S-C 特征提取的计算机漏洞自动分类算法*
2020-07-10任家东李亚洲刘佳新
任家东,王 倩+,王 菲,李亚洲,刘佳新
1.燕山大学 信息科学与工程学院,河北 秦皇岛066001
2.河北省计算机虚拟技术与系统集成实验室,河北 秦皇岛066001
1 引言
计算机网络技术的迅猛发展,使得计算机网络在经济生产、社会生活、教育、科技、国防等领域发挥着极其重要的作用。网络在为人们带来诸多便利的同时,也随之产生了一系列的安全问题,如恶意攻击、盗窃机密数据、种植病毒等。通过网络漏洞进行网络攻击是攻击者最常采用的手段之一,不仅会对大众的生活产生严重的影响,威胁人们的信息安全、财产安全,甚至会泄漏国家机密等,严重危害国家安全。近年来新发现的未知漏洞数量相比过去增长迅速,根据国家信息安全漏洞库数据(China National Vulnerability Database,CNNVD),网址为http://www.cnnvd.org.cn/,2018 年每个月平均发现未知漏洞多达2 013 个。当网络管理者发现未知的漏洞时,需要整合漏洞信息以邮件的方式提交到国家信息安全漏洞库,再由工作人员进行漏洞分析,若干个工作日后才可以将漏洞的类别、危害值等信息发布在漏洞平台。这不仅会给工作人员造成巨大的工作量,更重要的是无法及时获取未知漏洞的类型及危险值,进而无法采取防护措施。面对海量增长的漏洞,如何对新发现的未知漏洞进行及时有效的分析和管理,是十分重要且有待解决的问题。低效率的人工分类方法已无法满足目前的需求,漏洞自动化分类成为漏洞相关研究的重点。
目前,机器学习算法被大量应用在文本数据的研究中[1-2],如分析文档数据的相似度、文本的语义以及情感态度等。比如,Baharum等人总结了机器学习在文本分类领域的研究进展[3],并探讨了在处理文本分类中所遇常见问题的可能解决方法,肯定了这项技术未来的发展。在计算机漏洞描述的文本信息中,也包含了大量关于漏洞特征的信息,因此很多研究者利用机器学习的方法,对漏洞文本进行有效的分析,从而实现对漏洞的自动分类,并取得了进展。Li 等人提出了一种基于漏洞特征包括错误、资源的积累消费、严格的时间要求和复杂的环境与软件之间的互动的软件漏洞分类方法[4]。Gawron 等人提出了基于机器学习的漏洞分类方法[5],该方法中应用了文本预处理技术对漏洞文本进行预处理,分别介绍和构建了基于朴素贝叶斯和神经网络的漏洞分类器,评估了机器学习算法在漏洞分类上的可行性。Shuai 等人提出了一种基于隐含狄利克雷分布模型(latent Dirichlet allocation,LDA)和支持向量机算法(support vector machine,SVM)的漏洞自动分类器[6],该方法将单词位置信息引入加权位置LDA 模型(weighted location LDA,WL-LDA)中,通过在主题之外生成向量空间,然后再构建基于漏洞分布的HTSVM(Huffman tree SVM)多分类器;在美国国家通用漏洞数据库(National Vulnerability Database,NVD)上进行实验,实验表明该方法可以获得更高的分类精度和效率。Davari 等人提出了一种基于激活漏洞条件的自动漏洞分类框架[7],使用不同的机器学习技术,来构建具有最高F-度量的分类器,以标记未知漏洞。基于漏洞之间相关性的漏洞分类方法被Zhang等人提出[8]。该方法是基于词频-逆文本频率(term frequency-inverse document frequency,TFIDF)和贝叶斯算法的漏洞自动分类模型,在Linux漏洞数据上进行实验,实验结果表明了该方法的有效性,使用这种方法能有效分析漏洞之间的相关性并将漏洞进行分类。
这些机器学习分类算法在许多领域取得了很好的效果,而且许多研究人员已经验证了机器学习算法在漏洞分类领域的有效性。但由于漏洞的描述信息为短文本,漏洞的数量和种类又较多,使得漏洞特征词的提取变得困难,以至漏洞分类效果的提升并不明显。因此本文提出的S-C特征提取方法,通过结合词语的类间重要程度和类内重要程度的综合函数C,计算出词语对于类别的重要程度。再利用词语对于类别间的信息熵S,来弱化对于分类较为混乱的词语的重要程度。最终选取得到较好的特征词集。并利用关联了特征词集间相互关系的平均一阶依赖贝叶斯模型(averaged one-dependence estimators,AODE)对漏洞数据集进行分类。使用美国国家漏洞数据库(National Vulnerability Database,NVD)中的文本数据进行训练模型和测试,网址为http://nvd.nist.gov/。实验显示,本文构建的漏洞自动分类模型能有效提高漏洞分类性能。
2 基于熵改进的S-C 特征提取方法
数据预处理是对数据分析的第一步。图1 是数据预处理流程图。首先,对漏洞数据进行获取,提取有效字段;其次,对描述漏洞的文本进行分词操作,去除停用词以减少数据冗余;再次,利用基于熵改进的S-C算法提取特征词;最后,通过特征集合建立样本的词语向量,完成漏洞文本数据预处理。

