散空间还是连续空间,Fast-PPO和PPO算法都是有效的.但PG和PGPE只能用于连续空间.在第二阶段,我们设计了一个网球赛,Fast-PPO和PPO控制两个球拍.我们提出的Fast-PPO算法控制的球拍可以获得比其他算法更高的分数.因为,Fast-PPO比PPO具有更快的收敛速度和更高的回报.第三阶段,采用Fast-PPO算法训练一只狗获取一根木棍,证明了我们提出的强化学习算法的通用性.
2 预备知识
2.1 策略梯度法
策略梯度法[11]通过计算策略梯度的估计量并将其插入随机梯度上升算法来工作.策略梯度(PG)算法可以学习随机策略,设计策略的目标函数,通过梯度下降算法对参数进行优化,最后进行奖励.假设轨迹为τ=(s0,a0,r0,…,sT-1,aT-1,rT-1),at是当前动作,st是当前状态,这是一个完整的事件状态、行动和奖励,通常的策略梯度算子形式如下:
JPG=t[R]
(1)

θJPG=t[θlogπθ(at|st)R]
(2)
2.2 正则化策略梯度法
当总回报R较大时,轨迹τ的发生概率增加,当总回报R较小时,轨迹τ的发生概率减小.同时为了进一步减小梯度估计的方差,赵婷婷等人[17]提出正则化策略梯度算法R-PGPEOB,策略梯度的形式为:
(3)
V(θ)=Varθ[Rθlogπθ(at|st)]
(4)
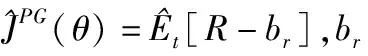
2.3 近端策略优化算法
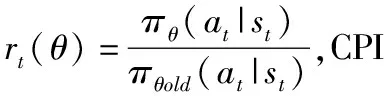
(5)
LCPI(θ)=t[min(rt(θ)t,clip(rt(θ),1-ε,1+ε)t)]
(6)
其中epsilon是一个超参数.min中的第一项是LCPI.第二项,clip(rt(θ),1-ε,1+ε)t通过削减概率比来修改代理目标,这消除了在区间[1-ε,1+ε]的影响.最后,取剪切和未剪切目标中的最小值,最终目标函数是未剪切目标的下限.
3 提出的快速PPO算法
如前一节所述,PPO算法是PG算法的一个变种.虽然PPO算法对策略的更新是有效的,但我们认为PPO算法对策略更新的限制过强,不仅采用rt(θ)来防止策略更新过快,还采用clip函数进一步控制策略的更新速度.根据该方法[17],基线减分能够提高PG算法的效率.因为基线的使用有助于从经验上找到策略更新的正确方向,从而提高PG算法的效率.因此,我们提出了一种具有最佳基线的PPO方法(Fast-PPO),它结合了PPO算法的优点和最佳基线方法的优点.
3.1 基线减法的策略梯度
Fast-PPO算法中的梯度估计可以通过减去基线bA进一步稳定:
(7)
根据方法[6,17]中使用的优势函数,计算出最佳基线如下:
(8)
其中Var表示协方差矩阵的轨迹,即:
A=(A1,A2,…,Al)T
Varθ[A]=tr(Eθ[(A-Eθ[A])(A-Eθ[A])T])
(9)
3.2 基于最佳基线DPG方法的拓展
在Zhao的方法中[17],梯度更新使用随机梯度下降方法.随机梯度下降算法[21]每次从训练集中随机选择一个样本来学习.
随机梯度下降算法一次只随机选取一个样本来更新模型的参数,因此每次运行都非常快速,可以在线更新.最大随机梯度下降的缺点是,不是每个更新都会朝正确的方向进行,从而产生优化方差.
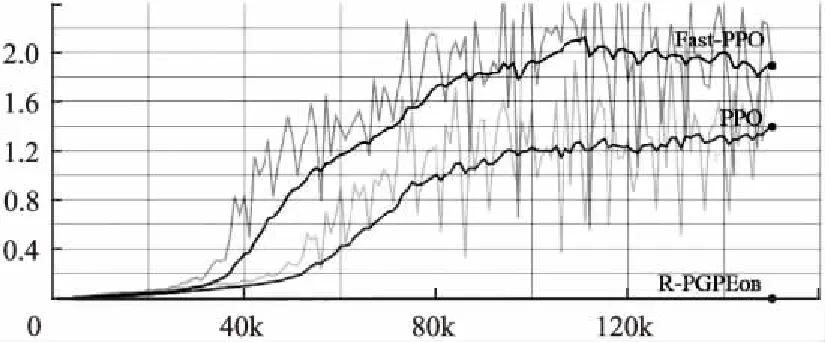
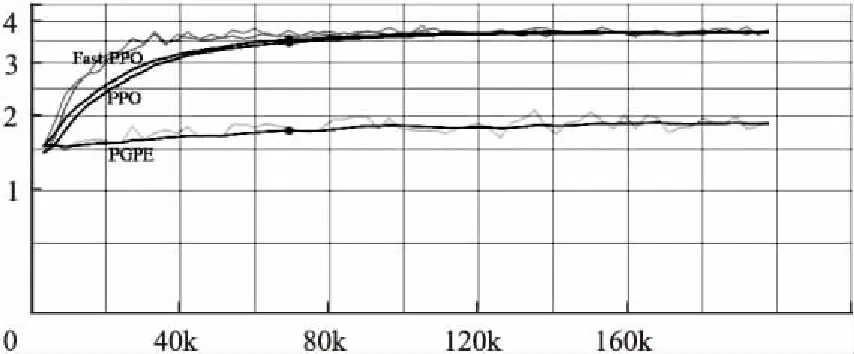
因此,在快速PPO算法中,我们使用小批量梯度方法[22]来降低小批量梯度,以将批量梯度和随机梯度结合起来.在更新速度和更新次数之间取得平衡.每次更新都从训练集中随机选择m(m θ=θ-η·LPG(θ;xi:i+m;yi:i+m) (10) 与随机梯度下降相比,小批量梯度降低了收敛波动性,降低了参数更新的方差,使参数更新更加稳定. 利用小批量的思想,我们可以解出bA的方程(9),给出快速PPO的最佳基线: (11) 其中: (12) 现在我们来简化公式‖▽θlogπi(θ)‖2: 令: (13) 于是: ▽θlogπi(θ)=E-P (*)(14) 因此, ‖▽θlogπi(θ)‖2=trace((*)2)=trace(E-2P+PPT) (15) 然后我们可以将等式(15)简化为: trace((*)2)=trace(E-2P+PPT) =trace(E)-2trace(P)+trace(PPT) (16) Actor-Critic(AC)框架算法[23]可用于解决连续运动空间中的DRL问题.但是AC有两个网络(actor和critic)需要训练,因此它需要分别优化这两组权重.Critic网络计算当前状态下某个操作的得分Q,Actor网络使用该Q值更新其自己的策略权重.然而,基于价值函数的方法训练波动较大. 为了缓解这个问题,A3C定义了一个优势函数,它给出了与当前状态相比的平均动作(动作值函数)的优势值.考虑到使用在策略和价值函数之间共享参数的神经网络结构的想法,我们提出了一个损失函数,可用于结合策略替代项和价值函数误差项[7]. 如果使用共享策略函数和价值函数参数[7]的神经网络架构,损失函数则可以组合上述目标函数以及价值函数的误差项[24].同时也可以通过添加熵奖励来确保充分的探索.我们通过结合这几项,获得以下损失函数方程,如下所示: (17) 在整个Fast-PPO算法的每次迭代中,通过执行当前策略来估计目标函数,然后通过轮流优化目标函数来更新策略参数. PG方法中的每一次更新都应该增加那些优于平均值的操作的概率,同时减少那些低于平均值的操作的概率.但其方差很高,因此提出了AC算法[26],用一个值函数代替经验收益作为偏差来减少方差.但实际上,John Schulman[20]主要讨论了GAE(广义优势估计)方法,该方法大大减少了方差,确保了控制偏差的前提.使用的GAE估计量是: (18) 其中t在给定的长度T轨迹段内以[0,T]指定时间指数.概括这一选择,使用广义优势估计的截短版本[20],当λ=1时,可简化方程(17)为: t=δt+(γλ)δt+1+…+…+(γλ)T-t+1δT-1 (19) 其中: δt=rt+γV(st+1)-V(st) (20) 算法 1.Fast-PPO,Actor-Critic Style foriteration=1,2,…do foractor=1,2,…,Ndo 在环境中,T时间步骤内,运行策略πθold 从整体而言,“师傅型”师资的职业职责有:①了解学徒的发展规律;②熟悉合作企业的典型职业工作和企业实际操作流程;③开发、设计、制定以工作过程行动导向的培训计划;④从事培训准备、培训实施、培训考核指导等工作;⑤促进学徒学习,引领学徒职业素养形成,传承企业文化;⑥为学徒提供职业发展咨询、服务。具体需要具备以下素质: endfor 在Kepochs中,令Mini-batchM的大小:M≤NT,优化含θ的L目标函数 θold←θ endfor 在本节中,我们通过与原始PPO算法的比较,实验评估了我们提出的方法的效率.我们使用一个新的开源工具包,使用Unity平台创建模拟环境并与之交互:Unity ML-Agents Toolkit.