Fig.1 Data preprocessing flow chart图1 数据预处理流程图
2.1 数据的获取
目前的漏洞数据库主要是结构化的漏洞数据库,结构化漏洞库中的漏洞数据具有统一的格式,以统一格式收集、存储和发布。主要包括:美国国家漏洞数据库NVD、开源漏洞数据库(Open Source Vulnerability Database,OSVDB)和中国国家漏洞数据库CNNVD。中国国家信息安全漏洞库将漏洞分为SQL(structured query language)注入、资源管理错误、数字错误、缓冲区溢出等26个类别,实现了对漏洞的分类化管理。本文以国际公认的美国国家计算机通用漏洞数据库NVD 中的descript 漏洞描述字段作为实验数据。并依据中国国家漏洞数据库CNNVD 中的漏洞类别,根据NVD 与CNNVD 中每条漏洞的CVE(common vulnerabilities&exposures)编号,确定漏洞的漏洞类型,完成漏洞数据的获取。
2.2 数据的特征提取
文本特征提取[9]是指基于一定的评估标准,从漏洞文本描述的词语中,选择出能够有效描述漏洞的类别信息的关键词。由于本文分析的数据是文本类型的数据,在对漏洞进行分词后,产生了大量的词语,多达6万多个。这使得漏洞样本在向量化时产生了巨大维度的向量,在后续利用机器学习算法进行文本挖掘时,效率以及准确率变得异常低下。因此要对文本样本进行特征词的提取,选出对分类贡献较高的词语,作为样本的特征。通过特征词选取,可大大降低漏洞特征的向量维度,节省时间和空间资源,提高分类器的准确率和效率。本文通过分析漏洞样本文本的特征,定义了综合函数C来表示词语对于类别的重要程度,并结合信息熵S最终确定出S-C算法来提取数据集的特征集。
2.2.1 综合函数C
一个词语对于类别的重要程度,通过两方面确定。一方面是词语对于类别内部的重要程度,词语在本类中出现的文档数越多,并且分布得越均匀,说明这个词语能够很好地代表本类。但若某个词语在其他多数类别中,都很频繁地出现,则也不能很好地代表本类漏洞。因此另一方面,是词语在类间重要程度,若词语在本类出现的频率大于在全部样本中出现的频率,说明这个词语可以更好地代表本类漏洞,通过这两方面确立出综合函数C。以下给出公式中用到的符号说明以及相关定义:N表示漏洞样本的总数量;Di表示类别i的漏洞样本数量;dit表示类别i中词语t出现的漏洞样本数量;ft表示词语t出现的频数;fit表示类别i中词语t出现的频数;pit=表示在类别i中词语t的平均分布频数;pt=表示在总样本中词语t的平均分布频数。
定义1(类内重要程度I)若词语t在第i类漏洞中频繁出现,且均匀分布在各个漏洞上,则说明词语t对i类内的重要程度越高,对于漏洞类别i的判定有着更加重要的意义。公式如下:

定义2(类间重要程度E)若词语t在第i类漏洞中的分布频数大于词语t在总样本中分布频数,则认为词语t对第i类别有着比对其他类别更重要的意义。公式如下:

定义3(综合函数C)代表词语t对于类别i的重要程度,由类间重要程度与类内重要程度相乘得出。公式如下:

2.2.2 S-C 特征提取算法
在选取漏洞特征词时,是根据词语对分类的重要程度的值来选取,但是由于特征词和漏洞类别之间不是非此即彼的关系,即同一特征词可能对多个类别都表现出具有重要的意义。此时若依旧选取此词语作为关键词,则会对分类的效果产生负面影响。为了解决这一问题,引入信息熵来弱化这些词语的重要程度。使用信息熵S与综合函数C相结合的方式,应用于特征提取上。
定义4(信息熵[10])用于信息论中,是度量信息量大小的一个概念。越是有序的系统,信息熵越低;相反,越是混乱的系统,信息熵就越高。因此,也用信息熵来度量系统有序化的程度。其公式如下:

定义5(特征词t的信息熵S(t))表示特征词t隶属类别的混乱程度。S(t)越大,表示特征词t越无法较好地区分出类别。n表示漏洞类别数,公式如下:

定义6(特征词的S-C值)表示利用S-C算法计算出的特征词t对于类别i的重要程度值。公式如下:

算法1S-C特征提取算法

3 基于AODE的漏洞分类算法
目前有大量的机器学习模型以及算法应用于文本分类的研究中,大量学者将贝叶斯分类器运用到文本分类的领域中。贝叶斯是一种结构简单且分类效率高的分类技术,在应用于某些领域的分类问题中能够与决策树、神经网络相媲美,且运行效率很高。贝叶斯分类器的原理,是根据样本的先验概率以及条件概率,计算出待分样本的后验概率。由于不是将样本绝对地分给某一类,而是通过计算待分样本的后验概率,去确定样本的类别,具有最大概率的类就是待分样本所属的类别。这在理论上保证了分类器具有最小概率误差。因此贝叶斯分类器非常适用于处理多分类问题。考虑到本文研究数据集的特征,由于漏洞分类是多分类问题,且数据量庞大,为了保证准确率以及运行效率,本文选取贝叶斯分类器作为研究对象。
3.1 朴素贝叶斯分类模型
朴素贝叶斯分类模型(naive Bayes classifier,NB)[11]的核心是具有条件独立性假设,也就是每一个属性独立地对分类结果发生影响。这样的假设降低了模型计算过程的复杂性,从而大大提高了分类的效率。朴素贝叶斯分类模型的原理,是根据样本中类别ci的先验概率p(ci)和类别ci与样本X的条件概率p(X|ci),计算出后验概率p(ci|X),选择后验概率最大的类别即为样本所属类别。
假设数据集D={(X1,X2,…,Xm,ci),…},其中X={X1,X2,…,Xm}为某一个样本的特征向量,ci为此样本所属类别。在对一条未知类别的样本x={x1,x2,…,xm}进行分类时,选取p(ci|x)最大的ci作为其所属的类别。计算公式如下所示:
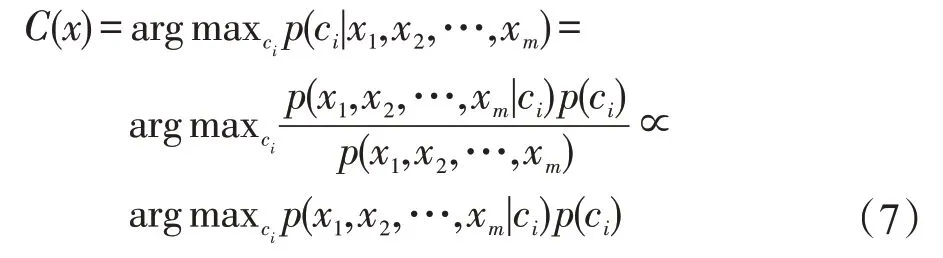
由于朴素贝叶斯分类模型的条件独立性假设,计算公式简化为:

3.2 平均一阶依赖贝叶斯模型
朴素贝叶斯的条件独立假设,假定了属性之间是相互独立的,即词与词之间不存在任何依赖关系。显然,这样的独立性假设在实际的漏洞描述文本中是不成立的。在有些类别中,多个词语经常同时出现,因此不能忽略词语之间的依赖关系。本文使用朴素贝叶斯的改进算法——平均一阶依赖贝叶斯模型(AODE)[12]来对漏洞进行分类。AODE 的分类准确度要优于朴素贝叶斯,这主要得力于其自身的集成学习机制。AODE 是一个集成的一阶依赖贝叶斯模型,在其每一个子模型中,令所有特征词都依赖于同一个特征词节点,即超父节点,每一个特征词都轮流做一遍超父节点。这样就关联了所有特征词之间的关系,改善了朴素贝叶斯中认为每一个特征词都相互独立的缺点。
AODE分类器中有两个公共的父节点,除了类别节点作为父节点外,每个特征词节点都会轮流作为其他剩余特征词节点的父节点。若样本的特征向量中,有m个特征,AODE分类器就会形成m个分类器子模型,其中每一个子分类器结构都是一个1-依赖分类器,最终将这些1-依赖分类器进行平均。假设给定一个具有4 个特征值的样本集D={(X1,X2,X3,X4),(X1,X2,X3,X4)…},其AODE分类器中的4个子分类器如图2 所示,4 个子分类器分别以类别和一个特征词节点作为父节点。

Fig.2 AODE submodel diagram图2 AODE子模型图
具有m个特征{x1,x2,…,xm},n个类别的数据集,共构成m个子模型。子模型的后验概率计算公式如下:

接下来对子模型求平均值,选择后验概率最大的类别作为样本所属类别,AODE 分类器计算公式如下:
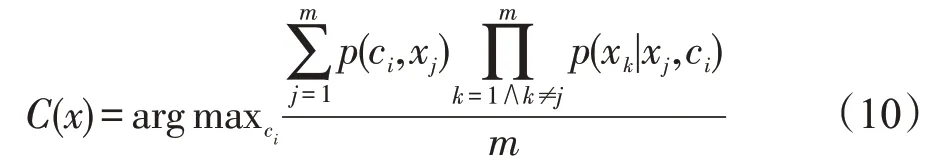
算法2AODE漏洞分类器算法
输入:漏洞训练数据集D={X1,X2,…,Xm},漏洞测试数据集X。
输出:每个漏洞测试样本的类别C(X)。
步骤1轮流使每个特征词节点作为父节点,构造m个1-依赖分类器;
步骤2对每一个1-依赖子分类器,利用式(9)计算漏洞样本的后验概率;
步骤3得到每一个1-依赖子分类器后验概率后,利用式(10)求平均值;
步骤4选择平均后验概率最大的漏洞类别存储于C(X)中;
步骤5输出测试集漏洞类别C(X)。
可以看出,与朴素贝叶斯相比,AODE 分类器关联了属性间的联系,弱化了条件独立性假设,使分类器算法更加符合实际需求。
4 实验与结果分析
通过对实验数据的获取,得到了漏洞文本分类实验所用的漏洞数据。包括漏洞ID、漏洞描述文本、漏洞对应的类别标签。接下来要通过获取的漏洞样本,训练漏洞分类模型,要进行以下步骤。首先,对漏洞文本数据进行预处理,进行分词和停用词过滤,去除数据冗余。其次,利用本文提出的S-C特征提取算法进行漏洞特征词的提取,利用获取的特征词集合对漏洞样本进行向量化。再次,利用AODE 分类器对漏洞样本进行分类。最后,利用准确率指标对比不同的特征提取算法和不同分类器模型,验证本文提出模型的优越性。
4.1 实验环境
为了验证本文提出的漏洞自动分类算法的准确性,实验在Windows 7操作系统,Intel®CoreTMi7-4510U处理器,主频为2.60 GHz,内存为8.00 GB的PC上进行。在Anaconda3版本的Spyder上进行编程建模,完成建模。
4.2 实验数据描述
本文以国际公认的美国国家计算机通用漏洞数据库NVD 中的descript 漏洞描述字段作为实验数据。并依据中国国家漏洞数据库CNNVD 中的漏洞类别,根据NVD与CNNVD中每条漏洞的CVE编号,确定出NVD 漏洞库中每条漏洞的类型,得到带有类别标签的实验数据。实验数据总共包含NVD漏洞库在1999—2018年间发布的72 005条漏洞记录。截至2018年年底,NVD漏洞数据库共包含了24种漏洞类型。其中包含了1 个未知漏洞类型,这类漏洞多达15 521 条,且属于未知类别的类型,因此对漏洞分类并无实际作用,将这类漏洞去除。最终得到本实验所用的56 484 条漏洞数据。从中选取20%的漏洞数据进行实验,利用其中90%的数据作为训练集,10%的数据作为测试集进行实验,实验所用漏洞数据的年份分布以及类别分布,如图3和图4所示。