通过将Unity作为仿真平台,该工具包可以开发具有丰富的感官和物理复杂性的学习环境,提供引人注目的认知挑战并支持动态多代理交互. 基于ML-Agents,NPC通过相机获取的状态信息可以发送到Python的训练模型,并且通过图像识别来提取图像中的参数信息.例如,障碍物的分类,到目标的距离,自身和目标的相对位置以及运动方向的判断,这些信息被发送到训练模型,并且模型输出的命令被发送回NPC,从而控制NPC在虚拟游戏环境中的动作.训练架构如图1所示. 图1 训练架构图 在这一部分,我们将Hallway,Banana和3DBall作为培训agent的环境.这三种环境分为两类.一个是离散的空间,包括Hallway和Banana,另一个连续的空间是3DBall.结果如图2所示. 这些任务的目标如表1所示.它们的训练参数设置如下: HallwayBrain: 序列长度:64; num layers:2; hidden units:128;memory size:256; beta:1.0e-2; gamma:0.99; num epoch:3; buffer size:1024; 批量大小:128; 最大步数:5.0e5. BananaBrain: 批量大小:1024; beta:5.0e3; buffer size:10240;最大步数:1.5e5. 3DBallBrain: 批量大小:64; buffer size:12000; lambd:0.99; gamma:0.995; beta:0.001. 表1 任务及其目标 Table 1 Tasks and their goals 任务空间目 标Hallway离散移动到与房间中方块的颜色相对应的目标Banana离散尽量多吃黄香蕉,同时避免吃到蓝香蕉3DBall连续为了尽可能长时间地保持球在平台上的平衡 图2 任务场景和奖励(从左到右、从上到下分别是Hallway、Banana和3DBall) 从上述任务的奖励曲线可以看出,在Hallway任务中,Fast-PPO在200,000次收敛到0.6,PPO在450,000次收敛到0.4,R-PGPEOB算法甚至无法完成此任务.与PPO算法相比,Fast-PPO可以在此任务中将速度提高1倍以上,并且Fast-PPO的奖励也是1.5倍.我们相信更高的奖励可以让代理商更好地完成任务.在Banana实验中,Fast-PPO和PPO具有相同的收敛趋势,但Fast-PPO收敛的收益率为13,大于PPO收敛的回报率为12.R-PGPEOB早期跌入局部最大值,无法从环境中学习.在3DBall任务中,Fast-PPO和PPO也具有相同的收敛趋势,但仔细观察,Fast-PPO比PPO更稳定,即标准差更小.R-PGPEOB在800,000次达到局部最大值,再也无法继续从环境中学习.根据这三个实验的结果,我们可以得出结论R-PGPEOB算法可以在连续的空间中应用,但是非常有限并且容易陷入局部最大值.此外,它们在离散空间中表现极其不好.然而,Fast-PPO和PPO不仅可以在连续空间中有效地应用,而且可以在离散空间中有效地应用.另外,无论环境是否离散或者连续,Fast-PPO都有最高的回报. Fast-PPO和PPO都可以通过几场比赛来控制NPC的行为.为了直观地比较Fast-PPO和PPO的效率,我们使用Unity Machine Learning Agent Toolkit中的网球游戏作为培训智能代理的环境.然后我们使用上述方法分别训练代理的行为.每种方法的表现都是通过超过2万次运行的回报和损失来衡量的.虽然我们只是展示了网球训练的结果(在网球环境中训练球拍的过程如图3所示),但我们还是做了更多的工作来说明我们的方法(Fast-PPO)能够有效地训练NPC在各种动作游戏中的行为. 每种方法的表现都是通过累积奖励和策略损失来衡量的.对于我们的方法,我们设置超参数γ= 0.99,λ= 0.95,c1= 0.5,自学习参数β使用Tensor流的多项式衰减方法,初始值为0.05.