Fig.3 Year distribution of experimental data图3 实验数据年份分布图

Fig.4 Class distribution diagram of experimental data图4 实验数据类别分布图
本文根据进行实验所需的漏洞数据,利用Python导入漏洞信息,包括CVE 编号、漏洞文本描述、漏洞类型三部分。部分数据如表1所示。
4.3 实验过程描述
4.3.1 漏洞数据预处理
(1)对漏洞文本数据进行分词
分词是文本数据预处理过程中最关键的步骤之一,目的是将连贯漏洞文本描述语句切分成一个一个的独立的单词,以便将整个文本信息转化为可以进行数学统计及复杂分析的词语集合。由于本文漏洞的描述信息是英文文本,而英文文本是以单词为单位,词与词之间由空格或者标点符号分隔开来,因此只需要以空格或者标点作为分隔符,便可以将整个英文文本切分成独立的词语。

Table 1 Vulnerability data sheet表1 漏洞数据表
实验使用正则表达式进行漏洞描述文本的分词。如编号为CVE-1999-1431 的漏洞文本描述为“ZAK in Appstation mode allows users to bypass the"Run only allowed apps" policy by starting Explorer from Office 97...”。经过分词操作后,得到了单词的集合为['zak','in','appstation','mode','allows','users','to','bypass','the','','run','only','allowed','apps','','policy','by','starting','explorer','from','office','97'...]。
(2)对漏洞文本数据进行停用词过滤
停用词过滤是指去除掉在文档样本中频繁出现,但是对文本的内容、类别等不提供或提供非常少量信息的词,如连词、助词、介词以及代词等。另外,对于漏洞描述文本来说,“vulnerability”“allow”等词对于漏洞的分类几乎不能提供实质性信息,因此这类词语也应去掉。通过去除停用词,以大大减少文本数据的冗余信息,从而提高数据的处理效率以及后续分类算法的准确性。
如编号为CVE-1999-1431 的漏洞文本经过去除停用词后得到的词语集合为['zak','appstation','mode','users','bypass''run','only','allowed','apps','policy','starting','explorer','from','office','97','a pplications'...]。此漏洞文本经过分词处理后,得到52个词,经过过滤停用词后词语个数变为30 个。可见,去除停用词可以减少数据的冗余。
4.3.2 使用S-C 特征提取法提取特征
实验数据通过上述的文本预处理操作之后,得到候选的特征词集。使用本文提出的S-C特征提取法进行特征词的提取。首先计算每个词语的综合函数C与信息熵S,其次计算出每个词语的S-C值。下面以SQL注入类别中的几个词语为例,可以看出,由于信息熵的作用,词语的重要程度排序发生了改变。本实验中部分词语的C值、S值、S-C值,以及词语重要程度排序如表2所示。

Table 2 WordC/S/S-C value sort table表2 词语C/S/S-C 值排序表
选取特征时,将每个漏洞类别的特征词根据S-C值进行降序排序,每个类别分别选取前n个词语共同构成最终的特征词集合。本实验最终选取每个类别前10个特征词构成特征集合,实验选取的特征如表3所示。
4.3.3 建立特征词向量
要通过机器学习算法对文本数据进行分析,要先把文本信息转化成离散的数字表示的向量,以便利用算法对文本数据进行操作。利用经过预处理得到的一个个漏洞的词集合,根据S-C特征提取法提取的n个特征,将每一个漏洞描述文本信息转换成一个n维的向量vi={t1,t2,…,tn}。由于漏洞文本属于短文本,特征词是否出现是决定类别的关键,本实验并不关心特征词出现的频率。将漏洞样本的向量化定义为:如果特征词tj出现在第i个漏洞词集中,则令vi(j)=1;如果特征词tj没有出现在第i个漏洞词集中,则令vi(j)=0;以此完成漏洞的向量表示。例如,CVE-2001-1376的向量表示如表4所示。
4.3.4 使用AODE分类器分类
实验利用经过预处理和向量化的漏洞数据作为实验数据,使用AODE分类器训练出分类模型。
4.4 实验结果分析
为验证本文提出漏洞分类器的有效性,实验用不同的特征提取方法和不同的分类器算法分别对漏洞数据进行分类,并利用准确率Accuracy作为评价指标,评价分类器的优劣。

Table 3 Set of feature words表3 特征词集合

Table 4 CVE-2001-1376 vectors表4 CVE-2001-1376的向量表示
4.4.1 评价指标
为了对特征提取算法以及分类器算法进行优劣的比较,需要统一评价标准。本文使用准确率Accuracy作为评价指标,准确率是指漏洞样本属于分类器所判定的漏洞类别的概率。公式如下所示:

其中,TPi是指属于第i类的漏洞样本被分类器判定为第i类的漏洞个数;FPi是指属于第i类的漏洞样本被分类器判定为其他类别的漏洞个数。因此,利用准确率这一评价指标,可以计算出分类器将漏洞分对类别的比例,以判定分类器的优劣。
4.4.2 不同特征提取方法的比较
为了验证本文提出的S-C特征提取方法的有效性,实验使用TFIDF 特征提取法[13]、综合函数C特征提取法和S-C特征提取法分别提取特征,利用朴素贝叶斯分类器进行漏洞分类,最终将漏洞分类的准确性进行比较,实验结果如图5所示。

Fig.5 Comparison chart of feature selection accuracy图5 特征选择准确率对比图
由实验结果可以看出,本文所提出的综合函数C特征提取法相比较TFIDF 特征提取法,准确率高出2.6 个百分点。验证了综合函数C,利用漏洞词语类间重要程度和类内重要程度,共同作为判定漏洞词语对区分类别的贡献程度的合理性。其次,基于信息熵改进的S-C特征提取法,相较TFIDF 特征提取法和综合函数C特征提取法,准确率分别高出5.6个百分点和3个百分点。验证了基于信息熵改进的S-C特征提取法能够有效地提高特征的选取质量,选取出了对分类更加有意义的特征词。
4.4.3 不同分类算法的比较
为了验证AODE 分类算法对于漏洞数据集的适用性,本文选取K近邻分类算法(K-nearest neighbor,KNN)[14]、决策树(decision tree,DT)[15]分类算法、朴素贝叶斯分类算法(naïve Bayes,NB)与平均一阶依赖贝叶斯分类算法(AODE)进行对比。实验结果如图6所示。

Fig.6 Comparison of classifier accuracy图6 分类器准确率对比图
根据实验结果对比可以看出,决策树分类算法和K近邻分类算法在漏洞数据集上的准确率分别为70.3%和74.8%,要低于朴素贝叶斯分类器和AODE分类器的准确率。说明在短文本的分类中,贝叶斯分类器有着良好的适用性。S-C-AODE 漏洞分类算法的准确率为86.9%,分别高于S-C-KNN 分类器和S-C-DT 分类器12.1 个百分点、16.6 个百分点,对比S-C-NB 分类器提高了2.1 个百分点。证明了SC-AODE 漏洞分类算法对于漏洞文本分类的准确性,要优于传统的机器学习算法。
5 结束语
为了对海量增长的计算机漏洞实现有效的自动化分类管理,本文对计算机漏洞数据进行了分析研究。获取了NVD 和CNNVD 漏洞数据库中的数据,通过对漏洞描述字段的分析,本文定义了综合函数C来表明词语对类别的重要程度,并利用词语对于类别的信息熵,修正词语的重要程度。提出了基于S-C特征提取方法,并有效提取了漏洞的特征词集合。结合AODE分类器对计算机漏洞进行了文本分类。通过实验对比表明,S-C特征提取法能够有效提取较优特征词集,并且结合AODE 分类器的分类效果要优于传统的分类器模型,验证了本文提出模型分类的准确性。