同时,策略参数在每次迭代中迭代超过200000次.在每次迭代中,我们收集了1024个样本用于批处理.结果如图4所示. 可以清楚地看到,我们的方法具有更大的累积奖励.此外,PG和R-PGPEOB已陷入600000次死锁,不再向环境中学习.因此,证明了我们提出的方法比PPO方法和其他算法更有效. 在通过我们提出的方法(Fast-PPO)和其他算法训练代理之后,我们获得存储为.byte文件的策略,该文件可以用作Unity中的大脑来控制代理的行为.为了更直观地观察Fast-PPO和其他算法的性能,我们设计了网球游戏.这两种方法用于控制两个网球拍.从上面的实验中,我们可以看出PPO是唯一可以与Fast-PPO一战高下的算法.所以我们使用经过训练的PPO算法和Fast-PPO算法来控制各种球拍并执行网球比赛.代理人的目标是他们必须在彼此之间反弹球而不丢球或将球送出界外. 图3 网球比赛的过程 图4 Fast-PPO和其他算法的奖励比较 通过数千万次运行,我们获得了两个对手的分数,如图5所示.事实上,这场比赛不符合网球比赛的规则.因为在这项任务中,即使一方失去了分数,游戏仍然会继续.我们只想收集由PPO和Fast-PPO算法控制的AI分数.然而,我们可以保证Fast-PPO的得分总是高于PPO,这意味着用Fast-PPO方法训练的大脑比用PPO方法训练的大脑更有效.因此有理由相信我们提出的方法(Fast-PPO)是一种更好的方法来训练NPC的动作游戏. 图5 Fast-PPO和PPO之间的得分比较 为了证明我们提出的Fast-PPO算法的普遍性,本部分进行了更为复杂的训练任务.实际上,使用强化学习训练NPC的过程与训练幼犬的方式非常相似.我们将向小狗展示一根棍子然后扔出棍子.起初,小狗会四处游荡,不知道该做什么,直到它最终拿起木棍并将其带回来,并获得零食作为奖励.经过几次训练后,小狗知道获得回击的策略是获得奖励的最佳方式,然后继续这样做.这是如何加强NPC行为学习的过程.每当NPC正确完成任务时,我们都会给NPC一个奖励.通过多次模拟游戏,NPC构建了一个内部模型,以最大化奖励并实现所需的行为.因此,我们不必为每次观察NPC创建和维持低级别的行动.我们只需要在任务正确完成时提供高级奖励,然后NPC就可以学习适当的低级行为.每次Corgi执行动作时,我们都会向代理提供奖励,奖励设置为: (21) 图6 Corgi捡木棍的过程 训练Corgi有以下四条规则: ·获得奖励:当柯基犬走向目标时,我们会给予奖励. ·时间惩罚:我们将给予Corgi每项行动的定额罚款.通过这种方式,Corgi将学会尽快检索棍子并避免过多的时间惩罚. ·轮换罚分:如果Corgi旋转太多次,将受到惩罚.实际上,如果小狗变得太多,它就会晕眩.为了让游戏更加逼真,Corgi在转弯过快时会受到惩罚. ·目标奖励:Corgi到达目标位置时会获得奖励. 使用Fast-PPO和其他算法的训练犬的结果如图7所示.训练之后,byte文件用于控制Corgi的行为.获取木棍的过程如图6所示.它显示了使用Fast-PPO训练的Corgi完成棺材棒的任务.我们可以清楚地看到,柯基犬正朝着目标稳步前进,并且很好地完成了这项任务. 图7 柯基犬的奖励图 在本文中,我们提出了一种新的方法,即具有最佳基线的Fast-PPO,与PPO算法相比,它有助于提高正确方向的策略更新速度.通过比较奖励,我们提出的方法(Fast-PPO)通过实验证明了具有比主流强化学习算法更好的性能.从理论上讲,我们提出的方法比其他强化学习算法具有更高的回报和更快的收敛速度.此外,以Unity中的环境为例,应用Fast-PPO算法,无论环境是连续的还是离散的,所有结果都表明了Fast-PPO算法在游戏中控制NPC的良好性能.3.3 Fast-PPO中A2C的结构

4 实 验

4.1 任务中RL算法的比较


4.2 Fast-PPO和PPO在网球中的比较


4.3 在Corgi中应用Fast-PPO


5 结 论
